Special exceptions in .NET and how to prepare them
Different exceptions in .NET have their own characteristics, and knowing them can be very useful. How to trick the CLR? How to stay alive in runtime by catching a StackOverflowException? It seems that it is impossible to catch any exceptions, but if you really want to, you can?

Under the cut, deciphering the report of Eugene ( epeshk ) Peshkov from our conference DotNext 2018 Piter , where he spoke about these and other features of the exceptions.
Hello! My name is Evgeniy. I work at SKB Kontur and develop a system for hosting and deploying applications for Windows. The bottom line is that we have many grocery teams that write their own services and host them with us. We provide them with an easy and simple solution to a variety of infrastructure problems. For example, trace the consumption of system resources or drop the replicas to the service.
Sometimes it turns out that applications hosted on our system are falling apart. We have seen so many ways that an application can crash at runtime. One of such ways is to throw out some unexpected and enchanting exception.
Today I will talk about the features of exceptions in .NET. We encountered some of these features in production, and some of them during experiments.
Everything discussed below is true for Windows. All examples were tested on the latest version of the full .NET framework 4.7.1. There will also be few references to .NET Core.
This exception occurs during incorrect memory operations. For example, if an application tries to access a memory area to which it does not have access. The exception is low-level, and usually, if it happens, there will be a very long debugging.
Let's try to get this exception using C #. To do this, we write byte 42 at 1000 (we assume that 1000 is a fairly random address and our application most likely does not have access to it).
WriteByte does just what we need: writes a byte at a given address. We expect this call to throw an AccessViolationException. This code will really throw this exception, it will be able to process it and the application will continue to work. Now let's change the code a bit:
If, instead of WriteByte, you use the Copy method and copy byte 42 at address 1000, then using try-catch you will not be able to catch AccessViolation. At the same time, a message will be displayed on the console stating that the application has been terminated due to a raw AccessViolationException.
It turns out that we have two lines of code, while the first one crashes the entire application with AccessViolation, and the second throws a processed exception of the same type. To understand why this is happening, we will look at how these methods are designed from the inside.
Let's start with the Copy method.
The only thing that the Copy method does is call the CopyToNative method, implemented inside .NET. If our application does crash and an exception somewhere happens, then this can only happen inside CopyToNative. From here you can make the first observation: if the .NET code caused the native code and AccessViolation occurred inside it, then the .NET code cannot handle this exception for some reason.
Now let's see why we managed to process AccessViolation using the WriteByte method. Let's look at the code for this method:
This method is implemented entirely in managed code. Here C # -pointer is used to write data to the desired address, and NullReferenceException is also intercepted. If an NRE is caught, an AccessViolationException is thrown. So need because of the specification . At the same time, all exceptions thrown by the throw construct are processed. Accordingly, if a nullReferenceException occurs during the execution of the code inside WriteByte, we will be able to catch AccessViolation. Could NRE, in our case, occur when addressing not 1000 address, but address 1000?
Rewrite the code using C # pointers directly, and see that when accessing a non-zero address, a NullReferenceException is really thrown:
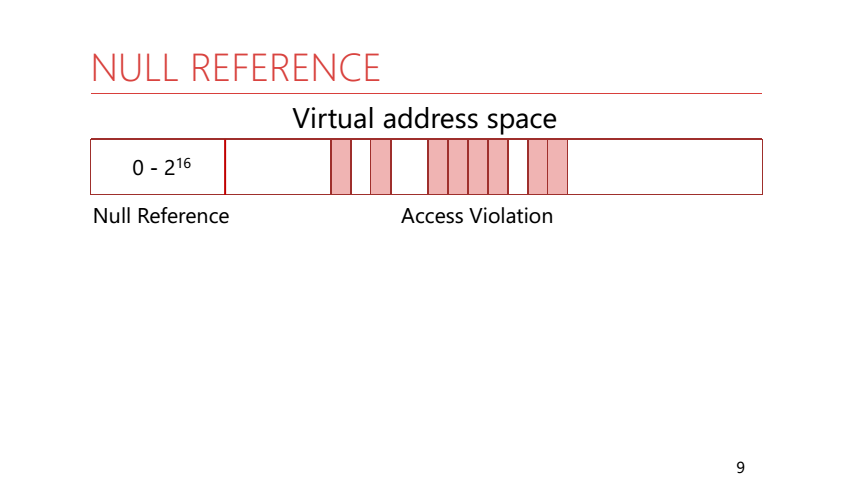
To understand why this is happening, we need to remember how the process memory is organized. In the process memory, all addresses are virtual. This means that the application has a large address space and only some pages from it are displayed in real physical memory. But there is a feature: the first 64 KB of addresses are never displayed in physical memory and are not given to the application. Rantaym .NET knows this and uses it. If AccessViolation occurred in a managed code, then runtime checks to which address in memory the access occurred, and generates a corresponding exception. For addresses from 0 to 2 ^ 16 - NullReference, for all others - AccessViolation.
Let's see why NullReference is thrown not only when accessing a zero address. Imagine that you are accessing a field of an object of a reference type, and the reference to this object is zero:

In this situation, we expect to receive a NullReferenceException. Appeal to the field of an object occurs by offset relative to the address of this object. It turns out that we turn to an address close enough to zero (remember that the reference to our original object is zero). With this behavior, we get the expected exception without further checking the address of the object itself.
But what happens if we access the field of an object, and the object itself takes more than 64 KB?

