Exponential Backoff or how not to crash a server
In any interaction between the client and server, we are faced with the need to repeat requests. The network connection may be unreliable, there may be problems on the server or any other reasons due to which it is necessary to repeat the request. The same applies to the interaction of the backend server with the database or any other data warehouse (other service).
Today we’ll talk about the request retry interval. How long after a failed request can it be repeated? Let's look at two strategies: repeating at a fixed time interval and exponential backoff. We will see on the simulation that, provided there are a large number of clients, repeating at a fixed interval may not allow the server to "rise", and using exponential backoff avoids this problem.
The issue of retry interval becomes important when there are problems on the server. Very often, the server is able to withstand the load from clients who send requests in some “current” mode, randomly distributing their requests over time. If a failure occurs on the server, all clients detect it and begin to repeat requests at a certain interval. It may turn out that the frequency of such requests exceeds the limit that the server can handle.
Another important point is that the client often cannot distinguish problems on the server from problems with the network connection on the client side: if the response to the request does not arrive at the specified time interval, the client cannot make a conclusion about exactly what the problem is. And the client’s behavior (request retry, retry interval) will be the same in both situations.
This is the simplest strategy (and the most commonly used). If the request fails, the client repeats the request through the interval T. Here we are looking for a compromise between not filling up the server with too frequent requests in the event of a failure, and in order not to worsen the user experience without repeating the requests for too long single problems in the network.
A typical retry interval can range from hundreds of milliseconds to several seconds.
The exponential snooze algorithm can be written in pseudo-code as follows:
In this pseudo
There are the following algorithm parameters:
Calculation of the delay interval works quite simply: the first interval is equal
Than this method of calculating repetition is better than repetition after a fixed period of time:
You can ask a reasonable question: what if the client just has a bad network connection? After all, the exponential snooze algorithm will increase the request interval all the time, and the user will not wait indefinitely. Here are three considerations:
To illustrate the graphics of the delay interval with this algorithm with the parameters:
On the horizontal axis is the number of the attempt.
The same graphs, the logarithmic scale:

Is it so easy to believe that the complexity of exponential shelving is justified? Let's try to simulate and find out the effect of different algorithms. The simulation consists of two independent parts: client and server, I will describe them in turn.
The server emulates a typical database latency for response to a request: up to a certain limit of the number of simultaneous requests, the server responds with a fixed delay, and then the response time begins to increase exponentially depending on the number of simultaneous requests. If we are talking about a backend server, most often its response time is also limited by the response time of the database.
The server is responsible for
The client models the flow of requests from
The simulation scenario is as follows: we start the client and server with some parameters, after 10-15 seconds there is a steady-state mode in which requests are executed successfully with small delays. Then we stop the server (emulate a server crash or network problems) simply by a signal
The simulation code is written in Go and uploaded to GitHub . To build, you need Go 1.1+, the compiler can be installed from the OS package or downloaded :
A simple scenario: in the first console, start the server:
The server listens for incoming HTTP requests on port 8070 and prints the current number of concurrent connections and the last calculated client service delay every second.
In another console, launch the client:
Every 5 seconds, the client prints statistics on successful requests, requests that ended in error, as well as requests for which the timeout for waiting for a response has been exceeded.
In the first console, we stop the server:
The client detects that the server is stopped:
We try to restore the server:
The number of simultaneous connections is increasing, the server response delay is increasing, for the client this will mean even more timeout situations, even more retries, even more simultaneous requests, the server will increase the delay even more, our model service has “fallen” and will not rise anymore.
Stop the client and restart the server to start again with exponentially delaying the retry:
We repeat the same sequence of actions with the suspension and resumption of the server - the server did not fall and successfully rose, the service was restored within a short period of time.
The test client and server have a large number of parameters that can be controlled both by load and timeouts, behavior under load, etc.:
Even in this simple simulation, it is easy to see that the behavior of a group of clients (which client emulates) differs in the case of "successful" work and in the event of a problem (on the network or on the server side):
Tip: use exponential snoozing for any repetition of the request - in the client when accessing the server or in the server when accessing the database or other service.
This post was written based on the materials of the master class about high loads and reliability.
Today we’ll talk about the request retry interval. How long after a failed request can it be repeated? Let's look at two strategies: repeating at a fixed time interval and exponential backoff. We will see on the simulation that, provided there are a large number of clients, repeating at a fixed interval may not allow the server to "rise", and using exponential backoff avoids this problem.
The issue of retry interval becomes important when there are problems on the server. Very often, the server is able to withstand the load from clients who send requests in some “current” mode, randomly distributing their requests over time. If a failure occurs on the server, all clients detect it and begin to repeat requests at a certain interval. It may turn out that the frequency of such requests exceeds the limit that the server can handle.
