The book "Guide to the architecture of cloud applications"
 This guide has structured guidelines for designing scalable, resilient, and highly available cloud applications. It is designed to help you make decisions about architecture, no matter what cloud platform you use.
This guide has structured guidelines for designing scalable, resilient, and highly available cloud applications. It is designed to help you make decisions about architecture, no matter what cloud platform you use. The guide is organized as a sequence of steps — choosing an architecture → choosing technologies for computing and storing data → designing an Azure application → choosing templates → verifying an architecture. For each of them are recommendations that will help you in developing the architecture of the application.
Today we publish part of the first chapter of this book. You can download the full version for free at the link .
Table of contents
- The choice of architecture - 1;
- The choice of technologies for computing and storing data - 35;
- Designing an Azure Application: Design Principles - 60;
- Designing an Azure application: quality scores - 95;
- Designing an Azure Application: Design Patterns - 103;
- Template Catalog - 110;
- Architecture checklists - 263;
- The conclusion is 291;
- Azure Reference Architecture - 292;
Choice of architecture
The first decision you need to make when designing a cloud application is to choose an architecture. The choice of architecture depends on the complexity of the application, its application, its type (IaaS or PaaS) and the tasks for which it is intended. It is also important to take into account the skills of the development team and the project managers, as well as the availability of the finished architecture.
The choice of architecture imposes certain restrictions on the structure of the application, limiting the choice of technologies and other elements of the application. These limitations are associated with both the advantages and disadvantages of the chosen architecture.
The information in this section will help you find a balance between them when implementing a particular architecture. This section lists ten design principles to keep in mind. Following these principles will help create a more scalable, resilient, and manageable application.
We have identified a set of architectural options that are commonly used in cloud applications. A section dedicated to each of them contains:
- description and logic of the architecture;
- recommendations on the scope of this architecture;
- advantages, disadvantages and recommendations for use;
- Recommended deployment option using suitable Azure services.
Overview of Architecture Options
This section provides a brief overview of the selected architecture options, as well as general recommendations for their use. More information can be found in the relevant sections, available on the links.
N-tier
N-tier architecture is most often used in enterprise applications. To manage dependencies, an application is divided into layers, each of which is responsible for a certain logical function, for example, data presentation, business logic, or data access. A layer can call to other layers below. However, such a division into horizontal layers may cause additional difficulties. For example, it may be difficult to make changes to one part of an application without affecting its other elements. Therefore, to frequently update such an application is not easy, and developers will have to add new functions less often.
N-tier architecture is a natural choice when porting already used applications built on a multi-tier architecture. Therefore, this architecture is most often used in IaaS solutions (infrastructure as a service) or in applications that combine IaaS with managed services.

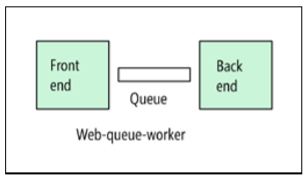
Web Interface - Queue - Worker
For PaaS solutions, the “web interface - queue - worker role” architecture is suitable. With this architecture, the application has a web interface that processes HTTP requests and a server worker role that is responsible for operations that are performed for a long time or are demanding of computing resources. An asynchronous message queue is used for interaction between the interface and the server working role.
The "web interface - queue - worker role" architecture is suitable for relatively simple tasks demanding of computational resources. Like the N-tier architecture, this model is easy to understand. The use of managed services simplifies deployment and operation. But when creating applications for complex subject areas, it is difficult to control dependencies. The web interface and the worker role can easily grow to large monolithic components that are difficult to maintain and update. As with the N-tier architecture, this model is characterized by a lower frequency of updates and limited opportunities for improvement.
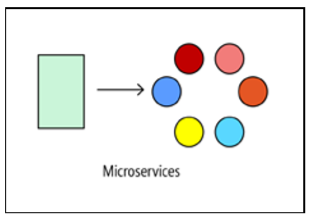
Microservices
If the application is designed to solve more complex problems, try to implement it based on the microservice architecture. Such an application consists of many small independent services. Each service is responsible for a separate business function. Services are loosely coupled and use API contracts to communicate.
A small team of developers can work on creating a separate service. Services can be deployed without complex coordination between developers, which makes it easy to update them regularly. The architecture of microservices is more difficult to implement and manage than the previous two approaches. It requires a mature culture of managing the development process. But if everything is organized correctly, such an approach helps to increase the frequency of new versions, accelerate the introduction of innovations and make the architecture more resilient.
