Part one, but still no one reads the second part
What is it actually about
Once, one late December evening, the collection of material for the Habr article on SAT was completed. There was too much material, and I had a choice: to divide the article into two parts or to collect all the material together in one article. The choice was made in favor of dividing into parts ( first and second ). To my surprise, the second part received significantly less attention than the first - in fact, it was read by half as few people.
Time passed, and I began to notice that this happened not only with my articles, but also with many other articles in several parts. Then I had a question, but is it generally true that the second part receives less attention (views, pluses, and favorites)?

(made on the basis of a habr articleHow to lie using statistics )
Article structure
As a result, the following idea came to me: to collect pairs of articles - the first or second part and see if there is a significant difference in the main parameters between the articles. And also evaluate how these parameters change for articles in several (more than two) parts.
Data
As in the previous article, all data, code and scripts for visualization are available for download on github . You can repeat all the experiments, as well as collect and verify all the source data - using the code and examples from the previous article . First of all, this is necessary in order to ensure transparency and repeatability of experiments, as well as to provide some starting point for those who want to conduct their own research on habr-data.
Collecting article data in several parts is far from the easiest task, but we can collect enough articles using a couple of simple ideas. Let's consider all.csv dataset with a habra-articles from the last article

Great experience in reading the Habr prompted me that information about what has several parts should be looked for in the title (title in the tablet). If we go through all the headlines for the presence of the keyword part , then we can put together a good set of candidates. A simple filter.py script for preliminary filtering of articles produced an impressive, but not a huge list of candidate articles grouped by authors. Having analyzed the candidates, two series1.csv and series2.csv datasets were formed , containing the first and second parts, respectively:

Each dataset contains 180 entries.
Compare parts
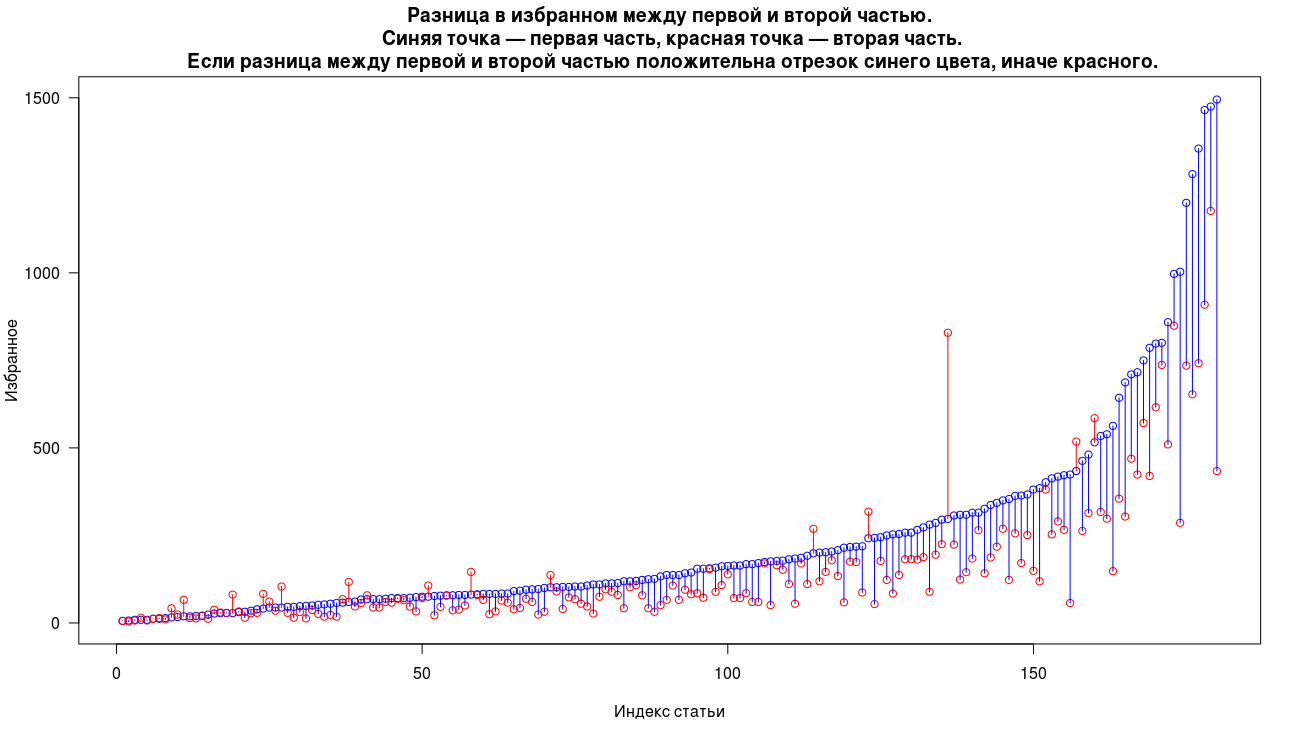
Consider the difference between the first and second parts for the following indicators: views, rating, and favorites. In each of the graphs below, a blue dot means the first part of the article, and a red dot means the second part. Two parts of the same article are displayed on the same x-coordinate. If the difference in the measurement of views, ratings or favorites is positive between the first and second parts is positive, then the segment between them is blue, and if it is negative, then red. Visually, the more blue lines we see, the more often the first part turns out to be better, according to the measured parameters. Articles on graphs are sorted by increasing the parameter of the first article.
