What is a web application in production?
- Transfer
At the dawn of a career, I worked for a company that produced a content management system. This CMS helped the marketing departments to manage the sites themselves, rather than relying on developers for every change. The system helped customers reduce operating expenses, and I learned how to create web applications.
Although the product itself was very general, customers typically used it for specific tasks. These tasks squeezed the most out of the CMS, and developers had to look for a solution to the problems. After ten years of working in this environment, I learned a huge number of ways how a web application can break down in production. Some of them are discussed in this article.
One of the lessons learned over the years is that individual engineers are usually very deeply immersed in the field of interest, and everything else is studied to a dangerous surface. The scheme normally works in a team of engineers with good communication, where knowledge overlaps and fills in the individual gaps in each of them. But in teams with little experience or at individual engineers fails.
If you started working in such an environment and then started building and deploying a web application from scratch, you will very quickly learn what “up to dangerous surface knowledge” is.
The industry has a number of solutions to solve this problem: managed web applications (Beanstalk, AppEngine, etc.), container management (Kubernetes, ECS, etc.), and many others. They work well out of the box and can perfectly solve the problem. But this is unnecessary complexity when launching a web application, and usually such solutions “just work”.
Unfortunately, they do not always "just work." If there is any nuance, then you want to know a little more about this sinister black box.
In the article, we take an unreliable system and modify it to a reasonable level of reliability. At every step, a real problem is used, the solution of which takes us to the next stage. I believe that it is more efficient not to analyze all parts of the final design, but to use just such a phased approach. He better demonstrates when and in what order to make certain decisions. In the end, we will build from scratch the basic structure of the hosting service for managed web applications, and I hope we will explain in detail the reasons for the existence of each part of it.
Imagine that your budget for hosting is $ 500 per year, so you decided to rent one t2.medium server on Amazon AWS. At the time of this writing, this is about $ 400 per year.
You know in advance that you will have an authorization system and that you will need to store information about users, so you need a database. Due to the limited budget we will place it on our only server. In the end, we get the following infrastructure:
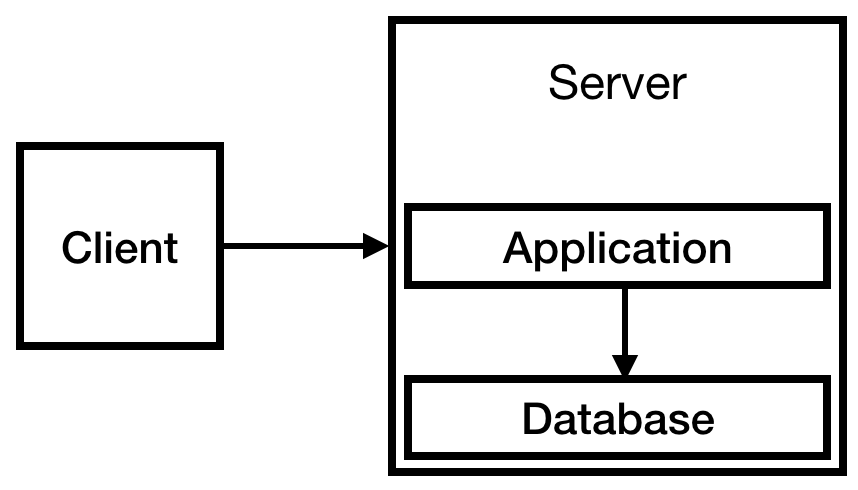
Fig. 1
While this is enough. In fact, such a system can work for quite some time. Service is small, less than 10 visits per day. It was possible that a small instance was enough, but we are optimistic about the growth of the company, so we prudently took t2.medium.
The value of a business is in the database, so it is very important. You need to make sure that if the server goes down, you will not lose data. Probably, you should make sure that the contents of the database is not stored on a temporary disk. After all, if the instance is deleted, you will lose your data. This is a very scary thought.
You should also make sure that you have backups on external storage. S3 seems like a good place for them, and relatively inexpensive, so let's also tweak it. And you need to check that the backup works, periodically restoring the backup.
Now the system looks like this:

Fig. 2
You have increased the reliability of the database, and it's time to prepare for the habraeffect by running a load test on the server. Everything seems to be normal, until 500 errors appear, and then the 404 error stream, so you study what happened.
