Multicellular processor - what is it?
Many have heard about multicellular architecture, processors, and even the first devices on them. Especially advanced users have tested their algorithms. The first simple performance tests were conducted, as well as a Barsmonster user who etched a P1 processor chip. The R1 processor is already undergoing the first tests and will soon be available to everyone. But not everyone knows the answer to the question of how multicellular architecture works and what is its difference. Let’s try now to get things up to date.
1. Multicellularity Multicellular
nucleus- This is a group of identical processor units (2 or more), united by a fully connected unidirectional switching environment. Peculiarities of the interaction of processor units between themselves follow from the presentation of the algorithm (more on this below). The processor unit in multicellular architecture is called a cell. The set of commands that it can execute is determined by the specific implementation and is architecture independent.
Algorithms "eyes" of the multicellular nucleus
First.
Any formula can be represented in the form of a tiered-parallel form (NPF). Consider a
simple example: g = e * (a + b) + (ac) * f, in a NPS this might look like this:
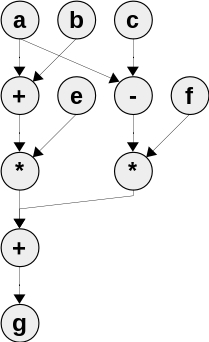
Figure 1. Example of NPS
In the general case, to perform operations, nodes located on the i-th tier can use the results obtained on tiers from 1 to (i-1) th. It follows that the teams located on the same tier are independent.
Any algorithm is a set of formulas, which is divided into subsets - linear sections, interconnected by control transfer operators. A linear section (LU) is a subset of formulas that can be calculated if and only if control is transferred to a given linear section. Inside a linear section, informationally unrelated formulas can be executed in any order.
As you know, the result of execution by the processor of any command is expressed in a change in the state of the processor. The use of this new state by subsequent teams forms an information link between the source command of the result and the receiver commands of this result. Such a relationship can be either indirect (indirect) or direct (direct).
With indirect communication, the result is available only after its alienation: recording in public registers or memory or other devices. The source command must put the result in these devices, and the receiver command will have to take data from there. The device name is specified as an operand. Such a connection between teams is the basis of absolutely all modern processors, except multicellular ones.
In the case of direct information communication, the teams are named and the names should identify the team itself, and not its location or other features of the implementation. Results can be accessed by the names of both source teams and receiver teams. In the first case, broadcasting is used, followed by roll-call selection, in which the name of the source command is specified in the operand field of the destination command. In the second, a roll-out is performed, in which the source command sets the name of the result destination command.
Theoretically, the nodes of the NPS can be named in any way. The only requirement is uniqueness. To do this, in the multicellular processor of the team, when fetching from memory, they get a tag (label) - thus they are given a local name and their results - and then the interaction between the teams is organized through tags. Data can be obtained from any team with a tag less than its own. The tag number of the desired result is set by the difference between the values of the command tag and the tag of the desired result. For example, if @ 5 is specified in the operand, and the command tag is 7, then the result of the command with tag 2 is used as the operand. All the results of command execution are sent to the switching environment, from which the required ones are selected by tag. Thus, in a multicellular processor, broadcast results are used with their subsequent selection by name.
It is worth noting that due to physical limitations there is the concept of a “visibility window”, which determines the maximum distance of the source command from the receiver command. The tag in the process of selecting commands changes cyclically. Its maximum value is determined by the size of the command buffer. In fact, the size of the tag determines the number of commands that can simultaneously be at different stages of execution. The tag value cannot be used if the command to which it was previously assigned has not yet been executed.
Secondly.
A multicellular processor operates with structures that we call paragraphs.
Paragraph- This is an informationally closed sequence of commands. A paragraph is an analogue of a command, after which the state of the processor and / or systems in its composition (registers, buses, memory cells, input / output channels, etc.) changes. Those. for a multicellular nucleus, a paragraph is a command.
The main feature of multicellular architecture is that it directly implements the JPF representation of the algorithm. From this understanding of the algorithm, many properties of multicellular architecture follow.
2. Properties of multicellular architecture
Let us consider in more detail what the paragraph for the algorithm described in Section 2 will look like.

For a multicellular nucleus, the following paragraph construction scheme is typical (not mandatory, there are also deviations in the above example):
It should be recalled that a change in the state of a machine in a multicellular processor occurs at the end of a paragraph.
The algorithm does not depend on the number of cells.
The information links between the teams are indicated explicitly and there is no need to know about the number of processor units when a program is being written. The teams just wait for the readiness of their operands and after that they go to execution and they don’t care who and when they will prepare the operands. Imagine a watering can - you do not think about how many holes in its nozzle when watering. The cells are identical and there is no difference in which cell this or that command will be executed.
The teams are distributed in the cells in the order they follow, 1 team in 0 cell, 2 team in 1 cell, etc., when the team was transferred to the last available cell, we begin to redistribute from 0 cell. Consider the work of 4 cell nuclei. The paragraph above will be executed as follows:
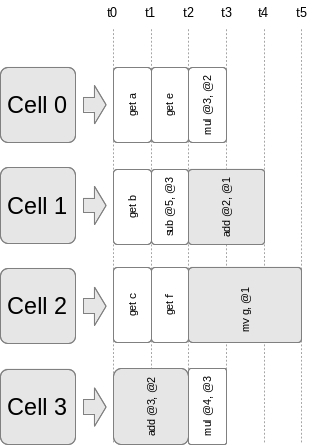
Fig. 2. Distribution of commands by cells.
Number of simultaneously executed commands depends on the number of cells. Choosing the optimal number of cells for each task is a task that requires analysis. It is still impossible to create a universal system, therefore, you can focus on the following data: 4 cells do pretty good on common tasks, and 16 cells do on signal processing tasks, and there can be hundreds of them to process a video image.
You can analyze your code and imagine what would be the optimal number of cells for them. To do this, you will need to present your algorithm in the NPS and calculate the number of teams in tiers. The average number of teams in them will hint at the optimal number of cells in your particular case.
All commands ready for execution are executed simultaneously.
