Log collection and analysis with Fluentd

Any system administrator in his daily activities has to deal with the collection and analysis of logs. The collected logs need to be stored - they can be used for a variety of purposes: for debugging programs, for analyzing incidents, as a help for technical support, etc. In addition, it is necessary to provide the ability to search the entire data array.
Organizing the collection and analysis of logs is not as simple as it might seem at first glance. To begin with, you have to aggregate the logs of different systems that may have nothing in common with each other. It is also highly advisable to attach the collected data to a single timeline in order to track the connections between events. Implementing a log search is a separate and complex problem.
Over the past few years, interesting software tools have appeared to solve the problems described above. Solutions that allow you to store and process logs online: Splunk , Loggly , Papertrail , Logentries and others are becoming increasingly popular . Among the undoubted advantages of these services should be called a convenient interface and low cost of use (and within the framework of basic free tariffs they provide very good opportunities). But when working with large numbers of logs, they often do not cope with the tasks assigned to them. In addition, their use to work with large amounts of information is often disadvantageous from a purely financial point of view.
A much more preferable option is to deploy an independent solution. We thought about this issue when we faced the need to collect and analyze cloud storage logs .
We started looking for a suitable solution and opted for Fluentd , a not- without -interest tool with a fairly wide functionality, about which there are almost no detailed publications in Russian. The features of Fluentd will be described in detail in this article.
general information
Fluend was developed by Sadayuki Furuhashi, co-founder of Treasure Data (she is one of the sponsors of the project), in 2011. It is written in Ruby. Fluentd is actively developing and improving (see the repository on GitHub, where updates appear steadily every few days).
Among the users of Fluentd are such well-known companies as Nintendo, Amazon, Slideshare and others.
Fluentd collects logs from various sources and passes them to other applications for further processing. In a schematic form, the process of collecting and analyzing logs using Fluentd can be represented as follows:
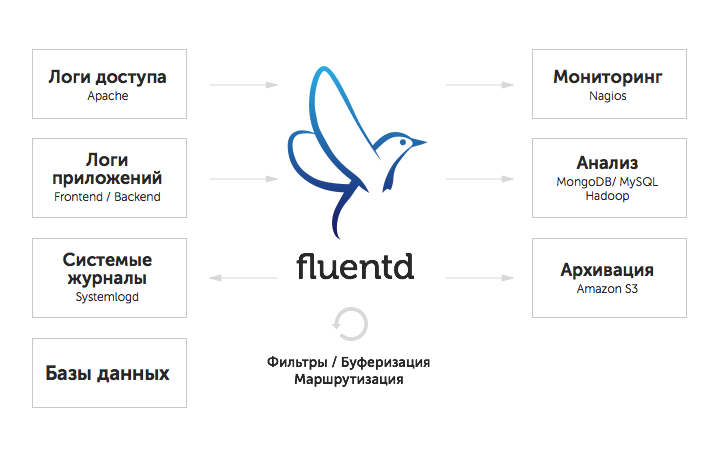
The following are the main advantages of Fluentd:
- Low system resource requirements. For normal operation, Fluentd is enough 30 - 40 MB of RAM; the processing speed is 13,000 events per second.
- Using a unified logging format. Fluentd translates data from multiple sources into JSON format. This helps to solve the problem of collecting logs from various systems and opens up wide opportunities for integration with other software solutions.
- Convenient architecture. The Fluentd architecture allows you to expand your existing feature set with the help of numerous plug-ins (to date, more than 300 of them have been created). Using plugins, you can connect new data sources and display data in various formats.
- Ability to integrate with various programming languages. Fluentd can accept logs from applications in Python, Ruby, PHP, Perl, Node.JS, Java, Scala.
Fluentd is distributed free of charge under the Apache 2.0 license. The project is documented in sufficient detail; on the official website and in the blog published a lot of useful training materials.
Installation
In this article, we describe the installation procedure for Ubuntu 14.04. Installation instructions for other operating systems can be found here.
