Lossy Image Compression
The idea underlying all lossy compression algorithms is quite simple: at the first stage, delete irrelevant information, and at the second stage, apply the most suitable lossless compression algorithm to the remaining data. The main difficulties lie in highlighting this non-essential information. The approaches here vary significantly depending on the type of data being compressed. For sound, they most often remove frequencies that a person is simply not able to perceive, reduce the sampling frequency, and some algorithms delete quiet sounds immediately after loud ones, for moving data, only moving objects are encoded, and minor changes on stationary objects are simply discarded. Methods for highlighting non-essential information in images will be discussed in detail below.
Before talking about lossy compression algorithms, you need to agree on what is considered acceptable loss. It is clear that the main criterion remains the visual assessment of the image, but also changes in the compressed image can be quantified. The easiest way to evaluate is to calculate the direct difference between the compressed and the source image. We agree that by we will mean a pixel located at the intersection of the i-th row and the j-th column of the original image, and by
we will mean a pixel located at the intersection of the i-th row and the j-th column of the original image, and by  - the corresponding pixel of the compressed image. Then, for any pixel, you can easily determine the coding error
- the corresponding pixel of the compressed image. Then, for any pixel, you can easily determine the coding error  , and for the whole image, consisting of N rows and M columns, you can calculate the total error
, and for the whole image, consisting of N rows and M columns, you can calculate the total error . Obviously, the larger the total error, the stronger the distortion in the compressed image. Nevertheless, this value is extremely rarely used in practice, because it does not take into account the size of the image. Much wider is the estimate using standard deviation
. Obviously, the larger the total error, the stronger the distortion in the compressed image. Nevertheless, this value is extremely rarely used in practice, because it does not take into account the size of the image. Much wider is the estimate using standard deviation 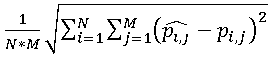 .
.
Another (albeit close in essence) approach is as follows: the pixels of the final image are considered as the sum of the pixels of the original image and noise. The criterion for the quality of this approach is called the magnitude signal to noise ratio (SNR), computed as follows: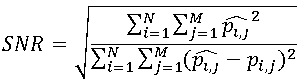 .
.
Both of these ratings are called objective criteria for fidelity of reproduction, because depend solely on the original and compressed image. However, these criteria do not always correspond to subjective assessments. If the images are intended for human perception, the only thing that can be stated: poor indicators of objective criteria most often correspond to low subjective ratings, while good indicators of objective criteria do not guarantee high subjective ratings.
The concept of visual redundancy is associated with the process of quantization and discretization. A significant part of the information in the image cannot be perceived by a person: for example, a person is able to notice minor differences in brightness, but is much less sensitive to color. Also, starting from a certain moment, increasing the accuracy of sampling does not affect the visual perception of the image. Thus, some of the information can be deleted without compromising visual quality. Such information is called visually redundant.
The easiest way to remove visual redundancy is to reduce the sampling accuracy, but in practice this method can only be used for images with a simple structure, because distortions arising on complex images are too noticeable (see Table 1)
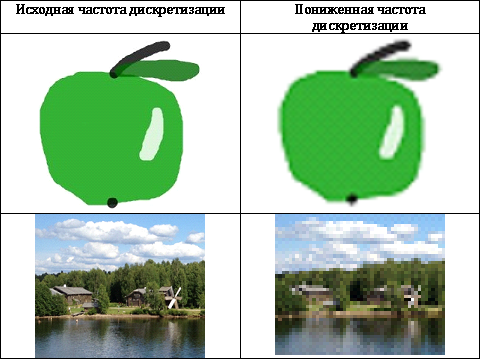
To remove redundant information, the accuracy of quantization is often reduced, but it cannot be reduced thoughtlessly, because this leads to a sharp deterioration in image quality.
Consider the image we already know. Suppose that the image is represented in the RGB color space, the encoding results of this image with reduced quantization accuracy are presented in Table. 2.

In the considered example, uniform quantization is used as the easiest way, but if it is more important to preserve color reproduction, you can use one of the following approaches: either use uniform quantization, but choose not the middle of the segment as the value of the encoded brightness, but the mathematical expectation of brightness on this segment , or use an uneven partition of the entire brightness range.
