Designing a news feed on social networks
It so happened that over the past couple of years I managed to participate in the development of several social networks. The main task that had to be solved in each of these projects was to form a user news feed. Moreover, an important condition was the ability to scale this tape in the context of an increase in the number of users (more precisely, the number of connections between them) and, as a result, the amount of content that they share with each other.
My story will be about how, overcoming difficulties , I solved the problem of forming a news feed. And also I will talk about the approaches that the guys from the Socialite project have developed and which they shared on MongoDB World .
{kind=link}
How to form a tape?
So, for starters, absolutely banal information that any news feed is formed from the activity of users with whom we are friends (or whom we follow / read / etc). Therefore, the task of forming a tape is the task of delivering content from the author to his followers. The tape, as a rule, consists of completely motley content: cats, cobs, comedy videos, some text statuses and other things. On top of this, we have reposts, comments, likes, user tagging on these same statuses / photos / videos. Therefore, the main tasks that arise for developers of a social network are:
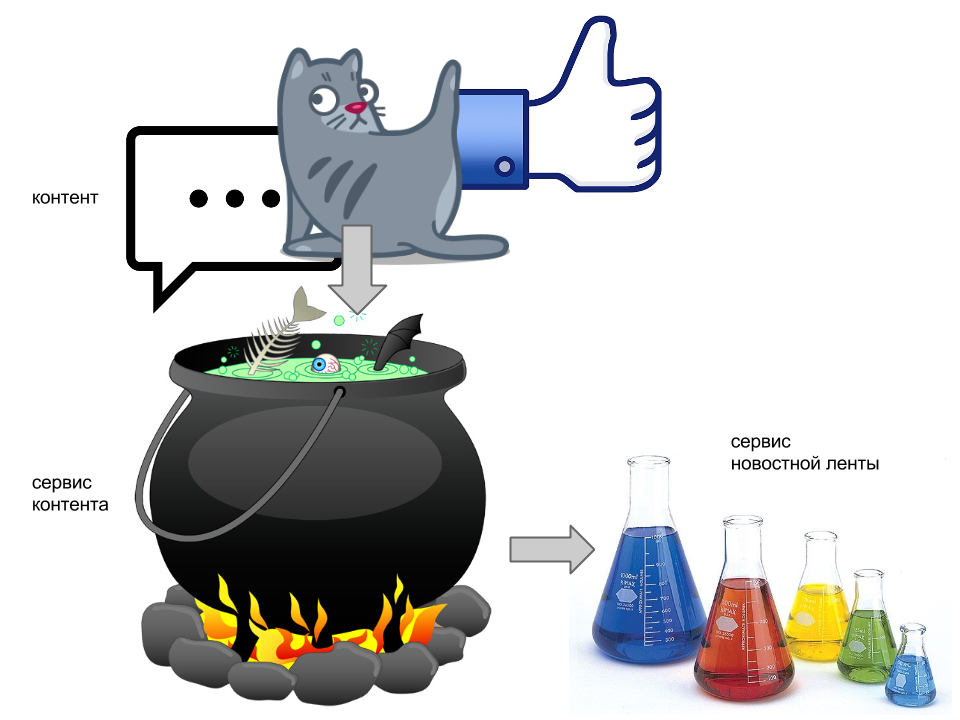
1. Aggregation of all activity, all content that users post. Let's call this a content service.. In the post-Halloween picture above, he is depicted as a boiling magic cauldron that digests and aggregates all kinds of motley objects into a collection of more or less homogeneous documents.
2. Delivery of user content to his followers. We will entrust this process to the service of the tape , which is represented by cones. Thus, when the user wants to read his feed, he goes after his personal cone, takes it, walks with it to the bowler and we pour him the desired piece of content.
It seems to be nowhere easier. Let's take a closer look at the approaches to implementing the formation of a personal news feed (in other words, delivering content from the author to his readers). I guarantee you a couple of interesting difficulties.
We form a tape when reading
This approach involves the formation of tape on the fly. Those. when a user requests his newsletter, we extract from our content service records of people that the user is subscribed to, sort them by time and get a newsletter. That, in general, is all. I think this is the most obvious and intuitive approach. On the diagram it looks something like this:

When a user posts something new, the process is absolutely trivial: you need to make only one entry in the content service. This simplicity is not surprising since The tape is delivered while reading, which means that the most interesting part is there.
OK, move on to reading the tape. To create a feed for a specific user, you need to take a list of people to whom he is subscribed. With this list, we go to the content service and pull out the posts of these people. Of course, it is not necessary to take all-all records directly, as a rule, you can take some part of this necessary to form the beginning of the tape or its next part. But in any case, the size of the received data will be much larger than what we ultimately return to the user. This is due to the fact that the activity of our friends is completely uneven and in advance we do not know how many posts we need to take from each of them to show the right part of the tape.
But this is not the biggest problem with this approach. Obviously, as the network grows, the collection of content will grow faster than the rest. And sooner or later there will come a need to shard this collection. And, of course, sharding will occur by content authors (for example, by their ID). So, the biggest minus of this approach is that our request will affect a very large number of arbitrary shards. Unless of course you follow one person.
Let’s now summarize the results of the delivery of Lena for reading.
From the pros:
- Ease of implementation. That is why such an approach is good to use "by default." For example, in order to quickly make a working demo, Proof on Concept, etc.
- No need for additional storage for copies of content from followers.
Now about the cons:
- Reading the tape affects many shards, which will no doubt affect the speed of such sampling.
- And this, most likely, will lead to the need for additional indexing.
- The need to select content with a "margin."
We form a tape when recording
Let's approach the problem from a slightly different perspective. What if for each user to keep a ready-made news feed and update it every time his friends post something new? In other words, we will make a copy of each post of the author in the “materialized” feed of his subscribers. This approach is slightly less obvious, but there is nothing beyond its complexity. The most important thing in it is to find the optimal storage model for this same “materialized” tape for each user.

And so, what happens when a user posts something new? As in the previous case, the post is sent to the content service. But now we additionally make a copy of the post in the feed of each subscriber (in fact, in this picture, the arrows going to the feed service should not start from the author’s post, but from the content service). Thus, each user has personalized tapes ready for reading. It is also very important that when sharding data from the feed service, the ID of subscribers will be used, not the authors (as is the case with the content service). Accordingly, now we will read the tape from one shard and this will give significant acceleration.
At first glance, it might seem that creating copies of the post for each subscriber (especially if there are tens of thousands of them) can turn out to be very slow. But we are not developing live chat, so it’s not at all scary if the cloning process takes even a few minutes. After all, we can do all this work asynchronously, unlike reading. Those. the user does not have to wait until his record is duplicated in the feed of each of his subscribers.
There is another, much more perceptible drawback - the need to store all our “materialized” tapes somewhere. Those. this is the need for extra hundred. And if the user has 15,000 followers, then this means that all of his content will be constantly stored in 15,000 thousand copies. And it doesn’t look at all cool.
And briefly about the advantages and disadvantages.
From the pros:
- The tape is formed by reading one or more documents. The number of documents will depend on the selected tape storage model, about a little later.
- It is easy to exclude inactive users from the process of pre-creating tapes.
About cons:
- Delivery of copies to a large number of subscribers can take quite a while.
- The need for additional storage for “materialized” tapes.
Storage Models for Materialized Tapes
As you might imagine, we won’t just put up with the problems, especially the scroll just in the middle of the article :-) And here the guys from MongoDB Labs come to our aid, who have developed as many as 3 models for storing “materialized” tapes. Each of these models somehow solves the disadvantages described above.Looking ahead, I’ll say that the first two models involve storing a personal tape for the entire period of its existence. Those. with these two approaches, we store absolutely all the records that ever got into the tape. Thus, the first two approaches, unlike the third, do not solve the problem of “swelling” of data. But, on the other hand, they allow you to very quickly give the user not only the top tapes, but also all its subsequent parts, up to the very end. Of course, users rarely scroll the ribbon to the bottom, but it all depends on the specific project and requirements.
Group by time
This model implies that all posts in the feed for a certain time interval (hour / day / etc.) Are grouped in one document. The guys from MongoDB Labs call such a document “bucket”. In our post-Halloween style, they are depicted by cones:

Example with MongoDB Documents
{
"_id": {"user": "vasya", "time": 516935},
"timeline": [
{"_id": ObjectId("...dc1"), "author": "masha", "post": "How are you?"},
{"_id": ObjectId("...dd2"), "author": "petya", "post": "Let's go drinking!"}
]
},
{
"_id": {"user": "petya", "time": 516934},
"timeline": [
{"_id": ObjectId("...dc1"), "author": "dimon", "post": "My name is Dimon."}
]
},
{
"_id": {"user": "vasya", "time": 516934},
"timeline": [
{"_id": ObjectId("...da7"), "author": "masha", "post": "Hi, Vasya!"}
]
}
All we do is round the current time (for example, take the beginning of each hour / day), take the follower ID, and write up each new post in our bucket with an upsert. Thus, all posts for a certain time interval will be grouped for each subscriber in one document.
If on the last day the people you are subscribing to wrote 23 posts, then in yesterday’s bucket your user will have exactly 23 posts. If, for example, there were no new posts in the last 10 days, then no new buckets will be created. So in certain cases, this approach will be very convenient.
The most important drawback of the model is that the generated buckets will be of unpredictable size. For example, on Friday, Friday cobs will post everything, and you will have several hundred entries in your bucket. And the next day everyone is asleep, and your Saturday’s bucket will have 1-2 entries. This is bad because you do not know how many documents you need to read in order to form the necessary part of the tape (even the beginning). And you can trite to exceed the maximum document size of 16MB.
Group by size
If the unpredictability of the size of buckets is critical for your project, then you need to build buckets by the number of entries in them.

Example with MongoDB Documents
{
"_id": ObjectId("...122"),
"user": "vasya",
"size": 3,
"timeline": [
{"_id": ObjectId("...dc1"), "author": "masha", "post": "How are you?"},
{"_id": ObjectId("...dd2"), "author": "petya", "post": "Let's go drinking!"},
{"_id": ObjectId("...da7"), "author": "petya", "post": "Hi, Vasya!"}
]
},
{
"_id": ObjectId("...011"),
"user": "petya",
"size": 1,
"timeline": [
{"_id": ObjectId("...dc1"), "author": "dimon", "post": "My name is Dimon."}
]
}
I will give an example. Set a limit on a bucket of 50 entries. Then we write the first 50 posts in the first bucket of the user. When it comes to the 51st post, create a second bucket for the same user, and write this and the next 50 posts there. Etc. In such a simple way, we solved the problem with an unstable and unpredictable size. But such a model works on recording about 2 times slower than the previous one. This is due to the fact that when recording each new post, it is necessary to check whether we have reached the established limit or not. And if you have reached, then create a new bucket and write in it already.
So, on the one hand, this approach solves the problems of the previous one, and on the other, it creates new ones. Therefore, the choice of model will depend on the specific requirements of your system.
Cache top
And finally, the latest model of tape storage, which should solve all the accumulated problems. Or at least balance them.

Example with MongoDB Documents
{
"user": "vasya",
"timeline": [
{"_id": ObjectId("...dc1"), "author": "masha", "post": "How are you?"},
{"_id": ObjectId("...dd2"), "author": "petya", "post": "Let's go drinking!"},
{"_id": ObjectId("...da7"), "author": "petya", "post": "Hi, Vasya!"}
]
},
{
"user": "petya",
"timeline": [
{"_id": ObjectId("...dc1"), "author": "dimon", "post": "My name is Dimon."}
]
}
The main idea of this model is that we cache a certain number of recent posts, and do not store the entire history. Those. in fact, the bucket will be a capped-array that stores a certain number of records. In MongoDB (since version 2.4), this is done very simply using the $ push and $ slice operators.
There are several advantages from this approach. First, we need to update just one document. What does this update have to be very fast, because it lacks any checks, unlike the previous model. Secondly, to get the tape we need to read again only one document.
Further. If the user does not log into our service for a long time, then we can simply delete his cache. Thus, we will exclude inactive users from the process of creating “materialized” tapes, freeing up the resources of our servers. If the inactive user suddenly decides to return, say in a year, we can easily create a new cache for him. You can fill it with actual posts using fallback in a simple read delivery.
Thus, this model is an excellent balance between storing the entire feed for each user and building this feed for each request.
Embedding vs Linking
And another important point regarding the storage of the tape in the cache: to store the content of posts or just a link?
The approach of storing a full copy of posts directly in the bucket will be good if the content of the posts is small and most importantly of a known size. An ideal example is Twitter with its 140-character status.
In the general case, the second approach wins when we store the post ID and, possibly, some meta-data (for example, author’s ID, publication date, etc.). Content is only stretched if necessary. At what to do it having a post ID can be very easy and fast.
What if I am very lazy?
In the 21st century, for every lazy person, there are approximately 100,500 applications for every occasion. Accordingly, for each developer there are a little less than 100500 services. Cool tape management service lives here .
That’s all for me. I just want to say that, as expected, no silver bullet was found to solve all the problems of forming a news feed. But we examined a whole bunch of solutions and approaches, each of which will work well in its own specific situation.