Optimization of work with prototypes in JavaScript engines
- Transfer
The material, the translation of which we are publishing today, was prepared by Matthias Beinens and Benedict Meirer. They are working on the V8 JS engine at Google. This article is devoted to some basic mechanisms that are typical not only for the V8, but also for other engines. Familiarity with the internal structure of such mechanisms allows those who are engaged in JavaScript development to better navigate in terms of code performance. In particular, here we will talk about the features of the engine optimization pipeline, and how to accelerate access to the properties of prototypes of objects.

The process of converting the texts of programs written in JavaScript into suitable for execution code looks approximately the same in different engines.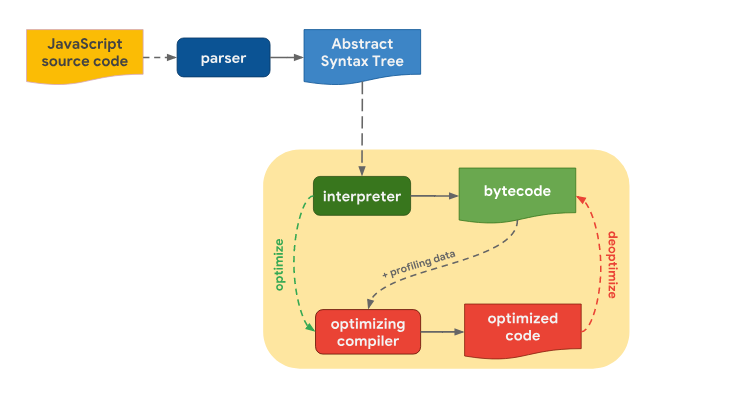 The process of converting the original JS code into executable code
The process of converting the original JS code into executable code
You can see more details here . In addition, it should be noted that although, at a high level, the pipelines for converting source code into executable are very similar for different engines, their code optimization systems often differ. Why is this so? Why do some engines have more optimization levels than others? It turns out that engines have to compromise one way or another, which is that they can either quickly generate a code that is not the most effective, but suitable for execution, or spend more time to create such code, but due to this, achieve optimal performance.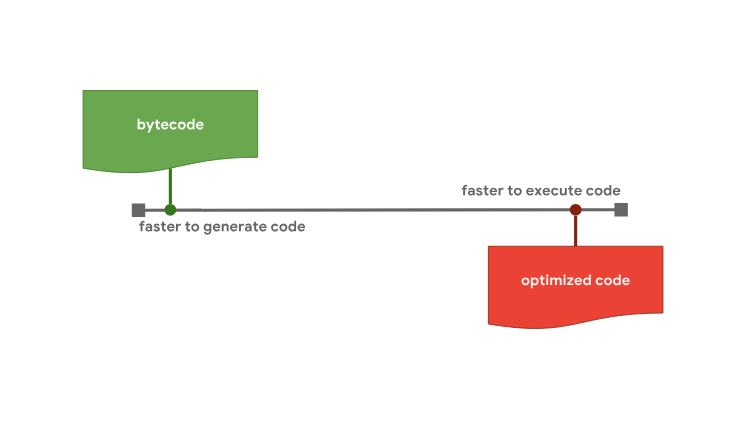 Fast preparation of code for execution and optimized code that prepares longer, but runs faster The
Fast preparation of code for execution and optimized code that prepares longer, but runs faster The
interpreter is able to quickly generate byte-code, but such code is usually not very effective. An optimizing compiler, on the other hand, takes more time to generate code, but in the end it produces an optimized, faster machine code.
This model of code preparation for execution is used in V8. The V8 interpreter is called Ignition, it is the fastest of the existing interpreters (in terms of the execution of the original bytecode). The optimizing V8 compiler is called TurboFan, it is responsible for creating highly optimized machine code.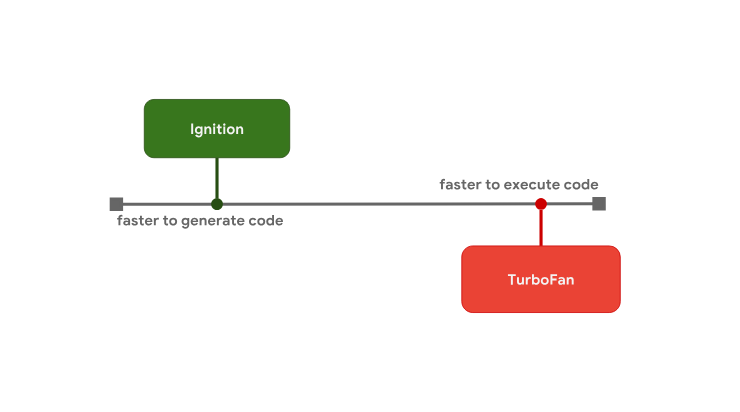 The Ignition interpreter and TurboFan optimizing compiler. The
The Ignition interpreter and TurboFan optimizing compiler. The
compromise between program launch delay and execution speed is the reason for some JS engines to have additional optimization levels. For example, in SpiderMonkey, between the interpreter and the optimizing IonMonkey compiler, there is an intermediate level represented by the basic compiler (itis called “The Baseline Compiler”in theMozilla documentation , but “baseline” is not a proper name).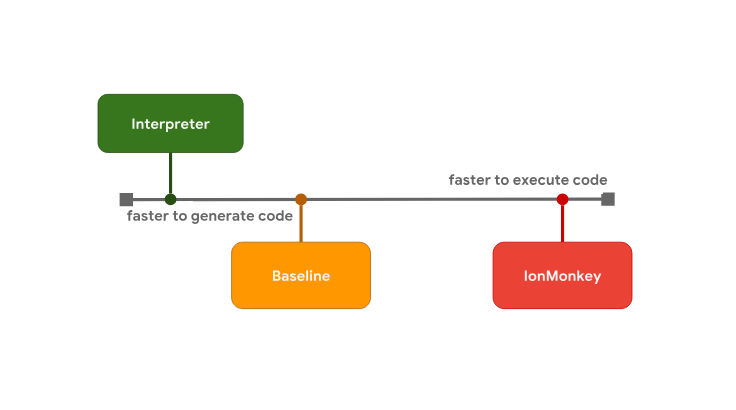 SpiderMonkey code optimization levels
SpiderMonkey code optimization levels
Interpreter quickly generates bytecode, but such code runs relatively slowly. The base compiler takes more time to generate code, but this code is already running faster. Finally, the IonMonkey optimizing compiler takes the most time to create machine code, but this code can be executed very efficiently.
