DDIA book (book with hog) - make level up in understanding databases
A few months ago, at one of the retrospectives, we decided to try reading together.
Our format:
What gives:
One of the recent books we read is Designing Data-Intensive Applications . Yes, yes, the same book with a hog. And everyone liked this book so much that I decided to make a review here so that more people could read it.
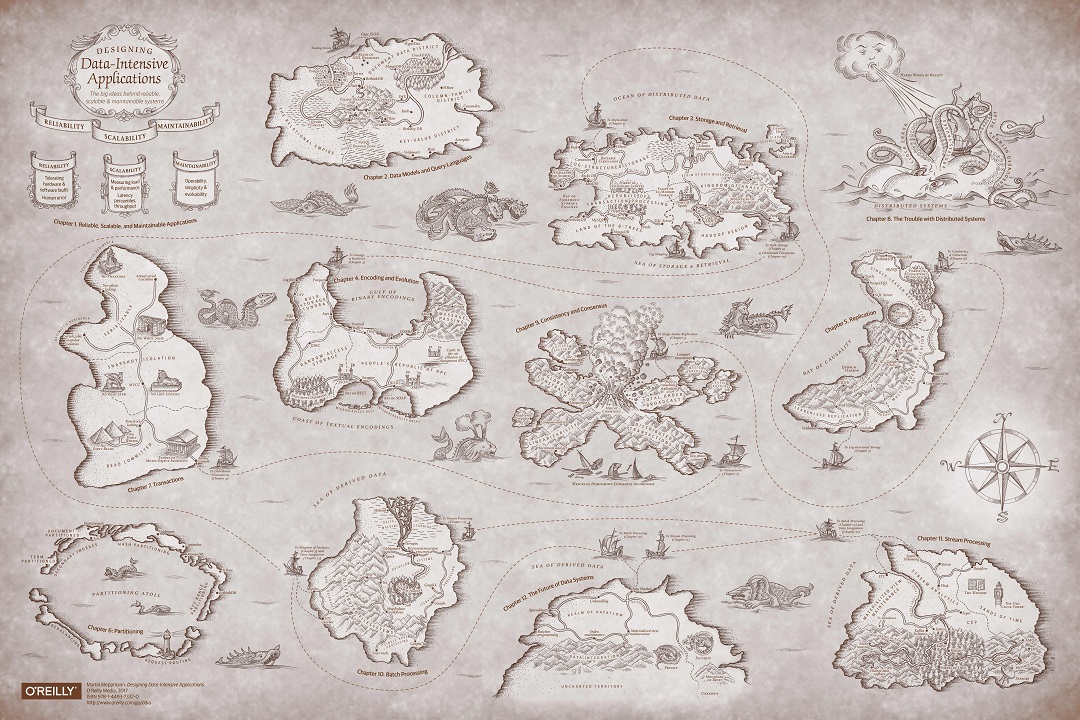
Map in original quality
The first chapter indicates that the important properties of such systems are reliability, scalability and maintainability.
The second chapter describes the various data models. The usual relational and document-oriented DBMS, as well as less well-known graph and column databases are described.
The first chapters introduce the situation, establish the scope of the book. In many places, the author further refers to the first chapters. In fairness, it can be said that the book is full of cross-references.
What is surprising from the very first chapters is the number of sources (there is a bibliography after each chapter). Links to dozens of articles (both blogs and scientific) and books are meticulously arranged in all chapters. The number of sources to some chapters exceeds one hundred.
The third chapter begins with the source of the simplest key-value of the repository:
It will even work, very good at writing, but, of course, not without problems when reading.
And immediately offered options for improving performance. Hash indexes, SSTable, b-tree, and LSM-tree are described. All this is explained on the fingers, but it shows how this or that structure is used in the databases we are used to.
Practice orientation is another feature of the book. Most of the examples and recipes are so practical that I have come across almost all of the relevant.
The fourth chapter describes the encoding: from ordinary JSON and XML to Protobuf and AVRO. We do not always choose the format consciously, usually it is imposed on one or another technology as a whole. But it's cool to understand how it is inside, what are the strengths and weaknesses of the format.
The second part of the book is about distributed data processing systems. Almost all modern more or less loaded systems have several replicas or subsystems (microservices).