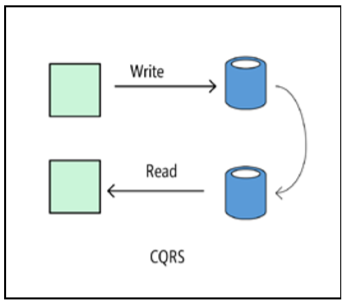
CQRS
The CQRS architecture (Command and Query Responsibility Segregation, sharing responsibility between teams and queries) allows you to divide read and write operations between separate models. As a result, the parts of the system responsible for changing the data are isolated from the parts of the system that are responsible for reading the data. Moreover, read operations can be performed in a materialized view that is physically separated from the database to which it is being written. This allows independent scaling of the reading and writing processes and optimizing the materialized view for executing queries.
The CQRS model is best used for a subsystem of a larger architecture. In general, it should not be applied to the entire application, since this will unnecessarily complicate its architecture. It performs well in collaboration systems, where a large number of users simultaneously work with the same data.
Event Based Architecture
The event-based architecture uses a publish-subscription model in which providers publish events, and consumers subscribe to them. Suppliers are independent of consumers, and consumers are independent of each other.
The event-based architecture is well-suited for applications that need to quickly receive and process large amounts of data with low latency, such as the Internet of things. In addition, this architecture is well manifested in cases where different subsystems must handle the same event data in different ways.

Big data, big calculations
Big data and big computations are special architectures used to solve particular problems. When using the big data architecture, large data sets are divided into fragments, which are then processed in parallel for analysis and reporting purposes. Large computing is also called high performance computing (HPC). This technology allows you to distribute computing between multiple (thousands) of processor cores. These architectures can be used for simulation, 3D-rendering and other similar tasks.
Architecture options as limitations
The architecture acts as a constraint in the design of the solution, in particular, it determines which elements can be used and which connections between them are possible. Constraints set the "form" of the architecture and allow you to make a choice from a narrower set of options. If the limitations of the chosen architecture are met, the properties characteristic of this architecture appear.
For example, microservices have the following limitations:
- each service is responsible for a separate function;
- services are independent of each other;
- data is available only for the service that is responsible for them. Services do not exchange data.
Following these limitations leads to the creation of a system in which services can be deployed independently of each other, faults are isolated, frequent updates are possible, and new technologies are easily added to the application.
Before choosing an architecture, make sure that you understand the underlying principles and the associated limitations. Otherwise, you can get a solution that externally corresponds to the chosen architecture model, but it does not fully reveal the potential of this model. It is also important to be guided by common sense. Sometimes it is more reasonable to refuse from this or that restriction than to strive for cleanliness of architecture.
The following table shows how dependencies are managed in each of their architectures, and for which tasks this or that architecture is most suitable.

Analysis of the advantages and disadvantages
Restrictions create additional difficulties, so it is important to understand what has to be sacrificed when choosing one or another architecture option, and to be able to answer the question whether the advantages of the chosen option outweigh its disadvantages for a particular task in a particular context.
The following are some of the drawbacks to consider when choosing an architecture:
- Complexity. Is the use of a complex architecture justified for your task? Conversely, is the architecture too simple for a complex task? In this case, you risk getting a system without a clear structure, since the architecture used does not allow you to manage dependencies correctly.
- Asynchronous messaging and coherence ultimately. Asynchronous messaging helps to separate services and increase reliability (thanks to the possibility of re-sending messages) and scalability. However, it creates certain difficulties, such as the semantics of a one-time transfer only and the problem of consistency in the long run.
- Interaction between services. If you divide the application into separate services, there is a risk that the data exchange between the services will take too much time or lead to network overload (for example, when using micro-services).
- Controllability. How difficult will it be to manage the application, monitor its operation, deploy updates and perform other tasks?
N-tier architecture
In the N-tier architecture, the application is divided into logical layers and physical layers.
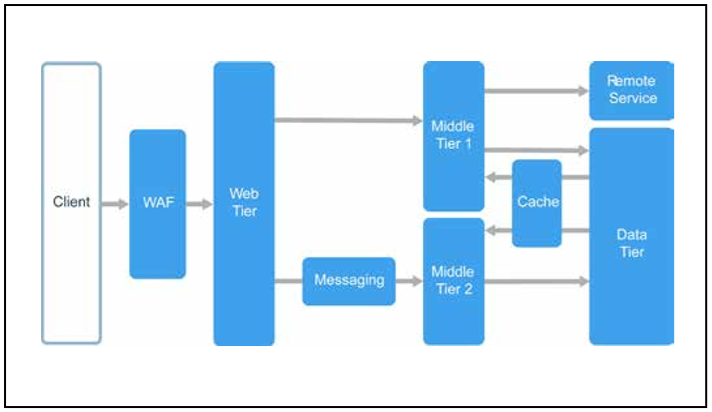
Layers are a responsibility sharing and dependency management mechanism. Each layer has its own area of responsibility. The higher layers use the services of the lower layers, but not vice versa.
