Computing Graphs, Speculative Locks and Arenas for Tasks in Intel® Threading Building Blocks
- Transfer
This post is a translation of the article “Flow Graphs, Speculative Locks, and Task Arenas in Intel Threading Building Blocks” from Parallel Universe Magazine, issue 18, 2014. If you are interested in Intel TBB library in particular, and interesting modern concepts of parallel programming in general, then welcome under cat.
The Intel Threading Building Blocks (Intel TBB) library provides C ++ programmers with a solution to add concurrency to their applications and libraries. The widely known advantage of the Intel TBB library is that it makes scalability and the power of parallel execution of their applications easily accessible for developers if their algorithms are based on cycles or tasks. A general overview of the library can be seen under the spoiler.
Next, we will focus on several specific parts of the library. First up is a review of the flow graph , which is available starting with Intel TBB 4.0. Then we will talk about two components of the library, which were first released in Intel TBB 4.2. This speculative locks ( Speculative locks ), that take advantage of Intel Transactional Synchronization Extensions Technology (Intel TSX) and user-controlled arena for tasks ( user-task 'managed arenas ), which provide advanced monitoring and control of the level of parallelism and insulation problems.
Although the Intel TBB library is well known for loop parallelization, the computational graph interface [4] expands its capabilities for the fast and efficient implementation of algorithms based on data and / or execution dependency graphs, helping developers use parallelism in their applications at a higher level.
For example, consider a simple application that sequentially performs four functions, as shown in Fig. 2 (a). The loop parallelization approach implies that the developer can consider each of these functions for parallelization using algorithms such as parallel_for and parallel_reduce. Sometimes this may be enough, but in other cases this may not be enough. For example, in Fig. Figure 2 (b) shows that it was possible to parallelize the functions B and D in cycles. In this case, the execution time will be reduced, but what if the resulting increase in productivity is still not enough?
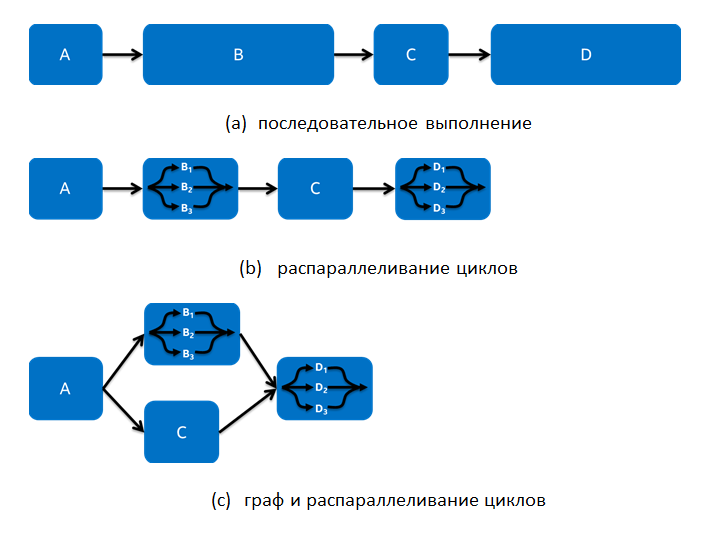
Fig. 2: A simple example of different forms of concurrency
Sometimes excessive restrictions are imposed on a function call, such as: the order of the function call must be defined, strictly ordered, one after the other calls, even in the case of not complete, but partial dependencies between functions. In Fig. 2 (a) the functions are written by the developer in such a way that the function is executed only after all the input values are received during the previous execution. But what if the functions B and C depend on the data calculated in function A, and the function C does not depend on the data of function B? Fig. 2 (c) shows the implementation of this example through a graph and parallelization of loops. In this implementation, parallelization at the cycle level is used, and full ordering is replaced by partial ordering, which allows functions B and C to be executed simultaneously.
The Intel TBB flow graph interface makes it easy for developers to express graph-level concurrency. It provides support for the various types of graphs that can be found in many areas, such as multimedia processing, games, financial and high-performance computing, and healthcare computing. This interface is fully supported in the library and is available starting with Intel TBB 4.0.