As mentioned above, the multicellular nucleus implements the JPF representation of the algorithm; independent teams are located on the tiers. Everything that can be done at the moment will be executed without any special instructions from the programmer, the main condition is that the team must receive all the data for execution.
Technological limitations should be taken into account: the number of cells is limited, so as many commands will be executed simultaneously as there are cells in the nucleus.
“Alignment collapse” or dynamic allocation of computing resources
Because the code does not depend on the number of cells by which it will be executed, the ability of a multicellular nucleus to distribute its computing resources during operation appears, and control is performed programmatically.
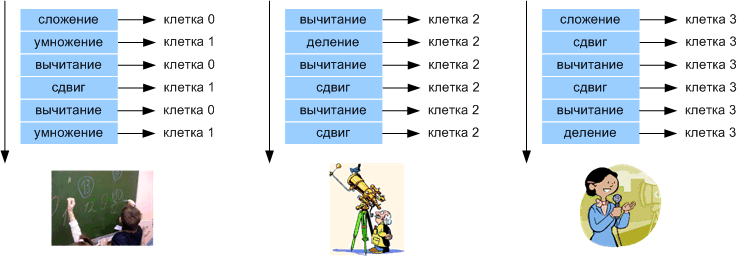
The ability of multicellular architecture to redistribute its resources is what we call reconfiguration . For example, the cells of a multicellular nucleus can be arbitrarily distributed to execute any algorithm or part of it. A group (they haven’t come up with a better name yet) is a part of the cells of a multicellular nucleus that are interconnected to execute any algorithm or part of an algorithm. A group may contain 1 or more cells. When a multicellular nucleus divides a group into parts, this is called decomposition . Grouping process -composition . Figure 3 below shows how a 4-cell nucleus reconfigures over time (example). Cells that perform one task have one color fill.
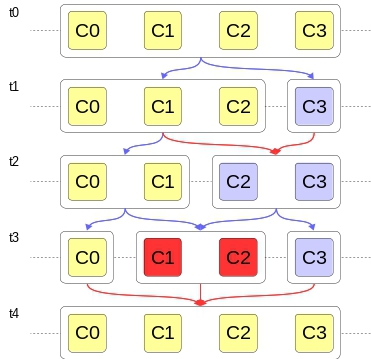
Figure 3. An example of cell reconfiguration.
Reducing energy consumption. It works when there is work.
The fundamental basis of multicellular architecture is broadcast. To date, this is so far the only architecture that uses direct information communication to transfer data between teams in the program.
If you pay attention to Figure 1, which shows an example of code execution by a 4-cell processor, it is clear that cells execute commands located on tiers when they are ready to be executed. The result is placed in a switching environment and is waiting for its consumer.
The multicellular nucleus does not perform unnecessary actions, it works when there is work. If any of the components of the processor is not ready to execute the command, then work with it is suspended until released.
Scalability, there are no restrictions on the number of cells.
Architecture does not limit the number of cells. Technology is behind it.
There are several options for organizing a large number of cells, but this is a topic for a separate article, which we will prepare later.
3. Implementation of the “ Multi-
Cell” Multicellular Processor
A multicellular processor consists of N identical cells with numbers from 0 to n-1, united by a switching medium. Each cell contains a program memory unit (PM), a control unit (CU), buffer devices (BUF), and each cell corresponds to a switching device (SU), the combination of which forms a switching medium (SB). The processor also contains data memory (DM), a block of general purpose registers (GPR) and an execution unit (EU), consisting of an arithmetic logic device for floating point numbers (ALU_FLOAT), ALU for integers (ALU_INTEGER) and a memory access unit data (DMS).
The program for multicell assembler consists of paragraphs. For instance:
In fact, the command to go to the next paragraph can be anywhere in the current paragraph, but for now we are not focusing on this. In this example, a paragraph is all commands from the label “Paragragh” to the label of the end of the section of commands - “complete”.
In the paragraph, the commands can be arranged in random order, the teams can refer to the result of previous commands using the “@” operator, but keep in mind that you cannot refer to the result of a command that is 64 orders higher than the current one. Those. the result visibility window for each command is 64, while the size of the paragraph is not limited, i.e. it can consist of at least several thousand teams. Consider an example:
In this example, the addl @ 1, @ 2 command adds the two previous commands, and the addl @ 1, @ 3 command adds the result of the previous command and the result of the command, which is 3 lines higher.
The state of the processor changes when moving from one paragraph to another. Writes to memory, registers occur at the end of the paragraph in the event that the control of reading the record is enabled or direct read and write commands are not used. But there is the possibility of disabling read and write control, i.e. writing to memory will take place in the paragraph itself, without waiting for its completion (in cases where it is possible to disable read and write control, when working with memory it can bring a noticeable increase in performance). In fact, it’s easy to get the most out of a multicellular processor, but this is a topic for another article.
To execute a context-sensitive program, the commands of each paragraph are sequentially, starting from the same address, which is the address of this paragraph, placed in PM cells. The location address of the first executable paragraph is equal to the address from which cells select commands. As a result, in the PM of the i-th cell, starting from the address of the paragraph, its commands with numbers i, N + i, 2 * N + i, ..., are sequentially placed.
Each cell provides, starting from the address indicated to it, a sequential selection of instructions and placing them on the instruction register for subsequent decoding. Cell commands are selected synchronously.
When decoding each next selected group of N commands, the next tag value (t) is assigned, and the number from the group and, accordingly, its result is assigned a number. The selection and decoding of instructions continues until a command is selected that is marked with the control sign “end of paragraph” (Complete). The address of the new paragraph can be received either at any time in the selection of commands of the current paragraph, or after completion of the selection of commands. It enters all cells simultaneously. If at the time of the selection of the last paragraph command the address of the next paragraph is not calculated, then the selection is suspended until the address is received. If the address is received, the selection continues from this address. The selected instruction arrives at the buffer device, which consists of the buffer of the first operand, the buffer of the second operand, and the instruction buffer (operation codes, tags, etc.
