Once Again About Hyper-Threading
There was a time when it was necessary to evaluate memory performance in the context of Hyper-threading technology . We conclude that its influence is not always positive. When the quantum of free time appeared, there was a desire to continue research and consider the processes taking place to the accuracy of machine clocks and bits, using software of our own design.
The object of experimentation is the ASUS N750JK laptop with an Intel Core i7-4700HQ processor. The clock frequency of 2.4GHz, increased in Intel Turbo Boost mode to 3.4GHz. Installed 16 gigabytes of RAM DDR3-1600 (PC3-12800), working in dual channel mode. Operating System - Microsoft Windows 8.1 64 bit.
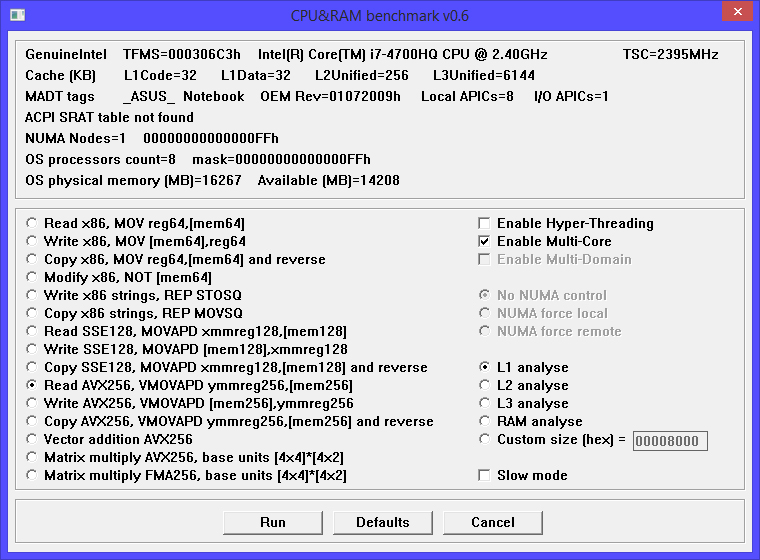
Fig. 1 Configuration of the studied platform.
The processor of the platform under study contains 4 cores, which, when Hyper-Threading technology is turned on, provides hardware support for 8 threads or logical processors. The platform firmware transmits this information to the operating system via the MADT (Multiple APIC Description Table) ACPI table. Since the platform contains only one RAM controller, there is no SRAT (System Resource Affinity Table) table declaring the proximity of processor cores to memory controllers. Obviously, the laptop under study is not a NUMA platform, but the operating system, for the purpose of unification, considers it as a NUMA system with one domain, as evidenced by the NUMA line Nodes = 1. The fact that is important for our experiments is that the cache of the first level data has a size of 32 kilobytes for each of the four cores. Two logical processors sharing the same core share the first and second level cache memory.
We will investigate the dependence of the reading speed of a data block on its size. To do this, we choose the most efficient method, namely reading 256-bit operands using the AVX-instruction VMOVAPD. On the graphs, the x-axis shows the block size, the y-axis shows the read speed. In the vicinity of the X point, corresponding to the size of the cache in the first level, we expect to see the inflection point, since the performance should drop after the processed block goes beyond the cache. In our test, in the case of multi-threaded processing, each of 16 initiated threads works with a separate address range. To control Hyper-Threading technology within the application, each thread uses the SetThreadAffinityMask API function, which defines a mask in which one logical bit corresponds to each logical processor. A single bit value allows the use of a given processor by a given thread, a zero value prohibits it. For 8 logical processors of the platform under study, mask 11111111b allows using all processors (Hyper-Threading is enabled), mask 01010101b allows using one logical processor in each core (Hyper-Threading is disabled).
The following abbreviations are used on the charts:
MBPS (Megabytes per Second) - block read speed in megabytes per second ;
CPI (Clocks per Instruction) - the number of measures per instruction ;
TSC (Time Stamp Counter) - processor clock counter .
Note: The clock frequency of the TSC register may not match the processor clock speed when operating in Turbo Boost mode. This must be taken into account when interpreting the results.
On the right side of the graphs, a hexadecimal dump of instructions representing the body of the cycle of the target operation performed in each of the program flows, or the first 128 bytes of this code is visualized.
