I’ll calculate you over networks: we use the APIs of the largest social networks for my own selfish purposes

It's no secret that modern social networks are huge databases containing a lot of interesting information about the privacy of their users. You won’t get much data through the web-face, but each network has its own API ... So let's see how this can be used to find users and collect information about them.
There is a discipline in US intelligence such as OSINT (Open source intelligence), which is responsible for finding, collecting and selecting information from public sources. One of the largest providers of publicly available information includes social networks. After all, almost every one of us has an account (and someone has more than one) in one or more social networks. Here we share our news, personal photos, tastes (for example, like something or joining a group), the circle of our acquaintances. And we do this of our own free will and practically do not think about the possible consequences. The pages of the magazine have repeatedly considered how to extract interesting data from social networks using various tricks. Usually, for this it was necessary to manually perform some kind of manipulation. But for successful reconnaissance, it is more logical to use special utilities. There are several open source utilities that allow you to pull information about users from social networks.
Creepy
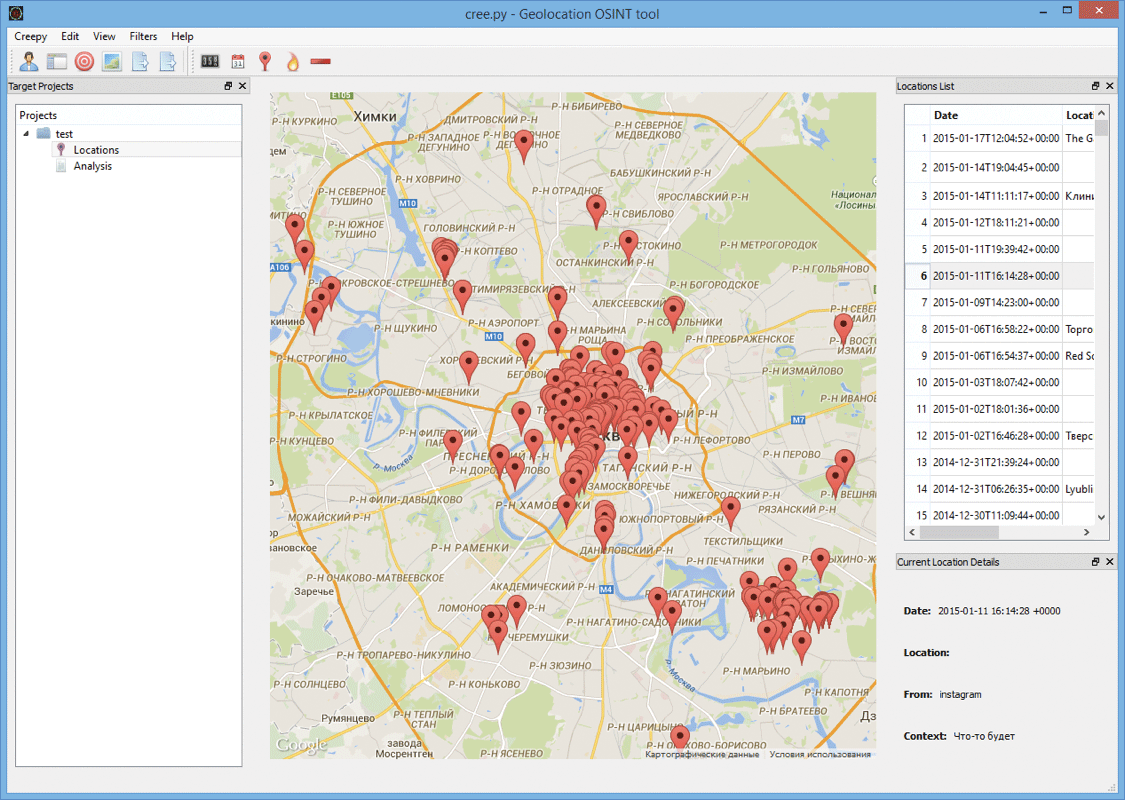
One of the most popular is Creepy.. It is designed to collect geolocation information about the user based on data from his Twitter, Instagram, Google+ and Flickr accounts. The advantages of this tool, which is standardly included in Kali Linux, include an intuitive interface, a very convenient process for obtaining tokens for using API services, as well as displaying the results found by labels on the map (which, in turn, allows you to track all user movements). The disadvantages I would include a rather weak functionality. Tulsa knows how to collect geotags for the listed services and display them on a Google map, shows who and how many times the user retweeted, considers statistics on the devices from which tweets were written, as well as the time they were published. But due to the fact that this is an open source tool, its functionality can always be expanded by yourself.