Having carefully studied the obtained images, one can notice that distinctive false contours appear on the compressed images, which significantly worsen the visual perception. There are methods based on the transfer of quantization errors to the next pixel, which can significantly reduce or even completely remove these contours, but they lead to image noise and the appearance of grain. These disadvantages greatly limit the direct use of quantization for image compression.
Most modern methods of removing visually redundant information use information about the features of human vision. Everyone knows the different sensitivity of the human eye to information about the color and brightness of the image. In Tab. Figure 3 shows the image in the YIQ color space encoded with different quantization depths of the color-difference signals IQ:
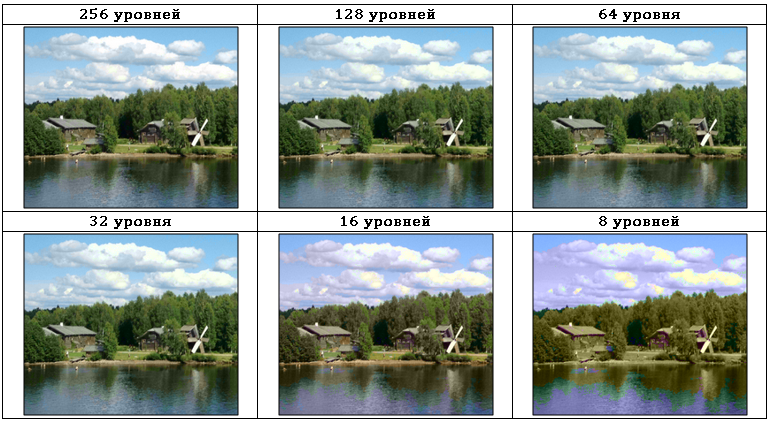
As can be seen from Table. 3, the quantization depth of color difference signals can be reduced from 256 to 32 levels with minimal visual changes. At the same time, losses in I and Q components are very significant and are shown in Table. 4

Despite the simplicity of the methods described, in their pure form they are rarely used, most often they serve as one of the steps of more efficient algorithms.
We have already considered predictive coding as a very efficient lossless information compression method. If we combine coding with prediction and compression by quantization, we get a very simple and efficient lossy image compression algorithm. In the method under consideration, the prediction error will be quantized. It is the accuracy of its quantization that will determine both the degree of compression and the distortions introduced into the compressed image. The selection of optimal algorithms for prediction and for quantization is a rather difficult task. In practice, the following universal (providing acceptable quality on most images) predictors are widely used:

We, in turn, will examine in detail the simplest and at the same time very popular way of lossy coding - the so-called delta modulation. This algorithm uses prediction based on one previous pixel, i.e. . The error obtained after the prediction stage is quantized as follows:
. The error obtained after the prediction stage is quantized as follows:
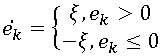
At first glance, this is a very crude method of quantization, but it has one undeniable advantage: the prediction result can be encoded with a single bit. In Tab. Figure 5 shows images encoded using delta modulation (line by line traversal) with various ξ values.

Two types of distortion are most noticeable - blurring of contours and a certain graininess of the image. These are the most typical distortions arising due to overload on the steepness and because of the so-called noise granularity. Such distortions are characteristic of all lossy prediction coding options, but it is by the example of delta modulation that they are best seen.
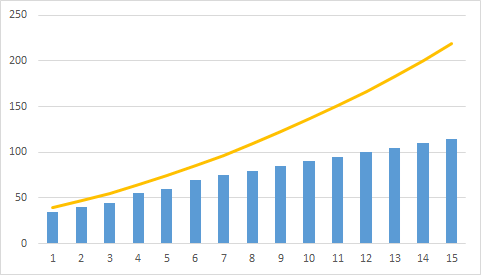
Granular noise occurs mainly in monophonic regions, when the value of ξ is too large for the correct display of small brightness fluctuations (or their absence). In Fig. 1, the yellow line indicates the initial brightness, and the blue columns show the noise that occurs when quantizing the prediction error.