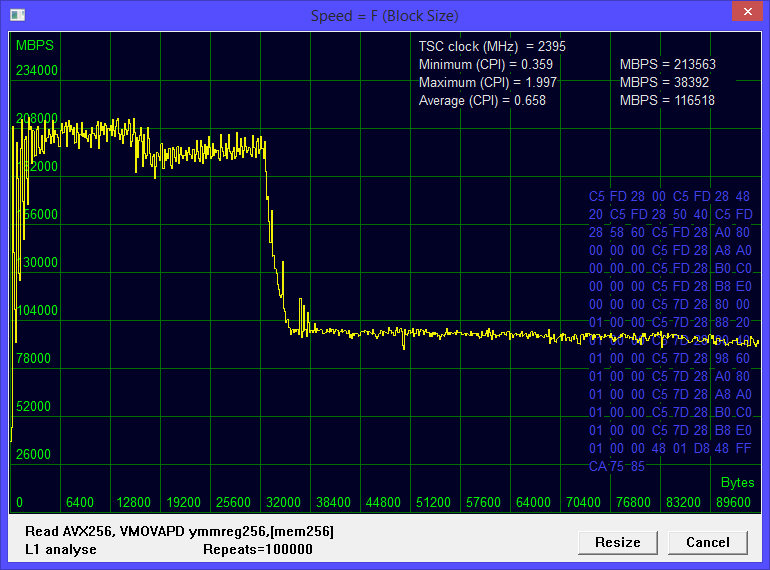
Fig. 2 Reading in one stream.
Maximum speed 213563 megabytes per second. An inflection point occurs at a block size of about 32 kilobytes.
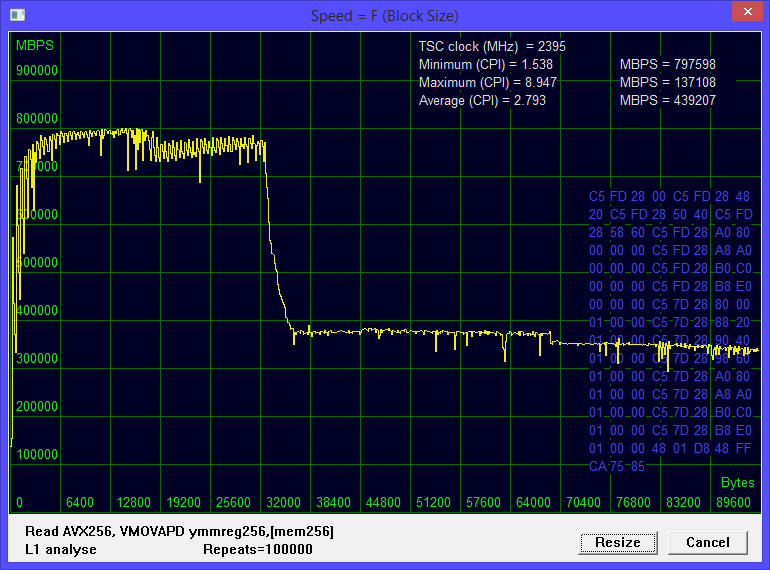
Figure 3 Reading by sixteen threads. The number of logical processors used is four;
Hyper-Threading is turned off. The maximum speed is 797598 megabytes per second. An inflection point occurs at a block size of about 32 kilobytes. As expected, compared with reading a single thread, the speed increased by about 4 times, in terms of the number of working cores.
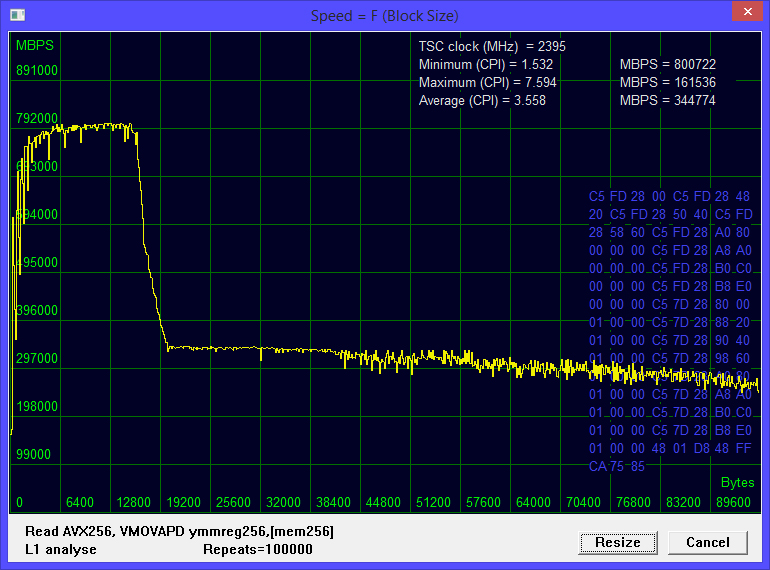
Figure 4 Reading by sixteen threads. The number of logical processors used is eight
Hyper-Threading enabled. The maximum speed of 800,722 megabytes per second, as a result of the inclusion of Hyper-Threading almost did not increase. The big minus - the inflection point occurs at a block size of about 16 kilobytes. Enabling Hyper-Threading slightly increased the maximum speed, but the speed drop now occurs when the block size is half as large - about 16 kilobytes, so the average speed has dropped significantly. This is not surprising, each core has its own cache of the first level, while the logical processors of one core share it.
