Scapegoat trees
- Tutorial
 Today we look at a data structure called a Scapegoat tree. “Scapegoat”, who does not know, is translated as “scapegoat”, which makes the literal translation of the name of the structure somehow strange, so we will use the original name. There are a lot of different types of search trees, as you probably know , and all of them are based on the same idea: " But it would be nice to search through an element not only the whole data set in a row, but only some part, preferably the size order log (N) . "
Today we look at a data structure called a Scapegoat tree. “Scapegoat”, who does not know, is translated as “scapegoat”, which makes the literal translation of the name of the structure somehow strange, so we will use the original name. There are a lot of different types of search trees, as you probably know , and all of them are based on the same idea: " But it would be nice to search through an element not only the whole data set in a row, but only some part, preferably the size order log (N) . "To do this, each vertex stores links to its children and some kind of criterion by which it is clear when searching which one of the child vertices should go to. In a logarithmic time, all this will work when the tree is balanced (well, or tends to this) - i.e. when the "height" of each of the subtrees of each vertex is approximately the same. But each tree type has its own balancing methods: “red” markers are stored in the red-black trees at the tops that tell when and how to rebalance the tree, in the AVL trees, the height differences of the children are stored in the vertices, Splay trees are forced to balance change the tree during search operations, etc.
Scapegoat-tree also has its own approach to solving the problem of balancing the tree. As for all other cases, it is not ideal, but it is quite applicable in some situations.
The advantages of Scapegoat-tree include:
- No need to store any additional data at the vertices (which means that we win by memory from red-black, AVL and Cartesian trees)
- No need to rebalance the tree during the search operation (which means we can guarantee the maximum search time O (log N), unlike Splay-trees, where only amortized O (log N) is guaranteed)
- The amortized complexity of O (log N) insert and delete operations is basically the same as other tree types
- When constructing a tree, we choose a certain coefficient of "rigor" α, which allows you to "tune" the tree, making search operations faster by slowing down modification operations or vice versa. You can implement the data structure, and then select the coefficient according to the results of tests on real data and the specifics of using the tree.
The disadvantages include:
- In the worst case, tree modification operations can take O (n) time (the amortized complexity is still O (log N), but there is no protection against “bad” cases).
- You can incorrectly assess the frequency of different operations with the tree and make a mistake with choosing the coefficient α - as a result, frequently used operations will work for a long time, and rarely used ones will work quickly, which is somehow not good.
Let's understand what a Scapegoat tree is and how to perform search, insert and delete operations for it.
The concepts used (square brackets in the notation above mean that we store this value explicitly, which means we can take O (1) in time. Parentheses mean that the value will be calculated in the process, i.e. memory is not wasted, but time to calculate)
- T - so we will denote the tree
- root [T] - root of the tree T
- left [x] - left "son" of vertex x
- right [x] - the right "son" of the vertex x
- brother (x) - brother of vertex x (vertex that has a common parent with x)
- depth (x) - the depth of the vertex x. This is the distance from it to the root (number of ribs)
- height (T) is the depth of the tree T. This is the depth of the deepest top of the tree T
- size (x) is the weight of the vertex x. This is the number of all its child vertices + 1 (she herself)
- size [T] - the size of the tree T. This is the number of vertices in it (root weight)
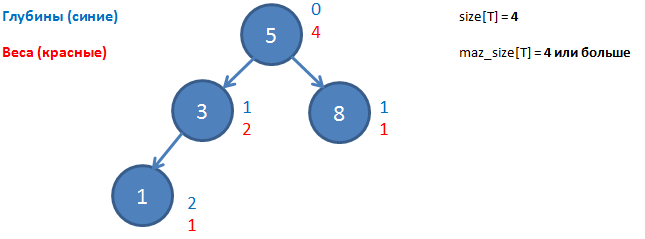
Now we introduce the concepts we need for the Scapegoat tree:
- max_size [T] - maximum tree size. This is the maximum value that size [T] has taken since the last rebalance. If rebalancing has just occurred, then max_size [T] = size [T]
- Coefficient α is a number in the range from [0.5; 1), which determines the required degree of quality of balancing the tree. Some vertex x is called "α-weight-balanced" if the weight of her left son is less than or equal to α * size (x) and the weight of her right son is less than or equal to α * size (x).
size (left [x]) ≤ α * size (x)
size (right [x]) ≤ α * size (x)
Let's try to understand this criterion. If α = 0.5, we require that in the left subtree there are exactly as many vertices as in the right (± 1). Those. in fact, this is a requirement for a perfectly balanced tree. For α> 0.5 we say “ok, let the balancing be not perfect, let one of the subtrees be allowed to have more vertices than the other”. For α = 0.6, one of the subtrees of the vertex x can contain up to 60% of all vertices of the subtree x so that the vertex x is still considered "α-weighted". It is easy to see that with α tending to 1, we actually agree to consider even a regular linked list as “α-balanced by weight”.
Now let's see how normal operations are performed in the Scapegoat tree.
At the beginning of working with a tree, we select the parameter α in the range [0.5; 1). We also start two variables to store the current values of size [T] and max_size [T] and zero them.
Search
So, we have some Scapegoat tree and we want to find an element in it. Since this is a binary search tree, then the search will be standard: we’ll go from the root, compare the vertex with the desired value, if we find it, return it, if the value in the vertex is less, search recursively in the left subtree, if more, in the right subtree. The tree is not modified during the search.
