EPAM, collect me the genome
If we compare a person with a computer, then his body is hardware, and what breathes life into him is software. And today we will talk about human software - its genome.

At present, it is difficult to surprise anyone with the terms “gene,” “genome,” “DNA,” so tightly into our daily lives. Everyone heard that the human genome has been deciphered, but few of us clearly understand the importance of this scientific breakthrough for all of humanity. Correction of human "weaknesses", increasing life expectancy and finding more and more effective ways to combat crime - all this is possible thanks to the study of hereditary information contained in the human genome.
Since most of us have forgotten the school biology course somewhat, we suggest refreshing the basic concepts:
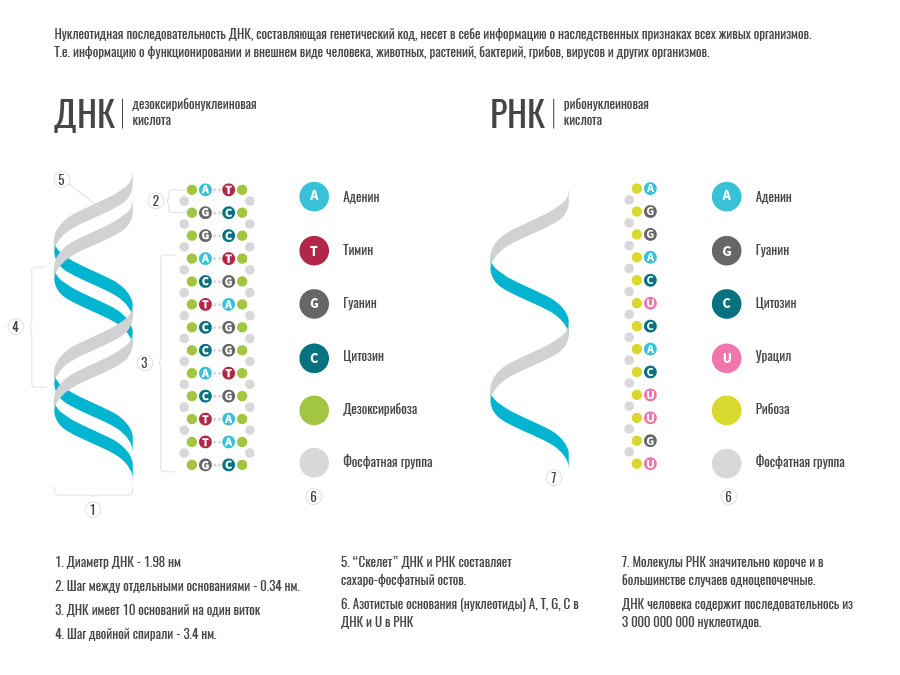
Deoxyribonucleic acid , better known as DNA , is a highly polymer natural compound contained in the nuclei of cells of all living organisms, a carrier of genetic information. DNA consists of 4 types of nucleotides. The basis of DNA nucleotides is deoxyribose sugar (the same for all nucleotides) and 4 types of nitrogenous bases - adenine (A), thymine (T), guanine (G) and cytosine. It is the nucleotide sequence that determines the information recorded in DNA. Individual sections of DNA correspond to specific genes.
Gene, in turn, is a physical (specific DNA site) and functional (encodes a protein or ribonucleic acid) unit of heredity. The most important property of genes is the combination of their high stability in a number of generations with the ability to inherited changes (mutations), which serves as the basis for the variability of organisms, which provides material for natural selection.
Ribonucleic Acids (RNA)- A type of nucleic acid that consists of 4 nucleotides based on ribose sugar and nitrogen bases - this is adenine, guanine, cytosine, uracil (A, C, G, U). Uracil (U) is a complete analogue of thymine (T) in DNA, so for our purposes they can be considered identical. In the cells of all living organisms, RNAs are involved in the realization of genetic information. An RNA copy is created from the genes in the DNA, which either functions by itself or serves as a matrix for protein synthesis.
