Development and testing of ASKUE module
ASKUE - Automated Systems for Monitoring and Accounting of Energy Resources. The tasks of such systems include collecting data from energy metering devices (gas, water, heating, electricity) and providing these data in a form convenient for analysis and control.
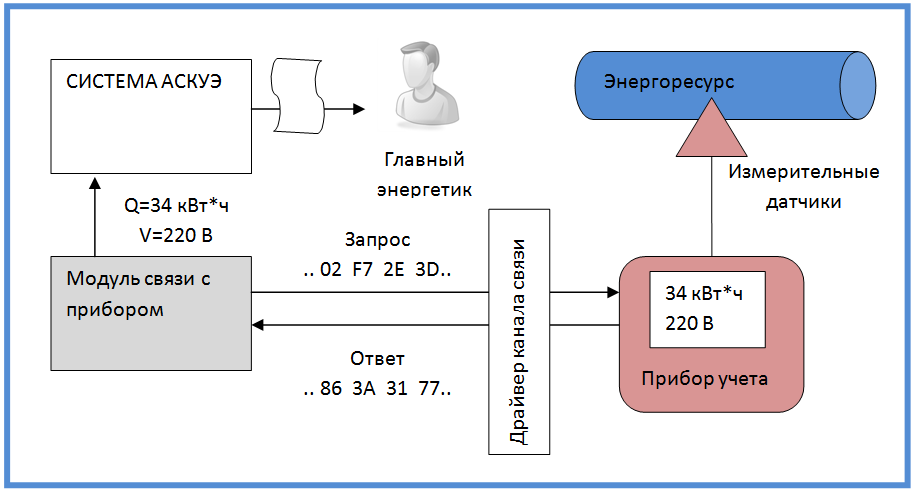
Since such systems are forced to deal with many different devices and controllers, most often they are built on a modular basis. Not so long ago I was asked to write a module for such a system that communicates with one of the metering devices (three-phase electronic energy meter CE2753 ).
In the course of the narration, you will see comments highlighted in this way. Their only goal is that you do not fall asleep in the process of getting to know the article.
I have long wanted to apply automated testing. I thought that now is just a good opportunity. Why did I decide so?
Why is this case convenient for trying testing?
- The module did not have a user interface - only a strictly defined API, which is very convenient to test.
- The project dates were not too tight, so I had time for experiments.
- The ASKUE system belongs to the class of industrial systems and excess reliability does not hinder it.
By betting on automated testing, I actually doubled the amount of code I needed to write. Looking ahead, I’ll say that I had to write a device emulator. But in the end, I think it was worth it.
One of the interesting consequences was that I could conduct development without a living device - having only a description of its protocol on hand. A living device, of course, appeared, but after the bulk of the code was created.
Development was carried out in the environment of Delphi 7. For automated testing, the DUnit library was used. Version Control System - Mercurial. Repository - BitBucket.
A little more information about the place of the module in the system
The main task of the module is to communicate with the meter according to a low-level protocol, and to provide the results of this communication in a form understandable to the ASKUE system. The physical communication channel, as a rule, is a COM port with various kinds of devices expanding its functionality - modems, interface converters. A very common bunch of RS-232 / RS-485. Sometimes TCP / IP is possible. For the nuances of organizing a communication channel, special ASKUE modules are responsible - channel drivers.
As for the protocol itself, in general terms it is a sequence of requests and responses in the form of a set of bytes. Almost always, requests and responses are followed by a checksum. It is difficult to say something more specific. The most characteristic representative of this method of communication is the MODBUS specification.
The MODBUS protocol is the destiny of gray and dull people. If you are a bright and creative person, you, of course, do not take advantage of a reliable and proven solution, but come up with your own version of the protocol that is nothing like it. And in this case, the marketing department will carefully write in the advertising brochure so as not to scare future buyers of the device that the device communicates using a MODBUS-like protocol. Although of course - there can be no talk of any compatibility with MODBUS.
The internal structure of the module
I give the internal structure of the module, which turned out as a result of several iterations of development and refactoring. You may notice that it is not very original.
The main Device object contains a code that is responsible for general actions with the device, as well as for returning the ASKUE data in the required format.