When using Intel TBB flow graph, calculations are represented by nodes, and communication channels between these nodes are represented by edges. The user uses edges to specify the dependencies that the nodes should take into account when queuing for execution, allowing the Intel TBB task scheduler to implement parallelism at the graph topology level. When a node in a graph receives a message, the task of executing a functor on this message is queued for execution by the Intel TBB scheduler.
The flow graph interface supports several different types of nodes (Fig. 3): Functional nodes, which perform user-defined functions, Buffering nodes, which can be used to organize and buffer messages as they should pass through the graph , Aggregation / Deaggregation nodes, which connect or disconnect messages, as well as other useful nodes. Users connect the objects of these nodes with edges in order to indicate the dependencies between them, and provide objects that perform work in these nodes.
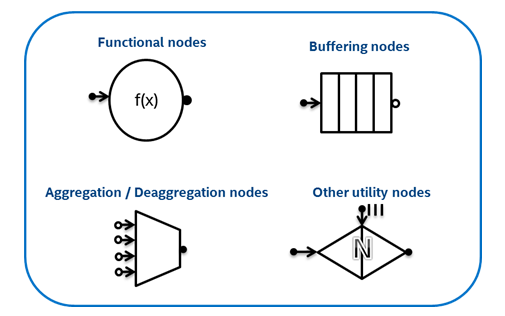
Fig. 3: Types of nodes supported by the flow graph interface
Consider the source code for a simple flow graph application, “Hello World”. This example is very simple and does not contain any parallelism, but it demonstrates the syntax of this interface. In this example, using lambda expressions, two nodes are created: hello and world , which print, respectively, “Hello” and “World”. Each node of type continue_node is a functional node with the type provided by the interface. The make_edge call creates an edge between the hello and world nodes . Whenever the task started by the hello node is completed , it will send a message to the world node , forcing it to run the task to execute its lambda expression.
In the above code, calling hello.try_put (continue_msg ()) sends a message to the hello node , causing it to invoke a task to execute the object body. When the task is completed, it sends a message to the world node . Only when all tasks started by the nodes are finished, is the return from the g.wait_for_all () function performed.
The Intel TBB flow graph interface allows you to program very complex graphs that include thousands of nodes, edges, loops, and other elements. Fig. 4 shows a visual representation of two implementation graphs of the Cholesky decomposition, which use an algorithm similar to that found in [5]. In Fig. 4 (a) each function call of the Intel Math Kernel Library (Intel MKL) dpotf2m ,dtrsm , dgemm and dsyrk are a separate node in the graph. In this case, the graph is huge, with many nodes per each block of the matrix, but it can be easily implemented by modifying the initial sequential nested cycles of the Cholesky decomposition by replacing function calls with the creation of nodes and edges. In this graph, edges are used to indicate dependency relationships; each node waits until all nodes on which it depends are executed. It is easy to see how parallelization is implemented in this graph.
Fig. 4 (b) shows an alternative version, which can also be implemented using the flow graph interface . In this small, more compact version of the graph, there is only a udin node that is responsible for calling all the necessary functions of the Intel MKL library. In this implementation, blocks are transmitted as messages between nodes in a graph. When a node accepts a set of blocks of a certain type, it invokes a task that processes these blocks and then forwards the new generated block to other nodes. Parallelization in such a graph will be implemented due to the ability of the library to simultaneously execute many instances of the objects of each graph node.
Although the implementation details discussed in Fig. 4, are beyond the scope of this article, this example demonstrates that the Intel TBB flow graph interface is a powerful and flexible level of abstraction. It can be used to create large directed acyclic graphs, for example, such as in Figure 4 (a), where the developer creates a dedicated node for each call to the Intel MKL library. On the other hand, using the Intel TBB flow graph interface, you can create a compact data dependency graph that includes loops and conditional execution, as shown in Fig. 4 (b).
More information on flow graph interfaces can be found in the Intel TBB Reference Guide.
In the next half of the article, we will look at speculative locks that take advantage of Intel Transactional Synchronization Extensions (Intel TSX) technology and user-managed task arenas that provide advanced control and management of concurrency and isolation of tasks. .
