Submission Mechanism - Special Cuban Magic
- Transfer

Views, or views, is one of the concepts of the CUBA platform, not the most common in the world of web frameworks. To understand it means to save yourself from stupid mistakes when, due to incompletely loaded data, the application suddenly stops working. Let's see what the presentation (pun) is and why it is actually convenient.
The problem of unloaded data
Take the subject area easier and consider the problem in her example. Suppose we have a Customer entity that refers to the CustomerType entity in relation to the many-to-one, in other words, the buyer has a reference to some type describing it: for example, a cash cow, a barkman, etc. The CustomerType entity has a name attribute in which the type name is stored.
And, probably, all novices (or even advanced users) in CUBA sooner or later received the following error:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
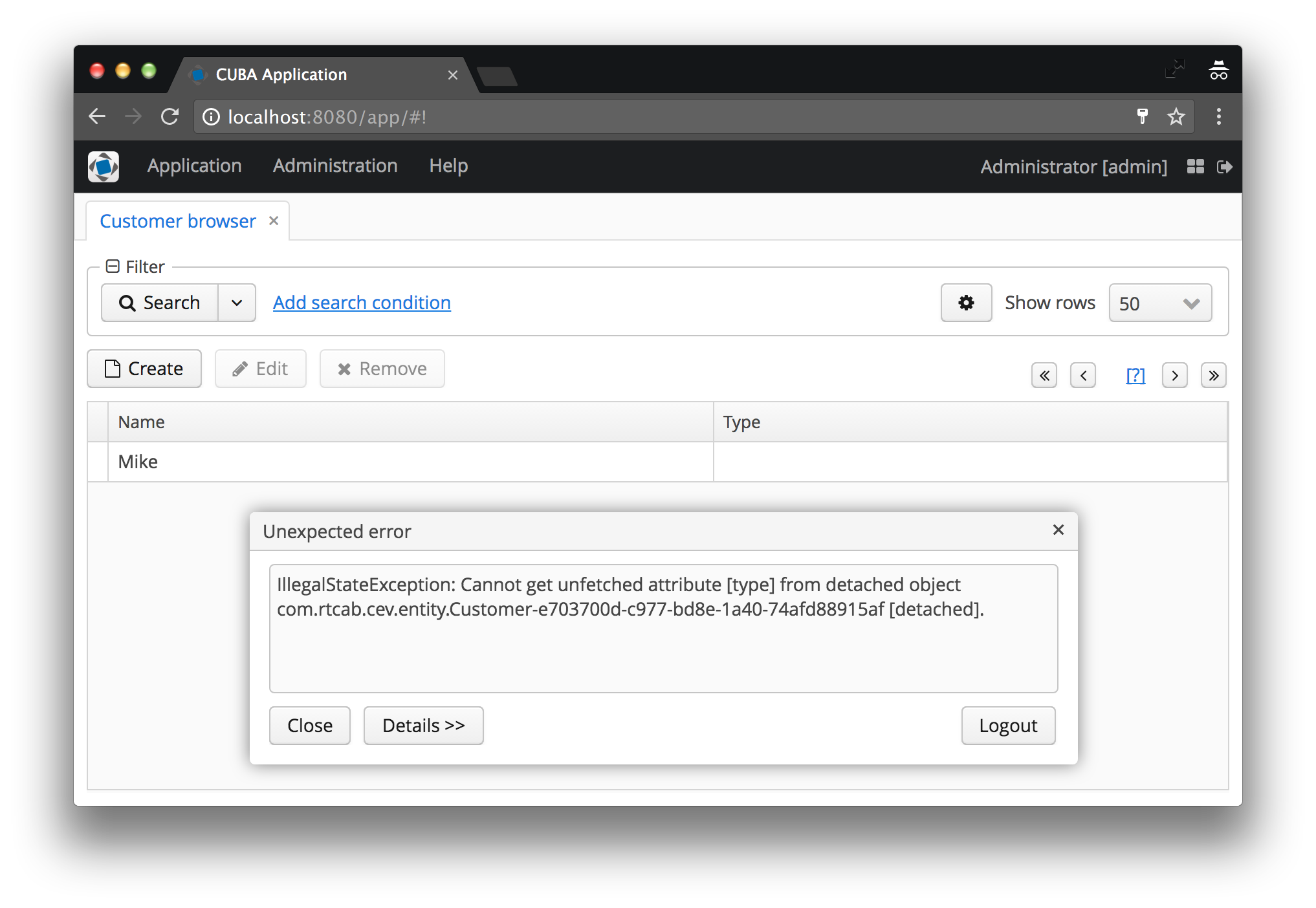
Admit it, you saw it with your own eyes too? I am, yes, in a hundred different situations. In this article we will look at the cause of this problem, why it exists at all and how to solve it.