Take a look at a specific example and look at how the conveyors of various engines handle the code. In the example presented here, there is a “hot” loop containing code that is repeated many times.
V8 starts to perform bytecode in the interpreter Ignition. At some point in time, the engine finds out that the code is “hot” and starts the TurboFan frontend, which is part of TurboFan, which works with profiling data and creates a basic machine code representation. The data is then passed to the TurboFan optimizer, running in a separate thread, for further improvements.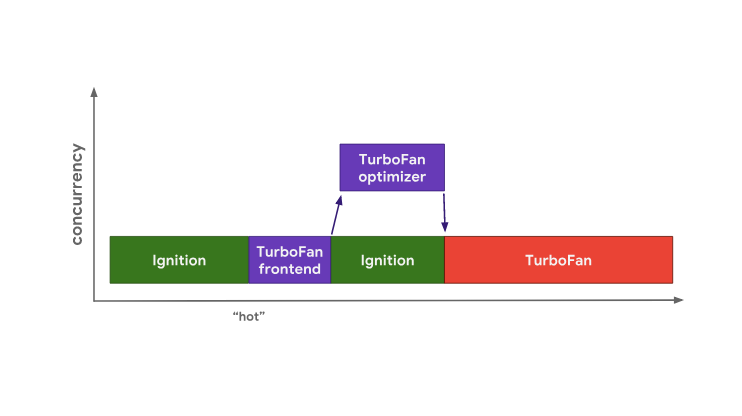 Optimizing Hot Code in V8
Optimizing Hot Code in V8
During optimization, V8 continues to execute byte code in Ignition. When the optimizer finishes, we have executable machine code that can be used later.
The SpiderMonkey engine also starts to execute bytecode in the interpreter. But it has an additional level provided by the base compiler, which leads to the fact that the “hot” code first gets to this compiler. It generates the base code in the main thread, the transition to the execution of this code is made when it is ready.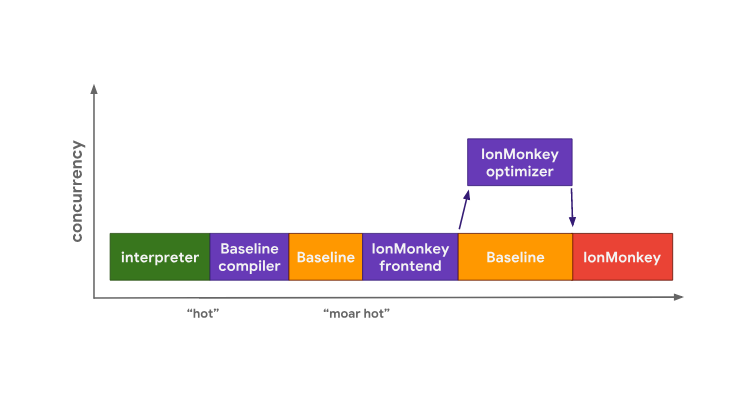 Optimizing Hot Code in SpiderMonkey
Optimizing Hot Code in SpiderMonkey
If the base code runs long enough, SpiderMonkey eventually launches the IonMonkey frontend and optimizer, which is very similar to what happens in V8. The base code continues to run as part of the code optimization process performed by IonMonkey. As a result, when the optimization is complete, the optimized code is executed instead of the base code.
The architecture of the Chakra engine is very similar to the SpiderMonkey architecture, but Chakra tends to a higher level of parallelism in order to avoid blocking the main thread. Instead of solving any compilation problems in the main stream, Chakra copies and sends the bytecode and profiling data that the compiler most likely needs in a separate compilation process.
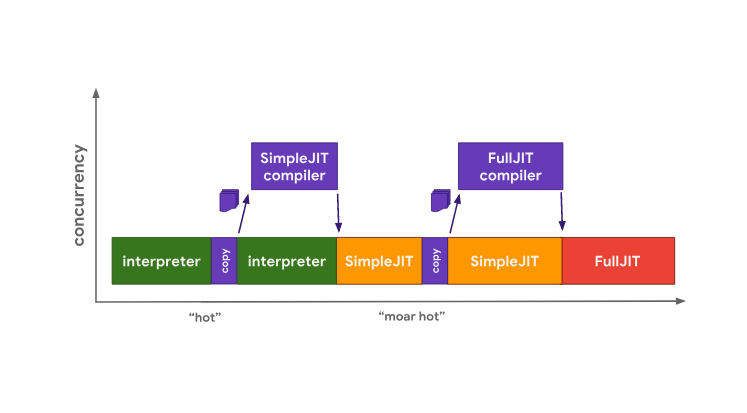 Optimization of the “hot” code in Chakra
Optimization of the “hot” code in Chakra
When the generated code prepared by SimpleJIT means is ready, the engine will execute it instead of the bytecode. This process is repeated to proceed to the execution of the code prepared by means of FullJIT. The advantage of this approach is that the pauses associated with copying data are usually much shorter than those caused by the work of a full-fledged compiler (frontend). However, the disadvantage of this approach is the fact that heuristic copying algorithms can skip some information that may be useful for performing some optimization. Here we see an example of a compromise between the quality of the received code and delays.
In JavaScriptCore, all tasks of optimizing compilation are performed in parallel with the main thread responsible for executing JavaScript code. In this case there is no copying stage. Instead, the main thread simply invokes compilation tasks on another thread. The compiler then uses a complex locking scheme to access profiling data from the main thread.
