Virtualization¹
In the previous part, I talked about three IA-32 modes: protected, VM86, and SMM. Although they are not customary to associate with virtualization, they serve to create isolated environments for programs running on the processor. In this article, I will describe the “true” Intel VT-x virtualization technology. I want to show how the theory of effective virtualization is manifested in every aspect of its practical implementation.
On KDPV: Launched under the control of Ubuntu Linux program Oracle VirtualBox, which runs the operating system MS Windows XP, which runs the simulator Bochs, which runs the operating system FreeDOS, which runs the simulator MYZ80 for the processor Z80, which runs the operating system CP / M (in full screen).
In 2006, Intel introduced VT-x, an extension for efficient virtualization of the IA-32 architecture. It includes a set of VMX instructions and two new modes of operation. I do not want to repeat all the documentation here, it is very boring to write and read. However, I will describe some features of the interfaces proposed in it.
It was impossible to manage virtualization with already existing processor modes, because some of the IA-32 instructions that existed at that time were official, but not privileged, and, according to theory, they could not be effectively intercepted and emulated. The new modes were called root and non-root, and they are, in general, orthogonal to all classical modes (although there are features, see below). The first one is for virtual machine monitor, the second is for guest environments. By default, virtualization is unavailable after power on. Entering root mode occurs after executing a new VMXON instruction, and subsequent non-root logins using VMLAUNCH / VMRESUME.
The key process in any hardware virtualization system is to save the current state of the guest processor and load the state of the monitor. In VT-x, everything is done strictly according to the mentioned theory. An entity called VMCS (Virtual Machine Control Structure) is used to store the states of both the guest and the host. This structure should be its own for every active guest. In the following figure, illustrating the transitions between root and non-root modes, two areas are used inside VMCS: guest-state and host-state.
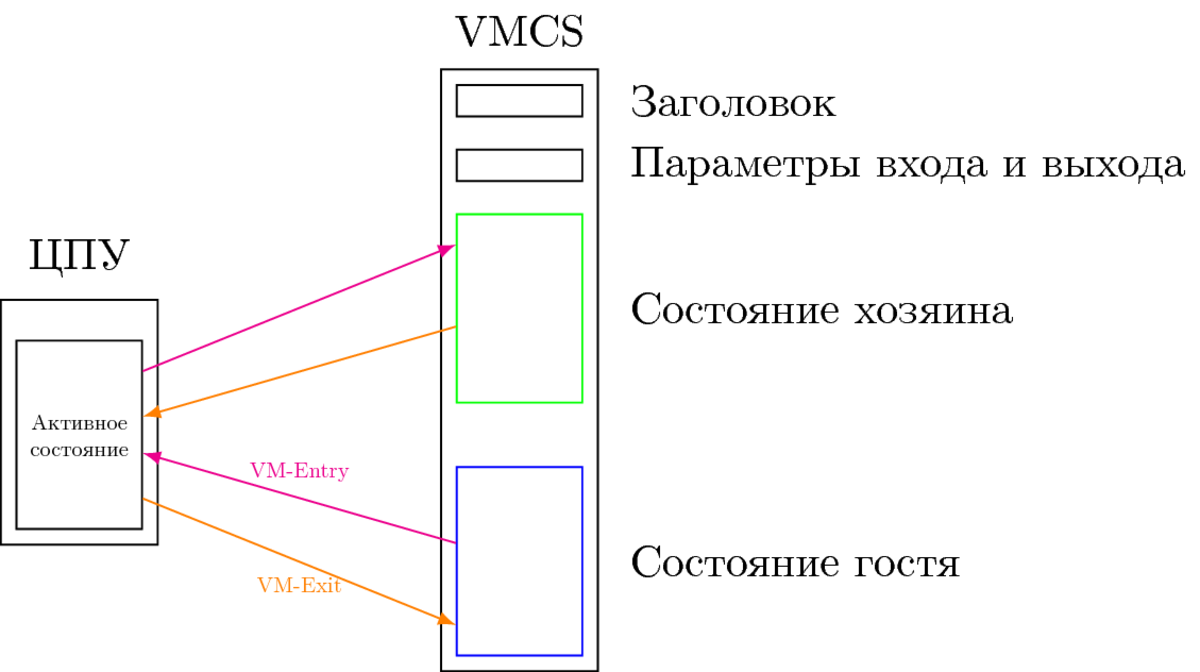
In this figure, the VM-Entry event is one of two instructions: VMLAUNCH or VMRESUME, and VM-Exit is one of many synchronous and asynchronous events declared privileged in the VT-x non-root context and therefore require monitor interception. Details of what and how to load when switching from root to non-root and vice versa are also stored in VMCS in the so-called. VM-entry and VM-exit controls, "entry and exit parameters". Storage areas are divided into fields, each of which stores a register or other processor architectural information.
