Optimized command system for microcontrollers
A little less than a year ago, the article “Microprocessor“ From the Garage ”” was published , and perhaps now is a good moment to remind about the project again.
Perhaps the main news is the expansion of the command system, called "Version 1.1". Its difference from the previous one is advanced addressing capabilities. But first things first. To imagine what is at stake, take a look at the map of the command system (the picture is clickable):
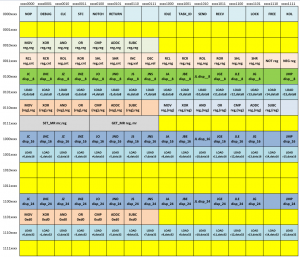
First of all, it was her who wanted to be brought to your court. When designing a command system, two basic requirements were identified - good extensibility and high code density. Reserved operation codes are marked in yellow on the picture. As you can see from the picture, we succeeded in meeting the requirements of extensibility. However, yellow “cells” is not the only opportunity for expansion - some reserve is stored in unused bits in multibyte operation codes. In addition, two prefixes (NOTCH and KOL) can extend the semantics of operation codes. As you can see from the picture, the number of single-byte prefixes can be painlessly increased. These factors make it possible to state outstanding expansion opportunities. But that is not all. Currently, the maximum instruction length is limited to five bytes - this size was chosen based on the capabilities of our inexpensive FPGA. Imagine how much you can expand the command system if you assign operation codes in the range from 0xf0 to 0xff for longer instructions - six bytes, seven ... the length of the instruction can be limited only by common sense. So, I hope that no one has doubts about the possibilities of expanding the command system, if they do exist - you are welcome to discuss them in the comments.
But what about code density? Yes, Habr is severe and does not like fictitious data. According to subjective estimates, the current code density can compete in code density with the first versions of processors with RISC architecture. For example, if we consider the very first versions of ARM and MIPS, then it seems that version 1.1 is superior to them in this parameter. As for x86 and modern RISC, thanks to the richness of the teams of these architectures, the code density on them is higher. However, if you properly exploit the inherent expansion options, then by the parameter "Code Density" you can surpass modern popular architectures.
I am sure that for many programmers with experience writing x86 assembler, a quick look at the table with instructions is enough to say "I can write in this assembler." I don’t know how the names of assembler mnemonics are protected by patents, but if possible they are chosen to coincide with x86. I would also like to say about instructions from the range 0xd0-0xd7. These are four-byte instructions, the second byte of which defines general-purpose registers, and the third and fourth serve for extended addressing.
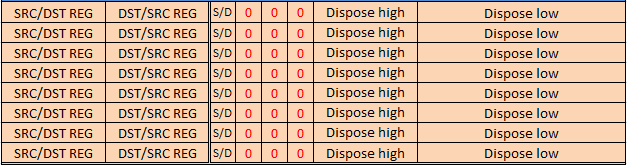
The S / D bit determines which of the arguments (four-bit register codes in the second byte) is a pointer - the first or second register. Three bits are reserved for further extensions and should be set to 0, the remaining bits define an unsigned number, added to the pointer during indirect addressing. These operations have appeared to simplify the work with structured data. You can read about this, for example, here - everest.l4os.ru/aliases_for_registers
What is characteristic, initially the code was developed as completely positionally independent and in the command system you will not find any instructions for navigating to an absolute address - either conditional or unconditional. All transition addresses are represented as offsets relative to the instruction counter. What for? This is done in order to implement 100% positionally independent machine code at the architecture level. Need a constant? Select it by offset relative to the command counter. Need a static variable, address relative to the instruction counter. However, implementation details of different addressing modes are reliably hidden behind assembler macros. The answer to the question of how to call system functions without absolute addressing is hereinafter.
Actually, all of the above applies to the command system. You probably appreciated it, perhaps even agreed with something, but ... she was 20 years late. The main areas of microprocessor application are already divided between x86, arm, mips architectures and simple microcontrollers. Extensibility and code density are the latest things that a device developer will look at when choosing a microprocessor. What gives hope that the project will be interesting to developers? Since this is a command system, take a look at the single-byte instructions IDLE , TASK_ID , SEND , RECV , LOCK , FREE .
