The most effective in terms of speed - the server circuit, for the client-server 1C 8.x
Preface I was
constantly confronted with the statements of IT specialists: “the network is 20% loaded ... the processors are 50% ... there are few queues for disks ... So the network and servers are coping ... see the code in 1C there is a problem exclusively”.
In fact, the following happened (the 1C server and SQL were separated into different computers): the network was practically used to the maximum ( these " 20% load of the network interface " = "20% useful data" + "80% loss on official processing" ). And accordingly, due to the small width of the “useful” data exchange channel, the SQL server with “Server 1C” was constantly waiting for each other, which led to a small utilization of CPU and disk system resources.
Introduction: First, I want to focus on what is 1C platform ?.
So start with the main 1C - built on the ORM (Object Relational Mapping) is a system and a programmer it does not work directly with a relational representation, and with objects.
ru.wikipedia.org/wiki/ORM
Programmer in 1C environment - writes object logic, and the platform itself is responsible for assembling / disassembling and writing objects in a “flat view” according to the database tables.
The main "+" and "-" from the point of view of ORM:
"+" The programmer in the ORM environment gets an advantage in the speed of application development due to the reduction in the amount of code and its simplicity compared to exclusively relational program code (example SQL queries). It is also freed from writing code that works directly with entries in the tables of the Relational DBMS.
"-" Difficulties for the creators of ORM "platforms" and performance problems:
* 1 “Clarification”. Despite the fact that 1C 8.x allows you to work with relational-like code (read-only) in the 1C “Request” object, it is still not a direct one-to-one query to data storage tables translated into a relational DBMS, but before In total, the "Object Request" is also not passing the stage of assembling the disassembly of objects. Therefore, often instead of many thousand lower case “Object queries” - the most optimal in terms of code speed and development speed - write object-less non-relational-like code.