We will not consider how to use the program - everything is perfectly shown in the official video , after watching which there should not be any questions about working with the tool.
fbStalker
Two other tools that are less well-known but have strong functionality and deserve your attention are fbStalker and geoStalker .
fbStalker is designed to collect user information based on its Facebook profile. Allows you to get the following data:
- videos, photos, user posts;
- who and how many times liked his posts;
- geolocation of photos;
- statistics of comments on his posts and photos;
- the time that he usually visits online.
For this tool to work, you will need Google Chrome, ChromeDriver, which is installed as follows:
wget http://goo.gl/Kvh33W
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver /usr/bin/chromedriver
chmod 777 /usr/bin/chromedriver
In addition, you will need installed Python 2.7, as well as pip to install the following packages:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
And finally, you need a library for parsing GraphML files:
git clone https://github.com/hadim/pygraphml.git
cd pygraphml
python2.7 setup.py install
After that, it will be possible to fix `fbstalker.py`, indicating there your soap, password, username, and proceed with the search. Using tools is quite simple:
python fbstalker.py -user [имя интересующего пользователя]
geoStalker
geoStalker is much more interesting. He collects information on the coordinates that you gave him. For instance:
- local Wi-Fi-points based on the base `wigle.net` (in particular, their` essid`, `bssid`,` geo`);
- Checks from Foursquare;
- Instagram and Flickr accounts from which photos were posted with reference to these coordinates;
- all tweets made in the area.
For the tool to work, as in the previous case, you will need Chrome & ChromeDriver, Python 2.7, pip (to install the following packages: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite , TwitterSearch, foursquare), as well as pygraphml and gdata:
git clone https://github.com/hadim/pygraphml.git
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode.com/files/gdata-2.0.18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
After that, edit `geostalker.py`, filling out all the necessary API keys and access tokens (if for any social network this data is not specified, then it simply will not participate in the search). Then we launch the tool with the command `sudo python2.7 geostalker.py` and specify the address or coordinates. As a result, all data is collected and placed on a Google map, and also saved in an HTML file.
Move on to action
Before that, it was about ready-made tools. In most cases, their functionality will be lacking and you will either have to modify them or write your own tools - all popular social networks provide their APIs. Usually they appear as a separate subdomain to which we send GET requests, and in response we get XML / JSON responses. For example, for "Instagram" it is `api.instagram.com`, for" Contact "it is` api.vk.com`. Of course, most of these APIs have their own library of functions for working with them, but we want to understand how it works, and weight the script with unnecessary external libraries due to one or two functions not comme il faut. So, let's take and write our own tool that would allow us to search for photos from VK and Instagram based on the given coordinates and time interval.
Using the documentation for API VK and Instagram, we make requests for a list of photos by geographical information and time.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat=" + location_latitude
+ "&lng=" + location_longitude
+ "&distance=" + distance
+ "&min_timestamp=" + timestamp
+ "&max_timestamp=" + (timestamp + date_increment)
+ "&access_token=" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat=" + location_latitude
+ "&long=" + location_longitude
+ "&count=" + 100
+ "&radius=" + distance
+ "&start_time=" + timestamp
+ "&end_time=" + (timestamp + date_increment)
The variables used here are:
- location_latitude - geographical latitude;
- location_longitude - geographical longitude;
- distance - search radius;
- timestamp - the initial boundary of the time interval;
- date_increment - the number of seconds from the start to the end of the time interval;
- access_token - developer token.
As it turned out, access to Instagram requires access_token. It’s easy to get it, but you’ll have to get a little confused (see sidebar). Contact is more loyal to strangers, which is very good for us.