What is a genome? The genome is DNA contained in the haploid set of chromosomes of a cell of a certain type of organism. In an expanded form, the genome refers to the entire hereditary system of the cell.
About 23 pairs of chromosomes in the human genome, I think, everyone remembers. Originally chromosomescalled the structure of a very tightly folded filament, which is formed in the cell at a certain moment in the process of division, and is visible in a conventional optical microscope. The DNA strand itself is also called a chromosome in a “straightened” state.
Reed is a separate reading of a DNA fragment. A locus , in turn, is the location of a particular gene on a genetic or cytological map of a chromosome.
Everyone has heard about the “decoding” of the human genome in one way or another. Unfortunately, the term “decryption” itself was chosen poorly, which constantly raises questions. It is correct to say that the human genome was read (sequenced) , i.e., the complete nucleotide sequence of all DNA strands was obtained.
Reading DNA is a very difficult technical task in itself. But even after reading such a genome appears to us in the form of a string consisting of four letters (A, C, G, T), and its length can reach several billion characters. At the same time, there are no absolutely clear “punctuation marks” in DNA that would indicate the beginning and end of sentence genes and other functionally significant elements. This huge information volume is somewhat similar to a complete computer memory dump. And to understand from this dump how our live computer works is a separate, much more difficult task.
Previously, only short pieces of the DNA sequence — individual genes and their fragments — were available for analysis. Thanks to the complete genome sequencing, it has become much easier to analyze the DNA “text” and look for functional areas in it. Over the past 10 years, scientists have made great strides in this direction. New genes were discovered whose mutant forms lead to cancer, atherosclerosis, Alzheimer's disease, and cardiovascular diseases. A person's predisposition to alcoholism, drug addiction, gambling, mental illness and even suicide has a genetic basis. Moreover, the tendency to search for new experiences, maternal instinct, aggressive behavior, activity and irritability are also under strict genetic control! Of course, not every opportunity inherent in DNA will be realized,
By the way, the traumatic experience of parents can be directly transmitted to descendants through the so-called epigenetic inheritance. The fears and stresses of the ancestors significantly affect the structure and function of the nervous system of subsequent generations. And if you are for some reason afraid of dogs, perhaps one of your ancestors was once bitten. This area has been studied very little, but is also actively developing.
A DNA test allows you to detect a person’s predisposition to certain diseases, including those caused by external causes (viruses, nutrition, etc.), identify a person, establish paternity, determine the compatibility of a donor and recipient during transplantation, and much more.
Sometimes it happens.In 2002, an American, Lydia Fairchild, during a divorce from her husband, underwent a DNA analysis procedure, which showed that she was not a mother to her two children. At that time she was already pregnant with the third, whose blood tests after birth showed that she was not a mother to him either. Further studies revealed that Lydia is a chimera, that is, an organism that has two different genomes.
Full sequencing of the genome of an individual person allows you to simultaneously get the full text of DNA and analyze all its genes at once instead of several thousand specialized tests for individual hereditary diseases. The Human Genome project took 5 years and several billion dollars. Modern machines allow you to completely sequence the human genome in 15-20 days at a price of about $ 1000 / genome. Then why are genome research and genomic diagnostics not happening as fast as we would like?
The fact is that no modern sequencer can read the entire DNA strand from beginning to end. For DNA sequencing, randomly cut into short fragments, which the sequencer then reads in large quantities in parallel. As a result, files of hundreds of gigabytes in size are obtained, in which there is an enormous number of short (150-300 nucleotides) reads.
Since there are many cells in one biological sample, and DNA is fragmented randomly, the read fragments will overlap many times.
To obtain the desired genome, you need to assemble this puzzle in full text. This is a colossal computing task, and processing such files takes a long time. All data is processed by special genomic assemblers, which collect the longest sections of the genome as long as possible.
The conventional wisdom that time is money is also true for genomic research. Deciphering the hereditary material opens up fantastic opportunities for medicine: from “repairing” defective genes to finding the secrets of eternal youth. And that is why many scientific institutes and private companies are making incredible efforts to accelerate the processing of the genome.