The operational part (instruction buffer), in addition to the instruction code, includes all the necessary service information for sending and receiving results, namely, the instruction number and signs of the readiness of the first (second) operand to execute the instruction.
The operand storage buffer is associatively addressed. The associative
address is the tag of the requested result. As operands during operations, the following can be used:
In the first case, the readiness flag of this operand when writing the command is set to the “not ready” state, and in the second - to the “ready” state. After receiving the requested result from the switching device, the sign, in the first case, is also set to “ready”. A command that has received all the operands undergoes priority selection among other ready-made commands in the buffer device, after which it is issued for execution provided that the executive device is unoccupied.
In processor P1, a separate memory area was allocated for each cell, i.e. program memory and data memory did not overlap. In processor R1, program memory and data memory are in the same address space, i.e. cells have access channels to program memory and data memory. Figure 4 shows the general structure of processor P1. Figure 5 shows the cell structure and its description for processor R1.
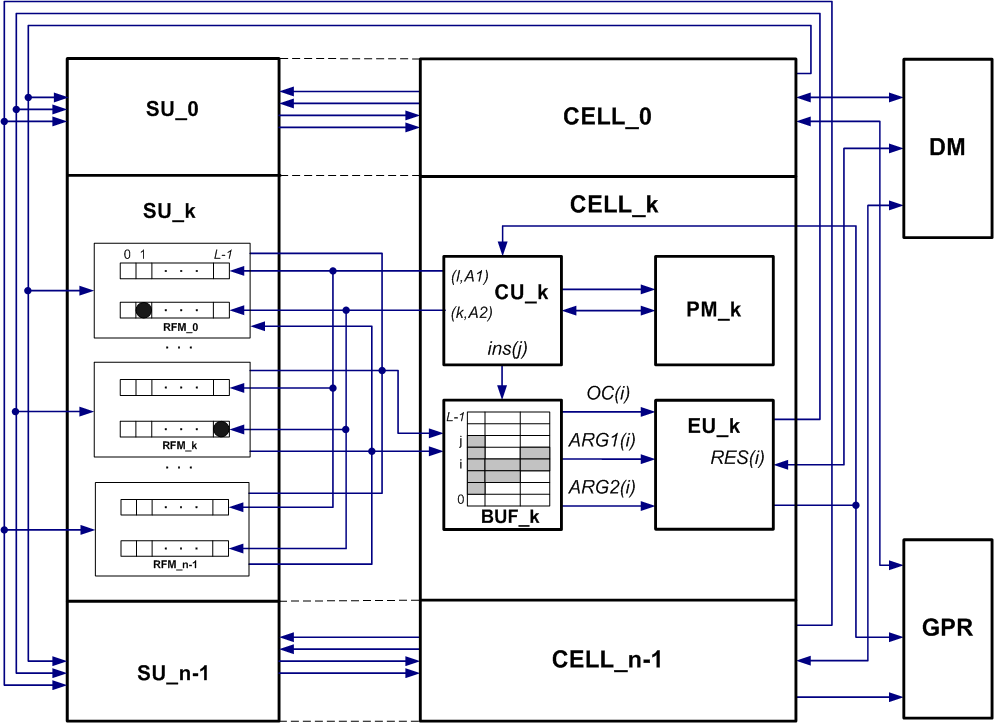
Figure 4. General structure of a multicellular processor
Arithmetic logic devices (ALU), along with the DMS unit, are part of the set of actuators available in each cell (CELL).
The cell includes the following devices:
1. Instruction Distribution Unit (IDU).
2. The control device.
3. Switching device SU (Switch Unit).
4. Buffer device.
5. Integer ALU.
6. ALU floating point.
7. Block access to data memory DMS (Data Memory Service).
8. Multiplexer of results.
9. A set of registers GPR (General-Purpose Registers).
10. Interrupt Controller IC (Interrupt Controller).
11. Debugging block JTAG-GPR.
A detailed cell structure is shown in Figure 5:

Figure 5. Cell structure.
The result of the execution of the actuators are passed to the switching device.
If the results of executing the integer ALU, ALU with floating point and DMS instructions are ready at the same time, the switching device receives the result of executing the ALU floating point command.
Actuators are distributed according to the priority of reading the result as follows: 1. AALU with a floating point;
2.DMS;
3. Integer ALU.
Actuators, the result of which at the current cycle cannot be issued to the switching device, write the result of the command to the output register and wait for their turn to issue the result.
The situation described above has the consequence that the number of measures required to execute a command is a non-deterministic quantity.
Each cell has two ALUs: an integer ALU and an ALU for floating-point numbers.
Integer ALU is designed to execute commands on integer operands, while operands can be represented in the following formats (depending on the command):
ALU with a floating point is designed to execute commands on operands presented in the format of single or 32-bit or double-precision floating-point numbers (64 bits) in accordance with the requirements of the IEEE-754 standard.
Structurally, a floating-point ALU consists of three parts:
What is the difference between multicellular processors and multicore processors?
In conventional processors consisting of one or more cores, the elementary unit of execution is a command executed in a specific order. In a multicellular processor, the elementary unit of execution is a paragraph, i.e. linear section, consisting of an unlimited number of teams, after which there is a transition to another linear section with a given label. Commands from this section will be executed in parallel where possible. Parallelization occurs in hardware, i.e. the programmer does not need to worry about which cell the team will get into. This is what we call "natural parallelism." As a result of this, the same code can be executed on any number of cells. Another difference of a multicellular processor is the transmission of the results of the work of commands using broadcasting, whereas in many single-core systems, results are transmitted through memory and registers. Of course, multicellular processors have memory and registers for transferring data between linear sections, but inside a linear section, basic operations can be carried out without using registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability. but within the linear section, basic operations can be carried out without the use of registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability. but within the linear section, basic operations can be carried out without the use of registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability.
We will return to issues of parallelism and reconfiguration later in this article.
4. Examples. A multicellular
processor consists of 4 cells (maybe 256 or more), the cells are completely equal and united by a switching environment (commutator). The result of executing the commands of the cell is stored in the switch.
The assembler program is divided into sections and paragraphs that contain commands.
