Dagaz: Out of the Fog
 All this is Queen Mab's rogue.
All this is Queen Mab's rogue. She braids the mane stables
And knocks her hair with a prick ...
William Shakespeare
It was a long release , but a lot was done. A session-manager appeared , allowing you to roll back wrongly made moves. Somewhere where sound design was added. And also, I came up with a cool way to push several alternative options for the initial placement into one game. And most importantly - I finally got to the games with incomplete information.
I will explain what is at stake. In board games we are used to, such as Chess or Checkers , players, at any time of the game, have complete information about the location of the pieces (their own and the opponent), the rules of their movement, the goals of the game, etc. Such games are fairly well studied and belong to the category of " games with full information ." Now imagine that some of this information may be hidden from the player.
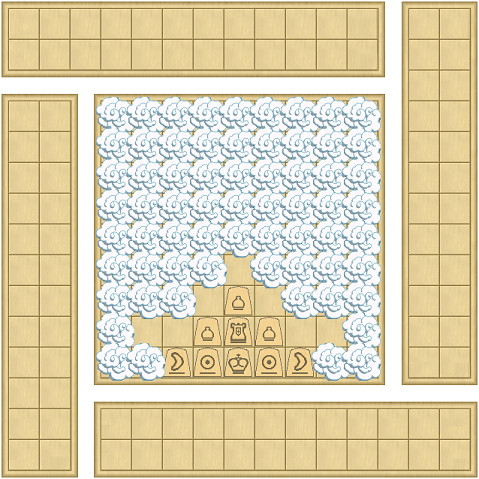
The Fog of War is a great illustration of the theme. According to the rules of " Chess in the Dark ", players can see not all the opponent's pieces, but only those that are placed on the fields, which can be reached with one move of any of their pieces. I made two additions to this rule:
- Of course, the player always sees his pieces, but according to how they are displayed - in a normal or translucent form, he can judge whether the opponent sees them.
- Solely for decorative purposes, I placed “clouds” on areas that are currently invisible.
Having mastered the general principle , I got a little carried away and made a huge number of games with the "fog of war." In addition to Chess itself , I have “dark” options for Syantsy , Changi , Shatrandzha , Sittuyin and many other games. There are even " Guns in the dark "! All these games have one thing in common:
Computer cheats!
Я даже не пытался вносить изменения в алгоритмы работы ботов для этих игр, поскольку сделал ставку на то, что неравные условия хотя бы частично компенсируют крайне слабую их игру, по сравнению с человеком. Как я уже писал ранее, разработка качественного AI для настольных игр является очень непростой задачей. Разумеется, у правил есть исключения. Даже при очень слабой игре бота, человеку будет сложно играть в незнакомую игру, буквально напичканную ловушками. Что уж говорить о её «тёмном» варианте
However, in general, this is not a very correct approach. I want to see a bot who knows how to manage exactly the data that is available to his opponent - a man. Why is it important? Everything is very simple - by the way a bot plays, sometimes it is very easy to guess whether it has access to hidden information (spies) or not. And, of course, it is much more interesting for a person to play with the bot that does not spy (it is even more interesting to play with another person, but this is another story).
And here it is worth picking up a game that is a little different from Chess (since I am not ready to engage in developing an "honest" Chess-playing bot "in the dark"). There are a lot of such games and it’s impossible to say that they are simpler than Chess or Checkers. They are just different and require an individual approach.
for example
Есть одна детская игра, с разработкой бота для которой я пока не справился. Называется она «Джунгли» или Dou Shou Qi. Цель игры — проникновение на вражескую территорию. У каждого из игроков есть «логово» — центральное поле на первой линии. Если в логово войдёт любая из фигур противника — он победил (своими фигурами занимать логово нельзя).

Фигуры упорядочены по старшинству. Слон бьёт все фигуры, далее следуют: Лев, Тигр, Леопард, Собака, Волк, Кошка и Крыса. Крыса может бить только слона и другую крысу, кроме того, это единственная фигура, способная перемещаться в воде (в середине доски расположены два водоёма). Тигр и лев могут воду перепрыгивать, но только в том случае, если путь по воде не перекрывает крыса. За исключением прыжков, все фигуры движутся одинаково — на одно соседнее поле по вертикали или горизонтали. Логово окружено ловушками. Фигура в ловушке уязвима для любой фигуры противника.