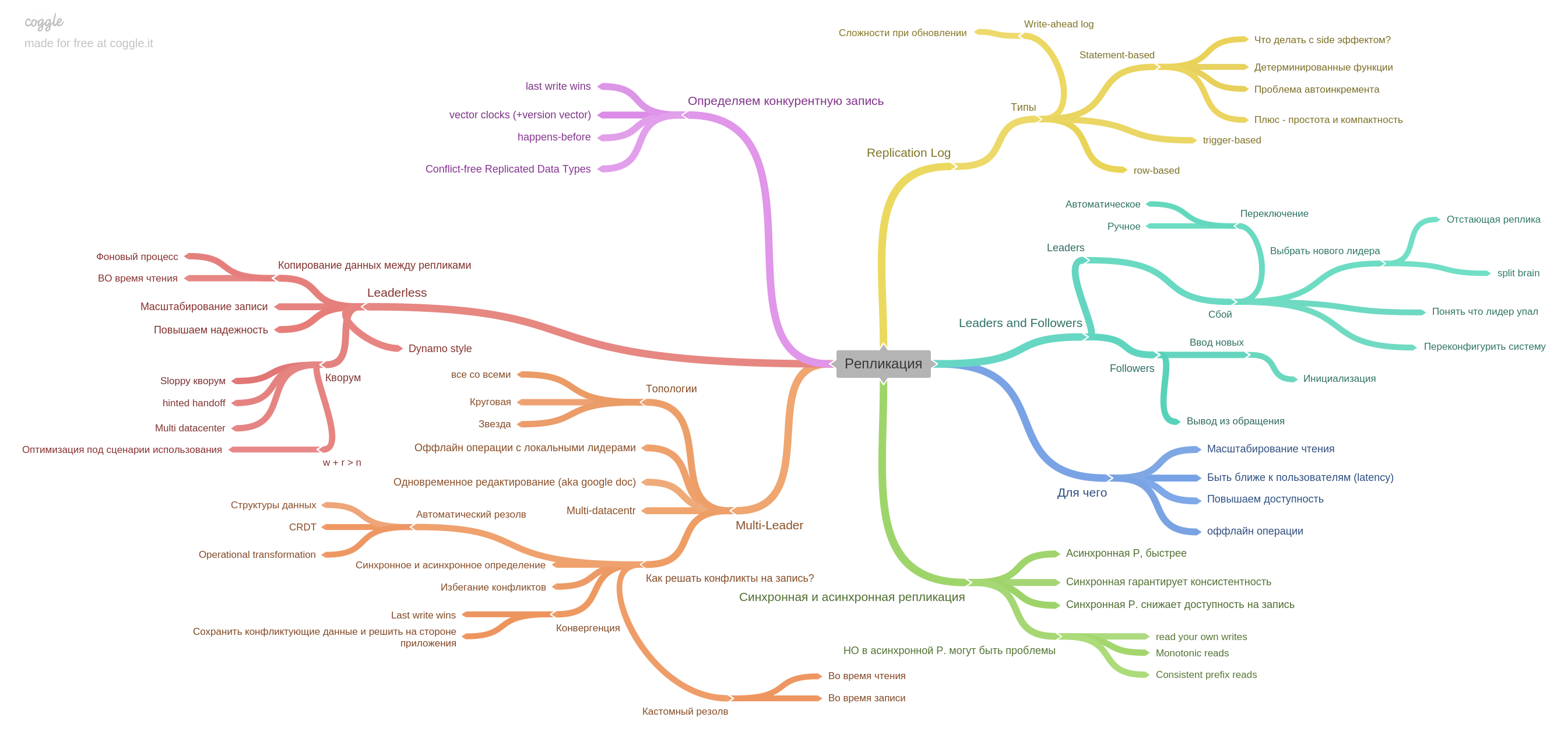
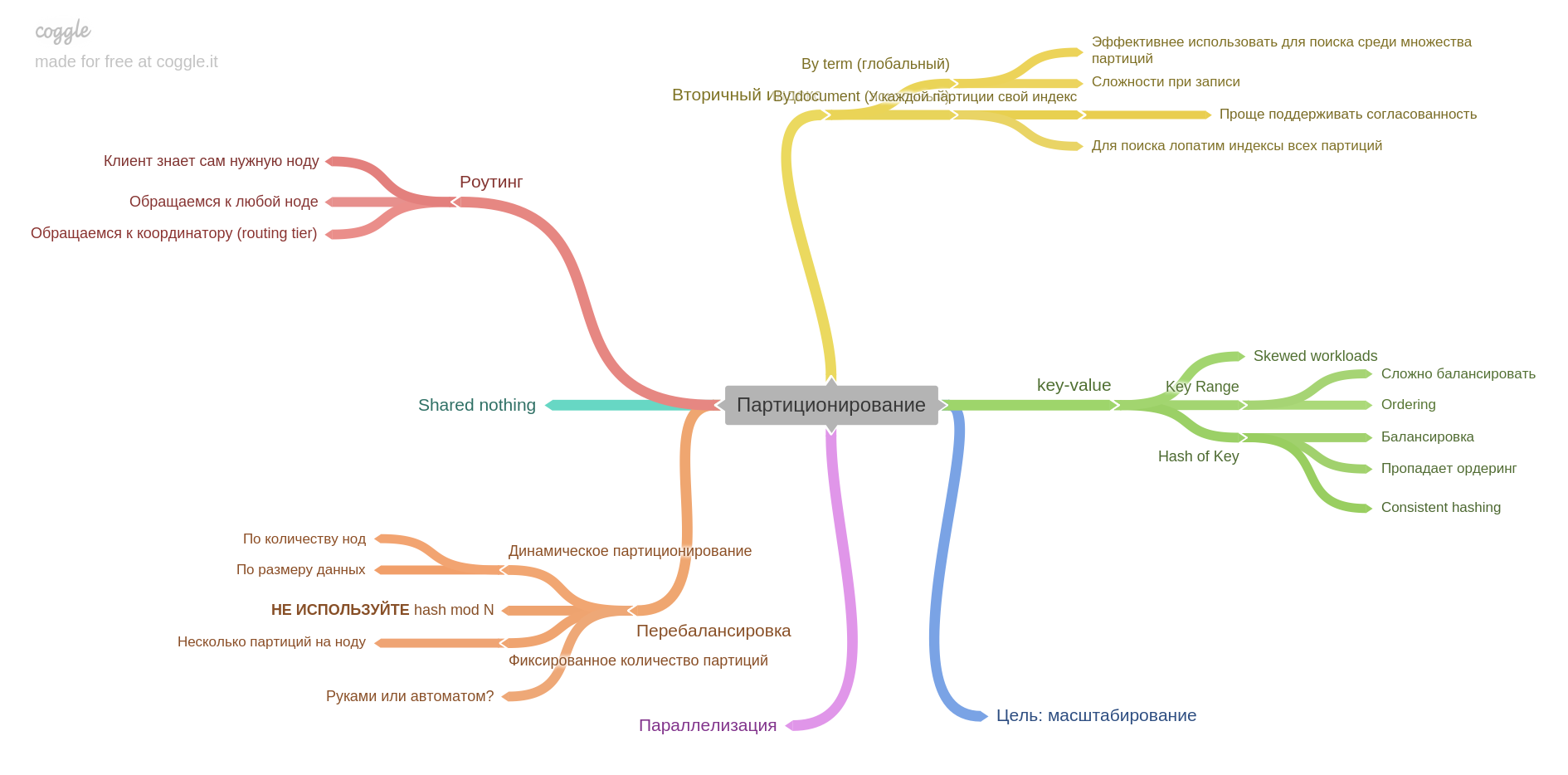
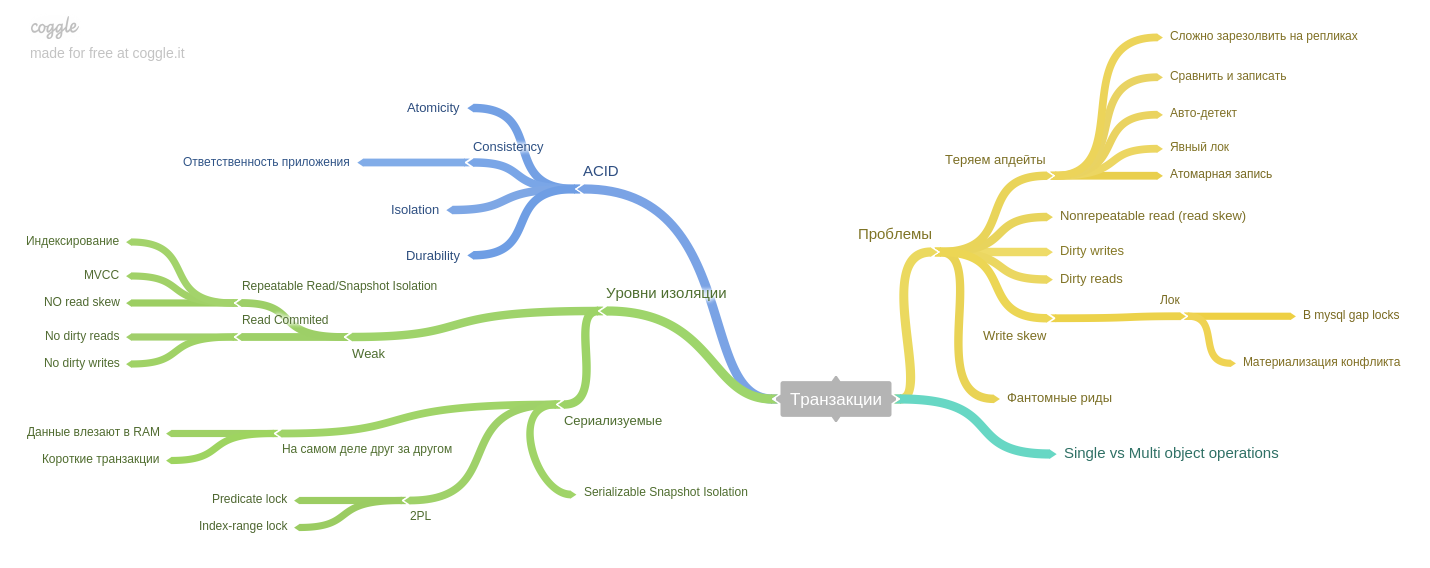
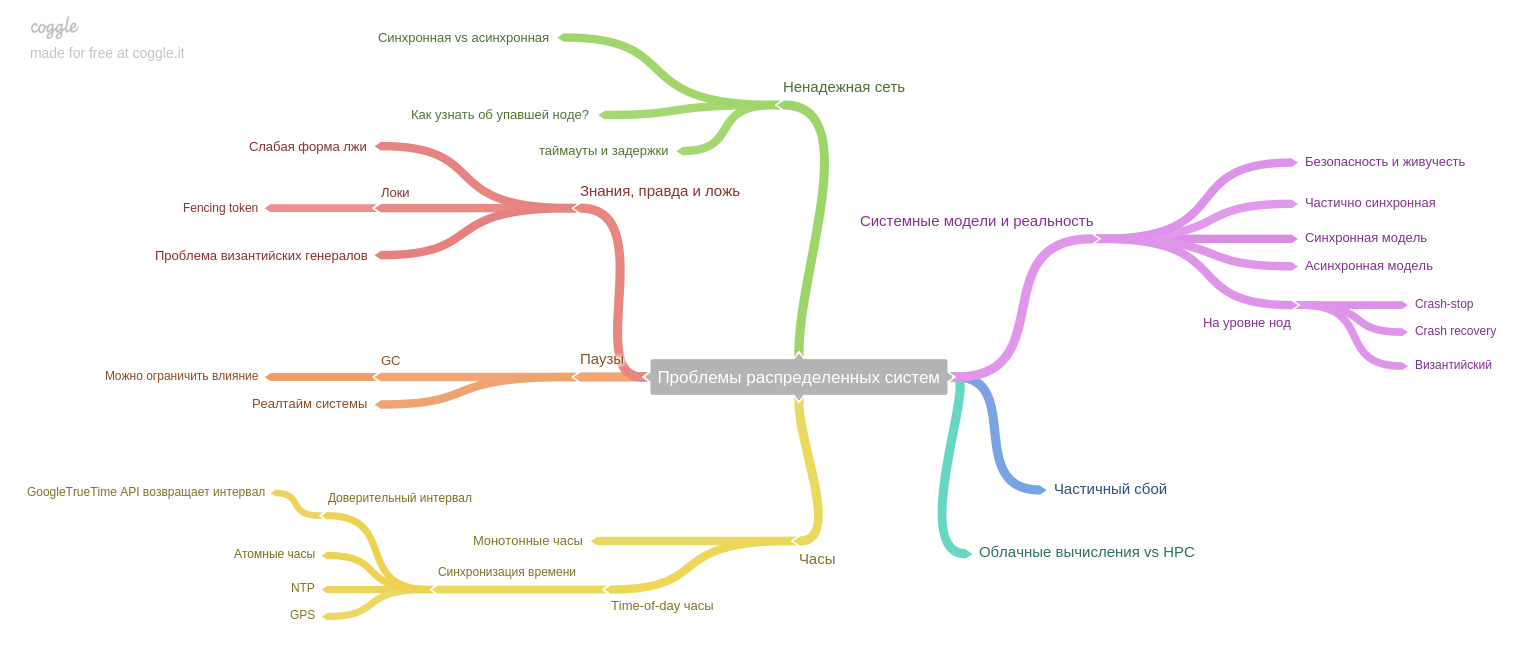
The author highlights an important idea: if the system used to work on one machine, and in the event of a failure, the entire system stopped working (and accept any new data). Thus, the data after the failures