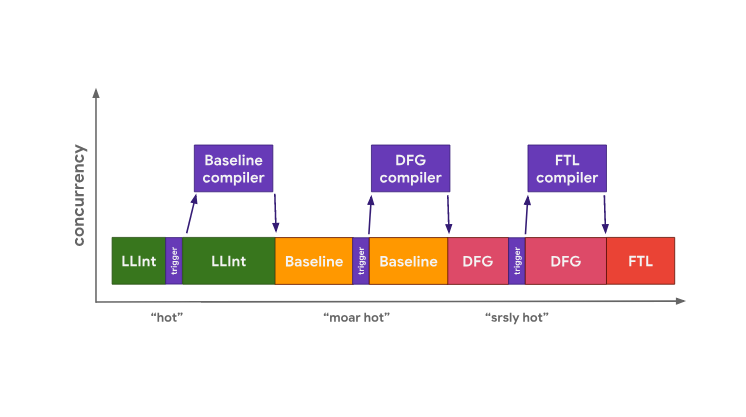 Optimization of the “hot” code in JavaScriptCore
Optimization of the “hot” code in JavaScriptCore
The advantage of this approach is that it reduces the forced blocking of the main thread, caused by the fact that it performs code optimization tasks. The disadvantages of such an architecture are that its implementation requires the solution of complex problems of multi-threaded data processing, and that during the work, to perform various operations, it is necessary to resort to locks.
We have just discussed the trade-offs that engines have to go to, choosing between fast code generation using interpreters and creating fast code using optimizing compilers. However, this is not all the problems that confront engines. Memory is another system resource that, when used, has to resort to compromise solutions. In order to demonstrate this, consider a simple JS program that adds numbers.
Here is the function byte-code
The meaning of this bytecode can not go into, in fact, its contents are not particularly interested in us. The main thing here is that there are only four instructions in it.
When this code snippet turns out to be “hot,” TurboFan is taken into account, which generates the following highly optimized machine code:
As you can see, the amount of code, in comparison with the above example of the four instructions, is very large. As a rule, bytecode is much more compact than machine code, and in particular - optimized machine code. On the other hand, an interpreter is needed to execute the bytecode, and the optimized code can be executed directly on the processor.
This is one of the main reasons why JavaScript engines do not optimize absolutely all code. As we saw earlier, creating optimized machine code takes a lot of time, and, moreover, as we just found out, it takes more memory to store optimized machine code.
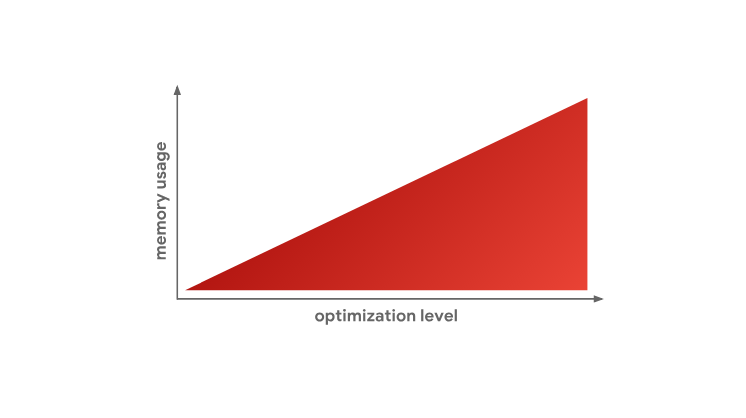 Memory Usage and Level of Optimization
Memory Usage and Level of Optimization
In summary, the reason why JS engines have different levels of optimization is the fundamental problem of choosing between fast code generation, for example, using an interpreter, and fast code generation performed by the optimizing compiler. If we talk about the levels of code optimization used in the engines, then the more of them, the more subtle optimizations can be subjected to the code, but this is achieved due to the complexity of the engines and due to the additional load on the system. In addition, here we must not forget that the level of code optimization affects the amount of memory that this code occupies. That is why JS-engines are trying to optimize only the "hot" features.
JavaScript engines optimize access to object properties through the use of so-called object shapes (Shape) and inline caches (Inline Cache, IC). Details about this can be read in this material, if we express it in a nutshell, then we can say that the engine keeps the shape of the object separately from the values of the object.
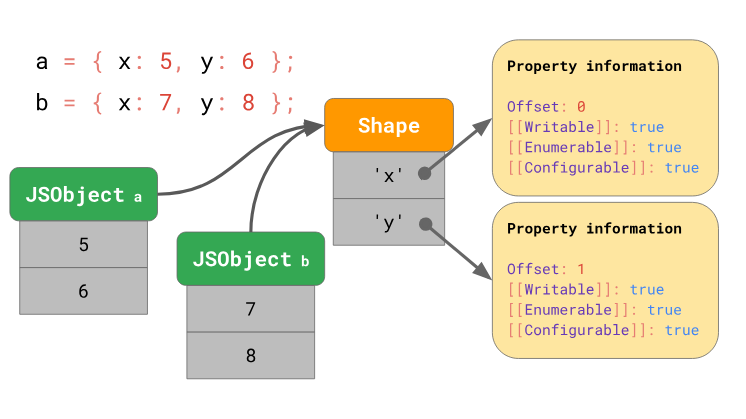 Objects that have the same form
Objects that have the same form
Using the forms of objects allows you to perform optimization, called inline-caching. Sharing of forms of objects and inline-caches allows you to speed up repeated operations of accessing the properties of objects performed from the same place in the code.
