Новый золотой век для компьютерной архитектуры
- Перевод
The authors are John Hennessy and David Patterson, laureates of the 2017 Turing Award “for an innovative systematic and measurable approach to the design and testing of computer architectures, which had a long-lasting impact on the entire microprocessor technology industry”. The article was published in the journal Communications of the ACM, February 2019, Vol. 62, No. 2, pp. 48-60, doi: 10.1145 / 3282307
 “Those who do not remember the past are doomed to repeat it” - George Santayana, 1905
“Those who do not remember the past are doomed to repeat it” - George Santayana, 1905
His Turing lectureOn June 4, 2018, we began with a review of computer architecture, starting in the 1960s. In addition to it, we are covering current issues and trying to identify future opportunities that promise a new golden age in the field of computer architecture in the next decade. The same as in the 1980s, when we conducted our research on improving the cost, energy efficiency, safety and performance of processors, for which we received this honorable award.
The software “talks” to the hardware through a dictionary called the “instruction set architecture” (ISA). By the early 1960s, IBM had four incompatible series of computers, each with its own ISA, software stack, I / O system and market niche — targeted at small business, large business, scientific applications and real-time systems, respectively. IBM engineers, including the Turing Award winner Frederick Brooks, Jr., decided to create a single ISA that would effectively unite all four.
They needed a technical solution, how to provide an equally fast ISA for computers with both an 8-bit and 64-bit bus. In a sense, tires are the “muscles” of computers: they do the job, but relatively easily “shrink” and “expand”. Then and now the biggest challenge for designers is the processor “brain” - control equipment. Inspired by programming, pioneer of computer technology and Turing Award winner Maurice Wilks offered options for simplifying this system. The control was represented as a two-dimensional array, which it called the "control memory" (control store). Each column of the array corresponded to a single control line, each row was a microinstruction, and the record of microinstructions was called microprogramming.. The control memory contains an ISA interpreter written by microinstructions, so the execution of the usual instruction takes several microinstructions. The control memory is implemented, in fact, in memory, and it is much cheaper than logical elements.
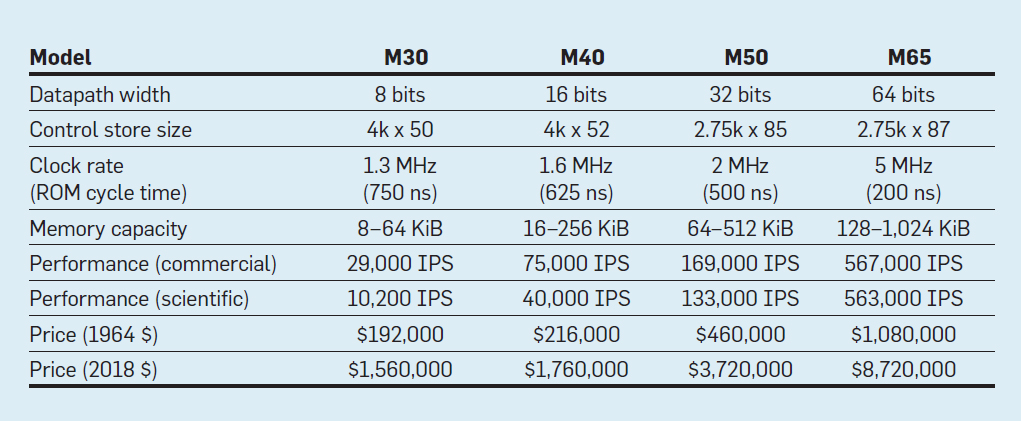
Characteristics of the four models of the IBM System / 360 family; IPS means the number of operations per second
The table lists four models of the new ISA in System / 360 from IBM, presented on April 7, 1964. Tires differ 8 times, memory size - at 16, clock frequency - almost at 4, performance - at 50, and cost - at almost 6. In most expensive computers, the most extensive control memory, because more complex data buses used more control lines . The cheapest computers have less control memory due to simpler hardware, but they needed more micro-instructions, since they needed more clock cycles to execute the System / 360 instruction.
Thanks to microprogramming, IBM has bet that the new ISA is revolutionizing the computing industry — and won the bet. IBM dominated its markets, and the descendants of the old IBM 55-year-old IBM mainframes still generate $ 10 billion in revenue a year.
As has been repeatedly noted, although the market is an imperfect arbiter as technology, but given the close links between architecture and commercial computers, it ultimately determines the success of architectural innovations, which often require significant engineering investments.
When computers switched to integrated circuits, Moore’s law meant that the control memory could become much larger. In turn, this allowed a much more complex ISA. For example, a VAX-11/780 control memory from Digital Equipment Corp. in 1977 it was 5,120 words for 96 bits, while its predecessor used only 256 words for 56 bits.
Some manufacturers allowed microprogramming to select customers who could add their own user functions. It was called the “writable control store (WCS)”. Alto is the most famous WCS computer.The Turing laureates Chuck Tucker and Butler Lampson and their colleagues created the Xerox Palo Alto research center in 1973. It was really the first personal computer: here is the first display with element-by-image imaging and the first Ethernet LAN. Controllers for innovative display and network cards were firmware stored in WCS with 4096 words of 32 bits each.
In the 70s, the processors still remained 8-bit (for example, the Intel 8080) and were programmed mostly in assembler. Competitors added new instructions to outdo each other, showing their achievements with assembler examples.
Gordon Moore believed that Intel’s next ISA would remain forever for the company, so he hired many smart doctors in computer science and sent them to a new facility in Portland to invent the next great ISA. The 8800 processor, as Intel originally called it, has become an absolutely ambitious computer architecture project for any era, of course, it was the most aggressive project of the 80s. It provided for 32-bit mandatory addressing (capability-based addressing), an object-oriented architecture, variable-length instructions, and its own operating system in the new Ada programming language.
Unfortunately, this ambitious project required several years of development, which forced Intel to launch an emergency backup project in Santa Clara to quickly launch a 16-bit processor in 1979. Intel gave the new team 52 weeks to develop a new ISA "8086", designing and assembling the chip. Given the tight schedule, ISA design took just 10 man-weeks over three regular calendar weeks, mainly due to the expansion of 8-bit registers and the 8080 instruction set to 16 bits. The team completed the 8086 schedule, but this emergency processor was announced without much fanfare.
Intel was very lucky that IBM designed a personal computer to compete with the Apple II and needed a 16-bit microprocessor. IBM looked closely at the Motorola 68000 with an ISA similar to the IBM 360, but it lagged behind IBM's aggressive graphics. Instead, IBM switched to the 8-bit version of the 8086 bus. When IBM announced the PC on August 12, 1981, it hoped to sell 250,000 computers by 1986. Instead, the company sold 100 million worldwide, presenting a very promising future with an extra ISA from Intel.
The original Intel 8800 project was renamed to iAPX-432. Finally, it was announced in 1981, but it required several microchips and had serious performance problems. It was completed in 1986, a year after Intel expanded the 16-bit ISA 8086 to 80386, increasing the registers from 16 bits to 32 bits. Thus, Moore's prediction regarding ISA turned out to be correct, but the market chose the 8086 made by scoops, rather than the iAPX-432 “anointed one”. As the architects of the Motorola 68000 and iAPX-432 processors understood, the market rarely knows how to be patient.
In the early 1980s, several studies of computers with a set of complex instructions (CISC) were carried out: they have large firmware in large control memory. When Unix demonstrated that even an operating system can be written in a high-level language, the main question was: “What instructions will compilers generate?” Instead of “What assembler will programmers use?” A significant increase in the hardware-software interface created an opportunity for innovation in architecture.
Turing Award winner John Cock and his colleagues have developed simpler ISA and compilers for minicomputers. As an experiment, they reoriented their research compilers to use in the IBM 360 ISA only simple operations between registers and memorized loads, avoiding more complex instructions. They noticed that programs run three times faster if they use a simple subset. Emer and Clark discoveredThat 20% of VAX instructions take up 60% of the microcode and take up only 0.2% of the execution time. One author of this article (Patterson) spent a creative leave at DEC, helping to reduce the number of errors in the VAX microcode. If the manufacturers of microprocessors were going to follow the construction of ISA with a set of complex CISC commands in large computers, then they assumed a large number of microcode errors and wanted to find a way to fix them. He wrote such an article , but Computer magazinerejected her. Reviewers have suggested that the terrible idea to build microprocessors with ISA is so complicated that they need to be repaired in the field. This failure questioned the value of CISC for microprocessors. Ironically, modern CISC microprocessors do include microcode recovery mechanisms, but the refusal to publish the article inspired the author to develop a less complex ISA for microprocessors — RISC computers.
These comments and the transition to high-level languages allowed us to move from CISC to RISC. First, the RISC instructions are simplified, so there is no need for an interpreter. RISC instructions are usually simple as microinstructions and can be executed directly by the hardware. Secondly, the fast memory previously used for the CISC microcode interpreter was converted to the RISC instruction cache (the cache is a small, fast memory that buffers recently executed instructions, since such instructions are likely to be reused soon). Third, register allocators based on the Gregory Chaytin graph dyeing schemeSignificantly facilitated compilers efficient use of registers, from which these ISA with the register-register operations. Finally, Moore's law led to the fact that in the 1980s there were enough transistors on a chip to put a full 32-bit bus on one chip, along with caches for instructions and data.
For example, in fig. Figure 1 shows the RISC-I and MIPS microprocessors developed at the University of California at Berkeley and Stanford University in 1982 and 1983, which demonstrated the advantages of RISC. As a result, in 1984, these processors were presented at the leading circuit design conference, IEEE International Solid-State Circuits Conference ( 1 , 2). It was a wonderful moment when several graduate students at Berkeley and Stanford created microprocessors that were superior to the industry of that era.

Fig. 1. RISC-I processors from the University of California at Berkeley and MIPS from Stanford University
Those academic chips inspired many companies to create RISC microprocessors, which were the fastest over the next 15 years. The explanation is related to the following processor performance formula:
Time / Program = (Instructions / Program) × (cycles / Instruction) × (Time / tact)
DEC engineers later showedthat for one program more complex CISCs require 75% of the number of RISC instructions (the first term in the formula), but in a similar technology (third member) each CISC instruction takes 5-6 cycles more (second member), which makes RISC microprocessors approximately 4 times faster.
Such formulas were not in the computer literature of the 80s, which forced us in 1989 to write the book Computer Architecture: A Quantitective Approach . The subtitle explains the topic of the book: use measurements and benchmarks to quantify tradeoffs instead of relying on the intuition and experience of the designer, as in the past. Our quantitative approach was also inspired by what Turing’s winner Donald Knuth’s book did for algorithms .
The next innovative ISA was supposed to surpass the success of both RISC and CISC. The architecture of very long VLIW machine instructions and its cousin EPIC (computation with explicit machine command parallelism) from Intel and Hewlett-Packard used long instructions, each of which consisted of several independent operations, connected together. Proponents of VLIW and EPIC at the time believed that if one instruction could specify, say, six independent operations — two data transfers, two integer operations and two floating point operations — and the compiler technology could effectively assign operations to six instruction slots, That equipment can be simplified. Similar to the RISC approach, VLIW and EPIC moved work from hardware to compiler.