On the first graph, we see a clear predominance of the first parts over the second by views, only in 10% of cases the second part is better than the first. But most of these cases show an insignificant difference in views, among all the records in only two cases we see a significant predominance of the second part over the first. The median number of views is about 20k for the first parts and 10k for the second.

In general, we see a similar picture for the records in favorites, only in 14% of cases the second part collects more records in favorites, there is a significant predominance in only one case. The median of the favorites is 137 for the first parts and 82 for the second.
In the case of a rating, the second parts dominate the first more often in 22% of cases. Significant predominance, as in the case of views, occurs only in two cases. Median rating for the first parts 25 and 17 for the second.
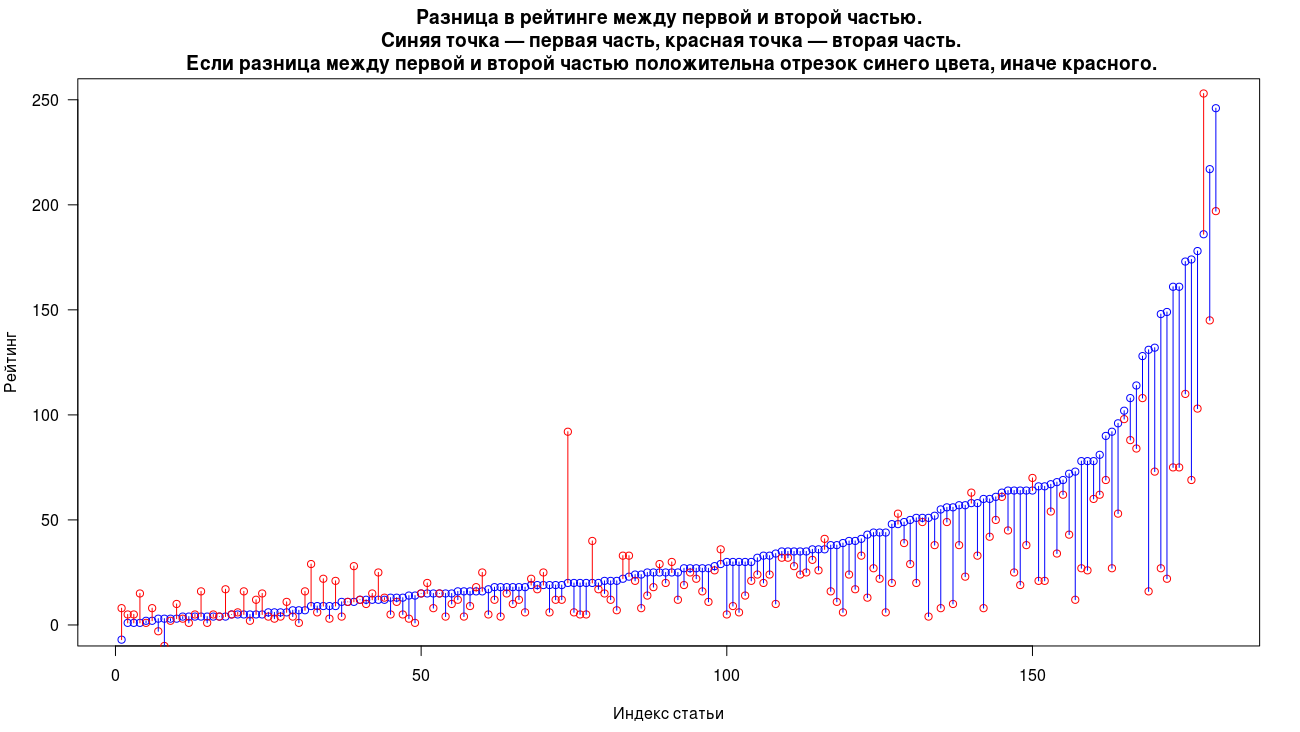
(the graphs were obtained using the difference.R script )