It turns out that you have no idea what happened, because they wrote logs to the console and did not send the output to the file. You also see that the process does not work, so you can most likely assume that this is why 404 errors appear. A wave of relief rolls in, that you correctly run the local load test, and did not cause a real effect as a test load.
You fix the problem with automatic restart by creating a service
And again we see errors 500 (fortunately, without 404). You check the logs. It is detected that the database connection pool is full, because a small limit of 10 connections has been set. Update the limit, restart the database and run the load test again. Everything is going well, so you decide to tell about your site on Habré.
Mother of God! Your service instantly becomes a hit. You have reached the main page and get 5000 views in the first 30 minutes - and see the comments. What do they write there?
In a mad rush, you set up Nginx as a reverse proxy server for your application and set up a static page 404 there. You also change the deployment procedure to send static files to S3: this is necessary for CloudFront CDN to reduce download time in Australia.
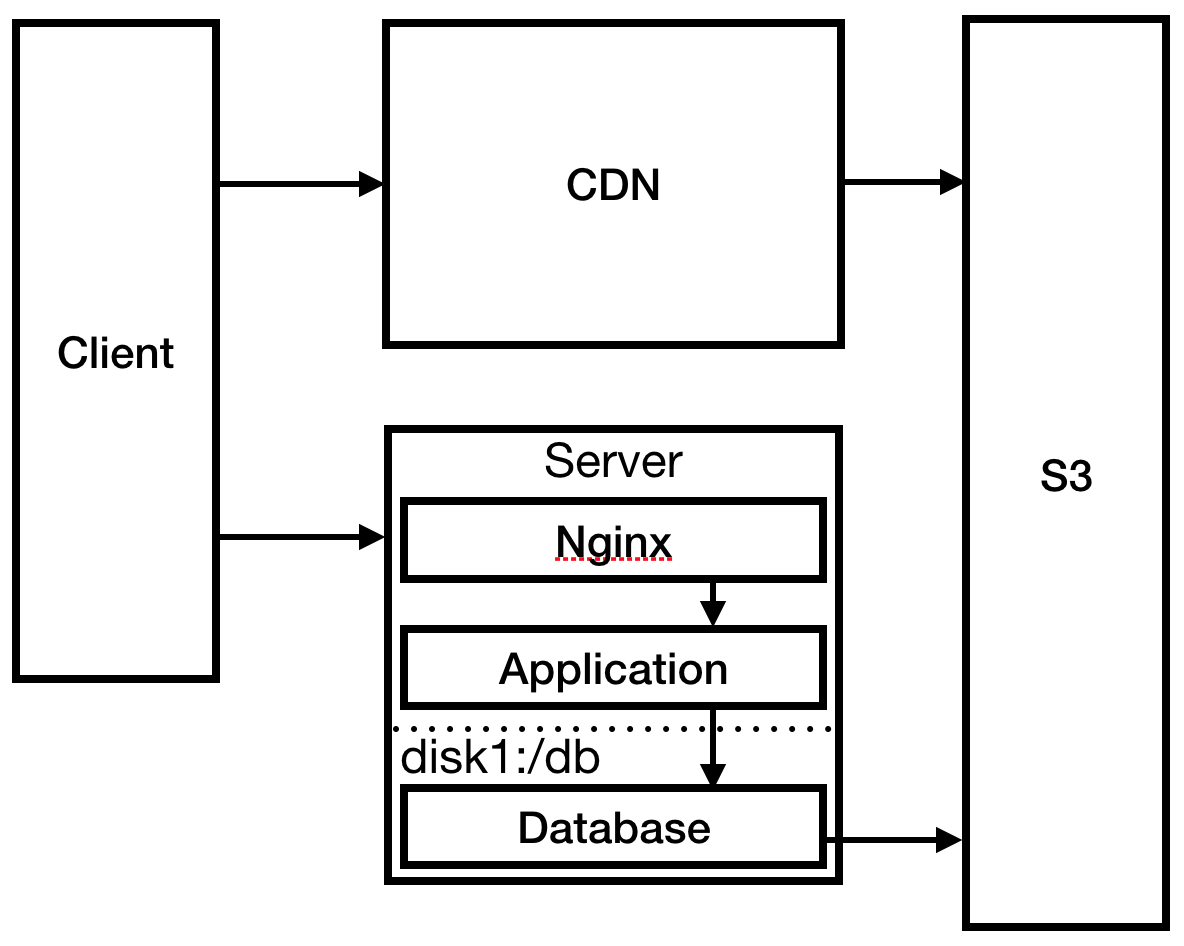
Fig. 3
You have solved the most pressing problem, go to the server and check the logs. Your SSH connection unusually lags. After some study, you can see that the log files have completely consumed the disk space, which led to the failure of the process and preventing it from restarting. Create a much larger disk and mount logs there. Make
Months go by. The audience is growing. The site is starting to slow down. You have noticed in the monitoring of CloudWatch that this only happens between 00:00 and 12:00 UTC. Due to the same start and end time of the lags, you can guess that this is due to the scheduled task on the server. Check crontab and understand that one task is scheduled for midnight: backup. Of course, backup takes twelve hours and leads to database overload, causing a significant slowdown of the site.