Working together, Intel and Hewlett-Packard developed a 64-bit processor based on EPIC ideas to replace the 32-bit x86 architecture. High hopes were pinned on the first EPIC processor called Itanium, but the reality did not correspond to the early statements of the developers. Although the EPIC approach worked well for highly structured floating point programs, it could never achieve high performance for integer programs with less predictable branching and cache misses. As noted laterDonald Knuth: “It was supposed that the Itanium approach ... would be awesome - until it turned out that the desired compilers are basically impossible to write." Critics have noted delays in the release of Itanium and dubbed it “Itanik” in honor of the ill-fated passenger ship “Titanic”. The market was again unable to be patient and accepted as successor the 64-bit version of x86, and not Itanium.
The good news is that VLIW is still suitable for more specialized applications, where small programs run with simpler branches and cache passes, including digital signal processing.
AMD and Intel needed design teams of 500 people and superior semiconductor technology to narrow the performance gap between x86 and RISC. Again, for the sake of performance, which is achieved through pipelining, a decoder of instructions on the fly translates complex x86 instructions into internal RISC-like microinstructions. AMD and Intel then build a pipeline of their execution. Any ideas that RISC designers used to improve performance — separate instruction and data caches, second-level caches on a chip, a deep pipeline, and the simultaneous acquisition and execution of several instructions — were then included in x86. At the peak of the personal computer era in 2011, AMD and Intel supplied around 350 million x86 microprocessors annually.
With hundreds of millions of computers sold annually, software has become a giant market. While suppliers of software for Unix had to release different versions of software for different RISC architectures — Alpha, HP-PA, MIPS, Power, and SPARC — personal computers had one ISA, therefore, they released “uzhaty” software, binary compatible only with architecture x86 Because of the much larger software base, similar performance, and lower prices, by 2000, the x86 architecture dominated the desktop and small server markets.
Apple helped open the post-PC era with the release of the iPhone in 2007. Instead of purchasing microprocessors, smartphone companies made their own on-chip systems (SoC) using other people's work, including ARM's RISC processors. Here, designers are important not only performance, but also power consumption and the area of the crystal, which put at a disadvantage CISC architecture. In addition, the Internet of Things has significantly increased both the number of processors and the necessary tradeoffs in chip size, power, cost, and performance. This trend has increased the importance of time and cost of design, which further worsened the position of CISC processors. In today's post-PC era, annual x86 shipments fell by almost 10% from peak 2011, while RISC chips soared to 20 billion.
Concluding this historical review, we can say that the market has settled the dispute between RISC and CISC. Although CISC won the later stages of the PC era, but RISC wins now, when the post-PC era has arrived. New ISA on CISC has not been created for decades. To our surprise, the general opinion on the best ISA principles for general purpose processors today is still in favor of RISC, 35 years after its invention.
“If a problem does not have a solution, perhaps this is not a problem, but a givenness with which one should learn to live.” - Shimon Perez
Although the previous section focused on developing the instruction set architecture (ISA), most designers in the industry do not develop new ISA, and implement the existing ISA in the existing production technology. Since the end of the 70s, integrated circuits on MOS structures (MOS), first n-type (nMOS), and then complementary (CMOS) have been the prevailing technology. The staggering pace of MOS technology advancement — captured in the predictions of Gordon Moore — became the driving force that allowed designers to develop more aggressive methods of achieving performance for this ISA. Moore's initial prediction in 1965provided for an annual doubling of the density of transistors; in 1975, he revised it , predicting a doubling every two years. In the end, this forecast became known as Moore's law. Since the density of transistors grows quadratically and the speed linearly, with a larger number of transistors you can improve performance.
Although Moore’s law acted for many decades (see Fig. 2), somewhere around the year 2000 it began to slow down, and by 2018, the gap between Moore’s prediction and current opportunities had grown to 15 times. In 2003, Moore expressed the opinion that this was inevitable . At present, it is expected that the gap will continue to widen as the CMOS technology approaches the fundamental limits.
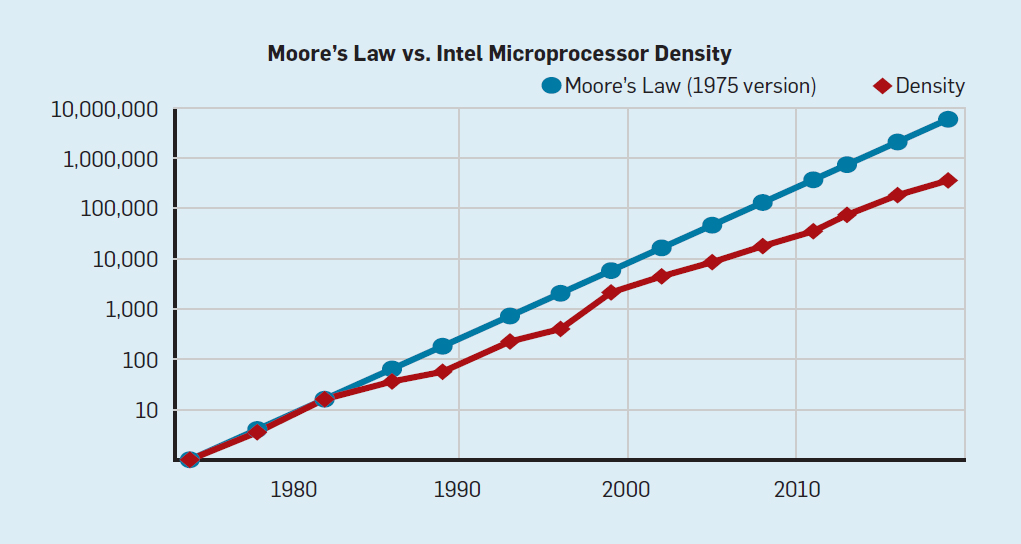
Fig. 2. The number of transistors on an Intel chip versus Moore's
Law Moore 's Law was accompanied by a projection made by Robert Dennard called “Dennard Scaling”As the transistor density increases, the power consumption per transistor will decrease, so the consumption per mm² of silicon will be almost constant. As the computing power of silicon millimeter grew with each new generation of technology, computers became more energy efficient. Dennard's scaling began to slow significantly in 2007, and by 2012 it was almost gone (see Figure 3).
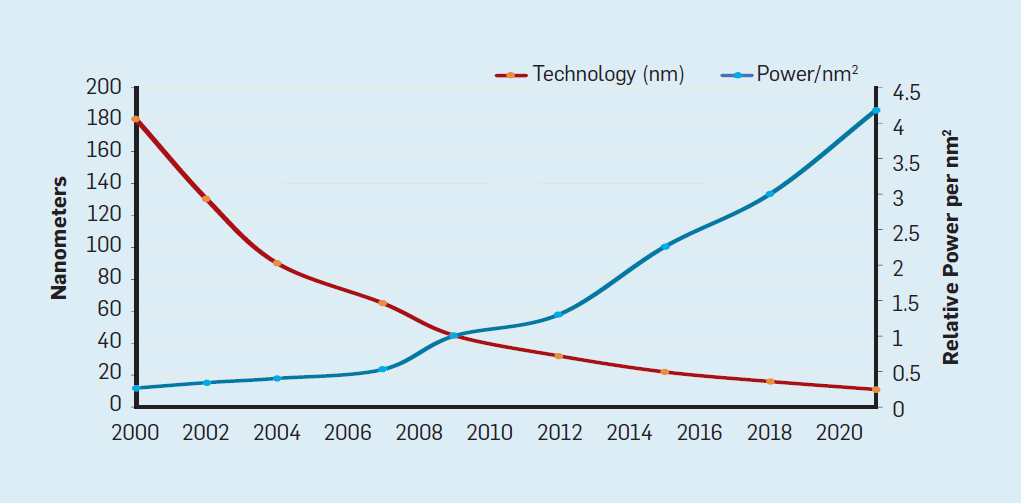
Fig. 2. The number of transistors per chip and energy consumption per mm²
From 1986 to 2002, instruction-level overlap (ILP) was the main architectural method for increasing productivity. Along with the increase in the speed of the transistors, this gave an annual performance increase of about 50%. The end of Dennard's scaling meant that architects had to find better ways to use concurrency.
To understand why an increase in ILP reduced efficiency, consider the core of modern ARM, Intel and AMD processors. Suppose that he has a 15-stage pipeline and four instructions per beat. Thus, at any time, up to 60 instructions are on the conveyor, including approximately 15 branches, since they constitute approximately 25% of the instructions executed. To fill the pipeline, the branches are predicted, and the code is speculatively placed in the pipeline for execution. A speculative forecast is at the same time a source of both ILP productivity and inefficiency. When branch prediction is ideal, speculation boosts performance and only slightly increases power consumption — and can even save energy — but when branches are predicted incorrectly, the processor must throw out incorrect calculations, and all the work and energy is wasted. The internal state of the processor will also have to be restored to the state that existed before the misunderstood branch, with the expenditure of additional time and energy.
To understand how difficult this design is, imagine the difficulty of correctly predicting the results of 15 branches. If the designer of the processor puts a limit of 10% loss, the processor must correctly predict each branch with an accuracy of 99.3%. There are not many general purpose programs with branches that can be predicted so accurately.
To evaluate what this wasted work consists of, consider the data in Figure 2. 4, showing the proportion of instructions that are effectively executed, but are wasted because the processor incorrectly predicted branching. In SPEC tests on an Intel Core i7, an average of 19% of the instructions are wasted. However, the amount of energy expended is greater, since the processor must use additional energy to restore the state when it has incorrectly predicted.
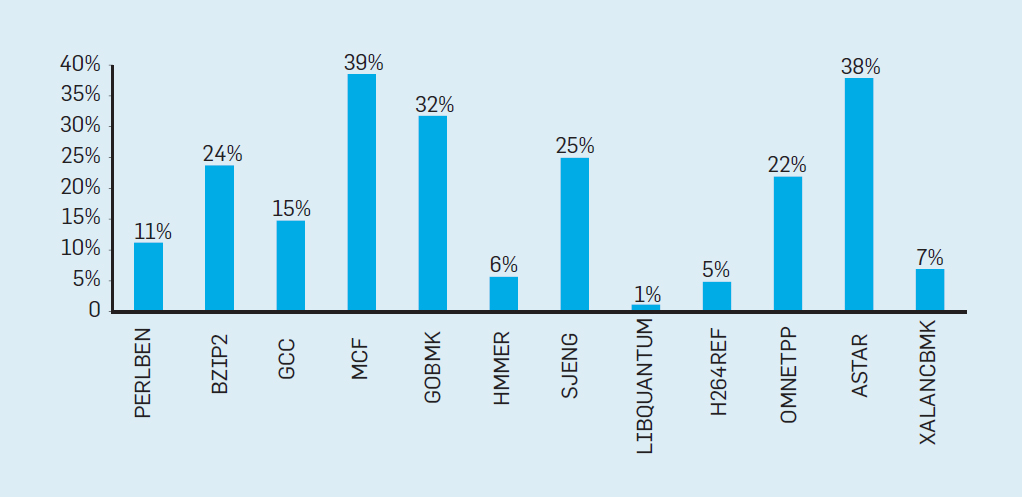
Fig.4. Wasted instructions as a percentage of all instructions executed on the Intel Core i7 for various SPEC integer tests
Such measurements led many to conclude that you need to look for a different approach to achieve better performance. Thus was born a multi-core era.