The investigated operation scales quite well on a multi-core processor. Reasons - each core contains its own cache of the first and second levels, the size of the target block is comparable to the size of the cache, and each of the threads works with its own range of addresses. For academic purposes, we created such conditions in a synthetic test, realizing that real applications are usually far from ideal optimization. But the inclusion of Hyper-Threading, even under these conditions, had a negative effect, with a small increase in peak speed, there is a significant loss in processing speed of blocks whose size is in the range from 16 to 32 kilobytes.
Research platform
The object of experimentation is the ASUS N750JK laptop with an Intel Core i7-4700HQ processor. The clock frequency of 2.4GHz, increased in Intel Turbo Boost mode to 3.4GHz. Installed 16 gigabytes of RAM DDR3-1600 (PC3-12800), working in dual channel mode. Operating System - Microsoft Windows 8.1 64 bit.
Fig. 1 Configuration of the studied platform.
The processor of the platform under study contains 4 cores, which, when Hyper-Threading technology is turned on, provides hardware support for 8 threads or logical processors. The platform firmware transmits this information to the operating system via the MADT (Multiple APIC Description Table) ACPI table. Since the platform contains only one RAM controller, there is no SRAT (System Resource Affinity Table) table declaring the proximity of processor cores to memory controllers. Obviously, the laptop under study is not a NUMA platform, but the operating system, for the purpose of unification, considers it as a NUMA system with one domain, as evidenced by the NUMA line Nodes = 1. The fact that is important for our experiments is that the cache of the first level data has a size of 32 kilobytes for each of the four cores. Two logical processors sharing the same core share the first and second level cache memory.
Study operation
We will investigate the dependence of the reading speed of a data block on its size. To do this, we choose the most efficient method, namely reading 256-bit operands using the AVX-instruction VMOVAPD. On the graphs, the x-axis shows the block size, the y-axis shows the read speed. In the vicinity of the X point, corresponding to the size of the cache in the first level, we expect to see the inflection point, since the performance should drop after the processed block goes beyond the cache. In our test, in the case of multi-threaded processing, each of 16 initiated threads works with a separate address range. To control Hyper-Threading technology within the application, each thread uses the SetThreadAffinityMask API function, which defines a mask in which one logical bit corresponds to each logical processor. A single bit value allows the use of a given processor by a given thread, a zero value prohibits it. For 8 logical processors of the platform under study, mask 11111111b allows using all processors (Hyper-Threading is enabled), mask 01010101b allows using one logical processor in each core (Hyper-Threading is disabled).
The following abbreviations are used on the charts:
MBPS (Megabytes per Second) - block read speed in megabytes per second ;
CPI (Clocks per Instruction) - the number of measures per instruction ;
TSC (Time Stamp Counter) - processor clock counter .
Note: The clock frequency of the TSC register may not match the processor clock speed when operating in Turbo Boost mode. This must be taken into account when interpreting the results.
On the right side of the graphs, a hexadecimal dump of instructions representing the body of the cycle of the target operation performed in each of the program flows, or the first 128 bytes of this code is visualized.
Experience No. 1. Single thread
Fig. 2 Reading in one stream.
Maximum speed 213563 megabytes per second. An inflection point occurs at a block size of about 32 kilobytes.
Experience No. 2. 16 threads on 4 processors, Hyper-Threading is turned off
Figure 3 Reading by sixteen threads. The number of logical processors used is four;
Hyper-Threading is turned off. The maximum speed is 797598 megabytes per second. An inflection point occurs at a block size of about 32 kilobytes. As expected, compared with reading a single thread, the speed increased by about 4 times, in terms of the number of working cores.
Experience No. 3. 16 threads on 8 processors, Hyper-Threading enabled
Figure 4 Reading by sixteen threads. The number of logical processors used is eight
Hyper-Threading enabled. The maximum speed of 800,722 megabytes per second, as a result of the inclusion of Hyper-Threading almost did not increase. The big minus - the inflection point occurs at a block size of about 16 kilobytes. Enabling Hyper-Threading slightly increased the maximum speed, but the speed drop now occurs when the block size is half as large - about 16 kilobytes, so the average speed has dropped significantly. This is not surprising, each core has its own cache of the first level, while the logical processors of one core share it.
conclusions
The investigated operation scales quite well on a multi-core processor. Reasons - each core contains its own cache of the first and second levels, the size of the target block is comparable to the size of the cache, and each of the threads works with its own range of addresses. For academic purposes, we created such conditions in a synthetic test, realizing that real applications are usually far from ideal optimization. But the inclusion of Hyper-Threading, even under these conditions, had a negative effect, with a small increase in peak speed, there is a significant loss in processing speed of blocks whose size is in the range from 16 to 32 kilobytes.