Chapter 1: Consider the client-server model 1C 8.x
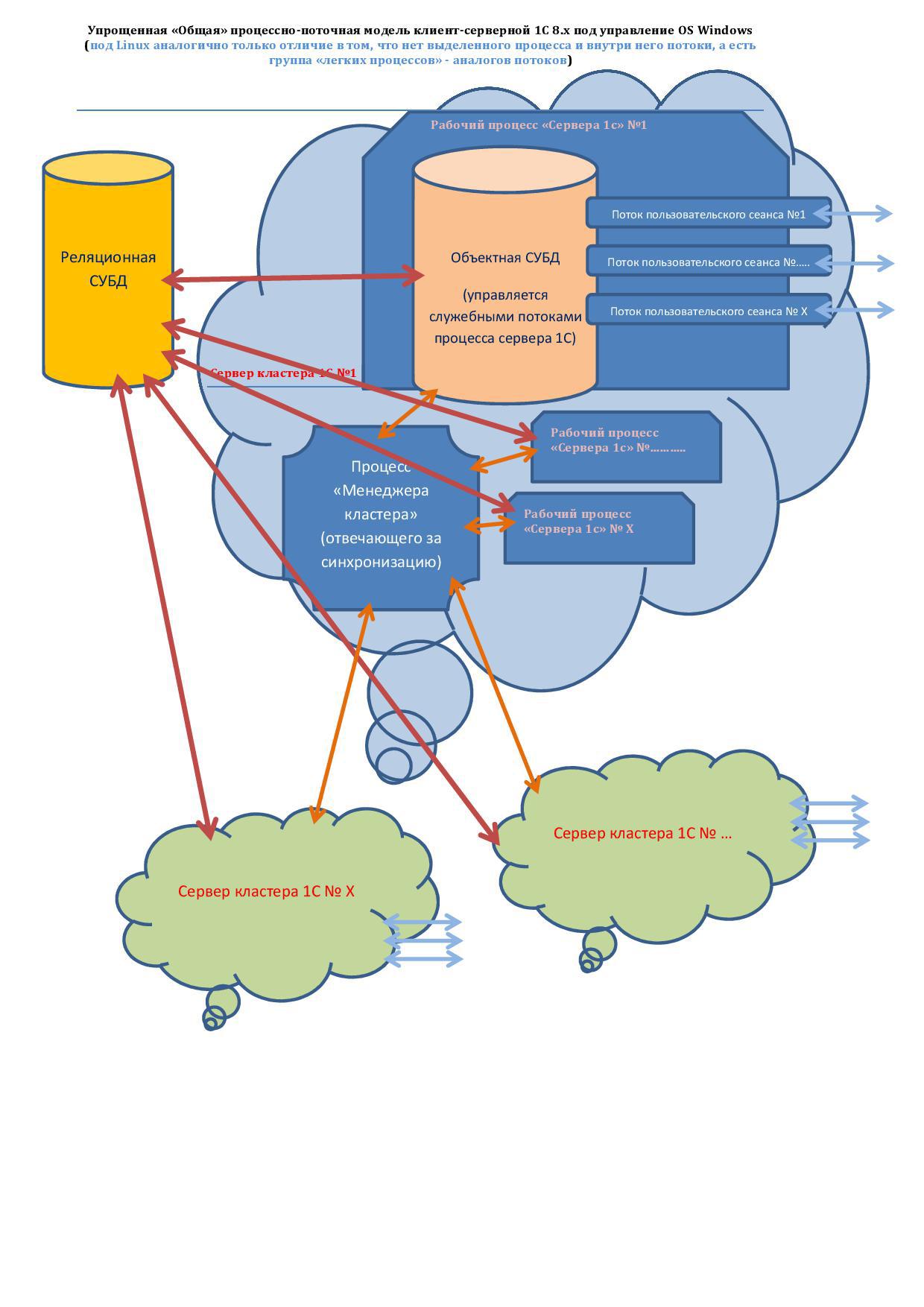
I ’ll note the main bottlenecks that affect performance:
1) The first bottleneck is the communication medium for data transfer .
In the figure, arrows show the data exchange flows, where “red” is the Relational DBMS <-> Object DBMS, “orange” is the synchronization between the Object DBMS.
Because when using separate servers for DBMS and 1C clusters - the communication environment is network connections - there are significant delays in the transfer of data in numerous small portions - both because of the latency of the physical implementation of the interfaces and because of the latency of the nodes in this network.
Consider the Ethernet Gigabit network standard as an example ( data rate dependence chart ... below )
using the 1C Server with MS SQL as an example ( the default size of communication packets is 4 kb) :
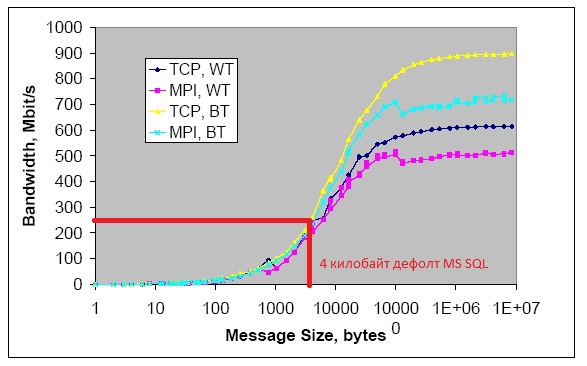
The graph shows that when using DATA packets = 4 kb, the throughput of the considered network is only 250 megabits / s. (as correctly noted in the commentary to the publication: these are not protocol packets, for example, of the TCP level , but DATA packets that generate the applications participating in the exchange)
...
From practice: such a separation into Two separate
MS SQL servers (server No. 1) <- Ethernet Gigabit - -> "server 1C" (server №1)
lost on the platform speed
by 50% the MS version of the SQL (server №1) <- Shared memory (without a network via a memory section) ---> "The server 1C" (server №1 ) ... and this is already "in one highly loaded user session"
2) The bottleneck is the number of individual computers of “1C clusters” , the more they are, the greater the cost of synchronization and, as a consequence, a decrease in system performance.