In this concept, the responsibility for identifying concurrency and deciding how to use it is shifted to the programmer and language system. Multi-core does not solve the problem of energy-efficient computing, which was exacerbated by the end of Dennard scaling. Each active core consumes energy, regardless of whether it is involved in effective calculations. The main obstacle is the old observation, called the law of Amdal. It says that the benefit from parallel computing is limited to the fraction of consecutive calculations. To appreciate the importance of this observation, consider Figure 5. It shows how much faster an application works with 64 cores compared to one core, assuming a different share of sequential calculations when only one processor is active. For example, if 1% of the time the calculation is performed sequentially, then the advantage of the 64-processor configuration is only 35%. Unfortunately, the power consumption is proportional to 64 processors, so about 45% of the energy is wasted.
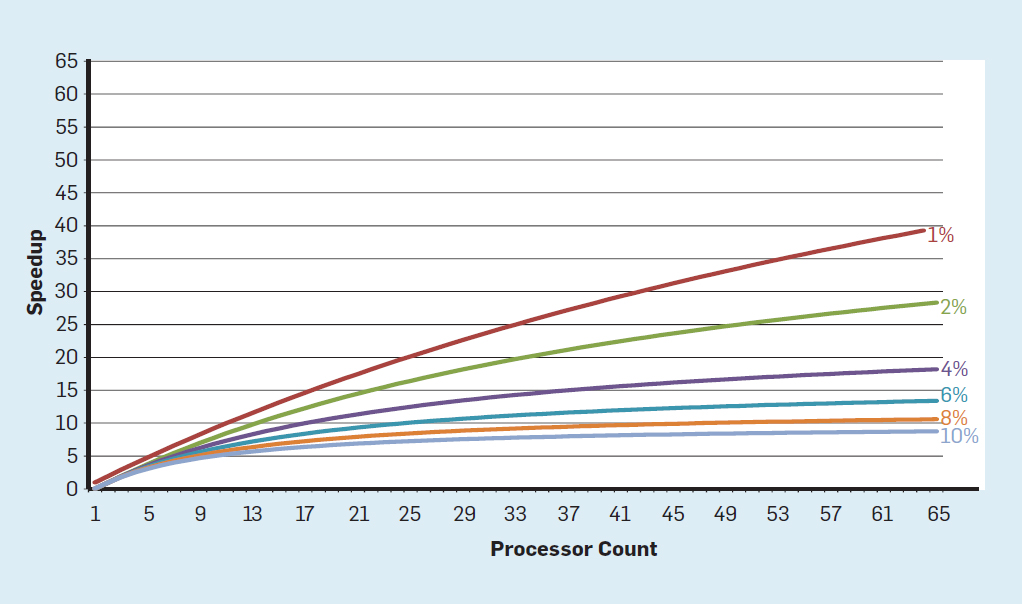
Fig. 5. The influence of Amdal's law on the increase in speed, taking into account the share of cycles in the sequential mode
Of course, real programs have a more complex structure. There are fragments that allow using a different number of processors at any given time. However, the need to periodically interact and synchronize them means that most applications have some parts that can effectively use only part of the processors. Although the Amdahl law is over 50 years old, it remains a difficult obstacle.
With the end of Dennard scaling, an increase in the number of cores on a chip meant that the power also increased at almost the same speed. Unfortunately, the voltage applied to the processor should then also be removed as heat. Thus, multi-core processors are limited by thermal output power (TDP) or the average amount of power that the chassis and cooling system can remove. Although some high-end data centers use more advanced cooling technologies, no user wants to put a small heat exchanger on the table or carry a radiator on their backs to cool their mobile phone. The TDP limit led to an era of “dark silicon” (dark silicon), when processors slow down the clock frequency and turn off idle cores to prevent overheating. Another way to consider this approach is to
The non-scaling epoch of Dennard, along with the reduction of Moore's law and Amdahl's law, means that inefficiency limits productivity improvement to only a few percent a year (see Figure 6).
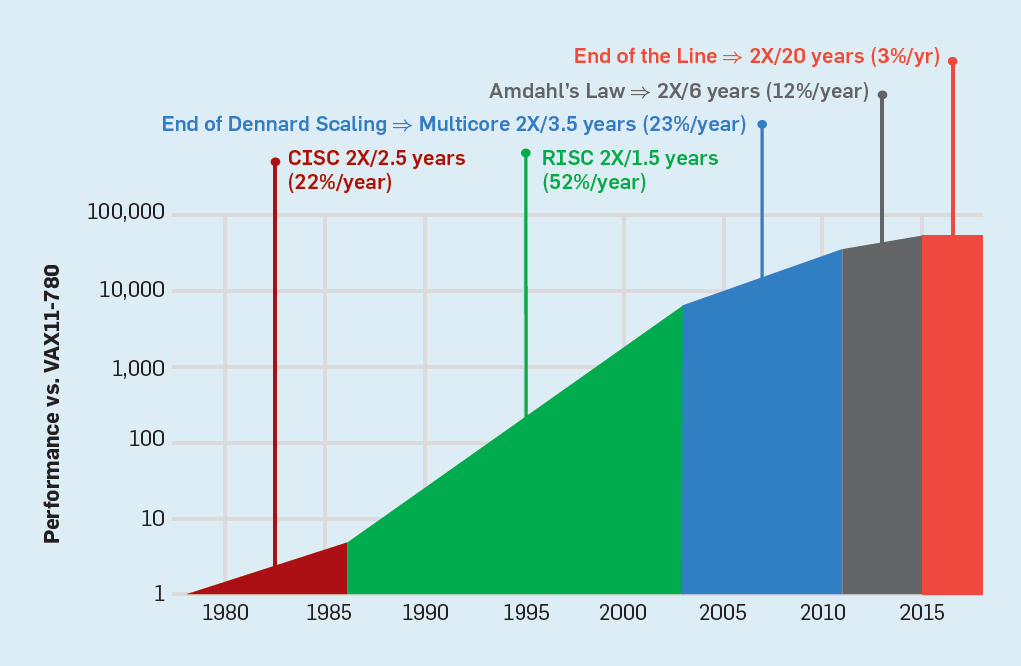
Fig. 6. Increased computer productivity in integer tests (SPECintCPU)
Achieving higher rates of productivity improvement — as noted in the 80s and 90s — requires new architectural approaches that take advantage of integrated circuit capabilities much more efficiently. We will return to the discussion of potentially effective approaches, mentioning another serious drawback of modern computers - security.
In the 70s, processor developers diligently ensured computer security using different concepts, ranging from protective rings to special functions. They were well aware that most of the bugs would be in software, but they believed that architectural support could help. These functions were largely not used by operating systems that operated in a supposedly safe environment (like personal computers). Therefore, the functions associated with significant overhead are eliminated. In the software community, many believed that formal testing and methods like using a microkernel would provide effective mechanisms for creating highly secure software. Unfortunately, the scale of our common software systems and the desire for performance meant that such methods could not keep up with performance. As a result, large software systems still have many security flaws, and the effect is exacerbated by the huge and growing amount of personal information on the Internet and the use of cloud computing, where users share the same physical hardware with a potential intruder.
Although processor designers and others may not immediately recognize the growing importance of security, they began to include hardware support for virtual machines and encryption. Unfortunately, branch prediction introduced an unknown but significant security flaw in many processors. In particular, the vulnerabilities of Meltdown and Specter use microarchitecture features, allowing leakage of protected information . They both use the so-called attacks on third-party channels, when information leaks through the time difference spent on the task. In 2018, researchers showed how to use one of Specter’s options to extract information over the network without downloading code to the target processor.. Although this attack, called NetSpectre, transmits information slowly, but the very fact that it allows you to attack any machine on the same local network (or cluster in the cloud) creates many new attack vectors. Subsequently, two more vulnerabilities were reported in the virtual machine architecture ( 1 , 2 ). One of them, called Foreshadow, allows you to penetrate Intel SGX security mechanisms designed to protect the most valuable data (such as encryption keys). New vulnerabilities are found monthly.
Attacks on third-party channels are not new, but in most cases, before, the fault was in software bugs. In Meltdown, Specter and other attacks this is a flaw in the hardware implementation. There is a fundamental difficulty in how processor architects determine what is the correct implementation of ISA, because the standard definition says nothing about the performance effects of executing a sequence of instructions, only about the visible ISA architectural state of execution. Architects should review their definition of the correct implementation of ISA to prevent such security flaws. At the same time, they need to rethink the attention they give to computer security, and how architects can work with software developers to implement more secure systems.
“We have tremendous opportunities disguised as unsolvable problems” - John Gardner, 1965
The inherent inefficiency of general-purpose processors, be it ILP technologies or multi-core processors, combined with the completion of Dennard scaling and Moore's law make it unlikely architects and processors will be able to support significant rates of increase in performance of general purpose processors Given the importance of improving performance for software, we must ask the question: what other promising approaches are there?
There are two clear possibilities, as well as a third one, created by combining these two. First, existing software development methods widely use high-level languages with dynamic typing. Unfortunately, such languages are usually interpreted and executed extremely inefficiently. To illustrate this inefficiency Leiceson and colleagues gave a small example: the multiplication of matrices .
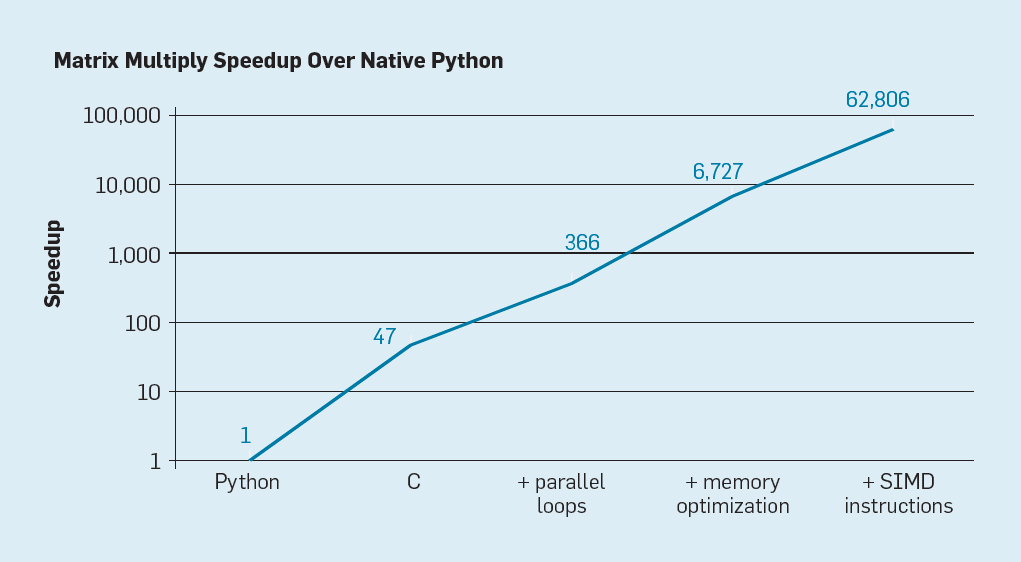
Fig. 7. Potential acceleration of Python matrix multiplication after four optimizations.