Как можно видеть, правила довольно простые. Что мешает разработать бота для этой игры? Прежде всего — тихоходность фигур. При наличии угроз, я могу оценить выгоду разменов, но большую часть игры фигуры просто бегают друг за другом на довольно протяжённые расстояния. Я не могу позволить себе просмотр партии на большое число ходов вперёд (из за ограничений на продолжительность расчёта хода), в результате чего размены выпадают за «горизонт» просмотра и все ходы становятся для меня равноценными.
Фигуры упорядочены по старшинству. Слон бьёт все фигуры, далее следуют: Лев, Тигр, Леопард, Собака, Волк, Кошка и Крыса. Крыса может бить только слона и другую крысу, кроме того, это единственная фигура, способная перемещаться в воде (в середине доски расположены два водоёма). Тигр и лев могут воду перепрыгивать, но только в том случае, если путь по воде не перекрывает крыса. За исключением прыжков, все фигуры движутся одинаково — на одно соседнее поле по вертикали или горизонтали. Логово окружено ловушками. Фигура в ловушке уязвима для любой фигуры противника.
Как можно видеть, правила довольно простые. Что мешает разработать бота для этой игры? Прежде всего — тихоходность фигур. При наличии угроз, я могу оценить выгоду разменов, но большую часть игры фигуры просто бегают друг за другом на довольно протяжённые расстояния. Я не могу позволить себе просмотр партии на большое число ходов вперёд (из за ограничений на продолжительность расчёта хода), в результате чего размены выпадают за «горизонт» просмотра и все ходы становятся для меня равноценными.
To begin with, I decided to stop at BanQi - Chinese "Blind Chess". This is a very original game with hidden information, akin to "Jungle". For me, it is important that the developments, in connection with the creation of a bot for this game, can be used in other games, such as Dou Shou Qi , Luzhan Qi , Stratego, or even (possibly) Tafl .
I'll tell you about the rules. The game takes place on the half board for "Chinese chess" ( Xiang Qi ), while the original layout of the board does not play any role. The figures are placed inside the cells (as in traditional ones), and not at the intersections of the lines (as in Chinese chess). At the beginning of the game, all the figures are thoroughly mixed and placed on the board face down (since the traditional figures of Xiangqi are sort of barrels, and their number coincides with the number of fields on the half of the board, there are no difficulties with this).
Next, the players alternate their moves. When making a move, the player can turn over any of the closed figures, or move the previously opened figure of his own color. The colors of the players are determined by the very first move. If the black piece is opened first, the player who opened it will play black. All the figures in the game go the same way (except for the “Guns” in the Taiwanese version, which I will talk about later) - on one adjacent cell vertically or horizontally. The possibility of taking is determined by the order of precedence of the figures:
General> Counselor> Elephant> Carriage> Horse> Cannon> Soldier
Senior figures beat younger or equal to them, with one exception: a soldier beats a general (a kind of " Rock-Paper-Scissors "). It remains to say a few words about the Taiwan BanQi:
- Unlike the Chinese version, in Taiwan BanQi, a general can not beat a soldier.
- The gun moves according to the rules of XiangQi , that is, to any number of fields orthogonal on a quiet course (like a chariot) or hits any opponent's piece, with a jump through the "carriage", when performing an attacking turn.
There is also a Hong Kong version, but it is practically no different from the Chinese, except that the order of the precedence of the figures has been changed. I decided to focus on the Taiwanese version of the rules, as the most interesting, in tactical terms.
What should I look for when developing a bot?
Во первых, игра выглядит очень простой, но таковой не является. Даже если не рассматривать нюансы, связанные с тайваньскими пушками, стоимость фигур контринтуитивна. Хотя «Советник» может побить меньшее количество фигур чем «Генерал», именно он является главным действующим лицом в игре. Во первых, советников у игрока два. Кроме того, каждого советника превосходит по силе всего один вражеский генерал, в то время как генерала могут атаковать целых пять солдат! По той же причине, стоимость солдата, в игре, выше стоимости генерала. В конце концов, он может побить самую сильную фигуру! Второе важное соображение подсказывает одна из «кентерберийских» головоломок Генри Дьюдени.