The slope overload situation is fundamentally different from the situation with granularity noise. In this case, the quantity ξ is too small to transmit a sharp difference in brightness. Due to the fact that the brightness of the encoded image cannot grow as fast as the brightness of the original image, there is a noticeable blurring of the contours. The situation with overload by steepness is explained in Fig. 2
It is easy to see that the noise of the granularity decreases with a decrease in ξ, but along with this, distortions increase due to overload along the steepness and vice versa. This leads to the need to optimize ξ. For most images, it is recommended to choose ξ∈ [5; 7].
All previously discussed image compression methods worked directly with the pixels of the original image. This approach is called spatial coding. In the current section, we will consider a fundamentally different approach, called transformational coding.
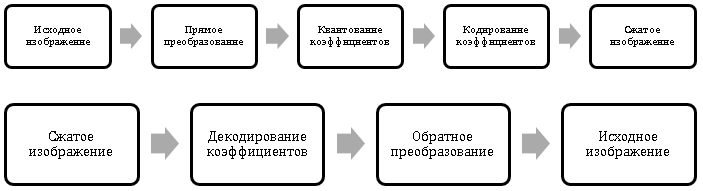
The main idea of the approach is similar to the compression method using quantization considered earlier, but not the brightness of the pixels will be quantized, but the conversion (transformation) coefficients specially calculated on their basis. Schemes of transformational compression and image restoration are shown in Fig. 3, Fig. 4.
Direct compression occurs not at the moment of encoding, but at the moment of quantization of the coefficients, because for most real images, most of the coefficients can be roughly quantized.
To obtain the coefficients, reversible linear transformations are used: for example, the Fourier transform, the discrete cosine transform, or the Walsh-Hadamard transform. The choice of a particular conversion depends on the acceptable level of distortion and available resources.
In the general case, an image of N * N pixels is considered as a discrete function of the two arguments I (r, c), then the direct transformation can be expressed as follows: The

set is the desired set of coefficients. Based on this set, you can restore the original image using the inverse transformation:
is the desired set of coefficients. Based on this set, you can restore the original image using the inverse transformation:
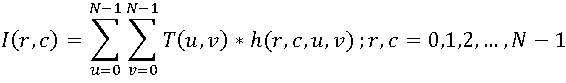
Functions are called transformation kernels, and the function g is the kernel of the direct transformation, and the function h is the kernel of the inverse transformation. The choice of the transformation core determines both the compression efficiency and the computing resources required to perform the conversion.
are called transformation kernels, and the function g is the kernel of the direct transformation, and the function h is the kernel of the inverse transformation. The choice of the transformation core determines both the compression efficiency and the computing resources required to perform the conversion.
Most commonly used in transformation coding are the kernels listed below.
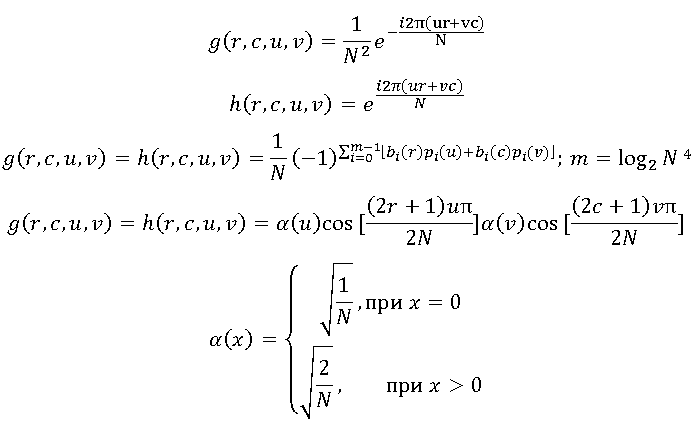
Using the first two cores of these cores leads to a simplified version of the discrete Fourier transform. The second pair of nuclei corresponds to the quite often used Walsh-Hadamard transform. And finally, the most common transform is the discrete cosine transform:
The widespread use of the discrete cosine transform is due to its good ability to compress image energy. Strictly speaking, there are more efficient conversions. For example, the Karhunen-Loev transformation has the best efficiency in terms of energy compaction, but its complexity practically excludes the possibility of wide practical application.
The combination of energy densification efficiency and comparative ease of implementation made discrete cosine transformation the standard of transformation coding.
