The use of machine learning in trading
- Transfer
- Tutorial
Translator's Note 1. I came across this blog in one of the machine learning material reviews. If you are well versed in machine learning, then in this article you will not find anything interesting for yourself. It is quite superficial and affects only the basics. If you, like me, are just starting to become interested in this topic, then welcome to cat.
Translator’s note 2. The code will be small, and the one that is written in the R language, but do not despair if you have never seen it in your eyes. Prior to this article, I also did not know anything about him, so I specially wrote a “spur” in language, including everything that you will find in the article. If you want to figure it out for yourself, then I recommend starting with a small course at CodeSchool. The habr also has interesting information and useful links . And finally , there is a big cheat sheet.
Translator's note 3. An article is in two parts, but the most interesting part begins only in the second part, so I allowed myself to combine them into one article.

In this series of articles, I’m going to build and test a simple machine learning based asset management strategy step by step. The first part will be devoted to the basic concepts of machine learning and their application to financial markets.
Machine learning is one of the most promising areas in financial mathematics, which in recent years has gained a reputation as a sophisticated and complex tool. In reality, everything is not so complicated.
The goal of machine learning is to build an accurate model based on historical data and then use this model for predictions in the future. In financial mathematics, using machine learning, the following tasks are solved:
Consider a simple example. Let's try to predict the movement of the value of Google stocks one day in advance. In the next part we will use several indicators, but now, to study the basics, we will use only one indicator: day of the week. So, let's try to predict the price movement based on the day of the week.
Below is a graph of Google stocks and a picture of exported data from Yahoo Finance.


I added the day of the week column and the closing price column minus the opening price. Also, I added a price direction column where I write “UP” if the difference between the closing and opening prices is more than 0 and “DOWN” if less:
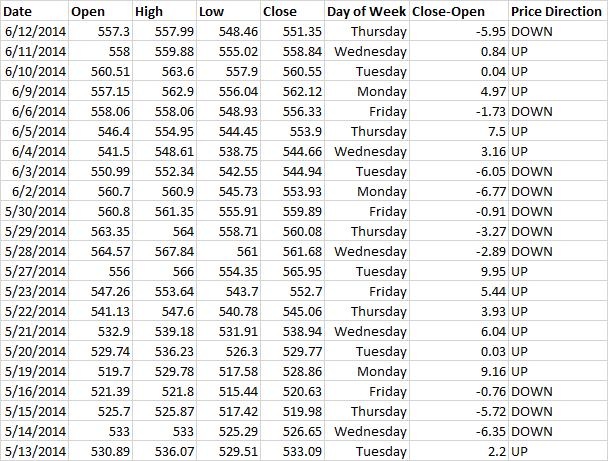
In machine learning, this data set will be called training because the algorithm is trained on them. In other words, the algorithm scans the entire data set and establishes the relationship between the day of the week and the direction of the change in the value of the stock. Note that our set is small - there are only 23 lines. In the next part, we will use hundreds of lines to build the model. In fact, the more data, the better.
Now let's choose an algorithm. There are a number of algorithms that you can use, including hidden Markov Models, artificial neural networks, a naive Bayesian classifier, a support vector method, a decision tree, analysis of variance and many others. Here is a good listwhere you can understand each algorithm and understand when and which one to apply. To begin with, I recommend using one of the most commonly used algorithms, for example, the support vector method or the naive Bayesian classifier. Do not spend a lot of time choosing, the most important parts of your analysis are the indicators that you use and the value that you predict.
Now that we’ve figured out the basic concept of using machine learning algorithms in your strategy, we’ll look at a simple example of using the naive Bayes classifier to predict Apple stock direction. First, we will understand how this classifier works, then we will consider a very simple example of using the day of the week to predict price movements, and in the end we will complicate the model by adding a technical indicator.
Bayes formula allows you to find the probability that event A will happen if it is known that event B has already occurred. It is usually designated as: P (A | B).
In our example, we ask: "What is the likelihood that today's price will rise if it is known that today is Wednesday?" The method takes into account both the probability that today's price will rise based on the total number of days during which growth was observed, and based on the fact that today is Wednesday, that is, how many times the price rose on Wednesday.
We have the opportunity to compare the likelihood that today's price will rise and the likelihood that it will fall, and use the highest value as a forecast.
So far, we have discussed only one indicator, but as soon as there are several of them, all mathematics is quickly complicated. To prevent this, a naive Bayesian classifier is used ( here's a good article). It treats each indicator as independent, or not correlated (hence the term naive). Therefore, it is important to use indicators that are weakly or not related at all.