For the exchange of information between cells, a switch is used, and for the exchange between paragraphs, there are RONs, index registers, data memory. There are peripheral registers for working with peripherals.
To weed out statements of the form:
Consider a simple program:
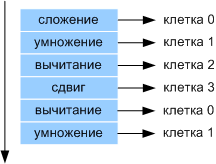
Fig 2. Distribution of teams by cells
As shown in Figure 2, the teams from the paragraph will be distributed by cells. Commands in each cell are executed in parallel ("natural parallelism"). The execution of commands occurs when the arguments are ready. In this case, the program is executed by a group of 4 cells. The program will be successfully executed both on 4, so on any other number of cells. The basic principle of multicellular architecture is that cells are independent of each other and from anyone and are the same. This principle applies to processors with reconfiguration.
Reconfiguration- the ability of processor cells to composition (collection) and decomposition (analysis) into groups, i.e. the ability of cells to unite in groups from one cell to N (for N cell processor) and execute their own code section. By default, when starting any program, all cells are in one group. It is worth noting that each group has its own set of RONs, index, control registers, you can assign your own interrupt handler.
In an article on von Neumann architecture, Leonid Chernyak identifies the following three types of reconfigurable processors:
1) specialized processors
2) configurable processors
3) dynamically reconfigurable processors (as an example, the only class of this kind that exists at the time of publication of the article by L. Chernyak - FPGA) is given.
The first two types acquire their specificity in the manufacturing process, and the third can be programmed.
The multicellular processor R1, in accordance with this classification, is dynamically reconfigurable, however, it is a processor on a chip and, due to the independence of machine code, the redistribution of resources (cells), unlike FPGA, occurs without stopping or rebooting the processor and without loss of information. Thus, MultiClet R1 is a new class of the third kind (along with the first - FPGA).
To date, no one has made such processors in the world.
L.Chernyakom proposed classification, adjusted for future development, can be developed in view of the fourth, which we formulate as
4) self-adapting processor ,
capable of self-sufficient operation of all systems, automatically reallocate resources. In the event of damage, failures or additional tasks, the processor or system from the processors must be able to self-adapt to new conditions.
The first step towards the creation of such systems, perhaps, will be the Multiclet L1 processor or its-based CMS.
Consider an example of decomposition (division into groups) of cells:
In this example, we see a partition into 3 groups: cells with numbers 0 and 1 perform calculations, cell 2 collects information from sensors, and cell 3 compiles work reports and interacts with the external environment. If it so happens that cells 0 and 1 do not have time to process the data, then cell 3 can come to their aid and get two groups. It is important to note that a processor reset is not required for cell reconfiguration. Cell 3 will speak the same language with cells 0 and 1, i.e. their set of RONs, index registers and control registers will acquire them.
A simple example of a regular program in assembler (you can write in standard C):
The paragraphs are in a section labeled as “.text”. A paragraph can contain an unlimited number of commands (as long as the program memory allows), but each command can only turn to a command for a result that is no more than 63 lines higher.
For convenience, in assembler, you can set a label for each command, for example:
In a multicellular processor there is no hardware that provides for the identification of information links between selected operations (teams) and their distribution among functional devices, i.e. no dynamic parallelization. There is no static parallelization, as Although the program describes information connections, it has a linear form and does not contain any indications of what and how can be performed in parallel. This is a fundamental difference from other processors. Due to the same feature, the multicellular processor is potentially survivable, i.e. the possibility of continuous execution of the program without recompilation or reboot if its individual cells fail (processor degradation).
Due to the property of a multicellular processor to dynamically distribute its resources, we can create systems capable of performing the task even in the event of a failure of part of the cells.
Degradation is associated with a loss of productivity and, consequently, an increase in the time for solving problems. But, for a number of built-in applications, the vitality of a multicellular processor allows a managed object to perform basic functions, either by reducing their quality or by refusing to solve secondary problems.
The asynchronous and decentralized organization of a multicellular processor, both at the system level - between cells (when implementing parallelism), and at the intracellular level - between cell blocks (when implementing commands), additionally provides:
As a result, a well-structured and modular system is obtained, which makes it possible to drastically reduce processor complexity and, accordingly, reduce costs and improve design quality. Moreover, in comparison with the von Neumann model, the quantitative characteristics of the processor are also improved.
At the moment, tests of simple algorithms such as POCNT and encryption algorithms have been conducted. The program for assembler was written for the popcnt test and we compared the result with a simple program for the Pentium Dual Core 5700 in C.
The test results can be summarized in the following table (the number of clock cycles per 32-bit calculation cycle):
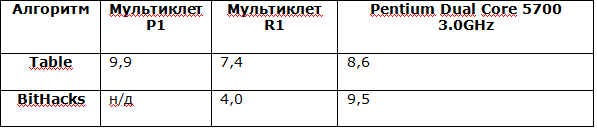
Those. we can conclude that the Multiclet R1 processor on the “table” test is 15% faster than the Intel processor, and on the BitHacks test the Multiclet R1 processor is more than 2 times faster than Intel. The popcnt test for a multicellular processor was simply converted to parallel computing. Of course, in the new Intel processors there is a hardware implementation of popcnt, but in this test we showed the capabilities of our processors.
5. What we have now
. At the moment, the Multiclet P1 processor is released and it is available for order, as well as two debug boards.

In addition, the Multiclet Key_P1 information security device was developed on the first multicellular processor, the first production batch is scheduled for September 2014.

In addition, on the basis of the P1 processor, a printer for foil stamping from Wirschke LLC was developed and supplied as a standard.
Users are actively mastering multicellular processors and complement libraries, as well as creating new useful examples.

The first batch of R1 processors was received, testing of new processors was started.
The first revision of the processor is called R1-1.
Again, the new processor is a topic for a separate article; we will publish the characteristics of the processor of the first revision a bit later.

For this processor, LDM-Systems has released a debug board consisting of a base and a processor. In the photo there is a version with a block. The custom version will be slightly different. The package bundle of the base board can be chosen for your tasks; in the maximum configuration, the base + processor board will have an acceptable cost.