As shown in fig. 7, simply rewriting code from Python to C improves productivity by 47 times. Using parallel loops on many cores gives an additional factor of about 7. Optimizing the memory structure for using caches gives a factor of 20, and the last factor 9 comes from using hardware extensions to perform parallel SIMD operations that are capable of performing 16 32-bit operations per instruction. After that, the final, highly optimized version runs on a multi-core Intel processor 62,806 times faster than the original Python version. This, of course, is a small example. It can be assumed that programmers will use an optimized library. Although there is an exaggerated performance gap, there are probably many programs that
An interesting area of research is the question of whether some performance gaps can be eliminated with the help of a new compiler technology, perhaps with the help of architectural improvements. Although it is difficult to efficiently translate and compile high-level scripting languages such as Python, the potential gain is huge. Even a small optimization can lead to the fact that Python programs will run tens or hundreds of times faster. This simple example shows how wide the gap is between modern languages, focused on the efficiency of a programmer, and traditional approaches that emphasize performance.
A more hardware-oriented approach is the design of architectures adapted to a specific subject area, where they demonstrate significant efficiency. These are specialized or domain-specific architectures (DSA). These are usually programmable and turing-complete processors, but taking into account a specific class of problems. In this sense, they differ from specialized integrated circuits (application-specific integrated circuits, ASIC), which are often used for one function with a code that rarely changes. DSAs are often referred to as accelerators, since they speed up some applications compared to running an entire application on a general purpose CPU. In addition, DSAs can provide better performance because they are more precisely adapted to the needs of the application. Examples of DSAs include graphics processors (GPUs), neural network processors used for deep learning, and processors for software-defined networks (SDNs). DSAs achieve higher performance and greater energy efficiency for four main reasons.
First, DSAs use a more efficient form of parallelism for a particular subject area. For example, SIMD (single command stream, multiple data stream) is more efficient than MIMD (multiple command stream, multiple data stream). Although SIMD is less flexible, it is well suited for many DSAs. Specialized processors may also use VLIW approaches to ILP, instead of poorly working speculative mechanisms. As mentioned earlier, VLIW processors are poorly suited for general purpose code.But for narrow areas it is much more efficient, since management mechanisms are simpler. In particular, the most top-end general-purpose processors are excessively multi-pipelined, which requires complex control logic both for the beginning and for the completion of instructions. In contrast, the VLIW performs the necessary analysis and planning at compile time, which can work well for an explicitly parallel program.
Second, DSA services use memory hierarchy more efficiently. Memory access has become much more expensive than arithmetic, as Horowitz noted. For example, accessing a block in a 32-kilobyte cache requires approximately 200 times more energy than adding 32-bit integers. This huge difference makes memory access optimization critical to achieving high energy efficiency. General-purpose processors execute code in which memory accesses typically exhibit spatial and temporal locality, but are otherwise not very predictable at compile time. Therefore, to increase the bandwidth of the CPU, multi-level caches are used and the delay is hidden in relatively slow DRAM outside the crystal. These multi-level caches often consume about half of the processor's power, but they prevent almost all access to DRAM, which takes about 10 times more energy than access to the latest level cache.
Caches have two noticeable flaws.
When data sets are very large . Caches simply work poorly when data sets are very large, have low temporal or spatial locality.
When caches work well . When caches work well, locality is very high, that is, by definition, most of the cache is idle most of the time.
In applications where memory access patterns are well defined and understandable at compile time, which is true for typical domain-specific languages (DSL), programmers and compilers can optimize memory usage better than dynamically allocated caches. Thus, DSAs typically use a relocation memory hierarchy that is explicitly controlled by software, just as vector processors work. In the corresponding applications, “manual” memory control by the user allows you to spend much less energy than the standard cache.
Thirdly, DSA can reduce the accuracy of calculations if high accuracy is not needed. General purpose CPUs typically support 32-bit and 64-bit integer calculations, as well as floating-point data (FP). For many applications in machine learning and graphics, this is excessive accuracy. For example, in deep neural networks, 4, 8, or 16-bit numbers are often used in calculations, improving both data throughput and computational power. Similarly, floating point computations are useful for learning neural networks, but 32 bits is enough, and often 16 bits.
Finally, DSAs benefit from programs written in domain-specific languages that allow more concurrency, improve structure, memory access, and simplify the efficient application of a program onto a specialized processor.
DSAs require high-level operations to be adapted to the processor architecture, but this is very difficult to do in a general purpose language such as Python, Java, C, or Fortran. Domain-specific languages (DSL) help with this and allow DSA to be programmed effectively. For example, DSL can make explicit vector, dense matrix and sparse matrix operations, which will allow the DSL compiler to efficiently match operations with the processor. The domain-specific languages include Matlab, a language for working with matrices, TensorFlow for programming neural networks, P4 for programming software-defined networks, and Halide for image processing with an indication of high-level transformations.
The problem with DSL is how to maintain sufficient architectural independence so that the software on it can be ported to different architectures, while achieving high performance when comparing software with the base DSA. For example, the XLA system translates Tensorflow code to heterogeneous systems with Nvidia GPUs or tensor processors (TPU). Balancing portability between DSAs while preserving efficiency is an interesting research challenge for language developers, compilers, and DSAs themselves.
As an example of DSA, consider Google TPU v1, which is designed to speed up the operation of a neural network ( 1 , 2 ). This TPU has been produced since 2015, and many applications work on it: from search queries to text translation and image recognition in AlphaGo and AlphaZero, DeepMind programs for go and chess. The goal was to improve the performance and energy efficiency of deep neural networks by 10 times.
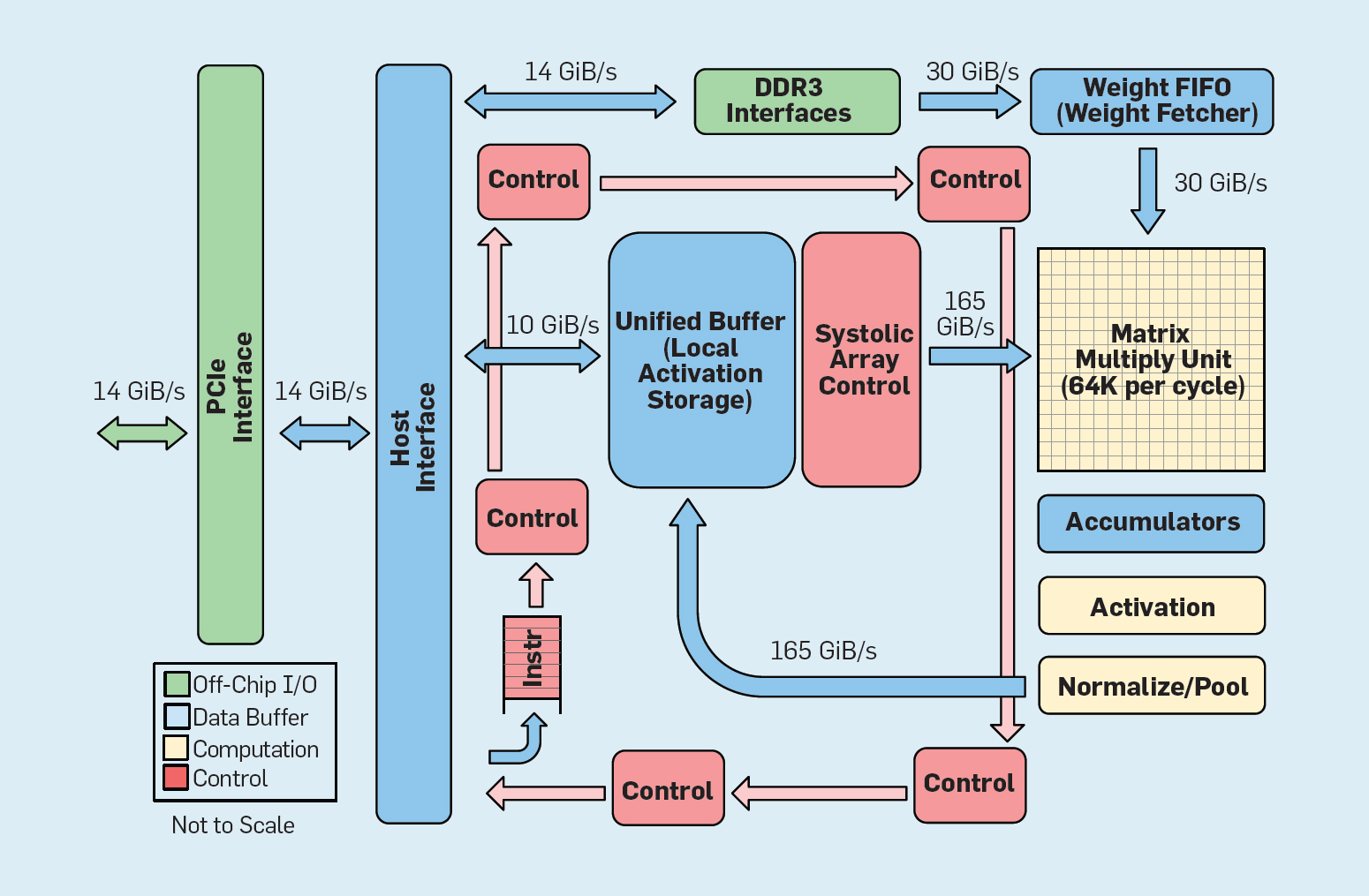
Fig. 8. The functional organization of the Google Tensor Processing Unit (TPU v1)
As shown in Figure 8, the organization of the TPU is radically different from the general purpose processor. The main computational unit is the matrix unit, the structure of systolic arrayswhich each clock cycle produces 256 × 256 multiply accumulations (multiply-accumulate). The combination of 8-bit accuracy, a highly efficient systolic structure, SIMD control, and the allocation of a significant part of the chip to this function help to perform approximately 100 times more accumulation and accumulation operations than the core of a general-purpose CPU per cycle. Instead of TPU caches, 24 MB of local memory is used, which is approximately twice as large as caches of general purpose CPU 2015 with the same TDP. Finally, both the neuron activation memory and the neural network weights memory (including the FIFO structure, which stores weights) are connected via high-speed channels controlled by the user. The weighted average performance of TPU in six typical problems of logical inference of neural networks in Google data centers is 29 times higher than that of general-purpose processors.
We considered two different approaches to improving program performance by increasing the efficiency of using hardware technologies. First, by improving the performance of modern high-level languages, which are usually interpreted. Secondly, by creating architectures for specific subject areas that significantly improve performance and efficiency compared to general-purpose processors. Domain-specific languages are another example of how to improve the hardware-software interface that allows you to implement architectural innovations, such as DSA. To achieve significant success with these approaches, you will need a vertically integrated project team that understands applications, domain-specific languages and related compilation technologies, computer architecture, as well as in basic technology implementation. The need for vertical integration and design decision making at different levels of abstraction was typical of most early work in the field of computing technology before the industry became horizontally structured. In this new era, vertical integration has become more important. Benefits will be given to teams that can find and accept complex trade-offs and optimizations.
This opportunity has already led to a surge in architectural innovation, attracting many competing architectural philosophies: the
GPU . Nvidia GPUs use multiple cores, each with large register files, multiple hardware threads and caches.
TPU . Google's TPUs rely on large two-dimensional systolic arrays and software-controlled on-chip memory.
FPGA . Microsoft, in its data centers, implements user-programmable gate arrays (FPGAs), which it uses in neural networks.
CPU. Intel offers processors with many cores, a large multi-level cache and one-dimensional SIMD instructions, in a way like Microsoft's FPGA, and a new neural processor closer to TPU than to a CPU .
In addition to these major players, dozens of start-ups implement their own ideas . To meet growing demand, designers combine hundreds and thousands of chips to create neural network supercomputers.