The complexity of the search operation, as you might have guessed, depends on α and is expressed by the formula
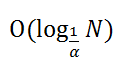
Those. complexity, of course, is logarithmic, only the basis of the logarithm is interesting. With α close to 0.5, we get the binary (or almost binary) logarithm, which means the ideal (or almost perfect) search speed. With α close to unity, the base of the logarithm tends to unity, which means that the overall complexity tends to O (N). Yeah, and no one promised the ideal.
Insert
The insertion of a new element into the Scapegoat tree begins in a classic way: by searching, we look for a place where to hang a new vertex, and then we hang it. It is easy to see that this action could disrupt α-weight balancing for one or more tree vertices. And now begins what gave the name to the data structure: we are looking for a “scapegoat” (Scapegoat peak) - the peak for which the α-balance is lost and its subtree needs to be rebuilt. The peak just inserted, although it’s to blame for the loss of balance, cannot become a “scapegoat” - it does not have “children” yet, which means its balance is perfect. Accordingly, you need to go through the tree from this vertex to the root, recounting the weights for each vertex along the path. If there is a peak along the way,
Along the way, a number of questions arise:
- And how to get from the top “up” to the root? Do we need to keep links to parents?
- Not. Since we came to the place of inserting a new vertex from the root of the tree, we have a stack that contains all the way from the root to the new top. We take parents from it.
- And how to calculate the "weight" of the peak - we do not store it in the peak itself?
- No, we don’t store it. For a new vertex, weight = 1. For its parent, weight = 1 (weight of the new vertex) + 1 (weight of the parent itself) + size (brother (x)).
- Well, ok, but how to calculate size (brother (x))?
- Recursively. Yes, it will take O (size (brother (x))) time. Understanding that in the worst case, we may have to calculate the weight of half a tree - we see the very complexity O (N) in the worst case, which was mentioned at the beginning. But since we bypass the subtree of the α-weight-balanced tree, it can be shown that the amortized complexity of the operation does not exceed O (log N).
- But there may be several peaks for which the α-balance has been violated - what should I do?
- Short answer: you can choose any. The long answer: in the original document describing the data structure, there are a couple of heuristics on how to choose a “specific scapegoat” (that’s the terminology!), But actually they come down to “so we tried this way and that, experiments showed that it’s like that’s better, but we can’t explain why. ”
- And how to rebalance the found Scapegoat peaks?
- There are two ways: trivial and a little trickier.
Trivial rebalancing
- We bypass the entire subtree of the Scapegoat vertex (including its own) with the help of in-order traversal - at the output we get a sorted list (In-order property of traversing the binary search tree).
- We find the median on this segment, suspend it as the root of the subtree.
- For the “left” and “right” subtrees, we repeat the same operation recursively.
It can be seen that this whole thing requires O (size (Scapegoat-vertex)) time and the same amount of memory.
A bit trickier rebalancing
We are unlikely to improve the rebalancing time — after all, each vertex needs to be “suspended” in a new place. But we can try to save memory. Let's take a closer look at the “trivial” algorithm. Here we select the median, hang it at the root, the tree is divided into two subtrees - and it is divided very clearly. You can’t choose “some other median” or suspend the “right” subtree instead of the left one. The same unambiguity haunts us at each of the next steps. Those. for a list of vertices sorted in ascending order, we will have exactly one tree generated by this algorithm. And where did we get the sorted list of vertices? From in-order traversal of the original tree. Those. each vertex found during the in-order traversal of the rebalanced tree corresponds to one specific position in the new tree. And we can calculate this position in principle without creating the sorted list itself. And having calculated - immediately write it there. There is only one problem - after all, this overwrites some (possibly not yet viewed) peak - what should we do? Keep her. Where? Well, allocate memory for the list of such vertices. But this memory will no longer need O (size (N)), but only O (log N).
As an exercise, imagine in your mind a tree consisting of three peaks — a root and two peaks suspended as “left” sons. An in-order round will return us these vertices in order from the “deepest” to the root, but to store in separate memory during this round we will have to only one vertex (the deepest), because when we come to the second peak, we will already know that it is a median and that it will be the root, and the other two peaks will be its children. Those. the memory consumption here is to store one vertex, which is consistent with the upper estimate for a tree of three vertices - log (3).
Deleting a vertex
We delete a vertex by the usual deletion of the top of the binary search tree (search, delete, possible re-suspension of children).
Next, we verify the condition
size [T] <α * max_size [T]
if it is executed, the tree could lose α-balancing by weight, which means that it is necessary to perform a complete rebalancing of the tree (starting from the root) and assign max_size [T] = size [T]
How productive is this?
The lack of memory overhead and rebalancing when searching is good, it works for us. On the other hand, rebalancing with modifications is not so very cheap. Well, the choice of α significantly affects the performance of certain operations. The inventors themselves compared the performance of a Scapegoat tree with red-black and Splay trees. They managed to select α so that on random data the Scapegoat tree outperformed all other types of trees in any operations (which is actually pretty good). Unfortunately, on a monotonically increasing dataset, the Scapegoat tree works worse in terms of insertion operations, and Scapegoat did not win with any α.