Installation and initial setup of Fluentd is carried out using a special script. Run the commands:
$ wget http://packages.treasuredata.com/2/ubuntu/trusty/pool/contrib/t/td-agent/td-agent_2.0.4-0_amd64.deb $ sudo dpkg -i td-agent_2.0.4-0_amd64.deb
When the installation is complete, run Fluentd:
$ /etc/init.d/td-agent restart
Configuration
The principle of operation of Fluentd is as follows: it collects data from various sources, checks for compliance with certain criteria, and then forwards it to the specified locations for storage and further processing. All this can be
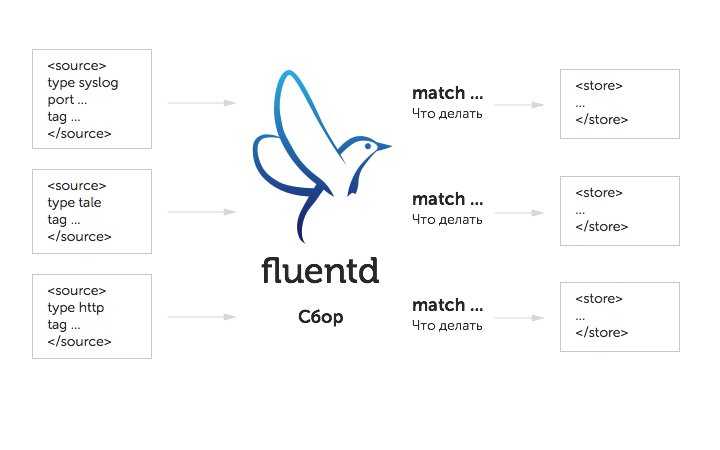
visually presented in the form of the following scheme: Fluentd settings (what data and where to get it, what criteria they should meet, where to forward it) are written in the configuration file /etc/td-agent/td-agent.conf, which is built from the following blocks:
- source - contains information about the data source;
- match - contains information about where to transfer the received data;
- include - contains information about file types;
- system - contains system settings.
Consider the structure and content of these blocks in more detail.
Source: where to get data
The source block contains information about where to get the data. Fluentd can receive data from various sources: these are application logs in various programming languages (Python, PHP, Ruby, Scala, Go, Perl, Java), database logs, logs from various hardware devices, data from monitoring utilities ... With a complete list of possible sources data can be found here. To connect sources, specialized plugins are used.
Standard plugins include http (used to receive HTTP messages) and forward (used to receive TCP packets). You can use both of these plugins at the same time.
Example:
# We accept events from port 24224 / tcptype forward port 24224 # http://this.host:9880/myapp.access?json={"event":"data "} type http port 9880
As can be seen from the above example, the type of the plugin is specified in the type directive, and the port number in the port directive.
The number of data sources is unlimited. Each data source is described in a separate block.
All events received from sources are sent to the message router. Each event has three attributes: tag, time and record. Based on the tag attribute, a decision is made about where the events should be redirected (more on this below). The time attribute is specified in the time attribute (this is done automatically), and in the record attribute - data in JSON format.
Here is an example of a description of the event:
# generated by http://this.host:9880/myapp.access?json={"event":"data "}
tag: myapp.access
time: (current time)
record: {"event": "data"}
Match: what to do with data
The Match section indicates by what criteria events will be selected for subsequent processing. For this, specialized plugins are used.
Standard output plugins include match and forward:
# We receive events from port 24224type forward port 24224 # http://this.host:9880/myapp.access?json={"event":"data "} type http port 9880 # Take events tagged with "myapp.access" # and save them in the file / var / log / fluent / access.% Y-% m-% d # data can be divided into portions using the time_slice_format option. type file path / var / log / fluent / access
The above snippet indicates that all events marked with the tags myapp and access should be saved in a file, the path to which is specified in the path directive. Please note that events that, in addition to the myapp and access tags are also marked by other tags, will not be sent to the file.
Briefly consider the syntax features of the match directive:
- * symbol means matching any part of the tag (if specified
, then ab will match the given condition, but abc will not); - ** means match any tag (if you specify
, then a, and ab, and abc) will correspond to the given condition; - {x, y, z} means matching at least one of the tags indicated in braces (if you specify
, then a and b will correspond to the given condition, while c will not); - braces can be used in combination with * and **, for example:
or *; means matching tags a and b at the same time; means matching tags a, ab and abc (first part) and bd (second part).
Fluentd checks events for matching tags in the order in which match blocks follow each other in the configuration file. First, correspondences of a private nature are indicated, and then more general correspondences. If this rule is violated, Fluentd will not work correctly. So, a fragment of the form
type blackhole_plugin type file path / var / log / fluent / access
contains an error: first, it indicates extremely general matches (
type file path / var / log / fluent / access type blackhole_plugin
Include: merge configuration files
Directives can be imported from one configuration file to another and merged. This operation is performed in the include block:
include config.d / *. conf
In this directive, you can specify the path to one or more files with a mask or URL:
# absolute file path include /path/to/config.conf # you can specify a relative path include extra.conf #mask include config.d / *. conf # http include http://example.com/fluent.conf
System: set advanced settings
In the System block, you can set additional settings, for example, set the logging level (see here for details ), enable or disable the option to delete duplicate entries from logs, etc.
Supported Data Types
Each plugin for Fluentd has a specific set of parameters. Each parameter is in turn associated with a particular data type.