A large number of programs have been created to process and analyze the results of the sequence. However, the performance of sequencers and the amount of information received are growing at such a rate that developers often do not have time to optimize their programs to process an ever-increasing amount of data. There is a need to adapt the developed programs for parallel operation, the use of computing clusters, etc.
One of the clients turned to us for automation of the process of controlling the quality of genome assembly and reducing computational time.
At the moment we are optimizing various processes in order to minimize time and, consequently, costs. The work is carried out with small utilities that are involved in the calculation of metrics - numerical characteristics by which the experimenter controls the quality of sample preparation, sequencing and genome assembly. Metrics allow you to evaluate the file that is issued by the sequencer: is it suitable for further analysis of the genome or you need to conduct another experiment.
Thanks to the work of our department of algorithms, the calculation time for one metric was reduced from 11 hours to 105 minutes. Previously, a serious machine counted four metrics in 25 hours. We, with the help of multithreading and processing algorithms, have reduced this time by four times. And this is not the limit.
The optimization of metrics was to find points in the code for branching the calculation process. All metrics are different in structure, but they have one thing in common: they all read a .bam file, which stores data about individual readings of DNA fragments (reads).
The optimization scheme is simple: data processors use an iterator that reads one record from a file (SAMRecord), and analyze information with the accumulation of intermediate results (statistics) in certain data structures.
One of the optimized metrics allows you to collect statistics from a .bam file, with which you can evaluate how well the experiment was conducted. To distinguish a sequencing error from a mutation, the statistics should contain a sufficiently large number of individual readings of DNA fragments (reads). A very large coverage suggests that the experiment could have been cheaper without loss of quality. As a result, the metric provides information on how many aligned bases were filtered out due to poor quality.
What is the optimization? Initially, the algorithm calculated statistics for each location of a particular gene (locus), passing through all the reads covering this position. If the read consisted of 300 bases (and this is its standard length), then the algorithm read this DNA fragment 300 times to obtain information about the quality of its base. An algorithm optimized by one of our specialists reads data on the quality of all bases at the moment when the read occurs for the first time, which avoids accessing it for each locus. Information about the filtered bases is accumulated in the counter array, which shifts as it passes through the genome. Thus, statistics for each reading is collected only once, which can significantly speed up the data processing.
Another metric collects statistics about duplicates (i.e. identical reads that match up to a given number of bases). Based on these statistics, the complexity of the read library is estimated. Too many duplicates indicates that the experiment could have been cheaper. The low complexity of the library suggests that we are dealing with a small number of reads, which can distort the accuracy of the results in further work with the genome.
The original algorithm divided the reads into subsets, combining them according to the first n-elements. Then there was a comparison of the readings of DNA fragments for each of them. Obviously, such an algorithm works extremely slowly (for large subsets, time grows exponentially). Optimization in this case is the use of a modified LSH algorithm (locality-sensitive hashing algorithm ). Each read is divided into shingles, that is, small pieces that include several bases and the position of the beginning of this piece in the read. Next, a table is built in which information is stored on which reads this shingle is found in. Then, using random permutations, similar readings are determined, which are compared character by character. Using this optimization avoids a huge number of unnecessary comparisons.
As already mentioned above, our specialists were able to significantly reduce the calculation time for metrics. This became possible not only through the processing of algorithms, but also through multithreading. What changes were made?
A separate stream was created to read records from a .bam file, which accumulates them in a separate circular buffer (bounded buffer). As soon as the buffer is full, it is added to a bounded queue. Both the buffer and the queue of such filled buffers are limited for reasons of the finite amount of RAM allocated to the process.
Another thread (or several threads for some metrics) takes the next full buffer from this queue and uses it as a data source for an iterator. Further, everything acts in the same way as in the original scheme.
The accumulation of the results of processing records from several streams requires the use of new data structures for metric statistics. This is done in order to avoid a race condition. To this end, we have created additional classes for collecting statistics and apply atomic operations (atomics).