This avalanche of neural network architectures speaks of the advent of an interesting time in the history of computer architecture. In 2019, it is difficult to predict which of these many directions will win (if someone wins at all), but the market will definitely determine the result, just as he settled the architectural debates of the past.
Following the example of a successful open source software, open ISA represents an alternative opportunity in a computer architecture. They are needed to create a kind of “Linux for processors” so that the community can create open source kernels in addition to individual companies that own proprietary cores. If many organizations are developing processors using the same ISA, then more competition can lead to even faster innovations. The goal is to provide architecture for processors ranging from a few cents to $ 100.
The first example is RISC-V (RISC Five), the fifth architecture of RISC, developed at the University of California at Berkeley . It is supported by the community under the leadership of the Foundation RISC-V. The openness of the architecture allows the evolution of ISA to occur in public view, with the involvement of experts before making a final decision. An additional advantage of an open fund is that ISA is unlikely to expand primarily for marketing reasons, because sometimes this is the only explanation for expanding your own instruction sets.
RISC-V is a modular instruction set. A small instruction base launches a full open source software stack, followed by additional standard extensions that designers can enable or disable depending on needs. This database contains 32-bit and 64-bit versions of addresses. RISC-V can only grow through optional extensions; the software stack will still work fine, even if architects do not accept new extensions. Proprietary architectures typically require upward compatibility at the binary code level: this means that if the processor company adds a new feature, all future processors must also include it. The RISC-V is wrong, here all the improvements are optional and can be deleted if they are not needed by the application.
The third distinctive feature of RISC-V is the simplicity of ISA. Although this figure is not quantifiable, here are two comparisons with the ARMv8 architecture, which ARM developed in parallel:
Simplicity simplifies both the design of the processor design and the verification of their correctness. Since RISC-V focuses on everything from data centers to IoT devices, design verification can be a significant part of development costs.
Fourth, RISC-V is a design from scratch 25 years later, where architects learn from the mistakes of their predecessors. Unlike the first generation RISC architecture, it avoids microarchitecture or functions that depend on technology (such as deferred branches and deferred loads) or innovations (like register windows), which have been supplanted by compiler achievements.
Finally, RISC-V supports DSA, reserving a vast amount of opcodes for custom accelerators.
In addition to RISC-V, Nvidia also announced (in 2017)free and open architecture , she calls it the Nvidia Deep Learning Accelerator (NVDLA). This is a scalable, customizable DSA for inference in machine learning. Configuration parameters include the data type (int8, int16 or fp16) and the size of the two-dimensional multiplication matrix. Silicon substrate scales range from 0.5 mm² to 3 mm², and energy consumption ranges from 20 mW to 300 mW. ISA, software stack and implementation are open.
Open simple architectures work well with security. First, security experts do not believe in security through obscurity, so open implementations are attractive, and open implementations require an open architecture. Equally important is the increase in the number of people and organizations that can innovate in the field of secure architectures. Proprietary architectures limit employee participation, but open architectures allow the best minds in academia and industry to help with security. Finally, the simplicity of RISC-V simplifies the verification of its implementations. In addition, open architectures, implementations, and software stacks, as well as FPGA plasticity, mean that architects can deploy and evaluate new solutions online with weekly rather than annual release cycles. Although FPGA is 10 times slower than custom chips, but their productivity is enough to work online and exhibit security innovations in front of real attackers to test. We expect open architects to be an example of a joint design of hardware and software by architects and security experts.
The Software Development Manifesto (2001) by Beck et al. Revolutionized software development, eliminating the problems of the traditional waterfall system based on planning and documentation. Small teams of programmers quickly create working but incomplete prototypes, and receive customer feedback before the next iteration. Scrum version of Agile brings together teams of five to ten programmers who perform sprints of two to four weeks per iteration.
Again, having borrowed the idea from software development, it is possible to organize flexible hardware development. The good news is that modern electronic computer-aided design (ECAD) tools have increased the level of abstraction, allowing for flexible development. This higher level of abstraction also increases the level of reuse of work between different designs.
Four-week sprints seem implausible for processors, considering the months between when creating a design and producing a chip. In fig. 9 shows how the flexible method can work by modifying the prototype at an appropriate level .
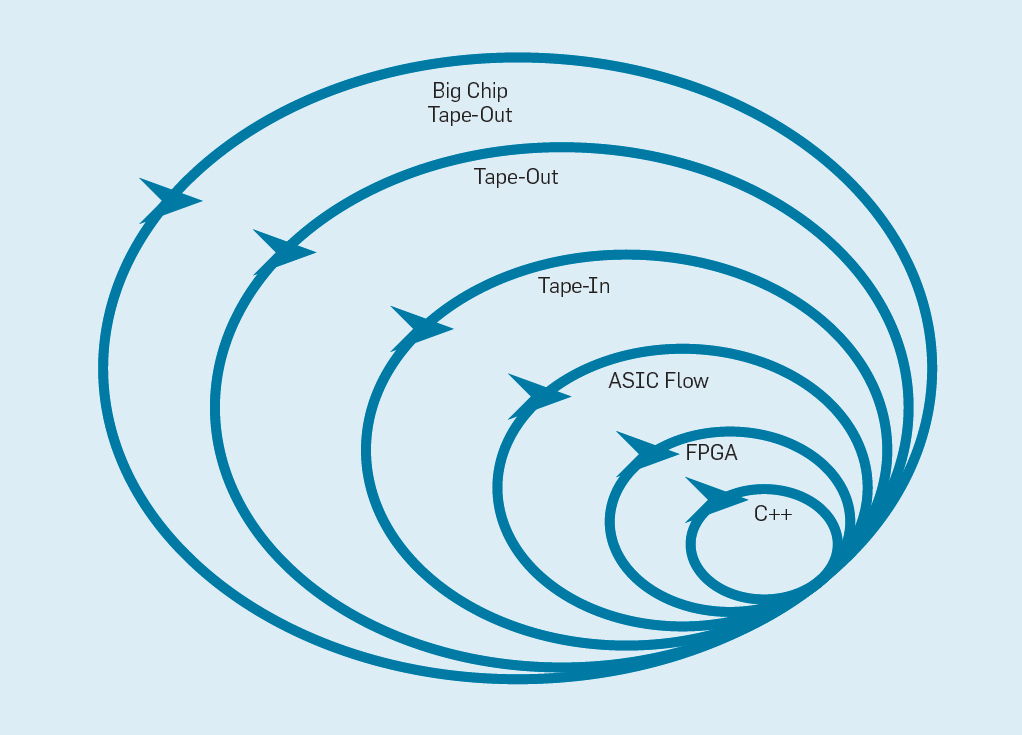
Fig. 9. Flexible equipment development methodology
The innermost level is a software simulator, the easiest and fastest place to make changes. The next level is FPGA chips, which can work hundreds of times faster than a detailed software simulator. FPGAs can work with operating systems and full benchmarks, such as the Standard Performance Evaluation Corporation (SPEC), which allows for much more accurate evaluation of prototypes. Amazon Web Services offers FPGAs in the cloud, so architects can use FPGAs without having to first buy equipment and build a lab. The next level uses ECAD tools to generate a chip layout, document dimensions and power consumption. Even after using the tools, you must perform some manual steps to refine the results before sending the new processor into production.tape in . These first four levels support four-week sprints.
For research purposes, we could stay at the fourth level, since estimates of area, energy, and performance are very accurate. But it was like a runner ran a marathon and stopped 5 meters before the finish, because his finish time is already clear. Despite the heavy preparation for the marathon, he will miss the thrill and pleasure of actually crossing the finish line. One of the advantages of hardware engineers over software engineers is that they create physical things. Get chips from the factory: measure, run real programs, show them to friends and family - a great joy for the designer.
Many researchers believe that they should stop, because the manufacture of chips is too affordable. But if the construction is small, it is surprisingly inexpensive. Engineers can order 100 1 mm² microcircuits for as little as $ 14,000. At 28 nm, a 1 mm2 chip contains millions of transistors: this is enough for both the RISC-V processor and the NVLDA accelerator. The outermost level is expensive if the designer intends to create a large microcircuit, but many new ideas can be demonstrated on small chips.
“The darkest hour is just before dawn” - Thomas Fuller, 1650
To benefit from the lessons of history, processor makers need to understand that much can be learned from the software industry, that increasing the hardware / software interface abstraction level provides opportunities for innovation and that the market in ultimately determine the winner. iAPX-432 and Itanium demonstrate how investments in architecture may fail, while S / 360, 8086 and ARM have provided high results for decades without an end in sight.
Completing Moore's Law and Dennard's scaling, as well as slowing the growth of standard microprocessor performance, are not problems to be solved, but a given, which, as we know, offers exciting opportunities. High-level domain-specific languages and architectures that exempt from the chains of proprietary instruction sets, along with the public demand for increased security, will open a new golden age for computer architecture. In open source ecosystems, artfully designed chips will convincingly demonstrate achievements and thereby accelerate commercial adoption. The philosophy of general-purpose processors in these chips is likely to be RISC, which has stood the test of time. Expect the same rapid innovation, as during the last golden age,
In the next decade, the Cambrian explosion of new computer architectures will occur, signifying exciting times for computer architects in academia and in the industry.
“Those who do not remember the past are doomed to repeat it” - George Santayana, 1905His Turing lectureOn June 4, 2018, we began with a review of computer architecture, starting in the 1960s. In addition to it, we are covering current issues and trying to identify future opportunities that promise a new golden age in the field of computer architecture in the next decade. The same as in the 1980s, when we conducted our research on improving the cost, energy efficiency, safety and performance of processors, for which we received this honorable award.
Key ideas
- Software progress can spur architectural innovation.
- Enhancing software and hardware interfaces creates opportunities for architectural innovation.
- The market ultimately determines the winner of the architecture dispute.
The software “talks” to the hardware through a dictionary called the “instruction set architecture” (ISA). By the early 1960s, IBM had four incompatible series of computers, each with its own ISA, software stack, I / O system and market niche — targeted at small business, large business, scientific applications and real-time systems, respectively. IBM engineers, including the Turing Award winner Frederick Brooks, Jr., decided to create a single ISA that would effectively unite all four.
They needed a technical solution, how to provide an equally fast ISA for computers with both an 8-bit and 64-bit bus. In a sense, tires are the “muscles” of computers: they do the job, but relatively easily “shrink” and “expand”. Then and now the biggest challenge for designers is the processor “brain” - control equipment. Inspired by programming, pioneer of computer technology and Turing Award winner Maurice Wilks offered options for simplifying this system. The control was represented as a two-dimensional array, which it called the "control memory" (control store). Each column of the array corresponded to a single control line, each row was a microinstruction, and the record of microinstructions was called microprogramming.. The control memory contains an ISA interpreter written by microinstructions, so the execution of the usual instruction takes several microinstructions. The control memory is implemented, in fact, in memory, and it is much cheaper than logical elements.
Characteristics of the four models of the IBM System / 360 family; IPS means the number of operations per second
The table lists four models of the new ISA in System / 360 from IBM, presented on April 7, 1964. Tires differ 8 times, memory size - at 16, clock frequency - almost at 4, performance - at 50, and cost - at almost 6. In most expensive computers, the most extensive control memory, because more complex data buses used more control lines . The cheapest computers have less control memory due to simpler hardware, but they needed more micro-instructions, since they needed more clock cycles to execute the System / 360 instruction.