Another important point is that the client often cannot distinguish problems on the server from problems with the network connection on the client side: if the response to the request does not arrive at the specified time interval, the client cannot make a conclusion about exactly what the problem is. And the client’s behavior (request retry, retry interval) will be the same in both situations.
Repeat at a fixed time interval
This is the simplest strategy (and the most commonly used). If the request fails, the client repeats the request through the interval T. Here we are looking for a compromise between not filling up the server with too frequent requests in the event of a failure, and in order not to worsen the user experience without repeating the requests for too long single problems in the network.
A typical retry interval can range from hundreds of milliseconds to several seconds.
Exponential backoff
The exponential snooze algorithm can be written in pseudo-code as follows:
delay = MinDelay
while True:
error = perform_request()
if not error:
# ok, got response
break
# error happened, pause between requests
sleep(delay)
# calculate next delay
delay = min(delay * Factor, MaxDelay)
delay = delay + norm_variate(delay * Jitter)
In this pseudo
delay- code - the interval between requests, perform_requestexecutes the request itself, and norm_variatecalculates the normal distribution. There are the following algorithm parameters:
MinDelay- minimum (initial) retry interval (e.g. 100 ms)MaxDelay- restriction on the length of the retry interval (for example, 15 minutes)Factor- coefficient of exponential increase in delay (for example, 2)Jitter- “jitter”, defines a random component (for example, 0.1)
Calculation of the delay interval works quite simply: the first interval is equal
MinDelay, then in the case of an error in the execution of the request, the interval is increased by a Factorfactor of a while, a random variable proportional is added Jitter. The retry interval is limited MaxDelay(excluding Jitter). Than this method of calculating repetition is better than repetition after a fixed period of time:
- the interval increases with each attempt, if the server cannot handle the flow of requests, the flow of requests from clients will decrease over time;
- intervals are randomized, i.e. there will be no “flurry” of requests per clock proportional to a fixed interval.
You can ask a reasonable question: what if the client just has a bad network connection? After all, the exponential snooze algorithm will increase the request interval all the time, and the user will not wait indefinitely. Here are three considerations:
- if the connection is really bad (2, 3, 4 attempts were unsuccessful), it might not be worth it to repeat requests so often;
- the client does not know what the problem is (see above), and for some time the behavior for the user may not be so bad as compared to the situation when the server is inundated with requests and cannot return to normal life;
- parameters
Factor,MaxDelayandMinDelaycan be changed to slow down the increase in the repeat interval or limit it.
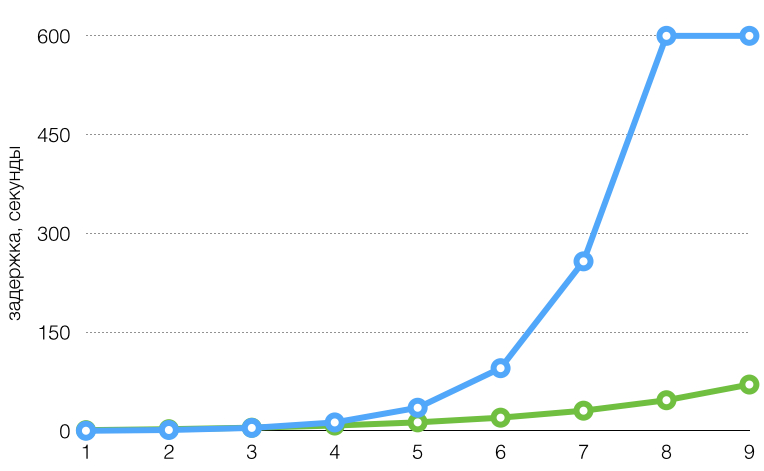
To illustrate the graphics of the delay interval with this algorithm with the parameters:
- blue graph:
MinDelay100 ms,Factor2.7,Jitter0.1,MaxDelay10 min; - green graph:
MinDelay1 sec,Factor1.5,Jitter0.1,MaxDelay5 min.
On the horizontal axis is the number of the attempt.
The same graphs, the logarithmic scale:
Simulation
Is it so easy to believe that the complexity of exponential shelving is justified? Let's try to simulate and find out the effect of different algorithms. The simulation consists of two independent parts: client and server, I will describe them in turn.
The server emulates a typical database latency for response to a request: up to a certain limit of the number of simultaneous requests, the server responds with a fixed delay, and then the response time begins to increase exponentially depending on the number of simultaneous requests. If we are talking about a backend server, most often its response time is also limited by the response time of the database.
