About automation of chord selection
I have long been interested in the question: “what if you try to run a digital recording of a song through the Fourier transform, see the dependence of the spectrum on time and try to extract the chords of the song from the received information?” Here, finally, I found the time to try ...
So, the statement of the problem:
There is a file with digitized music (not MIDI!), For definiteness mp3. It is necessary to determine the sequence of the change of chords, forming the harmony of the work. By “music” we mean typical European music - 12 semitones in an octave, harmony mainly based on major / minor triads, reduced and increased triads and * sus2 / * sus4 (chords with the 2nd / 4th stage instead of 3 are also acceptable) th).
Notes in European music are sounds with frequencies from a fixed set (more on that below), while sounds differing in frequency by 2, 4, 8 ... times are indicated by one note. Musical intervals are fixed ratios of frequencies of two notes. This interval system is arranged as follows:
The letter notation in the notation accepted in Russia is as follows:
A - A, B - B flat, H - B, C - C, D - re, E - mi, F - fa, G - salt.
# (sharp) indicates an increase in frequency by 1/2 tone, b (flat) indicates a decrease by 1/2 tone. On an octave of 12 halftones, the notes are displayed like this:
ABHCC # / Db DD # / Eb EFF # / Gb GG # / Ab
Octaves have tricky names and numbers, but we are not interested, it’s enough to know that the frequency of the “a” note of the first octave is 440 Hz The frequencies of the remaining notes are easy to calculate based on the above.
The chord consists of several simultaneously sounding notes. At the same time, they can be extracted sequentially (arpeggio, it’s also “busting” in the jargon of yard guitarists), but since the sound does not calm down immediately, the notes manage to sound together for some time. In the European tradition, the most common chords of three sounds (actually triads). Major and minor triads are commonly used. In major chords, the 1st (beginning with the lowest) and 2nd notes form a large third, and the 2nd and 3rd - a minor, in minor, on the contrary, the 1st and 2nd - a small, 2nd and 3rd is big. The 1st and 3rd notes in both cases form a fifth. There are also reduced (two small thirds) and increased (two large thirds) triads, and sustained chords (I don’t know how they are in Russian) are quite common in rock music - sus2 with a 2nd note in 1/2 tones below, than minor and sus4 with the 2nd note, 1/2 tone higher than the major. The 3rd note in both versions of the sustained chord forms with the 1st regular fifth.
In one piece of music, it is rare that all 12 notes are used to the same extent. As a rule, there is a “basic” subset of 7 notes, and the notes are mainly taken from it. Such a subset can be determined using a mask of 0 and 1 superimposed on a vector of 12 notes. If you exaggerate, such a subset is called tonality, and the set of all possible cyclic shifts of the tonality mask is called the fret. In European music, two frets are mainly used:
The chords used in a particular key are built, if possible, from the notes of that key.
You may notice that the masks of major and minor differ with accuracy to a shift. Accordingly, the chords, for example, in C major and the corresponding A-minor are used the same (this is what we so unobtrusively returned to our task).
The note “beginning with which” the mask was applied is called a tonic. The number of the note entering the key, starting with the tonic, is called the step. When talking about the structure of a particular chord, the steps are counted from its 1st note (the so-called main tone).
Chords are traditionally indicated by the symbol of its fundamental tone, to which a chord type suffix is assigned to the right without a space. For example, notes A (a):
[Offtopic for those who studied at the music school] I heard about the differences between melodic and harmonic minors and about the problems of temperament (returning to the roots of the 12th degree), too. But, as it seems to me, within the framework of this article, the above simplified description of the subject area is enough.
So we need:
I did not bother with the first task - I took a ready-made sox sound converter that supports both mp3 and “raw” formats, where the sound is stored just like a graph of the amplitude versus time. In * nix-systems it is installed trivially with the help of the package manager - on Ubuntu it looks like this:
$ sudo apt-get install sox
$ sudo apt-get install lame
The second line puts LAME mp3 encoder.
Under Windows, sox can be downloaded from the official site, but then you will have to suffer a bit with searching the Internet for suitable LAME DLLs.