To be continued…
Introduction
The Intel Threading Building Blocks (Intel TBB) library provides C ++ programmers with a solution to add concurrency to their applications and libraries. The widely known advantage of the Intel TBB library is that it makes scalability and the power of parallel execution of their applications easily accessible for developers if their algorithms are based on cycles or tasks. A general overview of the library can be seen under the spoiler.
About the library
The library includes general parallel algorithms, a scheduler and a task balancer, thread-safe containers, a memory manager, synchronization primitives and more (Fig. 1). Using the basic parallel programming patterns in conjunction with these building blocks, developers make parallel applications that abstract from the problems of implementing the multithreading mechanism on a particular platform, while obtaining performance that scales with an increase in the number of cores.

Figure 1: “Building Blocks” Intel Threading Building Blocks
The book “Structured parallel programming” [1] describes a number of useful parallel patterns that fit well with Intel TBB algorithms:
Intel TBB library can be used with any C ++ compiler. It also supports the C ++ 11 standard, for example, lambda expressions, which simplifies the writing and readability of the code, since there is no need to write utility functor classes. Various library components can be used independently and even combined with other parallel programming technologies.
Intel TBB 4.2 introduced new features that include support for the latest architecture features, such as Intel Transactional Synchronization Extensions (Intel TSX) technology and support for Intel Xeon Phi coprocessor on Windows *. Also appeared support for applications for the Windows Store * and Android * [2, 3]. In addition, the current components have been improved (see documentation). Intel TBB 4.2 is available both separately and as part of products such as Intel INDE, Intel Cluster Studio XE, Intel Parallel Studio XE, Intel C ++ Studio XE, Intel Composer XE and Intel C ++ Composer XE.
The open source library version supports more architectures, compilers and operating systems thanks to the contributions of our community. The library can work with the Solaris * operating system and the Oracle * C ++ compiler for Intel Architecture compiler and the C ++ compiler for SPARC * -compatible architectures, IBM * Blue Gene * supercomputers, and PowerPC * -compatible architectures. It also works with Android *, Windows Phone * 8, and Windows RT * operating systems for ARM * -compatible architectures, FreeBSD *, Robot *, and many other platforms that support atomic operations built into the GCC * compiler. This broad cross-platform approach means that an application once written using the Intel TBB library can be ported to many other operating systems or architectures without rewriting the basic algorithms.
Figure 1: “Building Blocks” Intel Threading Building Blocks
The book “Structured parallel programming” [1] describes a number of useful parallel patterns that fit well with Intel TBB algorithms:
- parallel_for : map, stencil (multidimensional data table)
- parallel_reduce, parallel_scan : reduce (reduction), scan (calculation of partial reductions)
- parallel_do : workpile (multidimensional data table with an unknown number of elements at the start of execution)
- parallel_pipeline : pipeline
- parallel_invoke, task_group : fork-join patterns
- flow_graph : computational graph patterns
Intel TBB library can be used with any C ++ compiler. It also supports the C ++ 11 standard, for example, lambda expressions, which simplifies the writing and readability of the code, since there is no need to write utility functor classes. Various library components can be used independently and even combined with other parallel programming technologies.
Intel TBB 4.2 introduced new features that include support for the latest architecture features, such as Intel Transactional Synchronization Extensions (Intel TSX) technology and support for Intel Xeon Phi coprocessor on Windows *. Also appeared support for applications for the Windows Store * and Android * [2, 3]. In addition, the current components have been improved (see documentation). Intel TBB 4.2 is available both separately and as part of products such as Intel INDE, Intel Cluster Studio XE, Intel Parallel Studio XE, Intel C ++ Studio XE, Intel Composer XE and Intel C ++ Composer XE.
The open source library version supports more architectures, compilers and operating systems thanks to the contributions of our community. The library can work with the Solaris * operating system and the Oracle * C ++ compiler for Intel Architecture compiler and the C ++ compiler for SPARC * -compatible architectures, IBM * Blue Gene * supercomputers, and PowerPC * -compatible architectures. It also works with Android *, Windows Phone * 8, and Windows RT * operating systems for ARM * -compatible architectures, FreeBSD *, Robot *, and many other platforms that support atomic operations built into the GCC * compiler. This broad cross-platform approach means that an application once written using the Intel TBB library can be ported to many other operating systems or architectures without rewriting the basic algorithms.