This is a very simplified description of the naive Bayes classifier, if you are interested in learning more about it, as well as about other machine learning algorithms, look here
Now let's look at a very simple example on R. We will use the day of the week to predict whether Apple's stock price will move up or down.
First, let's make sure that we have all the libraries we need:
Now let's get the data we need:
Now that we have all the necessary data, let's get our “day of the week” indicator:
What we are going to predict, i.e. moving the price up or down and creating the final data set:
Now we are ready to apply the naive Bayes classifier:
Congratulations! We used machine learning to analyze Apple stocks. Now let's look at the results.

Displays the probability of a price increase or decrease based on an initial data set (known as previous probabilities). We can see a slight bearish bias.

Conditional probabilities are displayed here (the probability of price increase or fall for each day of the week is indicated).
It can be seen that the model is not very good, because it does not return high probabilities. Nevertheless, it is noticeable that it is better to open long positions at the beginning of the week, and shorten closer to the end.
Obviously, you will want to use a more complex strategy than just targeting the day of the week. Let's add a moving average intersection to our model (you can get more information about adding various indicators to your model here )
I prefer to use exponential moving averages, so let's look at 5-day and 10-day exponential moving averages (EMA).
First we need to calculate the EMA:
Then we calculate the intersection:
Now round up the values to 2 decimal places. This is important, because if you get a value that the naive Bayesian classifier did not see during training, it will automatically calculate the probability of 0%. For example, if we look at the EMA intersection with an accuracy of 6 digits, and a high probability of a price movement down was found when the difference was $ 2.349181, and then a new data point was presented that had a difference of $ 2.349182, a 0% probability of increase or price reduction. By rounding to 2 decimal places, we reduce the risk of encountering an unknown value for the model (provided that a sufficiently large data set was used for training, in which all indicator values are likely to be found). This is an important limitation to keep in mind when building your own models.
Let's create a new dataset and divide the data into a training and test set. Thus, we can understand how well our model works on new data.
Now build a model:

The conditional probability of the intersection of moving averages is a number that shows the average value for each case ([, 1]) and for the standard deviation ([, 2]). We can see that on average the difference between the 5-day EMA and the 10-day EMA for long and short trades was $ 0.54 and - $ 0.24, respectively.
Now test on the new data:

A total of 164 days in the test sample. Moreover, the predictions of our model coincided with real data 79 times or in 48% of cases.
This result cannot be called good, but it should give you an idea of how to build your own machine learning strategy. In the next part, we will see how you can use this model to improve your strategy.
Translator's Note 5. To date, there are 2 more articles from this series: about the decision tree and about neural networks. Articles in the same style, i.e. not deep, but only giving a general idea of the issue. If interested, I will continue to translate. About all comments, inaccuracies and other errors, write in a personal.
Translator’s note 2. The code will be small, and the one that is written in the R language, but do not despair if you have never seen it in your eyes. Prior to this article, I also did not know anything about him, so I specially wrote a “spur” in language, including everything that you will find in the article. If you want to figure it out for yourself, then I recommend starting with a small course at CodeSchool. The habr also has interesting information and useful links . And finally , there is a big cheat sheet.
Translator's note 3. An article is in two parts, but the most interesting part begins only in the second part, so I allowed myself to combine them into one article.
Part 1
In this series of articles, I’m going to build and test a simple machine learning based asset management strategy step by step. The first part will be devoted to the basic concepts of machine learning and their application to financial markets.
Machine learning is one of the most promising areas in financial mathematics, which in recent years has gained a reputation as a sophisticated and complex tool. In reality, everything is not so complicated.
The goal of machine learning is to build an accurate model based on historical data and then use this model for predictions in the future. In financial mathematics, using machine learning, the following tasks are solved:
- Regression. Used to predict the direction and value of a quantity. For example, a $ 7.00 increase in the value of Google shares per day.
- Classification. Used to predict categories, such as the direction of the price of Google stocks per day.
Consider a simple example. Let's try to predict the movement of the value of Google stocks one day in advance. In the next part we will use several indicators, but now, to study the basics, we will use only one indicator: day of the week. So, let's try to predict the price movement based on the day of the week.
Below is a graph of Google stocks and a picture of exported data from Yahoo Finance.
I added the day of the week column and the closing price column minus the opening price. Also, I added a price direction column where I write “UP” if the difference between the closing and opening prices is more than 0 and “DOWN” if less:
In machine learning, this data set will be called training because the algorithm is trained on them. In other words, the algorithm scans the entire data set and establishes the relationship between the day of the week and the direction of the change in the value of the stock. Note that our set is small - there are only 23 lines. In the next part, we will use hundreds of lines to build the model. In fact, the more data, the better.
