How to expand Kubernetes
Today we will talk about DevOps, or rather, mostly about Ops. They say that there are very few people who are satisfied with the level of automation of their operations. But it seems that the situation is fixable. In this article, Nikolai Ryzhikov will talk about his experience in expanding Kubernetes.

The material was prepared on the basis of Nikolay's speech at the autumn DevOops 2017 conference. Under the cut - video and text transcript of the report.
At the moment, Nikolai Ryzhikov is working in the Health-IT sector to create medical information systems. Member of the St. Petersburg community of functional programmers FPROG. An active member of the Online Clojure community, a member of the standard for the exchange of medical information HL7 FHIR. Engaged in programming for 15 years.
What side we treat DevOps? Our DevOps formula for the past 10 years is quite simple: developers are responsible for operations, developers are deployed, developers are mainten. With this arrangement, which looks a bit harsh, you will in any case become DevOps. If you want to implement DevOps quickly and painfully - make the developers responsible for your production. If the guys are smart, they will start to get out and understand everything.

Our story: long ago, when there were no Chef and automation yet, we already deployed the automatic Capistrano. Then they began to bore it to make it fashionable. But then Chef appeared. We switched to it and left for the cloud: we were tired of our data centers. Then Ansible appeared, Docker appeared. After that, we moved to Terraform with a hand-written supervisor for Condo dockers at Camel. And now we are moving to Kubernetes.

What is the worst thing about operations? Very few people are satisfied with the level of automation of their operations. It's scary, I confirm: we spent a lot of resources and efforts to collect all these stacks for ourselves, and the result is unsatisfactory.
There is a feeling that with the arrival of Kubernetes something can change. I am an adherent of lean manufacturing and, from his point of view, operations are not beneficial at all. Perfect operations are the absence or minimum of operations in a project. Value is created when a developer makes a product. When it is ready, the delivery does not add value. But you need to reduce costs.

For me, the ideal has always been heroku. We used it for simple applications, where the developer needed to say git push and configure heroku to deploy his service. It takes a minute.

How to be? You can buy NoOps - also heroku. And I advise you to buy, otherwise there is a chance to spend more money on developing normal operations.
There are guys Deis, they are trying to do something like heroku on Kubernetes. There is a cloud foundry, which also provides a platform on which to work.

But if you bother with something more complex or large, you can do it yourself. Now with Docker and Kubernetes, this becomes a task that can be accomplished in a reasonable amount of time at a reasonable cost. Once it was too hard.

One of the problems of operations is repeatability. The wonderful thing that the docker introduced is two phases. We have a build phase.
The second point that pleases Docker is a universal interface for launching arbitrary services. Someone gathered Docker, put something inside, and operations just say Docker run and run.

What is Kubernetes? So we made a Docker and we need to run it somewhere, merge, configure and link it to others. Kubernetes allows you to do this. He introduces a series of abstractions, which are called "resource". We quickly go through them and even try to create.
The first abstraction is a POD or a set of containers. Properly done, what exactly is a set of containers, not just one. Sets can fumble among themselves volumes that see each other through localhost. This allows you to use such a pattern as a sidecar (this is when we launch the main container, and next to it there are auxiliary containers that help it).
For example, the ambassador approach. This is when you do not want the container to think about where some services are located. You put near a container that knows where these services lie. And they become available to the main container on localhost. Thus, the environment begins to look like you are working locally.

Let's raise the POD and see how it is described. You can develop minikube locally. It eats up a bunch of CPUs, but allows you to raise a small Kubernetes cluster on the virtualbox and work with it.
Let's close up the POD. I said Kubernetes apply and uploaded the POD. I can see what kind of PODs I have: I see that one POD has been captured. This means that Kubernetes has launched these containers.
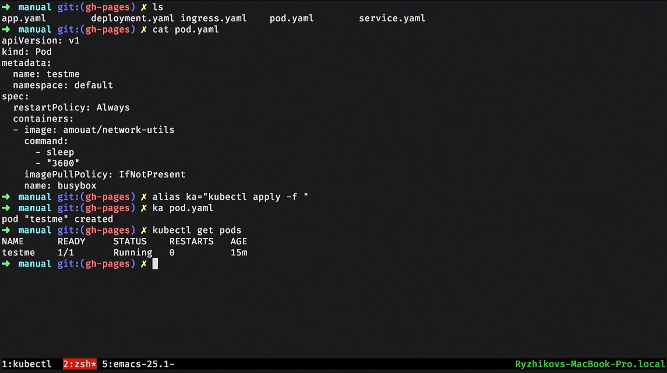
I can even go into this container.
From this point of view, Kubernetes is made for humans. Indeed, what we constantly do in operations, in the Kubernetes harness, for example, with the help of the utility kubectl, can be done easily.
But POD is mortal. It runs as a docker run: if someone stops it, no one will raise it up. On top of this abstraction, Kubernetes begins building the next one — for example, the replicaset. This is such a supervisor who watches the POD, watches their number, and if the PODs fall, he re-raises them. This is an important self-healing concept in Kubernetes that allows you to sleep at night.
On top of the replicaset there is an abstraction. Deployment is also a resource that allows zero time deployment. For example, one replicaset works. When we deploy and change the version of the container, for example, ours, inside the deployment, another replicaset rises. We wait for these containers to start, pass their health checks, and then we quickly switch to a new replicaset. Also a classic and good practice.

