Messaging between threads. Classic blocking algorithms
 Once I got out of the sandbox with a scoop in my hand and a post about non-blocking queues and data transfer between threads. That post was not so much about algorithms and their implementation, but about measuring performance. Then in the comments I was asked a perfectly reasonable question about conventional, blocking transmission algorithms - how much slower they are and how to choose the optimal algorithm for a specific task in general.
Once I got out of the sandbox with a scoop in my hand and a post about non-blocking queues and data transfer between threads. That post was not so much about algorithms and their implementation, but about measuring performance. Then in the comments I was asked a perfectly reasonable question about conventional, blocking transmission algorithms - how much slower they are and how to choose the optimal algorithm for a specific task in general.Of course, I promised and enthusiastically got down to business, I even got funny results, however ... there wasn’t any highlight, it turned out boring and flat. As a result, my inner perfectionist teamed up with my undisguised procrastinator and both of them defeated me, the post settled for a long time in drafts and even my conscience did not tremble at the sight of a forgotten headline.
However, everything changes, new technologies appear, old ones disappear in the archives, and I suddenly decided that it was time to repay debts and keep promises. As a punishment, I had to rewrite everything from scratch, if the avaricious pays twice, then the lazy person remakes twice, so I need to.
Yes, I apologize for the KDPV - it is of course from a completely different subject area, but nevertheless fits perfectly to illustrate the interaction between the flows.
So what woke Herzen?
Introducing me to action acquaintance with
language D
- an extremely conceptually beautiful language that inherited and powerfully moved forward the C ++ idioms and at the same time retained effective low-level tools, up to and including pointers. Perhaps because of this, in my opinion, the standard library D has some dichotomy - most of the functionality can be called either from the box, in a simple and easy way, or through an interface that is close to the native interface, but fully using the resources and capabilities of the system. If C ++ covers the entire range with a continuous spectrum, then in D this division is usually clearly visible. See for yourself: you need to measure the time interval, there is a wonderful module std.datetime , however, the measurement quantum is 100 ns, which is absolutely not enough for me, please - there is no less wonderful module - core.time. Not satisfied with the lightweight Java-like std.concurrency.spawn - you can use the whole bouquet from core.thread. And so almost everywhere, with the exception of one, but extremely important place - the separation of data between streams. Yes, yes, all local variables for a given thread are placed in thread local storage and no forces can force another thread to see their address. And for the exchange of data, built-in queues are provided, it must be recognized very convenient - polymorphic, with the possibility of extraordinary sending of important messages and an extremely pleasant interface. It is possible to send data through them naturally either by value, or immutable links. When I read about this for the first time, I simply jumped out of indignation - “How did your filthy hand go up ...” - and then I thought about it, recalled my projects in recent years and admitted - yes, the whole exchange between flows takes place according to this scheme , but what does not pass is a clear design error.no need to continue the analogy, I did not mean to say that he is terribly far from the people
Nevertheless, the question hangs in the air - how effective are the lines in D? If not, it negates all the other effectiveness of the language, a kind of built-in bottleneck. So I woke up and took up the measurements again.
What exactly will we measure?
The question is actually not simple, I wrote about it the last time and perhaps I will repeat it. The usual "naive" approach, when they send N messages, measure the total time and divide by N does not work . Let's see, we measure queue performance , right? Therefore, we can assume that during the measurement process the speed of the message generator and message receiver tends to infinity , with a reasonable assumption that the data is not copied inside the queue , it turns out to be beneficial to place as much data as possible in the queue, then perform a single transmission of some internal pointer and that’s all, the data is already there . Whereinthe average time per message will fall as 1 / N (actually limited from below by the insert / delete time, which can be a few nanoseconds), while the delivery time of each message in theory remains constant, and even grows as O (N) in practice.
Instead, I use the opposite approach - each message is sent, time is measured, and only then is the next one sent ( latency ). As a result, the results are presented in the form of histograms, along the X axis - time, along the Y axis - the number of packets delivered during this time. Two parameters are most interesting numerically - the median average distribution time and the percentage of messages that did not fit into some (arbitrary) upper limit.