Thanks to microprogramming, IBM has bet that the new ISA is revolutionizing the computing industry — and won the bet. IBM dominated its markets, and the descendants of the old IBM 55-year-old IBM mainframes still generate $ 10 billion in revenue a year.
As has been repeatedly noted, although the market is an imperfect arbiter as technology, but given the close links between architecture and commercial computers, it ultimately determines the success of architectural innovations, which often require significant engineering investments.
Integrated Circuits, CISC, 432, 8086, IBM PC
When computers switched to integrated circuits, Moore’s law meant that the control memory could become much larger. In turn, this allowed a much more complex ISA. For example, a VAX-11/780 control memory from Digital Equipment Corp. in 1977 it was 5,120 words for 96 bits, while its predecessor used only 256 words for 56 bits.
Some manufacturers allowed microprogramming to select customers who could add their own user functions. It was called the “writable control store (WCS)”. Alto is the most famous WCS computer.The Turing laureates Chuck Tucker and Butler Lampson and their colleagues created the Xerox Palo Alto research center in 1973. It was really the first personal computer: here is the first display with element-by-image imaging and the first Ethernet LAN. Controllers for innovative display and network cards were firmware stored in WCS with 4096 words of 32 bits each.
In the 70s, the processors still remained 8-bit (for example, the Intel 8080) and were programmed mostly in assembler. Competitors added new instructions to outdo each other, showing their achievements with assembler examples.
Gordon Moore believed that Intel’s next ISA would remain forever for the company, so he hired many smart doctors in computer science and sent them to a new facility in Portland to invent the next great ISA. The 8800 processor, as Intel originally called it, has become an absolutely ambitious computer architecture project for any era, of course, it was the most aggressive project of the 80s. It provided for 32-bit mandatory addressing (capability-based addressing), an object-oriented architecture, variable-length instructions, and its own operating system in the new Ada programming language.
Unfortunately, this ambitious project required several years of development, which forced Intel to launch an emergency backup project in Santa Clara to quickly launch a 16-bit processor in 1979. Intel gave the new team 52 weeks to develop a new ISA "8086", designing and assembling the chip. Given the tight schedule, ISA design took just 10 man-weeks over three regular calendar weeks, mainly due to the expansion of 8-bit registers and the 8080 instruction set to 16 bits. The team completed the 8086 schedule, but this emergency processor was announced without much fanfare.
Intel was very lucky that IBM designed a personal computer to compete with the Apple II and needed a 16-bit microprocessor. IBM looked closely at the Motorola 68000 with an ISA similar to the IBM 360, but it lagged behind IBM's aggressive graphics. Instead, IBM switched to the 8-bit version of the 8086 bus. When IBM announced the PC on August 12, 1981, it hoped to sell 250,000 computers by 1986. Instead, the company sold 100 million worldwide, presenting a very promising future with an extra ISA from Intel.
The original Intel 8800 project was renamed to iAPX-432. Finally, it was announced in 1981, but it required several microchips and had serious performance problems. It was completed in 1986, a year after Intel expanded the 16-bit ISA 8086 to 80386, increasing the registers from 16 bits to 32 bits. Thus, Moore's prediction regarding ISA turned out to be correct, but the market chose the 8086 made by scoops, rather than the iAPX-432 “anointed one”. As the architects of the Motorola 68000 and iAPX-432 processors understood, the market rarely knows how to be patient.
From hard to short recruitment
In the early 1980s, several studies of computers with a set of complex instructions (CISC) were carried out: they have large firmware in large control memory. When Unix demonstrated that even an operating system can be written in a high-level language, the main question was: “What instructions will compilers generate?” Instead of “What assembler will programmers use?” A significant increase in the hardware-software interface created an opportunity for innovation in architecture.
Turing Award winner John Cock and his colleagues have developed simpler ISA and compilers for minicomputers. As an experiment, they reoriented their research compilers to use in the IBM 360 ISA only simple operations between registers and memorized loads, avoiding more complex instructions. They noticed that programs run three times faster if they use a simple subset. Emer and Clark discoveredThat 20% of VAX instructions take up 60% of the microcode and take up only 0.2% of the execution time. One author of this article (Patterson) spent a creative leave at DEC, helping to reduce the number of errors in the VAX microcode. If the manufacturers of microprocessors were going to follow the construction of ISA with a set of complex CISC commands in large computers, then they assumed a large number of microcode errors and wanted to find a way to fix them. He wrote such an article , but Computer magazinerejected her. Reviewers have suggested that the terrible idea to build microprocessors with ISA is so complicated that they need to be repaired in the field. This failure questioned the value of CISC for microprocessors. Ironically, modern CISC microprocessors do include microcode recovery mechanisms, but the refusal to publish the article inspired the author to develop a less complex ISA for microprocessors — RISC computers.
These comments and the transition to high-level languages allowed us to move from CISC to RISC. First, the RISC instructions are simplified, so there is no need for an interpreter. RISC instructions are usually simple as microinstructions and can be executed directly by the hardware. Secondly, the fast memory previously used for the CISC microcode interpreter was converted to the RISC instruction cache (the cache is a small, fast memory that buffers recently executed instructions, since such instructions are likely to be reused soon). Third, register allocators based on the Gregory Chaytin graph dyeing schemeSignificantly facilitated compilers efficient use of registers, from which these ISA with the register-register operations. Finally, Moore's law led to the fact that in the 1980s there were enough transistors on a chip to put a full 32-bit bus on one chip, along with caches for instructions and data.
For example, in fig. Figure 1 shows the RISC-I and MIPS microprocessors developed at the University of California at Berkeley and Stanford University in 1982 and 1983, which demonstrated the advantages of RISC. As a result, in 1984, these processors were presented at the leading circuit design conference, IEEE International Solid-State Circuits Conference ( 1 , 2). It was a wonderful moment when several graduate students at Berkeley and Stanford created microprocessors that were superior to the industry of that era.
Fig. 1. RISC-I processors from the University of California at Berkeley and MIPS from Stanford University
Those academic chips inspired many companies to create RISC microprocessors, which were the fastest over the next 15 years. The explanation is related to the following processor performance formula:
Time / Program = (Instructions / Program) × (cycles / Instruction) × (Time / tact)
DEC engineers later showedthat for one program more complex CISCs require 75% of the number of RISC instructions (the first term in the formula), but in a similar technology (third member) each CISC instruction takes 5-6 cycles more (second member), which makes RISC microprocessors approximately 4 times faster.
Such formulas were not in the computer literature of the 80s, which forced us in 1989 to write the book Computer Architecture: A Quantitective Approach . The subtitle explains the topic of the book: use measurements and benchmarks to quantify tradeoffs instead of relying on the intuition and experience of the designer, as in the past. Our quantitative approach was also inspired by what Turing’s winner Donald Knuth’s book did for algorithms .
VLIW, EPIC, Itanium
The next innovative ISA was supposed to surpass the success of both RISC and CISC. The architecture of very long VLIW machine instructions and its cousin EPIC (computation with explicit machine command parallelism) from Intel and Hewlett-Packard used long instructions, each of which consisted of several independent operations, connected together. Proponents of VLIW and EPIC at the time believed that if one instruction could specify, say, six independent operations — two data transfers, two integer operations and two floating point operations — and the compiler technology could effectively assign operations to six instruction slots, That equipment can be simplified. Similar to the RISC approach, VLIW and EPIC moved work from hardware to compiler.
Working together, Intel and Hewlett-Packard developed a 64-bit processor based on EPIC ideas to replace the 32-bit x86 architecture. High hopes were pinned on the first EPIC processor called Itanium, but the reality did not correspond to the early statements of the developers. Although the EPIC approach worked well for highly structured floating point programs, it could never achieve high performance for integer programs with less predictable branching and cache misses. As noted laterDonald Knuth: “It was supposed that the Itanium approach ... would be awesome - until it turned out that the desired compilers are basically impossible to write." Critics have noted delays in the release of Itanium and dubbed it “Itanik” in honor of the ill-fated passenger ship “Titanic”. The market was again unable to be patient and accepted as successor the 64-bit version of x86, and not Itanium.
The good news is that VLIW is still suitable for more specialized applications, where small programs run with simpler branches and cache passes, including digital signal processing.
RISC vs. CISC in the era of PC and post-PC
AMD and Intel needed design teams of 500 people and superior semiconductor technology to narrow the performance gap between x86 and RISC. Again, for the sake of performance, which is achieved through pipelining, a decoder of instructions on the fly translates complex x86 instructions into internal RISC-like microinstructions. AMD and Intel then build a pipeline of their execution. Any ideas that RISC designers used to improve performance — separate instruction and data caches, second-level caches on a chip, a deep pipeline, and the simultaneous acquisition and execution of several instructions — were then included in x86. At the peak of the personal computer era in 2011, AMD and Intel supplied around 350 million x86 microprocessors annually.
With hundreds of millions of computers sold annually, software has become a giant market. While suppliers of software for Unix had to release different versions of software for different RISC architectures — Alpha, HP-PA, MIPS, Power, and SPARC — personal computers had one ISA, therefore, they released “uzhaty” software, binary compatible only with architecture x86 Because of the much larger software base, similar performance, and lower prices, by 2000, the x86 architecture dominated the desktop and small server markets.
Apple helped open the post-PC era with the release of the iPhone in 2007. Instead of purchasing microprocessors, smartphone companies made their own on-chip systems (SoC) using other people's work, including ARM's RISC processors. Here, designers are important not only performance, but also power consumption and the area of the crystal, which put at a disadvantage CISC architecture. In addition, the Internet of Things has significantly increased both the number of processors and the necessary tradeoffs in chip size, power, cost, and performance. This trend has increased the importance of time and cost of design, which further worsened the position of CISC processors. In today's post-PC era, annual x86 shipments fell by almost 10% from peak 2011, while RISC chips soared to 20 billion.
Concluding this historical review, we can say that the market has settled the dispute between RISC and CISC. Although CISC won the later stages of the PC era, but RISC wins now, when the post-PC era has arrived. New ISA on CISC has not been created for decades. To our surprise, the general opinion on the best ISA principles for general purpose processors today is still in favor of RISC, 35 years after its invention.
Modern challenges for processor architecture
“If a problem does not have a solution, perhaps this is not a problem, but a givenness with which one should learn to live.” - Shimon Perez
Although the previous section focused on developing the instruction set architecture (ISA), most designers in the industry do not develop new ISA, and implement the existing ISA in the existing production technology. Since the end of the 70s, integrated circuits on MOS structures (MOS), first n-type (nMOS), and then complementary (CMOS) have been the prevailing technology. The staggering pace of MOS technology advancement — captured in the predictions of Gordon Moore — became the driving force that allowed designers to develop more aggressive methods of achieving performance for this ISA. Moore's initial prediction in 1965provided for an annual doubling of the density of transistors; in 1975, he revised it , predicting a doubling every two years. In the end, this forecast became known as Moore's law. Since the density of transistors grows quadratically and the speed linearly, with a larger number of transistors you can improve performance.
The end of the law of Moore and the law of scaling Dennard
Although Moore’s law acted for many decades (see Fig. 2), somewhere around the year 2000 it began to slow down, and by 2018, the gap between Moore’s prediction and current opportunities had grown to 15 times. In 2003, Moore expressed the opinion that this was inevitable . At present, it is expected that the gap will continue to widen as the CMOS technology approaches the fundamental limits.