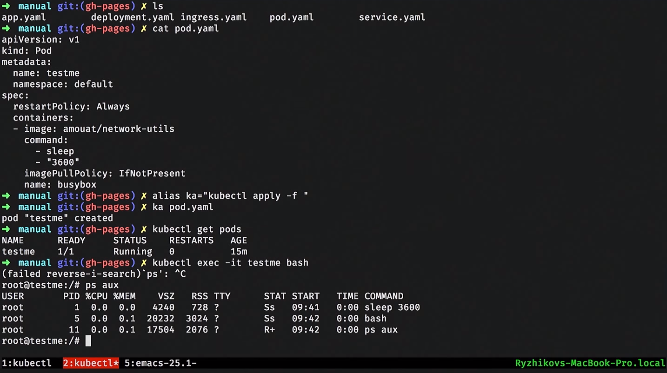
Let's raise a simple service. For example, we have a deployment. Inside, he describes the POD template that he will raise. We can apply this deployment, see what we have. Cool feature Kubernetes - everything is in the database, and we can see what is happening in the system.
Here we see one deployment. If we try to look at the PODs, then we see that some POD has risen. We can take and delete this POD. What happens to PODs? One is destroyed, and the second rises immediately. This replicaset controller did not find the desired POD and launched another one.
Further, if this is some kind of web service, or inside our services must be connected, service discovery is needed. You must give the service a name and entry point. For this Kubernetes offers a resource called service. He may engage in load balancing and be responsible for service discovery.

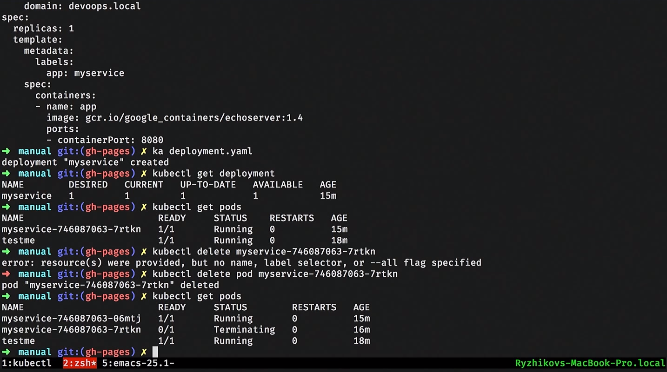
Let's see a simple service. We associate it with deployment and POD via labels: such dynamic binding. A very important concept in Kubernetes: the system is dynamic. No matter in what order it will be created. Service will try to find PODs with such labels and start their load balance.

Applaim service, we look, what services we have. Go to our test POD, which was raised, and do nslookup. Kubernetes gives us a DNS, through which services can see and detect each other.

Service is rather an interface. There are several different implementations there, because the load balancing and service tasks are quite complex: in one way we work with regular databases, with other methods with loaded ones, and some simple ones we do in a very simple way. This is also an important concept in Kubernetes: some things can be called interfaces rather than implementations. They are not rigidly fixed, and different, for example, cloud providers provide different implementations. Ie, for example, there is a persistent volume resource, which is already implemented in each specific cloud by its own standard means.
Next, we usually want to bring the web service somewhere outside. There is an ingress abstraction in Kubernetes. Usually SSL is added there.

The simplest ingress looks something like this. There we write the rules: by what url, by which hosts, to which internal service to redirect the request. In the same way we can raise our ingress.
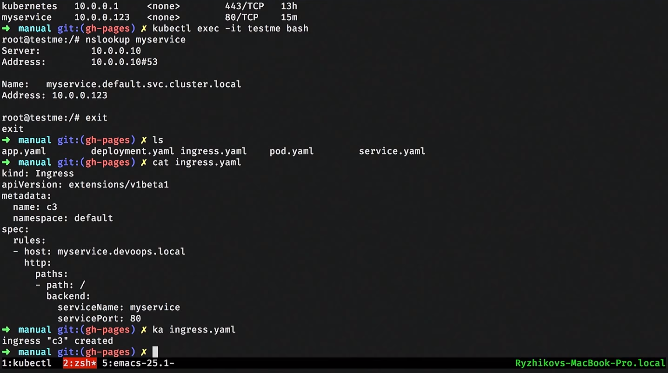
After that, registering locally in the hosts, you can see this service from here.

This is such a regular task: we have deployed a web service, a little bit acquainted with Kubernetes.
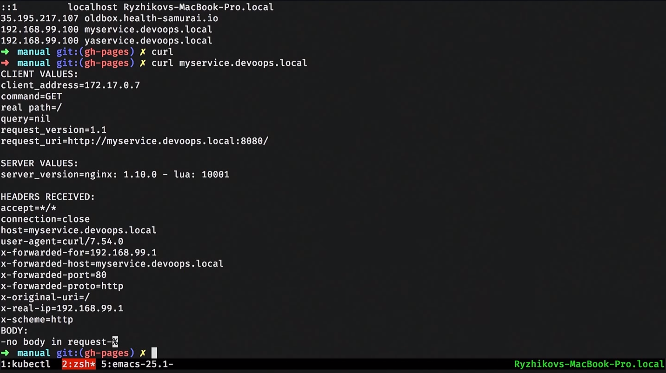
We clean out all this, remove the ingress and look at all the resources.
There are a number of resources, such as configmap and secret. These are purely informational resources that you can put into a container and transfer, for example, the password from postgres. You can associate this with environment variables that will be injected into the container during startup. You can mount the file system. Everything is quite convenient: standard tasks, nice solutions.
There is a persistent volume - an interface that is implemented differently for different cloud providers. It is divided into two parts: there is a persistent volume claim (request), and then some kind of EBS-ka is created, which is dragged to the container. You can work with a stateful service.