Can we get AccessViolation in this case? Let's do an experiment. Create a very large object and refer to its fields. One field - at the beginning of the object, the second - at the end:

Both methods throw a NullReferenceException. No AccessViolationException will occur.
Look at the instructions that will be generated for these methods. In the second case, the JIT compiler added an additional cmp instruction that accesses the address of the object itself, thereby causing an AccessViolation with a zero address, which will be converted to runtime NullReferenceException.
It should be noted that for this experiment it is not enough to use an array as a large object. Why? Leave this question to the reader, write ideas in the comments :)
Let's summarize the experiments with AccessViolation.

AccessViolationException behaves differently depending on where the exception occurred (in a managed code or in a native code). In addition, if an exception occurred in the managed code, the address of the object will be checked.
The question arises: can we handle an AccessViolationException that occurred in native code or in managed code, but not converted to a NullReference and not thrown using a throw? This is sometimes a useful feature, especially when working with unsafe code. The answer to this question depends on the version of .NET.

In .NET 1.0 there was no AccessViolationException at all. All links were considered either valid or null. By the time of .NET 2.0, it became clear that without direct work with memory - in any way, and AccessViolation appeared, while being processed. In 4.0 and higher, it was still processed, but processing it was not so easy. To catch this exception, you now need to mark the method that contains the catch block with the HandleProcessCorruptedStateException attribute. Apparently, the developers did this, because they considered that AccessViolationException is not the exception that should be caught in a regular application.
In addition, for backward compatibility it is possible to use runtime settings:
The .NET Core AccessViolation is not handled at all.
In our production there was this situation: The

application compiled for .NET 4.7.1 used a library with common code compiled for .NET 3.5. In this library there was a helper to run a periodic action:
In this helper, we passed the action from our application. It so happened that he fell from AccessViolation. As a result, our application constantly logged AccessViolation, instead of falling, because The code in the library under 3.5 could catch it. It should be noted that interceptability does not depend on the version of the runtime on which the application is running, but on the TargetFramework, under which the application was built, and its dependencies.
Summing up. The processing of AccessVilolation depends on where it originated — in native or managed code — and also on TargetFramework and runtime settings.
Sometimes in the code you need to stop the execution of one of the threads. For this, you can use the thread.Abort () method;
When the Abort method is called, a ThreadAbortException is thrown in the thread being stopped. We analyze its features. For example, the following code:
Absolutely equivalent to this:
If you still need to handle ThreadAbort and perform some other actions in the stream that is stopped, then you can use the Thread.ResetAbort () method; It stops the process of stopping the thread and the exception stops prokidyvatsya higher in the stack. It is important to understand that the thread.Abort () method by itself does not guarantee anything - the code in the stream being stopped may prevent it from stopping.
Another feature of thread.Abort () is that it will not be able to interrupt the code if it is in catch and finally blocks.
Inside the framework code, you can often find methods that have a try block empty, and all the logic is inside finally. This is done in order to prevent this code from being interrupted by a ThreadAbortException.
Also calling the thread.Abort () method waits for a ThreadAbortException to be thrown. Let us combine these two facts and get that the thread.Abort () method can block the calling thread.
In reality, this can be encountered when using the using construct. It unfolds in try / finally, and Dispose is called inside finally. It can be arbitrarily complex, contain calls to event handlers, use locks. And if thread.Abort was called during execution, Dispose - thread.Abort () will wait for it. So we get a lock almost from scratch.
In the .NET Core, the thread.Abort () method throws a PlatformNotSupportedException. And I think this is very good, because it motivates to use not thread.Abort (), but non-invasive methods of stopping code execution, for example, using CancellationToken.
This exception can be obtained if the memory on the machine is less than what is required. Or when we came up against the limitations of the 32-bit process. But you can get it, even if the computer has a lot of free memory, and the process is 64-bit.
The code above will throw OutOfMemory. The thing is that in the default data objects with no more than 2 GB are not allowed. This can be fixed by setting gcAllowVeryLargeObjects in App.config. In this case, an array of 4 GB will be created.
And now we will try to create an array even more.
Now even gcAllowVeryLargeObjects will not help. All due to the fact that in .NET there is a limit on the maximum index in the array . This limit is less than int.MaxValue.
Max array index:
In this case, an OutOfMemoryException will occur, although in reality we have rested on the data type restriction, and not on the lack of memory.
Sometimes OutOfMemory is explicitly thrown away by managed code inside the .NET framework:

This is an implementation of the string.Concat method. If the length of the result string is greater than int.MaxValue, then an OutOfMemoryException is immediately thrown.
Let us turn to the situation when OutOfMemory arises in the case, when the memory really ends.
First, we limit the memory of our process to 64 MB. Next, inside the loop, select new arrays of bytes, save them to some sheet so that the GC does not collect them, and try to catch OutOfMemory.
In this case, anything can happen:
In this case, the program will turn out to be absolutely non-deterministic. Let's sort all options:
In virtual memory, pages can be not only mapped to physical memory, but can also be reserved (reserved). If the page is reserved, the application indicated that it was going to use it. If the page is already mapped into real memory or a swap, then it is called “committed”. The stack uses this ability to divide the memory into reserved and locked-in memory. It looks like this:

It turns out that we call the WriteLine method, which takes up some space on the stack. So it turns out that the entire zakommichennaya memory is over, it means that the operating system at this moment should take another reserved page of the stack and display it in real physical memory, which is already filled with arrays of bytes. This results in a StackOverflow exception.