With the second task, in principle, everything is simple. In order to understand what notes sound at a particular moment in time, it is necessary to perform a spectral analysis of a piece of our array with amplitudes in the index range corresponding to a small neighborhood of this moment. As a result of spectral analysis, we obtain the amplitudes for the set of frequencies that "make up" the analyzed piece of sound. It is necessary to filter the frequencies, selecting those that are close to the frequencies of the notes, and select the largest of them - they correspond to the loudest notes. I say “close”, not “equal”, because in nature there are no perfectly tuned musical instruments; this is especially true for guitars.
For spectral analysis of a discrete representation of a time-varying signal, you can use the window fast Fourier transform. I tore off the simplest non-optimized FFT implementation from the Internet, transferred it from C ++ to Scala, and took the Hann function as a window function. You can read more about this in the relevant Wikipedia articles.
After receiving an array of amplitudes in frequencies, we select the frequencies in the neighborhood (by default, its size is 1/4 semitone) around the frequency of each note in a certain range of octaves (experience shows that it is best to analyze octaves with a large second or third octave). In each such neighborhood, we calculate the maximum amplitude and consider it as the loudness of the corresponding note. After that, we summarize the "volume" of each note in all octaves and, finally, divide all the elements of the resulting array of 12 "volumes" by the value of its maximum element. The resulting vector of 12 elements in different sources is called a chromogram.
Here it is impossible not to mention a couple of subtleties. Firstly, for different works, the convenient range of octaves for analysis is different - for example, the introduction to My Friend Of Misery Metallica is played, apparently, on the bass and sounds pretty low; in the upper octaves there are mostly overtone and left frequencies from distortion, which only interfere.
Secondly, there are no perfectly tuned guitars in nature. This is probably due to the fact that the strings, depending on the fret, differently lengthen when clamped (well, in general, the fingers press on them unevenly). In addition, this instrument is quickly upset during the game on it. For example, in Letov’s acoustic recordings with tuning, the finish is complete - well, this can be understood. And here is why in the same My Friend Of Misery one I don’t remember which note stably sounds exactly a quarter tone, either higher or lower - a mystery. And even with well-tuned guitars on the recordings of various tenants, the structure usually does not coincide with the canonical in overall height - i.e. The “la” of the first octave may not be exactly 440 hertz.
To neutralize such jambs, it was necessary to provide in the program the possibility of compensating for the general shift of the system. But there is nothing to be done with the frustration of individual strings and the overall inherent “inability” of guitars. So an ambush with the main rock instrument.
[Another offtopic] The set of compositions that will be mentioned in this, so to speak, "essay" may seem somewhat wild. However, the selection criteria were very simple:
That is, I tried to simplify my life, at least at the beginning of torment with the selection of each song.
But back to our three tasks.
The remaining, third, task seems trivial - we select the three loudest notes and add a chord from them. But in reality, nothing will turn out that way (well, not at all - see below, but there is very little sense from this approach). And in general, this task turned out to be the most difficult of all.
Now, first things first.
At first, I did exactly as described above - after analyzing each “window” of the sound file, I selected the three loudest notes and tried to create a chord from them.
The first composition on which I tried to experience the magical effect of my miracle program was Letov’s in Paradise by Letov in the version from the Tyumen bootleg aka “Russian Field of Experiments (acoustics)”. The introduction to this song is a slot in a minor minor triad for about a dozen seconds.
However, having run my program at the beginning of this song, I did not find a single (!) Em chord in the output. Basically nothing was determined, occasionally all completely “left” nonsense climbed. What was the matter, it was not clear. I had to implement the frequency dump of each window in the form of a histogram of the symbols '*'. From the histogram, it was first found out that the guitar structure differs by about a quarter tone from the face value. OK, enter the correction. Hurrah! The notes E and H began to be determined - the 1st and 3rd notes in the chord. But where is G?
Further investigation of the dump revealed the following:
Apparently, that's why G rarely happens to even be in 4th place.
In general, I scored on Letov’s selection. In general, it became clear that you need to look for another way to analyze the chromogram. But, in fairness, it must be said that at least one fragment exists in nature that is normally selected in this way. This is an introduction to Olga Pulatova’s song “Pink Elephant”, which is an arpeggio on electronic keys. The program on it produced the following result (after manually clearing artifacts formed “at the junctions” of chords and removing successive repeats): Fm Cm (c db f) Ab Abm Eb Ebm B. ((c db f) - a non-standard consonance that without special damage can be replaced by Db). Independent verification shows that the chords are correct.