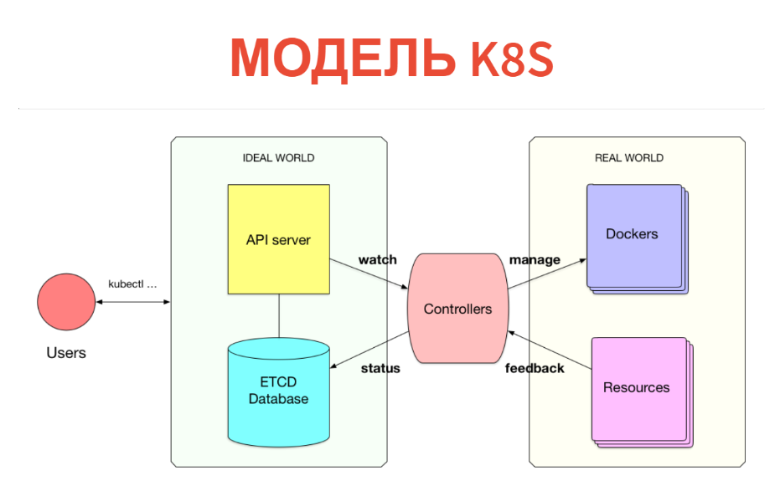
But how does it work inside? The concept itself is very simple and transparent. Kubernetes consists of two parts. One is just a database in which we have all these resources. You can present the resources as labels: specifically, these instances are just records in the labels. An API server is configured on top of Kubernetes. That is, when you have Kubernetes cluster, you usually communicate with the API server (more precisely, the client communicates with it).
Accordingly, what we created (PODs, services, etc.) is simply written to the database. This database is implemented by ETCD, i.e. so that it is stable at the high-available level.
What is being done next? Further under each type of resources there is a certain controller. It is just a service that monitors its type of resource and does something in the outside world. For example, does the docker run. If we have a POD, for each Node there is a kubelet-service, which monitors the PODs that go to this node. And all he does is a Docker run after another periodic check, if this POD is not.
Further, which is very important - everything happens in real time, so the power of this controller is above the minimum. Often, the controller still removes metrics and looks at what it has launched. Those. takes feedback from the real world and writes it to the database so that you or other controllers can see it. For example, the same POD status will be written back to ETCD.
Thus, everything is implemented in Kubernetes. It is very cool that the information model is separated from the operating room. In the database, through the usual CRUD interface, we declare what should be. Then a set of controllers tries to make it all right. True, this is not always the case.
This is a cybernetic model. We have a certain preset, there is some kind of machine that is trying to direct the real world or the machine into the place that is needed. It doesn't always work that way: we should have a feedback loop. Sometimes the machine can not do this and should appeal to the person.
In real systems, we think of abstractions of the following level: we have certain services, databases, and we connect all this. We do not think of PODs and Ingress, and we want to build some next level of abstraction.

So that the developer was as easy as possible: so that he simply said, “I want to launch such a service,” and everything else happened inside.
There is such a thing as HELM. This is the wrong way - the template is ansible style, where we just try to generate a set of configured resources and throw them into the Kubernetes cluster.
The problem, firstly, is that it is performed only at the time of rolling. That is a lot of logic, he can not implement. Secondly, this abstraction disappears in runtime. When I go to look at my cluster, I just see the PODs and services. I do not see that such and such a service is affected, that such a base with replication is raised there. I just see there are dozens of pods. Abstraction disappears in the matrix.

On the other hand, Kubernetes itself already inside gives a very interesting and simple extension model. We can announce new types of resources, such as deployment. This is a resource built on top of a POD or replicaset. We can write a controller to this resource, put this resource in the database and launch our cybernetic loop so that everything works. This sounds interesting, and I think this is the right way to expand Kubernetes.

I would like to be able to just write a kind of manifest for my service in the heroku style. A very simple example: I want to enclose some kind of application in my real environment. There are already agreements, SSL, domains purchased. I just wanted to give developers the easiest interface possible. Manifest tells me which container to lift, what resources this container still needs. He casts this ad in the cluster, and everything starts to work.

What will it look like in terms of custom resources and controllers? Here we will have to be in the resource application database. And the application controller will spawn three resources. That is, he will register in ingress the rules on how to route to this service, start the service for load balancing and launch the deployment with some configuration.
Before we create a custom resource in Kubernetes, we need to declare it. For this, there is a meta-resource called CustomResourceDefinition.
In order to announce a new resource in Kubernetes, we just need to zaplapit here such an ad. Read this create table.

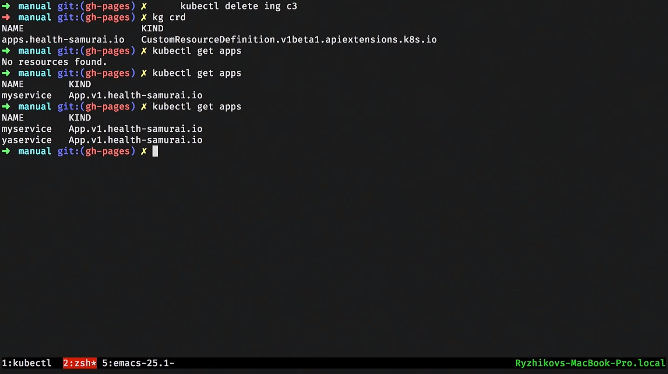
Created a table. After that we can look through the kubectl get to the third-party resources that we have. As soon as we announced it, we also got an apish. We can do, for example, kubeclt get apps. But so far no appov there.

Let's write some app. After that we can make a custom resource instance. Let's look at it in YAML and create it by posting to a specific URL.

If we run and see through kubectl, then one app appeared. But while nothing happens, it just lies in the database. You can, for example, take and request all app resources.

We can create a second such resource from the same template, simply by changing the name. Here came the second resource.
Next, our controller should do the templating, similar to what HELM does. That is, having received a description of our app, I have to generate a resource deployment and resource service, and also make an entry in the ingress. This is the easiest part: here in clojure, it's erlmacro. I transfer the data structure, it jerks the deployment function, passes to the debug, which is the pipeline. And this is a pure function: simple templating. Accordingly, in the most naive form, I could immediately create it, turn it into a console utility and start distributing.