Now let's choose an algorithm. There are a number of algorithms that you can use, including hidden Markov Models, artificial neural networks, a naive Bayesian classifier, a support vector method, a decision tree, analysis of variance and many others. Here is a good listwhere you can understand each algorithm and understand when and which one to apply. To begin with, I recommend using one of the most commonly used algorithms, for example, the support vector method or the naive Bayesian classifier. Do not spend a lot of time choosing, the most important parts of your analysis are the indicators that you use and the value that you predict.
Part 2
Now that we’ve figured out the basic concept of using machine learning algorithms in your strategy, we’ll look at a simple example of using the naive Bayes classifier to predict Apple stock direction. First, we will understand how this classifier works, then we will consider a very simple example of using the day of the week to predict price movements, and in the end we will complicate the model by adding a technical indicator.
What is a naive Bayes classifier?
Bayes formula allows you to find the probability that event A will happen if it is known that event B has already occurred. It is usually designated as: P (A | B).
In our example, we ask: "What is the likelihood that today's price will rise if it is known that today is Wednesday?" The method takes into account both the probability that today's price will rise based on the total number of days during which growth was observed, and based on the fact that today is Wednesday, that is, how many times the price rose on Wednesday.
We have the opportunity to compare the likelihood that today's price will rise and the likelihood that it will fall, and use the highest value as a forecast.
So far, we have discussed only one indicator, but as soon as there are several of them, all mathematics is quickly complicated. To prevent this, a naive Bayesian classifier is used ( here's a good article). It treats each indicator as independent, or not correlated (hence the term naive). Therefore, it is important to use indicators that are weakly or not related at all.
This is a very simplified description of the naive Bayes classifier, if you are interested in learning more about it, as well as about other machine learning algorithms, look here
Step-by-step example on R
Spur on R
For work you will need:
The language itself is very simple. Script files can not be created - everything is written directly to the console.
Now, in order, all that will meet:
The language is not a strict typification, there is no need to declare variables. To assign a value, use the "<-" sign.
For example:
The vector is assigned as follows:
There is a special type - data frame. Visually, it is easiest to present in a table. For example (taken from CodeSchool):
You can specify a range of rows / columns. For example, to display all columns from line 1 to 4, you would write:
To display all rows and only the second column:
In the language itself, initially there are not many functions, so some libraries will need to be connected to work. For this, it is prescribed:
When calling functions, additional parameters are written like this: parameter_name = value. For instance:
Specifically, this function uploads stock price data from yahoo. More details about it in the manual: www.quantmod.com/documentation/getSymbols.html
With the rest I think there will be no questions.
- R language interpreter
- As an IDE, I used RStudio .
The language itself is very simple. Script files can not be created - everything is written directly to the console.
Now, in order, all that will meet:
The language is not a strict typification, there is no need to declare variables. To assign a value, use the "<-" sign.
For example:
a <- 1.
The vector is assigned as follows:
a <- c(1,2,3)
There is a special type - data frame. Visually, it is easiest to present in a table. For example (taken from CodeSchool):
> weights <- c(300, 200, 100, 250, 150)
> prices <- c(9000, 5000, 12000, 7500, 18000)
> types <- c(1, 2, 3, 2, 3)
> treasure <- data.frame(weights, prices, types)
> print(treasure)
weights prices types
1 300 9000 1
2 200 5000 2
3 100 12000 3
4 250 7500 2
5 150 18000 3
You can specify a range of rows / columns. For example, to display all columns from line 1 to 4, you would write:
treasure[1:4,]
To display all rows and only the second column:
treasure[,2]
In the language itself, initially there are not many functions, so some libraries will need to be connected to work. For this, it is prescribed:
install.packages("lib_name")
library("lib_name")
When calling functions, additional parameters are written like this: parameter_name = value. For instance:
getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate)
Specifically, this function uploads stock price data from yahoo. More details about it in the manual: www.quantmod.com/documentation/getSymbols.html
With the rest I think there will be no questions.
Now let's look at a very simple example on R. We will use the day of the week to predict whether Apple's stock price will move up or down.
First, let's make sure that we have all the libraries we need:
install.packages("quantmod")
library("quantmod")
#Позволяет импортировать данные
install.packages("lubridate")
library("lubridate")
#Упрощает работу с датами
install.packages("e1071")
library("e1071")
#Дает доступ к алгоритму наивного байесовского классификатора
Now let's get the data we need:
startDate = as.Date("2012-01-01")
#Начало рассматриваемого промежутка
endDate = as.Date("2014-01-01")
#Конец рассматриваемого промежутка
getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate)
#Получаем дневное OHLCV акций Apple с Yahoo FinanceNow that we have all the necessary data, let's get our “day of the week” indicator:
DayofWeek<-wday(AAPL, label=TRUE)
#Находим день неделиWhat we are going to predict, i.e. moving the price up or down and creating the final data set:
PriceChange<- Cl(AAPL) - Op(AAPL)
#Находим разницу между ценой закрытия и ценой открытия.