Atomic operations lead to relatively high costs of consolidating intermediate statistics from different flows for individual metrics. In order to speed up the processing, the records were made in the form of blocks of several hundred in a single stream.
Thanks to the optimization, the calculation time for metrics was reduced several times. However, this is not the limit. For sorted indexed .bam files, it is possible to switch to parallel reading and processing of data on individual chromosomes, which will further reduce the processing time of genome data.
We can talk about genetics and genome almost endlessly, since the topic is interesting and concerns us all. Perhaps, thanks to the constant work on the automation of genome processing, in a couple of years it will take literally several hours to decipher and assemble it, and the cost will drop so that absolutely everyone can afford to conduct gene analysis. Fantasy? Unlikely. Genomic technologies are now being developed almost according to Moore’s law; sequencer productivity doubles approximately every 2 years. Therefore, it is likely that over the next 10-15 years, genomic technology will become as common and familiar as smartphones and laptops have become.
PS Due to the limited volume, the article does not claim to be strictly scientific correct in the description of biological terms and processes.
At present, it is difficult to surprise anyone with the terms “gene,” “genome,” “DNA,” so tightly into our daily lives. Everyone heard that the human genome has been deciphered, but few of us clearly understand the importance of this scientific breakthrough for all of humanity. Correction of human "weaknesses", increasing life expectancy and finding more and more effective ways to combat crime - all this is possible thanks to the study of hereditary information contained in the human genome.
Bit of theory
Since most of us have forgotten the school biology course somewhat, we suggest refreshing the basic concepts:
Deoxyribonucleic acid , better known as DNA , is a highly polymer natural compound contained in the nuclei of cells of all living organisms, a carrier of genetic information. DNA consists of 4 types of nucleotides. The basis of DNA nucleotides is deoxyribose sugar (the same for all nucleotides) and 4 types of nitrogenous bases - adenine (A), thymine (T), guanine (G) and cytosine. It is the nucleotide sequence that determines the information recorded in DNA. Individual sections of DNA correspond to specific genes.
Gene, in turn, is a physical (specific DNA site) and functional (encodes a protein or ribonucleic acid) unit of heredity. The most important property of genes is the combination of their high stability in a number of generations with the ability to inherited changes (mutations), which serves as the basis for the variability of organisms, which provides material for natural selection.
Ribonucleic Acids (RNA)- A type of nucleic acid that consists of 4 nucleotides based on ribose sugar and nitrogen bases - this is adenine, guanine, cytosine, uracil (A, C, G, U). Uracil (U) is a complete analogue of thymine (T) in DNA, so for our purposes they can be considered identical. In the cells of all living organisms, RNAs are involved in the realization of genetic information. An RNA copy is created from the genes in the DNA, which either functions by itself or serves as a matrix for protein synthesis.
What is a genome? The genome is DNA contained in the haploid set of chromosomes of a cell of a certain type of organism. In an expanded form, the genome refers to the entire hereditary system of the cell.
About 23 pairs of chromosomes in the human genome, I think, everyone remembers. Originally chromosomescalled the structure of a very tightly folded filament, which is formed in the cell at a certain moment in the process of division, and is visible in a conventional optical microscope. The DNA strand itself is also called a chromosome in a “straightened” state.
Reed is a separate reading of a DNA fragment. A locus , in turn, is the location of a particular gene on a genetic or cytological map of a chromosome.
Genome and medicine
Everyone has heard about the “decoding” of the human genome in one way or another. Unfortunately, the term “decryption” itself was chosen poorly, which constantly raises questions. It is correct to say that the human genome was read (sequenced) , i.e., the complete nucleotide sequence of all DNA strands was obtained.
Reading DNA is a very difficult technical task in itself. But even after reading such a genome appears to us in the form of a string consisting of four letters (A, C, G, T), and its length can reach several billion characters. At the same time, there are no absolutely clear “punctuation marks” in DNA that would indicate the beginning and end of sentence genes and other functionally significant elements. This huge information volume is somewhat similar to a complete computer memory dump. And to understand from this dump how our live computer works is a separate, much more difficult task.