The following code will allow at the start of the thread to commit all the memory under the stack at once.
In addition, you can use runtime setting disableCommitThreadStack . It needs to be disabled so that the stack of the thread commits in advance. It should be noted that the default behavior described in the documentation and observed in reality is different.

Let's understand in more detail with StackOverflowException. Let's look at two code examples. In one of them, we run an infinite recursion that causes a stack overflow, in the second we just throw this exception using a throw.
Since all exceptions thrown with throw are handled, in the second case we will catch the exception. And with the first case all the more interesting. Turn to MSDN :
It says here that we will not be able to intercept a StackOverflowException, since the interception itself may require additional stack space, which has already ended.
To somehow protect against this exception, you can proceed as follows. First, you can limit the depth of recursion. Secondly, you can use the methods of the class RuntimeHelpers:
The documentation for this method says that it checks that there is enough space on the stack to perform the average .NET function. But what is the average function? In fact, in the .NET Framework, this method checks that at least half of its size is free on the stack. In .NET Core, it checks to have 64 KB free.
Also in .NET Core an analog appeared: RuntimeHelpers.TryEnsureSufficientExecutionStack () returning a bool, rather than throwing an exception.
In C # 7.2, it became possible to use Span and stackallock together without using unsafe code. Perhaps due to this, stackalloc will be used more often in code and it will be useful to have a way to protect against StackOverflow when using it, choosing where to allocate memory. As such a method, a method is proposed that tests the possibility of allocation on the stack and the trystackalloc construction .
Let's go back to the StackOverflow documentation on MSDN
If there is a “normal” application that drops when StackOverflow, then there is also a non- “normal” application that does not fall? In order to answer this question you will have to go down to the level below from the level of the managed application to the CLR level.

An application that is hosted by the CLR can override the behavior of a stack overflow so that instead of terminating the entire process, the Application Domain is unloaded, in the thread of which this overflow occurred. That way, we can turn a StackOverflowException into an AppDomainUnloadedException.
When you run a managed application, the .NET runtime automatically starts. But you can go the other way. For example, write an unmanaged application (in C ++ or another language) that will use a special API to raise the CLR and run our application. An application that runs inside of itself CLR will be called CLR-host. Having written it, we can configure many things in runtime. For example, replace the memory manager and the thread manager. We in production use the CLR-host in order to avoid memory pages getting into the swap.
The following code configures the CLR-host so that the AppDomain (C ++) is unloaded when StackOverflow:
Is this a good way to escape from StackOverflow? Probably not. First, we had to write code in C ++, which we would not like to do. Secondly, we need to change our C # code so that the function that can throw a StackOverflowException is performed in a separate AppDomain and in a separate thread. Our code will immediately turn into such noodles:
In order to call the InfiniteRecursion method, we wrote a bunch of lines. Third, we started using the AppDomain. And it almost guarantees a bunch of new problems. Including, with exceptions. Consider an example:
Since our exception is not marked as serializable, our code will drop with a SerializationException exception. And in order to fix this problem, it’s not enough for us to mark our exception with the Serializable attribute, we still need to implement an additional constructor for serialization.
This all turns out to be not very beautiful, so we go further - to the level of the operating system and hacks, which should not be used in production.

Note that if Managed-exceptions flew between Managed and CLR, then SEH-exceptions fly between CLR and Windows.
SEH - Structured Exception Handling
SEH is an exception handling mechanism in Windows; it allows you to handle any exceptions that came from the processor level, for example, or were related to the logic of the application itself.
Rantaym .NET knows about SEH-exceptions and can convert them into managed-exceptions:
We can interact with SEH through WinApi.
In fact, the throw construct also works through SEH.
Here it is worth noting that the CLR-exception code is always the same, so whatever type of exception we throw, it will always be processed.
VEH is vector-based exception handling, an extension of SEH, but operating at the process level, not at the level of a single thread. If SEH by semantics is similar to try-catch, then VEH by semantics is similar to interrupt handler. We simply set our handler and can receive information about all exceptions that occur in our process. An interesting feature of VEH is that it allows you to change the SEH exception before it gets to the handler.

We can put our own vector handler between the operating system and the runtime, which will handle SEH-exceptions and change it so that the .NET runtime does not crash the process when it encounters EXCEPTION_STACK_OVERFLOW.
You can interact with VEH through WinApi:
The Context contains information about the state of all processor registers at the time of the exception. We will be interested in EXCEPTION_RECORD and the ExceptionCode field in it. We can replace it with our own exception code, which the CLR knows nothing about. The vector handler looks like this:
Now we’ll make a wrapper that installs a vector handler as a HandleSO method, which takes a delegate that can potentially fall from a StackOverflowException (for clarity, the code does not handle WinApi functions and deletes the vector handler).
Inside it also uses the SetThreadStackGuarantee method. This method reserves stack space for processing StackOverflow.
Thus, we can survive the method call with infinite recursion. Our stream will continue to work as if nothing had happened, as if no overflow occurred.
But, what happens if you call HandleSO twice in the same thread?
And there will be AccessViolationException. Let's go back to the stack device.

