Distributed Computing: A Little Theory
- Tutorial
Nine years ago, I began “in my spare time from my main job” to teach computer disciplines at a university in St. Petersburg. And only relatively recently, to my surprise, I discovered that in our universities there are practically no courses with a focus on the problems of distributed computing. And even on Habré this topic is not disclosed sufficiently! We need to correct the situation right now.
I wanted to devote an article or even a series of articles to this topic. But then I decided to lay out my study guide on the basics of distributed computing, published this year (read, a small book of 155 pages). The result is a hybrid - an article with a link to a book. The book is distributed free of charge and is available in electronic form.
Instead of a prologue.Having started the text of the article, I once again wondered why a programmer needs to know the theoretical foundations of distributed computing. I have heard (and continue to hear) this question from students and specialists already working in the field of IT. Indeed, why, for example, know that “the set of events of distributed computing is partially ordered, not linearly”? What is the everyday practical use of this fundamental knowledge, so to speak?
I must admit that I do not have a ready-made memorized answer that I can give out without hesitation. Therefore, each time you have to strain yourself with convolutions, and each time the answers and arguments are different. And now everything is like the first time ...
Let's try to start from afar. And to make it clearer - with medicine. Because, if it comes to medical errors, the brain begins to work actively and generate strong indignation: horror, horror, they could kill a person. What are they there, or what? Do not they know what they are doing?
We all completely naturally expect that before starting any manipulations with the human body, doctors still study its internal structure and principles of work. We absolutely disagree with the statement that it is much more important for surgeons to take practical courses in cutting and sewing instead of many years of cramming of theoretical material about what we have inside and why it is there. So why do programmers involved in developing a system with network connectivity (that is, to date, almost any system) not need to know "what's inside and why is it there"? Why are errors in IT perceived with maximum irony? Well, yes, well, a bug. And whodoesn’t drink does not make bugs ?! Name it! No, I'm waiting!Among the requirements for programmers, very often for some reason practical skills in mastering one or another programming language come to the fore. And much to the fore, completely overshadowing the requirements for understanding basic concepts, theoretical models, algorithms, in the end ... And the programmers themselves, what a sin, with the start of the conversation "about an unnecessary theory" wither like flowers in the desert ... Miracles , isn’t it ...
I’ll give a short statement by L. Lamport on this topic (a little lower I tried to translate this statement into Russian, not moving very far from the original):
To illustrate how “concepts” and “theory elements” can be important in building distributed systems, let's look at a couple of simple examples. To begin with - a group distribution of e-mail messages between users A, B, C and X. Suppose that user A sends an entire group an email with the subject “General Meeting”. Users B and C respond to it with the whole group with their messages with the subject “Re: General meeting”.
In fact, events occur in the following sequence:
However, due to arbitrary and independent delays in message delivery, some users may see a different sequence of events. For example, according to the scenario shown in the figure below, messages in the user’s mailbox X will be in the following order:
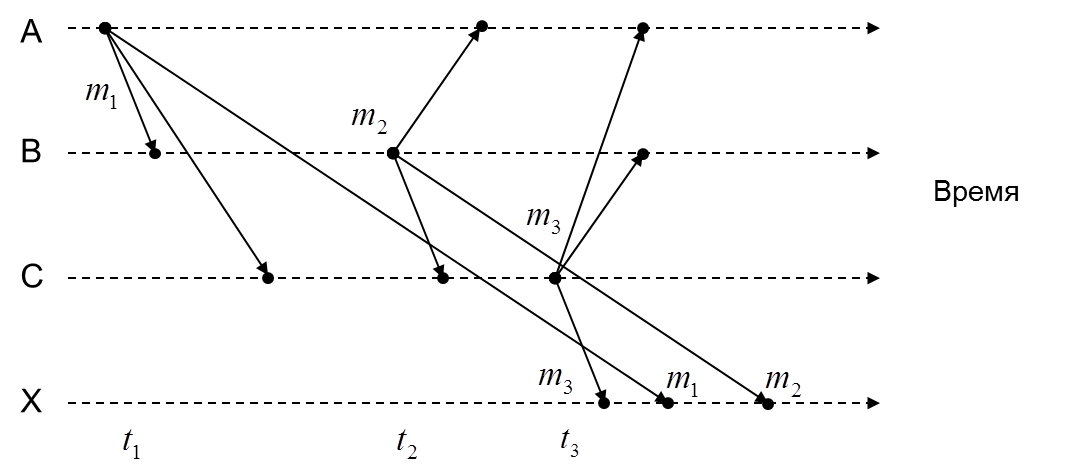
Yeah, it turns out the order in which messages are received, observed by different processes, can be different even for FIFO channels! But what if we want the observed order to be the same everywhere (and still do not want to use synchronous messaging)? For example, if we write our transport with the corresponding guarantees. Or do we want to build a replicated state machine where each replica should process incoming requests in the same order for all replicas so that the states of the replicas do not differ? Question…
Now consider another implementation of a distributed system in which processes interact only through messaging, and each process is engaged in turning on / off the lamp with a certain light. Let the first process control the lamp with red light, the second with yellow, and the third with green. Such a traffic light system. In the figure below, the inclusion of the process of its lantern is indicated by a rectangle, and the shutdown by a vertical line; sending and receiving messages - arrow. Question: can processes determine which lights shone at the same time?