The software package includes:
• Assembler
• C compiler
• Functional model
• Libraries
• Debugger for IDE Geany
• OS FreeRTOS
• Examples of programs
• Plotter
PS If you like this article despite the large volume, I can write a sequel on programming processors, an overview of the R1 processor and principles of building high-performance systems on multicellular processors.
UPD: The program for checking the running time of the popcnt algorithm is taken from the site www.strchr.com/crc32_popcnt. As already noted in the article, there are other faster algorithms for implementing the popcnt test for Intel processors that require certain instructions implemented at the hardware level. To evaluate the capabilities of multicellular architecture, the Table and Bit hacks algorithms were taken.
UPD2: Updated Figure 2. The add @ 3, @ 2 command should be stretched over two lines, and the mpy @ 4, @ 3 command has been reduced in duration, because the arguments for it were ready earlier, which also reduced the overall length of the paragraph. The mpy command has also been replaced by mul.
UPD3: Each cell contains a buffer for 64 teams. The selection of paragraph instructions by cells continues in parallel with the execution, the selection of the next paragraph can be started only if the address of the transition to it is known.
1. Multicellularity Multicellular
nucleus- This is a group of identical processor units (2 or more), united by a fully connected unidirectional switching environment. Peculiarities of the interaction of processor units between themselves follow from the presentation of the algorithm (more on this below). The processor unit in multicellular architecture is called a cell. The set of commands that it can execute is determined by the specific implementation and is architecture independent.
Algorithms "eyes" of the multicellular nucleus
First.
Any formula can be represented in the form of a tiered-parallel form (NPF). Consider a
simple example: g = e * (a + b) + (ac) * f, in a NPS this might look like this:
Figure 1. Example of NPS
In the general case, to perform operations, nodes located on the i-th tier can use the results obtained on tiers from 1 to (i-1) th. It follows that the teams located on the same tier are independent.
Any algorithm is a set of formulas, which is divided into subsets - linear sections, interconnected by control transfer operators. A linear section (LU) is a subset of formulas that can be calculated if and only if control is transferred to a given linear section. Inside a linear section, informationally unrelated formulas can be executed in any order.
As you know, the result of execution by the processor of any command is expressed in a change in the state of the processor. The use of this new state by subsequent teams forms an information link between the source command of the result and the receiver commands of this result. Such a relationship can be either indirect (indirect) or direct (direct).
With indirect communication, the result is available only after its alienation: recording in public registers or memory or other devices. The source command must put the result in these devices, and the receiver command will have to take data from there. The device name is specified as an operand. Such a connection between teams is the basis of absolutely all modern processors, except multicellular ones.
In the case of direct information communication, the teams are named and the names should identify the team itself, and not its location or other features of the implementation. Results can be accessed by the names of both source teams and receiver teams. In the first case, broadcasting is used, followed by roll-call selection, in which the name of the source command is specified in the operand field of the destination command. In the second, a roll-out is performed, in which the source command sets the name of the result destination command.
Theoretically, the nodes of the NPS can be named in any way. The only requirement is uniqueness. To do this, in the multicellular processor of the team, when fetching from memory, they get a tag (label) - thus they are given a local name and their results - and then the interaction between the teams is organized through tags. Data can be obtained from any team with a tag less than its own. The tag number of the desired result is set by the difference between the values of the command tag and the tag of the desired result. For example, if @ 5 is specified in the operand, and the command tag is 7, then the result of the command with tag 2 is used as the operand. All the results of command execution are sent to the switching environment, from which the required ones are selected by tag. Thus, in a multicellular processor, broadcast results are used with their subsequent selection by name.
It is worth noting that due to physical limitations there is the concept of a “visibility window”, which determines the maximum distance of the source command from the receiver command. The tag in the process of selecting commands changes cyclically. Its maximum value is determined by the size of the command buffer. In fact, the size of the tag determines the number of commands that can simultaneously be at different stages of execution. The tag value cannot be used if the command to which it was previously assigned has not yet been executed.
Secondly.
A multicellular processor operates with structures that we call paragraphs.
Paragraph- This is an informationally closed sequence of commands. A paragraph is an analogue of a command, after which the state of the processor and / or systems in its composition (registers, buses, memory cells, input / output channels, etc.) changes. Those. for a multicellular nucleus, a paragraph is a command.
The main feature of multicellular architecture is that it directly implements the JPF representation of the algorithm. From this understanding of the algorithm, many properties of multicellular architecture follow.
2. Properties of multicellular architecture
- independence from the number of cells;
- dynamic allocation of computing resources;
- all commands ready for execution are executed simultaneously;
- lower power consumption. It works when there is work;
- scalability, there are no restrictions on the number of cells.
Let us consider in more detail what the paragraph for the algorithm described in Section 2 will look like.
For a multicellular nucleus, the following paragraph construction scheme is typical (not mandatory, there are also deviations in the above example):
- receiving data for work (commands with a tag 0-2,4,6 in the example);
- data processing (commands with the tag 3,5,7-9 in the example);
- saving results (command with tag 10 in the example).
It should be recalled that a change in the state of a machine in a multicellular processor occurs at the end of a paragraph.
The algorithm does not depend on the number of cells.
The information links between the teams are indicated explicitly and there is no need to know about the number of processor units when a program is being written. The teams just wait for the readiness of their operands and after that they go to execution and they don’t care who and when they will prepare the operands. Imagine a watering can - you do not think about how many holes in its nozzle when watering. The cells are identical and there is no difference in which cell this or that command will be executed.
The teams are distributed in the cells in the order they follow, 1 team in 0 cell, 2 team in 1 cell, etc., when the team was transferred to the last available cell, we begin to redistribute from 0 cell. Consider the work of 4 cell nuclei. The paragraph above will be executed as follows:
Fig. 2. Distribution of commands by cells.
Number of simultaneously executed commands depends on the number of cells. Choosing the optimal number of cells for each task is a task that requires analysis. It is still impossible to create a universal system, therefore, you can focus on the following data: 4 cells do pretty good on common tasks, and 16 cells do on signal processing tasks, and there can be hundreds of them to process a video image.
