HP Vertica: Big Data Analysis Database Engine
- Transfer
 One of the problems of modern business is an overabundance of data - a huge amount of information is scattered across different storages, databases, file servers, etc. There is a lot of information, but decisions need to be taken promptly.
One of the problems of modern business is an overabundance of data - a huge amount of information is scattered across different storages, databases, file servers, etc. There is a lot of information, but decisions need to be taken promptly. Tools for working with such big data do not keep up with their growth. Among these problems:
- a high proportion of manual labor,
- the inability to implement analysis in real time,
- low search accuracy and lack of consistency,
- inefficient processing of unstructured information.
The solution may be the specialized HP Vertica database, designed to analyze big data in real time, working much faster than traditional DBMSs.
Work with data
HP Vertica shows the best results in storing and compressing data because it uses columns instead of rows. Using cluster technologies allows linearly increasing system performance by connecting more resources on the fly, reducing storage and reducing search time. Storing data by columns makes it possible to read from the disks not the entire record, but only the necessary fields involved in the request.
The data in the columns is compressed by recording the number of repetitions along with the field value, delta coding of sequential values and LZO Lempel – Ziv – Oberhumer compression for columns with a large number of unique values and unsorted columns. In addition, special compression algorithms are used for floating point numbers, dates, and a number of other field types. All this allows us to provide a degree of information compression of over 90%. An important aspect is the ability in most cases to perform data operations without decoding, which not only reduces the required storage capacity and the number of disk accesses, but also reduces the load on processors and memory.

The acceleration of processing a large number of parallel queries is also carried out through the use of different sorting orders in different copies of columns in different projections, which are automatically selected.
Aggressive compression allows you to store multiple copies of the same columns in different "projections" of the database, which are sets of columns contained together. It is possible to store not only various copies on different disks, but also the division of the "projection" by the value of one of the fields into segments located and processed on different machines.
To work with already accumulated data, Vertica supports SQL and is equipped with a standard SQL interface (ANSI SQL-99), which has extensions for working with analytical queries. The platform is compatible with data cleansing and reporting mechanisms, as well as with business intelligence solutions from Cognos, Informatica, Business Objects and SAS. This facilitates the transfer of databases and the use of other analytical applications that have a standard SQL interface, ODBC, JDBC, or ADO.NET connectors.
Analytical “crane”
In August 2014, a significant updated version of HP Vertica 7.1 was released, which in the continuation of the tradition of large construction was called Dragline - “Scraper Excavator”. The main innovation of this version is:
- support for direct work with unstructured data,
- text analysis,
- geo-spatial analytics,
- improved workload management,
- support for projection aggregates and much more.
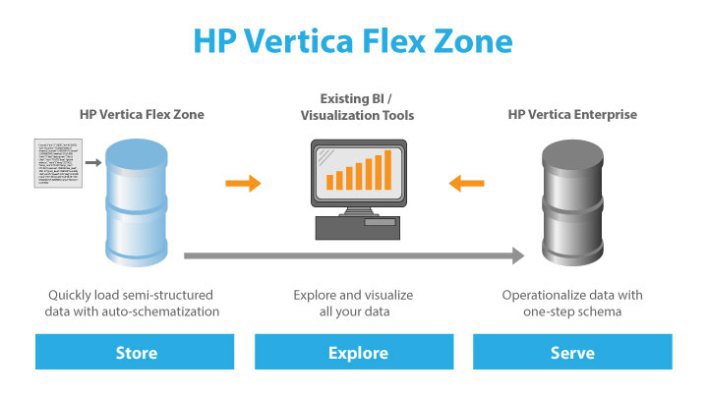
HP Vertica 7 has a dedicated Flex Zone storage and processing area for unstructured data. It makes it possible to create Flex tables, load information from CSV, JSON and other files into them and execute queries against them, combining this data in queries with Vertica relational tables. The data in these tables is stored on the cluster nodes in a special format, but according to the same principles as the relational database data. Unstructured data can be compressed, mirrored, and segmented.
The advantage of Flex Zone is that it is not an external solution integrated with Vertica, but rather an implementation of native support for unstructured data. This provides a guarantee of the speed of work during hybrid processing in queries using tables of structured and unstructured data.