remained in a consistent state, but today, in the era of replicas and microservices, only part of the system stops its operation. Thus, we face a new problem: ensuring consistency of data in the face of partial failure, persistent problems with an unreliable network, etc.
The ninth chapter describes consistency and consensus and introduces an important notion: linearizability. I remember that the head went hard and fit in my head)
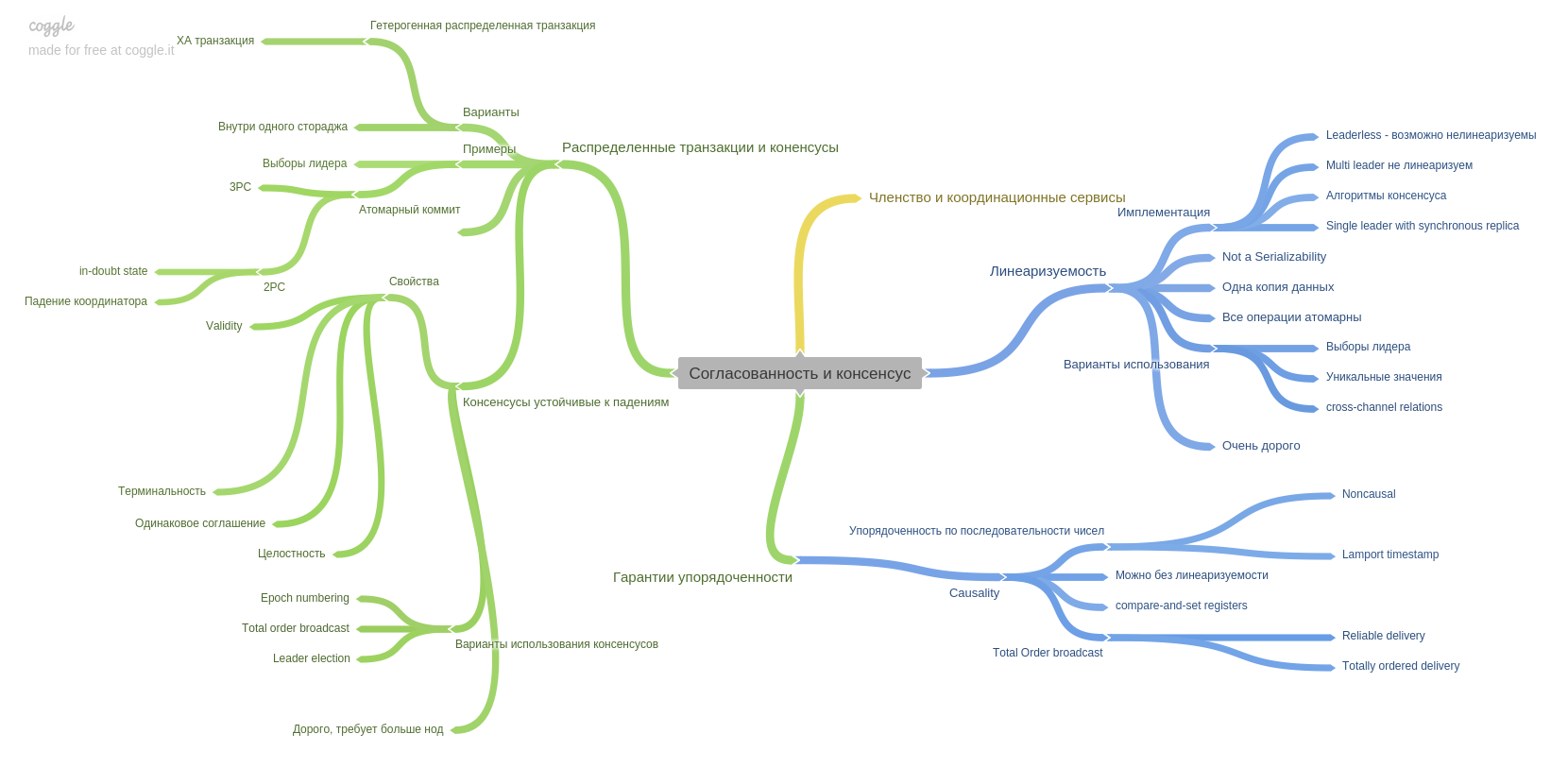
This chapter also describes the technique of a two-phase commit and its weak points. Also in this chapter, you will read about the guarantees of orderliness. Like what modern systems can provide you.
The third part of the book is devoted to derived data (no fixed translation). As