Next, we will focus on several specific parts of the library. First up is a review of the flow graph , which is available starting with Intel TBB 4.0. Then we will talk about two components of the library, which were first released in Intel TBB 4.2. This speculative locks ( Speculative locks ), that take advantage of Intel Transactional Synchronization Extensions Technology (Intel TSX) and user-controlled arena for tasks ( user-task 'managed arenas ), which provide advanced monitoring and control of the level of parallelism and insulation problems.
Computing Graphs
Although the Intel TBB library is well known for loop parallelization, the computational graph interface [4] expands its capabilities for the fast and efficient implementation of algorithms based on data and / or execution dependency graphs, helping developers use parallelism in their applications at a higher level.
For example, consider a simple application that sequentially performs four functions, as shown in Fig. 2 (a). The loop parallelization approach implies that the developer can consider each of these functions for parallelization using algorithms such as parallel_for and parallel_reduce. Sometimes this may be enough, but in other cases this may not be enough. For example, in Fig. Figure 2 (b) shows that it was possible to parallelize the functions B and D in cycles. In this case, the execution time will be reduced, but what if the resulting increase in productivity is still not enough?
Fig. 2: A simple example of different forms of concurrency
Sometimes excessive restrictions are imposed on a function call, such as: the order of the function call must be defined, strictly ordered, one after the other calls, even in the case of not complete, but partial dependencies between functions. In Fig. 2 (a) the functions are written by the developer in such a way that the function is executed only after all the input values are received during the previous execution. But what if the functions B and C depend on the data calculated in function A, and the function C does not depend on the data of function B? Fig. 2 (c) shows the implementation of this example through a graph and parallelization of loops. In this implementation, parallelization at the cycle level is used, and full ordering is replaced by partial ordering, which allows functions B and C to be executed simultaneously.
The Intel TBB flow graph interface makes it easy for developers to express graph-level concurrency. It provides support for the various types of graphs that can be found in many areas, such as multimedia processing, games, financial and high-performance computing, and healthcare computing. This interface is fully supported in the library and is available starting with Intel TBB 4.0.
When using Intel TBB flow graph, calculations are represented by nodes, and communication channels between these nodes are represented by edges. The user uses edges to specify the dependencies that the nodes should take into account when queuing for execution, allowing the Intel TBB task scheduler to implement parallelism at the graph topology level. When a node in a graph receives a message, the task of executing a functor on this message is queued for execution by the Intel TBB scheduler.
The flow graph interface supports several different types of nodes (Fig. 3): Functional nodes, which perform user-defined functions, Buffering nodes, which can be used to organize and buffer messages as they should pass through the graph , Aggregation / Deaggregation nodes, which connect or disconnect messages, as well as other useful nodes. Users connect the objects of these nodes with edges in order to indicate the dependencies between them, and provide objects that perform work in these nodes.
Fig. 3: Types of nodes supported by the flow graph interface
Consider the source code for a simple flow graph application, “Hello World”. This example is very simple and does not contain any parallelism, but it demonstrates the syntax of this interface. In this example, using lambda expressions, two nodes are created: hello and world , which print, respectively, “Hello” and “World”. Each node of type continue_node is a functional node with the type provided by the interface. The make_edge call creates an edge between the hello and world nodes . Whenever the task started by the hello node is completed , it will send a message to the world node , forcing it to run the task to execute its lambda expression.
#include "tbb/flow_graph.h"
#include
using namespace std;
using namespace tbb::flow;
int main() {
graph g;
continue_node< continue_msg> hello( g,
[]( const continue_msg &) {
cout << "Hello";
}
);
continue_node< continue_msg> world( g,
[]( const continue_msg &) {
cout << " World\n";
}
);
make_edge(hello, world);
hello.try_put(continue_msg());
g.wait_for_all();
return 0;
}
In the above code, calling hello.try_put (continue_msg ()) sends a message to the hello node , causing it to invoke a task to execute the object body. When the task is completed, it sends a message to the world node . Only when all tasks started by the nodes are finished, is the return from the g.wait_for_all () function performed.