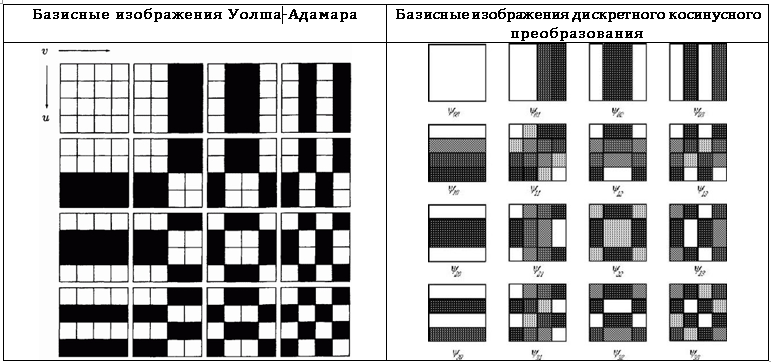
In the context of functional analysis, the considered transformations can be considered as an expansion in a set of basis functions. At the same time, in the context of image processing, these transformations can be perceived as a decomposition into basic images. To clarify this idea, consider a square image I of size n * n pixels. Transformation kernels do not depend on transformation coefficients or on the pixel value of the original image, therefore, the inverse transformation can be written in matrix form:

If these matrices are arranged in the form of a square, and the values obtained are presented in the form of pixels of a certain color, we can obtain a graphical representation of the basis functions, i.e. basic images. The basic images of the Walsh-Hadamard transform and the discrete cosine transform for n = 4 are given in Table. 7.
The general idea of transformational coding was described earlier, but, nevertheless, the practical implementation of transformational coding requires clarification of several issues.
Before encoding, the image is divided into square blocks, and then each block is converted. Both computational complexity and the final compression efficiency depend on the choice of block size. As the block size increases, both compression efficiency and computational complexity increase, therefore, in practice, blocks of 8 * 8 or 16 * 16 pixels are most often used.
After conversion coefficients are calculated for each block, it is necessary to quantize and encode them. The most common approaches are zone and threshold coding.
With the zonal approach, it is assumed that the most informative coefficients will be near the zero indices of the resulting array. This means that the corresponding coefficients should be most accurately quantized. Other coefficients can be quantized much coarser or simply discarded. The easiest way to understand the idea of zonal coding is by looking at the corresponding mask (Table 8):

The number in the cell shows the number of bits allocated for coding the corresponding coefficient.
Unlike zone coding, where the same mask is used for any block, threshold coding implies the use of a unique mask for each block. The threshold mask for the block is constructed on the basis of the following considerations: the most important factors for restoring the original image are the coefficients with the maximum value, therefore, preserving these coefficients and zeroing all the others, you can ensure both a high compression ratio and an acceptable quality of the restored image. In Tab. 9 shows an exemplary mask view for a particular block.

Units correspond to the coefficients that will be stored and quantized, and zeros correspond to the ejected coefficients. After applying the mask, the resulting coefficient matrix must be converted into a one-dimensional array, and for conversion it is necessary to use snake traversal. Then, in the resulting one-dimensional array, all significant coefficients will be concentrated in the first half, and the second half will almost entirely consist of zeros. As shown in earlier, such sequences are very efficiently compressed by series length coding algorithms.
Wavelets are mathematical functions designed to analyze the frequency components of data. Wavelets have been used relatively recently in information compression problems; nevertheless, researchers were able to achieve impressive results.
Unlike the transformations discussed above, wavelets do not require preliminary splitting of the original image into blocks, but can be applied to the image as a whole. In this section, wavelet compression will be explained using a fairly simple Haar wavelet as an example.
First, consider the Haar transformation for a one-dimensional signal. Let there be a set S of n values, during the Haar transformation, two numbers are assigned to each pair of elements: half-sum of elements and their half-difference. It is important to note that this transformation is reversible: i.e. From a pair of numbers, you can easily restore the original pair. In Fig. Figure 5 shows an example of a one-dimensional Haar transformation:

It can be seen that the signal splits into two components: an approximate value of the original (with a resolution reduced by half) and clarifying information.
