Processing 1 million requests per minute with Go
- Transfer
I offer readers of Habrahabr a translation of an article by the chief architect of Malwarebytes about how they achieved processing 1 million requests per minute on just 4 servers.
At Malwarebytes, we are experiencing wild growth, and since I joined the company about a year ago in Silicon Valley, one of my main responsibilities has been the design and development of several systems architectures to develop a fast-growing company and all the necessary infrastructure to support a product that used by millions of people every day. I have been working in the antivirus industry for more than 12 years in several different companies, and I know how complicated these systems are as a result, due to the enormous amounts of data that I have to deal with every day.
What is interesting is that for the last 9 years or so, all of the web backend development I've come across has been done on Ruby on Rails. Don’t get me wrong, I love Ruby on Rails and I believe that this is a great environment, but after a while you get used to thinking about developing Ruby style systems and you forget how efficient and simple your architecture could be if you involved multithreading, concurrency, fast execution and efficient use of memory. For many years I wrote in C / C ++, Delphi, and C #, and I began to realize how less complicated things could be if you chose the right tool for the job.
As the Chief Architect, I am not a fan of holivars about the languages and frameworks that are so popular on the net. I believe that the effectiveness, productivity and maintainability of the code depends mainly on how simple you can build your solution.
Working on one of the parts of our anonymous telemetry and analytics collection system, we were faced with the task of processing a huge number of POST requests from millions of customers. The web processor should have received a JSON document, which may contain a collection of data (payload), which, in turn, must be stored on Amazon S3, so that our map-reduce systems will process this data later.
Traditionally, we would look towards the worker-tier architecture, and use things like:
And they would install 2 different clusters, one for the web frontend, and the other for workers, so that background tasks could be scaled.
But from the very beginning, our team knew that we should write it on Go, since at the stage of discussion we already understood that this system would have to cope with huge traffic. I used Go for about 2 years, and we developed several systems on it, but none of them have worked with such loads so far.
We started by creating several structures to describe the request data that will be accepted in POST requests, and a method for downloading them to our S3 bucket.
Initially, we took the simplest naive solution of a POST handler, just trying to parallelize the processing using a simple go-routine:
For medium loads, this approach will work for most people, but it quickly proved to be ineffective on a larger scale. We expected that there would be many requests, but when we rolled out the first version in production, we realized that we were mistaken by orders of magnitude. We completely underestimated the amount of traffic.
The approach above is bad for several reasons. There is no way to control how much goroutine we run. And since we received 1 million POST requests per minute, this code, of course, quickly crashed and crashed.
We had to find another way. From the very beginning, we discussed that we need to reduce the processing time of the request to a minimum and do heavy tasks in the background. Of course, this is how you should do it in the world of Ruby on Rails, otherwise you will be blocked by all available web handlers, and it does not matter if you use puma, unicorn or passenger (Just let's not discuss JRuby here, please). So we would have to use generally accepted solutions for such tasks as Resque, Sidekiq, SQS, etc. ... This list is large, since there are many ways to solve our problem.
And our second attempt was to create a buffered channel in which we could place the task queue and upload them to S3, and since we can control the maximum number of objects in our queue, and we have a bunch of RAM to keep everything in memory, we decided that it would be quite simple to buffer tasks in the queue channel.
And then, in fact, to read tasks from the queue and process them, we used something similar to this code:
Honestly, I have no idea what we were thinking then. This, apparently, was late at night, with a bunch of drunk Red Bulls. This approach did not give us any gain, we simply exchanged poor competitiveness for a buffered channel and this simply postponed the problem. Our synchronous queue processor loaded only one packet of data on S3 per unit of time, and since the frequency of incoming requests was much higher than the ability of the processor to load them on S3, our buffered channel very quickly reached its limit and blocked the ability to add new tasks to the queue.
We silently ignored the problem and launched a countdown of our system crash. Response time (latency) increased in accrual several minutes after we deployed this buggy version.