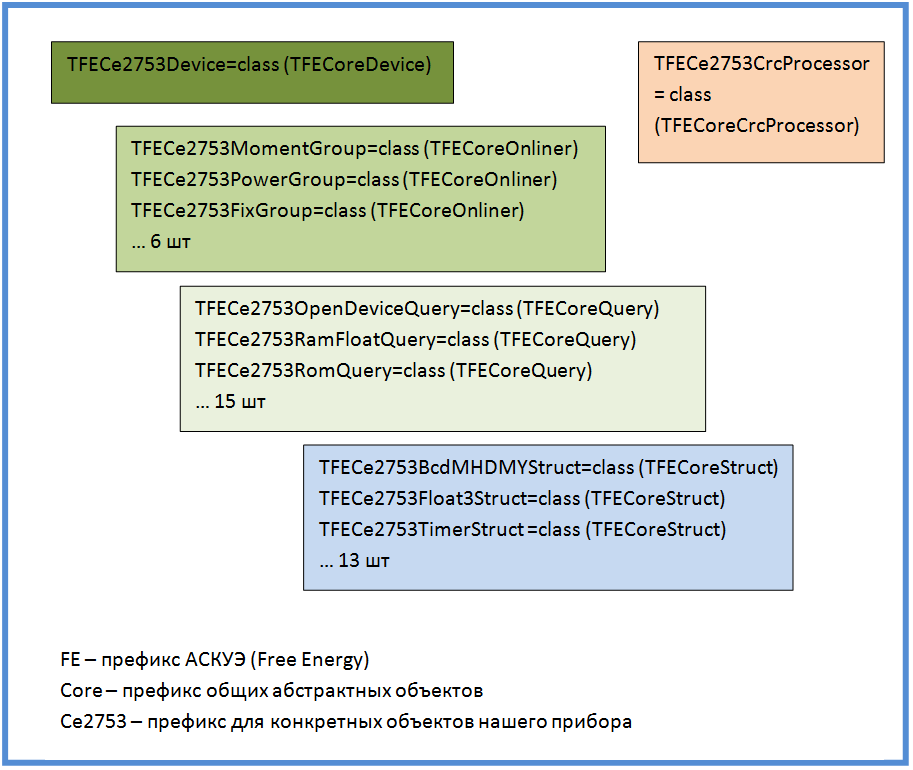
A Device object owns several Onliner objects. Each Onliner is responsible for a fully completed communication session with the device. Different types of online users are responsible for various typical operations with the device. The most common is polling a group of parameters. In the case of my device, there were six groups of parameters, each of them had its own Onliner.
Onliner uses Query objects in its work. The Query object is responsible for a single request-response cycle. The result of the Query object operation is a specific piece of information received from the device, reduced to a convenient form for use. In addition, the Query object recognizes incorrect and broken instrument responses, and repeats the query if necessary. This logic is hidden at the Query level and Onliner is not worried about this.
The lowest level is Struct objects. They are responsible for converting various low-level byte formats to the values used in the programming language. At the input of the Struct object, a stream of bytes is fed - at the output - values of type Integer, Float, String. Sometimes (almost always), the Struct object has to do non-trivial things. Thus, at the Struct level, all the mathematical work of serializing and deserializing data is encapsulated. He hides all the nuances of this hard work from higher levels.
The CrcProcessor object is also highlighted in the diagram. According to its name, it is responsible for calculating the checksum. The case is not as simple as it seems at first glance.
Below I will dwell a little more on data conversion (Struct) and checksum calculation (CrcProcessor), since the topic is interesting and there is something to talk about.
Data formats in metering devices
It is difficult to name any way of encoding information that you will not find in the requests and answers of metering devices.
The most harmless is the whole type. All types of addresses, pointers, counters are encoded as a whole type, sometimes the target parameters can also be of an integer type. A particular integer type differs in byte length and the sequence in which these bytes are transmitted over the channel.
Mathematics, or rather its carefully developed section - combinatorics, sets a strict limit to the number of permutations of objects (n!). For example, three bytes can be arranged in order of just 6 ways. This insurmountable (if they do not turn to quantum computing) theoretical limit very upsets the creators of the protocols of metering devices. If 3 bytes could be sent in 20 different ways, I think sooner or later you would encounter each of them.