 Acceleration of access to the property of the object
Acceleration of access to the property of the object
Now that we know how to speed up access to the properties of objects in JavaScript, take a look at one of the recent JavaScript innovations — classes. Here is the class declaration:
Although it may look like the appearance of a completely new concept in JS, classes, in fact, are only syntactic sugar for the prototype object design system that has always been present in JavaScript:
Here we write the function to the property of the
Look at what is happening, so to speak, behind the scenes, when we create a new instance of an object
After executing such code, the instance of the object created here will have a form containing a single property
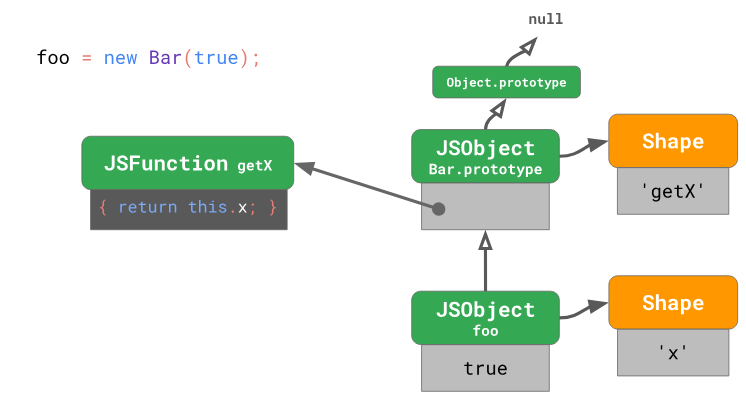 An object and its prototype
An object and its prototype
U
Now let's see what happens if we create another type object
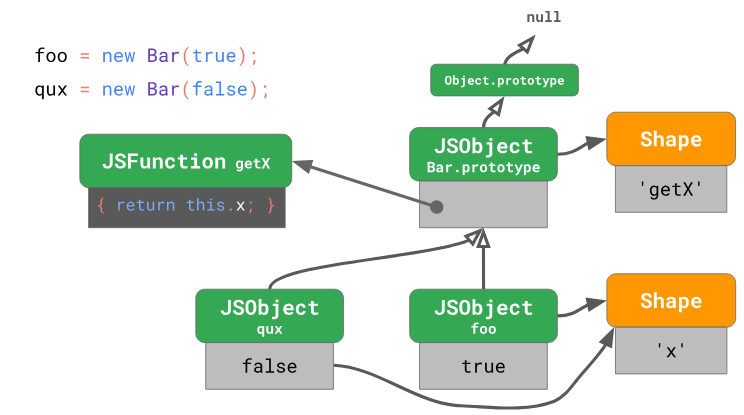 Several objects of the same type
Several objects of the same type
As you can see, both an object
So now we know what happens when we declare a new class and create instances of it. And what about the method call object? Consider the following code snippet:
The method call can be perceived as an operation consisting of two steps:
The first step is loading the method, which is just a property of the prototype (the value of which is a function). In the second step, the function is called with the installation
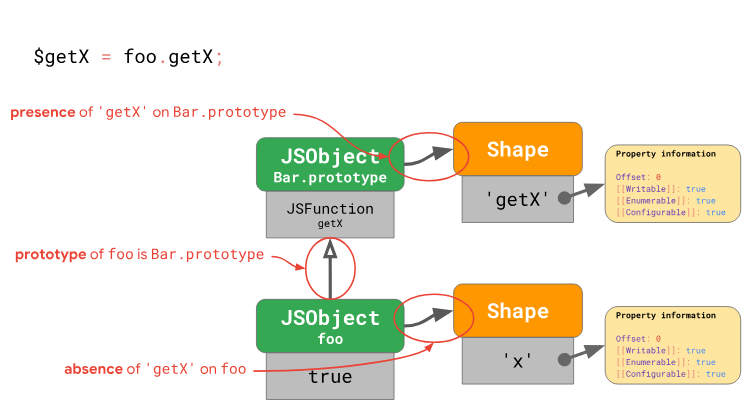
 Loading the getX method from the foo object
Loading the getX method from the foo object
The engine analyzes the object
The flexibility of JavaScript makes it possible to change prototype chains. For example:
In this example, we call the method
If we consider the real-life programs, it turns out that the loading of the properties of prototypes is an operation that occurs very often. It is executed every time a method call is made.
Earlier, we talked about how engines optimize loading of regular, own properties of objects through the use of object shapes and inline caches. How to optimize repeated loadings of properties of a prototype for objects with the same form? Above, we have seen how properties are loaded.
 Loading the getX method from the foo object
Loading the getX method from the foo object
In order to speed up access to the method during repeated calls to it, in our case, you need to know the following:
In general, this means that we need to make 1 check of the object itself, and 2 checks for each prototype, up to the prototype that stores the property we are looking for. That is, you need to carry out 1 + 2N checks (where N is the number of prototypes to be checked), which in this case does not look so bad, since the chain of prototypes is rather short. However, engines often have to work with much longer chains of prototypes. This, for example, is typical of ordinary DOM elements. Here is an example:
Here we have
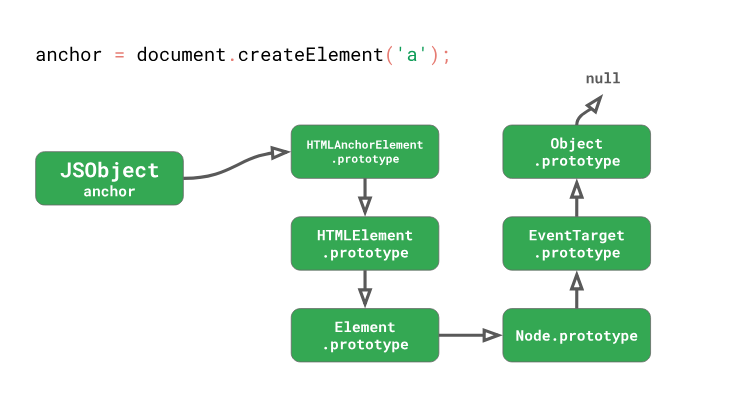 A chain of prototypes
A chain of prototypes
The method
As you can see, 7 checks are performed here. Since such code is very common in web programming, the engines use optimizations to reduce the number of checks needed to load prototype properties.
If you go back to one of the previous examples, you can remember that when accessing the method of an
For each object that exists in the chain of prototypes, down to the one that contains the desired property, we need to check the shape of the object only to find out that we are not looking for there. It would be nice if we could reduce the number of checks by reducing the prototype check to checking the presence or absence of what we are looking for. This is exactly what the engine does with a simple move: instead of storing a reference to the prototype in the instance itself, the engine stores it in the form of an object.