Here it is, the power of a dull piece of iron! With Olin’s hands, a sophistication with three tonalities of 8 chords can be selected for a long time and unsuccessfully ... But, alas, I repeat, this is the only composition I know that can be successfully analyzed in this way. The reasons for the failure are understandable - on the one hand, the overtone and the “left” frequencies of the guitar “lotions” interfere, on the other hand, chords rarely sound on their own, on top of them with a larger, moreover, usually there is a melody in volume - vocals, guitar / keyboard solo, etc. .P. A melody rarely ever completely fits in with harmony in notes - it is too sad, as a result, “temporary” harmonies are constantly formed in the stream of sound, which do not correspond to any canonical chords, and everything breaks.
I had to google and dig. The topic turned out to be quite popular in the scientific and semi-scientific environment, and in nature there is something to read about it, if you are not afraid of terms such as hidden Markov model, naive bayesian classifier, gaussian mix, expectation maximization etc. At first I was afraid to climb into all this jungle. Then he sorted it out slowly.
Here lies the article that turned out to be the most useful for me:
http://academia.edu/1026470/Enhancing_chord_classification_through_neighborhood_histograms
To begin with, the authors propose not to search for exact matches with chords, but to evaluate the degree of “proximity” of the chromogram to the chord. They offer three ways to evaluate such proximity:
The third method, after a somewhat more detailed study of other sources, I threw back - judging by the conclusions from the above article, it gives results slightly better than the trivial first method, and hemorrhoids with matrix arithmetic, calculation of determinants, etc. many.
But the first two I implemented.
The first way is super simple. Suppose we have a chord (for definiteness Am) and a chromogram. How to determine how much the chromogram is “similar” to a chord?
We take a mask of notes that sound in a chord - like the one we painted for tonality. For Am, it will be 1 0 0 1 0 0 0 1 0 0 0 0. Multiply this mask scalarly by the chromogram, as if it were 12-dimensional vectors (well, that is, we stupidly summarize the elements of the chromogram with those indices for which one is in the mask) . Voila - here it is, a measure of "similarity." We sort through all the chords that we know, we find the one with the greatest “similarity” - we believe that it sounds.
The second method in implementation is a little more complicated, but requires training data. It is based on Bayes theorem. On the fingers, it looks like this.
There is the concept of conditional probability: the conditional probability P (A | B) is the probability of event A , provided that event B has occurred. This value is determined by this identity:P (AB) == P (A | Bed and) * P (Bed and) , where P (AB) - probability of simultaneous occurrence of the events A and Bed and .
Hence:
P (AB) == P (A | B) * P (B)
P (AB) == P (B | A) * P (A)
That is, provided that P (A)
P (B | A) == P (A | B) * P (B) / P (A)
This is Bayes' theorem.
How do we use this? We rewrite the statement of the theorem in the notation convenient for our problem:
P (Chord | Chroma) = P (Chroma | Chord) * P (Chord) / P (Chroma) ,
where Chord is a chord, Chroma is a chromogram
If we find out somewhere the distribution of chromograms depending on the chord, then we can find the most plausible chord for a given chromogram by maximizing the product P (Chroma | Chord) * P (Chord) - since we have a chromogram, and P (Chroma) , therefore, a constant.
It remains to understand where to get the distributions of P (Chroma | Chord) . You can, for example, let the program “listen” to the recordings of specific knownly known chords so that it evaluates these distributions on their basis. But there is a nuance. The probability of getting a specific value of the chromogram on the “training” examples is negligible - simply because there are very, very many possible values. As a result, when using learning outcomes for real work in the vast majority of casesP (Chroma | Chord) for all values of Chord will be equal to zero, and there will be nothing to maximize.
It is possible (and necessary) to simplify the chromograms before classification, for example, by dividing the relative amplitude range [0, 1], on which the components of the chromogram are defined, say, into 3 parts (with the meaning “almost as loud as the loudest note”, “somewhat quieter than the loudest note "," quite quiet compared to the loudest note "). But still there will be too many options.