The operating system can detect stack overflow. At the very top of the stack is a special page marked with the Guard page flag. When you first access this page, another exception will occur - STATUS_GUARD_PAGE_VIOLATION, and the Guard page flag will be removed from the page. If you just intercept this overflow, then this page will no longer be on the stack - on the next overflow the operating system will not be able to understand this and the stack-pointer will go beyond the memory allocated for the stack. As a result, AccessViolationException will occur. So you need to restore page flags after processing StackOverflow - the easiest way to do this is to use the _resetstkoflw method from runtime library C (msvcrt.dll).
In a similar way, you can catch AccessViolationException in a .NET Core under Windows, which causes the process to crash. In this case, you need to take into account the order of calling vector handlers and set your handler to the beginning of the chain, since .NET Core also uses VEH when processing AccessViolation. The order of the callbacks is answered by the first parameter of the AddVectoredExceptionHandler function:
Having studied the practical issues, we summarize the results:
→ repository with examples from the report
→ Dotnext 2016 Moscow - by Adam Sitnik - Exceptional is the Exceptions in .NET
→ DotNetBook: the Exceptions
→ .NET Inside Out Part 8 - Handling the Stack Overflow is the Exception in the C # with VEH - another way to intercept StackOverflow.
Under the cut, deciphering the report of Eugene ( epeshk ) Peshkov from our conference DotNext 2018 Piter , where he spoke about these and other features of the exceptions.
Hello! My name is Evgeniy. I work at SKB Kontur and develop a system for hosting and deploying applications for Windows. The bottom line is that we have many grocery teams that write their own services and host them with us. We provide them with an easy and simple solution to a variety of infrastructure problems. For example, trace the consumption of system resources or drop the replicas to the service.
Sometimes it turns out that applications hosted on our system are falling apart. We have seen so many ways that an application can crash at runtime. One of such ways is to throw out some unexpected and enchanting exception.
Today I will talk about the features of exceptions in .NET. We encountered some of these features in production, and some of them during experiments.
Plan
- Exception behavior in .NET
- Windows exception handling and hacks
Everything discussed below is true for Windows. All examples were tested on the latest version of the full .NET framework 4.7.1. There will also be few references to .NET Core.
Access Violation
This exception occurs during incorrect memory operations. For example, if an application tries to access a memory area to which it does not have access. The exception is low-level, and usually, if it happens, there will be a very long debugging.
Let's try to get this exception using C #. To do this, we write byte 42 at 1000 (we assume that 1000 is a fairly random address and our application most likely does not have access to it).
try {
Marshal.WriteByte((IntPtr) 1000, 42);
}
catch (AccessViolationException) {
...
}
WriteByte does just what we need: writes a byte at a given address. We expect this call to throw an AccessViolationException. This code will really throw this exception, it will be able to process it and the application will continue to work. Now let's change the code a bit:
try {
var bytes = newbyte[] {42};
Marshal.Copy(bytes, 0, (IntPtr) 1000, bytes.Length);
}
catch (AccessViolationException) {
...
}
If, instead of WriteByte, you use the Copy method and copy byte 42 at address 1000, then using try-catch you will not be able to catch AccessViolation. At the same time, a message will be displayed on the console stating that the application has been terminated due to a raw AccessViolationException.
Marshal.Copy(bytes, 0, (IntPtr) 1000, bytes.Length);
Marshal.WriteByte((IntPtr) 1000, 42);
It turns out that we have two lines of code, while the first one crashes the entire application with AccessViolation, and the second throws a processed exception of the same type. To understand why this is happening, we will look at how these methods are designed from the inside.
Let's start with the Copy method.
staticvoidCopy(...) {
Marshal.CopyToNative((object) source, startIndex, destination, length);
}
[MethodImpl(MethodImplOptions.InternalCall)]
staticexternvoidCopyToNative(object source, int startIndex, IntPtr destination, int length);
The only thing that the Copy method does is call the CopyToNative method, implemented inside .NET. If our application does crash and an exception somewhere happens, then this can only happen inside CopyToNative. From here you can make the first observation: if the .NET code caused the native code and AccessViolation occurred inside it, then the .NET code cannot handle this exception for some reason.
Now let's see why we managed to process AccessViolation using the WriteByte method. Let's look at the code for this method:
unsafestaticvoidWriteByte(IntPtr ptr, byte val) {
try {
*(byte*) ptr = val;
}
catch (NullReferenceException) {
// this method is documented to throw AccessViolationException on any AVthrownew AccessViolationException();
}
}
This method is implemented entirely in managed code. Here C # -pointer is used to write data to the desired address, and NullReferenceException is also intercepted. If an NRE is caught, an AccessViolationException is thrown. So need because of the specification . At the same time, all exceptions thrown by the throw construct are processed. Accordingly, if a nullReferenceException occurs during the execution of the code inside WriteByte, we will be able to catch AccessViolation. Could NRE, in our case, occur when addressing not 1000 address, but address 1000?
Rewrite the code using C # pointers directly, and see that when accessing a non-zero address, a NullReferenceException is really thrown:
*(byte*) 1000 = 42;
To understand why this is happening, we need to remember how the process memory is organized. In the process memory, all addresses are virtual. This means that the application has a large address space and only some pages from it are displayed in real physical memory. But there is a feature: the first 64 KB of addresses are never displayed in physical memory and are not given to the application. Rantaym .NET knows this and uses it. If AccessViolation occurred in a managed code, then runtime checks to which address in memory the access occurred, and generates a corresponding exception. For addresses from 0 to 2 ^ 16 - NullReference, for all others - AccessViolation.