The chip of the processor is that inside it is hidden a small part of the operating system that manages the tasks and the very concept of the task is “wired” in the microprocessor. The new instructions serve to support multitasking. The IDLE statement unconditionally enters the scheduler. In fact, an unnecessary instruction, useful only for debugging the scheduler itself. The TASK_ID instruction will return the identifier of the active task and the number of ticks until the next scheduled time allocation operation. Pair LOCK and FREE instructions are used to capture and free the message buffer. In this case, despite the coincidence of the name of the LOCK instruction with the x86 instruction, it performs completely different functions. Since the processor operates on the concept of a task, means are needed for the interaction of tasks. Using the LOCK statement, the task captures the message buffer, and using the FREE statement frees him. The message buffer is 64 registers, the exchange of which takes place using the instructions SET_MR (write message register with a value from RON) and GET_MR and (read message register in RON).
Of course, the most important instructions, for which the whole project was started, are the SEND and RECV instructions - the instructions for sending and receiving messages. These instructions have two arguments - the task number for interaction and the operation timeout (set in registers). The easiest way to give the task time to the system or to implement a delay is to send a message to itself or wait for a message from itself - the scheduler simply will not transfer control to the blocked task before the message timeout expires.
SEND and RECV operations are synchronous - in order for a message to pass between tasks, one of the tasks must be executed by RECV, and the other by SEND. In most cases, this means that the first task that has completed one of these instructions will block waiting for another task to be ready. If for some reason blocking is undesirable, then a zero timeout is set and if one of the parties is not ready, instead of blocking, the task receives a status signaling a timeout.
At the time the message is sent, the message buffer that was previously captured by the LOCK instruction is switched to the task of the receiving message. The task that received the message should work after the buffer has been freed. For example, a call to the puts library function might look like this:
This code is as simple as possible for ease of understanding. In this example, the FREE instruction frees the message buffer received by the RECV statement because the buffer captured by the LOCK instruction is delegated to the receiver task when the message was sent.
Despite the apparent complexity and unusualness of the solution, nothing changes from the point of view of the application programmer - library functions carefully hide implementation details. But system programmers and library developers will have to try - they will have to start with the fact that any interaction between programs must be described in the form of a protocol that describes the format of requests and responses - a complex software complex is described as a set of interacting entities that solve certain problems through interaction.
All experiments are conducted with this miracle - Mars rover2 board:

Thank you for your attention. First of all, I would like to discuss the command system, since it already works in hardware. As for hardware extensions for multitasking, they are not ready yet - information on multitasking support is provided for informational purposes, and the actual implementation may not correspond to the material in the article.
Perhaps the main news is the expansion of the command system, called "Version 1.1". Its difference from the previous one is advanced addressing capabilities. But first things first. To imagine what is at stake, take a look at the map of the command system (the picture is clickable):

First of all, it was her who wanted to be brought to your court. When designing a command system, two basic requirements were identified - good extensibility and high code density. Reserved operation codes are marked in yellow on the picture. As you can see from the picture, we succeeded in meeting the requirements of extensibility. However, yellow “cells” is not the only opportunity for expansion - some reserve is stored in unused bits in multibyte operation codes. In addition, two prefixes (NOTCH and KOL) can extend the semantics of operation codes. As you can see from the picture, the number of single-byte prefixes can be painlessly increased. These factors make it possible to state outstanding expansion opportunities. But that is not all. Currently, the maximum instruction length is limited to five bytes - this size was chosen based on the capabilities of our inexpensive FPGA. Imagine how much you can expand the command system if you assign operation codes in the range from 0xf0 to 0xff for longer instructions - six bytes, seven ... the length of the instruction can be limited only by common sense. So, I hope that no one has doubts about the possibilities of expanding the command system, if they do exist - you are welcome to discuss them in the comments.
But what about code density? Yes, Habr is severe and does not like fictitious data. According to subjective estimates, the current code density can compete in code density with the first versions of processors with RISC architecture. For example, if we consider the very first versions of ARM and MIPS, then it seems that version 1.1 is superior to them in this parameter. As for x86 and modern RISC, thanks to the richness of the teams of these architectures, the code density on them is higher. However, if you properly exploit the inherent expansion options, then by the parameter "Code Density" you can surpass modern popular architectures.
I am sure that for many programmers with experience writing x86 assembler, a quick look at the table with instructions is enough to say "I can write in this assembler." I don’t know how the names of assembler mnemonics are protected by patents, but if possible they are chosen to coincide with x86. I would also like to say about instructions from the range 0xd0-0xd7. These are four-byte instructions, the second byte of which defines general-purpose registers, and the third and fourth serve for extended addressing.