You have read about this before - and decide to run backups in a slave database (slave). Then you remember: you do not have a subordinate database, so you need to create it. It makes little sense to run the slave database on the same server, so you decide to expand. Create two new servers: one for the master database and one for the slave database. Change the backup to work with a subordinate database.

Fig. four
For a while, everything goes smoothly. Months go by. You hire developers. One of the newbies introduces a bug that brings down the production server. The developer blames the development environment, which is different from production. There is some truth in his words. Since you are a reasonable person with a good character, you perceive this event as a lesson.
It's time to create additional environments: intermediate (staging), QA, and production. Fortunately, you automated the creation of infrastructure from day one, so everything runs smoothly and simply. You also have good practices for continuous delivery since day one, so you can easily assemble a conveyor from new branches.
The marketing department insists on the release of version 2.0. You do not quite understand what 2.0 means, but you agree. It's time to prepare for the next surge of traffic. You are already close to the peak on the current server, so it's time for load balancing. Amazon ELB makes it easy. Around this time, you notice that the multi-level diagrams in this article should show the layers from top to bottom, not from left to right.

Fig. 5
Confident that you will cope with the load, you again mention your site on Habré. About a miracle, it maintains traffic. Big success!
Everything seemed to be going fine until you went to check the logs. 12 servers took an hour to check (four servers in each environment). The real hassle. Fortunately, there is enough money to buy the ELK stack (ElasticSearch, LogStash, Kibana). You deploy it and send back servers from all environments.

Fig. 6
Now, you can again refer to the logs, you watch them - and notice something strange. They are full of such records:
You are not using PHP or WordPress, so this is pretty weird. You notice similar suspicious entries in the logs of the database servers and wonder how they even connected to the Internet. It's time to introduce public and private subnets.

Fig. 7
Check the logs again. The hacking attempts remained, but now they are limited to port 80 on the load balancer, which is a bit comforting because the application servers, database servers and the ELK stack are no longer in open access.
Despite the centralized logs, you are tired of looking for downtime, checking the logs manually. Through Amazon CloudWatch, you set up email alerts when disk, CPU, and network reach 80% utilization. Fine!
Just kidding! In software, there is no such thing as smooth operation. Something will break. Fortunately, you now have a lot of tools to cope with the situation.
We have created a scalable web application with backups, rollbacks (using blue / green layouts between production and intermediate stages), centralized logs, monitoring and alerting. Further scaling, as a rule, depends on the specific needs of the application.
There are many hosting options on the market that take on most of the tasks mentioned. Instead of self-development, you can rely on Beanstalk, AppEngine, GKE, ECS, etc. Most of these services automatically set reasonable resolutions, load balancers, subnets, etc. This eliminates a significant part of the hassle when launching a web application on a fast and reliable backend that works for a long time.
Despite this, I find it helpful to understand what kind of functionality each of these platforms provides and why they provide it. This makes it easier to choose a platform based on your own needs. Placing the application on such a platform, you will already know how these modules work. When something goes wrong, it is helpful to know the toolkit to solve the problem.
This article omitted many details. It does not describe how to automate the creation of infrastructure, how to prepare and configure servers. The creation of development environments, the setting of continuous delivery pipelines, and the implementation of deployments and rollbacks are not considered. We did not affect network security, key sharing, and the principle of minimal privileges. They did not tell about the importance of immutable infrastructure, stateless servers and migrations. Each of the topics requires a separate article.
The purpose of this post is a general overview of what a reasonable web application should look like in production. Future articles may link here and expand the topic.