The two-dimensional Haar transformation is a simple composition of one-dimensional transformations. If the initial data is presented in the form of a matrix, then the conversion is first performed for each row, and then the transformation for each column is performed for the obtained matrices. In Fig. 6 shows an example of a two-dimensional Haar transformation.

The color is proportional to the value of the function at the point (the larger the value, the darker). As a result of the conversion, four matrices are obtained: one contains an approximation of the original image (with a reduced sampling frequency), and the other three contain refinement information.
Compression is achieved by removing some coefficients from the refinement matrices. In Fig. 7 shows the recovery process and the reconstructed image itself after removal of small modulo coefficients from the refinement matrices:

Obviously, the representation of the image using wavelets allows us to achieve effective compression, while maintaining the visual quality of the image. Despite its simplicity, the Haar transformation is relatively rarely used in practice, because there are other wavelets that have several advantages (for example, Daubechies wavelets or biorthogonal wavelets).
PS Other chapters of the monograph are available for free access on gorkoff.ru
Compressed Image Quality Criteria
Before talking about lossy compression algorithms, you need to agree on what is considered acceptable loss. It is clear that the main criterion remains the visual assessment of the image, but also changes in the compressed image can be quantified. The easiest way to evaluate is to calculate the direct difference between the compressed and the source image. We agree that by
we will mean a pixel located at the intersection of the i-th row and the j-th column of the original image, and by - the corresponding pixel of the compressed image. Then, for any pixel, you can easily determine the coding error , and for the whole image, consisting of N rows and M columns, you can calculate the total error. Obviously, the larger the total error, the stronger the distortion in the compressed image. Nevertheless, this value is extremely rarely used in practice, because it does not take into account the size of the image. Much wider is the estimate using standard deviation . Another (albeit close in essence) approach is as follows: the pixels of the final image are considered as the sum of the pixels of the original image and noise. The criterion for the quality of this approach is called the magnitude signal to noise ratio (SNR), computed as follows:
.Both of these ratings are called objective criteria for fidelity of reproduction, because depend solely on the original and compressed image. However, these criteria do not always correspond to subjective assessments. If the images are intended for human perception, the only thing that can be stated: poor indicators of objective criteria most often correspond to low subjective ratings, while good indicators of objective criteria do not guarantee high subjective ratings.
Quantization and Sample Compression
The concept of visual redundancy is associated with the process of quantization and discretization. A significant part of the information in the image cannot be perceived by a person: for example, a person is able to notice minor differences in brightness, but is much less sensitive to color. Also, starting from a certain moment, increasing the accuracy of sampling does not affect the visual perception of the image. Thus, some of the information can be deleted without compromising visual quality. Such information is called visually redundant.
The easiest way to remove visual redundancy is to reduce the sampling accuracy, but in practice this method can only be used for images with a simple structure, because distortions arising on complex images are too noticeable (see Table 1)
To remove redundant information, the accuracy of quantization is often reduced, but it cannot be reduced thoughtlessly, because this leads to a sharp deterioration in image quality.
Consider the image we already know. Suppose that the image is represented in the RGB color space, the encoding results of this image with reduced quantization accuracy are presented in Table. 2.
In the considered example, uniform quantization is used as the easiest way, but if it is more important to preserve color reproduction, you can use one of the following approaches: either use uniform quantization, but choose not the middle of the segment as the value of the encoded brightness, but the mathematical expectation of brightness on this segment , or use an uneven partition of the entire brightness range.
Having carefully studied the obtained images, one can notice that distinctive false contours appear on the compressed images, which significantly worsen the visual perception. There are methods based on the transfer of quantization errors to the next pixel, which can significantly reduce or even completely remove these contours, but they lead to image noise and the appearance of grain. These disadvantages greatly limit the direct use of quantization for image compression.
Most modern methods of removing visually redundant information use information about the features of human vision. Everyone knows the different sensitivity of the human eye to information about the color and brightness of the image. In Tab. Figure 3 shows the image in the YIQ color space encoded with different quantization depths of the color-difference signals IQ:
As can be seen from Table. 3, the quantization depth of color difference signals can be reduced from 256 to 32 levels with minimal visual changes. At the same time, losses in I and Q components are very significant and are shown in Table. 4
Despite the simplicity of the methods described, in their pure form they are rarely used, most often they serve as one of the steps of more efficient algorithms.