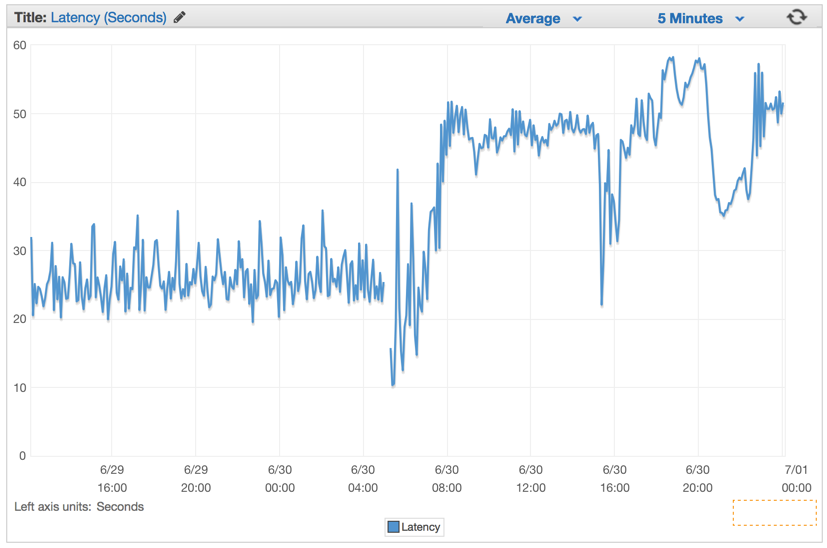
We decided to use the popular pattern of working with channels in Go to create a two-level system of channels, one for working with a channel queue, the other for controlling the number of task handlers working with a queue at a time.
The idea was to parallelize the download on S3, controlling this process, so as not to overload the machine and not rest on connection errors with S3. Therefore, we chose the Job / Worker pattern. For those familiar with Java, C #, etc, consider this a Go-way for implementing Worker Thread-Pool using pipes.
We changed our request handler so that it creates an object of type Job with data, and sends it to the JobQueue channel so that it can be picked up by task handlers.
During server initialization, we create a Dispatcher and call Run () to create a pool of workers and start listening to incoming tasks in JobQueue.
Below is our dispatcher implementation code:
Note that we indicate the number of handlers that will be launched and added to the pool. Since we used the Amazon Elasticbeanstalk for this project and the dockerized Go environment, and always tried to follow a twelve -factor methodology to configure our systems in production, we read these values from environment variables. Thus, we can control the number of handlers and the maximum queue size in order to quickly tighten these parameters without re-deploying the entire cluster.
Immediately after we deployed the last solution, we saw that the response time dropped to insignificant numbers and our ability to process requests grew radically.
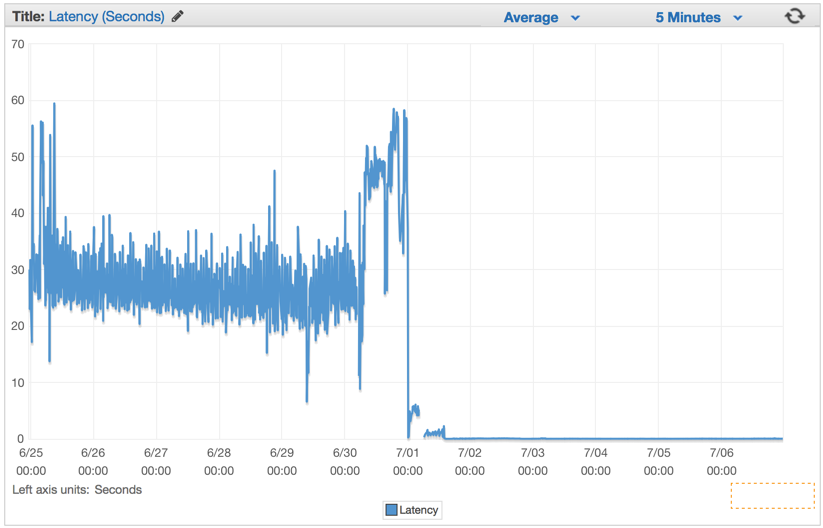
A few minutes after warming up the Elastic Load Balancers, we saw that our ElasticBeanstalk application processes about 1 million requests per minute. We usually have a few hours in the morning, when traffic peaks reach more than 1 million requests per minute.
As soon as we deployed the new code, the number of required servers dropped significantly, from 100 to about 20 servers.