3) The bottleneck is the number of individual server processes 1s , the more they are, the greater the cost of synchronizing them ... But here it is most likely necessary to find a "middle ground" - to ensure stability. 2 *
2 * “Clarification” - for MS Windows there is such a rule:
Processes are more expensive than threads, which means the following in practice: the exchange rate between two flows within one process is much higher, the exchange rate between flows located in different processes.
Therefore, for example, “File 1C 8.x” always exceeds the speed of single-user operation of the platform in the client-server version. Everything is simple because in the case of “File 1C 8.x”, the flow of the “Relational DBMS” communicates with the flow of the “Object DBMS” within one single process.
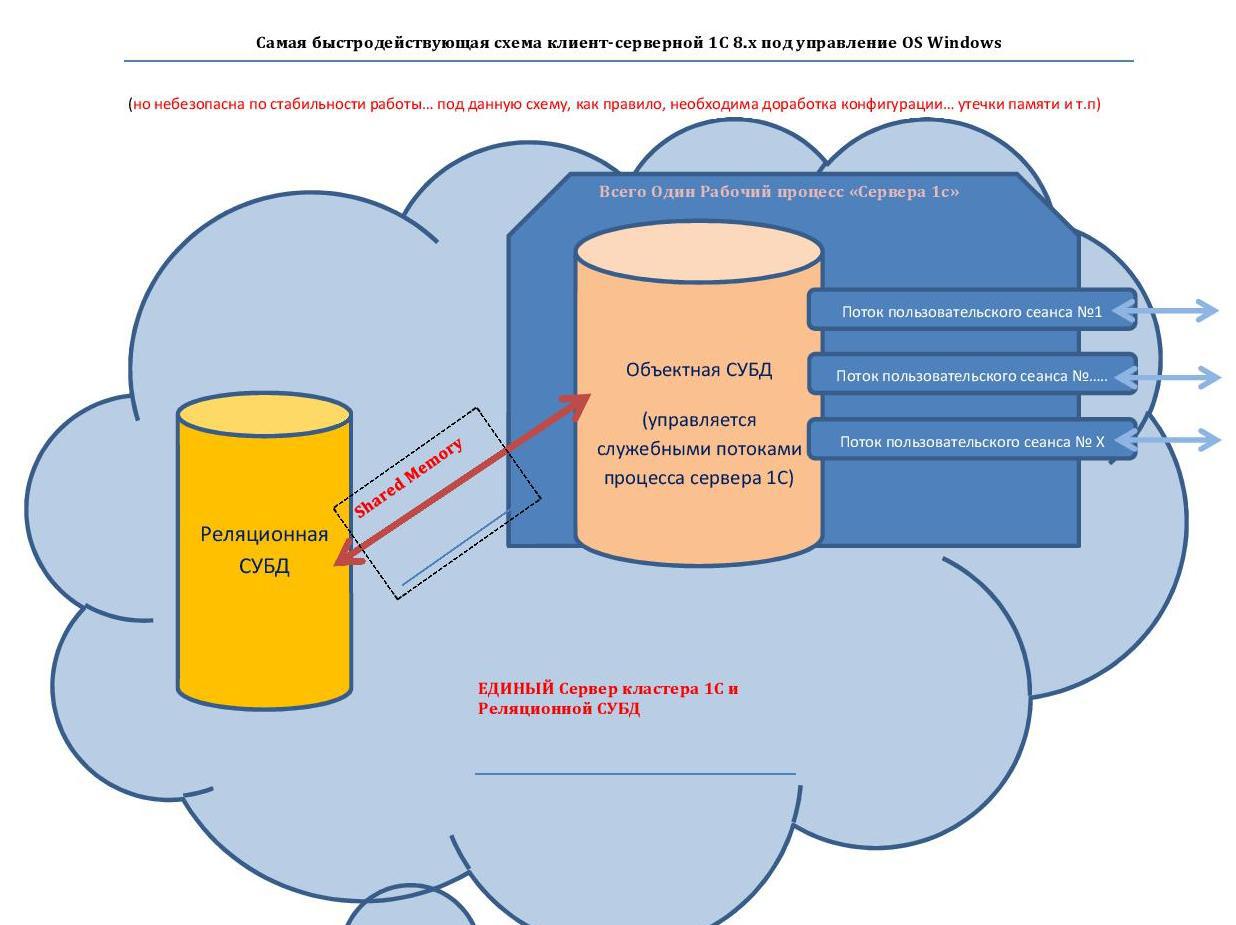
4) Bottleneck - single-threaded user session , because each individual one - the user session is not parallelized by the platform for several, then its operation is limited to using the resources of one core of the CPU => therefore, the maximum speed of each core is desirable, in this case, the performance of the 1C platform, for example, on a 10-core CPU of 1 GHz, will be significantly inferior to performance platforms on a 4-core 3 GHz CPU - naturally up to a certain number of threads.
Chapter 2 (Summary):Consider non-scalable and scalable options - the most effective schemes for the platform 1s 8.x. for OS Windows (I suppose the situation is similar for Linux)