I want to show how the creators of VT-x have carefully approached versioning and backward compatibility with future implementations. The key design element here is the amazing (given its low level) abstractness of the proposed interface. Instead of describing the layout of the VMCS structure in memory and allowing working with it using the usual LOAD and STORE instructions, two new instructions were introduced: VMREAD and VMWRITE. And they do not operate with byte offsets within the structure, but with encodings of individual fields. Moreover, it is not even guaranteed that all fields in memory store actual values. The processor can cache some of them, thereby speeding up the process of switching modes - data does not have to be loaded from slow memory. He is obliged to unload everything in memory only when VMCLEAR is executed.
As a result of the introduction of this level of indirection, the creators of future VT-x variants will not be tied to the requirements of compatibility of the VMCS layout in memory with existing implementations.
To compare this method with alternatives, look at how the operation of the XSAVE and XRSTOR [1] instructions used to save and restore vector registers is described. Since vector registers after storage are stored in memory, offsets for them can be used in ordinary operations with it. But for the layout of the fields in memory is described in a separate sheet of data returned by the CPUID instruction.
I will continue the story about the features of VT-x, which surprised me with its thoughtfulness (not all of the extensions to the instruction sets can be said this way). Many of them relate to identifying support for existing as well as future extensions to this technology.
Instead of putting VT-x information in the output of the CPUID instruction , new Model-specific register or MSR registers were added. This is quite justified - MSRs can only be read from privileged mode, user applications do not need to know about the features of supporting virtualization of the current processor. The fact that virtualization is supported is reported by a single bit CPUID.1.ECX [5].
The indication mechanism for the supported VT-x extensions is described in Appendix A of Intel SDM [1]. The possibility of evolution passes through all the MSRs presented in the documentation.
So, the IA32_VMX_BASIC register is divided into several fields. One of them contains a revision of the VMCS structure. The equality of revisions of two implementations of VMCS means the equality of the sizes of memory areas for their storage. Bit 55 set in this register means that a number of configuration items that, in the first version of VT-x, had fixed values (only on or only off), in this implementation can already be switched to a different state than the original one.
A complete list of feature MSRs includes registers IA32_VMX_ (TRUE_) PINBASED_CTLS, IA32_VMX_ (TRUE_) PROCBASED_CTLS, IA32_VMX_PROCBSAED_CTLS2, IA32_VMX_ (TRUE_) EXIT_CTMT_TRY_TA32_ IA32. In total, they determine which architectural events can trigger VM-exit, which is acceptable to load with VM-entry. Initially, the set of registers in the first revision of VT-x turned out to be insufficient, so the “TRUE” variants of some of them appeared. For the same reason, PROCBASED_CTLS has been extended with PROCBASED_CTLS2.
Unlike the traditional approach, when for each new feature one bit is set in the register, which means whether it is supported or not, VT-x has two bits for each architecture extension. The first bit means the possibility of turning on some functionality, and the second - turning it off. This affects what bits in the composition of the control fields the VMCS monitor can modify. So, for example, it may turn out that in some processors it will not be possible to turn off VT-exit generation according to the RDRAND instruction, while in others, on the contrary, such an output cannot be turned on.
For those fields that can be in either of the two states, the monitor program is allowed to configure them according to its capabilities and use only those that were embedded in its logic, even if the monitor is running on a more modern processor that offers more efficient techniques.
This solution creates scope for the evolution of both processors and monitor programs of virtual machines. The former can give up support for old features, simply by indicating that they cannot be turned on, and the latter can detect and use only the functionality of the equipment for which they are programmed. This maintains backward compatibility and ensures direct compatibility.
Since so much effort has been spent on supporting VT-x extensions, there must probably be many such extensions. I will talk about some of them in this article, and I will hold the rest for later, when the meaningfulness of their introduction will become more clear.
But first, I want to think about the general development vector of VT-x - why all these extensions exist.
Virtualization must be effective, i.e. make the minimum possible overhead compared with direct guest performance on the equipment. This is formulated as “not to interfere with as many operations as possible”. The general principle of optimization is to accelerate primarily those subsystems that are on the critical path of performance. After eliminating the main bottleneck, go to the next in importance. Consider the order of importance for computing systems.