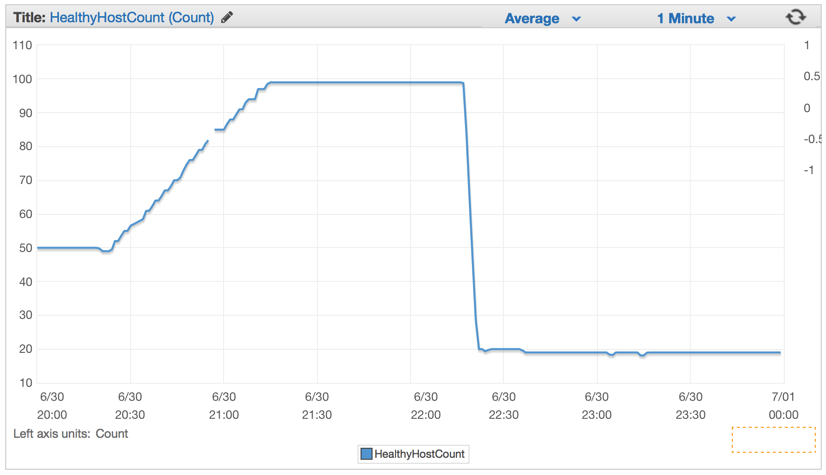
After we set up our cluster and auto-scaling settings, we were able to reduce their number even more - up to 4 EC c4.large instances and Elastic Auto-Scaling launched a new instance if CPU usage exceeded 90% for 5 minutes .
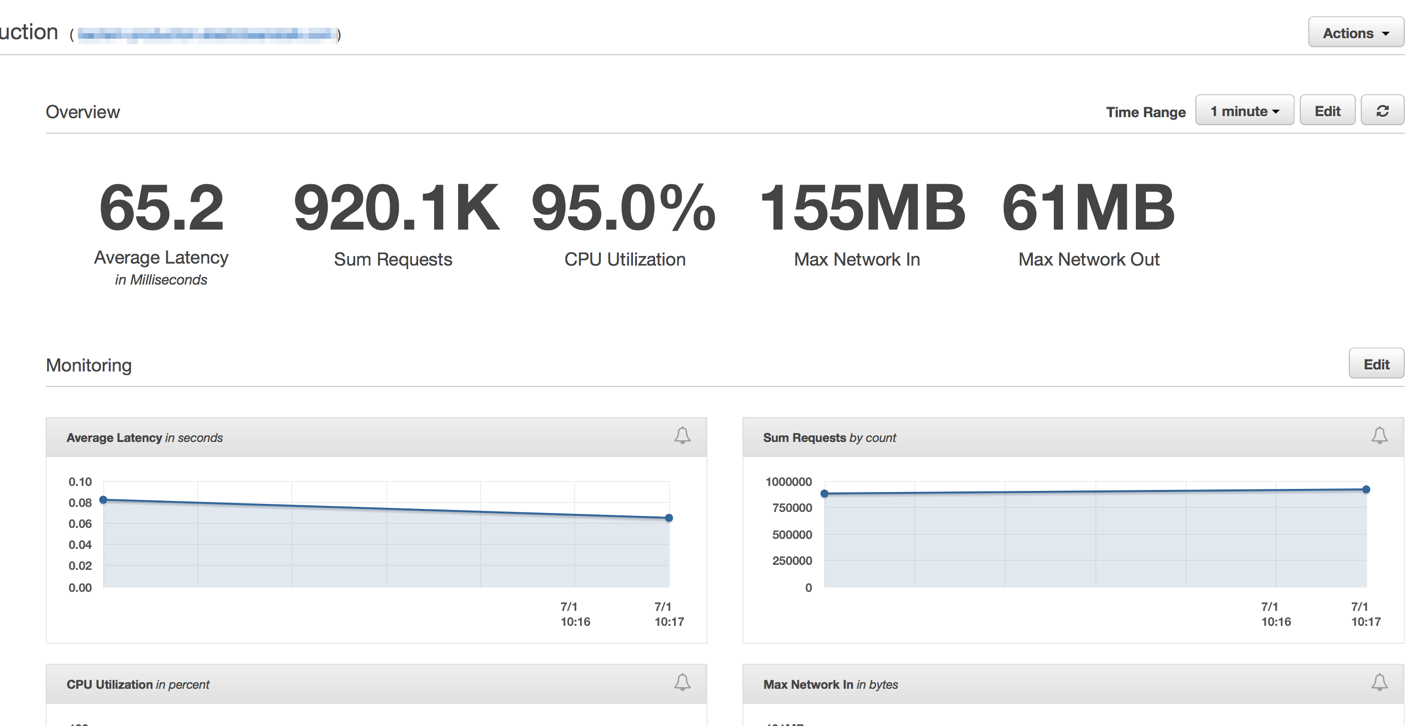
I am deeply convinced that simplicity always wins. We could create a complex system with a bunch of queues, background processes, a complex deploy, but instead of all this, we decided to use the power of ElasticBeanstalk auto-scaling and the efficiency and simplicity of the competitive approach that Golang gives out of the box.