Class<-ifelse(PriceChange>0, "UP","DOWN")
#Конвертируем в двоичную классификацию. (В наших данных не встречаются дни, когда цена открытия была равна цене закрытия, т. е. изменение было равно нулю, поэтому для упрощения мы не рассматриваем этот случай)
DataSet<-data.frame(DayofWeek,Class)
#Создаем наш набор данных
Now we are ready to apply the naive Bayes classifier:
MyModel<-naiveBayes(DataSet[,1],DataSet[,2])
#Входное значение, или независимая переменная (DataSet[,1]), и то, что мы собираемся предсказывать, зависимая переменная (DataSet[,2]).Congratulations! We used machine learning to analyze Apple stocks. Now let's look at the results.
Displays the probability of a price increase or decrease based on an initial data set (known as previous probabilities). We can see a slight bearish bias.
Conditional probabilities are displayed here (the probability of price increase or fall for each day of the week is indicated).
It can be seen that the model is not very good, because it does not return high probabilities. Nevertheless, it is noticeable that it is better to open long positions at the beginning of the week, and shorten closer to the end.
Improving the model
Obviously, you will want to use a more complex strategy than just targeting the day of the week. Let's add a moving average intersection to our model (you can get more information about adding various indicators to your model here )
I prefer to use exponential moving averages, so let's look at 5-day and 10-day exponential moving averages (EMA).
First we need to calculate the EMA:
EMA5<-EMA(Op(AAPL),n = 5)
#Мы рассчитываем 5-периодную EMA по цене открытия
EMA10<-EMA(Op(AAPL),n = 10)
#Затем 10-ти периодную EMA, так же по цене открытия
Then we calculate the intersection:
EMACross <- EMA5 - EMA10
#Положительные значения будут означать что EMA5 расположена на графике выше EMA10Now round up the values to 2 decimal places. This is important, because if you get a value that the naive Bayesian classifier did not see during training, it will automatically calculate the probability of 0%. For example, if we look at the EMA intersection with an accuracy of 6 digits, and a high probability of a price movement down was found when the difference was $ 2.349181, and then a new data point was presented that had a difference of $ 2.349182, a 0% probability of increase or price reduction. By rounding to 2 decimal places, we reduce the risk of encountering an unknown value for the model (provided that a sufficiently large data set was used for training, in which all indicator values are likely to be found). This is an important limitation to keep in mind when building your own models.
EMACross<-round(EMACross,2)Let's create a new dataset and divide the data into a training and test set. Thus, we can understand how well our model works on new data.
DataSet2<-data.frame(DayofWeek,EMACross, Class)
DataSet2<-DataSet2[-c(1:10),]
#Нам нужно удалить значения, в которых 10-периодная скользящая средняя все еще не рассчитана
TrainingSet<-DataSet2[1:328,]
#Мы используем 2/3 данных для обучения модели
TestSet<-DataSet2[329:492,]
#И 1/3 для тестирования моделиNow build a model:
EMACrossModel<-naiveBayes(TrainingSet[,1:2],TrainingSet[,3])The conditional probability of the intersection of moving averages is a number that shows the average value for each case ([, 1]) and for the standard deviation ([, 2]). We can see that on average the difference between the 5-day EMA and the 10-day EMA for long and short trades was $ 0.54 and - $ 0.24, respectively.
Now test on the new data:
table(predict(EMACrossModel,TestSet),TestSet[,3],dnn=list('predicted','actual'))Translator Note 4
For some reason, for a long time I could not understand how to read this table. For those who also had a hard day: the numbers at the down-down and up-up intersections are the number of days in which the prediction coincided with real data. Accordingly, if you look at the down column and the up line, this is the number of days in which our model predicted an upward movement, but really there was a downward movement.
A total of 164 days in the test sample. Moreover, the predictions of our model coincided with real data 79 times or in 48% of cases.
This result cannot be called good, but it should give you an idea of how to build your own machine learning strategy. In the next part, we will see how you can use this model to improve your strategy.
Translator's Note 5. To date, there are 2 more articles from this series: about the decision tree and about neural networks. Articles in the same style, i.e. not deep, but only giving a general idea of the issue. If interested, I will continue to translate. About all comments, inaccuracies and other errors, write in a personal.