We do the same for the service: the service function accepts a declaration and generates the Kubernetes resource for us.
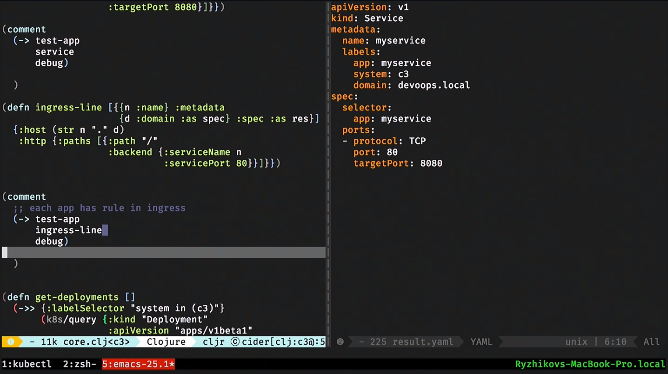
We do the same for the ingress line.

How will it all work? There will be something in the real world and there will be what we want. What we want is we take the application resource and generate it for what should be. And now we need to see what is. What we have is requested through the REST API. We can get all the services, all deployments.
How will our custom controller work? He will receive what we want and what is, take from this div and apply to Kubernetes. This is similar to React. I came up with a virtual DOM, when some functions simply generate a tree of JS objects. And then a certain algorithm calculates the patch and applies it to the real DOM.
We will do the same here. This is done in 50 lines of code. Want it - everything is on Github. As a result, we should get the function reconcile-actions.
We have a reconcile-actions function that does nothing and just computes this div. She takes what is, plus what is needed. And then gives what needs to be done to bring the first to the second.
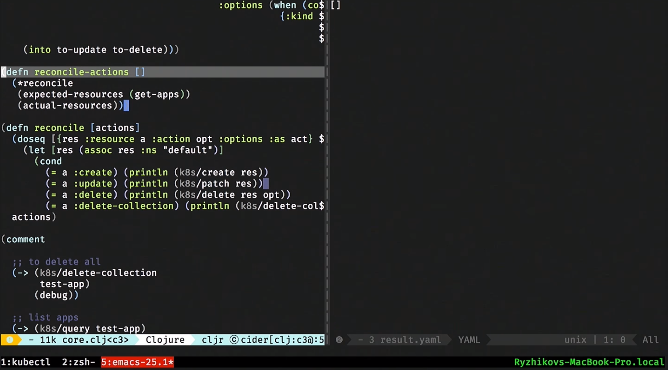
Let's jerk her. There is nothing wrong with it, you can debug it. She says that you need to create an ingress-service, make two entries in it, create deployment 1 and 2, create service 1 and 2.
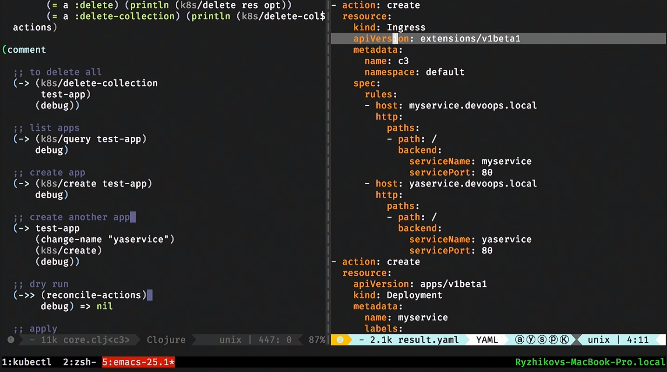
In this case, there should already be only one service. We see by ingress that only one record remains.
Next, all that remains is to write a function that applies this patch to the Kubernetes cluster. To do this, we simply pass the reconcile-actions to the reconcile function, and everything will apply. And here we see that POD has risen, deployment has become, and the service has started.

Let's add one more service: once again we will execute the function reconcile-actions. Let's see what happened. Everything started, all is well.

How to deal with this? We all pack it in Docker-container. After this, we write a function that periodically wakes up, makes reconcile and falls asleep. The speed is not very important, it can sleep for five seconds and do reconcile-actions less often.

Our custom controller is just a service that will wake up and periodically calculate a patch.
Now we have two services zepeploino, let's remove one of the applications. Let's see how our cluster responded: everything is ok. Remove the second: everything is cleared.

Let's see through the eyes of the developer. He just needs to say Kubernetes apply and set the name of the new service. We do this, our controller has picked up and created everything.

Next, we collect all of this into the deployment service, and with the standard Kubernetes tools we throw this custom controller into a cluster. We have created an abstraction for 200 lines of code.
It's all like HELM, but actually more powerful. The controller works in a cluster: it sees the base, sees the outside world and can be made quite clever.
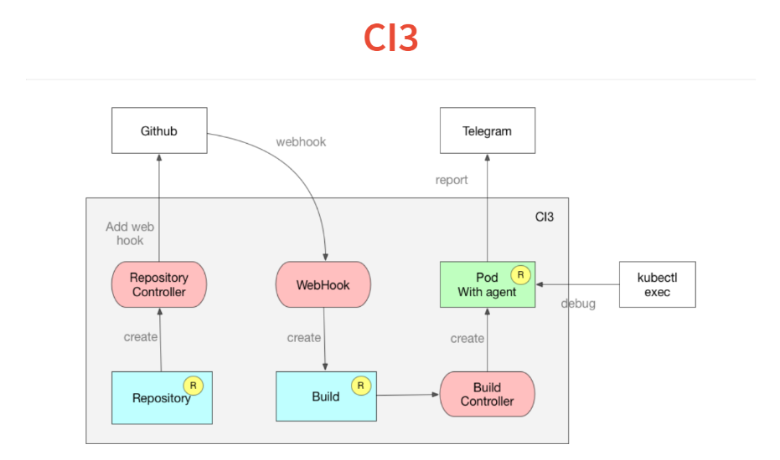
Consider the Kubernetes extension examples. We decided that CI should be part of the infrastructure. This is good, it is convenient from the point of view of security - a private repository. We tried to use jenkins, but it is an obsolete tool. I wanted a hacker CI. We do not need interfaces, we love ChatOps: let them just say in chat whether the build is down or not. In addition, I wanted to debug everything locally.