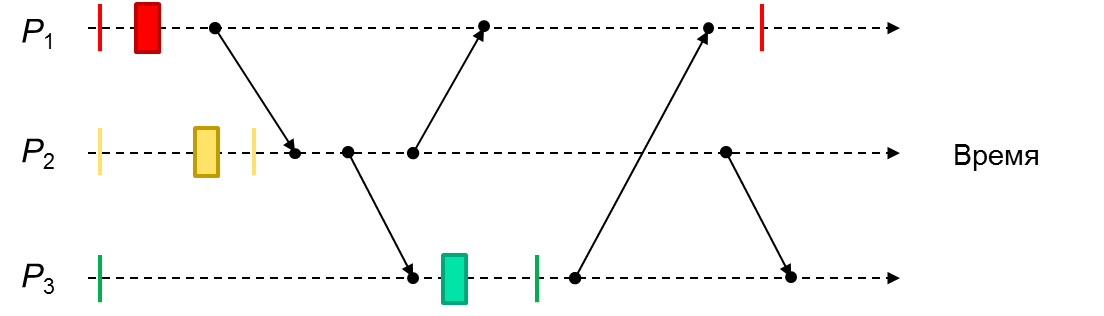
So it turns out that in this embodiment of the asynchronous system, the processes will not be able to determine whether the red light was turned on simultaneously with the yellow one. Maybe yes. Or maybe not ... This will remain unknown. But it will be known for sure that the red and green lights were simultaneously on. In other words, it turns out that it makes little sense to say that this or that global state is reached during the execution of a distributed system! As well as very often it is impossible to say whether any condition (predicate) given on the set of its global states was satisfied! Again the question: why?
Our answer toChamberlain .In fact, the answers to these and many other questions related to the operation of asynchronous distributed systems are extremely difficult to fit into the framework of one article. Therefore, I decided to publish several articles at once in one. More precisely, as indicated at the beginning of the article, submit your small book on the basics of distributed computing, available in electronic form.
Introduction to Distributed Computing >>
From this book you will learn:
What does a book consist of and how to read it?
In the beginning, I tried to briefly state what goals were set when writing the book, and how it relates to other literature. This is the subject of an introduction to the book. It only takes a little more than two pages, so it’s worth reading.
The first section is mostly boltological and is devoted to the “quality” features of distributed systems. If you do not know what a distributed system is and what requirements are imposed on it, then the first section makes sense to read. If you know that the messages received by the recipient process can give an outdated idea of the sender process, just like the light radiation coming to us from a distant star, gives an idea of the state of this star in the past, then the first four points can be skip :) Separately, it is worth noting section 1.5 “Interaction in distributed systems”, in which I tried to give some simple tasks that demonstrate the difficulties that can be encountered in the development of distributed systems. We will then solve these problems, armed with theoretical knowledge,
The second section presents the distributed computing model and the main theory used in the further discussion. In a sense, this section is key. However, one must be prepared to work with such terms as “set / subset”, “binary relation”, “equivalence relation”, “order relation”, “linear / partial order”. In this section you will find evidence of some claims. It seems to me that they should at least be overlooked (or better studied) for a deeper understanding of the essential features of the functioning of distributed systems that distinguish them from systems of other classes.
On the basis of the theory presented above, in the third section, finally, more practical things are considered, namely, the various mechanisms of the logical clock. With their help, we can organize events into one or more sequences that could occur in the system, which allows us to significantly simplify the development of algorithms for distributed systems. Examples of using logical clocks to solve the problems formulated in clause 1.5 “Interaction in distributed systems” are given.
The fourth section is devoted to the study of the basic distributed mutual exclusion algorithms constructed without the use of the usual shared variables. The key ideas of these algorithms are also used to solve many other problems in distributed systems. In addition, their study reveals such important issues as ensuring the security and survivability of distributed algorithms. Therefore, this section seems to me very useful for familiarization.
Who is this book aimed at?
The material of the book should be considered as an introduction to the problems of distributed computing. She grew out of the academic university environment, and will certainly be useful if you are just starting to work in this area. If you already have some experience in developing distributed systems and algorithms, you may find something new for yourself and share your opinion in the comments. If you have many years of experience behind you and are an expert in this topic, I hope that you can complement me with your thoughts and thoughts.