You can analyze your code and imagine what would be the optimal number of cells for them. To do this, you will need to present your algorithm in the NPS and calculate the number of teams in tiers. The average number of teams in them will hint at the optimal number of cells in your particular case.
All commands ready for execution are executed simultaneously.
As mentioned above, the multicellular nucleus implements the JPF representation of the algorithm; independent teams are located on the tiers. Everything that can be done at the moment will be executed without any special instructions from the programmer, the main condition is that the team must receive all the data for execution.
Technological limitations should be taken into account: the number of cells is limited, so as many commands will be executed simultaneously as there are cells in the nucleus.
“Alignment collapse” or dynamic allocation of computing resources
Because the code does not depend on the number of cells by which it will be executed, the ability of a multicellular nucleus to distribute its computing resources during operation appears, and control is performed programmatically.
The ability of multicellular architecture to redistribute its resources is what we call reconfiguration . For example, the cells of a multicellular nucleus can be arbitrarily distributed to execute any algorithm or part of it. A group (they haven’t come up with a better name yet) is a part of the cells of a multicellular nucleus that are interconnected to execute any algorithm or part of an algorithm. A group may contain 1 or more cells. When a multicellular nucleus divides a group into parts, this is called decomposition . Grouping process -composition . Figure 3 below shows how a 4-cell nucleus reconfigures over time (example). Cells that perform one task have one color fill.
Figure 3. An example of cell reconfiguration.
Reducing energy consumption. It works when there is work.
The fundamental basis of multicellular architecture is broadcast. To date, this is so far the only architecture that uses direct information communication to transfer data between teams in the program.
If you pay attention to Figure 1, which shows an example of code execution by a 4-cell processor, it is clear that cells execute commands located on tiers when they are ready to be executed. The result is placed in a switching environment and is waiting for its consumer.
The multicellular nucleus does not perform unnecessary actions, it works when there is work. If any of the components of the processor is not ready to execute the command, then work with it is suspended until released.
Scalability, there are no restrictions on the number of cells.
Architecture does not limit the number of cells. Technology is behind it.
There are several options for organizing a large number of cells, but this is a topic for a separate article, which we will prepare later.
3. Implementation of the “ Multi-
Cell” Multicellular Processor
A multicellular processor consists of N identical cells with numbers from 0 to n-1, united by a switching medium. Each cell contains a program memory unit (PM), a control unit (CU), buffer devices (BUF), and each cell corresponds to a switching device (SU), the combination of which forms a switching medium (SB). The processor also contains data memory (DM), a block of general purpose registers (GPR) and an execution unit (EU), consisting of an arithmetic logic device for floating point numbers (ALU_FLOAT), ALU for integers (ALU_INTEGER) and a memory access unit data (DMS).
The program for multicell assembler consists of paragraphs. For instance:
Paragraph:
;Различные команды
jmp paragraph_next ; переход на следующий параграф
complete
In fact, the command to go to the next paragraph can be anywhere in the current paragraph, but for now we are not focusing on this. In this example, a paragraph is all commands from the label “Paragragh” to the label of the end of the section of commands - “complete”.
In the paragraph, the commands can be arranged in random order, the teams can refer to the result of previous commands using the “@” operator, but keep in mind that you cannot refer to the result of a command that is 64 orders higher than the current one. Those. the result visibility window for each command is 64, while the size of the paragraph is not limited, i.e. it can consist of at least several thousand teams. Consider an example:
Paragraph:
getl 2 ;загрузка числа в коммутатор
getl 3 ;загрузка числа в коммутатор
addl @1, @2 ;сложение 2 + 3
addl @1, @3 ;сложение 5 +2
jmp paragraph2
complete
In this example, the addl @ 1, @ 2 command adds the two previous commands, and the addl @ 1, @ 3 command adds the result of the previous command and the result of the command, which is 3 lines higher.
The state of the processor changes when moving from one paragraph to another. Writes to memory, registers occur at the end of the paragraph in the event that the control of reading the record is enabled or direct read and write commands are not used. But there is the possibility of disabling read and write control, i.e. writing to memory will take place in the paragraph itself, without waiting for its completion (in cases where it is possible to disable read and write control, when working with memory it can bring a noticeable increase in performance). In fact, it’s easy to get the most out of a multicellular processor, but this is a topic for another article.
To execute a context-sensitive program, the commands of each paragraph are sequentially, starting from the same address, which is the address of this paragraph, placed in PM cells. The location address of the first executable paragraph is equal to the address from which cells select commands. As a result, in the PM of the i-th cell, starting from the address of the paragraph, its commands with numbers i, N + i, 2 * N + i, ..., are sequentially placed.
Each cell provides, starting from the address indicated to it, a sequential selection of instructions and placing them on the instruction register for subsequent decoding. Cell commands are selected synchronously.
When decoding each next selected group of N commands, the next tag value (t) is assigned, and the number from the group and, accordingly, its result is assigned a number. The selection and decoding of instructions continues until a command is selected that is marked with the control sign “end of paragraph” (Complete). The address of the new paragraph can be received either at any time in the selection of commands of the current paragraph, or after completion of the selection of commands. It enters all cells simultaneously. If at the time of the selection of the last paragraph command the address of the next paragraph is not calculated, then the selection is suspended until the address is received. If the address is received, the selection continues from this address. The selected instruction arrives at the buffer device, which consists of the buffer of the first operand, the buffer of the second operand, and the instruction buffer (operation codes, tags, etc.
The operational part (instruction buffer), in addition to the instruction code, includes all the necessary service information for sending and receiving results, namely, the instruction number and signs of the readiness of the first (second) operand to execute the instruction.
The operand storage buffer is associatively addressed. The associative
address is the tag of the requested result. As operands during operations, the following can be used:
- requested results from source commands coming from the switch;
- values calculated when decoding the control word, as well as directly present in the command word or taken from general registers.