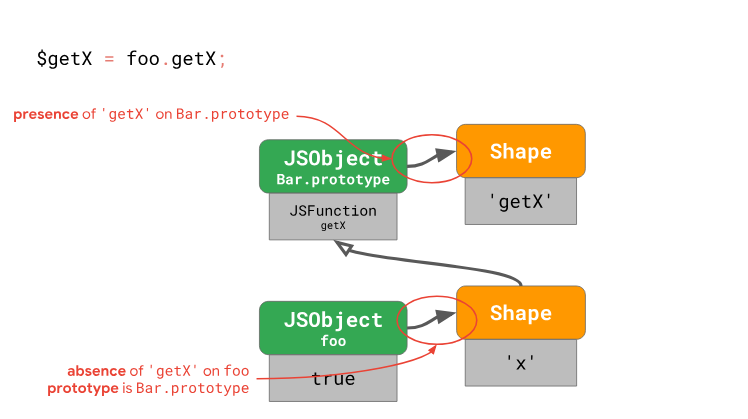 Storing references to prototypes
Storing references to prototypes
Each form has a reference to the prototype. This also means that whenever the prototype
Thanks to this approach, we can reduce the number of checks from 1 + 2N to 1 + N, which will speed up access to the properties of prototypes. However, such operations are still quite resource-intensive, since there is a linear relationship between their number and the length of the prototype chain. In the engines, various mechanisms are implemented to ensure that the number of checks does not depend on the length of the prototype chain, to be expressed as a constant. This is especially true in situations where the same property is loaded several times.
V8 refers to prototype forms specifically for the above purpose. Each prototype has a unique form that is not used in conjunction with other objects (in particular, with other prototypes), and each of the forms of prototype objects has a property associated with them
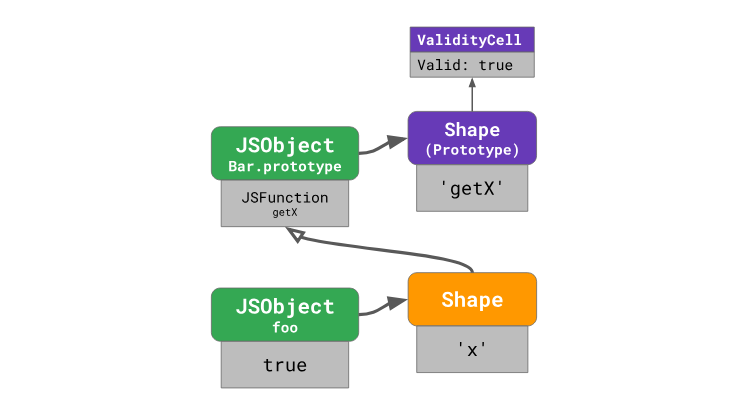 ValidityCell Property
ValidityCell Property
This property is declared invalid if the prototype associated with the form or any upstream prototype changes. Consider this mechanism in more detail.
In order to accelerate the serial download operation properties of the prototype, the V8 uses inline cache that contains four fields:
 Inline Cache Fields
Inline Cache Fields
During the inline cache warm-up when the code is first run, V8 remembers the offset at which the property was found in the prototype, the prototype in which the property was found (in this example -
The next time the inline cache is accessed, the engine will need to check the shape of the object and
When the prototype changes, a new form is created, and the previous property is
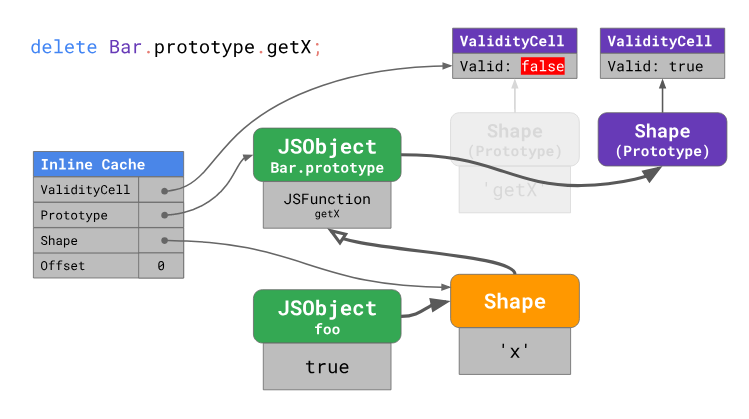 The consequences of the prototype change
The consequences of the prototype change
Going back to the example of DOM-elements, which means that any change, such as in the prototype
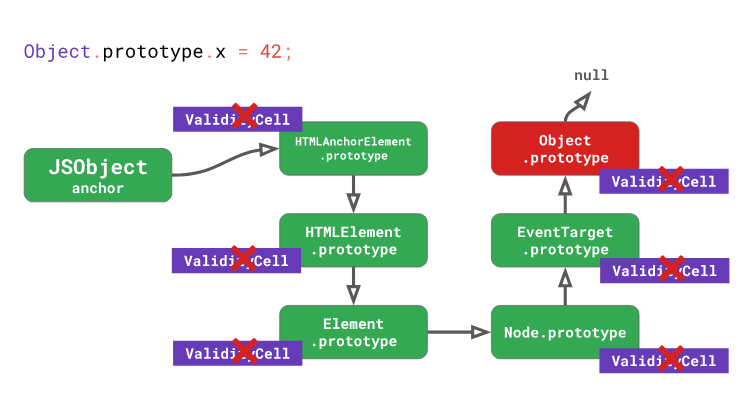 Consequences of changing Object.prototype
Consequences of changing Object.prototype
In fact, modifying
We investigate the above with an example. Suppose we have a class
Inline cache is
Changing
We expanded
Cleaning seems to be a good idea. But in this case it worsens the already bad situation even more. Deleting a property modifies
As a result, it can be concluded that, although prototypes are ordinary objects, JS engines relate to them in a special way in order to optimize the performance of searching methods in them. Therefore, it is best not to touch the prototypes of existing objects. And if you really need to change them, then do it before any other code will be executed. So you, at least, do not destroy the results of efforts to optimize the code achieved by the engine during its execution.