But what happened to the three processor modes that I described in the previous part of the article? As it turns out, their features also had to be taken into account in virtualization.
Protected mode with segmentation enabled and the page mechanism supported since the very first edition of VT-x. Other modes, including 16-bit real, it was impossible to run directly in non-root mode - an attempt to load such a guest state using VMLAUNCH / VMRESUME would fail. On the one hand, this restriction was reasonable - most of the practically important tasks work in protected mode, and it should be virtualized in the first place.
On the other hand, when loading a traditional OS, the processor, before entering protected mode, is still executed in other modes for some time. In order to support them, the monitor had to have an alternative simulation mechanism - an interpreter, a binary translator, a return to VM86, or something similar. This did not have a positive effect on the amount of monitor code or on the speed of its operation. Therefore, in subsequent generations of VT-x, the so-called Unrestricted Guest mode - execution of guest systems that do not use protected mode.
While root and non-root VT-x modes are running, it is still possible that #SMI interrupts occur, which should unconditionally put the processor into SMM mode. The process of transitions to / from the SMM mode has been modified to take into account the specifics of virtualization.
In the simplest case, logging into SMM looks the same as it did without virtualization. However, at the same time, you still have to maintain an additional architectural state, including a pointer to the current VMCS, the status of the SS.DPL field, the RFLAGS.VM flag, STI and MOV SS locks, and virtual guest NMIs. As a result, the processor actually interrupts the operation of the monitor and all virtual machines and cannot use the capabilities of VT-x until it quits using the RSM instruction. This is not always convenient.
The VT-x extension, called Dual Monitor Treatment, allows the SMM monitor and the virtual machine monitor to cooperate and use the modified VM-exit / entry mechanism to enter and exit SMM. I will list here some features of this option.
Thus, dual monitor facilitates the solution of the difficult question “who is in charge of the house?”, Making the work of two monitors more consistent and symmetrical.
At this point, I hope that I have been able to outline the motivation, main ideas and development directions of Intel VTx. Here I could finish my story, but ...
If some technology is successful, then quite quickly its users begin to come up with completely unexpected ways for its creators to use it, including "Wrong." It did not bypass virtualization. Virtual machines have replaced physical machines in many areas. They began to unite in the clouds, sell / rent. And end users began to run their virtual machines inside the systems they issued. And then it turned out that a similar scenario of nested virtualization was not originally provided for by the creators of the hardware. What has been done in order to support the effective operation of some virtual machines inside others on Intel architecture is the next part of the article.
On KDPV: Launched under the control of Ubuntu Linux program Oracle VirtualBox, which runs the operating system MS Windows XP, which runs the simulator Bochs, which runs the operating system FreeDOS, which runs the simulator MYZ80 for the processor Z80, which runs the operating system CP / M (in full screen).
VT-x
In 2006, Intel introduced VT-x, an extension for efficient virtualization of the IA-32 architecture. It includes a set of VMX instructions and two new modes of operation. I do not want to repeat all the documentation here, it is very boring to write and read. However, I will describe some features of the interfaces proposed in it.
It was impossible to manage virtualization with already existing processor modes, because some of the IA-32 instructions that existed at that time were official, but not privileged, and, according to theory, they could not be effectively intercepted and emulated. The new modes were called root and non-root, and they are, in general, orthogonal to all classical modes (although there are features, see below). The first one is for virtual machine monitor, the second is for guest environments. By default, virtualization is unavailable after power on. Entering root mode occurs after executing a new VMXON instruction, and subsequent non-root logins using VMLAUNCH / VMRESUME.
VMCS
The key process in any hardware virtualization system is to save the current state of the guest processor and load the state of the monitor. In VT-x, everything is done strictly according to the mentioned theory. An entity called VMCS (Virtual Machine Control Structure) is used to store the states of both the guest and the host. This structure should be its own for every active guest. In the following figure, illustrating the transitions between root and non-root modes, two areas are used inside VMCS: guest-state and host-state.
In this figure, the VM-Entry event is one of two instructions: VMLAUNCH or VMRESUME, and VM-Exit is one of many synchronous and asynchronous events declared privileged in the VT-x non-root context and therefore require monitor interception. Details of what and how to load when switching from root to non-root and vice versa are also stored in VMCS in the so-called. VM-entry and VM-exit controls, "entry and exit parameters". Storage areas are divided into fields, each of which stores a register or other processor architectural information.