a result, the author voiced the idea that all indexes, tables, materialized views are just a cache above the log. Only the log contains the most current data, everything else is late and is used for convenience.
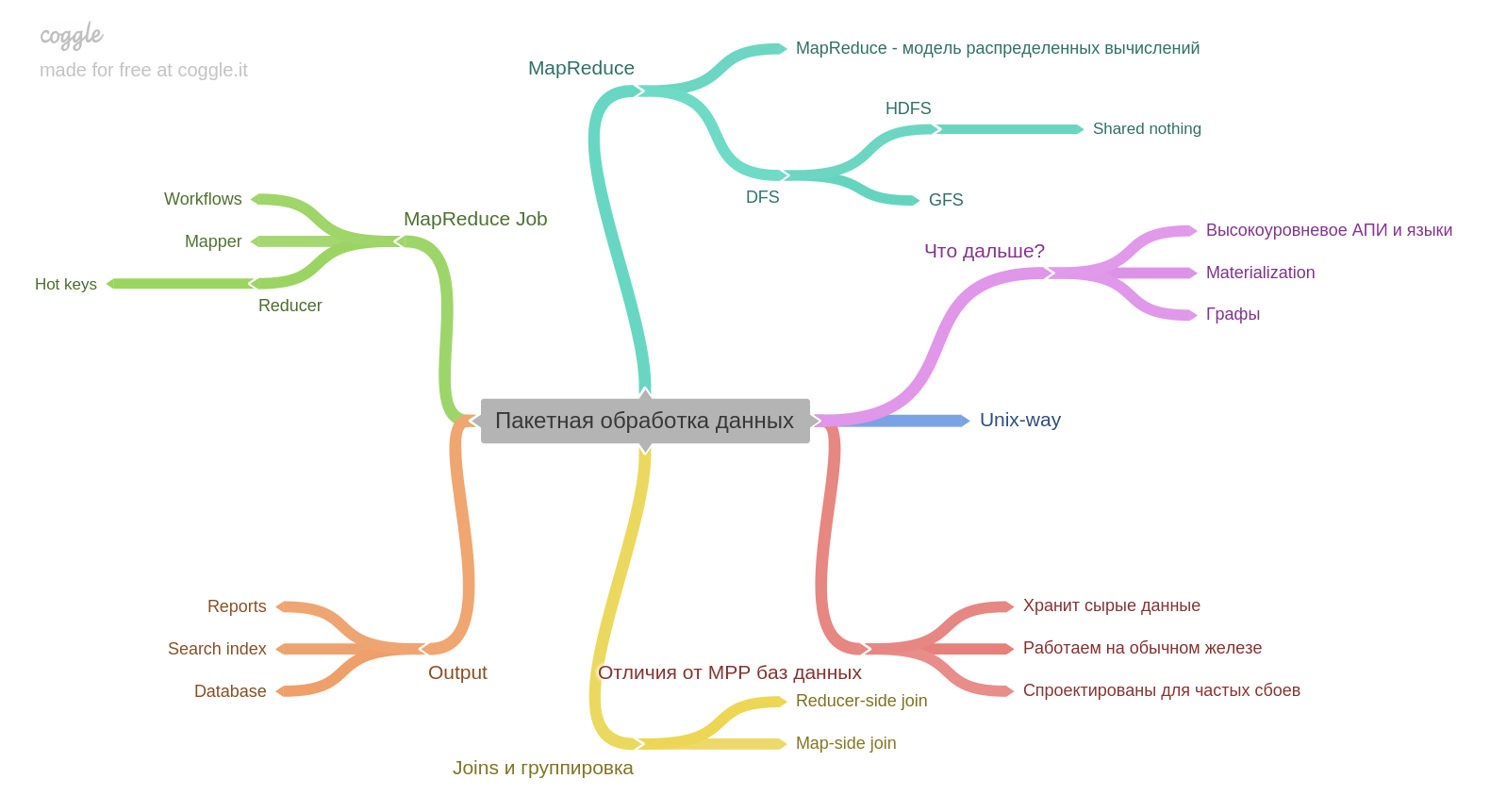
The tenth chapter. If you have experience with Hadoop or MapReduce, you may find out a little new. But I did not work