Clustering capabilities
Fault tolerance of HP Vertica is provided with the special mechanism of creation of copies of data (K-Safety). The mechanism guarantees the most affordable level of fault tolerance in 24x7x365 mode. The cluster is able to withstand failures of several nodes without stopping the execution of requests. The main data segment and its copy are stored on the K nodes of the cluster. If any nodes fail, the system continues to function using copies of segments. Access to this data is automatic. To replace a failed node, the original data is restored from copies of segments that are stored on healthy nodes.
In addition, clustering allows you to proportionally increase productivity and provide not only scaling, but also fault tolerance. Since the cluster does not contain shared resources, no time is spent waiting for their locks and, therefore, there is no need for distributed lock management tools. The Vertica architecture also provides for the rejection of journaling, as journaling often becomes a bottleneck when loading data. Instead, the system supports multiple copies of columns on different nodes of the cluster.
Since real-time analytics is most often needed, Vertica has a special mechanism for continuously loading data without sacrificing read speed. Data is written to a special area of the WOS memory (Write Optimized Store), and reading is done from disks from the storage area of the ROS (Read Optimized Store) type, and the information in WOS is not sorted or indexed. At the same time, information located in WOS is available for receiving query results even before transferring to ROS.
Transferring records from WOS to ROS takes place in large blocks, automatically and asynchronously using the special Tuple Mover record transfer process. Since this process operates entirely throughout WOS, moving records can be very efficient, while sorting many records and transferring them to disk in batch mode.

Advantages of using
Statistics of already implemented platforms show that work with databases is accelerated on average up to 1000 times. The average information compression ratio compared to other systems is 10: 1, and data loading for further analysis is 10 times faster and comparable to a mode close to real time.
Unlike the solutions available on the market, the HP Vertica has no binding to a specific hardware platform - the user chooses the required equipment. It is only worth noting that there are recommended configurations.
Since Vertica was originally designed to work in a horizontally scalable environment and licensed not by processors, but by the amount of data loaded into the system, it is easy to integrate it into cloud environments, for example, in VMware vSphere or Amazon Elastic Compute Cloud. The advantage of a virtualized environment is the speed of deployment, since all nodes in the Vertica complex are the same and the finished image of the virtual machine is instantly installed on existing equipment.
HP Vertica comes with Database Designer software to automatically customize your system. Vertica has simple integration tools and reporting capabilities through SQL, JDBC, ODBC, ADO.NET. There is also a free version of Vertica Community Edition, which allows analysts to create their own applications and share experiences with the Vertica community.
Life example
One of the largest installations of the Vertica DBMS at the moment is made in a company that develops network games for social networks. The system serves about 200 million active players, up to 40 million playing simultaneously. The daily data stream is 3 TB. 200 cars in the cluster provide instant analysis and provide players with information in the form of recommendations. The installation works in 24x7x365 mode without “windows” for downloading data, analyzing real-time incoming and historical data. However, this is far from the limit. The largest client is Facebook with a data volume of several petabytes and a cluster of several hundred nodes. The speed of downloading data to the cluster today is 40 Tb / hour.
We distribute HP solutions in Ukraine, Georgia and Tajikistan. Prices, questions - write: abo@muk.ua, or in PM.
Catalog of all solutions and services of the distributor of MUK
Hewlett-Packard authorized training courses
Upcoming Hewlett-Packard courses:
February 16-17, 2015, (Kiev, UMUK UC) - Infrastructure management through HP OneView
February 11-13, 2015 (Kiev, UUK MUK) - HP BladeSystem Virtual Connect
February 23-24, 2015 (Kiev, UT MUK) - Implementing MSA 2000 Storage Solutions
MUK-Service - all types of IT repair: warranty, non-warranty repairs, sale of spare parts, contract service