From this material, you learned about how JS engines store objects and classes, about how forms of objects, inline caches, properties
Dear readers! Have you encountered in practice cases where the poor performance of any program written in JS can be explained by interfering with object prototypes during code execution?

Code Optimization Levels and Tradeoffs
The process of converting the texts of programs written in JavaScript into suitable for execution code looks approximately the same in different engines.
You can see more details here . In addition, it should be noted that although, at a high level, the pipelines for converting source code into executable are very similar for different engines, their code optimization systems often differ. Why is this so? Why do some engines have more optimization levels than others? It turns out that engines have to compromise one way or another, which is that they can either quickly generate a code that is not the most effective, but suitable for execution, or spend more time to create such code, but due to this, achieve optimal performance.
interpreter is able to quickly generate byte-code, but such code is usually not very effective. An optimizing compiler, on the other hand, takes more time to generate code, but in the end it produces an optimized, faster machine code.
This model of code preparation for execution is used in V8. The V8 interpreter is called Ignition, it is the fastest of the existing interpreters (in terms of the execution of the original bytecode). The optimizing V8 compiler is called TurboFan, it is responsible for creating highly optimized machine code.
compromise between program launch delay and execution speed is the reason for some JS engines to have additional optimization levels. For example, in SpiderMonkey, between the interpreter and the optimizing IonMonkey compiler, there is an intermediate level represented by the basic compiler (itis called “The Baseline Compiler”in theMozilla documentation , but “baseline” is not a proper name).
Interpreter quickly generates bytecode, but such code runs relatively slowly. The base compiler takes more time to generate code, but this code is already running faster. Finally, the IonMonkey optimizing compiler takes the most time to create machine code, but this code can be executed very efficiently.
Take a look at a specific example and look at how the conveyors of various engines handle the code. In the example presented here, there is a “hot” loop containing code that is repeated many times.
let result = 0;
for (let i = 0; i < 4242424242; ++i) {
result += i;
}
console.log(result);V8 starts to perform bytecode in the interpreter Ignition. At some point in time, the engine finds out that the code is “hot” and starts the TurboFan frontend, which is part of TurboFan, which works with profiling data and creates a basic machine code representation. The data is then passed to the TurboFan optimizer, running in a separate thread, for further improvements.
During optimization, V8 continues to execute byte code in Ignition. When the optimizer finishes, we have executable machine code that can be used later.
The SpiderMonkey engine also starts to execute bytecode in the interpreter. But it has an additional level provided by the base compiler, which leads to the fact that the “hot” code first gets to this compiler. It generates the base code in the main thread, the transition to the execution of this code is made when it is ready.
If the base code runs long enough, SpiderMonkey eventually launches the IonMonkey frontend and optimizer, which is very similar to what happens in V8. The base code continues to run as part of the code optimization process performed by IonMonkey. As a result, when the optimization is complete, the optimized code is executed instead of the base code.
The architecture of the Chakra engine is very similar to the SpiderMonkey architecture, but Chakra tends to a higher level of parallelism in order to avoid blocking the main thread. Instead of solving any compilation problems in the main stream, Chakra copies and sends the bytecode and profiling data that the compiler most likely needs in a separate compilation process.
When the generated code prepared by SimpleJIT means is ready, the engine will execute it instead of the bytecode. This process is repeated to proceed to the execution of the code prepared by means of FullJIT. The advantage of this approach is that the pauses associated with copying data are usually much shorter than those caused by the work of a full-fledged compiler (frontend). However, the disadvantage of this approach is the fact that heuristic copying algorithms can skip some information that may be useful for performing some optimization. Here we see an example of a compromise between the quality of the received code and delays.
In JavaScriptCore, all tasks of optimizing compilation are performed in parallel with the main thread responsible for executing JavaScript code. In this case there is no copying stage. Instead, the main thread simply invokes compilation tasks on another thread. The compiler then uses a complex locking scheme to access profiling data from the main thread.
The advantage of this approach is that it reduces the forced blocking of the main thread, caused by the fact that it performs code optimization tasks. The disadvantages of such an architecture are that its implementation requires the solution of complex problems of multi-threaded data processing, and that during the work, to perform various operations, it is necessary to resort to locks.
We have just discussed the trade-offs that engines have to go to, choosing between fast code generation using interpreters and creating fast code using optimizing compilers. However, this is not all the problems that confront engines. Memory is another system resource that, when used, has to resort to compromise solutions. In order to demonstrate this, consider a simple JS program that adds numbers.
functionadd(x, y) {
return x + y;
}
add(1, 2);Here is the function byte-code
addgenerated by the Ignition interpreter in V8:StackCheck
Ldar a1
Add a0, [0]
ReturnThe meaning of this bytecode can not go into, in fact, its contents are not particularly interested in us. The main thing here is that there are only four instructions in it.
When this code snippet turns out to be “hot,” TurboFan is taken into account, which generates the following highly optimized machine code:
leaqrcx,[rip+0x0]movqrcx,[rcx-0x37]testb[rcx+0xf],0x1jnzCompileLazyDeoptimizedCodepushrbpmovqrbp,rsppushrsipushrdicmpqrsp,[r13+0xe88]jnaStackOverflowmovqrax,[rbp+0x18]testal,0x1jnzDeoptimizemovqrbx,[rbp+0x10]testbrbx,0x1jnzDeoptimizemovqrdx,rbxshrqrdx, 32
movqrcx,raxshrqrcx, 32
addlrdx,rcxjoDeoptimizeshlqrdx, 32
movqrax,rdxmovqrsp,rbppoprbpret 0x18As you can see, the amount of code, in comparison with the above example of the four instructions, is very large. As a rule, bytecode is much more compact than machine code, and in particular - optimized machine code. On the other hand, an interpreter is needed to execute the bytecode, and the optimized code can be executed directly on the processor.