Fig. 2. The number of transistors on an Intel chip versus Moore's
Law Moore 's Law was accompanied by a projection made by Robert Dennard called “Dennard Scaling”As the transistor density increases, the power consumption per transistor will decrease, so the consumption per mm² of silicon will be almost constant. As the computing power of silicon millimeter grew with each new generation of technology, computers became more energy efficient. Dennard's scaling began to slow significantly in 2007, and by 2012 it was almost gone (see Figure 3).
Fig. 2. The number of transistors per chip and energy consumption per mm²
From 1986 to 2002, instruction-level overlap (ILP) was the main architectural method for increasing productivity. Along with the increase in the speed of the transistors, this gave an annual performance increase of about 50%. The end of Dennard's scaling meant that architects had to find better ways to use concurrency.
To understand why an increase in ILP reduced efficiency, consider the core of modern ARM, Intel and AMD processors. Suppose that he has a 15-stage pipeline and four instructions per beat. Thus, at any time, up to 60 instructions are on the conveyor, including approximately 15 branches, since they constitute approximately 25% of the instructions executed. To fill the pipeline, the branches are predicted, and the code is speculatively placed in the pipeline for execution. A speculative forecast is at the same time a source of both ILP productivity and inefficiency. When branch prediction is ideal, speculation boosts performance and only slightly increases power consumption — and can even save energy — but when branches are predicted incorrectly, the processor must throw out incorrect calculations, and all the work and energy is wasted. The internal state of the processor will also have to be restored to the state that existed before the misunderstood branch, with the expenditure of additional time and energy.
To understand how difficult this design is, imagine the difficulty of correctly predicting the results of 15 branches. If the designer of the processor puts a limit of 10% loss, the processor must correctly predict each branch with an accuracy of 99.3%. There are not many general purpose programs with branches that can be predicted so accurately.
To evaluate what this wasted work consists of, consider the data in Figure 2. 4, showing the proportion of instructions that are effectively executed, but are wasted because the processor incorrectly predicted branching. In SPEC tests on an Intel Core i7, an average of 19% of the instructions are wasted. However, the amount of energy expended is greater, since the processor must use additional energy to restore the state when it has incorrectly predicted.
Fig.4. Wasted instructions as a percentage of all instructions executed on the Intel Core i7 for various SPEC integer tests
Such measurements led many to conclude that you need to look for a different approach to achieve better performance. Thus was born a multi-core era.
In this concept, the responsibility for identifying concurrency and deciding how to use it is shifted to the programmer and language system. Multi-core does not solve the problem of energy-efficient computing, which was exacerbated by the end of Dennard scaling. Each active core consumes energy, regardless of whether it is involved in effective calculations. The main obstacle is the old observation, called the law of Amdal. It says that the benefit from parallel computing is limited to the fraction of consecutive calculations. To appreciate the importance of this observation, consider Figure 5. It shows how much faster an application works with 64 cores compared to one core, assuming a different share of sequential calculations when only one processor is active. For example, if 1% of the time the calculation is performed sequentially, then the advantage of the 64-processor configuration is only 35%. Unfortunately, the power consumption is proportional to 64 processors, so about 45% of the energy is wasted.
Fig. 5. The influence of Amdal's law on the increase in speed, taking into account the share of cycles in the sequential mode
Of course, real programs have a more complex structure. There are fragments that allow using a different number of processors at any given time. However, the need to periodically interact and synchronize them means that most applications have some parts that can effectively use only part of the processors. Although the Amdahl law is over 50 years old, it remains a difficult obstacle.
With the end of Dennard scaling, an increase in the number of cores on a chip meant that the power also increased at almost the same speed. Unfortunately, the voltage applied to the processor should then also be removed as heat. Thus, multi-core processors are limited by thermal output power (TDP) or the average amount of power that the chassis and cooling system can remove. Although some high-end data centers use more advanced cooling technologies, no user wants to put a small heat exchanger on the table or carry a radiator on their backs to cool their mobile phone. The TDP limit led to an era of “dark silicon” (dark silicon), when processors slow down the clock frequency and turn off idle cores to prevent overheating. Another way to consider this approach is to
The non-scaling epoch of Dennard, along with the reduction of Moore's law and Amdahl's law, means that inefficiency limits productivity improvement to only a few percent a year (see Figure 6).
Fig. 6. Increased computer productivity in integer tests (SPECintCPU)
Achieving higher rates of productivity improvement — as noted in the 80s and 90s — requires new architectural approaches that take advantage of integrated circuit capabilities much more efficiently. We will return to the discussion of potentially effective approaches, mentioning another serious drawback of modern computers - security.
Forgotten security
In the 70s, processor developers diligently ensured computer security using different concepts, ranging from protective rings to special functions. They were well aware that most of the bugs would be in software, but they believed that architectural support could help. These functions were largely not used by operating systems that operated in a supposedly safe environment (like personal computers). Therefore, the functions associated with significant overhead are eliminated. In the software community, many believed that formal testing and methods like using a microkernel would provide effective mechanisms for creating highly secure software. Unfortunately, the scale of our common software systems and the desire for performance meant that such methods could not keep up with performance. As a result, large software systems still have many security flaws, and the effect is exacerbated by the huge and growing amount of personal information on the Internet and the use of cloud computing, where users share the same physical hardware with a potential intruder.
Although processor designers and others may not immediately recognize the growing importance of security, they began to include hardware support for virtual machines and encryption. Unfortunately, branch prediction introduced an unknown but significant security flaw in many processors. In particular, the vulnerabilities of Meltdown and Specter use microarchitecture features, allowing leakage of protected information . They both use the so-called attacks on third-party channels, when information leaks through the time difference spent on the task. In 2018, researchers showed how to use one of Specter’s options to extract information over the network without downloading code to the target processor.. Although this attack, called NetSpectre, transmits information slowly, but the very fact that it allows you to attack any machine on the same local network (or cluster in the cloud) creates many new attack vectors. Subsequently, two more vulnerabilities were reported in the virtual machine architecture ( 1 , 2 ). One of them, called Foreshadow, allows you to penetrate Intel SGX security mechanisms designed to protect the most valuable data (such as encryption keys). New vulnerabilities are found monthly.
Attacks on third-party channels are not new, but in most cases, before, the fault was in software bugs. In Meltdown, Specter and other attacks this is a flaw in the hardware implementation. There is a fundamental difficulty in how processor architects determine what is the correct implementation of ISA, because the standard definition says nothing about the performance effects of executing a sequence of instructions, only about the visible ISA architectural state of execution. Architects should review their definition of the correct implementation of ISA to prevent such security flaws. At the same time, they need to rethink the attention they give to computer security, and how architects can work with software developers to implement more secure systems.
Future features in computer architecture
“We have tremendous opportunities disguised as unsolvable problems” - John Gardner, 1965
The inherent inefficiency of general-purpose processors, be it ILP technologies or multi-core processors, combined with the completion of Dennard scaling and Moore's law make it unlikely architects and processors will be able to support significant rates of increase in performance of general purpose processors Given the importance of improving performance for software, we must ask the question: what other promising approaches are there?
There are two clear possibilities, as well as a third one, created by combining these two. First, existing software development methods widely use high-level languages with dynamic typing. Unfortunately, such languages are usually interpreted and executed extremely inefficiently. To illustrate this inefficiency Leiceson and colleagues gave a small example: the multiplication of matrices .
Fig. 7. Potential acceleration of Python matrix multiplication after four optimizations.
As shown in fig. 7, simply rewriting code from Python to C improves productivity by 47 times. Using parallel loops on many cores gives an additional factor of about 7. Optimizing the memory structure for using caches gives a factor of 20, and the last factor 9 comes from using hardware extensions to perform parallel SIMD operations that are capable of performing 16 32-bit operations per instruction. After that, the final, highly optimized version runs on a multi-core Intel processor 62,806 times faster than the original Python version. This, of course, is a small example. It can be assumed that programmers will use an optimized library. Although there is an exaggerated performance gap, there are probably many programs that
An interesting area of research is the question of whether some performance gaps can be eliminated with the help of a new compiler technology, perhaps with the help of architectural improvements. Although it is difficult to efficiently translate and compile high-level scripting languages such as Python, the potential gain is huge. Even a small optimization can lead to the fact that Python programs will run tens or hundreds of times faster. This simple example shows how wide the gap is between modern languages, focused on the efficiency of a programmer, and traditional approaches that emphasize performance.
Specialized architectures
A more hardware-oriented approach is the design of architectures adapted to a specific subject area, where they demonstrate significant efficiency. These are specialized or domain-specific architectures (DSA). These are usually programmable and turing-complete processors, but taking into account a specific class of problems. In this sense, they differ from specialized integrated circuits (application-specific integrated circuits, ASIC), which are often used for one function with a code that rarely changes. DSAs are often referred to as accelerators, since they speed up some applications compared to running an entire application on a general purpose CPU. In addition, DSAs can provide better performance because they are more precisely adapted to the needs of the application. Examples of DSAs include graphics processors (GPUs), neural network processors used for deep learning, and processors for software-defined networks (SDNs). DSAs achieve higher performance and greater energy efficiency for four main reasons.
First, DSAs use a more efficient form of parallelism for a particular subject area. For example, SIMD (single command stream, multiple data stream) is more efficient than MIMD (multiple command stream, multiple data stream). Although SIMD is less flexible, it is well suited for many DSAs. Specialized processors may also use VLIW approaches to ILP, instead of poorly working speculative mechanisms. As mentioned earlier, VLIW processors are poorly suited for general purpose code.But for narrow areas it is much more efficient, since management mechanisms are simpler. In particular, the most top-end general-purpose processors are excessively multi-pipelined, which requires complex control logic both for the beginning and for the completion of instructions. In contrast, the VLIW performs the necessary analysis and planning at compile time, which can work well for an explicitly parallel program.
Second, DSA services use memory hierarchy more efficiently. Memory access has become much more expensive than arithmetic, as Horowitz noted. For example, accessing a block in a 32-kilobyte cache requires approximately 200 times more energy than adding 32-bit integers. This huge difference makes memory access optimization critical to achieving high energy efficiency. General-purpose processors execute code in which memory accesses typically exhibit spatial and temporal locality, but are otherwise not very predictable at compile time. Therefore, to increase the bandwidth of the CPU, multi-level caches are used and the delay is hidden in relatively slow DRAM outside the crystal. These multi-level caches often consume about half of the processor's power, but they prevent almost all access to DRAM, which takes about 10 times more energy than access to the latest level cache.
Caches have two noticeable flaws.
When data sets are very large . Caches simply work poorly when data sets are very large, have low temporal or spatial locality.
When caches work well . When caches work well, locality is very high, that is, by definition, most of the cache is idle most of the time.
In applications where memory access patterns are well defined and understandable at compile time, which is true for typical domain-specific languages (DSL), programmers and compilers can optimize memory usage better than dynamically allocated caches. Thus, DSAs typically use a relocation memory hierarchy that is explicitly controlled by software, just as vector processors work. In the corresponding applications, “manual” memory control by the user allows you to spend much less energy than the standard cache.
Thirdly, DSA can reduce the accuracy of calculations if high accuracy is not needed. General purpose CPUs typically support 32-bit and 64-bit integer calculations, as well as floating-point data (FP). For many applications in machine learning and graphics, this is excessive accuracy. For example, in deep neural networks, 4, 8, or 16-bit numbers are often used in calculations, improving both data throughput and computational power. Similarly, floating point computations are useful for learning neural networks, but 32 bits is enough, and often 16 bits.