If anyone is interested, the significant prevalence of the second part over the first occurs in these articles:
As I wrote Pacman, and what came of it. Part 1
As I wrote Pacman, and what came of it. Part 2
and the biggest difference in performance in the article:
Part 1. Unboxing VisuMax - a femto laser for vision correction
Part 2. How many megabits / s can be passed through the optic nerve and what resolution does the retina have? Bit of theory
Series of articles
It is even more interesting to consider long chains of articles. Of the total number of candidates, chains of articles of 5 or more parts were selected - they can be found in the series_long.csv dataset .
The data has the following format:

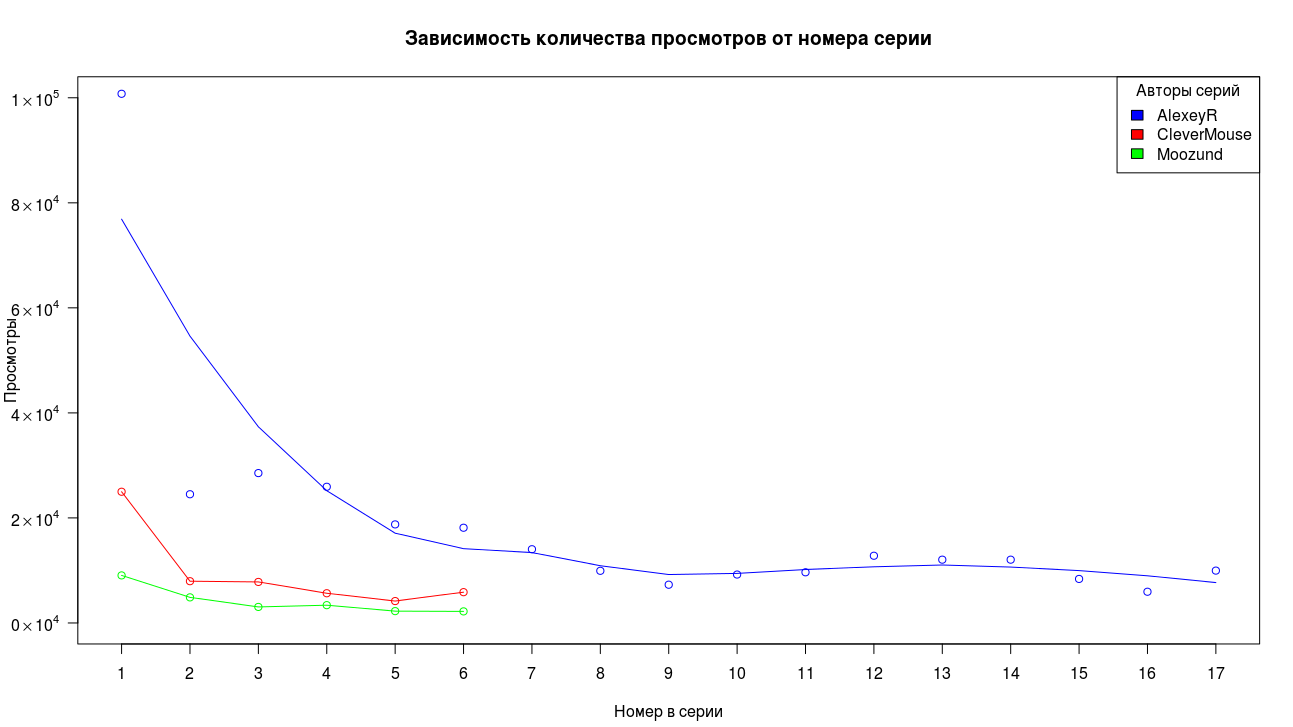
The data collected represent a very limited sample size, therefore it is difficult to draw unambiguous conclusions, but we can at least evaluate the general nature of the changes. We give as an example and motivation the three longest chains of articles for the collected period.