Strictly speaking, this approach is also not quite adequate, however, it describes the performance requirements much more accurately. I will do a little self-criticism in conclusion, until I just say that the full description would include generating all possible types of traffic and analyzing it with statistical methods, I would get a full-fledged scientific work from the field of QA theory, or I would sooner catch another attack of procrastination.
Another point, I mention this because the last time there was a long debate, the message generator can insert them into the queue arbitrarily quickly, but provided that the recipient is on averagemanages to extract and process them, otherwise the whole dimension is simply meaningless. If your receiving stream does not manage to process the data stream, you need to make the code faster, parallelize the processing, change the message protocol, but in any case, the queue itself has nothing to do with it. It seems to be a simple idea, but the last time had to be repeated several times in the comments. Speed fluctuations, when suddenly there are a lot of messages in the queue, are quite possible and even inevitable, this is just one of the factors that a well-designed algorithm should smooth out, but this is only possible if the maximum receive speed is greater than the average sending speed.
Start with
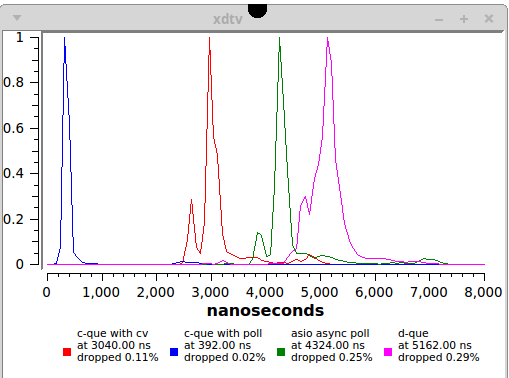
What's this? And this is actually the result, all my works fit into one picture, but now I will explain for a long time what and why is painted here.
Pink. Standard gear D
5 microseconds, is it a lot or a little? In almost all cases, this is small (that is, it is very good). For the vast majority of real projects, this is more than enough speed, moreover, not so long ago such a transmission time could only be obtained using special hardware and / or very special software. Here we have a tool from the standard library, with many other tasty buns and fast enough for all practical needs. The rating is excellent. But however it’s not great, because this implementation has some disadvantages that are not related to speed, I will talk about it in the abusive part.
Once again, we are pleased to see that the main magic of programming is in the absence of any magic. If you crawl under the hood (of course, I couldn't help but peek), we will see that the code is completely ordinary - simply connected lists protected by mutexes. I won’t even bring him here because in the sense of implementing the line, he will not tell us anything new. But those few who really need faster algorithms, including non-blocking ones, can easily write their own version by removing all the convenient but slow-down buns. But I will give my code just to show how much D is nevertheless laconic and expressive language.
code for illustration
import std.stdio, std.concurrency, std.datetime, core.thread;
void main()
{
immutable int N=1000000;
auto tid=spawn(&f, N);
foreach(i; 0..N) {
tid.send(thisTid, MonoTime.currTime.ticks);
// wait for receiver to handle message
receiveOnly!int();
}
}
void f(int n)
{
foreach(i; 0..n) {
auto m=receiveOnly!(Tid,long)();
writeln(MonoTime.currTime.ticks-m[1]);
// ask for the next message
m[0].send(0);
}
}
Blue. Fierce and undisguised C ++.
400 nanoseconds! Bingo! Side by side, all non-blocking and other tricky algorithms! Or is it still not?
No, of course, this is a gross provocation, the fact is that in this version the reading stream never falls asleep, continues to continuously check the queue for incoming messages in a loop. This option works while your CPU simply has nothing more to do, as soon as competing processes appear, especially if they are equally careless about shared resources, everything starts to slip unpredictably. Yes, there is the option of forcing one of the cores to serve this thread, but architecturally this is very baddecision, I will come back to this later. There are places where it is justified or even necessary, but if you work in such a place, you probably already know everything yourself, this post is completely superfluous for you.
However, we received important information - on modern systems, the speed of transactions is not determined at all by the speed of mutexes or copying data, the main factor is wake up time for a stream after a forced or voluntary pause. Hence the moral - if you do not want or cannot afford a dedicated CPU to process messages from the queue, think twice before using fast and complex but inconvenient to use solutions, the loss of adjusting the application architecture for them will almost completely outweigh the slight gain that brings the algorithm itself during the transaction. And yes, here I mean
boost :: lockfree
this is an exemplary implementation of a non-blocking queue, but the message type must have a trivial destructor and assignment operator , the condition is so cruel for C ++ that I actually never brought the code to the final product.