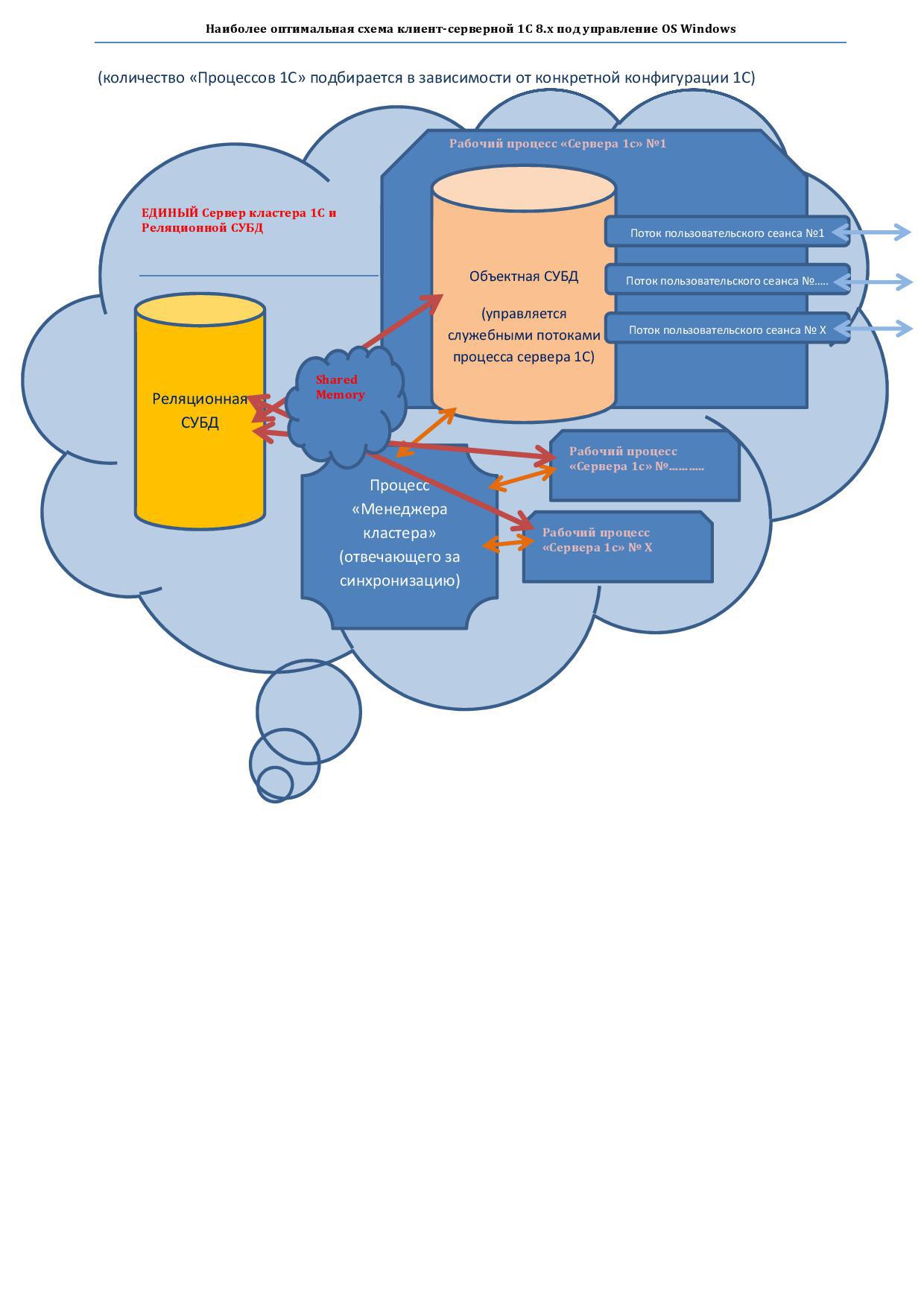
1-Option (not scalable). Based on 100 “highly loaded user sessions”
1) an ordinary 2-socket server with 4-core 3 GHz CPUs is effective.
2) fast disk system on SSD
3) MS SQL <- Shared memory -> "Server 1C"
2-Option (scalable). starting with 100 “heavily loaded user sessions” and more ....
Here it’s most logical to follow the path of the German 1s “Sap HANA”))
To assemble a modular “Super Computer” from SGI - consisting of “blades” on 2 socket motherboards, each blade is connected to each other by a complex topology of ultra-fast interconnect based on NUMA chips, and everything is under the control of a single OS. Those. programs inside such a server, by definition, have access to the resources of any “blade”.
1) add “blades” at the required load ... at the rate of about one “blade” per 100 users.
2) fast disk system on SSD
3) MS SQL <- Shared memory -> "Server 1C"
constantly confronted with the statements of IT specialists: “the network is 20% loaded ... the processors are 50% ... there are few queues for disks ... So the network and servers are coping ... see the code in 1C there is a problem exclusively”.
In fact, the following happened (the 1C server and SQL were separated into different computers): the network was practically used to the maximum ( these " 20% load of the network interface " = "20% useful data" + "80% loss on official processing" ). And accordingly, due to the small width of the “useful” data exchange channel, the SQL server with “Server 1C” was constantly waiting for each other, which led to a small utilization of CPU and disk system resources.
Introduction: First, I want to focus on what is 1C platform ?.
So start with the main 1C - built on the ORM (Object Relational Mapping) is a system and a programmer it does not work directly with a relational representation, and with objects.
ru.wikipedia.org/wiki/ORM
Programmer in 1C environment - writes object logic, and the platform itself is responsible for assembling / disassembling and writing objects in a “flat view” according to the database tables.
The main "+" and "-" from the point of view of ORM:
"+" The programmer in the ORM environment gets an advantage in the speed of application development due to the reduction in the amount of code and its simplicity compared to exclusively relational program code (example SQL queries). It is also freed from writing code that works directly with entries in the tables of the Relational DBMS.
"-" Difficulties for the creators of ORM "platforms" and performance problems:
Using a relational database to store object-oriented data leads to a “semantic gap”, forcing programmers to write software that must be able to process data in an object-oriented manner and be able to save this data in a relational form. This constant need for conversion between two different forms of data not only greatly reduces performance, but also creates difficulties for programmers, since both forms of data impose restrictions on each other.