Predictive coding
We have already considered predictive coding as a very efficient lossless information compression method. If we combine coding with prediction and compression by quantization, we get a very simple and efficient lossy image compression algorithm. In the method under consideration, the prediction error will be quantized. It is the accuracy of its quantization that will determine both the degree of compression and the distortions introduced into the compressed image. The selection of optimal algorithms for prediction and for quantization is a rather difficult task. In practice, the following universal (providing acceptable quality on most images) predictors are widely used:
We, in turn, will examine in detail the simplest and at the same time very popular way of lossy coding - the so-called delta modulation. This algorithm uses prediction based on one previous pixel, i.e.
. The error obtained after the prediction stage is quantized as follows: At first glance, this is a very crude method of quantization, but it has one undeniable advantage: the prediction result can be encoded with a single bit. In Tab. Figure 5 shows images encoded using delta modulation (line by line traversal) with various ξ values.
Two types of distortion are most noticeable - blurring of contours and a certain graininess of the image. These are the most typical distortions arising due to overload on the steepness and because of the so-called noise granularity. Such distortions are characteristic of all lossy prediction coding options, but it is by the example of delta modulation that they are best seen.
Granular noise occurs mainly in monophonic regions, when the value of ξ is too large for the correct display of small brightness fluctuations (or their absence). In Fig. 1, the yellow line indicates the initial brightness, and the blue columns show the noise that occurs when quantizing the prediction error.
The slope overload situation is fundamentally different from the situation with granularity noise. In this case, the quantity ξ is too small to transmit a sharp difference in brightness. Due to the fact that the brightness of the encoded image cannot grow as fast as the brightness of the original image, there is a noticeable blurring of the contours. The situation with overload by steepness is explained in Fig. 2
It is easy to see that the noise of the granularity decreases with a decrease in ξ, but along with this, distortions increase due to overload along the steepness and vice versa. This leads to the need to optimize ξ. For most images, it is recommended to choose ξ∈ [5; 7].
Transformation coding
All previously discussed image compression methods worked directly with the pixels of the original image. This approach is called spatial coding. In the current section, we will consider a fundamentally different approach, called transformational coding.
The main idea of the approach is similar to the compression method using quantization considered earlier, but not the brightness of the pixels will be quantized, but the conversion (transformation) coefficients specially calculated on their basis. Schemes of transformational compression and image restoration are shown in Fig. 3, Fig. 4.
Direct compression occurs not at the moment of encoding, but at the moment of quantization of the coefficients, because for most real images, most of the coefficients can be roughly quantized.
To obtain the coefficients, reversible linear transformations are used: for example, the Fourier transform, the discrete cosine transform, or the Walsh-Hadamard transform. The choice of a particular conversion depends on the acceptable level of distortion and available resources.
In the general case, an image of N * N pixels is considered as a discrete function of the two arguments I (r, c), then the direct transformation can be expressed as follows: The
set
is the desired set of coefficients. Based on this set, you can restore the original image using the inverse transformation: Functions
are called transformation kernels, and the function g is the kernel of the direct transformation, and the function h is the kernel of the inverse transformation. The choice of the transformation core determines both the compression efficiency and the computing resources required to perform the conversion.Widespread Conversion Kernels
Most commonly used in transformation coding are the kernels listed below.
Using the first two cores of these cores leads to a simplified version of the discrete Fourier transform. The second pair of nuclei corresponds to the quite often used Walsh-Hadamard transform. And finally, the most common transform is the discrete cosine transform:
The widespread use of the discrete cosine transform is due to its good ability to compress image energy. Strictly speaking, there are more efficient conversions. For example, the Karhunen-Loev transformation has the best efficiency in terms of energy compaction, but its complexity practically excludes the possibility of wide practical application.
The combination of energy densification efficiency and comparative ease of implementation made discrete cosine transformation the standard of transformation coding.