The S / D bit determines which of the arguments (four-bit register codes in the second byte) is a pointer - the first or second register. Three bits are reserved for further extensions and should be set to 0, the remaining bits define an unsigned number, added to the pointer during indirect addressing. These operations have appeared to simplify the work with structured data. You can read about this, for example, here - everest.l4os.ru/aliases_for_registers
What is characteristic, initially the code was developed as completely positionally independent and in the command system you will not find any instructions for navigating to an absolute address - either conditional or unconditional. All transition addresses are represented as offsets relative to the instruction counter. What for? This is done in order to implement 100% positionally independent machine code at the architecture level. Need a constant? Select it by offset relative to the command counter. Need a static variable, address relative to the instruction counter. However, implementation details of different addressing modes are reliably hidden behind assembler macros. The answer to the question of how to call system functions without absolute addressing is hereinafter.
Actually, all of the above applies to the command system. You probably appreciated it, perhaps even agreed with something, but ... she was 20 years late. The main areas of microprocessor application are already divided between x86, arm, mips architectures and simple microcontrollers. Extensibility and code density are the latest things that a device developer will look at when choosing a microprocessor. What gives hope that the project will be interesting to developers? Since this is a command system, take a look at the single-byte instructions IDLE , TASK_ID , SEND , RECV , LOCK , FREE .
The chip of the processor is that inside it is hidden a small part of the operating system that manages the tasks and the very concept of the task is “wired” in the microprocessor. The new instructions serve to support multitasking. The IDLE statement unconditionally enters the scheduler. In fact, an unnecessary instruction, useful only for debugging the scheduler itself. The TASK_ID instruction will return the identifier of the active task and the number of ticks until the next scheduled time allocation operation. Pair LOCK and FREE instructions are used to capture and free the message buffer. In this case, despite the coincidence of the name of the LOCK instruction with the x86 instruction, it performs completely different functions. Since the processor operates on the concept of a task, means are needed for the interaction of tasks. Using the LOCK statement, the task captures the message buffer, and using the FREE statement frees him. The message buffer is 64 registers, the exchange of which takes place using the instructions SET_MR (write message register with a value from RON) and GET_MR and (read message register in RON).
Of course, the most important instructions, for which the whole project was started, are the SEND and RECV instructions - the instructions for sending and receiving messages. These instructions have two arguments - the task number for interaction and the operation timeout (set in registers). The easiest way to give the task time to the system or to implement a delay is to send a message to itself or wait for a message from itself - the scheduler simply will not transfer control to the blocked task before the message timeout expires.
SEND and RECV operations are synchronous - in order for a message to pass between tasks, one of the tasks must be executed by RECV, and the other by SEND. In most cases, this means that the first task that has completed one of these instructions will block waiting for another task to be ready. If for some reason blocking is undesirable, then a zero timeout is set and if one of the parties is not ready, instead of blocking, the task receives a status signaling a timeout.
At the time the message is sent, the message buffer that was previously captured by the LOCK instruction is switched to the task of the receiving message. The task that received the message should work after the buffer has been freed. For example, a call to the puts library function might look like this:
LOCK; Message buffer capture SET_MR MR0, R2; setting message id SET_MR MR1, R3; setting the message argument SEND message passing RECV waiting for a reply to a message GET_MR R0, MR0; reading return code FREE; free message buffer
This code is as simple as possible for ease of understanding. In this example, the FREE instruction frees the message buffer received by the RECV statement because the buffer captured by the LOCK instruction is delegated to the receiver task when the message was sent.
Despite the apparent complexity and unusualness of the solution, nothing changes from the point of view of the application programmer - library functions carefully hide implementation details. But system programmers and library developers will have to try - they will have to start with the fact that any interaction between programs must be described in the form of a protocol that describes the format of requests and responses - a complex software complex is described as a set of interacting entities that solve certain problems through interaction.
All experiments are conducted with this miracle - Mars rover2 board:
Thank you for your attention. First of all, I would like to discuss the command system, since it already works in hardware. As for hardware extensions for multitasking, they are not ready yet - information on multitasking support is provided for informational purposes, and the actual implementation may not correspond to the material in the article.