For a start, a small introduction to the concept of views.
What is the presentation?
A view in CUBA is essentially a set of columns in a database that must be loaded together in a single query.
Suppose we want to create a UI with a customer table, where the first column is the buyer’s name and the second is the type name from the customerType attribute (as in the screenshot above). It is logical to assume that in this data model we will have two separate tables in the database, one for the Customer entity , the other for the CustomerType . The request SELECT * from CEV_CUSTOMERwill return data to us only from one table (attribute name, etc.). Obviously, to get data from other tables, we will use JOINs.
In the case of using classic SQL queries using JOIN, the hierarchy of associations (reference attributes) is expanded from a graph into a flat list.
Translator’s note: in other words, the relationships between tables are erased, and the result is presented in a single dataset representing the union of the tables.
In the case of CUBA, ORM is used, which does not lose information about the relationships between entities and presents the result of queries as a complete graph of the requested data. In this case, JPQL, an object analog of SQL, is used as the query language.
However, the data still needs to somehow be unloaded from the database and transformed into an entity graph. For this, the object-relational mapping mechanism (which is JPA) has two main approaches to queries to the base.
Lazy loading vs. eager fetching
Lazy loading and greedy loading are two possible strategies for retrieving data from the database. The fundamental difference between the two is the time at which data is loaded from the associated tables. A small example for better understanding:
Remember the scene from the book "The Hobbit, or there and back," where a group of gnomes in the company of Gandalf and Bilbo are trying to ask for a bed at Beorn's house? Gandalf ordered the gnomes to appear strictly in turns and only after he carefully agreed with Beorn and began to present them one by one, so as not to shock the owner by the need to accommodate 15 guests at once.

So, Gandalf and the dwarves in Beorn’s house ... Perhaps this is not the first thing that comes to mind at the thought of lazy and greedy loads, but there is definitely a similarity. Gandalf acted wisely here, as he was aware of limitations. He can be said to have consciously chosen the lazy loading of the gnomes, since he understood that downloading all the data would immediately be too difficult for this database. However, after the 8th gnome, Gandalf switched to greedy loading and loaded a pack of remaining gnomes, because he noticed that too many references to the database start to irritate her no less.
The moral is that both lazy and greedy loading have their pros and cons. What to apply in each situation, you decide.
N + 1 query problem
The problem of requesting N + 1 often arises if you are thoughtlessly using lazy loading wherever you go. To illustrate, let's look at a piece of Grails code. This does not mean that everything loads in Grails is lazy (in fact, you choose the method of loading yourself). In Grails, a query to the database by default returns instances of entities with all attributes from its table. Essentially, satisfied SELECT * FROM Pet.
If you want to go deep into the relationship between entities, you have to do this post factum. Here is an example:
function getPetOwnerNamesForPets(String nameOfPet) {
def pets = Pet.findAll(sort:"name") {
name == nameOfPet
}
def ownerNames = []
pets.each {
ownerNames << it.owner.name
}
return ownerNames.join(", ")
}Traversing the graph here performs one single line: it.owner.name. Owner is a relationship that was not loaded in the original query ( Pet.findAll). Thus, each time this line is called, GORM will do something like SELECT * FROM Person WHERE id=’…’. Clean water lazy loading.
If you count the total number of SQL queries, you get N (one host for each call it.owner) + 1 (for the initial one Pet.findAll). If you want to go deeper in the graph of related entities, it is likely that your database will quickly find the limit of its capabilities.
As a developer, you will hardly notice this, because from your point of view, you just walk around the object graph. This hidden nesting in one short line causes real pain to the database and makes lazy loading sometimes dangerous.