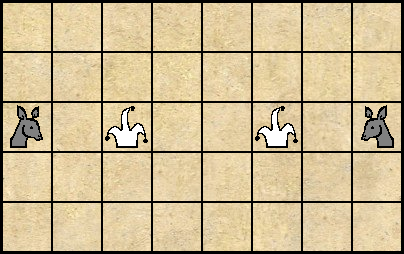
Это скорее задача-шутка, чем полноценная головоломка. Все фигуры могут ходить на одно соседнее поле по вертикали или горизонтали. Белые ходят первыми, при этом, и белые и чёрные всегда делают по два хода (разными фигурами)! В этих условиях, левый шут никогда не сможет поймать левого осла, а правый — правого (можете проверить это самостоятельно). Разумеется, правый шут может поймать левого осла без всякого труда. Всё дело в чётности!
Эта задачка натолкнула меня на некоторые мысли. Во первых, задача бота, в таких играх как BanQi или DouShouQi — это, прежде всего, поиск кратчайшего пути. От каждой из активных фигур (своей или противника) необходимо построить цепочки ходов ко всем возможным целям (в том числе и к своим фигурам, для расчёта возможных разменов). После этого, цепочки необходимо оценить и здесь возможны следующие варианты.
Разумеется, всё не так просто. Как минимум, следует помнить о специфичном ходе пушек в тайваньском BanQi (Что касается «Джунглей», то там особых случаев ещё больше), но это то, с чего можно начать. Имея полный набор оцененных цепочек, можно оценивать ходы. Стоимость хода должна складываться из стоимостей цепочек (как бонусных так и штрафных), длину которых он уменьшает.
Это скорее задача-шутка, чем полноценная головоломка. Все фигуры могут ходить на одно соседнее поле по вертикали или горизонтали. Белые ходят первыми, при этом, и белые и чёрные всегда делают по два хода (разными фигурами)! В этих условиях, левый шут никогда не сможет поймать левого осла, а правый — правого (можете проверить это самостоятельно). Разумеется, правый шут может поймать левого осла без всякого труда. Всё дело в чётности!
Эта задачка натолкнула меня на некоторые мысли. Во первых, задача бота, в таких играх как BanQi или DouShouQi — это, прежде всего, поиск кратчайшего пути. От каждой из активных фигур (своей или противника) необходимо построить цепочки ходов ко всем возможным целям (в том числе и к своим фигурам, для расчёта возможных разменов). После этого, цепочки необходимо оценить и здесь возможны следующие варианты.
- Атакующая фигура бьёт атакуемую — выгодная (бонусная) цепочка оцениваемая стоимостью атакуемой фигуры (за вычетом стоимости атакующей, если последняя находится под защитой), с учётом длины цепочки.
- Атакующая фигура бьётся атакуемой — не выгодная (штрафная) цепочка, оцениваемая стоимостью атакующей фигуры.
- Фигуры бьют друг друга (например равны) — здесь всё зависит от чётности, выгодны нечётные цепочки, а чётные должны рассматриваться как штрафные (если бы других фигур на поле не было, чётность полностью определяла бы итог игры).
Разумеется, всё не так просто. Как минимум, следует помнить о специфичном ходе пушек в тайваньском BanQi (Что касается «Джунглей», то там особых случаев ещё больше), но это то, с чего можно начать. Имея полный набор оцененных цепочек, можно оценивать ходы. Стоимость хода должна складываться из стоимостей цепочек (как бонусных так и штрафных), длину которых он уменьшает.
First of all, it is important to understand that effectively using minimax algorithms is unlikely to succeed here. Moves that reveal previously hidden pieces, too radically change the assessment of the position. Without information about hidden pieces, it is almost impossible to view a position for many moves ahead. But every cloud has a silver lining, but we can use much more complex (computationally) heuristics to evaluate the moves themselves!
I already have a bot evaluating moves based on their heuristics (needed for one funny game). This is a very simple algorithm. All moves are sorted in descending order of heuristics (moves with a negative value of heuristics are generally discarded), after which they are reviewed in order. If the next move leads to the position from which there is no response of the enemy, leading to immediate victory, the bot considers it the best. Using this algorithm, you can not bother with the assessment of the position, but you will have to sweat on heuristics .
First of all, we build chains
var getChains = function(design, board) {
var player = board.getValue(board.player);
if (player === null) return [];
if (_.isUndefined(board.chains)) {
board.chains = [];
var pieces = getGoals(design, board);
var targets = getTargets(design, board, pieces);
_.each(pieces.positions, function(pos) {
var goals = pieces; var f = true;
var piece = board.getPiece(pos);
if (piece === null) return;
if (!chinese && (piece.type == 12)) {
goals = targets;
f = false;
}
var group = [ pos ];
var level = [];
level[pos] = 0;
for (var i = 0; i < group.length; i++) {
if (_.indexOf(goals.positions, group[i]) >= 0) {
// Строим цепочку...