First of all, we see that the first part gained significantly more views than the other parts. For the second and third parts, the drop has a factor of the order of two, then the drop slows down and the views stabilize.
On the whole, we see a similar picture for the entries in the favorites, the high value of the first point, a sharp drop and stabilization of the tail.
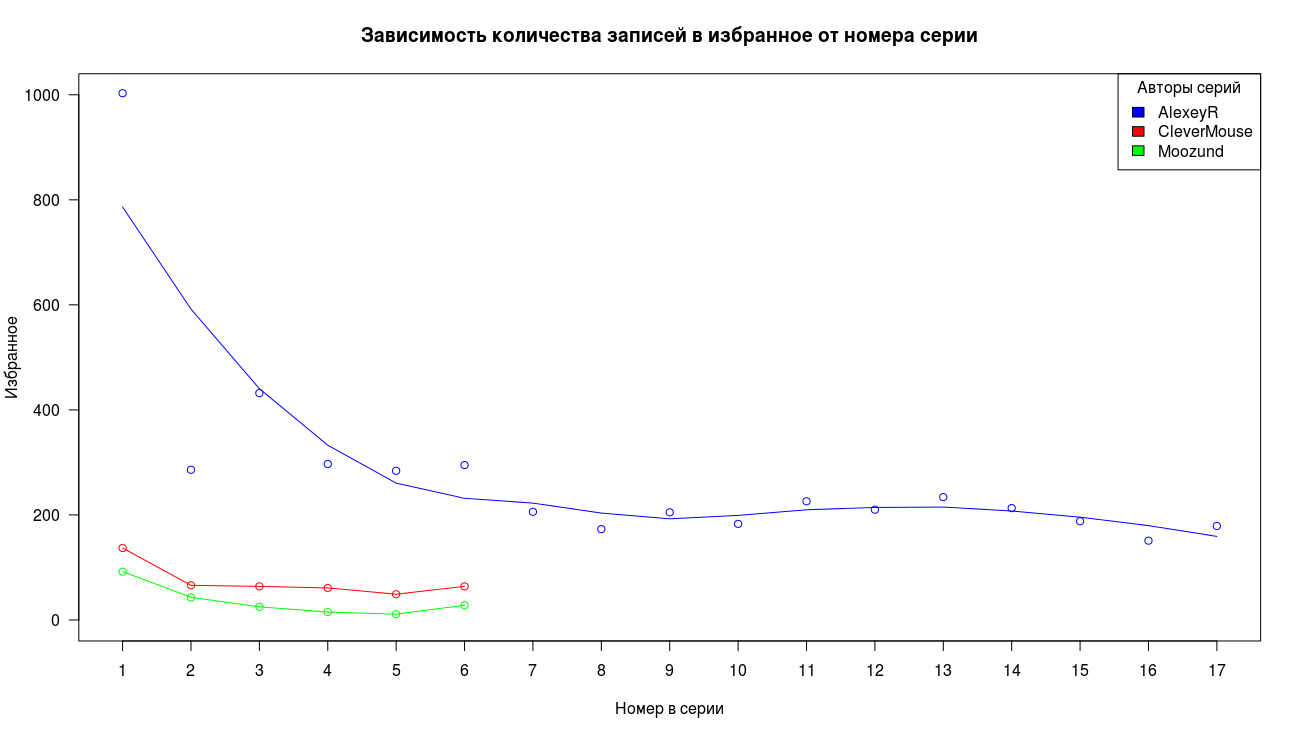
The situation with the rating differs from the two graphs discussed above, but in general the general view of the picture is preserved, except for the low initial result in the blue series.