In developing the Hobbic analogy, the N + 1 problem could manifest itself as follows: imagine that Gandalf is not able to remember the names of the dwarfs in memory. Therefore, introducing the gnomes one by one, he is forced to retreat back to his group and ask the gnome for his name. With this information, he goes back to Beorn and introduces Thorin. Then he repeats this maneuver for Bifur, Bofur, Fili, Kili, Dory, Nori, Ori, Oina, Gloin, Balin, Dvalin and Bombur.

It is not difficult to imagine that Beorn would hardly have liked such a scenario: which recipient would want to wait for the requested information for so long? Therefore, you should not mindlessly use this approach and blindly rely on the default settings of your persistence mapper.
Solving the problem of N + 1 queries using CUBA views
In CUBA, you most likely will never encounter the problem of N + 1 queries, since it was decided not to use the hidden lazy boot in the platform at all. Instead, CUBA introduced the concept of representations. Views are a description of which attributes should be selected and loaded along with entity instances. Something like
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.idOn the one hand, the view describes the columns that need to be loaded from the main table ( Pet ) (instead of loading all attributes via *), on the other hand, it also describes the columns that should be loaded from the c-JOIN tables.
You can think of the CUBA view as a SQL view for the OR-Mapper: the principle of operation is about the same.
In the CUBA platform, you cannot call a query through the DataManager without using view. The documentation provides an example:
@Injectprivate DataManager dataManager;
private Book loadBookById(UUID bookId){
LoadContext<Book> loadContext = LoadContext.create(Book.class)
.setId(bookId).setView("book.edit");
return dataManager.load(loadContext);
}Here we want to download the book by its ID. The method setView("book.edit")during the creation of the Load context indicates with which view the book should be loaded from the database. In case you don’t pass any view, the data manager uses one of the three standard views that each entity has: the _local view . Attributes that do not refer to other tables are called local here, everything is simple.
Solving the problem with IllegalStateException through views
Now that we have a little understanding of the concept of representations, let's go back to the first example from the beginning of the article and try to prevent the exception from being thrown.