The Intel TBB flow graph interface allows you to program very complex graphs that include thousands of nodes, edges, loops, and other elements. Fig. 4 shows a visual representation of two implementation graphs of the Cholesky decomposition, which use an algorithm similar to that found in [5]. In Fig. 4 (a) each function call of the Intel Math Kernel Library (Intel MKL) dpotf2m ,dtrsm , dgemm and dsyrk are a separate node in the graph. In this case, the graph is huge, with many nodes per each block of the matrix, but it can be easily implemented by modifying the initial sequential nested cycles of the Cholesky decomposition by replacing function calls with the creation of nodes and edges. In this graph, edges are used to indicate dependency relationships; each node waits until all nodes on which it depends are executed. It is easy to see how parallelization is implemented in this graph.
Fig. 4: Two parallel implementations of Cholesky decomposition based on flow graph interfaces
Fig. 4 (a) Using the directed acyclic graph

Fig. 4 (b) Using a compact data dependency graph

Fig. 4 (a) Using the directed acyclic graph

Fig. 4 (b) Using a compact data dependency graph
Fig. 4 (b) shows an alternative version, which can also be implemented using the flow graph interface . In this small, more compact version of the graph, there is only a udin node that is responsible for calling all the necessary functions of the Intel MKL library. In this implementation, blocks are transmitted as messages between nodes in a graph. When a node accepts a set of blocks of a certain type, it invokes a task that processes these blocks and then forwards the new generated block to other nodes. Parallelization in such a graph will be implemented due to the ability of the library to simultaneously execute many instances of the objects of each graph node.
Although the implementation details discussed in Fig. 4, are beyond the scope of this article, this example demonstrates that the Intel TBB flow graph interface is a powerful and flexible level of abstraction. It can be used to create large directed acyclic graphs, for example, such as in Figure 4 (a), where the developer creates a dedicated node for each call to the Intel MKL library. On the other hand, using the Intel TBB flow graph interface, you can create a compact data dependency graph that includes loops and conditional execution, as shown in Fig. 4 (b).
More information on flow graph interfaces can be found in the Intel TBB Reference Guide.
In the next half of the article, we will look at speculative locks that take advantage of Intel Transactional Synchronization Extensions (Intel TSX) technology and user-managed task arenas that provide advanced control and management of concurrency and isolation of tasks. .
To be continued…
Bibliography
[1] Michael McCool, Arch Robison, James Reinders “Structured Parallel Programming” parallelbook.com
[2] Vladimir Polin, “Android * Tutorial: Writing a Multithreaded Application using Intel Threading Building Blocks”. software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin, “Windows * 8 Tutorial: Writing a Multithreaded Application for the Windows Store * using Intel Threading Building Blocks. " software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss, “ The Intel Threading Building Blocks Flow Graph ”,
Dr. Dobb's, October 2011,www.drdobbs.com/tools/the-intel-threading-building-blocks-flow/231900177 .
[5] Aparna Chandramowlishwaran, Kathleen Knobe, and Richard Vuduc, “Performance
Evaluation of Concurrent Collections on High-Performance Multicore Computing Systems”,
2010 Symposium on Parallel & Distributed Processing (IPDPS), April 2010.
[2] Vladimir Polin, “Android * Tutorial: Writing a Multithreaded Application using Intel Threading Building Blocks”. software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin, “Windows * 8 Tutorial: Writing a Multithreaded Application for the Windows Store * using Intel Threading Building Blocks. " software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss, “ The Intel Threading Building Blocks Flow Graph ”,
Dr. Dobb's, October 2011,www.drdobbs.com/tools/the-intel-threading-building-blocks-flow/231900177 .
[5] Aparna Chandramowlishwaran, Kathleen Knobe, and Richard Vuduc, “Performance
Evaluation of Concurrent Collections on High-Performance Multicore Computing Systems”,
2010 Symposium on Parallel & Distributed Processing (IPDPS), April 2010.