We sat down and wrote our CI in a week. Just as an extension to Kubernetes. If you think about CI, then this is just a tool that runs some jobs. As part of this job, we are building something, running tests, often deploying.
How does all this work? It is built on the same concept of custom controllers. First, we drop the description of what repositories we are watching in Kubernetes. The controller simply goes to the githab and adds a web hook. We are left with introspection.
Next comes the web-hook, whose only task is to process the incoming JSON and throw it into the custom build resource, which also adds up to the Kubernetes database. The build resource is monitored by the build controller, which reads the manifest inside the project and starts the POD. This POD-e runs all the necessary services.
The POD has a very simple agent that reads a travis or circleci style declaration, and a set of steps in YAML. He starts to perform them. After that, at the end of the build, he casts his result in the Telegram.
Another feature that we got together with Kubernetes is that one of the commands in the execution of your CI or continuous delivery can be put just while true sleep 10, and your POD will freeze at this step. You do kubectl exec, you are inside your build and you can debug.
Another feature - everything is built on dockers and you can debug the script locally by launching the docker. It all took two weeks and 300 lines of code.
Our product is built on postgres, we use all its interesting features. We even wrote a number of extensions. But we can not use RDS or something else.
We are now in the process of developing an operator for non-killed postgres. Voiced architecture. I want to say "Cluster, give me postgres, which can not be killed." Add to this that I need two asynchronous replicas, one synchronous, backups daily and up to a terabyte. I throw it all over, further on my cluster controller begins to engage in orchestrating and unfolding my container. It creates pginstance resources that are responsible for each istance postgres. This will be cluster postgres.
Next is the pginstance controller, simple enough, just trying to run a POD or deployment there with this postgres. The heart is a persistent volume. This whole machine takes full control of postgres. You give her a Docker-container in which there is only binary postgres. Everything else: the configuration and creation of the start cluster postgres is done by the controller itself. He does this so that we can reconfigure later, and so that he can configure replication, log levels, etc. At the beginning, the temporary POD travels over the persistent volume and creates a postgres cluster for the master there.
Then, deployment starts with master. Then persistent volume is created in the same way. Another POD travels, makes a basic backup, tightens it, and deployment starts from a slave on top of this.
Next cluster controller creates a backup resource (after it described backups). And the backup controller already takes it and throws it into some S3.

Let's imagine with you the near future. It may happen that sooner or later we will have such interesting custom resources, custom controllers, that I will say “Give me postgres, give me kafka, leave me CI and start all this”. Everything will be easy.
If we are not talking about the near future, then, as a declarative programmer, I believe that the above functional programming is only logical or relational. There we have operations semantics completely separated from information semantics. If we look carefully at our custom controllers that we did, then we have in the database, for example, a resource application. And we derive three additional resources from it. This is very similar to the view in the database. This is a deduction of facts. This is a logical or relation view.
The next step for Kubernetes is, instead of chopped REST API, to give some illusion of a relational or logical base, where you can simply write a rule. Since sooner or later everything flows to the database, including feedback, the rules may sound like this: “If the load has increased like this, then increase the replication like this.” We will have a small sql or logical rule. All you need is a generic engine that will monitor this. But this is a bright future.