The message IllegalStateException: Cannot get unfetched attribute [] from detached object means only that you are trying to display some attribute that is not included in the view with which the entity is loaded.
As you can see, in the browse screen descriptor, I used the _local view , and that's the problem:
<dsContext><groupDatasourceid="customersDs"class="com.rtcab.cev.entity.Customer"view="_local"><query>
<![CDATA[select e from cev$Customer e]]>
</query></groupDatasource></dsContext>To get rid of the error, you first need to include the customer type in the view. Since we cannot change the default _local view , we can create our own. In Studio, this can be done, for example, as follows (right click on entities> create view):
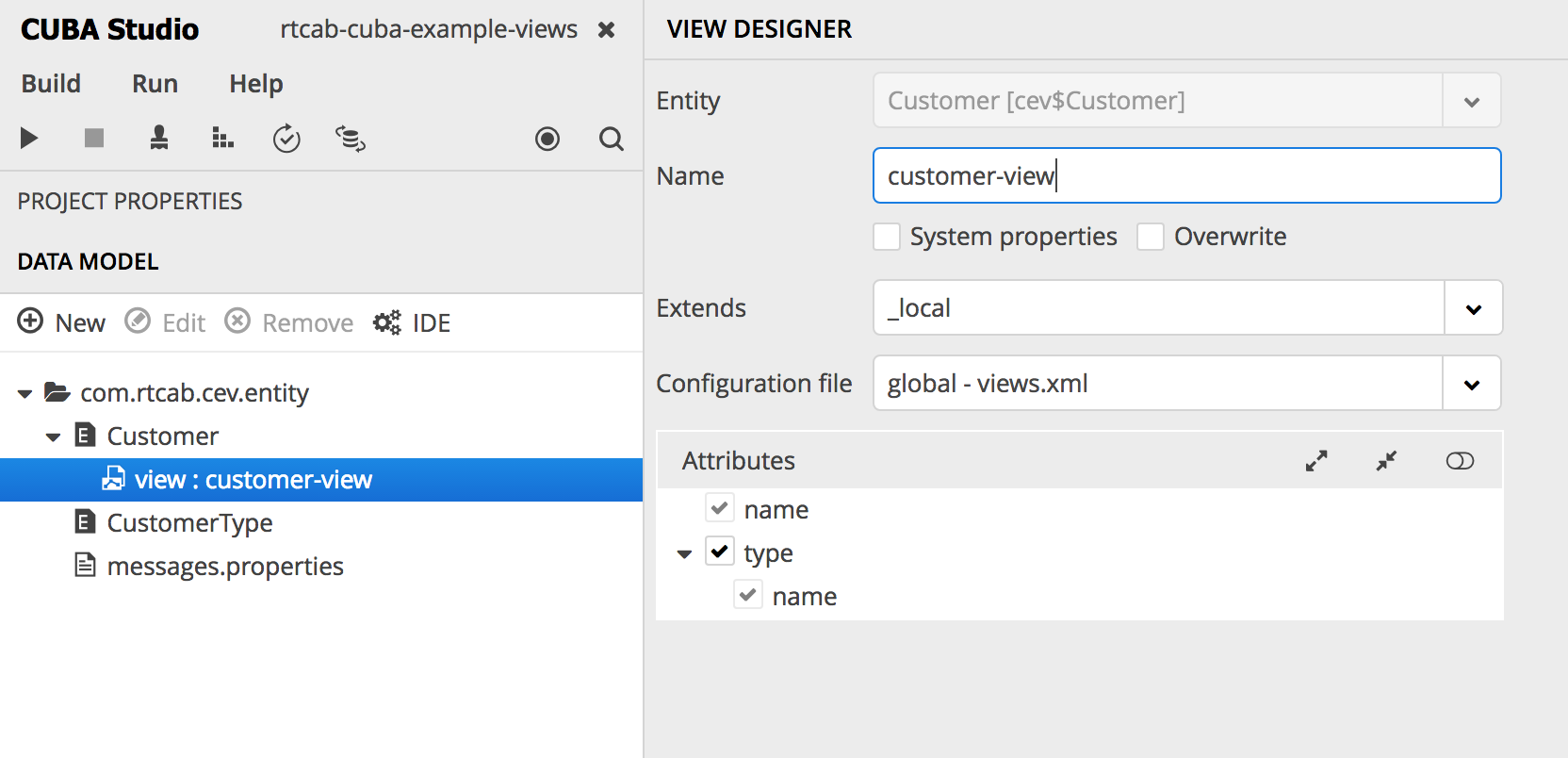
or directly in the views.xml descriptor of our application:
<viewclass="com.rtcab.cev.entity.Customer"extends="_local"name="customer-view"><propertyname="type"view="_minimal"/></view>After that we change the link to the browse screen view, like this:
<groupDatasourceid="customersDs"class="com.rtcab.cev.entity.Customer"view="customer-view"><query>
<![CDATA[select e from cev$Customer e]]>
</query></groupDatasource>This completely solves the problem, and now the reference data is displayed on the customer viewing screen.
_Minimal view and the concept of instance name
What else is worth mentioning in the context of views is the _minimal view. A local view has a very clear definition: it includes all the attributes of an entity that are the immediate attributes of a given table (which are not foreign keys).
The definition of the minimum representation is not so obvious, but also quite clear.
In CUBA, there is the concept of an entity name instance - instance name. An instance name is the equivalent of toString()a good old Java method . This is a string representation of an entity for display on the UI and used in links. The instance name is specified using the NamePattern entity annotation .
Use it like this: @NamePattern("%s (%s)|name,code"). We have two results:
The instance name defines the entity mapping in the UI.
First of all, the instance name determines what and in what order it will be displayed in the UI if a certain entity refers to another entity (as Customer refers to CustomerType ).
In our case, the type of customer will be displayed as the instance name CustomerType , to which code has been added to the brackets. If the instance name is not specified, the name of the entity class and the ID of the specific instance will be displayed, agree that this is not at all what the user would like to see. Examples of both cases are shown below in the “before and after” screenshots.