Let's see why NullReference is thrown not only when accessing a zero address. Imagine that you are accessing a field of an object of a reference type, and the reference to this object is zero:
In this situation, we expect to receive a NullReferenceException. Appeal to the field of an object occurs by offset relative to the address of this object. It turns out that we turn to an address close enough to zero (remember that the reference to our original object is zero). With this behavior, we get the expected exception without further checking the address of the object itself.
But what happens if we access the field of an object, and the object itself takes more than 64 KB?
Can we get AccessViolation in this case? Let's do an experiment. Create a very large object and refer to its fields. One field - at the beginning of the object, the second - at the end:
Both methods throw a NullReferenceException. No AccessViolationException will occur.
Look at the instructions that will be generated for these methods. In the second case, the JIT compiler added an additional cmp instruction that accesses the address of the object itself, thereby causing an AccessViolation with a zero address, which will be converted to runtime NullReferenceException.
It should be noted that for this experiment it is not enough to use an array as a large object. Why? Leave this question to the reader, write ideas in the comments :)
Let's summarize the experiments with AccessViolation.
AccessViolationException behaves differently depending on where the exception occurred (in a managed code or in a native code). In addition, if an exception occurred in the managed code, the address of the object will be checked.
The question arises: can we handle an AccessViolationException that occurred in native code or in managed code, but not converted to a NullReference and not thrown using a throw? This is sometimes a useful feature, especially when working with unsafe code. The answer to this question depends on the version of .NET.
In .NET 1.0 there was no AccessViolationException at all. All links were considered either valid or null. By the time of .NET 2.0, it became clear that without direct work with memory - in any way, and AccessViolation appeared, while being processed. In 4.0 and higher, it was still processed, but processing it was not so easy. To catch this exception, you now need to mark the method that contains the catch block with the HandleProcessCorruptedStateException attribute. Apparently, the developers did this, because they considered that AccessViolationException is not the exception that should be caught in a regular application.
In addition, for backward compatibility it is possible to use runtime settings:
- legacyNullReferenceExceptionPolicy returns .NET 1.0 behavior — all AVs turn into NRE
- legacyCorruptedStateExceptionsPolicy returns .NET 2.0 behavior - all AVs are intercepted
The .NET Core AccessViolation is not handled at all.
In our production there was this situation: The
application compiled for .NET 4.7.1 used a library with common code compiled for .NET 3.5. In this library there was a helper to run a periodic action:
while (isRunning) {
try {
action();
}
catch (Exception e) {
log.Error(e);
}
WaitForNextExecution(... );
}
In this helper, we passed the action from our application. It so happened that he fell from AccessViolation. As a result, our application constantly logged AccessViolation, instead of falling, because The code in the library under 3.5 could catch it. It should be noted that interceptability does not depend on the version of the runtime on which the application is running, but on the TargetFramework, under which the application was built, and its dependencies.
Summing up. The processing of AccessVilolation depends on where it originated — in native or managed code — and also on TargetFramework and runtime settings.
Thread abort
Sometimes in the code you need to stop the execution of one of the threads. For this, you can use the thread.Abort () method;
var thread = new Thread(() => {
try {
...
}
catch (ThreadAbortException e) {
...
Thread.ResetAbort();
}
});
...
thread.Abort();
When the Abort method is called, a ThreadAbortException is thrown in the thread being stopped. We analyze its features. For example, the following code:
var thread = new Thread(() => {
try {
…
} catch (ThreadAbortException e) {
…
}
});
...
thread.Abort();
Absolutely equivalent to this:
var thread = new Thread(() => {
try {
...
}
catch (ThreadAbortException e) {
...
throw;
}
});
...
thread.Abort();
If you still need to handle ThreadAbort and perform some other actions in the stream that is stopped, then you can use the Thread.ResetAbort () method; It stops the process of stopping the thread and the exception stops prokidyvatsya higher in the stack. It is important to understand that the thread.Abort () method by itself does not guarantee anything - the code in the stream being stopped may prevent it from stopping.
Another feature of thread.Abort () is that it will not be able to interrupt the code if it is in catch and finally blocks.
Inside the framework code, you can often find methods that have a try block empty, and all the logic is inside finally. This is done in order to prevent this code from being interrupted by a ThreadAbortException.
Also calling the thread.Abort () method waits for a ThreadAbortException to be thrown. Let us combine these two facts and get that the thread.Abort () method can block the calling thread.
var thread = new Thread(() =>
{
try { }
catch { } // <-- No ThreadAbortException in catch
finally { // <-- No ThreadAbortException in finally
Thread.Sleep(- 1);
}
});
thread.Start();
...
thread.Abort(); // Never returnsIn reality, this can be encountered when using the using construct. It unfolds in try / finally, and Dispose is called inside finally. It can be arbitrarily complex, contain calls to event handlers, use locks. And if thread.Abort was called during execution, Dispose - thread.Abort () will wait for it. So we get a lock almost from scratch.
In the .NET Core, the thread.Abort () method throws a PlatformNotSupportedException. And I think this is very good, because it motivates to use not thread.Abort (), but non-invasive methods of stopping code execution, for example, using CancellationToken.
OUT OF MEMORY
This exception can be obtained if the memory on the machine is less than what is required. Or when we came up against the limitations of the 32-bit process. But you can get it, even if the computer has a lot of free memory, and the process is 64-bit.
var arr4gb = newint[int.MaxValue/2];
The code above will throw OutOfMemory. The thing is that in the default data objects with no more than 2 GB are not allowed. This can be fixed by setting gcAllowVeryLargeObjects in App.config. In this case, an array of 4 GB will be created.