In the first case, the readiness flag of this operand when writing the command is set to the “not ready” state, and in the second - to the “ready” state. After receiving the requested result from the switching device, the sign, in the first case, is also set to “ready”. A command that has received all the operands undergoes priority selection among other ready-made commands in the buffer device, after which it is issued for execution provided that the executive device is unoccupied.
In processor P1, a separate memory area was allocated for each cell, i.e. program memory and data memory did not overlap. In processor R1, program memory and data memory are in the same address space, i.e. cells have access channels to program memory and data memory. Figure 4 shows the general structure of processor P1. Figure 5 shows the cell structure and its description for processor R1.
Figure 4. General structure of a multicellular processor
Arithmetic logic devices (ALU), along with the DMS unit, are part of the set of actuators available in each cell (CELL).
The cell includes the following devices:
1. Instruction Distribution Unit (IDU).
2. The control device.
3. Switching device SU (Switch Unit).
4. Buffer device.
5. Integer ALU.
6. ALU floating point.
7. Block access to data memory DMS (Data Memory Service).
8. Multiplexer of results.
9. A set of registers GPR (General-Purpose Registers).
10. Interrupt Controller IC (Interrupt Controller).
11. Debugging block JTAG-GPR.
A detailed cell structure is shown in Figure 5:
Figure 5. Cell structure.
The result of the execution of the actuators are passed to the switching device.
If the results of executing the integer ALU, ALU with floating point and DMS instructions are ready at the same time, the switching device receives the result of executing the ALU floating point command.
Actuators are distributed according to the priority of reading the result as follows: 1. AALU with a floating point;
2.DMS;
3. Integer ALU.
Actuators, the result of which at the current cycle cannot be issued to the switching device, write the result of the command to the output register and wait for their turn to issue the result.
The situation described above has the consequence that the number of measures required to execute a command is a non-deterministic quantity.
Each cell has two ALUs: an integer ALU and an ALU for floating-point numbers.
Integer ALU is designed to execute commands on integer operands, while operands can be represented in the following formats (depending on the command):
- 64-bit
- 32-bit
- 16 bit
- 8-bit
- packed 32-bit;
- packed 16-bit.
ALU with a floating point is designed to execute commands on operands presented in the format of single or 32-bit or double-precision floating-point numbers (64 bits) in accordance with the requirements of the IEEE-754 standard.
Structurally, a floating-point ALU consists of three parts:
- Single precision divider (division, square root extraction)
- Double precision divider
- Calculator (execution of other commands)
What is the difference between multicellular processors and multicore processors?
In conventional processors consisting of one or more cores, the elementary unit of execution is a command executed in a specific order. In a multicellular processor, the elementary unit of execution is a paragraph, i.e. linear section, consisting of an unlimited number of teams, after which there is a transition to another linear section with a given label. Commands from this section will be executed in parallel where possible. Parallelization occurs in hardware, i.e. the programmer does not need to worry about which cell the team will get into. This is what we call "natural parallelism." As a result of this, the same code can be executed on any number of cells. Another difference of a multicellular processor is the transmission of the results of the work of commands using broadcasting, whereas in many single-core systems, results are transmitted through memory and registers. Of course, multicellular processors have memory and registers for transferring data between linear sections, but inside a linear section, basic operations can be carried out without using registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability. but within the linear section, basic operations can be carried out without the use of registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability. but within the linear section, basic operations can be carried out without the use of registers and memory. This fact gives the multicellular architecture simplicity of implementation and a decrease in memory access, as a result of a reduction in power consumption. In addition, the execution of the same program on one, two, ..., two hundred and fifty-six cells makes it possible to reconfigure (combine cells into task groups) cells, create a fault-tolerant processor and scalability.
We will return to issues of parallelism and reconfiguration later in this article.
4. Examples. A multicellular
processor consists of 4 cells (maybe 256 or more), the cells are completely equal and united by a switching environment (commutator). The result of executing the commands of the cell is stored in the switch.
The assembler program is divided into sections and paragraphs that contain commands.
For the exchange of information between cells, a switch is used, and for the exchange between paragraphs, there are RONs, index registers, data memory. There are peripheral registers for working with peripherals.
To weed out statements of the form:
- Even if it is a “page” of memory, but who “steers” all memory? Where is the senior (upper) control unit for cells? Who is loading cell memory?
- Programmer, not processor, parallel
Consider a simple program:
Fig 2. Distribution of teams by cells
As shown in Figure 2, the teams from the paragraph will be distributed by cells. Commands in each cell are executed in parallel ("natural parallelism"). The execution of commands occurs when the arguments are ready. In this case, the program is executed by a group of 4 cells. The program will be successfully executed both on 4, so on any other number of cells. The basic principle of multicellular architecture is that cells are independent of each other and from anyone and are the same. This principle applies to processors with reconfiguration.
Reconfiguration- the ability of processor cells to composition (collection) and decomposition (analysis) into groups, i.e. the ability of cells to unite in groups from one cell to N (for N cell processor) and execute their own code section. By default, when starting any program, all cells are in one group. It is worth noting that each group has its own set of RONs, index, control registers, you can assign your own interrupt handler.
In an article on von Neumann architecture, Leonid Chernyak identifies the following three types of reconfigurable processors:
1) specialized processors
2) configurable processors
3) dynamically reconfigurable processors (as an example, the only class of this kind that exists at the time of publication of the article by L. Chernyak - FPGA) is given.
The first two types acquire their specificity in the manufacturing process, and the third can be programmed.
The multicellular processor R1, in accordance with this classification, is dynamically reconfigurable, however, it is a processor on a chip and, due to the independence of machine code, the redistribution of resources (cells), unlike FPGA, occurs without stopping or rebooting the processor and without loss of information. Thus, MultiClet R1 is a new class of the third kind (along with the first - FPGA).
To date, no one has made such processors in the world.
L.Chernyakom proposed classification, adjusted for future development, can be developed in view of the fourth, which we formulate as
4) self-adapting processor ,
capable of self-sufficient operation of all systems, automatically reallocate resources. In the event of damage, failures or additional tasks, the processor or system from the processors must be able to self-adapt to new conditions.