Getting Instagram Access Token
To get started, register on instagram. After registration, go to the following link:
instagram.com/developer/clients/manage
Click ** Register a New Client **. Enter the phone number, wait for the message and enter the code. In the window for creating a new client that opens, we need to fill in the important fields for us as follows:
- OAuth redirect_uri: localhost
- Disable implicit OAuth: checkmark must be unchecked
The remaining fields are filled arbitrarily. Once everything is full, create a new client. Now you need to get the token. To do this, enter the following URL in the address bar of the browser:https://instagram.com/oauth/authorize/?client_id=[CLIENT_ID]&redirect_uri=http://localhost/&response_type=token
where instead of [CLIENT_ID] specify the Client ID of the client you created. After that, follow the link, and if you did everything correctly, then you will be forwarded to localhost and Access Token will be written in the address bar.http://localhost/#access_token=[Access Token]
You can read more about this method of obtaining a token at the following link: jelled.com/instagram/access-token .
Automate the process
So, we learned how to make the necessary queries, but manually parsing the server response (in the form of JSON / XML) is not the coolest thing. It is much more convenient to make a small script that will do this for us. We will use again Python 2.7. The logic is as follows: we are looking for all the photos that fall in a given radius relative to the given coordinates in a given period of time. But consider one very important point - a limited number of photos are displayed. Therefore, for a large period of time, you will have to make several requests with intermediate time intervals (just date_increment). Also consider the coordinate error and do not specify a radius of several meters. And do not forget that time must be specified in timestamp.
We begin to code. First, we’ll connect all the libraries we need:
import httplib
import urllib
import json
import datetime
We write functions for receiving data from the API via HTTPS. Using the passed arguments to the function, we compose a GET request and return the server response as a string.
def get_instagram(latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/v1/media/search?lat=' + latitude
get_request+= '&lng=' + longitude
get_request += '&distance=' + distance
get_request += '&min_timestamp=' + str(min_timestamp)
get_request += '&max_timestamp=' + str(max_timestamp)
get_request += '&access_token=' + access_token
local_connect = httplib.HTTPSConnection('api.instagram.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
def get_vk(latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request+= '&long=' + location_longitude
get_request+= '&count=100'
get_request+= '&radius=' + distance
get_request+= '&start_time=' + str(min_timestamp)
get_request+= '&end_time=' + str(max_timestamp)
local_connect = httplib.HTTPSConnection('api.vk.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
We also add a little function to convert timestamp to human view:
def timestamptodate(timestamp):
return datetime.datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S')+' UTC'
Now we write the main logic for image search, after dividing the time interval into parts, we save the results in an HTML file. The function looks cumbersome, but the main difficulty in it is dividing the time interval into blocks. The rest is just parsing JSON and storing the necessary data in HTML.
def parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('instagram_'+location_latitude+location_longitude+'.html','w')
file_inst.write('')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
local_buffer = get_instagram(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads(local_buffer)
for local_i in instagram_json['data']:
file_inst.write('
')
file_inst.write('
')
file_inst.write(timestamptodate(int(local_i['created_time']))+'
')
file_inst.write(local_i['link']+'
')
file_inst.write('
')
local_min_timestamp = local_max_timestamp
file_inst.write('')
file_inst.close()
The HTML format was chosen for a reason. It allows us not to save pictures separately, but only indicate links to them. When the page starts, the results in the image browser are automatically loaded.
We are writing exactly the same function for “Contact”.
def parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('vk_'+location_latitude+location_longitude+'.html','w')
file_inst.write('')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
vk_json = json.loads(get_vk(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json['response']:
if type(local_i) is int:
continue
file_inst.write('
')
file_inst.write('
')
file_inst.write(timestamptodate(int(local_i['created']))+'
')
file_inst.write('http://vk.com/id'+str(local_i['owner_id'])+'
')
file_inst.write('
')
local_min_timestamp = local_max_timestamp
file_inst.write('')
file_inst.close()
And of course, the function calls themselves:
parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
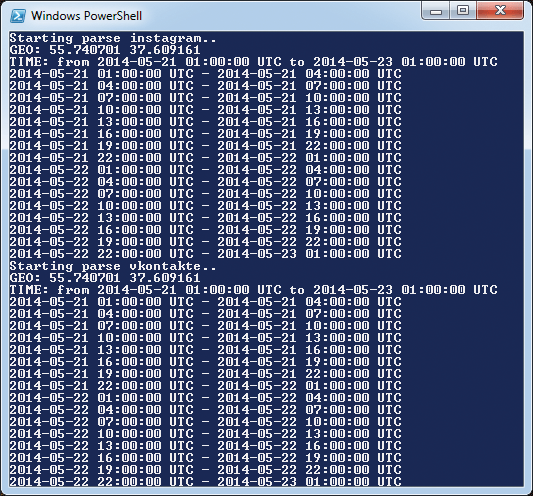
The result of the work of our script in the console

One of the results of the parsing of Instagram

The result of the parsing of "Contact"
Baptism of fire
The script is ready, it remains only to test it in action. And then an idea occurred to me. Those who were at PHD'14 probably remembered the very nice promos from Mail.Ru. Well, let's try to catch up - find them and get to know each other.
Actually, what do we know about PHD14:
- Venue - Digital October - 55.740701.37.609161;
- Date - May 21-22, 2014 - 1400619600-1400792400.
We
get the following data set: location_latitude = '55 .740701 '
location_longitude = '37 .609161'
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60 * 60 * 3 # every 3 hours
instagram_access_token = [Access Token]
Useful Tips
If as a result of the script work there are too few photos, you can try changing the `date_increment` variable, since it is it that is responsible for the time intervals over which the photos are collected. If the place is popular, then the intervals should be frequent (reduce the `date_increment)`, but if the place is blank and the photos are published once a month, then collecting photos at intervals of an hour does not make sense (increase the `date_increment`).
Run the script and go to analyze the results. Yeah, one of the girls posted a picture taken in the mirror in the toilet, with reference to the coordinates! Naturally, the API did not forgive such an error, and soon the pages of all the other promotions were found. As it turned out, two of them are twins :).

The same photo of a promo girl with PHD'14 taken in the toilet
Instructive example
As a second example, I want to recall one of the tasks from the CTF finals at PHD'14. Actually, it was after him that I became interested in this topic. Its essence was as follows.
There is an evil hacker who developed a certain malware. We are given a set of coordinates and the corresponding timestamps from which he went online. You need to get a name and a picture of this hacker. The coordinates were as follows:
55.7736147.37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
First of all, of course, we looked at what places correspond to these coordinates. As it turned out, these are Russian Railways stations, with the first coordinate being the Kazan railway station (Moscow), and the last - Zeleny Dol (Zelenodolsk). The rest are stations between Moscow and Zelenodolsk. It turns out that he went online from the train. At the time of departure, the desired train was found. As it turned out, the train's arrival station is Kazan. And then the main question arose: where to look for the name and photo. The logic was as follows: since you need to find a photo, it is quite reasonable to assume that you need to look for it somewhere on social networks. The main goals were chosen VKontakte, Facebook, Instagram and Twitter. In addition to the Russian teams, foreigners participated in the competitions, so we felt that the organizers would hardly have chosen VKontakte.
We did not have any scripts to search for photos by coordinates and time, and we had to use public services that could do this. As it turned out, there are quite a few of them and they provide a rather meager interface. After hundreds of photos viewed at each station, the train was finally found needed.
As a result, it took no more than an hour to find the train and the missing stations, as well as the logic of the further search. But finding the right photo is a lot of time. This once again emphasizes how important it is to have the right and convenient programs in your arsenal.
WWW
You can find the source code of the script in my Bitbucket repository.
conclusions
The article came to an end and it was time to draw a conclusion. But the conclusion is simple: upload photos with geo-referencing need to be deliberate. Competitive scouts are ready to cling to any opportunity to get new information, and the social network APIs can help them very well in this. When I wrote this article, I explored several other services, including Twitter, Facebook and LinkedIn, whether there is such functionality. Only Twitter gave positive results, which undoubtedly pleases. But Facebook and LinkedIn upset, although not everything is lost and, perhaps, in the future they will expand their APIs. In general, be more careful when posting your photos with geo-referencing - suddenly, someone else will find them. :)

First published in the Hacker magazine from 02/2015.
Posted by Arkady Litvinenko ( @BetepO_ok )
Subscribe to Hacker