This is one of the main reasons why JavaScript engines do not optimize absolutely all code. As we saw earlier, creating optimized machine code takes a lot of time, and, moreover, as we just found out, it takes more memory to store optimized machine code.
In summary, the reason why JS engines have different levels of optimization is the fundamental problem of choosing between fast code generation, for example, using an interpreter, and fast code generation performed by the optimizing compiler. If we talk about the levels of code optimization used in the engines, then the more of them, the more subtle optimizations can be subjected to the code, but this is achieved due to the complexity of the engines and due to the additional load on the system. In addition, here we must not forget that the level of code optimization affects the amount of memory that this code occupies. That is why JS-engines are trying to optimize only the "hot" features.
Optimize access to properties of prototypes of objects
JavaScript engines optimize access to object properties through the use of so-called object shapes (Shape) and inline caches (Inline Cache, IC). Details about this can be read in this material, if we express it in a nutshell, then we can say that the engine keeps the shape of the object separately from the values of the object.
Using the forms of objects allows you to perform optimization, called inline-caching. Sharing of forms of objects and inline-caches allows you to speed up repeated operations of accessing the properties of objects performed from the same place in the code.
Classes and prototypes
Now that we know how to speed up access to the properties of objects in JavaScript, take a look at one of the recent JavaScript innovations — classes. Here is the class declaration:
classBar{
constructor(x) {
this.x = x;
}
getX() {
returnthis.x;
}
}Although it may look like the appearance of a completely new concept in JS, classes, in fact, are only syntactic sugar for the prototype object design system that has always been present in JavaScript:
functionBar(x){
this.x = x;
}
Bar.prototype.getX = functiongetX(){
returnthis.x;
};Here we write the function to the property of the
getXobject Bar.prototype. Such an operation works in the same way as when creating a property of any other object, since the prototypes in JavaScript are objects. In languages based on the use of prototypes, such as JavaScript, methods that all objects of a certain type can share are stored in prototypes, and the fields of individual objects are stored in their instances. Look at what is happening, so to speak, behind the scenes, when we create a new instance of an object
Bar, assigning it to a constant foo.const foo = new Bar(true);After executing such code, the instance of the object created here will have a form containing a single property
x. The prototype of the object foowill be Bar.prototypethat belongs to the class Bar.U
Bar.prototypehas its own form containing a single propertygetX, the value of which is a function that, when called, returns a valuethis.x. Prototype prototypeBar.prototype- thisObject.prototypebeing the part of the language. Object.prototypeis the root element of the prototype tree, so its prototype is the valuenull. Now let's see what happens if we create another type object
Bar.As you can see, both an object
fooand an objectqux, which are instances of a classBar, as we have said, use the same object form. Both of them use the same prototype - the objectBar.prototype.Access to prototype properties
So now we know what happens when we declare a new class and create instances of it. And what about the method call object? Consider the following code snippet:
classBar{
constructor(x) { this.x = x; }
getX() { returnthis.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^The method call can be perceived as an operation consisting of two steps:
const x = foo.getX();
// на самом деле эта операция состоит из двух шагов:const $getX = foo.getX;
const x = $getX.call(foo);The first step is loading the method, which is just a property of the prototype (the value of which is a function). In the second step, the function is called with the installation
this. Consider the first step in which the method is loaded getXfrom the object foo:The engine analyzes the object
fooand finds out thatfoothere is no propertyin the object formgetX. This means that the engine needs to view a chain of object prototypes in order to find this method. The engine refers to the prototypeBar.prototypeand looks at the shape of the object of this prototype. There, he finds the desired property at offset 0. Next, the value stored at this offset in is accessedBar.prototype, it is found thereJSFunctiongetX- and this is exactly what we are looking for. This completes the search method. The flexibility of JavaScript makes it possible to change prototype chains. For example:
const foo = new Bar(true);
foo.getX();
// trueObject.setPrototypeOf(foo, null);
foo.getX();
// Uncaught TypeError: foo.getX isnot a functionIn this example, we call the method
foo.getX()twice, but each of these calls has a completely different meaning and result. That is why, although prototypes in JavaScript are just objects, accelerating access to the properties of prototypes is even more difficult for JS engines than accelerating access to the proper properties of ordinary objects. If we consider the real-life programs, it turns out that the loading of the properties of prototypes is an operation that occurs very often. It is executed every time a method call is made.
classBar{
constructor(x) { this.x = x; }
getX() { returnthis.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^Earlier, we talked about how engines optimize loading of regular, own properties of objects through the use of object shapes and inline caches. How to optimize repeated loadings of properties of a prototype for objects with the same form? Above, we have seen how properties are loaded.
In order to speed up access to the method during repeated calls to it, in our case, you need to know the following:
- The object form
foodoes not contain a methodgetXand does not change. This means that the object isfoonot modified by adding properties to it or deleting them, or changing the attributes of properties. - The prototype
foois still the originalBar.prototype. This means that the prototypefoodoes not change using the methodObject.setPrototypeOf()or by assigning a new prototype to a special property_proto_. - The form
Bar.prototypecontainsgetXand does not change. That is,Bar.prototypedo not change, deleting properties, adding them, or changing their attributes.
In general, this means that we need to make 1 check of the object itself, and 2 checks for each prototype, up to the prototype that stores the property we are looking for. That is, you need to carry out 1 + 2N checks (where N is the number of prototypes to be checked), which in this case does not look so bad, since the chain of prototypes is rather short. However, engines often have to work with much longer chains of prototypes. This, for example, is typical of ordinary DOM elements. Here is an example:
const anchor = document.createElement('a');
// HTMLAnchorElementconst title = anchor.getAttribute('title');Here we have
HTMLAnchorElementand we call his method getAttribute(). The prototype chain of this simple element representing an HTML link includes 6 prototypes! Most of the interesting DOM methods are not in their own prototype HTMLAnchorElement. They are located in the prototypes, located further in the chain.The method
getAttribute()can be found inElement.prototype. This means that each time the method is calledanchor.getAttribute(), the engine is forced to perform the following actions:- Check the object itself
anchorfor availabilitygetAttribute. - Check that the direct prototype of the object is
HTMLAnchorElement.prototype. - Figuring out that there is
HTMLAnchorElement.prototypeno methodgetAttribute. - Verify that the next prototype is
HTMLElement.prototype. - Figuring out that there is no necessary method here either.