The first step towards the creation of such systems, perhaps, will be the Multiclet L1 processor or its-based CMS.
Consider an example of decomposition (division into groups) of cells:
In this example, we see a partition into 3 groups: cells with numbers 0 and 1 perform calculations, cell 2 collects information from sensors, and cell 3 compiles work reports and interacts with the external environment. If it so happens that cells 0 and 1 do not have time to process the data, then cell 3 can come to their aid and get two groups. It is important to note that a processor reset is not required for cell reconfiguration. Cell 3 will speak the same language with cells 0 and 1, i.e. their set of RONs, index registers and control registers will acquire them.
A simple example of a regular program in assembler (you can write in standard C):
.text
habr:
getl 4 ;загрузка константы в коммутатор
getl 5 ; загрузка константы в коммутатор
addl @1, @2 ;сложение 4 + 5 = 9
mull @3, @2 ;умножение 4 * 5 = 20
subl @1, @2 ;вычитание 20 – 9 = 11
slrl @1, 2 ;сдвиг 11 << 2 = 44
subl @1, @2 ;вычитание 44 – 11 = 33
mull @4, @5 ;умножение 20 * 9 = 180
jmp habrahabr ;переход на следующий параграф
complete
habrahabr:
getl 5 ;загрузка константы в коммутатор
addl @1, [10] ;сложение константы и значения из памяти по адресу 10
setl #32, @1 ;запись суммы в регистр номер 32
complete
The paragraphs are in a section labeled as “.text”. A paragraph can contain an unlimited number of commands (as long as the program memory allows), but each command can only turn to a command for a result that is no more than 63 lines higher.
For convenience, in assembler, you can set a label for each command, for example:
habr:
arg1 := getl 5 ;загрузка константы в коммутатор
sum1 := addl @arg1, [10] ;сложение константы и значения из памяти по адресу 10
setl #32, @sum1 ;запись суммы в регистр номер 32
complete
In a multicellular processor there is no hardware that provides for the identification of information links between selected operations (teams) and their distribution among functional devices, i.e. no dynamic parallelization. There is no static parallelization, as Although the program describes information connections, it has a linear form and does not contain any indications of what and how can be performed in parallel. This is a fundamental difference from other processors. Due to the same feature, the multicellular processor is potentially survivable, i.e. the possibility of continuous execution of the program without recompilation or reboot if its individual cells fail (processor degradation).
Due to the property of a multicellular processor to dynamically distribute its resources, we can create systems capable of performing the task even in the event of a failure of part of the cells.
Degradation is associated with a loss of productivity and, consequently, an increase in the time for solving problems. But, for a number of built-in applications, the vitality of a multicellular processor allows a managed object to perform basic functions, either by reducing their quality or by refusing to solve secondary problems.
The asynchronous and decentralized organization of a multicellular processor, both at the system level - between cells (when implementing parallelism), and at the intracellular level - between cell blocks (when implementing commands), additionally provides:
- minimization of the nomenclature of design objects and reduction of their
complexity; - decrease in the area of the processor chip (the amount of equipment with
decentralized control is less than with centralized); - increased productivity and reduced energy consumption through the
implementation of a more efficient computing process; - the use of an individual synchronization system for each cell
when implementing tens or hundreds of cells on a single crystal.
As a result, a well-structured and modular system is obtained, which makes it possible to drastically reduce processor complexity and, accordingly, reduce costs and improve design quality. Moreover, in comparison with the von Neumann model, the quantitative characteristics of the processor are also improved.
At the moment, tests of simple algorithms such as POCNT and encryption algorithms have been conducted. The program for assembler was written for the popcnt test and we compared the result with a simple program for the Pentium Dual Core 5700 in C.
The test results can be summarized in the following table (the number of clock cycles per 32-bit calculation cycle):

Those. we can conclude that the Multiclet R1 processor on the “table” test is 15% faster than the Intel processor, and on the BitHacks test the Multiclet R1 processor is more than 2 times faster than Intel. The popcnt test for a multicellular processor was simply converted to parallel computing. Of course, in the new Intel processors there is a hardware implementation of popcnt, but in this test we showed the capabilities of our processors.
5. What we have now
. At the moment, the Multiclet P1 processor is released and it is available for order, as well as two debug boards.

In addition, the Multiclet Key_P1 information security device was developed on the first multicellular processor, the first production batch is scheduled for September 2014.

In addition, on the basis of the P1 processor, a printer for foil stamping from Wirschke LLC was developed and supplied as a standard.

Users are actively mastering multicellular processors and complement libraries, as well as creating new useful examples.

The first batch of R1 processors was received, testing of new processors was started.
The first revision of the processor is called R1-1.
Again, the new processor is a topic for a separate article; we will publish the characteristics of the processor of the first revision a bit later.

For this processor, LDM-Systems has released a debug board consisting of a base and a processor. In the photo there is a version with a block. The custom version will be slightly different. The package bundle of the base board can be chosen for your tasks; in the maximum configuration, the base + processor board will have an acceptable cost.

The software package includes:
• Assembler
• C compiler
• Functional model
• Libraries
• Debugger for IDE Geany
• OS FreeRTOS
• Examples of programs
• Plotter
PS If you like this article despite the large volume, I can write a sequel on programming processors, an overview of the R1 processor and principles of building high-performance systems on multicellular processors.
UPD: The program for checking the running time of the popcnt algorithm is taken from the site www.strchr.com/crc32_popcnt. As already noted in the article, there are other faster algorithms for implementing the popcnt test for Intel processors that require certain instructions implemented at the hardware level. To evaluate the capabilities of multicellular architecture, the Table and Bit hacks algorithms were taken.
UPD2: Updated Figure 2. The add @ 3, @ 2 command should be stretched over two lines, and the mpy @ 4, @ 3 command has been reduced in duration, because the arguments for it were ready earlier, which also reduced the overall length of the paragraph. The mpy command has also been replaced by mul.
UPD3: Each cell contains a buffer for 64 teams. The selection of paragraph instructions by cells continues in parallel with the execution, the selection of the next paragraph can be started only if the address of the transition to it is known.