}
if ((i > 0) && (board.getPiece(group[i]) !== null)) continue;
_.each(design.allDirections(), function(dir) {
p = design.navigate(board.player, group[i], dir);
while (p !== null) {
if (_.indexOf(group, p) >= 0) break;
group.push(p);
level[p] = level[ group[i] ] + 1;
if (f || (board.getPiece(p) !== null)) break;
p = design.navigate(board.player, p, dir);
}
});
}
});
}
return board.chains;
}
Of course, I cache all the intermediate data in the game state, so as not to count them several times. In addition, one trick is used here, which is very useful in calculating connected areas. I iterate through the group array , enclosing additional elements inside the loop as necessary. All difficulties are associated with guns. For them, the targets of the chains are not the figures themselves, but the fields from which the latter can be attacked.
Chains are evaluated exactly as I said
var getChainPrice = function(design, board, attacker, attacking, len) {
var player = board.getValue(board.player);
if ((player === null) || (attacker == null) || (attacking === null)) return0;
if (attacker.player == attacking.player) return0;
var isAttacking = isAttacker(design, attacker.type, attacking.type);
var isAttacked = isAttacker(design, attacking.type, attacker.type);
if (!chinese && (attacker.type == 12)) {
isAttacking = true;
isAttacked = (attacking.type == attacker.type) && (len == 1);
}
var price = 0;
var f = (len % 2 == 0);
if (attacker.player != player) f = !f;
if (isAttacking) {
if (isAttacked) {
price = f ? (len - design.price[attacker.type]) : (design.price[attacking.type] - len);
} else {
price = design.price[attacking.type] - len;
if (f) price = (price / 2) | 0;
}
} else {
if (isAttacked) {
price = len - design.price[attacker.type];
}
}
return price;
}
... depending on the length and parity of the chain, as well as the cost of attacking and attacking figures. But this is only half the battle! It is necessary to evaluate each of the possible moves using the constructed chains. I am introducing another intermediate structure - wishes to aggregate existing data. Assessment of the course consists of assessments of wishes, which it satisfies:
Something like that
var addWish = function(board, comment, price, src, dst) {
if (_.isUndefined(board.wish[src])) {
board.wish[src] = [];
}
if (_.isUndefined(dst)) dst = src;
if (_.isUndefined(board.wish[src][dst])) {
board.wish[src][dst] = price;
} else {
board.wish[src][dst] += price;
}
}
var getWish = function(design, board) {
if (_.isUndefined(board.wish)) {
...
}
return board.wish;
}
Dagaz.AI.heuristic = function(ai, design, board, move) {
var wish = getWish(design, board);
if (move.isSimpleMove() &&
!_.isUndefined(wish[ move.actions[0][0][0] ]) &&
!_.isUndefined(wish[ move.actions[0][0][0] ][ move.actions[0][1][0] ])) {
return wish[ move.actions[0][0][0] ][ move.actions[0][1][0] ];
}
return0;
}
As for the getWish function itself , magic begins here (and this is the place where I most likely plowed and more than once). First of all, I share the assessment of moves based on open information and the introduction of new pieces into the game. This is not entirely correct, but so far I just don’t know how to reconcile such diverse assessments. If, based on open information, no wishes were formed, the bot tries to discover new figures (there are also some tricks here).
- If an enemy cannon is open, surrounded by closed figures, it makes sense to open one of the figures next to it, since it is likely that it will be able to attack the cannon, and the cannon will not be able to beat it in any case.
- If the figure is different from the cannon, you can try to open the figure located through the "carriage" from it, because there is a chance that it will be a gun.
- In the presence of an attacking chain from the side of the enemy, you can open one of the figures, next to the chain, to intercept the attack.
- If you cannot protect the figure, you can open the figure next to it, trying to reduce the situation to exchange.
