Markov random fields
- Tutorial
The article is devoted to the description of the CRF method (Conditional Random Fields), which is a variation of the Markov random field method. This method has found wide application in various fields of AI, in particular, it has been successfully used in problems of speech and image recognition, processing text information, as well as in other subject areas: bioinformatics, computer graphics, etc.
A Markov random field or Markov network (not to be confused with Makov chains) is a graph model that is used to represent joint distributions of a set of several random variables. Formally, the Markov random field consists of the following components:
Vertices that are not adjacent must correspond to conditionally independent random variables. A group of adjacent vertices forms a clique; a set of vertex states is an argument of the corresponding potential function.
The joint distribution of a set of random variables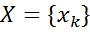 in a Markov random field is calculated by the formula:
in a Markov random field is calculated by the formula:
(1)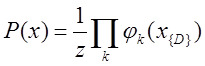 ,
,
where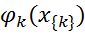 is a potential function that describes the state of random variables in the kth clique; Z - normalization coefficient is calculated by the formula:
is a potential function that describes the state of random variables in the kth clique; Z - normalization coefficient is calculated by the formula:
(2)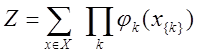 .
.
The set of input tokens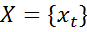 and the set of corresponding types
and the set of corresponding types 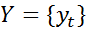 together form a set of random variables
together form a set of random variables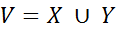 . To solve the problem of extracting information from text, it is enough to determine the conditional probability P (Y | X). The potential function has the form:,
. To solve the problem of extracting information from text, it is enough to determine the conditional probability P (Y | X). The potential function has the form:,
 where is a
where is a 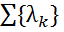 real-valued parametric vector, and
real-valued parametric vector, and
 is a set of attribute functions. Then the linear conditional random field is called the probability distribution of the form:
is a set of attribute functions. Then the linear conditional random field is called the probability distribution of the form:
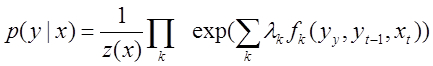 .
.
Whereas normalization coefficient Z (x) is calculated using the formula:
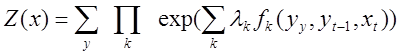 .
.
The CRF method, like the MEMM method (Maximum Entropy Markov Models), refers to discriminative probabilistic methods, in contrast to generative methods such as HMM (Hidden Markov Models) or the Naïve Bayes method.
By analogy with MEMM, the choice of factor signs for setting the probability of transition between states in the presence of an observed value depends on the specifics of specific data, but unlike the same MEMM,
depends on the specifics of specific data, but unlike the same MEMM,
CRF can take into account any features and interdependencies in the source data. The feature vector is calculated based on the training sample and determines the weight of each potential function. For training and application of the model, algorithms similar to the HMM algorithms are used: Viterbi and its variant - the forward-backward algorithm.
calculated based on the training sample and determines the weight of each potential function. For training and application of the model, algorithms similar to the HMM algorithms are used: Viterbi and its variant - the forward-backward algorithm.
The hidden Markov model can be considered as a special case of a linear conditional random field (CRF). In turn, a conditional random field can be considered as a kind of Markov random field (see. Fig.).

Fig. Graph image for HMM, MEMM, and CRF methods. Unfilled circles indicate that the distribution of a random variable is not taken into account in the model. Arrows indicate dependent nodes.
In conditional random fields, the so-called label bias problem - a situation where states with fewer transitions get the advantage, since a single probability distribution is built and normalization (coefficient Z (x) from formula (5)) is performed as a whole, and not within a separate state. This, of course, is an advantage of the method: the algorithm does not require the assumption of independence of the observed variables. In addition, the use of arbitrary factors allows us to describe various features of the objects being determined, which reduces the requirements for the completeness and volume of the training sample. Depending on the problem being solved, in practice, a volume of from several hundred thousand to millions of terms is sufficient. Moreover, the accuracy will be determined not only by the sample size, but also by the selected factors.
The disadvantage of the CRF approach is the computational complexity of the analysis of the training sample, which makes it difficult to constantly update the model when new training data arrives.
A comparison of the CRF method with some other methods used in computer linguistics can be found in [3]. It is shown in the paper that the proposed method works better than the others (according to F1) in solving various linguistic problems. For example, in the tasks of automatically finding named entities in the text, CRF demonstrates slightly lower accuracy compared to the MEMM method, but at the same time significantly wins in completeness.
It should be added that the implementation of the CRF algorithm has a good speed, which is very important when processing large amounts of information.
Today, it is the CRF method that is the most popular and accurate way to extract objects from text. For example, it was implemented in a Stanford University project, Stanford Named Entity Recognizer. Also, this method has been successfully implemented for different types of linguistic text processing.