So what can be done by staying within reason?
Red. Reasonable and balanced C ++.
If usleep () and others like it came to someone’s mind - forget, you are guaranteed to increase the response time to at least 40 microseconds, this is the best that the modern kernel can guarantee. Yield () is slightly better , although it works pretty well on small loads, it tends to share CPU time with anyone.
This is all because of the cats, of course
There is only one way out and it is obvious - use std :: condition_variable , since the mutexes for synchronization are already used and the changes in the code will be minimal. In this embodiment, the recipient falls asleep on the variable if the queue is empty, and the message generator sends a signal if it suspects that the partner may be sleeping. In this case, the kernel has all the possibilities for optimization and we get the result, 3 microseconds. It’s already possible to say that wow, we are literally on the heels of all sorts of tricky implementations, while the basic code is extremely simple and can be adapted for all occasions. Of course, no polymorphism here slept as in D, but it turned out almost twice as fast. No kidding, this is a very real competitor to non-blocking algorithms.Experience shows that on every server there is at least one process drawing cats at the moment, and it will not give the CPU to anyone until all the cats on the Internet are carefully drawn and clicked.
Green. Scalability, scalability.
And this is an architectural solution that I searched and hatched for a long time, although the result looks extremely simple. People often ask how many messages per second can be sent through a queue and the like, forgetting that the opposite situation happens no less often - let us have a certain number of threads that go about their business and from time to time should send messages, not too often, but important. We don’t want to hang a separate listener for each such thread, who will still sleep for the most part, so we will have to create one common processing center that will poll all queues and serve messages as they arrive. But since today is not an evening of long code, but an evening of short conceptual fragments, I suggest using boost :: asio, as a huge bonus, the same stream can also serve sockets and timers. Here, by the way, one could easily dispense with the queue altogether, capturing data directly in the transferred function, the queue serves more as an aggregator and buffer for data, and also for a semantic link with previous examples.
And what do we get? 4.3 microseconds on a process from only one generator, not bad at all. Keep in mind that the result will inevitably worsen in a system where many threads write messages at the same time, but scalability is practically unlimited and it costs a lot.
Once again I want to emphasize the philosophical meaning of this fragment - we are sending to another stream not just data, but data plus a functor who knows how to work with them, something like cross-threading virtuality. This is such a general concept that it could probably claim the title of a separate design pattern.
This ends the experimental part, if you need the code for all the tests, then here it is . Caution, this is not a ready-made library, so I do not advise you to mindlessly copy, but it can serve as a very useful tutorial for developing your code. Additions and improvements are welcome.
Different reasoning, in the case and not very.
Why do I need message queues? As Example D teaches us, this is the most kosher pattern for designing multi-threaded systems, for which the future means the future and the queues too. But are all the queues the same? What are the options and what are the differences? We’ll talk about this.
First, you need to distinguish between data streams and message streams.. With data streams, everything is relatively simple, each transmitted fragment does not carry a meaning and the boundaries between the fragments are quite arbitrary. The costs of copying are comparable or exceed the resources consumed by the queue itself and the recipe in this case is extremely simple - increase the internal buffer as much as possible, you will get incredible speed. A data quantum, a large file, for example, can be considered a single message, so large that it technically cannot be transmitted at a time. Well, that’s all, there’s probably nothing more to say about it. But in the message flow, each subsequent fragment carries a complete chunk of information and should cause an immediate reaction, we are talking about them today.
It is still useful to analyze the architecture in terms of connectivitythat connects with what. The simplest type is the “pipe”, which connects two streams, a writer and a reader, its main purpose is to provide a decoupling of the input and output streams, ideally, none of them should know about the problems of the other. The second atomic type of queue is a “funnel”, where an arbitrary number of threads can write, but only one reads it. This is probably the most popular case, the simplest example is a logger. And actually that's all, the opposite case, when one thread writes and reads several, is implemented using a bunch of “pipes” and therefore is not atomic, and if you suddenly needed a queue where anyone can write and anyone can read from it, then I I would strongly advise you to reconsider your attitude to life in general and to the design of multi-threaded systems in particular.