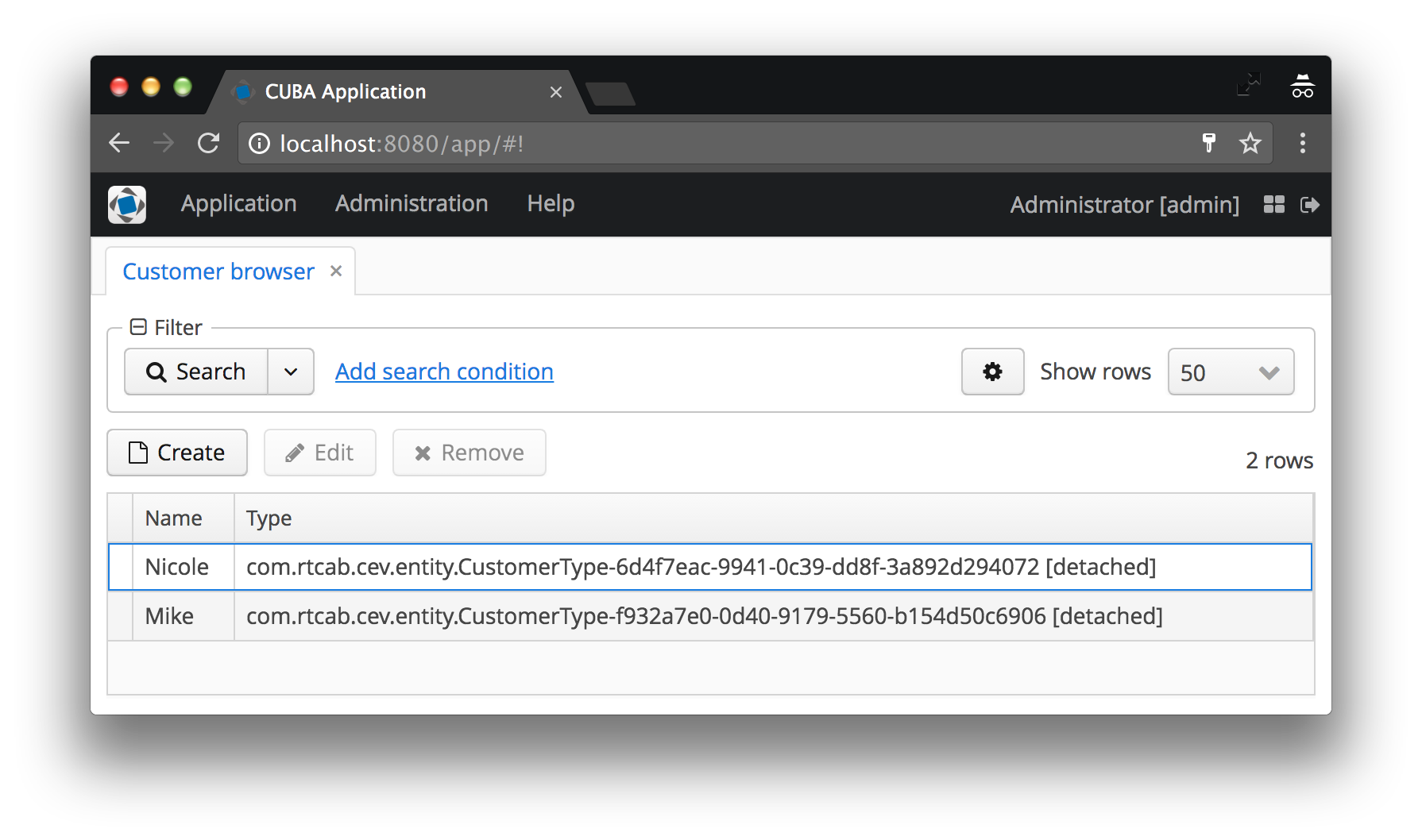
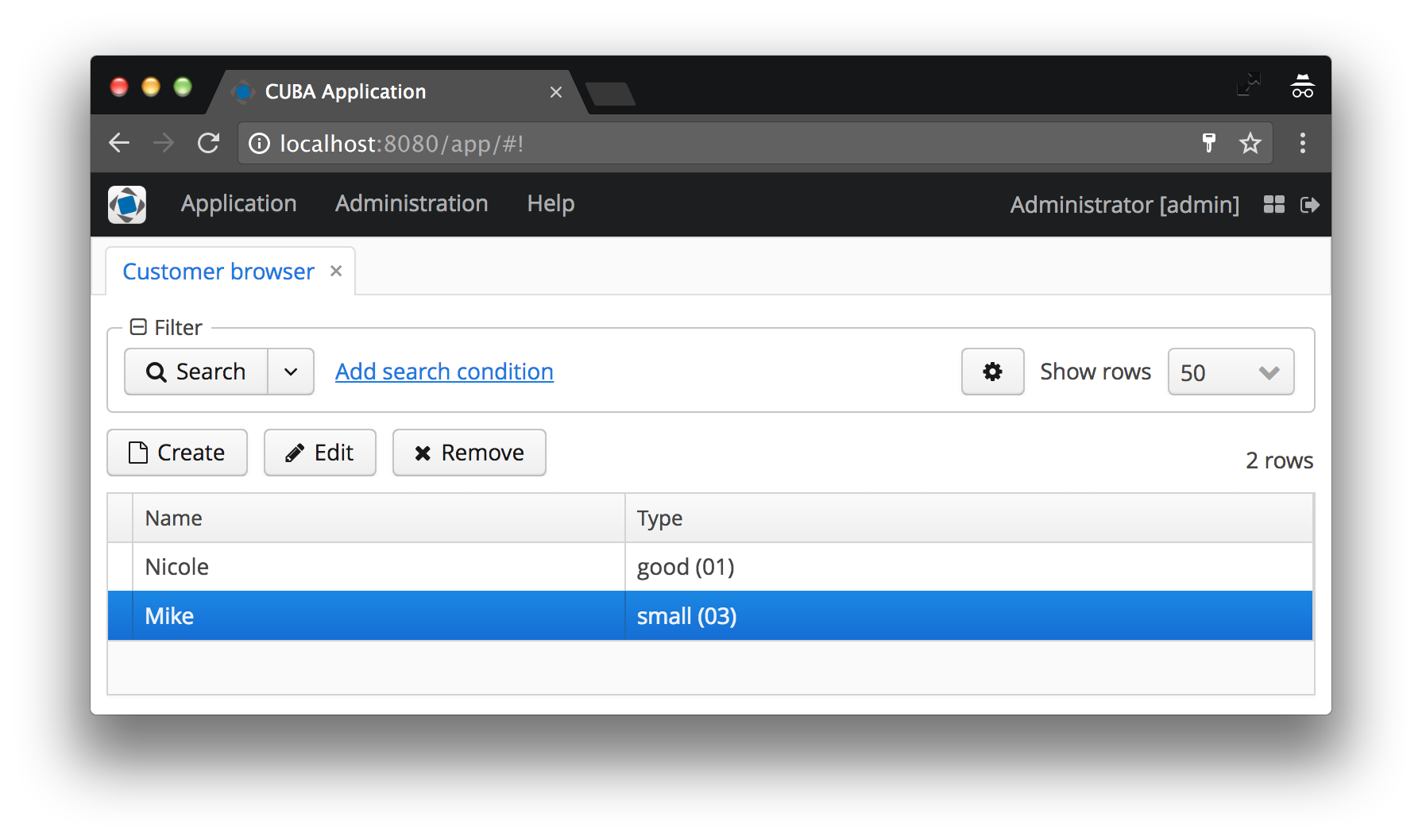
The instance name defines the attributes of the minimum view.
The second thing that affects the NamePattern annotation: all attributes specified after the vertical bar automatically form the _minimal view. At first glance, this seems obvious, because the data in some form must be displayed in the UI, which means that they must first be loaded from the database. Although, to be honest, I think about this fact infrequently.
It is important to note here that the minimum representation, when compared with the local one, may contain references to other entities. For example, for the buyer from the example above, I set the instance name, which includes one local attribute of the Customer entity ( name) and one reference attribute ( type):
@NamePattern("%s - %s|name,type")The minimum representation can be used recursively: (Customer [Instance Name] -> CustomerType [Instance Name])
Translator's note: since the publication of the article, another system view appeared - _baseview, which includes all local non-system attributes and attributes specified in the @NamePattern annotation (that is, in fact, _minimal+ _local).
Conclusion
In conclusion, summarize the most important topic. Thanks to the views, in CUBA we can clearly designate what should be loaded from the database. Views determine what will be loaded in a greedy way, while most other frameworks silently perform a lazy load.
Submissions may seem like a cumbersome mechanism, but in the long run, they pay off.
Hopefully, I’ve got an easy way to explain what these mysterious views really are. Of course, there are more advanced scenarios for their use, as well as pitfalls in working with ideas in general and with minimal ideas in particular, but I'll write about this sometime in a separate post.