That's all for now.
Thanks for reading and successful coding!
Note: Do not literally take the sequence from this illustrative article. Individually, all these events really happened to me, but at different times, in completely different environments and on different tasks.
Although the product itself was very general, customers typically used it for specific tasks. These tasks squeezed the most out of the CMS, and developers had to look for a solution to the problems. After ten years of working in this environment, I learned a huge number of ways how a web application can break down in production. Some of them are discussed in this article.
One of the lessons learned over the years is that individual engineers are usually very deeply immersed in the field of interest, and everything else is studied to a dangerous surface. The scheme normally works in a team of engineers with good communication, where knowledge overlaps and fills in the individual gaps in each of them. But in teams with little experience or at individual engineers fails.
If you started working in such an environment and then started building and deploying a web application from scratch, you will very quickly learn what “up to dangerous surface knowledge” is.
The industry has a number of solutions to solve this problem: managed web applications (Beanstalk, AppEngine, etc.), container management (Kubernetes, ECS, etc.), and many others. They work well out of the box and can perfectly solve the problem. But this is unnecessary complexity when launching a web application, and usually such solutions “just work”.
Unfortunately, they do not always "just work." If there is any nuance, then you want to know a little more about this sinister black box.
In the article, we take an unreliable system and modify it to a reasonable level of reliability. At every step, a real problem is used, the solution of which takes us to the next stage. I believe that it is more efficient not to analyze all parts of the final design, but to use just such a phased approach. He better demonstrates when and in what order to make certain decisions. In the end, we will build from scratch the basic structure of the hosting service for managed web applications, and I hope we will explain in detail the reasons for the existence of each part of it.
Start
Imagine that your budget for hosting is $ 500 per year, so you decided to rent one t2.medium server on Amazon AWS. At the time of this writing, this is about $ 400 per year.
You know in advance that you will have an authorization system and that you will need to store information about users, so you need a database. Due to the limited budget we will place it on our only server. In the end, we get the following infrastructure:
Fig. 1
While this is enough. In fact, such a system can work for quite some time. Service is small, less than 10 visits per day. It was possible that a small instance was enough, but we are optimistic about the growth of the company, so we prudently took t2.medium.
The value of a business is in the database, so it is very important. You need to make sure that if the server goes down, you will not lose data. Probably, you should make sure that the contents of the database is not stored on a temporary disk. After all, if the instance is deleted, you will lose your data. This is a very scary thought.
You should also make sure that you have backups on external storage. S3 seems like a good place for them, and relatively inexpensive, so let's also tweak it. And you need to check that the backup works, periodically restoring the backup.
Now the system looks like this:
Fig. 2
You have increased the reliability of the database, and it's time to prepare for the habraeffect by running a load test on the server. Everything seems to be normal, until 500 errors appear, and then the 404 error stream, so you study what happened.
It turns out that you have no idea what happened, because they wrote logs to the console and did not send the output to the file. You also see that the process does not work, so you can most likely assume that this is why 404 errors appear. A wave of relief rolls in, that you correctly run the local load test, and did not cause a real effect as a test load.
You fix the problem with automatic restart by creating a service
systemd, start a web server that simultaneously solves the problem with logging. Then run another load test for verification. And again we see errors 500 (fortunately, without 404). You check the logs. It is detected that the database connection pool is full, because a small limit of 10 connections has been set. Update the limit, restart the database and run the load test again. Everything is going well, so you decide to tell about your site on Habré.
Launch day
Mother of God! Your service instantly becomes a hit. You have reached the main page and get 5000 views in the first 30 minutes - and see the comments. What do they write there?
I have a 404 error, so I had to open the cached version of the page. Here is a link, if anyone needs: ......
Nothing opens. In addition, I have Javascript disabled. Why do people think that I want to load their Javascript on 2 MB ......
Loading the home page takes 4 seconds. Traceroute from Australia shows that the server is located somewhere in Texas. Also, why does the first page load 2 megabytes of Javascript?
In a mad rush, you set up Nginx as a reverse proxy server for your application and set up a static page 404 there. You also change the deployment procedure to send static files to S3: this is necessary for CloudFront CDN to reduce download time in Australia.