What would I like?
I will be glad if the material of the book is useful and informative for you - there will be time to return here after reading it and to write “thank you”, I will be grateful. In addition, I would like to collect all the material on the topic, including comments, questions and answers in one place, then to send everyone here, including new courses for new students. If you can help and supplement the material with your thoughts, your experience, I will be doubly grateful. Read, gain knowledge and use it in your work! You can download the book in PDF format right now at the link below:
Introduction to Distributed Computing >>
Success!
Mikhail Kosyakov
Instead of an epilogue. "Information, unlike resources, is intended to be shared." Robert Kiyosaki
I wanted to devote an article or even a series of articles to this topic. But then I decided to lay out my study guide on the basics of distributed computing, published this year (read, a small book of 155 pages). The result is a hybrid - an article with a link to a book. The book is distributed free of charge and is available in electronic form.
Instead of a prologue.Having started the text of the article, I once again wondered why a programmer needs to know the theoretical foundations of distributed computing. I have heard (and continue to hear) this question from students and specialists already working in the field of IT. Indeed, why, for example, know that “the set of events of distributed computing is partially ordered, not linearly”? What is the everyday practical use of this fundamental knowledge, so to speak?
I must admit that I do not have a ready-made memorized answer that I can give out without hesitation. Therefore, each time you have to strain yourself with convolutions, and each time the answers and arguments are different. And now everything is like the first time ...
Let's try to start from afar. And to make it clearer - with medicine. Because, if it comes to medical errors, the brain begins to work actively and generate strong indignation: horror, horror, they could kill a person. What are they there, or what? Do not they know what they are doing?
We all completely naturally expect that before starting any manipulations with the human body, doctors still study its internal structure and principles of work. We absolutely disagree with the statement that it is much more important for surgeons to take practical courses in cutting and sewing instead of many years of cramming of theoretical material about what we have inside and why it is there. So why do programmers involved in developing a system with network connectivity (that is, to date, almost any system) not need to know "what's inside and why is it there"? Why are errors in IT perceived with maximum irony? Well, yes, well, a bug. And who
I’ll give a short statement by L. Lamport on this topic (a little lower I tried to translate this statement into Russian, not moving very far from the original):
For quite a while, I've been disturbed by the emphasis on language in computer science. One result of that emphasis is programmers who are C ++ experts but can't write programs that do what they're supposed to. The typical computer science response is that programmers need to use the right programming / specification / development language instead of / in addition to C ++. The typical industrial response is to provide the programmer with better debugging tools, on the theory that we can obtain good programs by putting a monkey at a keyboard and automatically finding the errors in its code.
I believe that the best way to get better programs is to teach programmers how to think better. Thinking is not the ability to manipulate language; it's the ability to manipulate concepts. Computer science should be about concepts, not languages.
For quite a long time, I have been bothered by too much attention paid to the computer language in IT. As a result of an overabundance of such attention, programmers appear who are experts in C ++, but who are not able to write programs that do what is required of these programs. A typical reaction of IT representatives to this problem is to invite programmers to use another more suitable language (programming, specifications, etc.) instead of / in addition to C ++. In turn, the way out of the situation, typical of the software development industry, is to provide programmers with more advanced debugging tools, apparently based on the assumption that you can get good programs simply by putting the monkey on the keyboard and then finding and correcting errors in its code.
My strong belief is that in order to get quality programs, you need to teach programmers to think better. The ability to think is not the ability to operate in computer language; it is the ability to operate on concepts. The study of information technology should focus on the study of concepts, not languages.
To illustrate how “concepts” and “theory elements” can be important in building distributed systems, let's look at a couple of simple examples. To begin with - a group distribution of e-mail messages between users A, B, C and X. Suppose that user A sends an entire group an email with the subject “General Meeting”. Users B and C respond to it with the whole group with their messages with the subject “Re: General meeting”.
In fact, events occur in the following sequence:
- The first message sent from user A.
- User B receives it, reads and sends the response.
- User C receives both messages from A and B and then sends his response based on both messages from A and B.
However, due to arbitrary and independent delays in message delivery, some users may see a different sequence of events. For example, according to the scenario shown in the figure below, messages in the user’s mailbox X will be in the following order:
- Message from user C with the topic "Re: Re: General Meeting".
- Message from user A with the subject, “General Meeting.”
- Message from user B with the topic "Re: General Meeting".
Yeah, it turns out the order in which messages are received, observed by different processes, can be different even for FIFO channels! But what if we want the observed order to be the same everywhere (and still do not want to use synchronous messaging)? For example, if we write our transport with the corresponding guarantees. Or do we want to build a replicated state machine where each replica should process incoming requests in the same order for all replicas so that the states of the replicas do not differ? Question…
Now consider another implementation of a distributed system in which processes interact only through messaging, and each process is engaged in turning on / off the lamp with a certain light. Let the first process control the lamp with red light, the second with yellow, and the third with green. Such a traffic light system. In the figure below, the inclusion of the process of its lantern is indicated by a rectangle, and the shutdown by a vertical line; sending and receiving messages - arrow. Question: can processes determine which lights shone at the same time?