and it was very interesting. An important point for me - the result of batch processing itself can be the basis for another database. Chapter 11. Stream data processing.
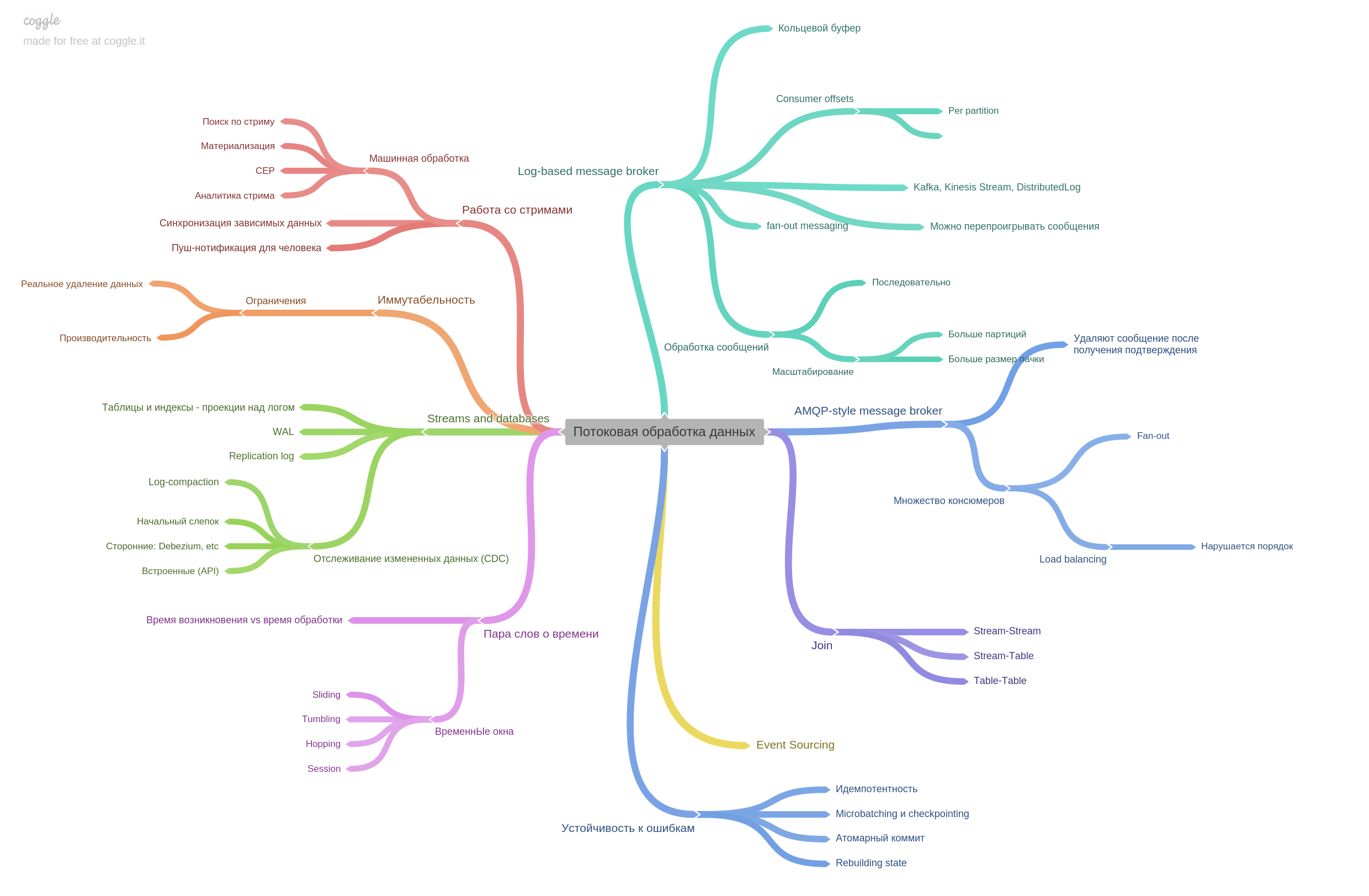
Message brokers are described and how AMPQ-style differs from log-based. Actually the chapter contains a lot of other information. It was very interesting to read.