Previously, only short pieces of the DNA sequence — individual genes and their fragments — were available for analysis. Thanks to the complete genome sequencing, it has become much easier to analyze the DNA “text” and look for functional areas in it. Over the past 10 years, scientists have made great strides in this direction. New genes were discovered whose mutant forms lead to cancer, atherosclerosis, Alzheimer's disease, and cardiovascular diseases. A person's predisposition to alcoholism, drug addiction, gambling, mental illness and even suicide has a genetic basis. Moreover, the tendency to search for new experiences, maternal instinct, aggressive behavior, activity and irritability are also under strict genetic control! Of course, not every opportunity inherent in DNA will be realized,
By the way, the traumatic experience of parents can be directly transmitted to descendants through the so-called epigenetic inheritance. The fears and stresses of the ancestors significantly affect the structure and function of the nervous system of subsequent generations. And if you are for some reason afraid of dogs, perhaps one of your ancestors was once bitten. This area has been studied very little, but is also actively developing.
A DNA test allows you to detect a person’s predisposition to certain diseases, including those caused by external causes (viruses, nutrition, etc.), identify a person, establish paternity, determine the compatibility of a donor and recipient during transplantation, and much more.
Sometimes it happens.In 2002, an American, Lydia Fairchild, during a divorce from her husband, underwent a DNA analysis procedure, which showed that she was not a mother to her two children. At that time she was already pregnant with the third, whose blood tests after birth showed that she was not a mother to him either. Further studies revealed that Lydia is a chimera, that is, an organism that has two different genomes.
Genome and bioinformatics
Full sequencing of the genome of an individual person allows you to simultaneously get the full text of DNA and analyze all its genes at once instead of several thousand specialized tests for individual hereditary diseases. The Human Genome project took 5 years and several billion dollars. Modern machines allow you to completely sequence the human genome in 15-20 days at a price of about $ 1000 / genome. Then why are genome research and genomic diagnostics not happening as fast as we would like?
The fact is that no modern sequencer can read the entire DNA strand from beginning to end. For DNA sequencing, randomly cut into short fragments, which the sequencer then reads in large quantities in parallel. As a result, files of hundreds of gigabytes in size are obtained, in which there is an enormous number of short (150-300 nucleotides) reads.
Since there are many cells in one biological sample, and DNA is fragmented randomly, the read fragments will overlap many times.
To obtain the desired genome, you need to assemble this puzzle in full text. This is a colossal computing task, and processing such files takes a long time. All data is processed by special genomic assemblers, which collect the longest sections of the genome as long as possible.
EPAM, collect me the genome
The conventional wisdom that time is money is also true for genomic research. Deciphering the hereditary material opens up fantastic opportunities for medicine: from “repairing” defective genes to finding the secrets of eternal youth. And that is why many scientific institutes and private companies are making incredible efforts to accelerate the processing of the genome.
A large number of programs have been created to process and analyze the results of the sequence. However, the performance of sequencers and the amount of information received are growing at such a rate that developers often do not have time to optimize their programs to process an ever-increasing amount of data. There is a need to adapt the developed programs for parallel operation, the use of computing clusters, etc.
One of the clients turned to us for automation of the process of controlling the quality of genome assembly and reducing computational time.
At the moment we are optimizing various processes in order to minimize time and, consequently, costs. The work is carried out with small utilities that are involved in the calculation of metrics - numerical characteristics by which the experimenter controls the quality of sample preparation, sequencing and genome assembly. Metrics allow you to evaluate the file that is issued by the sequencer: is it suitable for further analysis of the genome or you need to conduct another experiment.
Metrics and algorithms - work optimization
Thanks to the work of our department of algorithms, the calculation time for one metric was reduced from 11 hours to 105 minutes. Previously, a serious machine counted four metrics in 25 hours. We, with the help of multithreading and processing algorithms, have reduced this time by four times. And this is not the limit.