Here is a list of data types supported by Fluentd:
- string - string;
- integer is an integer;
- float - floating point number;
- size - number of bytes; The following recording options are possible:
- <integer> k is the size in kilobytes;
- <integer> g - size in gigabytes;
- <integer> t - terabyte size;
- if no unit is specified, then the value in the size field will be interpreted as the number of bytes.
- time - time; The following recording options are possible:
- <integer> s - time in seconds;
- <integer> m - time in minutes;
- <integer> h is the time in hours;
- <integer> d is the time in days;
- if no unit is indicated, the value in the time field will be interpreted as the number of seconds.
- array - a JSON array;
- hash is a JSON object.
Fluentd Plugins: Expanding Features
Fluentd uses 5 types of plugins: output plugins, input plugins, buffering plugins, form plugins, and parsing plugins.
Input plugins
Input plugins are used to obtain contracts from external sources. Typically, such a plugin creates a thread socket and a listen socket. You can also configure the plugin so that it will receive data from an external source with a certain frequency.
Input plugins include:
- in_forward - listens on a TCP socket;
- in_http - accepts messages transmitted in POST requests;
- in_tail - reads messages written in the last lines of text files (works the same as the tail -F command);
- in_exec - with this plugin you can run a third-party program and receive its event log; JSON, TSV and MessagePack formats are supported;
- in_syslog - using this plugin you can receive messages in syslog format via UDP;
- in_scribe - allows you to receive messages in the Scribe format (Scribe is also a log collector developed by Facebook).
Output plugins
Output plugins are divided into three groups:
- plugins without buffering - do not save the results in the buffer and instantly write them to standard output;
- with buffering - divide events into groups and record in turn; you can set limits on the number of stored events, as well as on the number of events placed in the queue;
- with separation by time intervals - these plugins are essentially a kind of plug-ins with buffering, only events are divided into groups by time intervals.
Non-buffered plugins include:
- out_copy - copies events to the specified location (or several places);
- out_null - this plugin just throws packets;
- out_roundrobin - writes events to various locations of output, which are selected by circular search;
- out_stdout - instantly writes events to standard output (or to the log file if it is running in daemon mode).
Buffered plugins include:
- out_exec_filter - launches an external program and reads an event from its output;
- out_forward - sends events to other fluentd nodes;
- out_mongo (or out_mongo_replset) - transfers records to the MongoDB database.
Buffering plugins
Buffering plugins are used as auxiliary for output plugins that use a buffer. This group of plugins includes:
- buf_memory - changes the amount of memory used to store buffered data (for more details, see the official documentation);
- buf_file - makes it possible to store the contents of the buffer in a file on the hard disk.
You can read more about how buffering plugins work here .
Formatting plugins
Using formatting plugins, you can change the format of data received from logs. The standard plugins in this group include:
- out_file - allows you to customize the data presented in the form of "time - tag - record in json format";
- json - removes the "time" or "tag" field from a json record;
- ltsv - converts a record to LTSV format;
- single_value - displays the value of one field instead of the whole record;
- csv - displays a record in CSV / TSV format.
You can read more about formatting plugins here .
Parsing plugins
These plugins are used to parse specific input data formats in cases when it is impossible to do this using regular tools. More information about parsing plugins can be found here .
Naturally, it is impossible to describe all the fluentd plugins in the review article - this is a topic for a separate publication. A complete list of all currently available plugins can be found on this page .
General parameters for all plugins
The following parameters are also indicated for all plugins:
- type - type;
- id - identification number;
- log_level - logging level (see above).
On the official site of fluentd, ready-made configuration files are laid out, adapted for various usage scenarios (see here ).
Data output and integration with other solutions
Collected using Fluentd can be transferred for storage and further processing to databases (MySQL, PostgreSQL, CouchBase, CouchDB, MongoDB, OpenTSDB, InfluxDB) distributed file systems (HDFS - see also the article on Fluentd c Hadoop integration) cloud services (AWS , Google BigQuery), search tools (Elasticsearch, Splunk, Loggly).
To provide the ability to search and visualize data, the Fluentd + Elasticsearc + Kibana combination is often used (for detailed installation and configuration instructions, see, for example, here ).
A complete list of services and tools to which Fluentd can transfer data is available here . The official website also published instructions how to use Fluentd in conjunction with other solutions.
Conclusion
In this article, we presented an overview of the capabilities of the Fluentd log collector, which we use to solve our own problems. If you are interested and you have a desire to try Fluentd in practice, we have prepared the Ansible role , which will help simplify the installation and deployment process.
Probably, many of you have faced the problem of collecting and analyzing logs. It would be interesting to know what tools you use to solve it and why you chose them. And if you use Fluentd - share your experience in the comments.
If you for one reason or another can not leave comments here - welcome to our blog .