Work with VMCS
I want to show how the creators of VT-x have carefully approached versioning and backward compatibility with future implementations. The key design element here is the amazing (given its low level) abstractness of the proposed interface. Instead of describing the layout of the VMCS structure in memory and allowing working with it using the usual LOAD and STORE instructions, two new instructions were introduced: VMREAD and VMWRITE. And they do not operate with byte offsets within the structure, but with encodings of individual fields. Moreover, it is not even guaranteed that all fields in memory store actual values. The processor can cache some of them, thereby speeding up the process of switching modes - data does not have to be loaded from slow memory. He is obliged to unload everything in memory only when VMCLEAR is executed.
As a result of the introduction of this level of indirection, the creators of future VT-x variants will not be tied to the requirements of compatibility of the VMCS layout in memory with existing implementations.
To compare this method with alternatives, look at how the operation of the XSAVE and XRSTOR [1] instructions used to save and restore vector registers is described. Since vector registers after storage are stored in memory, offsets for them can be used in ordinary operations with it. But for the layout of the fields in memory is described in a separate sheet of data returned by the CPUID instruction.
Indication of available functionality
I will continue the story about the features of VT-x, which surprised me with its thoughtfulness (not all of the extensions to the instruction sets can be said this way). Many of them relate to identifying support for existing as well as future extensions to this technology.
Instead of putting VT-x information in the output of the CPUID instruction , new Model-specific register or MSR registers were added. This is quite justified - MSRs can only be read from privileged mode, user applications do not need to know about the features of supporting virtualization of the current processor. The fact that virtualization is supported is reported by a single bit CPUID.1.ECX [5].
Versioning and display extensions
The indication mechanism for the supported VT-x extensions is described in Appendix A of Intel SDM [1]. The possibility of evolution passes through all the MSRs presented in the documentation.
So, the IA32_VMX_BASIC register is divided into several fields. One of them contains a revision of the VMCS structure. The equality of revisions of two implementations of VMCS means the equality of the sizes of memory areas for their storage. Bit 55 set in this register means that a number of configuration items that, in the first version of VT-x, had fixed values (only on or only off), in this implementation can already be switched to a different state than the original one.
A complete list of feature MSRs includes registers IA32_VMX_ (TRUE_) PINBASED_CTLS, IA32_VMX_ (TRUE_) PROCBASED_CTLS, IA32_VMX_PROCBSAED_CTLS2, IA32_VMX_ (TRUE_) EXIT_CTMT_TRY_TA32_ IA32. In total, they determine which architectural events can trigger VM-exit, which is acceptable to load with VM-entry. Initially, the set of registers in the first revision of VT-x turned out to be insufficient, so the “TRUE” variants of some of them appeared. For the same reason, PROCBASED_CTLS has been extended with PROCBASED_CTLS2.
Unlike the traditional approach, when for each new feature one bit is set in the register, which means whether it is supported or not, VT-x has two bits for each architecture extension. The first bit means the possibility of turning on some functionality, and the second - turning it off. This affects what bits in the composition of the control fields the VMCS monitor can modify. So, for example, it may turn out that in some processors it will not be possible to turn off VT-exit generation according to the RDRAND instruction, while in others, on the contrary, such an output cannot be turned on.
For those fields that can be in either of the two states, the monitor program is allowed to configure them according to its capabilities and use only those that were embedded in its logic, even if the monitor is running on a more modern processor that offers more efficient techniques.
This solution creates scope for the evolution of both processors and monitor programs of virtual machines. The former can give up support for old features, simply by indicating that they cannot be turned on, and the latter can detect and use only the functionality of the equipment for which they are programmed. This maintains backward compatibility and ensures direct compatibility.
Evolution VT-x
Since so much effort has been spent on supporting VT-x extensions, there must probably be many such extensions. I will talk about some of them in this article, and I will hold the rest for later, when the meaningfulness of their introduction will become more clear.
But first, I want to think about the general development vector of VT-x - why all these extensions exist.
Virtualization must be effective, i.e. make the minimum possible overhead compared with direct guest performance on the equipment. This is formulated as “not to interfere with as many operations as possible”. The general principle of optimization is to accelerate primarily those subsystems that are on the critical path of performance. After eliminating the main bottleneck, go to the next in importance. Consider the order of importance for computing systems.
- Processor instructions. The most important resource is the CPU, and the very first version of VT-x was aimed at the execution of most instructions without slowdown. Subsequent improvements in this direction were aimed at ensuring that even fewer instructions invoked VM-exit, as well as that all processor modes could be virtualized (see the sections on Unrestricted Guest and SMM later in this article).