Finally, DSAs benefit from programs written in domain-specific languages that allow more concurrency, improve structure, memory access, and simplify the efficient application of a program onto a specialized processor.
Domain-specific languages
DSAs require high-level operations to be adapted to the processor architecture, but this is very difficult to do in a general purpose language such as Python, Java, C, or Fortran. Domain-specific languages (DSL) help with this and allow DSA to be programmed effectively. For example, DSL can make explicit vector, dense matrix and sparse matrix operations, which will allow the DSL compiler to efficiently match operations with the processor. The domain-specific languages include Matlab, a language for working with matrices, TensorFlow for programming neural networks, P4 for programming software-defined networks, and Halide for image processing with an indication of high-level transformations.
The problem with DSL is how to maintain sufficient architectural independence so that the software on it can be ported to different architectures, while achieving high performance when comparing software with the base DSA. For example, the XLA system translates Tensorflow code to heterogeneous systems with Nvidia GPUs or tensor processors (TPU). Balancing portability between DSAs while preserving efficiency is an interesting research challenge for language developers, compilers, and DSAs themselves.
DSA Example: TPU v1
As an example of DSA, consider Google TPU v1, which is designed to speed up the operation of a neural network ( 1 , 2 ). This TPU has been produced since 2015, and many applications work on it: from search queries to text translation and image recognition in AlphaGo and AlphaZero, DeepMind programs for go and chess. The goal was to improve the performance and energy efficiency of deep neural networks by 10 times.
Fig. 8. The functional organization of the Google Tensor Processing Unit (TPU v1)
As shown in Figure 8, the organization of the TPU is radically different from the general purpose processor. The main computational unit is the matrix unit, the structure of systolic arrayswhich each clock cycle produces 256 × 256 multiply accumulations (multiply-accumulate). The combination of 8-bit accuracy, a highly efficient systolic structure, SIMD control, and the allocation of a significant part of the chip to this function help to perform approximately 100 times more accumulation and accumulation operations than the core of a general-purpose CPU per cycle. Instead of TPU caches, 24 MB of local memory is used, which is approximately twice as large as caches of general purpose CPU 2015 with the same TDP. Finally, both the neuron activation memory and the neural network weights memory (including the FIFO structure, which stores weights) are connected via high-speed channels controlled by the user. The weighted average performance of TPU in six typical problems of logical inference of neural networks in Google data centers is 29 times higher than that of general-purpose processors.
Резюме
We considered two different approaches to improving program performance by increasing the efficiency of using hardware technologies. First, by improving the performance of modern high-level languages, which are usually interpreted. Secondly, by creating architectures for specific subject areas that significantly improve performance and efficiency compared to general-purpose processors. Domain-specific languages are another example of how to improve the hardware-software interface that allows you to implement architectural innovations, such as DSA. To achieve significant success with these approaches, you will need a vertically integrated project team that understands applications, domain-specific languages and related compilation technologies, computer architecture, as well as in basic technology implementation. The need for vertical integration and design decision making at different levels of abstraction was typical of most early work in the field of computing technology before the industry became horizontally structured. In this new era, vertical integration has become more important. Benefits will be given to teams that can find and accept complex trade-offs and optimizations.
This opportunity has already led to a surge in architectural innovation, attracting many competing architectural philosophies: the
GPU . Nvidia GPUs use multiple cores, each with large register files, multiple hardware threads and caches.
TPU . Google's TPUs rely on large two-dimensional systolic arrays and software-controlled on-chip memory.
FPGA . Microsoft, in its data centers, implements user-programmable gate arrays (FPGAs), which it uses in neural networks.
CPU. Intel offers processors with many cores, a large multi-level cache and one-dimensional SIMD instructions, in a way like Microsoft's FPGA, and a new neural processor closer to TPU than to a CPU .
In addition to these major players, dozens of start-ups implement their own ideas . To meet growing demand, designers combine hundreds and thousands of chips to create neural network supercomputers.
This avalanche of neural network architectures speaks of the advent of an interesting time in the history of computer architecture. In 2019, it is difficult to predict which of these many directions will win (if someone wins at all), but the market will definitely determine the result, just as he settled the architectural debates of the past.
Open architecture
Following the example of a successful open source software, open ISA represents an alternative opportunity in a computer architecture. They are needed to create a kind of “Linux for processors” so that the community can create open source kernels in addition to individual companies that own proprietary cores. If many organizations are developing processors using the same ISA, then more competition can lead to even faster innovations. The goal is to provide architecture for processors ranging from a few cents to $ 100.
The first example is RISC-V (RISC Five), the fifth architecture of RISC, developed at the University of California at Berkeley . It is supported by the community under the leadership of the Foundation RISC-V. The openness of the architecture allows the evolution of ISA to occur in public view, with the involvement of experts before making a final decision. An additional advantage of an open fund is that ISA is unlikely to expand primarily for marketing reasons, because sometimes this is the only explanation for expanding your own instruction sets.
RISC-V is a modular instruction set. A small instruction base launches a full open source software stack, followed by additional standard extensions that designers can enable or disable depending on needs. This database contains 32-bit and 64-bit versions of addresses. RISC-V can only grow through optional extensions; the software stack will still work fine, even if architects do not accept new extensions. Proprietary architectures typically require upward compatibility at the binary code level: this means that if the processor company adds a new feature, all future processors must also include it. The RISC-V is wrong, here all the improvements are optional and can be deleted if they are not needed by the application.
- M. Multiplication / division of an integer.
- A. Atomic memory operations.
- F / d. Single / double precision floating point operations.
- C. Compressed instructions.
The third distinctive feature of RISC-V is the simplicity of ISA. Although this figure is not quantifiable, here are two comparisons with the ARMv8 architecture, which ARM developed in parallel:
- Less instructions . RISC-V has far fewer instructions. There are 50 pieces in the database, and they are surprisingly similar in number and character to the original RISC-I . The remaining standard extensions (M, A, F, and D) add 53 instructions, plus C adds another 34, so the total is 137. For comparison, ARMv8 has more than 500 instructions.
- Меньше форматов инструкций. У RISC-V гораздо меньше форматов инструкций: шесть, тогда как у ARMv8 по крайней мере 14.
Simplicity simplifies both the design of the processor design and the verification of their correctness. Since RISC-V focuses on everything from data centers to IoT devices, design verification can be a significant part of development costs.
Fourth, RISC-V is a design from scratch 25 years later, where architects learn from the mistakes of their predecessors. Unlike the first generation RISC architecture, it avoids microarchitecture or functions that depend on technology (such as deferred branches and deferred loads) or innovations (like register windows), which have been supplanted by compiler achievements.
Finally, RISC-V supports DSA, reserving a vast amount of opcodes for custom accelerators.
In addition to RISC-V, Nvidia also announced (in 2017)free and open architecture , she calls it the Nvidia Deep Learning Accelerator (NVDLA). This is a scalable, customizable DSA for inference in machine learning. Configuration parameters include the data type (int8, int16 or fp16) and the size of the two-dimensional multiplication matrix. Silicon substrate scales range from 0.5 mm² to 3 mm², and energy consumption ranges from 20 mW to 300 mW. ISA, software stack and implementation are open.
Open simple architectures work well with security. First, security experts do not believe in security through obscurity, so open implementations are attractive, and open implementations require an open architecture. Equally important is the increase in the number of people and organizations that can innovate in the field of secure architectures. Proprietary architectures limit employee participation, but open architectures allow the best minds in academia and industry to help with security. Finally, the simplicity of RISC-V simplifies the verification of its implementations. In addition, open architectures, implementations, and software stacks, as well as FPGA plasticity, mean that architects can deploy and evaluate new solutions online with weekly rather than annual release cycles. Although FPGA is 10 times slower than custom chips, but their productivity is enough to work online and exhibit security innovations in front of real attackers to test. We expect open architects to be an example of a joint design of hardware and software by architects and security experts.
Flexible hardware development
The Software Development Manifesto (2001) by Beck et al. Revolutionized software development, eliminating the problems of the traditional waterfall system based on planning and documentation. Small teams of programmers quickly create working but incomplete prototypes, and receive customer feedback before the next iteration. Scrum version of Agile brings together teams of five to ten programmers who perform sprints of two to four weeks per iteration.
Again, having borrowed the idea from software development, it is possible to organize flexible hardware development. The good news is that modern electronic computer-aided design (ECAD) tools have increased the level of abstraction, allowing for flexible development. This higher level of abstraction also increases the level of reuse of work between different designs.
Four-week sprints seem implausible for processors, considering the months between when creating a design and producing a chip. In fig. 9 shows how the flexible method can work by modifying the prototype at an appropriate level .
Fig. 9. Flexible equipment development methodology
The innermost level is a software simulator, the easiest and fastest place to make changes. The next level is FPGA chips, which can work hundreds of times faster than a detailed software simulator. FPGAs can work with operating systems and full benchmarks, such as the Standard Performance Evaluation Corporation (SPEC), which allows for much more accurate evaluation of prototypes. Amazon Web Services offers FPGAs in the cloud, so architects can use FPGAs without having to first buy equipment and build a lab. The next level uses ECAD tools to generate a chip layout, document dimensions and power consumption. Even after using the tools, you must perform some manual steps to refine the results before sending the new processor into production.tape in . These first four levels support four-week sprints.
For research purposes, we could stay at the fourth level, since estimates of area, energy, and performance are very accurate. But it was like a runner ran a marathon and stopped 5 meters before the finish, because his finish time is already clear. Despite the heavy preparation for the marathon, he will miss the thrill and pleasure of actually crossing the finish line. One of the advantages of hardware engineers over software engineers is that they create physical things. Get chips from the factory: measure, run real programs, show them to friends and family - a great joy for the designer.
Many researchers believe that they should stop, because the manufacture of chips is too affordable. But if the construction is small, it is surprisingly inexpensive. Engineers can order 100 1 mm² microcircuits for as little as $ 14,000. At 28 nm, a 1 mm2 chip contains millions of transistors: this is enough for both the RISC-V processor and the NVLDA accelerator. The outermost level is expensive if the designer intends to create a large microcircuit, but many new ideas can be demonstrated on small chips.
Conclusion
“The darkest hour is just before dawn” - Thomas Fuller, 1650
To benefit from the lessons of history, processor makers need to understand that much can be learned from the software industry, that increasing the hardware / software interface abstraction level provides opportunities for innovation and that the market in ultimately determine the winner. iAPX-432 and Itanium demonstrate how investments in architecture may fail, while S / 360, 8086 and ARM have provided high results for decades without an end in sight.
Completing Moore's Law and Dennard's scaling, as well as slowing the growth of standard microprocessor performance, are not problems to be solved, but a given, which, as we know, offers exciting opportunities. High-level domain-specific languages and architectures that exempt from the chains of proprietary instruction sets, along with the public demand for increased security, will open a new golden age for computer architecture. In open source ecosystems, artfully designed chips will convincingly demonstrate achievements and thereby accelerate commercial adoption. The philosophy of general-purpose processors in these chips is likely to be RISC, which has stood the test of time. Expect the same rapid innovation, as during the last golden age,
In the next decade, the Cambrian explosion of new computer architectures will occur, signifying exciting times for computer architects in academia and in the industry.