Returning to the decoupling of the input and output flows, this inevitably leads to the conclusion that the ideal queue should be dimensionless , that is, if necessary, contain infinitely manymessages. A simple example: let an extremely important and responsible stream want to write a short message to the log and return to its extremely important matters. However, the log we have built on the basis of a queue with a fixed-size buffer, and now someone just threw it "War and Peace" in full. What to do? Blocking the calling thread with such a low priority task as a logger should not, returning an error or an exception is extremely undesirable from an architectural point of view (we shift the responsibility to the calling function, we oblige it to monitor all possible outcomes, we extremely complicate the calling code and the probability of an error, but instead we get nothing - what to do is still not clear). And in general, what was all this talk about non-blocking queues for, if it’s lying right here before our eyes ?.
Fortunately, RAM is now one of the cheapest resources, so the adaptive strategy will probably be the most optimal among universal ones - memory is allocated from the heap if necessary (in large pieces
Well, the last one is the statistical nature of traffic. I already spoke about the difference between data transfer and message transfer, but messages can also have a different time distribution. Oddly enough, the easiest case is if the data arrives as quickly as possible (but not faster than we manage to remove it from the queue), but at the same time evenly. At the same time, various accelerators work as efficiently as possible, from spinlocks to tools built into the system. More complicated is the case when powerful spikes occur in the message flow that are guaranteed to exceed processing speed. In this mode, the queue should efficiently accumulate incoming messages, allocating memory if necessary and not allowing significant slowdown.
This is where I cheated
However, the most difficult mode is possible - when messages arrive very rarely, but require an immediate response. During this time, anything can happen, including falling into a swap. If in the normal distribution of intervals such events rarely occur and fall into those fractions of a percent that we rejected in the tests, then in this case the efficiency can drop by orders of magnitude.in tests, messages are sent strictly one at a time and I did not investigate the behavior of D queues when locking on records, or the behavior of C queues, if necessary, to allocate memory. I have not yet studied the mutual influence and the struggle for the resources of several threads, especially when there are more of them than physical CPUs. In terms of volume, it is easily drawn to a separate post.
An incomplete list of rakes in stock.
- Keep a balance of writing and reading : if the reading stream fails, no algorithm will save you. Do what you want to speed it up, only do not blame the line.
- Cumulative slowdown : it happens that for some implementations the queue speed depends on the number of messages in it, then a random burst of activity can slow down the queue so much that it does not free until the next burst, approximately like a traffic jam. Such instability is rather difficult to model during testing.
- Night watchman syndrome : sometimes messages come very rarely, once an hour or even once a day, from the point of view of the OS it’s always an eternity. If a watchman at a post sits and waits for an alarm, but there has never been a signal in his entire life, what will he do at a critical moment? It is difficult to fight such spontaneous falling asleep.
- Consider the tail of the distribution : in the above tests, 2-3 messages per 1000 were processed anomalously for a long time, this is a common feature for all general-purpose operating systems. If you suddenly need to lower this number, you will have to work hard.
- Do not rely on dedicated CPUs : this is a powerful accelerating factor, but absolutely not scalable. Unlike memory, a CPU is an expensive resource. Even if your system has 100500 cores, there are certainly 100500 + 1 developers who want one thingfor personal use.The same PM, which a year ago itself proposed to reserve a core for speeding up queues, will now look into the soul with honest blue eyes and say, “The guys from the front-end came to me, the company logo is redrawn on their main page on the main page. They ask you to give them one of the cores, you understand - this is serious and everyone can see, even the customer recently paid attention. And your server already seems to be working, and nobody sees it anyway. ” If this happens, I recommend taking a deep breath and slowly counting to ten, otherwise destruction and sacrifice are inevitable.
- there is much more : but I forgot what exactly
It is customary to end on an optimistic note: for multithreading, it is not that the future, but rather the present. And for the powerful, flexible and universal messaging mechanisms - the future, but they have not yet been clearly written, apparently waiting for us.
All success.