- Work with memory. Here, a frequent but potentially slow operation is the translation of linear addresses into physical ones. Its details and solution are described in my previous article, so I won’t repeat it. In IA-32, the corresponding extension is called Intel EPT (English Extended Page Translation), and it works according to theory. A resource such as TLB also required virtualization, and it was provided with the introduction of VPID, a technique for associating its entries with individual guests.
- Virtual APIC (English Advanced Programmable Interrupt Controller). The interrupt controller may turn out to be a bottleneck in monitor performance, since the load on it increases with the number of simultaneously running virtual machines (and the intensity of interruptions in the system). Therefore, several VT-x extensions were made for virtualizing APIC functions: virtual memory page for APIC registers, TPR shadow, CR8 load exiting, virtualize x2APIC mode.
- Peripheral devices that require a wide bandwidth to operate, such as graphics accelerators. For these devices, it is necessary to efficiently translate addresses in memory for DMA, as well as handle interrupts, in both cases doing this with minimal monitor involvement. For this functionality is no longer the specification of Intel VT-x, but Intel VT-d [2].
But what happened to the three processor modes that I described in the previous part of the article? As it turns out, their features also had to be taken into account in virtualization.
Unrestricted guest
Protected mode with segmentation enabled and the page mechanism supported since the very first edition of VT-x. Other modes, including 16-bit real, it was impossible to run directly in non-root mode - an attempt to load such a guest state using VMLAUNCH / VMRESUME would fail. On the one hand, this restriction was reasonable - most of the practically important tasks work in protected mode, and it should be virtualized in the first place.
On the other hand, when loading a traditional OS, the processor, before entering protected mode, is still executed in other modes for some time. In order to support them, the monitor had to have an alternative simulation mechanism - an interpreter, a binary translator, a return to VM86, or something similar. This did not have a positive effect on the amount of monitor code or on the speed of its operation. Therefore, in subsequent generations of VT-x, the so-called Unrestricted Guest mode - execution of guest systems that do not use protected mode.
SMM Interaction
While root and non-root VT-x modes are running, it is still possible that #SMI interrupts occur, which should unconditionally put the processor into SMM mode. The process of transitions to / from the SMM mode has been modified to take into account the specifics of virtualization.
In the simplest case, logging into SMM looks the same as it did without virtualization. However, at the same time, you still have to maintain an additional architectural state, including a pointer to the current VMCS, the status of the SS.DPL field, the RFLAGS.VM flag, STI and MOV SS locks, and virtual guest NMIs. As a result, the processor actually interrupts the operation of the monitor and all virtual machines and cannot use the capabilities of VT-x until it quits using the RSM instruction. This is not always convenient.
The VT-x extension, called Dual Monitor Treatment, allows the SMM monitor and the virtual machine monitor to cooperate and use the modified VM-exit / entry mechanism to enter and exit SMM. I will list here some features of this option.
- The transition to SMM is handled by a special kind of VM-exit, called SMM VM exit. The processes that occur in this case have some differences from ordinary VM-exit events.
- SMM VM exit is the only type of exit that can happen inside root mode , i.e. while the virtual machine monitor is running. Regular VM-exit can happen only during the work of guests.
- A separate VMCS is allocated for state storage and transition management SMM VM-exit.
- If in the classic case the RSM instruction was used to end work in SMM mode, then when virtualization is turned on, it uses the usual VM entry, which is returned either to the monitor (if the output was from root mode) or to the guest environment (in non- root).
- Logging into SMM is possible explicitly from root mode, using the VMCALL instruction, and not just by interrupting #SMI.
Thus, dual monitor facilitates the solution of the difficult question “who is in charge of the house?”, Making the work of two monitors more consistent and symmetrical.
At this point, I hope that I have been able to outline the motivation, main ideas and development directions of Intel VTx. Here I could finish my story, but ...
To be continued
If some technology is successful, then quite quickly its users begin to come up with completely unexpected ways for its creators to use it, including "Wrong." It did not bypass virtualization. Virtual machines have replaced physical machines in many areas. They began to unite in the clouds, sell / rent. And end users began to run their virtual machines inside the systems they issued. And then it turned out that a similar scenario of nested virtualization was not originally provided for by the creators of the hardware. What has been done in order to support the effective operation of some virtual machines inside others on Intel architecture is the next part of the article.
Literature
- Intel Corporation. Intel 64 and IA-32 Architectures Software Developer's Manual. Volumes 1-3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Intel Corporation. Intel Virtualization Technology for Directed I / O Architecture Specification. 2013. www.intel.com/content/www/us/en/intelligent-systems/intel-technology/vt-directed-io-spec.html