And now we will try to create an array even more.
var largeArr = newint[int.MaxValue];
Now even gcAllowVeryLargeObjects will not help. All due to the fact that in .NET there is a limit on the maximum index in the array . This limit is less than int.MaxValue.
Max array index:
- byte arrays - 0x7FFFFFC7
- other arrays - 0X7F E FFFFF
In this case, an OutOfMemoryException will occur, although in reality we have rested on the data type restriction, and not on the lack of memory.
Sometimes OutOfMemory is explicitly thrown away by managed code inside the .NET framework:
This is an implementation of the string.Concat method. If the length of the result string is greater than int.MaxValue, then an OutOfMemoryException is immediately thrown.
Let us turn to the situation when OutOfMemory arises in the case, when the memory really ends.
LimitMemory(64.Mb());
try {
while (true)
list.Add(newbyte[size]);
} catch (OutOfMemoryException e) {
Console.WriteLine(e);
}
First, we limit the memory of our process to 64 MB. Next, inside the loop, select new arrays of bytes, save them to some sheet so that the GC does not collect them, and try to catch OutOfMemory.
In this case, anything can happen:
- Exception will be processed
- The process will fall
- Go to catch, but the exception will crash again.
- Go to catch, but StackOverflow will crash.
In this case, the program will turn out to be absolutely non-deterministic. Let's sort all options:
- Exception can be handled. Inside .NET, nothing prevents you from handling OutOfMemoryException.
- The process may fall. Do not forget that we have a managed application. This means that not only our code is executed inside it, but also runtime code. For example, GC. Thus, a situation may occur when the runtime wants to allocate memory for itself, but cannot do it, then we will not be able to catch the exception.
- Go to catch, but the exception will crash again. Inside catch, we also perform work in which we need memory (we print an exception on the console), and this may cause a new exception.
- Зайдем в catch, но вылетит StackOverflow. Сам StackOverflow происходит при вызове метода WriteLine, но переполнения стека здесь нет, а происходит другая ситуация. Разберём её подробнее.
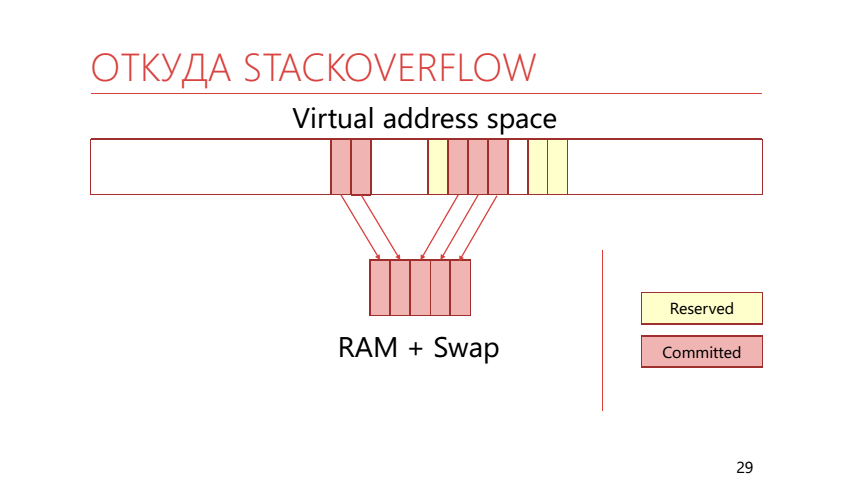
In virtual memory, pages can be not only mapped to physical memory, but can also be reserved (reserved). If the page is reserved, the application indicated that it was going to use it. If the page is already mapped into real memory or a swap, then it is called “committed”. The stack uses this ability to divide the memory into reserved and locked-in memory. It looks like this:
It turns out that we call the WriteLine method, which takes up some space on the stack. So it turns out that the entire zakommichennaya memory is over, it means that the operating system at this moment should take another reserved page of the stack and display it in real physical memory, which is already filled with arrays of bytes. This results in a StackOverflow exception.
The following code will allow at the start of the thread to commit all the memory under the stack at once.
new Thread(() => F(), 4*1024*1024).Start();
In addition, you can use runtime setting disableCommitThreadStack . It needs to be disabled so that the stack of the thread commits in advance. It should be noted that the default behavior described in the documentation and observed in reality is different.
Stack overflow
Let's understand in more detail with StackOverflowException. Let's look at two code examples. In one of them, we run an infinite recursion that causes a stack overflow, in the second we just throw this exception using a throw.
try {
InfiniteRecursion();
}
catch (Exception) {
...
}
try {
thrownew StackOverflowException();
}
catch (Exception) {
...
}
Since all exceptions thrown with throw are handled, in the second case we will catch the exception. And with the first case all the more interesting. Turn to MSDN :
"You can’t catch the stack overflow exceptions, because of the exception code you may need the stack."
MSDN
It says here that we will not be able to intercept a StackOverflowException, since the interception itself may require additional stack space, which has already ended.