* 1 “Clarification”. Despite the fact that 1C 8.x allows you to work with relational-like code (read-only) in the 1C “Request” object, it is still not a direct one-to-one query to data storage tables translated into a relational DBMS, but before In total, the "Object Request" is also not passing the stage of assembling the disassembly of objects. Therefore, often instead of many thousand lower case “Object queries” - the most optimal in terms of code speed and development speed - write object-less non-relational-like code.
Chapter 1: Consider the client-server model 1C 8.x
I ’ll note the main bottlenecks that affect performance:
1) The first bottleneck is the communication medium for data transfer .
In the figure, arrows show the data exchange flows, where “red” is the Relational DBMS <-> Object DBMS, “orange” is the synchronization between the Object DBMS.
Because when using separate servers for DBMS and 1C clusters - the communication environment is network connections - there are significant delays in the transfer of data in numerous small portions - both because of the latency of the physical implementation of the interfaces and because of the latency of the nodes in this network.
Consider the Ethernet Gigabit network standard as an example ( data rate dependence chart ... below )
using the 1C Server with MS SQL as an example ( the default size of communication packets is 4 kb) :
The graph shows that when using DATA packets = 4 kb, the throughput of the considered network is only 250 megabits / s. (as correctly noted in the commentary to the publication: these are not protocol packets, for example, of the TCP level , but DATA packets that generate the applications participating in the exchange)
...
From practice: such a separation into Two separate
MS SQL servers (server No. 1) <- Ethernet Gigabit - -> "server 1C" (server №1)
lost on the platform speed
by 50% the MS version of the SQL (server №1) <- Shared memory (without a network via a memory section) ---> "The server 1C" (server №1 ) ... and this is already "in one highly loaded user session"
2) The bottleneck is the number of individual computers of “1C clusters” , the more they are, the greater the cost of synchronization and, as a consequence, a decrease in system performance.
3) The bottleneck is the number of individual server processes 1s , the more they are, the greater the cost of synchronizing them ... But here it is most likely necessary to find a "middle ground" - to ensure stability. 2 *
2 * “Clarification” - for MS Windows there is such a rule:
Processes are more expensive than threads, which means the following in practice: the exchange rate between two flows within one process is much higher, the exchange rate between flows located in different processes.
Therefore, for example, “File 1C 8.x” always exceeds the speed of single-user operation of the platform in the client-server version. Everything is simple because in the case of “File 1C 8.x”, the flow of the “Relational DBMS” communicates with the flow of the “Object DBMS” within one single process.
4) Bottleneck - single-threaded user session , because each individual one - the user session is not parallelized by the platform for several, then its operation is limited to using the resources of one core of the CPU => therefore, the maximum speed of each core is desirable, in this case, the performance of the 1C platform, for example, on a 10-core CPU of 1 GHz, will be significantly inferior to performance platforms on a 4-core 3 GHz CPU - naturally up to a certain number of threads.
Chapter 2 (Summary):Consider non-scalable and scalable options - the most effective schemes for the platform 1s 8.x. for OS Windows (I suppose the situation is similar for Linux)
1-Option (not scalable). Based on 100 “highly loaded user sessions”
1) an ordinary 2-socket server with 4-core 3 GHz CPUs is effective.
2) fast disk system on SSD
3) MS SQL <- Shared memory -> "Server 1C"
2-Option (scalable). starting with 100 “heavily loaded user sessions” and more ....
Here it’s most logical to follow the path of the German 1s “Sap HANA”))
To assemble a modular “Super Computer” from SGI - consisting of “blades” on 2 socket motherboards, each blade is connected to each other by a complex topology of ultra-fast interconnect based on NUMA chips, and everything is under the control of a single OS. Those. programs inside such a server, by definition, have access to the resources of any “blade”.
1) add “blades” at the required load ... at the rate of about one “blade” per 100 users.
2) fast disk system on SSD
3) MS SQL <- Shared memory -> "Server 1C"