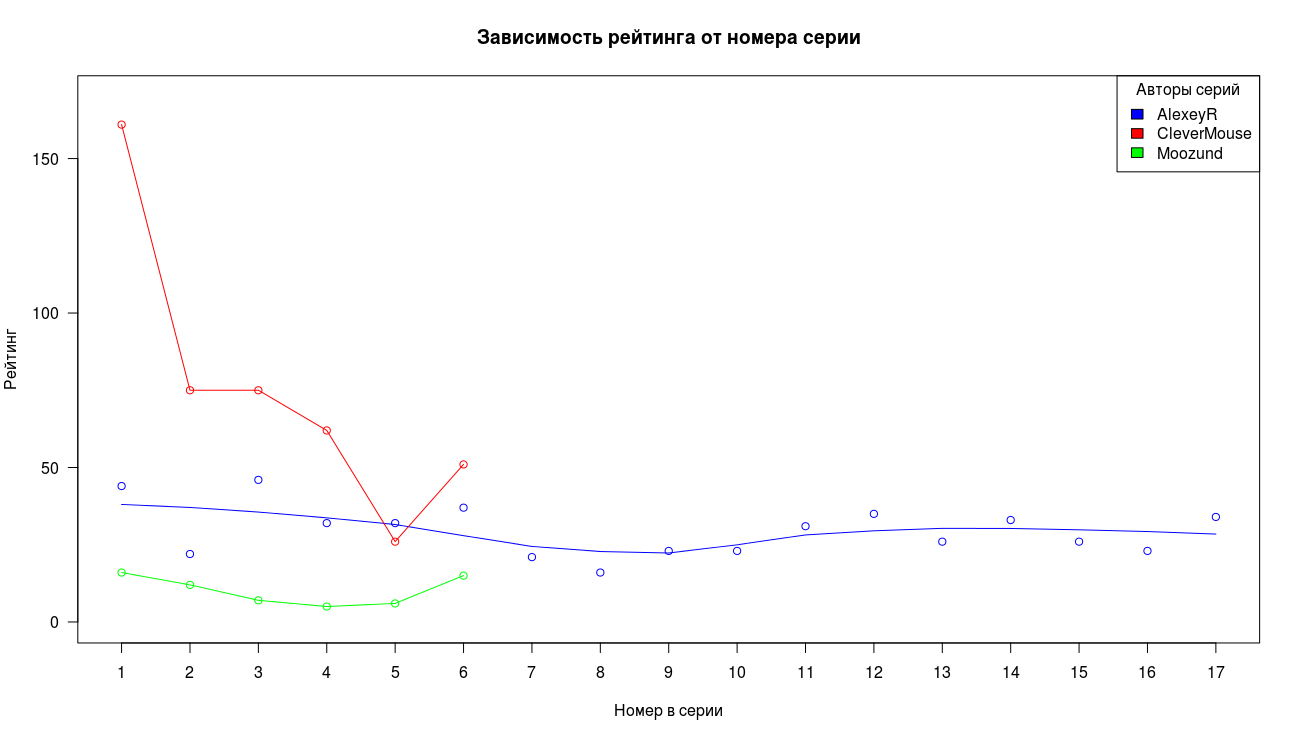
(obtained using the long_plot.R script )
Is the result so unexpected? Not really. This is approximately what was expected at the very beginning - as Zipf's classic distribution wrote in the previous article ( written in an interesting and less dry language here ). It is found quite often and it is not surprising to see it when counting the number of views of various series, for example, lecture notes:

(data taken from the youtube channel of the Stanford Programming Methodology course )
We see a similar picture when, at a high value of the parameter at the first point, a sharp drop and “stabilization” of the tail occurs. It is impossible not to note the similarity of the dependencies of views between articles on the hub and views of materials on other resources in several parts.
Conclusion
This empirical observation raises us to a number of interesting questions: is it possible that the drop in “interest” in the following parts lies in the very structure of the partition into parts? For example, to view article n , you need to see n-1 article, which significantly increases the reading time and reduces the audience. Does any specificity of articles on the hub play a role, or does this happen with all similar articles on other resources?
Of course, it is impossible to follow exclusively similar empirical observations to decide whether to divide an article into several parts or not, but this observation allows you to set some expectation standard (in the main parameters) for the following parts, based on current indicators.
Further reading
If the topic of data analysis seemed interesting, then useful material for studying
- Udacity
- Caltech - Learning from Data
- Coursera - Data Science Track
- If you live in St. Petersburg, then you can take courses at DMLabs
- If you live in Moscow, then you probably already heard about SHAD