The fixed-point type is, in my opinion, the most successful for metering devices. The idea is to transmit an integer value through the channel, with the caveat that the decimal point must then be shifted a few digits to the left. Very good and correctly behaving in various transformations type. So good that it is used as a standard in banking computing. (If anyone knows there is a Currency type in VisualBasic - it is structured just like that).
Since the basic type is intact, you cannot relax and forget about combinatorics and byte order.
Of course, in all respects, a lot of problems are a floating point type. There is only one recipe - to thoroughly understand what it means in it, where it is located, and what options may be. And again - remember the byte order.
Hoping that the floating-point type accidentally coincides in internal representation with one of the standard types of your platform is the height of disorder. If you are visited by such thoughts, you should do not programming, but a less risky craft - playing roulette, buying lottery tickets, betting on the World Cup.
The most interesting options arise when you try to transmit time stamps on a communication channel. Different parts of the date and time are transmitted in the most arbitrary formats.
The order of the year, month, day, hour, minute, second confidently strives all to the same theoretical limit (n!). You can still say a few words about the year. Since the problem of 2000 taught nothing to anyone, in most cases the year is transmitted in two digits.
Very often, the byte stream transmitted over the protocol is a direct dump of the internal memory of various microcircuits (timers, ADCs, ports, registers).
The guys creating the microchips know a lot about the careful use of each bit. So be prepared for the fact that you have to cut and paste individual bits and sets of bits from arbitrary places, glue them, apply masks, shift in different directions and do many more things without which the work of a real programmer would be a series of faceless days similar Each other.
I noted most of the formats, but this is far from all the subtleties. At any, most unexpected moment, special techniques can be applied that bring communication by protocol to a whole new level. For example, an exotic such as BCD (binary decimal format) or the transmission of numbers by ASCII characters can be applied. There are cases when parts of the same value are sent in different requests (for example, to get the whole part of the value you need to send one request to the device, to get the fractional one, the other).
The only thing I have not met is the transmission of national characters in UTF format. But I think it’s not a matter of goodwill, but the fact that working with UTF is a resource-intensive business, and the resources of microcontrollers are limited.
If you think that all of the above is the result of my vast experience working with several hundred devices, then you have to refute this. Almost all of this I met in the meter, for which I wrote a module. For those who do not believe, I can send a passport to the device and a description of the protocol. You will see that everything I wrote is true.
Checksum calculation
With the checksum, as I said above, is also not so simple as it might seem at first glance. Despite the fact that there are well-established terms CRC8, CRC16, CRC32, they do not give a clear understanding of how the checksum should be considered. And therefore, nuances always arise. The creators of communication protocols themselves know this and do not indicate a reference to the standard in the protocol description, but provide a piece of code (!!!), usually in C, which shows how the checksum should be calculated.
I would not recommend putting CRC calculation into shared libraries. Even if the algorithms coincide for several cases, someday you will come across a variant that completely turns your mind about CRC counting. I advise you to create your own algorithm for each device, even if you have to go for a small Copy-Paste.
In the case of my device, for some reason, the first byte of the request should not be included in the sequence for counting CRC. I consider it a great success that I paid attention to a short note in the description of the protocol. Because otherwise I would not be able to establish a connection with the device. Apparently, I came across the activity of the witness sect of the infallible first byte. In another way, I can’t explain all this.
Module Testing Scheme
The internal structure of the module and some features of its development, I described, now I bring the circuit testing module. The scheme does not repeat the structure of objects, but reflects the logical scheme of information flows and its verification. I think that this is the most important figure in the article and I will dwell on it in more detail.