Not every day you see a cluster of only 4 machines, which are even weaker than my current Macbook Pro, processing POST requests, writing to the Amazon S3 bucket 1 million times every minute.
There is always the right tool for the task. And for those cases when your Ruby on Rails system needs a more powerful web handler, exit a little from the ruby ecosystem for simpler, yet more powerful solutions.
At Malwarebytes, we are experiencing wild growth, and since I joined the company about a year ago in Silicon Valley, one of my main responsibilities has been the design and development of several systems architectures to develop a fast-growing company and all the necessary infrastructure to support a product that used by millions of people every day. I have been working in the antivirus industry for more than 12 years in several different companies, and I know how complicated these systems are as a result, due to the enormous amounts of data that I have to deal with every day.
What is interesting is that for the last 9 years or so, all of the web backend development I've come across has been done on Ruby on Rails. Don’t get me wrong, I love Ruby on Rails and I believe that this is a great environment, but after a while you get used to thinking about developing Ruby style systems and you forget how efficient and simple your architecture could be if you involved multithreading, concurrency, fast execution and efficient use of memory. For many years I wrote in C / C ++, Delphi, and C #, and I began to realize how less complicated things could be if you chose the right tool for the job.
As the Chief Architect, I am not a fan of holivars about the languages and frameworks that are so popular on the net. I believe that the effectiveness, productivity and maintainability of the code depends mainly on how simple you can build your solution.
Problem
Working on one of the parts of our anonymous telemetry and analytics collection system, we were faced with the task of processing a huge number of POST requests from millions of customers. The web processor should have received a JSON document, which may contain a collection of data (payload), which, in turn, must be stored on Amazon S3, so that our map-reduce systems will process this data later.
Traditionally, we would look towards the worker-tier architecture, and use things like:
- Sidekiq
- Resque
- DelayedJob
- Elasticbeanstalk Worker Tier
- Rabbitmq
- etc
And they would install 2 different clusters, one for the web frontend, and the other for workers, so that background tasks could be scaled.
But from the very beginning, our team knew that we should write it on Go, since at the stage of discussion we already understood that this system would have to cope with huge traffic. I used Go for about 2 years, and we developed several systems on it, but none of them have worked with such loads so far.
We started by creating several structures to describe the request data that will be accepted in POST requests, and a method for downloading them to our S3 bucket.
type PayloadCollection struct {
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// [redacted]
}
func (p *Payload) UploadToS3() error {
// the storageFolder method ensures that there are no name collision in
// case we get same timestamp in the key name
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// Everything we post to the S3 bucket should be marked 'private'
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}Go-ahead solution with Go routines
Initially, we took the simplest naive solution of a POST handler, just trying to parallelize the processing using a simple go-routine:
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
w.WriteHeader(http.StatusOK)
}For medium loads, this approach will work for most people, but it quickly proved to be ineffective on a larger scale. We expected that there would be many requests, but when we rolled out the first version in production, we realized that we were mistaken by orders of magnitude. We completely underestimated the amount of traffic.
The approach above is bad for several reasons. There is no way to control how much goroutine we run. And since we received 1 million POST requests per minute, this code, of course, quickly crashed and crashed.