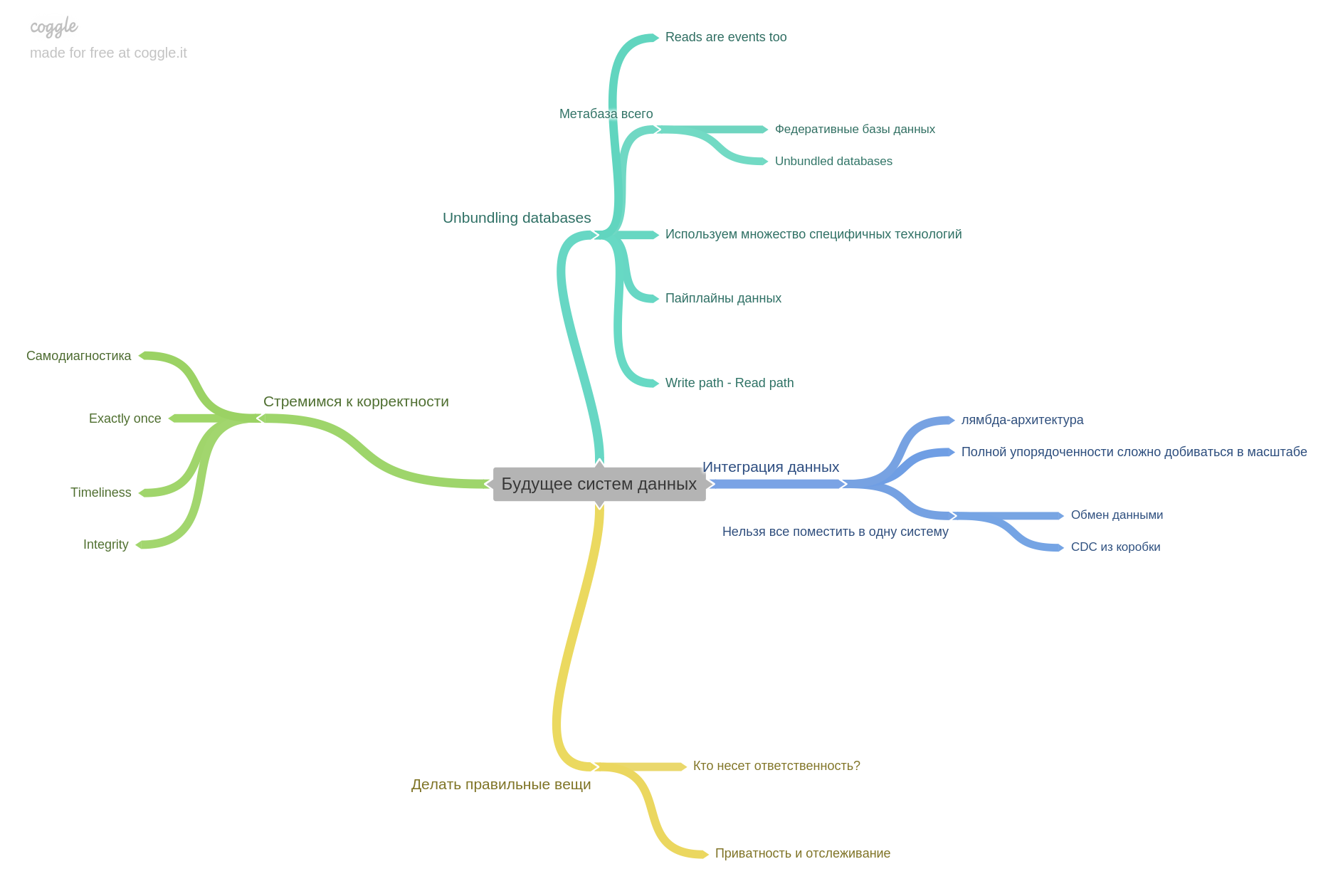
The last chapter is about the future. What to expect, what thoughts of researchers and engineers are already busy with. At this point I finish my review. It is important to understand that I made only part of the theses for each chapter. The book has such a dense content that it is not possible to briefly but fully retell. Personally, I think this book is the best technical for the past few years. I highly recommend reading it. And not just read, but work hard. Follow the links from the bibliography, play around with real DBMS.
After reading this book, you can easily answer many questions in a technical database interview. But this is not the main thing. You will become cooler as a developer, you will know the internal structure, the strengths and weaknesses of various databases and think about the problems of distributed systems.
I am ready to discuss in the comments both the book itself and our practice of joint reading.
Read books!
Our format:
- Choose a book.