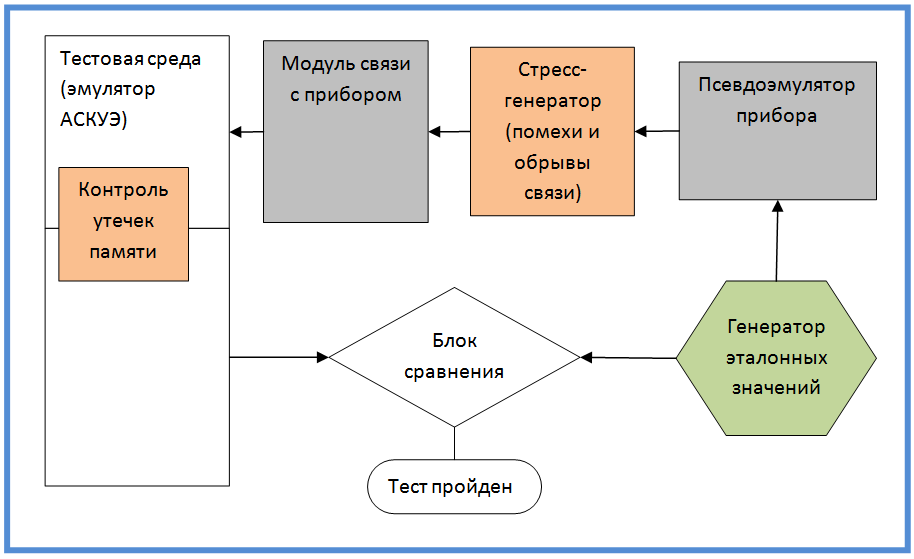
At first it seemed to me that this was a rather original scheme, but then I realized that it came up from my old institute knowledge (there were some courses in information theory).
The generator produces and remembers the reference values, they are accepted by the pseudo-emulator of the device and translates into a low-level protocol. The protocol is perceived by our module and reference values are restored from it. Values are returned to the test environment (which for the device module tries to look like ASKUE). Then the test environment compares the values obtained from the module with the reference values. Based on the comparison, a conclusion is made about the health of the module.
Two modules highlighted in red relate to stress testing. In particular, situations of lack of communication, disconnection, and packet distortion can be reproduced. The main task is to check the mechanisms of repeated requests to the device, as well as the correct allocation and release of memory in case of unexpected situations (this is monitored by a memory leak monitoring unit).
Reference value generator
Not a very complicated, but crucial unit is a reference value generator. The essence of the generator is to get the value of some measured ASKUE parameter. This value should, on the one hand, be varied and unpredictable (have a good distribution), and on the other hand, be deterministic (i.e. reproducible, from test to test, to enable us to effectively look for errors).
Without even thinking too much, it becomes clear that this should be some kind of hash function. Having experimented a bit with my own bike models, I eventually screwed up the Md5. I have no complaints about work. Below is the code for Delphi.
function TFECoreEmulator.GenNormalValue(const pTag:string):double;
var
A,B,C,D:longint;
begin
TFECoreMD5Computer.Compute(A,B,C,D,pTag+FE_CORE_EMULATOR_SECURE_MIX);
result:=0;
result:=result+Abs(A mod 1000)/1E3;
result:=result+Abs(B mod 1000)/1E6;
result:=result+Abs(C mod 1000)/1E9;
result:=result+Abs(D mod 1000)/1E12;
end;
function TFECoreEmulator.ModelValueTag(const pGroupNotation,
pParamNotation: string; const pStartTime, pFinishTime: TDateTime):string;
begin
result:=pGroupNotation+'@'+pParamNotation+'@'+DateTimeToStr(pStartTime)+'@'+DateTimeToStr(pFinishTime);
end;
As a result of simple transformations, we get the normal value (0..1), which we bring to the required range, and with a light heart we send to the emulator. At any time, the value can be reproduced with absolute accuracy.
Pseudo-emulator device
The main purpose of the pseudo-emulator is to generate responses to requests from the communication module with the device. He is “pseudo” because we are not talking about real emulation (this would be an ungrateful and useless work). All he has to do is form specific answers to specific requests. At the same time, if parameter values are needed, he turns to the generator of reference values.
There is nothing unusual in it, I will only note a special scheme for forming the answer. The first thing that comes to mind is a certain procedure (usually with the name Parse) for parsing a request and generating a response. But in practical implementation, this procedure grows to incredible sizes, with case and if strongly embedded in each other.
So I did a little different.
I provided the emulator with a set of helper objects — I named their replicas. Each replica tries to parse the request separately from the others. As soon as she understands that the request does not apply to her, she throws an exception, and the emulator passes the request for analysis to the next replica. Thus, it was possible to localize the code for each variant of the request in a separate object. If not a single replica has worked, it means that somewhere there is an error, either in the device module or in the emulator.