The server is responsible for
minDelay(100 ms) until the number of simultaneous connections exceeds concurrencyLimit(30), after which the response time increases exponentially:, minDelay * factor ^ ((concurrency - concurrencyLimit) / K)wherefactor, KAre constants, and concurrencyis the current number of simultaneous connections. In fact, the server does not do any work, it responds to the request with a fixed response, but the delay is calculated using the above formula. The client models the flow of requests from
Nclients, each of which executes requests independently. Each client thread executes queries at intervals corresponding to an exponential distribution with a parameter lambda(mat. The expectation of the query interval islambda) The exponential distribution describes well the random processes occurring in the real world (for example, user activity, which leads to server requests). In case of a request execution error (or when the response time-out is exceeded), the client begins to repeat the request either with a simple fixed interval or by the exponential delaying algorithm. The simulation scenario is as follows: we start the client and server with some parameters, after 10-15 seconds there is a steady-state mode in which requests are executed successfully with small delays. Then we stop the server (emulate a server crash or network problems) simply by a signal
SIGSTOP, the flow of clients detects this and begins to repeat requests. Then we restore the server and see how quickly the server will return to normal (or will not).Project code
The simulation code is written in Go and uploaded to GitHub . To build, you need Go 1.1+, the compiler can be installed from the OS package or downloaded :
$ git clone https://github.com/smira/exponential-backoff.git
$ cd exponential-backoff
$ go build -o client client.go
$ go build -o server server.go
A simple scenario: in the first console, start the server:
$ ./server
Jun 21 13:31:18.708: concurrency: 0, last delay: 0
...
The server listens for incoming HTTP requests on port 8070 and prints the current number of concurrent connections and the last calculated client service delay every second.
In another console, launch the client:
$ ./client
OK: 98.00 req/sec, errors: 0.00 req/sec, timedout: 0.00 req/sec
OK: 101.00 req/sec, errors: 0.00 req/sec, timedout: 0.00 req/sec
OK: 100.00 req/sec, errors: 0.00 req/sec, timedout: 0.00 req/sec
...
Every 5 seconds, the client prints statistics on successful requests, requests that ended in error, as well as requests for which the timeout for waiting for a response has been exceeded.
In the first console, we stop the server:
Jun 21 22:11:08.519: concurrency: 8, last delay: 100ms
Jun 21 22:11:09.519: concurrency: 10, last delay: 100ms
^Z
[1]+ Stopped ./server
The client detects that the server is stopped:
OK: 36.00 req/sec, errors: 0.00 req/sec, timedout: 22.60 req/sec
OK: 0.00 req/sec, errors: 0.00 req/sec, timedout: 170.60 req/sec
OK: 0.00 req/sec, errors: 0.00 req/sec, timedout: 298.80 req/sec
OK: 0.00 req/sec, errors: 0.00 req/sec, timedout: 371.20 req/sec
We try to restore the server:
$ fg
./server
Jun 21 22:13:06.693: concurrency: 0, last delay: 100ms
Jun 21 22:13:07.492: concurrency: 1040, last delay: 2.671444385s
Jun 21 22:13:08.492: concurrency: 1599, last delay: 16.458895305s
Jun 21 22:13:09.492: concurrency: 1925, last delay: 47.524196455s
Jun 21 22:13:10.492: concurrency: 2231, last delay: 2m8.580906589s
...
The number of simultaneous connections is increasing, the server response delay is increasing, for the client this will mean even more timeout situations, even more retries, even more simultaneous requests, the server will increase the delay even more, our model service has “fallen” and will not rise anymore.
Stop the client and restart the server to start again with exponentially delaying the retry:
$ ./client -exponential-backoff
We repeat the same sequence of actions with the suspension and resumption of the server - the server did not fall and successfully rose, the service was restored within a short period of time.
Instead of a conclusion
The test client and server have a large number of parameters that can be controlled both by load and timeouts, behavior under load, etc.:
$ ./client -h
$ ./server -h
Even in this simple simulation, it is easy to see that the behavior of a group of clients (which client emulates) differs in the case of "successful" work and in the event of a problem (on the network or on the server side):
- during normal operation, the load on the server (the number of requests per second) is determined by a random distribution, but it will be approximately constant (with default parameters about 100 requests per second);
- in case of problems with a simple delay, the number of requests reaches quickly high values (determined only by the number of clients and retry delay);
- in case of problems with exponential delay, the load on the server decreases over time (until the server can cope with the load).
Tip: use exponential snoozing for any repetition of the request - in the client when accessing the server or in the server when accessing the database or other service.
This post was written based on the materials of the master class about high loads and reliability.