The next thing that can be done is to assume that the probability distribution of each component of the chromogram is independent of the other components. In this case, P (Chroma | Chord) = P (c 1 | Chord) * ... * P (c 12 | Chord) , where c1 ..c 12 - components.
chromograms, and for this particular case we get the following formulation of Bayes's theorem:

But P (c i | Chord) can already be extracted even from the meager amount of training data - provided, of course, “simplify” the chromogram by limiting the domain of definition of ci to three values, as we agreed above.
It remains to take P (Chord) from somewherefor all the considered chords. It doesn’t matter - for this, any collection of songs with chords is suitable, the main thing is that there are a lot of songs, and they were different authors.
Classifier based on maximizing the expression P (c 1 | Chord) * ... * P (c 12 | Chord) * P (Chord)according to the Chord parameter , and is called the naive Bayesian classifier. And in this particular case, its “naivety” is significant, since in reality the components of the chromogram are dependent random variables - for example, because of the same overtones. However, as we will see later, this approach works.
All this is easily implemented - the code of the classifier itself and the “subsystem” of its training are much less than the description given here. I taught him on a set of major and minor grand piano chords from some free sample site and a collection of the author's song of the 90s with chords (the first that was found on the Internet as a single text file).
Now about the results of field trials. In the tests participated, in addition to the already mentioned My Friend Of Misery and "Pink Elephant", the following compositions:
What happened. Both classifiers work very twitchy, all the time jumping from chord to chord. Naive Bayes is a little more stable than the maximum of the scalar product, but it seems that only because it “knows” fewer chords (only major and minor). Since he, in contrast to the “scalar” brother, “knows” the probabilities that various chords meet in the author’s, damn, song of the 90s, he behaves somewhat redneckly, trying, roughly speaking, to stick “three thieves” everywhere . Glimpses of the mind are found in both classifiers, but for some reason, as a rule, on different fragments of the same work. Best of all, they dealt with Misery. Bayes periodically rather steadily gave out steam locomotives Dm and Am, which is correct (there is harmony like Dsus2 / E Am / E many, many times; / E is with bass “I” in the sense).
Something managed to be pulled out of the “In a dream”. Despite the poor sound quality, almost correct chords of the entry Cm Eb Bm (in fact, the last B chord, as it should be in the minor minor) and the couplet - Cm Gm Cm Gm Ab F Ab F. The second, “decorated”, part of the entry drowned in garbage (looking ahead - I still did not pick it up, more advanced classification methods also give nonsense).
From “Soldiers are not born” it was not possible to get anything at all ... Why - I do not understand. In dumps of a spectrum garbage. But it sounds normal by ear and you can pick it up manually - Am CGH is there in the introduction, however, I'm not sure about the tonality - the well-known beast has stepped in my ear).
With "Assoll" naive Bayes coped better. He clearly liked KSP-shnaya harmony in D minor, and glimpses of his mind happened quite often - he picked up 20-25 chords correctly, which against the general sad background and taking into account the “cunning” chords of comrade. Chigrakov is not bad. But why did he replace almost all A with F # and F # m? Nonconformist, however.
In general, it was clear that we had to dig further.
Why do the above methods work so poorly? If you know how to play something, imagine that you are offered to pick up a song, playing individually fragments of half a second in length, and not in order, but at random, so that you cannot take into account the already selected part when working with the next “quantum." Will you get something? I would venture to suggest that even if you have absolute hearing, the result will be disastrous.
Therefore, the authors of the work mentioned above (as well as other similar studies) suggest, after evaluating the "similarity" of the chromogram to different chords, to use, as they say, musical knowledge. For them, this secret knowledge boils down to the fact that the probability of meeting one of the chords that has already been encountered earlier in the composition (or rather, in a certain time window of it) is higher than such a probability for previously not encountered chords. At the same time, they take into account the “fuzziness” of chord recognition, the frequency of their occurrence in the analyzed window, etc.
In general, this is equivalent to such empirical knowledge "Songs are usually written in one, at most two keys, and therefore the set of chords used in them is limited."
I decided to go a little different way. I proceeded from the following:
With this assumption, you can use Markov chains to simulate the process of changing chords.