The optimization of metrics was to find points in the code for branching the calculation process. All metrics are different in structure, but they have one thing in common: they all read a .bam file, which stores data about individual readings of DNA fragments (reads).
The optimization scheme is simple: data processors use an iterator that reads one record from a file (SAMRecord), and analyze information with the accumulation of intermediate results (statistics) in certain data structures.
One of the optimized metrics allows you to collect statistics from a .bam file, with which you can evaluate how well the experiment was conducted. To distinguish a sequencing error from a mutation, the statistics should contain a sufficiently large number of individual readings of DNA fragments (reads). A very large coverage suggests that the experiment could have been cheaper without loss of quality. As a result, the metric provides information on how many aligned bases were filtered out due to poor quality.
What is the optimization? Initially, the algorithm calculated statistics for each location of a particular gene (locus), passing through all the reads covering this position. If the read consisted of 300 bases (and this is its standard length), then the algorithm read this DNA fragment 300 times to obtain information about the quality of its base. An algorithm optimized by one of our specialists reads data on the quality of all bases at the moment when the read occurs for the first time, which avoids accessing it for each locus. Information about the filtered bases is accumulated in the counter array, which shifts as it passes through the genome. Thus, statistics for each reading is collected only once, which can significantly speed up the data processing.
Another metric collects statistics about duplicates (i.e. identical reads that match up to a given number of bases). Based on these statistics, the complexity of the read library is estimated. Too many duplicates indicates that the experiment could have been cheaper. The low complexity of the library suggests that we are dealing with a small number of reads, which can distort the accuracy of the results in further work with the genome.
The original algorithm divided the reads into subsets, combining them according to the first n-elements. Then there was a comparison of the readings of DNA fragments for each of them. Obviously, such an algorithm works extremely slowly (for large subsets, time grows exponentially). Optimization in this case is the use of a modified LSH algorithm (locality-sensitive hashing algorithm ). Each read is divided into shingles, that is, small pieces that include several bases and the position of the beginning of this piece in the read. Next, a table is built in which information is stored on which reads this shingle is found in. Then, using random permutations, similar readings are determined, which are compared character by character. Using this optimization avoids a huge number of unnecessary comparisons.
Multithreading
As already mentioned above, our specialists were able to significantly reduce the calculation time for metrics. This became possible not only through the processing of algorithms, but also through multithreading. What changes were made?
A separate stream was created to read records from a .bam file, which accumulates them in a separate circular buffer (bounded buffer). As soon as the buffer is full, it is added to a bounded queue. Both the buffer and the queue of such filled buffers are limited for reasons of the finite amount of RAM allocated to the process.
Another thread (or several threads for some metrics) takes the next full buffer from this queue and uses it as a data source for an iterator. Further, everything acts in the same way as in the original scheme.
The accumulation of the results of processing records from several streams requires the use of new data structures for metric statistics. This is done in order to avoid a race condition. To this end, we have created additional classes for collecting statistics and apply atomic operations (atomics).
Atomic operations lead to relatively high costs of consolidating intermediate statistics from different flows for individual metrics. In order to speed up the processing, the records were made in the form of blocks of several hundred in a single stream.
Thanks to the optimization, the calculation time for metrics was reduced several times. However, this is not the limit. For sorted indexed .bam files, it is possible to switch to parallel reading and processing of data on individual chromosomes, which will further reduce the processing time of genome data.
In the end
We can talk about genetics and genome almost endlessly, since the topic is interesting and concerns us all. Perhaps, thanks to the constant work on the automation of genome processing, in a couple of years it will take literally several hours to decipher and assemble it, and the cost will drop so that absolutely everyone can afford to conduct gene analysis. Fantasy? Unlikely. Genomic technologies are now being developed almost according to Moore’s law; sequencer productivity doubles approximately every 2 years. Therefore, it is likely that over the next 10-15 years, genomic technology will become as common and familiar as smartphones and laptops have become.
PS Due to the limited volume, the article does not claim to be strictly scientific correct in the description of biological terms and processes.