Try again
We had to find another way. From the very beginning, we discussed that we need to reduce the processing time of the request to a minimum and do heavy tasks in the background. Of course, this is how you should do it in the world of Ruby on Rails, otherwise you will be blocked by all available web handlers, and it does not matter if you use puma, unicorn or passenger (Just let's not discuss JRuby here, please). So we would have to use generally accepted solutions for such tasks as Resque, Sidekiq, SQS, etc. ... This list is large, since there are many ways to solve our problem.
And our second attempt was to create a buffered channel in which we could place the task queue and upload them to S3, and since we can control the maximum number of objects in our queue, and we have a bunch of RAM to keep everything in memory, we decided that it would be quite simple to buffer tasks in the queue channel.
var Queue chan Payload
func init() {
Queue = make(chan Payload, MAX_QUEUE)
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
...
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
Queue <- payload
}
...
}And then, in fact, to read tasks from the queue and process them, we used something similar to this code:
func StartProcessor() {
for {
select {
case job := <-Queue:
job.payload.UploadToS3() // <-- STILL NOT GOOD
}
}
}Honestly, I have no idea what we were thinking then. This, apparently, was late at night, with a bunch of drunk Red Bulls. This approach did not give us any gain, we simply exchanged poor competitiveness for a buffered channel and this simply postponed the problem. Our synchronous queue processor loaded only one packet of data on S3 per unit of time, and since the frequency of incoming requests was much higher than the ability of the processor to load them on S3, our buffered channel very quickly reached its limit and blocked the ability to add new tasks to the queue.
We silently ignored the problem and launched a countdown of our system crash. Response time (latency) increased in accrual several minutes after we deployed this buggy version.
The best decision
We decided to use the popular pattern of working with channels in Go to create a two-level system of channels, one for working with a channel queue, the other for controlling the number of task handlers working with a queue at a time.
The idea was to parallelize the download on S3, controlling this process, so as not to overload the machine and not rest on connection errors with S3. Therefore, we chose the Job / Worker pattern. For those familiar with Java, C #, etc, consider this a Go-way for implementing Worker Thread-Pool using pipes.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job represents the job to be run
type Job struct {
Payload Payload
}
// A buffered channel that we can send work requests on.
var JobQueue chan Job
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// we have received a work request.
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}We changed our request handler so that it creates an object of type Job with data, and sends it to the JobQueue channel so that it can be picked up by task handlers.
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}During server initialization, we create a Dispatcher and call Run () to create a pool of workers and start listening to incoming tasks in JobQueue.
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()Below is our dispatcher implementation code:
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtain a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}Note that we indicate the number of handlers that will be launched and added to the pool. Since we used the Amazon Elasticbeanstalk for this project and the dockerized Go environment, and always tried to follow a twelve -factor methodology to configure our systems in production, we read these values from environment variables. Thus, we can control the number of handlers and the maximum queue size in order to quickly tighten these parameters without re-deploying the entire cluster.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)Instant result
Immediately after we deployed the last solution, we saw that the response time dropped to insignificant numbers and our ability to process requests grew radically.
A few minutes after warming up the Elastic Load Balancers, we saw that our ElasticBeanstalk application processes about 1 million requests per minute. We usually have a few hours in the morning, when traffic peaks reach more than 1 million requests per minute.
As soon as we deployed the new code, the number of required servers dropped significantly, from 100 to about 20 servers.
After we set up our cluster and auto-scaling settings, we were able to reduce their number even more - up to 4 EC c4.large instances and Elastic Auto-Scaling launched a new instance if CPU usage exceeded 90% for 5 minutes .
conclusions
I am deeply convinced that simplicity always wins. We could create a complex system with a bunch of queues, background processes, a complex deploy, but instead of all this, we decided to use the power of ElasticBeanstalk auto-scaling and the efficiency and simplicity of the competitive approach that Golang gives out of the box.
Not every day you see a cluster of only 4 machines, which are even weaker than my current Macbook Pro, processing POST requests, writing to the Amazon S3 bucket 1 million times every minute.
There is always the right tool for the task. And for those cases when your Ruby on Rails system needs a more powerful web handler, exit a little from the ruby ecosystem for simpler, yet more powerful solutions.