Levels are physically separated and work on different computers. One level can access another directly or using asynchronous messages (message queue). Although each layer should be placed on its own level, it is not necessary. At one level you can place multiple layers. Physical level separation makes the solution not only more scalable and fault-tolerant, but also slower, since the network is often used for interaction. A traditional three-tier application consists of the presentation, intermediate, and database levels. Intermediate level is optional. More complex applications can consist of more than three levels. The diagram above shows an application with two intermediate levels responsible for different functional areas.
An n-tier application can have a closed layer architecture or an open layer architecture.
- In a closed architecture, an arbitrary layer can only access the nearest lower layer.
- In an open architecture, an arbitrary layer can refer to any underlying layers.
The closed layer architecture limits the dependencies between the layers. However, its use may excessively increase network traffic if a particular layer simply forwards requests to the next layer.
Scopes of architecture
N-tier architecture is typically used in IaaS applications, where each layer runs on a separate set of virtual machines. However, the N-tier application does not have to be a clean IaaS application. It is often convenient to use managed services for some components of the solution, especially for caching, messaging and data storage.
N-tier architecture is recommended to be used in the following cases:
- simple web applications;
- Migrate a local application to Azure with minimal refactoring
- consistent deployment of local and cloud applications.
The N-tier architecture is common among normal local applications, so it is well suited for migrating existing applications to Azure.
Benefits
- The ability to transfer applications between local deployment and the cloud, as well as between cloud platforms.
- Less need for training for most developers.
- The natural continuation of the traditional model of applications.
- Support for heterogeneous environments (Windows / Linux).
disadvantages
- It is easy to get an application in which the intermediate level performs only CRUD operations in the database, increasing query processing time and without bringing any benefit.
- Monolithic architecture will not allow the development of individual components by independent development teams.
- Managing an IaaS application is more time consuming than an application based on managed services only.
- It may be difficult to manage network security in large systems.
Recommendations
- Use automatic scaling at variable load. See Auto Scaling Tips.
- Use asynchronous messaging to separate layers from each other.
- Cache semi-static data. See Caching Guidelines.
- Ensure high database availability with a solution such as Always On Availability Groups in SQL Server.
- Install a web application firewall (WAF) between the interface and the Internet.
- Place each level in its own subnet; use subnets as security boundaries.
- Restrict access to the data tier by allowing only requests from intermediate tiers.
N-tier architecture on virtual machines
This section provides guidelines for building an N-tier architecture when using virtual machines.

This section provides guidelines for building an N-tier architecture when using virtual machines. Each layer consists of two or more virtual machines located in an accessibility set or in a scalable set of virtual machines. Using multiple virtual machines provides fault tolerance in the event of a failure of one of them. To distribute requests between virtual machines of the same level, load balancers are used. The level can be scaled horizontally by adding new virtual machines to the pool.
Each level also fits inside its own subnet. This means that their internal IP addresses are in the same range. This makes it easy to apply network security group (NSG) rules and routing tables to individual levels.
Web tier and business tier status is not monitored. Any virtual machine can handle any requests for these levels. The data tier must consist of a replicated database. For Windows, we recommend using SQL Server with Always On availability groups for high availability. For Linux, choose a database that supports replication, such as Apache Cassandra.
Access to each level is limited to Network Security Groups (NSG). For example, access to the database tier is allowed only for the business tier.
Additional features
- N-tier architecture does not have to consist of three levels. In more complex applications, as a rule, more levels are used. In this case, use routing through layer 7 to redirect requests to a specific layer.
- Levels limit the decision regarding scalability, reliability and security. It is recommended to use different levels for services with different requirements for these characteristics.
- Apply automatic scaling using scalable sets of virtual machines.
- Find in the architecture elements that can be implemented using managed services without serious refactoring. In particular, pay attention to caching, messaging, storage, and databases.
- For increased security, place the application behind the perimeter network. The perimeter network includes virtual network components that provide security, such as firewalls and packet inspectors. For more information, see Perimeter Network Reference Architecture.
- For high availability, place two or more virtual network components in the availability set and add a load balancer to distribute Internet requests between them. For more information, see Deploying Virtual Network Components for High Availability.
- Do not allow direct access to virtual machines running application code using RDP and SSH. Instead, operators must enter the node base. This is a network-hosted virtual machine used by administrators to connect to other virtual machines. At the site-bastion NSG rules are configured, allowing access via RDP and SSH protocols only from approved public IP addresses.
- You can extend your Azure virtual network to your local network using a network-to-site virtual private network (VPN) or Azure ExpressRoute. For more information, see Hybrid Network Reference Architecture.
- If your organization uses Active Directory for identity management, you can extend the Active Directory environment to your Azure virtual network. For more information, see Identity Management Reference Architecture.
- If a higher level of availability is required than that provided by the Azure Service Level Agreement for virtual machines, replicate the application between the two regions and configure Azure Traffic Manager to fail over. For more information, see Running Windows virtual machines in several regions and Running Linux virtual machines in several regions.
Download the full version of the book for free and study it at the link below.
→ Download