The material was prepared on the basis of Nikolay's speech at the autumn DevOops 2017 conference. Under the cut - video and text transcript of the report.
At the moment, Nikolai Ryzhikov is working in the Health-IT sector to create medical information systems. Member of the St. Petersburg community of functional programmers FPROG. An active member of the Online Clojure community, a member of the standard for the exchange of medical information HL7 FHIR. Engaged in programming for 15 years.
What side we treat DevOps? Our DevOps formula for the past 10 years is quite simple: developers are responsible for operations, developers are deployed, developers are mainten. With this arrangement, which looks a bit harsh, you will in any case become DevOps. If you want to implement DevOps quickly and painfully - make the developers responsible for your production. If the guys are smart, they will start to get out and understand everything.
Our story: long ago, when there were no Chef and automation yet, we already deployed the automatic Capistrano. Then they began to bore it to make it fashionable. But then Chef appeared. We switched to it and left for the cloud: we were tired of our data centers. Then Ansible appeared, Docker appeared. After that, we moved to Terraform with a hand-written supervisor for Condo dockers at Camel. And now we are moving to Kubernetes.
What is the worst thing about operations? Very few people are satisfied with the level of automation of their operations. It's scary, I confirm: we spent a lot of resources and efforts to collect all these stacks for ourselves, and the result is unsatisfactory.
There is a feeling that with the arrival of Kubernetes something can change. I am an adherent of lean manufacturing and, from his point of view, operations are not beneficial at all. Perfect operations are the absence or minimum of operations in a project. Value is created when a developer makes a product. When it is ready, the delivery does not add value. But you need to reduce costs.
For me, the ideal has always been heroku. We used it for simple applications, where the developer needed to say git push and configure heroku to deploy his service. It takes a minute.
How to be? You can buy NoOps - also heroku. And I advise you to buy, otherwise there is a chance to spend more money on developing normal operations.
There are guys Deis, they are trying to do something like heroku on Kubernetes. There is a cloud foundry, which also provides a platform on which to work.
But if you bother with something more complex or large, you can do it yourself. Now with Docker and Kubernetes, this becomes a task that can be accomplished in a reasonable amount of time at a reasonable cost. Once it was too hard.
A bit about Docker and Kubernetes
One of the problems of operations is repeatability. The wonderful thing that the docker introduced is two phases. We have a build phase.
The second point that pleases Docker is a universal interface for launching arbitrary services. Someone gathered Docker, put something inside, and operations just say Docker run and run.
What is Kubernetes? So we made a Docker and we need to run it somewhere, merge, configure and link it to others. Kubernetes allows you to do this. He introduces a series of abstractions, which are called "resource". We quickly go through them and even try to create.
Abstractions
The first abstraction is a POD or a set of containers. Properly done, what exactly is a set of containers, not just one. Sets can fumble among themselves volumes that see each other through localhost. This allows you to use such a pattern as a sidecar (this is when we launch the main container, and next to it there are auxiliary containers that help it).
For example, the ambassador approach. This is when you do not want the container to think about where some services are located. You put near a container that knows where these services lie. And they become available to the main container on localhost. Thus, the environment begins to look like you are working locally.
Let's raise the POD and see how it is described. You can develop minikube locally. It eats up a bunch of CPUs, but allows you to raise a small Kubernetes cluster on the virtualbox and work with it.
Let's close up the POD. I said Kubernetes apply and uploaded the POD. I can see what kind of PODs I have: I see that one POD has been captured. This means that Kubernetes has launched these containers.
I can even go into this container.
From this point of view, Kubernetes is made for humans. Indeed, what we constantly do in operations, in the Kubernetes harness, for example, with the help of the utility kubectl, can be done easily.
But POD is mortal. It runs as a docker run: if someone stops it, no one will raise it up. On top of this abstraction, Kubernetes begins building the next one — for example, the replicaset. This is such a supervisor who watches the POD, watches their number, and if the PODs fall, he re-raises them. This is an important self-healing concept in Kubernetes that allows you to sleep at night.
On top of the replicaset there is an abstraction. Deployment is also a resource that allows zero time deployment. For example, one replicaset works. When we deploy and change the version of the container, for example, ours, inside the deployment, another replicaset rises. We wait for these containers to start, pass their health checks, and then we quickly switch to a new replicaset. Also a classic and good practice.
Let's raise a simple service. For example, we have a deployment. Inside, he describes the POD template that he will raise. We can apply this deployment, see what we have. Cool feature Kubernetes - everything is in the database, and we can see what is happening in the system.
Here we see one deployment. If we try to look at the PODs, then we see that some POD has risen. We can take and delete this POD. What happens to PODs? One is destroyed, and the second rises immediately. This replicaset controller did not find the desired POD and launched another one.
Further, if this is some kind of web service, or inside our services must be connected, service discovery is needed. You must give the service a name and entry point. For this Kubernetes offers a resource called service. He may engage in load balancing and be responsible for service discovery.
Let's see a simple service. We associate it with deployment and POD via labels: such dynamic binding. A very important concept in Kubernetes: the system is dynamic. No matter in what order it will be created. Service will try to find PODs with such labels and start their load balance.
Applaim service, we look, what services we have. Go to our test POD, which was raised, and do nslookup. Kubernetes gives us a DNS, through which services can see and detect each other.
Service is rather an interface. There are several different implementations there, because the load balancing and service tasks are quite complex: in one way we work with regular databases, with other methods with loaded ones, and some simple ones we do in a very simple way. This is also an important concept in Kubernetes: some things can be called interfaces rather than implementations. They are not rigidly fixed, and different, for example, cloud providers provide different implementations. Ie, for example, there is a persistent volume resource, which is already implemented in each specific cloud by its own standard means.
Next, we usually want to bring the web service somewhere outside. There is an ingress abstraction in Kubernetes. Usually SSL is added there.