Fig. 3
You have solved the most pressing problem, go to the server and check the logs. Your SSH connection unusually lags. After some study, you can see that the log files have completely consumed the disk space, which led to the failure of the process and preventing it from restarting. Create a much larger disk and mount logs there. Make
logrotatesure that the log files no longer grow to this size.Performance issues
Months go by. The audience is growing. The site is starting to slow down. You have noticed in the monitoring of CloudWatch that this only happens between 00:00 and 12:00 UTC. Due to the same start and end time of the lags, you can guess that this is due to the scheduled task on the server. Check crontab and understand that one task is scheduled for midnight: backup. Of course, backup takes twelve hours and leads to database overload, causing a significant slowdown of the site.
You have read about this before - and decide to run backups in a slave database (slave). Then you remember: you do not have a subordinate database, so you need to create it. It makes little sense to run the slave database on the same server, so you decide to expand. Create two new servers: one for the master database and one for the slave database. Change the backup to work with a subordinate database.
Fig. four
Team growth
For a while, everything goes smoothly. Months go by. You hire developers. One of the newbies introduces a bug that brings down the production server. The developer blames the development environment, which is different from production. There is some truth in his words. Since you are a reasonable person with a good character, you perceive this event as a lesson.
It's time to create additional environments: intermediate (staging), QA, and production. Fortunately, you automated the creation of infrastructure from day one, so everything runs smoothly and simply. You also have good practices for continuous delivery since day one, so you can easily assemble a conveyor from new branches.
The marketing department insists on the release of version 2.0. You do not quite understand what 2.0 means, but you agree. It's time to prepare for the next surge of traffic. You are already close to the peak on the current server, so it's time for load balancing. Amazon ELB makes it easy. Around this time, you notice that the multi-level diagrams in this article should show the layers from top to bottom, not from left to right.
Fig. 5
Confident that you will cope with the load, you again mention your site on Habré. About a miracle, it maintains traffic. Big success!
Everything seemed to be going fine until you went to check the logs. 12 servers took an hour to check (four servers in each environment). The real hassle. Fortunately, there is enough money to buy the ELK stack (ElasticSearch, LogStash, Kibana). You deploy it and send back servers from all environments.
Fig. 6
Now, you can again refer to the logs, you watch them - and notice something strange. They are full of such records:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1You are not using PHP or WordPress, so this is pretty weird. You notice similar suspicious entries in the logs of the database servers and wonder how they even connected to the Internet. It's time to introduce public and private subnets.
Fig. 7
Check the logs again. The hacking attempts remained, but now they are limited to port 80 on the load balancer, which is a bit comforting because the application servers, database servers and the ELK stack are no longer in open access.
Despite the centralized logs, you are tired of looking for downtime, checking the logs manually. Through Amazon CloudWatch, you set up email alerts when disk, CPU, and network reach 80% utilization. Fine!
Smooth operation
Just kidding! In software, there is no such thing as smooth operation. Something will break. Fortunately, you now have a lot of tools to cope with the situation.
We have created a scalable web application with backups, rollbacks (using blue / green layouts between production and intermediate stages), centralized logs, monitoring and alerting. Further scaling, as a rule, depends on the specific needs of the application.
There are many hosting options on the market that take on most of the tasks mentioned. Instead of self-development, you can rely on Beanstalk, AppEngine, GKE, ECS, etc. Most of these services automatically set reasonable resolutions, load balancers, subnets, etc. This eliminates a significant part of the hassle when launching a web application on a fast and reliable backend that works for a long time.
Despite this, I find it helpful to understand what kind of functionality each of these platforms provides and why they provide it. This makes it easier to choose a platform based on your own needs. Placing the application on such a platform, you will already know how these modules work. When something goes wrong, it is helpful to know the toolkit to solve the problem.
Conclusion
This article omitted many details. It does not describe how to automate the creation of infrastructure, how to prepare and configure servers. The creation of development environments, the setting of continuous delivery pipelines, and the implementation of deployments and rollbacks are not considered. We did not affect network security, key sharing, and the principle of minimal privileges. They did not tell about the importance of immutable infrastructure, stateless servers and migrations. Each of the topics requires a separate article.
The purpose of this post is a general overview of what a reasonable web application should look like in production. Future articles may link here and expand the topic.
That's all for now.
Thanks for reading and successful coding!
Note: Do not literally take the sequence from this illustrative article. Individually, all these events really happened to me, but at different times, in completely different environments and on different tasks.