Of course, the probability of opening a particular figure is useful to evaluate
var getShadow = function(design, board) {
var player = board.getValue(board.player);
if (player === null) return [];
if (_.isUndefined(board.shadow)) {
board.shadow = [];
_.each(design.allPositions(), function(pos) {
var piece = board.getPiece(pos);
if ((piece !== null) && (piece.type < 7)) {
var value = piece.type + 7;
if (piece.player != player) {
value = -value;
}
board.shadow.push(value);
}
});
}
return board.shadow;
}
var isFriend = function(design, x) {
return x > 0;
}
var isPiece = function(design, x, y) {
return x == y;
}
var isAttacker = function(design, x, enemy) {
if (x < 0) returnfalse;
if ((x == 13) && (enemy == 7)) returntrue;
if (!chinese && (x == 7) && (enemy == 13)) returnfalse;
if (!chinese && (x == 12)) returnfalse;
return x <= enemy;
}
var isDefender = function(design, x, enemy, friend) {
if (!isAttacker(design, x, enemy)) returnfalse;
return design.price[friend] <= design.price[enemy];
}
var estimate = function(design, board, p, y, z) {
var shadow = getShadow(design, board);
if (shadow.length == 0) return0;
var r = 0;
_.each(shadow, function(x) {
if (p(design, x, y, z)) r++;
});
return (100 * r) / shadow.length;
}
The player can estimate the probabilities, keeping track of the figures who left the game. In principle, the same thing can do, and the boat, but there is an easier way - to view all the undiscovered pieces en masse and on the basis of the information collected to assess the probability of the desired opening. At the same time, the success of the chosen move is not guaranteed, but if the probability of a favorable outcome is low, the move will not be chosen at all.
In principle, the approach justified itself, but there is still a lot of work to be done.
Пока не очень хорошо получаются защитные ходы. Некоторые фигуры отважно идут навстречу более сильному врагу, вместо того чтобы от него убегать (хотя убегать в их случае, как правило, уже бесполезно). Также, есть сложности с координацией действий различных фигур (это может быть полезно, для того чтобы «загнать» остатки фигур противника). Сам подход выглядит очень перспективным, но над эвристиками ещё предстоит подумать.
Эвристики на основе «цепочек» ходов могут быть полезны не только в BanQi, но и во многих других играх, с преобладанием «тихоходных» фигур (если и не в качестве определяющего критерия, то для предварительной оценки качества ходов в более сложных алгоритмах, по крайней мере). Особенно востребован этот подход в тех играх, для которых применение минимаксных алгоритмов затруднено или вообще невозможно (таких как Yonin Shogi, например).
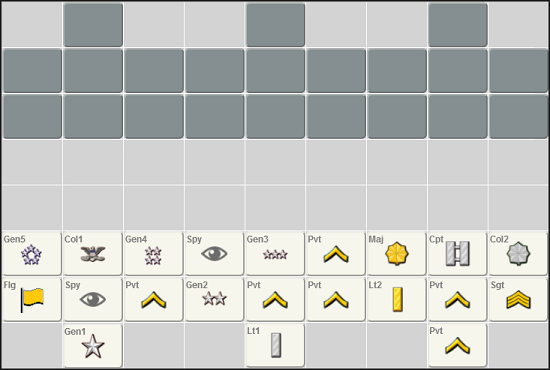
Разумеется, я собираюсь продолжить работу над играми с неполной информацией. На рисунке изображена филиппинская "Игра генералов", пока ещё не готовая. Это самая простая игра из большого семейства, включающего в себя такие игры как LuzhanQi и Stratego. И конечно, я всё ещё рассчитываю сделать работающего бота для "Джунглей"!
Эвристики на основе «цепочек» ходов могут быть полезны не только в BanQi, но и во многих других играх, с преобладанием «тихоходных» фигур (если и не в качестве определяющего критерия, то для предварительной оценки качества ходов в более сложных алгоритмах, по крайней мере). Особенно востребован этот подход в тех играх, для которых применение минимаксных алгоритмов затруднено или вообще невозможно (таких как Yonin Shogi, например).
Разумеется, я собираюсь продолжить работу над играми с неполной информацией. На рисунке изображена филиппинская "Игра генералов", пока ещё не готовая. Это самая простая игра из большого семейства, включающего в себя такие игры как LuzhanQi и Stratego. И конечно, я всё ещё рассчитываю сделать работающего бота для "Джунглей"!
And for those who are still reading me, I can offer another funny puzzle game with hidden information:

I played it in my childhood, on a programmable calculator, called Fox Hunting. On the field, 8 foxes are randomly hidden, which must be found using the "spear method." When you select an empty area, the total number of foxes in all eight directions is displayed. It is impossible to lose, but you can compete for the minimum number of clicks. And if you play in headphones, turn down the sound. Maybe I overdid it with sound effects.