The simplest ingress looks something like this. There we write the rules: by what url, by which hosts, to which internal service to redirect the request. In the same way we can raise our ingress.
After that, registering locally in the hosts, you can see this service from here.
This is such a regular task: we have deployed a web service, a little bit acquainted with Kubernetes.
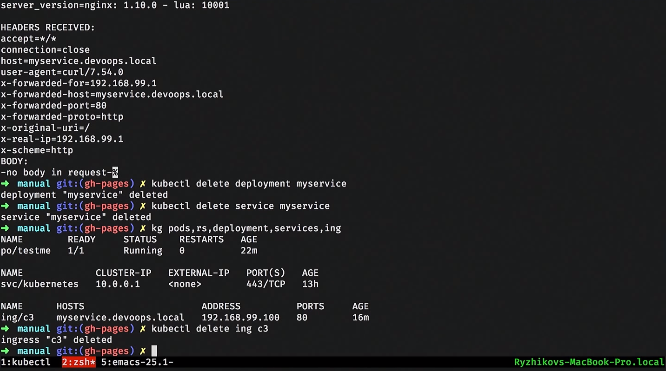
We clean out all this, remove the ingress and look at all the resources.
There are a number of resources, such as configmap and secret. These are purely informational resources that you can put into a container and transfer, for example, the password from postgres. You can associate this with environment variables that will be injected into the container during startup. You can mount the file system. Everything is quite convenient: standard tasks, nice solutions.
There is a persistent volume - an interface that is implemented differently for different cloud providers. It is divided into two parts: there is a persistent volume claim (request), and then some kind of EBS-ka is created, which is dragged to the container. You can work with a stateful service.
But how does it work inside? The concept itself is very simple and transparent. Kubernetes consists of two parts. One is just a database in which we have all these resources. You can present the resources as labels: specifically, these instances are just records in the labels. An API server is configured on top of Kubernetes. That is, when you have Kubernetes cluster, you usually communicate with the API server (more precisely, the client communicates with it).
Accordingly, what we created (PODs, services, etc.) is simply written to the database. This database is implemented by ETCD, i.e. so that it is stable at the high-available level.
What is being done next? Further under each type of resources there is a certain controller. It is just a service that monitors its type of resource and does something in the outside world. For example, does the docker run. If we have a POD, for each Node there is a kubelet-service, which monitors the PODs that go to this node. And all he does is a Docker run after another periodic check, if this POD is not.
Further, which is very important - everything happens in real time, so the power of this controller is above the minimum. Often, the controller still removes metrics and looks at what it has launched. Those. takes feedback from the real world and writes it to the database so that you or other controllers can see it. For example, the same POD status will be written back to ETCD.
Thus, everything is implemented in Kubernetes. It is very cool that the information model is separated from the operating room. In the database, through the usual CRUD interface, we declare what should be. Then a set of controllers tries to make it all right. True, this is not always the case.
This is a cybernetic model. We have a certain preset, there is some kind of machine that is trying to direct the real world or the machine into the place that is needed. It doesn't always work that way: we should have a feedback loop. Sometimes the machine can not do this and should appeal to the person.
In real systems, we think of abstractions of the following level: we have certain services, databases, and we connect all this. We do not think of PODs and Ingress, and we want to build some next level of abstraction.
So that the developer was as easy as possible: so that he simply said, “I want to launch such a service,” and everything else happened inside.
There is such a thing as HELM. This is the wrong way - the template is ansible style, where we just try to generate a set of configured resources and throw them into the Kubernetes cluster.
The problem, firstly, is that it is performed only at the time of rolling. That is a lot of logic, he can not implement. Secondly, this abstraction disappears in runtime. When I go to look at my cluster, I just see the PODs and services. I do not see that such and such a service is affected, that such a base with replication is raised there. I just see there are dozens of pods. Abstraction disappears in the matrix.
Internal solution model
On the other hand, Kubernetes itself already inside gives a very interesting and simple extension model. We can announce new types of resources, such as deployment. This is a resource built on top of a POD or replicaset. We can write a controller to this resource, put this resource in the database and launch our cybernetic loop so that everything works. This sounds interesting, and I think this is the right way to expand Kubernetes.
I would like to be able to just write a kind of manifest for my service in the heroku style. A very simple example: I want to enclose some kind of application in my real environment. There are already agreements, SSL, domains purchased. I just wanted to give developers the easiest interface possible. Manifest tells me which container to lift, what resources this container still needs. He casts this ad in the cluster, and everything starts to work.
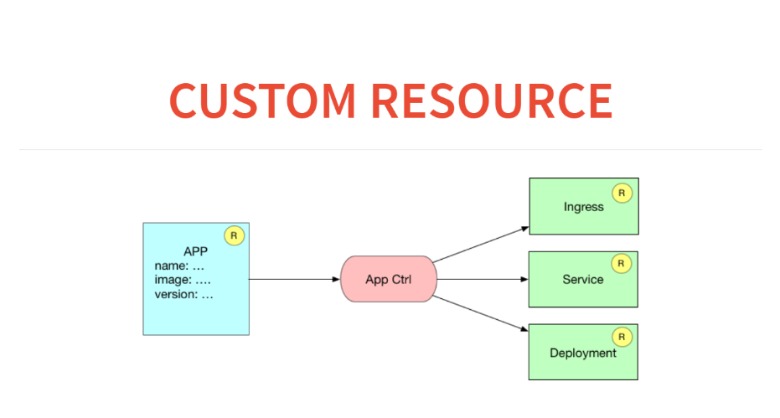
What will it look like in terms of custom resources and controllers? Here we will have to be in the resource application database. And the application controller will spawn three resources. That is, he will register in ingress the rules on how to route to this service, start the service for load balancing and launch the deployment with some configuration.
Before we create a custom resource in Kubernetes, we need to declare it. For this, there is a meta-resource called CustomResourceDefinition.
In order to announce a new resource in Kubernetes, we just need to zaplapit here such an ad. Read this create table.
Created a table. After that we can look through the kubectl get to the third-party resources that we have. As soon as we announced it, we also got an apish. We can do, for example, kubeclt get apps. But so far no appov there.
Let's write some app. After that we can make a custom resource instance. Let's look at it in YAML and create it by posting to a specific URL.
If we run and see through kubectl, then one app appeared. But while nothing happens, it just lies in the database. You can, for example, take and request all app resources.
We can create a second such resource from the same template, simply by changing the name. Here came the second resource.
Next, our controller should do the templating, similar to what HELM does. That is, having received a description of our app, I have to generate a resource deployment and resource service, and also make an entry in the ingress. This is the easiest part: here in clojure, it's erlmacro. I transfer the data structure, it jerks the deployment function, passes to the debug, which is the pipeline. And this is a pure function: simple templating. Accordingly, in the most naive form, I could immediately create it, turn it into a console utility and start distributing.
We do the same for the service: the service function accepts a declaration and generates the Kubernetes resource for us.
We do the same for the ingress line.
How will it all work? There will be something in the real world and there will be what we want. What we want is we take the application resource and generate it for what should be. And now we need to see what is. What we have is requested through the REST API. We can get all the services, all deployments.
How will our custom controller work? He will receive what we want and what is, take from this div and apply to Kubernetes. This is similar to React. I came up with a virtual DOM, when some functions simply generate a tree of JS objects. And then a certain algorithm calculates the patch and applies it to the real DOM.