To somehow protect against this exception, you can proceed as follows. First, you can limit the depth of recursion. Secondly, you can use the methods of the class RuntimeHelpers:
RuntimeHelpers.EnsureSufficientExecutionStack ();
- “Ensures that the remaining stack space is large .NET Framework function.” - MSDN
- InsufficientExecutionStackException
- 512 KB - x86, AnyCPU, 2 MB - x64 (half of stack size)
- 64/128 KB - .NET Core
- Check only stack address space
The documentation for this method says that it checks that there is enough space on the stack to perform the average .NET function. But what is the average function? In fact, in the .NET Framework, this method checks that at least half of its size is free on the stack. In .NET Core, it checks to have 64 KB free.
Also in .NET Core an analog appeared: RuntimeHelpers.TryEnsureSufficientExecutionStack () returning a bool, rather than throwing an exception.
In C # 7.2, it became possible to use Span and stackallock together without using unsafe code. Perhaps due to this, stackalloc will be used more often in code and it will be useful to have a way to protect against StackOverflow when using it, choosing where to allocate memory. As such a method, a method is proposed that tests the possibility of allocation on the stack and the trystackalloc construction .
Span<byte> span;
if (CanAllocateOnStack(size))
span = stackallocbyte[size];
else
span = newbyte[size];
Let's go back to the StackOverflow documentation on MSDN
Instead, when a stack overflow occurs in a normal application , the Common Language Runtime (CLR) terminates the process. »
MSDN
If there is a “normal” application that drops when StackOverflow, then there is also a non- “normal” application that does not fall? In order to answer this question you will have to go down to the level below from the level of the managed application to the CLR level.
«That of An application hosts file the the CLR CAN change the default behavior and the Specify the CLR That the the unload the application domain . The where clause by exception Occurs, But lets 'continue' the process» - the MSDN
StackOverflowException -> AppDomainUnloadedException
An application that is hosted by the CLR can override the behavior of a stack overflow so that instead of terminating the entire process, the Application Domain is unloaded, in the thread of which this overflow occurred. That way, we can turn a StackOverflowException into an AppDomainUnloadedException.
When you run a managed application, the .NET runtime automatically starts. But you can go the other way. For example, write an unmanaged application (in C ++ or another language) that will use a special API to raise the CLR and run our application. An application that runs inside of itself CLR will be called CLR-host. Having written it, we can configure many things in runtime. For example, replace the memory manager and the thread manager. We in production use the CLR-host in order to avoid memory pages getting into the swap.
The following code configures the CLR-host so that the AppDomain (C ++) is unloaded when StackOverflow:
ICLRPolicyManager *policyMgr;
pCLRControl->GetCLRManager(IID_ICLRPolicyManager, (void**) (&policyMgr));
policyMgr->SetActionOnFailure(FAIL_StackOverflow, eRudeUnloadAppDomain);
Is this a good way to escape from StackOverflow? Probably not. First, we had to write code in C ++, which we would not like to do. Secondly, we need to change our C # code so that the function that can throw a StackOverflowException is performed in a separate AppDomain and in a separate thread. Our code will immediately turn into such noodles:
try {
var appDomain = AppDomain.CreateDomain("...");
appDomain.DoCallBack(() =>
{
var thread = new Thread(() => InfiniteRecursion());
thread.Start();
thread.Join();
});
AppDomain.Unload(appDomain);
}
catch (AppDomainUnloadedException) { }
In order to call the InfiniteRecursion method, we wrote a bunch of lines. Third, we started using the AppDomain. And it almost guarantees a bunch of new problems. Including, with exceptions. Consider an example:
publicclassCustomException : Exception {}
var appDomain = AppDomain.CreateDomain( "...");
appDomain.DoCallBack(() => thrownew CustomException());
System.Runtime.Serialization.SerializationException:
Type 'CustomException'is not marked as serializable.
at System.AppDomain.DoCallBack(CrossAppDomainDelegate callBackDelegate)
Since our exception is not marked as serializable, our code will drop with a SerializationException exception. And in order to fix this problem, it’s not enough for us to mark our exception with the Serializable attribute, we still need to implement an additional constructor for serialization.
[Serializable]
publicclassCustomException : Exception
{
publicCustomException(){}
publicCustomException(SerializationInfo info, StreamingContext ctx) : base(info, context){}
}
var appDomain = AppDomain.CreateDomain("...");
appDomain.DoCallBack(() => thrownew CustomException());
This all turns out to be not very beautiful, so we go further - to the level of the operating system and hacks, which should not be used in production.
SEH / VEH
Note that if Managed-exceptions flew between Managed and CLR, then SEH-exceptions fly between CLR and Windows.
SEH - Structured Exception Handling
- Windows exception handling mechanism
- Uniform software and hardware exception handling
- C # exceptions are implemented over SEH
SEH is an exception handling mechanism in Windows; it allows you to handle any exceptions that came from the processor level, for example, or were related to the logic of the application itself.
Rantaym .NET knows about SEH-exceptions and can convert them into managed-exceptions:
- EXCEPTION_STACK_OVERFLOW -> Crash
- EXCEPTION_ACCESS_VIOLATION -> AccessViolationException
- EXCEPTION_ACCESS_VIOLATION -> NullReferenceException
- EXCEPTION_INT_DIVIDE_BY_ZERO -> DivideByZeroException
- Unknown SEH exceptions -> SEHException
We can interact with SEH through WinApi.
[DllImport("kernel32.dll")]
staticexternvoidRaiseException(uint dwExceptionCode, uint dwExceptionFlags, uint nNumberOfArguments,IntPtr lpArguments);
// DivideByZeroException
RaiseException(0xc0000094, 0, 0, IntPtr.Zero);
// Stack overflow
RaiseException(0xc00000fd, 0, 0, IntPtr.Zero);
In fact, the throw construct also works through SEH.
throw -> RaiseException(0xe0434f4d, ...)