- Finally, figuring out what the next prototype is
Element.prototype. - Figuring out that there is a method
getAttribute.
As you can see, 7 checks are performed here. Since such code is very common in web programming, the engines use optimizations to reduce the number of checks needed to load prototype properties.
If you go back to one of the previous examples, you can remember that when accessing the method of an
getXobject foo, we perform 3 checks:classBar{
constructor(x) { this.x = x; }
getX() { returnthis.x; }
}
const foo = new Bar(true);
const $getX = foo.getX;For each object that exists in the chain of prototypes, down to the one that contains the desired property, we need to check the shape of the object only to find out that we are not looking for there. It would be nice if we could reduce the number of checks by reducing the prototype check to checking the presence or absence of what we are looking for. This is exactly what the engine does with a simple move: instead of storing a reference to the prototype in the instance itself, the engine stores it in the form of an object.
Each form has a reference to the prototype. This also means that whenever the prototype
foochanges, the engine moves to a new form of the object. Now we just need to check the shape of the object for the presence of properties in it and take care of protecting the reference to the prototype.Thanks to this approach, we can reduce the number of checks from 1 + 2N to 1 + N, which will speed up access to the properties of prototypes. However, such operations are still quite resource-intensive, since there is a linear relationship between their number and the length of the prototype chain. In the engines, various mechanisms are implemented to ensure that the number of checks does not depend on the length of the prototype chain, to be expressed as a constant. This is especially true in situations where the same property is loaded several times.
ValidityCell property
V8 refers to prototype forms specifically for the above purpose. Each prototype has a unique form that is not used in conjunction with other objects (in particular, with other prototypes), and each of the forms of prototype objects has a property associated with them
ValidityCell.This property is declared invalid if the prototype associated with the form or any upstream prototype changes. Consider this mechanism in more detail.
In order to accelerate the serial download operation properties of the prototype, the V8 uses inline cache that contains four fields:
ValidityCell,Prototype,Shape,Offset.During the inline cache warm-up when the code is first run, V8 remembers the offset at which the property was found in the prototype, the prototype in which the property was found (in this example -
Bar.prototype), the shape of the object (fooin this case) and, in addition, a reference to the current parameter of theValidityCellimmediate prototype, which is referenced in the form of an object (in this case, tooBar.prototype). The next time the inline cache is accessed, the engine will need to check the shape of the object and
ValidityCell. If the indexValidityCellis still valid, the engine can directly use the previously stored offset in the prototype, without performing additional search operations.When the prototype changes, a new form is created, and the previous property is
ValidityCelldeclared invalid. As a result, the next attempt to access the inline cache does not bring any benefit, which results in poor performance.Going back to the example of DOM-elements, which means that any change, such as in the prototype
Object.prototype, will lead not only to the invalidation inline cache for himselfObject.prototype, but also for any prototypes, located below it in the chain of prototypes, includingEventTarget.prototype,Node.prototype,,Element.prototypeand so on, up toHTMLAnchorElement.prototype.In fact, modifying
Object.prototypein the process of executing code means causing serious harm to performance. Do not do this. We investigate the above with an example. Suppose we have a class
Bar, and a functionloadXthat calls the method of objects created from the classBar. We call a functionloadXseveral times, passing it instances of the same class.functionloadX(bar) {
return bar.getX(); // IC для 'getX' в экземплярах `Bar`.
}
loadX(new Bar(true));
loadX(new Bar(false));
// IC в `loadX` теперь указывает на `ValidityCell` для// `Bar.prototype`.Object.prototype.newMethod = y => y;
// `ValidityCell` в IC `loadX` объявлено недействительным// так как в `Object.prototype` внесены изменения.Inline cache is
loadXnow pointing to ValidityCellfor Bar.prototype. If then, say, change Object.prototype- the root prototype in JavaScript, then the value ValidityCellwill be invalid, and the existing inline cache will not help speed up the next attempt to access it, which will lead to poor performance. Changing
Object.prototypeis always bad, as it leads to the invalidation of all inline caches for loading properties from prototypes created by the engine until the root prototype changes. Here is another example of how not to act:Object.prototype.foo = function() { /* … */ };
// Особо важный фрагмент кода:
someObject.foo();
// Конец особо важного фрагмента кода.deleteObject.prototype.foo;We expanded
Object.prototype, which led to the invalidation of the inline-caches of the prototypes previously created by the engine. Then we run some code using the new prototype method. The engine has to start working with inline caches from a clean slate, create new caches to perform access operations to the properties of the prototypes. Then we return everything to the previous form, “we clean up after ourselves”, removing the prototype method added earlier. Cleaning seems to be a good idea. But in this case it worsens the already bad situation even more. Deleting a property modifies
Object.prototype, which means that all inline caches again become invalid and the engine again has to start creating them from scratch.As a result, it can be concluded that, although prototypes are ordinary objects, JS engines relate to them in a special way in order to optimize the performance of searching methods in them. Therefore, it is best not to touch the prototypes of existing objects. And if you really need to change them, then do it before any other code will be executed. So you, at least, do not destroy the results of efforts to optimize the code achieved by the engine during its execution.
Results
From this material, you learned about how JS engines store objects and classes, about how forms of objects, inline caches, properties
ValidityCellhelp optimize operations in which object prototypes participate. Based on this knowledge, we derived a practical recommendation on programming in JavaScript, which is that the prototypes are best not to change (and if you absolutely cannot do without it, then at least you need to do this before executing the rest of the program code). Dear readers! Have you encountered in practice cases where the poor performance of any program written in JS can be explained by interfering with object prototypes during code execution?