We will do the same here. This is done in 50 lines of code. Want it - everything is on Github. As a result, we should get the function reconcile-actions.
We have a reconcile-actions function that does nothing and just computes this div. She takes what is, plus what is needed. And then gives what needs to be done to bring the first to the second.
Let's jerk her. There is nothing wrong with it, you can debug it. She says that you need to create an ingress-service, make two entries in it, create deployment 1 and 2, create service 1 and 2.
In this case, there should already be only one service. We see by ingress that only one record remains.
Next, all that remains is to write a function that applies this patch to the Kubernetes cluster. To do this, we simply pass the reconcile-actions to the reconcile function, and everything will apply. And here we see that POD has risen, deployment has become, and the service has started.
Let's add one more service: once again we will execute the function reconcile-actions. Let's see what happened. Everything started, all is well.
How to deal with this? We all pack it in Docker-container. After this, we write a function that periodically wakes up, makes reconcile and falls asleep. The speed is not very important, it can sleep for five seconds and do reconcile-actions less often.
Our custom controller is just a service that will wake up and periodically calculate a patch.
Now we have two services zepeploino, let's remove one of the applications. Let's see how our cluster responded: everything is ok. Remove the second: everything is cleared.
Let's see through the eyes of the developer. He just needs to say Kubernetes apply and set the name of the new service. We do this, our controller has picked up and created everything.
Next, we collect all of this into the deployment service, and with the standard Kubernetes tools we throw this custom controller into a cluster. We have created an abstraction for 200 lines of code.
It's all like HELM, but actually more powerful. The controller works in a cluster: it sees the base, sees the outside world and can be made quite clever.
Own CI
Consider the Kubernetes extension examples. We decided that CI should be part of the infrastructure. This is good, it is convenient from the point of view of security - a private repository. We tried to use jenkins, but it is an obsolete tool. I wanted a hacker CI. We do not need interfaces, we love ChatOps: let them just say in chat whether the build is down or not. In addition, I wanted to debug everything locally.
We sat down and wrote our CI in a week. Just as an extension to Kubernetes. If you think about CI, then this is just a tool that runs some jobs. As part of this job, we are building something, running tests, often deploying.
How does all this work? It is built on the same concept of custom controllers. First, we drop the description of what repositories we are watching in Kubernetes. The controller simply goes to the githab and adds a web hook. We are left with introspection.
Next comes the web-hook, whose only task is to process the incoming JSON and throw it into the custom build resource, which also adds up to the Kubernetes database. The build resource is monitored by the build controller, which reads the manifest inside the project and starts the POD. This POD-e runs all the necessary services.
The POD has a very simple agent that reads a travis or circleci style declaration, and a set of steps in YAML. He starts to perform them. After that, at the end of the build, he casts his result in the Telegram.
Another feature that we got together with Kubernetes is that one of the commands in the execution of your CI or continuous delivery can be put just while true sleep 10, and your POD will freeze at this step. You do kubectl exec, you are inside your build and you can debug.
Another feature - everything is built on dockers and you can debug the script locally by launching the docker. It all took two weeks and 300 lines of code.
Working with postgres
Our product is built on postgres, we use all its interesting features. We even wrote a number of extensions. But we can not use RDS or something else.
We are now in the process of developing an operator for non-killed postgres. Voiced architecture. I want to say "Cluster, give me postgres, which can not be killed." Add to this that I need two asynchronous replicas, one synchronous, backups daily and up to a terabyte. I throw it all over, further on my cluster controller begins to engage in orchestrating and unfolding my container. It creates pginstance resources that are responsible for each istance postgres. This will be cluster postgres.
Next is the pginstance controller, simple enough, just trying to run a POD or deployment there with this postgres. The heart is a persistent volume. This whole machine takes full control of postgres. You give her a Docker-container in which there is only binary postgres. Everything else: the configuration and creation of the start cluster postgres is done by the controller itself. He does this so that we can reconfigure later, and so that he can configure replication, log levels, etc. At the beginning, the temporary POD travels over the persistent volume and creates a postgres cluster for the master there.
Then, deployment starts with master. Then persistent volume is created in the same way. Another POD travels, makes a basic backup, tightens it, and deployment starts from a slave on top of this.
Next cluster controller creates a backup resource (after it described backups). And the backup controller already takes it and throws it into some S3.
What's next?
Let's imagine with you the near future. It may happen that sooner or later we will have such interesting custom resources, custom controllers, that I will say “Give me postgres, give me kafka, leave me CI and start all this”. Everything will be easy.
If we are not talking about the near future, then, as a declarative programmer, I believe that the above functional programming is only logical or relational. There we have operations semantics completely separated from information semantics. If we look carefully at our custom controllers that we did, then we have in the database, for example, a resource application. And we derive three additional resources from it. This is very similar to the view in the database. This is a deduction of facts. This is a logical or relation view.
The next step for Kubernetes is, instead of chopped REST API, to give some illusion of a relational or logical base, where you can simply write a rule. Since sooner or later everything flows to the database, including feedback, the rules may sound like this: “If the load has increased like this, then increase the replication like this.” We will have a small sql or logical rule. All you need is a generic engine that will monitor this. But this is a bright future.
More cool reports at the DevOops 2018 conference ! All speakers and program - on the site .
If your home is on the shelf “The DevOps Handbook” , “Learning Chef: A Guide to Configuration Management and Automation” , “How to containerize your Go code” or the new one “Liquid Software: How To Achieve Achieve “ - bring them to the conference. In the discussion areas after the reports, we will organize small autograph sessions with the authors of these books.
Just think: a unique opportunity to get an autograph from John Willis himself !
And a nice bonus: until October 1Ticket for DevOops 2018 can be booked at a discount.