Method summary
(who does not like mathematics and is afraid of formulas, you can immediately go to the "comparison of methods").A Markov random field or Markov network (not to be confused with Makov chains) is a graph model that is used to represent joint distributions of a set of several random variables. Formally, the Markov random field consists of the following components:
- undirected graph or factor graph G = (V, E), where each vertex
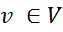 is a random variable X and each edge
is a random variable X and each edge 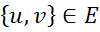 is a relationship between random variables u and v.
is a relationship between random variables u and v. - a set of potential functions or factors
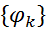 , one for each click (a click is a complete subgraph G of an undirected graph) in a graph. The function
, one for each click (a click is a complete subgraph G of an undirected graph) in a graph. The function 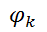 associates with each possible state of the clique elements a certain non-negative real-valued number.
associates with each possible state of the clique elements a certain non-negative real-valued number.
Vertices that are not adjacent must correspond to conditionally independent random variables. A group of adjacent vertices forms a clique; a set of vertex states is an argument of the corresponding potential function.
The joint distribution of a set of random variables
in a Markov random field is calculated by the formula: (1)
, where
is a potential function that describes the state of random variables in the kth clique; Z - normalization coefficient is calculated by the formula: (2)
. The set of input tokens
and the set of corresponding types together form a set of random variables. To solve the problem of extracting information from text, it is enough to determine the conditional probability P (Y | X). The potential function has the form:, where is a real-valued parametric vector, and is a set of attribute functions. Then the linear conditional random field is called the probability distribution of the form: . Whereas normalization coefficient Z (x) is calculated using the formula:
.Method Comparison
The CRF method, like the MEMM method (Maximum Entropy Markov Models), refers to discriminative probabilistic methods, in contrast to generative methods such as HMM (Hidden Markov Models) or the Naïve Bayes method.
By analogy with MEMM, the choice of factor signs for setting the probability of transition between states in the presence of an observed value
depends on the specifics of specific data, but unlike the same MEMM, CRF can take into account any features and interdependencies in the source data. The feature vector is
calculated based on the training sample and determines the weight of each potential function. For training and application of the model, algorithms similar to the HMM algorithms are used: Viterbi and its variant - the forward-backward algorithm.The hidden Markov model can be considered as a special case of a linear conditional random field (CRF). In turn, a conditional random field can be considered as a kind of Markov random field (see. Fig.).
Fig. Graph image for HMM, MEMM, and CRF methods. Unfilled circles indicate that the distribution of a random variable is not taken into account in the model. Arrows indicate dependent nodes.
In conditional random fields, the so-called label bias problem - a situation where states with fewer transitions get the advantage, since a single probability distribution is built and normalization (coefficient Z (x) from formula (5)) is performed as a whole, and not within a separate state. This, of course, is an advantage of the method: the algorithm does not require the assumption of independence of the observed variables. In addition, the use of arbitrary factors allows us to describe various features of the objects being determined, which reduces the requirements for the completeness and volume of the training sample. Depending on the problem being solved, in practice, a volume of from several hundred thousand to millions of terms is sufficient. Moreover, the accuracy will be determined not only by the sample size, but also by the selected factors.
The disadvantage of the CRF approach is the computational complexity of the analysis of the training sample, which makes it difficult to constantly update the model when new training data arrives.
A comparison of the CRF method with some other methods used in computer linguistics can be found in [3]. It is shown in the paper that the proposed method works better than the others (according to F1) in solving various linguistic problems. For example, in the tasks of automatically finding named entities in the text, CRF demonstrates slightly lower accuracy compared to the MEMM method, but at the same time significantly wins in completeness.
It should be added that the implementation of the CRF algorithm has a good speed, which is very important when processing large amounts of information.
Today, it is the CRF method that is the most popular and accurate way to extract objects from text. For example, it was implemented in a Stanford University project, Stanford Named Entity Recognizer. Also, this method has been successfully implemented for different types of linguistic text processing.
List of references
- Lafferty J., McCallum A., Pereira F. “ Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data ”. Proceedings of the 18th International Conference on Machine Learning. 282-289. 2001.
- Klinger R., Tomanek K .: Classical Probabilistic Models and Conditional Random Fields. Algorithm Engineering Report TR07-2-013. of Computer Science. Dortmund University of Technology. December 2007. ISSN 1864-4503.
- Antonova A.Yu., Soloviev A.N. The method of conditional random fields in the tasks of processing Russian-language texts. “Information Technologies and Systems - 2013”, Kaliningrad, 2013.
http://itas2013.iitp.ru/pdf/1569759547.pdf - Stanford Named Entity Recognizer // http://www-nlp.stanford.edu/software/CRF-NER.shtml