Here it is worth noting that the CLR-exception code is always the same, so whatever type of exception we throw, it will always be processed.
VEH is vector-based exception handling, an extension of SEH, but operating at the process level, not at the level of a single thread. If SEH by semantics is similar to try-catch, then VEH by semantics is similar to interrupt handler. We simply set our handler and can receive information about all exceptions that occur in our process. An interesting feature of VEH is that it allows you to change the SEH exception before it gets to the handler.
We can put our own vector handler between the operating system and the runtime, which will handle SEH-exceptions and change it so that the .NET runtime does not crash the process when it encounters EXCEPTION_STACK_OVERFLOW.
You can interact with VEH through WinApi:
[DllImport("kernel32.dll", SetLastError = true)]
staticextern IntPtr AddVectoredExceptionHandler(IntPtr FirstHandler, VECTORED_EXCEPTION_HANDLER VectoredHandler);
delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers);
publicenum VEH : long
{
EXCEPTION_CONTINUE_SEARCH = 0,
EXCEPTION_EXECUTE_HANDLER = 1,
EXCEPTION_CONTINUE_EXECUTION = -1
}
delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers);
[StructLayout(LayoutKind.Sequential)]
unsafestruct EXCEPTION_POINTERS {
public EXCEPTION_RECORD* ExceptionRecord;
public IntPtr Context;
}
delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers);
[StructLayout(LayoutKind.Sequential)]
unsafestruct EXCEPTION_RECORD {
publicuint ExceptionCode;
...
}
The Context contains information about the state of all processor registers at the time of the exception. We will be interested in EXCEPTION_RECORD and the ExceptionCode field in it. We can replace it with our own exception code, which the CLR knows nothing about. The vector handler looks like this:
staticunsafe VEH Handler(ref EXCEPTION_POINTERS e) {
if (e.ExceptionRecord == null)
return VEH. EXCEPTION_CONTINUE_SEARCH;
var record = e. ExceptionRecord;
if (record->ExceptionCode != ExceptionStackOverflow)
return VEH. EXCEPTION_CONTINUE_SEARCH;
record->ExceptionCode = 0x01234567;
return VEH. EXCEPTION_EXECUTE_HANDLER;
}
Now we’ll make a wrapper that installs a vector handler as a HandleSO method, which takes a delegate that can potentially fall from a StackOverflowException (for clarity, the code does not handle WinApi functions and deletes the vector handler).
HandleSO(() => InfiniteRecursion()) ;
static T HandleSO<T>(Func<T> action) {
Kernel32. AddVectoredExceptionHandler(IntPtr.Zero, Handler);
Kernel32.SetThreadStackGuarantee(ref size);
try {
return action();
}
catch (Exception e) when ((uint) Marshal. GetExceptionCode() == 0x01234567) {}
returndefault(T);
}
HandleSO(() => InfiniteRecursion());
Inside it also uses the SetThreadStackGuarantee method. This method reserves stack space for processing StackOverflow.
Thus, we can survive the method call with infinite recursion. Our stream will continue to work as if nothing had happened, as if no overflow occurred.
But, what happens if you call HandleSO twice in the same thread?
HandleSO(() => InfiniteRecursion());
HandleSO(() => InfiniteRecursion());
And there will be AccessViolationException. Let's go back to the stack device.
The operating system can detect stack overflow. At the very top of the stack is a special page marked with the Guard page flag. When you first access this page, another exception will occur - STATUS_GUARD_PAGE_VIOLATION, and the Guard page flag will be removed from the page. If you just intercept this overflow, then this page will no longer be on the stack - on the next overflow the operating system will not be able to understand this and the stack-pointer will go beyond the memory allocated for the stack. As a result, AccessViolationException will occur. So you need to restore page flags after processing StackOverflow - the easiest way to do this is to use the _resetstkoflw method from runtime library C (msvcrt.dll).
[DllImport("msvcrt.dll")]
staticexternint _resetstkoflw();
In a similar way, you can catch AccessViolationException in a .NET Core under Windows, which causes the process to crash. In this case, you need to take into account the order of calling vector handlers and set your handler to the beginning of the chain, since .NET Core also uses VEH when processing AccessViolation. The order of the callbacks is answered by the first parameter of the AddVectoredExceptionHandler function:
Kernel32.AddVectoredExceptionHandler(FirstHandler: (IntPtr) 1, handler);
Having studied the practical issues, we summarize the results:
- Exceptions are not as simple as they seem;
- Not all exceptions are handled the same way;
- Exception handling occurs at different levels of abstraction;
- You can intervene in the process of exception handling and make the .NET runtime not work as originally intended.
Links
→ repository with examples from the report
→ Dotnext 2016 Moscow - by Adam Sitnik - Exceptional is the Exceptions in .NET
→ DotNetBook: the Exceptions
→ .NET Inside Out Part 8 - Handling the Stack Overflow is the Exception in the C # with VEH - another way to intercept StackOverflow.
On November 22-23, Evgeny will speak at DotNext 2018 Moscow with the report “System Metrics: Collecting Pitfalls” . And Jeffrey Richter, Greg Young, Pavel Yosifovich and other equally interesting speakers will come to Moscow. Report topics can be viewed here , and tickets can be bought here . Join now!