You can also see that I reused Struct objects (I taught structures how to encode and decode information) and CrcProcessor. Of course, this should not be done in terms of reliability. But I think you will forgive me this compromise.
From the point of view of reliability, a common code should not be used in the tested object and test infrastructure (since the error can be mutually compensated). It is desirable that different people write objects and their tests. And it is desirable that they do not know anything about each other, and at a meeting do not shake hands. As you know, I wrote all this alone and a similar methodology was not available to me.
Stress generator
The stress generator is included in the gap between the module and the device emulator. He can do the following things:
- Block emulator response completely
- Break the answer somewhere in the middle
- Distort any response byte
In the case of a break in the answer, a problem arose - in which place to break off the answer. I made the answer break off in the most critical place - when all the headers and preambles are sent and the module waits for real data. It should already create all the helper objects. If you interrupt the transmission in this place, then there is a maximum probability of memory leaks.
In the process of working with a live device, I came across a very interesting error: the response of the device formally meets all the rules, even the checksum matches. But the data itself does not match the requested. Especially for this case, I introduced another mode, which I called the internal error of the device.
After long deliberation, how can this be, I came to the conclusion that the device simply does not control the integrity of the request. And the checksum, about which so much is written in the manual, is not considered the device itself. Therefore, when the request is distorted (for example, the address of the requested memory changes), the device with a pure heart forms a normal in form, but erroneous answer.
Memory allocation control
I’ll tell you a little how I tested the module for the correct memory allocation. Many things are obvious and known to everyone, but I’ll tell you anyway. Some of this may be interesting.
For a long time, programmers have nightmares associated with memory allocation at night. The invention of Java and DotNet with garbage collectors has somewhat improved the situation. But I think that nightmares still remained. They simply became more refined and sophisticated.
Modern error handling systems that are based on an exception mechanism are extremely useful. But they greatly complicate the processes of allocation and release of resources. This is because when an exception occurs, it interrupts the execution of the procedure. An exception easily overcomes the boundaries of conditions, loops, routines, and modules. And, of course, the code for releasing resources at the end of the procedure will not be executed unless special measures are taken.
The best minds of mankind have been thrown to solve this problem. As a result, the try..finally construct was invented. This design also takes place on systems with garbage collectors, because the resource can be not only memory, but also, for example, an open file.
The classic application scheme in the case - if the resource - the object looks like this.
myObject:=TVeryUsefulClass.Create;
try
...
VeryEmergenceProcedure;
...
finally
myObject.Free;
end;
But I like this way more (it allows you to process all the objects involved in the code at once, in addition, you can create objects wherever and whenever).
myObject1:=nil;
myObject2:=nil;
try
...
myObject1:=TVeryUsefulClass.Create;
...
VeryEmergenceProcedure;
...
myObject2:=TVeryUsefulClass.Create;
...
VeryVeryEmergenceProcedure;
...
finally
myObject1.Free;
myObject2.Free;
end;
The recipe for proper memory management is simple - wherever resources are allocated and there is the possibility of exceptions - apply the try..finally scheme. But by inattention, it is easy to forget or do something wrong. Therefore, it would be nice to test.
I did as follows. He made a common ancestor of all his objects and, upon creation, made them register on the general list, and upon destruction, delete himself from the list. At the end, the list is checked for undetected objects. This not-so-complicated scheme is also supplemented with some elements that help identify the object and find the place in the code where it is created. For this, the object is assigned a unique label, and the moments of creation and deletion are displayed in the trace file.
var
ObjectCounter:integer;
ObjectList:TObjectList;
...
TFECoreObject = class (TObject)
public
ObjectLabel:string;
procedure AfterConstruction; override;
procedure BeforeDestruction; override;
end;
...
procedure TFECoreObject.AfterConstruction;
begin
inc(ObjectCounter);
ObjectLabel:=ClassName+'('+IntToStr(ObjectCounter)+')'
ObjectList.Add(self);
Trace('Create object '+ObjectLabel)
end;
...
procedure TFECoreObject.BeforeDestruction;
begin
ObjectList.Delete(self);
Trace('Free object '+ObjectLabel)
end;
...
procedure CheckObjects;
var
i:integer;
begin
for i:=0 to ObjectList.Count-1 do
Trace('Bad object '+(ObjectList[i] as TFECoreObject).ObjectLabel);
end;
The most discerning readers will say that this is already some embryonic mechanism of the garbage collector. Of course, the garbage collector is far away. I think this is a good compromise. I did not notice any slowdown in the code. In addition, using the conditional compilation directives in the working assembly, this mechanism can be disabled.
