Server insurance company refactoring: when there is less physical space than data

Insurance - the third after banks and mobile operators, consumers of "heavy" IT-iron. At the time the work began, the situation was this: in the office of one company there was their central server room (resembling a small data center machine), and in general, everything worked fine in it.
The problem was that the place under the racks (and in the racks themselves) in the server room ended 2 years ago. There was a place in the other two data centers, but not here.
The second problem is that the main production base lay on 149 volumes, physically - like Swiss cheese in servers. This was due to the fact that when it was required to increase it, they found the first free hole in the physical disks and shoved it there. Between the database volumes there could be databases of other projects, software, various temporary files, and so on. In general, it was necessary to restore order.
Another interesting feature - when new data appeared, a new volume (LUN) for them was required. They cut him, and he immediately became a bottleneck. The explanation is very simple - in the combat base the most loaded place is just the new data. And when they are physically located on one disk, its maximum read / write speed limits, in fact, the entire system.
The options were as follows:
• Upgrade existing arrays (considered: expensive and inefficient, nowhere to put);
• Transition to a new generation of the same arrays (high cost for maintenance, constant tuning);
• Search for an alternative solution (flash miscalculation and tests).
Changes
We decided to start with a small piece of data, a separate subproject with its own base. Test on it, and then slowly and smoothly move to a new system. Naturally, everything worked there before the start of work. I just wanted it to work faster and more correctly. This data lay on the Symmetrix DMX-3.
We brought 3 units of Violin 6264 and started to shaman. To begin with, they sat down with oracleists for the optimal physical structure of the base. Taking into account common sense, OS features and the architecture of the base, we decided that 27 volumes were needed instead of 149. Later, 2 more were cut, it turned out 29. At the same time, by the way, we estimated how many empty spaces there were in the DMX - because if there is not enough empty space between the volumes, to chop something new, it is simply skipped. As a result, about 15% of the free space was spent on such “gaps” between independent pieces of data.
Of course, this has not yet been optimized in terms of performance. On DMX, one volume could lie on 7 physical disks. In Violin, due to the architecture of the controller itself and the factory data placement algorithms, the LUN is spread across the entire storage, which allows you to get maximum performance, even if the threshing servers decide to cling to one specific section in a couple of gigabytes in size.
Clearly, I had to agree on a simple one. Sometimes there is no way out, it is necessary to make men's decisions. But much later, another larger database was made through standby - the main database is copied, then half an hour only reads, then again the ability to record.
They doused the base late Saturday night, changed the structure, copied the data, brought it to the new hardware. Made measurements, everything is ok. Raised in production - it works, and it works, in general, well, but not as fast as we expected. In the sense that the full storage resources were not used.
We began to profile flows - it turned out that the calculation servers themselves became a bottleneck. Previously, they waited for a response from the storage, but began to thresh to the fullest, despite the fact that the storage system can give more. As a result, the customer was very impressed and bought 2 new “boxes” - one for this base, the second - immediately “for growth” under the main one.
With the new server they got what they wanted. The test is over, the result is good, the customer thinks about scaling further, and is slowly and calmly purchased with iron in steps.
What is nice, the problems with the architecture of the base were solved, and the issue of growth in speed-place, and the problem of physical space in the server room, and the issue of power, which would arise next year. It was a little pity to remove the once-high DMX, suitable for the third year of operation, but this is the fate of all the iron. Perhaps he will find his new life elsewhere.
Why Violin?
Habr's favorite question is why such a cosmically expensive iron. Yes, Violin, like any "real" (in the sense, not from the shelves of SSD) arrays without an overhead HDD technology is very expensive per unit. The question is hundreds of thousands of dollars for the whole system. On the other hand, here the story is this - if you can afford a flash array on serious data, you can definitely afford Violin, because in the future it pays off very well. Installing is expensive - operating profitably.
Naturally, there are cheaper solutions, but for our task there were a couple more important requirements:
- 24x7 base availability. The piece that we took for the test is the primary analytics of insurance cases. Roughly speaking, this is an estimate of the coefficients, which is not needed in real time. Got data, grind, updated formulas. It can be extinguished and stopped if necessary. Actually, at the peak of the load on the main base, priority was given to her, and this part of the calculations was inhibited. But the military base cannot be extinguished in any case, and it should always work always. Even a couple of minutes of downtime can cost a couple of million rubles. Therefore - only a high end.
- I really need the right support with a good SLA. In such systems, duplication is always used, and the failure of the second circuit is considered a serious accident. The base and services are switched, but you need to go and repair immediately, because if the equipment of the reserve also falls, this is the finish. From here - spare parts warehouses in Moscow, competent engineers, guarantees that someone will come and decide. In general, as usual. For example, here is the story of my colleagues serving Dell servers.
Further
The stages were as follows:
- Miscalculations and analysis (especially important issues were that actual operating costs after implementation were low).
- Testing with us.
- Buying the first array for OLAP.
- Wow! Oracle feels at least 2 times better; no specialists are needed to accompany it.
- We are waiting for six months. Within six months of work does not require attention.
- Once again, consider the case. 1 TB cost is lower than high-end solutions.
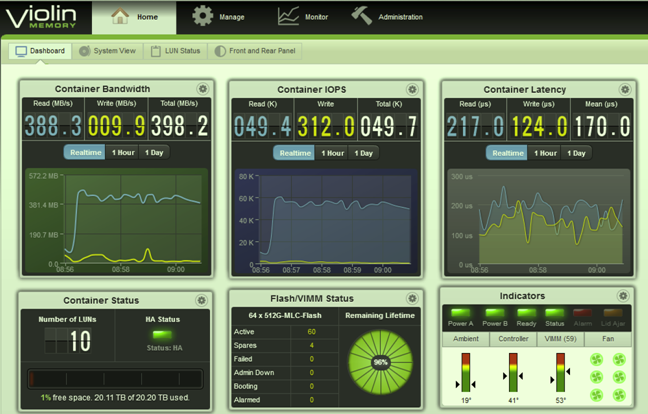
Violin GUI


An application for collecting Oracle database performance statistics
Six months after the test, they began to upgrade the second section. There was a competition, again the victory of our decision with Violin, implementation. As far as I know, the customer was still considered VNX and Hitachi, plus there were mixed systems. Violin turned out to be the cheapest despite the fact that it is also a complete flash. There are still many old storage systems in the server room, but everything important and live is already on the flash.

As you can see, the example is interesting. If you want me to consider approximately the case as a competition only for Violin - write to VBolotnov@croc.ru, I’ll say whether it makes sense to try to optimize in this way in your situation.