- We determine the part that needs to be read in a week. Choose a small volume.
- On Friday, we discuss what we read.
- We read during off-hours, we discuss in working hours.
- After finishing the book, jointly choose the next one.
What gives:
- Motivation for reading and reading.
- The development of skills (including the future).
- Alignment mindsets and terminology in the team.
- Growth of trust.
- An extra reason to talk.
One of the recent books we read is Designing Data-Intensive Applications . Yes, yes, the same book with a hog. And everyone liked this book so much that I decided to make a review here so that more people could read it.
Map in original quality
{kind=link}
There is a translation of this book into Russian from Peter Publishing. But we read the original, so I do not promise that the translations of the terms will coincide. Moreover, we deliberately did not translate part of the terms.The initial part of the book is devoted to the basics of data processing systems.
The first chapter indicates that the important properties of such systems are reliability, scalability and maintainability.
The second chapter describes the various data models. The usual relational and document-oriented DBMS, as well as less well-known graph and column databases are described.
The first chapters introduce the situation, establish the scope of the book. In many places, the author further refers to the first chapters. In fairness, it can be said that the book is full of cross-references.
What is surprising from the very first chapters is the number of sources (there is a bibliography after each chapter). Links to dozens of articles (both blogs and scientific) and books are meticulously arranged in all chapters. The number of sources to some chapters exceeds one hundred.
The third chapter begins with the source of the simplest key-value of the repository:
#!/bin/bash
db_set () {
echo"$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
It will even work, very good at writing, but, of course, not without problems when reading.
And immediately offered options for improving performance. Hash indexes, SSTable, b-tree, and LSM-tree are described. All this is explained on the fingers, but it shows how this or that structure is used in the databases we are used to.
Practice orientation is another feature of the book. Most of the examples and recipes are so practical that I have come across almost all of the relevant.
The fourth chapter describes the encoding: from ordinary JSON and XML to Protobuf and AVRO. We do not always choose the format consciously, usually it is imposed on one or another technology as a whole. But it's cool to understand how it is inside, what are the strengths and weaknesses of the format.
The author did not specifically use the term serialization, since this term has another meaning in databases.The content of the chapters is much richer than my short presentation. The first part also describes the differences between OLTP and OLAP, how the full-text search and search in column databases, REST and message brokers are arranged.
The second part of the book is about distributed data processing systems. Almost all modern more or less loaded systems have several replicas or subsystems (microservices).
When we started practicing reading together, we just discussed our notes, interesting places and thoughts. At some point, we realized that we lack just talk, after discussion everything is quickly forgotten. Then we decided to strengthen our practice and added a mind map fill. Innovation had just to this book. Beginning with the second part, we began to lead a mind map for each chapter. Therefore, further each chapter will be with our mind map. We used coggle.itThe fifth chapter describes replication. Here are collected all the basic information about the replicas: single-master, multimaster, replication log and how to live with a competitive entry in leaderless-systems. The sixth chapter describes partitioning (aka sharding and a bundle of other terms). You will learn how to break data into shards, what problems you can solve and which ones to get, how to build indexes and balance data. Seventh Chapter : Transaction. Phenomena are described (read skew, write skew, phantom reads, etc) and how exactly the isolation levels of the ACID-style databases help avoid problems. The eighth chapter: about problems specific to distributed systems.
The author highlights an important idea: if the system used to work on one machine, and in the event of a failure, the entire system stopped working (and accept any new data). Thus, the data after the failures remained in a consistent state, but today, in the era of replicas and microservices, only part of the system stops its operation. Thus, we face a new problem: ensuring consistency of data in the face of partial failure, persistent problems with an unreliable network, etc.
The ninth chapter describes consistency and consensus and introduces an important notion: linearizability. I remember that the head went hard and fit in my head)
This chapter also describes the technique of a two-phase commit and its weak points. Also in this chapter, you will read about the guarantees of orderliness. Like what modern systems can provide you.
The third part of the book is devoted to derived data (no fixed translation). As a result, the author voiced the idea that all indexes, tables, materialized views are just a cache above the log. Only the log contains the most current data, everything else is late and is used for convenience.
The tenth chapter. If you have experience with Hadoop or MapReduce, you may find out a little new. But I did not work and it was very interesting. An important point for me - the result of batch processing itself can be the basis for another database. Chapter 11. Stream data processing.
Message brokers are described and how AMPQ-style differs from log-based. Actually the chapter contains a lot of other information. It was very interesting to read.
The last chapter is about the future. What to expect, what thoughts of researchers and engineers are already busy with. At this point I finish my review. It is important to understand that I made only part of the theses for each chapter. The book has such a dense content that it is not possible to briefly but fully retell. Personally, I think this book is the best technical for the past few years. I highly recommend reading it. And not just read, but work hard. Follow the links from the bibliography, play around with real DBMS.
After reading this book, you can easily answer many questions in a technical database interview. But this is not the main thing. You will become cooler as a developer, you will know the internal structure, the strengths and weaknesses of various databases and think about the problems of distributed systems.
I am ready to discuss in the comments both the book itself and our practice of joint reading.
Read books!