The mechanism has a drawback - it does not allow you to monitor the creation of objects not generated from my common ancestor. As a rule, these are standard library objects TStringList, TObjectList, etc. I developed a rule according to which I create them only in the constructors of my objects, and I destroy them in destructors. And the test is already monitoring their objects. If you do everything carefully, the probability of error is minimized.
Somewhere in 3 hours of stress testing, I managed to identify all the critical places and put try..finally in the right way.
Reference Accuracy
I don’t know how at the time of computers, and at the time of logarithmic rulers it was considered a bad form to dump 14 decimal places on a person, if only 3 of them are reliable. Therefore, in the ASKUE system, for each parameter, you can set the accuracy. For all parameters, it is different and is determined by the communication module with the device. Only he knows how the values are formed and what permissible accuracy can be ensured. After the main work was completed, I decided to experiment and find out the maximum capabilities of the module in terms of accuracy.
Why am I doing this? Probably it's all about natural curiosity. I saw magical things happen before my eyes. Reference values are packed into cunning formats never seen before, and then, with a wave of a magic wand, they are practically restored from the ashes. And if you have a magic wand you always want to wave it a little. I think curiosity will one day ruin me.
So, for each type of value, I began to change the permissible accuracy. I will not describe in detail, I will tell only about one case. I noticed that the tests began to fall when, in my sense of a margin of accuracy, there was still enough.
After a little investigation, I found that in several places I used Trunc to round off the simplicity of my soul. I replaced with Round and the marginal accuracy immediately increased by an order of magnitude.
Друзья, для округления чисел, конечно нужно использовать Round и RoundTo. Функция Trunc с математической точки зрения – нелепое, плохо ведущее себя преобразование. Trunc нужно использовать только в одном случае, для которого она и была придумана – отделение целой части от дробной. Во всех остальных случаях – Round. Иначе Вос ждут мелкие, а иногда и крупные неприятности.
Подключение к живому прибору
As I said above, I connected to this device when the bulk of the work was done. Having learned that the device needs to be connected via RS-485, I was very happy. After all, there are only two wires. Having a pioneer circle of radio electronics behind me, I thought that I could somehow cope with two wires. When I tried to connect the interface converter and the device, after reading the contact designations, I found a picture that led me into a long stupor:

Realizing that from the point of view of formal logic, the situation has no solution, I decided to look on the Internet.
I am a naive and unsophisticated person. I start each new project with a belief in the triumph of goodness and the inviolability of standards. And always cruel disappointments befall me. Worst of all, this is repeated from time to time. Life doesn't teach me anything.
On the Internet it was said that maybe A will connect both minus and plus. It all depends on the manufacturer. I decided that if there was such confusion, then at the wrong connection, at least nothing should burn. I tried this and that. Everything worked.
Of course, the real device brought a lot of improvements to the project. Real communication sessions have put a lot in their places. Major changes have affected error handling and stress testing. Especially when I connected to the device via wireless modems (almost every third answer came in distorted).
Conclusion

I hope you were interested in my short story about the development and testing of the ASKUE module. The most important I consider testing. The quality of the product directly depends on it. All changes made to the project and not confirmed by testing are a waste of time and effort. After all, at the slightest change in the code, the untested problem will come back again and again.
My work was inspired by the TDD methodology (Test-Driven-Development development through testing). But, of course, I did not succeed in pure TDD. Here is what I did not do:
- Didn't write tests ahead
- I did not write tests for each class
- Did not write short tests
I don’t know what type of testing to attribute what happened in the project - to the modular or integration. I would say that this is acceptance testing of the subsystem.
I don’t want you to think that I am complaining about life after reading the comments. On the contrary, this is exactly what makes programming the most interesting activity in the world. I also ask that the creators of metering devices not take everything to heart. I know that on the other side of the interface, life is also interesting. All my irony is directed mainly at myself.
I wish you all a pleasant programming.