Graphical Explanation of Transformational Coding
In the context of functional analysis, the considered transformations can be considered as an expansion in a set of basis functions. At the same time, in the context of image processing, these transformations can be perceived as a decomposition into basic images. To clarify this idea, consider a square image I of size n * n pixels. Transformation kernels do not depend on transformation coefficients or on the pixel value of the original image, therefore, the inverse transformation can be written in matrix form:
If these matrices are arranged in the form of a square, and the values obtained are presented in the form of pixels of a certain color, we can obtain a graphical representation of the basis functions, i.e. basic images. The basic images of the Walsh-Hadamard transform and the discrete cosine transform for n = 4 are given in Table. 7.
Features of the practical implementation of transformational coding
The general idea of transformational coding was described earlier, but, nevertheless, the practical implementation of transformational coding requires clarification of several issues.
Before encoding, the image is divided into square blocks, and then each block is converted. Both computational complexity and the final compression efficiency depend on the choice of block size. As the block size increases, both compression efficiency and computational complexity increase, therefore, in practice, blocks of 8 * 8 or 16 * 16 pixels are most often used.
After conversion coefficients are calculated for each block, it is necessary to quantize and encode them. The most common approaches are zone and threshold coding.
With the zonal approach, it is assumed that the most informative coefficients will be near the zero indices of the resulting array. This means that the corresponding coefficients should be most accurately quantized. Other coefficients can be quantized much coarser or simply discarded. The easiest way to understand the idea of zonal coding is by looking at the corresponding mask (Table 8):
The number in the cell shows the number of bits allocated for coding the corresponding coefficient.
Unlike zone coding, where the same mask is used for any block, threshold coding implies the use of a unique mask for each block. The threshold mask for the block is constructed on the basis of the following considerations: the most important factors for restoring the original image are the coefficients with the maximum value, therefore, preserving these coefficients and zeroing all the others, you can ensure both a high compression ratio and an acceptable quality of the restored image. In Tab. 9 shows an exemplary mask view for a particular block.
Units correspond to the coefficients that will be stored and quantized, and zeros correspond to the ejected coefficients. After applying the mask, the resulting coefficient matrix must be converted into a one-dimensional array, and for conversion it is necessary to use snake traversal. Then, in the resulting one-dimensional array, all significant coefficients will be concentrated in the first half, and the second half will almost entirely consist of zeros. As shown in earlier, such sequences are very efficiently compressed by series length coding algorithms.
Wavelet compression
Wavelets are mathematical functions designed to analyze the frequency components of data. Wavelets have been used relatively recently in information compression problems; nevertheless, researchers were able to achieve impressive results.
Unlike the transformations discussed above, wavelets do not require preliminary splitting of the original image into blocks, but can be applied to the image as a whole. In this section, wavelet compression will be explained using a fairly simple Haar wavelet as an example.
First, consider the Haar transformation for a one-dimensional signal. Let there be a set S of n values, during the Haar transformation, two numbers are assigned to each pair of elements: half-sum of elements and their half-difference. It is important to note that this transformation is reversible: i.e. From a pair of numbers, you can easily restore the original pair. In Fig. Figure 5 shows an example of a one-dimensional Haar transformation:
It can be seen that the signal splits into two components: an approximate value of the original (with a resolution reduced by half) and clarifying information.
The two-dimensional Haar transformation is a simple composition of one-dimensional transformations. If the initial data is presented in the form of a matrix, then the conversion is first performed for each row, and then the transformation for each column is performed for the obtained matrices. In Fig. 6 shows an example of a two-dimensional Haar transformation.
The color is proportional to the value of the function at the point (the larger the value, the darker). As a result of the conversion, four matrices are obtained: one contains an approximation of the original image (with a reduced sampling frequency), and the other three contain refinement information.
Compression is achieved by removing some coefficients from the refinement matrices. In Fig. 7 shows the recovery process and the reconstructed image itself after removal of small modulo coefficients from the refinement matrices:
Obviously, the representation of the image using wavelets allows us to achieve effective compression, while maintaining the visual quality of the image. Despite its simplicity, the Haar transformation is relatively rarely used in practice, because there are other wavelets that have several advantages (for example, Daubechies wavelets or biorthogonal wavelets).
PS Other chapters of the monograph are available for free access on gorkoff.ru