So it turns out that in this embodiment of the asynchronous system, the processes will not be able to determine whether the red light was turned on simultaneously with the yellow one. Maybe yes. Or maybe not ... This will remain unknown. But it will be known for sure that the red and green lights were simultaneously on. In other words, it turns out that it makes little sense to say that this or that global state is reached during the execution of a distributed system! As well as very often it is impossible to say whether any condition (predicate) given on the set of its global states was satisfied! Again the question: why?
Our answer to
Introduction to Distributed Computing >>
From this book you will learn:
- about the causal order of events of distributed computing
- What is justice, security and vitality
- what is the cone of the past and the cone of the future for a computation event
- how logical parallelism differs from physical parallelism
- why it doesn’t make much sense to talk about a set of global states of calculation, but it makes sense to talk about a set of events of calculation
- how can we arrange the events of distributed computing into one or several sequences that “could” occur in the system
- what is a logical clock, and what is a logical time they count
- why does logical time stop if nothing happens in the system
- how is scalar time different from vector
- how and why you can use logical time in distributed algorithms
- what are the approaches to the effective implementation of vector clocks
- why do we need matrix time
- how the distributed algorithm differs from the centralized
- how to solve the problem of mutual exclusion without using shared variables
- what categories are all distributed mutual exclusion algorithms divided into
- why in algorithms based on obtaining permissions logical time is used
- why is it so difficult for philosophers to dine in a distributed system
- why do we need a graph of conflicts and a graph of precedence
- why should the precedence graph change over time
- why in algorithms based on marker transfer there is much more besides “marker transfer” itself
- and I hope something else ...
What does a book consist of and how to read it?
In the beginning, I tried to briefly state what goals were set when writing the book, and how it relates to other literature. This is the subject of an introduction to the book. It only takes a little more than two pages, so it’s worth reading.
The first section is mostly boltological and is devoted to the “quality” features of distributed systems. If you do not know what a distributed system is and what requirements are imposed on it, then the first section makes sense to read. If you know that the messages received by the recipient process can give an outdated idea of the sender process, just like the light radiation coming to us from a distant star, gives an idea of the state of this star in the past, then the first four points can be skip :) Separately, it is worth noting section 1.5 “Interaction in distributed systems”, in which I tried to give some simple tasks that demonstrate the difficulties that can be encountered in the development of distributed systems. We will then solve these problems, armed with theoretical knowledge,
The second section presents the distributed computing model and the main theory used in the further discussion. In a sense, this section is key. However, one must be prepared to work with such terms as “set / subset”, “binary relation”, “equivalence relation”, “order relation”, “linear / partial order”. In this section you will find evidence of some claims. It seems to me that they should at least be overlooked (or better studied) for a deeper understanding of the essential features of the functioning of distributed systems that distinguish them from systems of other classes.
On the basis of the theory presented above, in the third section, finally, more practical things are considered, namely, the various mechanisms of the logical clock. With their help, we can organize events into one or more sequences that could occur in the system, which allows us to significantly simplify the development of algorithms for distributed systems. Examples of using logical clocks to solve the problems formulated in clause 1.5 “Interaction in distributed systems” are given.
The fourth section is devoted to the study of the basic distributed mutual exclusion algorithms constructed without the use of the usual shared variables. The key ideas of these algorithms are also used to solve many other problems in distributed systems. In addition, their study reveals such important issues as ensuring the security and survivability of distributed algorithms. Therefore, this section seems to me very useful for familiarization.
Who is this book aimed at?
The material of the book should be considered as an introduction to the problems of distributed computing. She grew out of the academic university environment, and will certainly be useful if you are just starting to work in this area. If you already have some experience in developing distributed systems and algorithms, you may find something new for yourself and share your opinion in the comments. If you have many years of experience behind you and are an expert in this topic, I hope that you can complement me with your thoughts and thoughts.
What would I like?
I will be glad if the material of the book is useful and informative for you - there will be time to return here after reading it and to write “thank you”, I will be grateful. In addition, I would like to collect all the material on the topic, including comments, questions and answers in one place, then to send everyone here, including new courses for new students. If you can help and supplement the material with your thoughts, your experience, I will be doubly grateful. Read, gain knowledge and use it in your work! You can download the book in PDF format right now at the link below:
Introduction to Distributed Computing >>
Success!
Mikhail Kosyakov
Instead of an epilogue. "Information, unlike resources, is intended to be shared." Robert Kiyosaki