Imagine a system with a finite (or infinite but countable, i.e. "numbered") the set of states S . Let her “live” in discrete time, which has an initial “0th” moment and then each moment of time can be designated by its number - t 1 , t 2 , etc. Let the probability distribution for the initial state of the system P 0 (S i ) and the transition probabilities P (S (t n ) = S i | S (t n-1 ) = S j ). Such a random process, when the probability of a system transitioning to a specific state depends only on its current state, is called a Markov chain (in our case, with discrete time). If the probability distribution of the transitions does not depend on the time t n , the Markov chain is called homogeneous.
I fiddled with the distribution of the first chord and transitions from the heap of songs, unpacking a 40-megabyte chm nickname with a name like "all Russian rock with chords." However, the authors “drive” - there are no chords there even for some Kino and Crematorium albums, not to mention such exotic as Pulatova (there are texts, interestingly). But nevertheless, the array of selections is quite large, so the sample can be considered representative enough to estimate the parameters of our Markov chain. The analysis of the songs went from 10 pm to at least 5 am the next day, however, on the "atomic" netbook.
Move on. Remember Bayes' theorem - P (Chord | Chroma) = P (Chroma | Chord) * P (Chord) / P (Chroma) ? Using our Markov chain, we will evaluate P (Chord) , and P (Chroma | Chord)let it still be evaluated by naive Bayesian and "scalar" classifiers. Regarding the latter, we don’t really need a “real” probability here, therefore, we can consider our scalar product of chromograms and the mask of the chord as the “probability” that this chromogram corresponds to this chord. Well, you can still normalize these scalar products so that their sum for all chords is 1, although this is not necessary to find the maximum, and I scored it.
So, we can evaluate P (Chord (t 0 ) = C i ) based on a statistical estimate of the distribution of the first chords in the Russian rock collection (in this way we take into account actually different frequencies of using different keys). For the following windows, we can evaluate P (Chord (tn ) = C n ) as
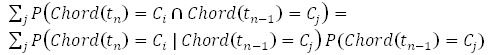
where P (Chord (t n-1 ) = C j ) were evaluated in the previous step. We find the maximum value of this expression for all i and get the most likely chord. Please note - this takes into account the fact that we do not know reliably which chord sounded in the previous window, we only have an estimate of the probability distribution of various chords.
As for the likelihood of a “non-transition” from chord to chord, I added the appropriate command line parameter and select the optimal value manually. In fact, this probability depends on the ratio between the durations of the analyzed stream window and the musical tempo of the work.
The above algorithm with the correct selection of parameters has proved to be very stable. Straying from the right path when trying to "cattle" of some complex harmony, he honestly tries to return from the split, and most often he succeeds.
Optimization number 1. It was noticed that the classifiers "blows the roof", as a rule, in different fragments. It is also noted that if the classifier has determined the same chord several times in a row, then this chord is usually correct. These observations led to the appearance of the following optimization: we start a ring buffer for several chords and shove the chords there from the output of both classifiers. If once again the classifiers issued different chords for the same window, we take the one that is more often found in the buffer (well, if the same frequency occurs or does not occur at all, then the first of two).
Optimization number 2.Different keys are used in music (especially in the guitar, where fingering depends on them) with different frequencies. Basically, people, of course, love those with fewer alteration icons in the key - i.e. in A minor / C major, E minor / G major, D minor / F major, or, as a last resort, B minor / D major.
Because of this, the statistics on transitions between chords for the most common keys are “better” than for less common ones. Hence the possibility of “virtual transposition” - the command line switches, which tells the program “pick up the chords in the key you see, but take the transition probabilities as if everything sounds n semitones lower / higher”.
This approach is often used for manual selection - for example, we know that the song is in D minor, but we select chords in A-minor, mooing the melody one and a half tones lower, because what kind of chords are there in this D-minor - you still need to figure it out and still fingers keep the barre tired all the time.
The results of this stage are as follows: when applying the approach described above with both optimizations, it was possible to select chords for the songs of O. Pulatova “In a Dream” (except for the second part of the introduction) and “River of Times” (introduction and couplet; tonality is a kind of cross between minor) with a reliability of selection of about 70% or even a little more. Hurrah!
As for the second half of the introduction to "In a Dream" - the optimal implementation, apparently, would be to go to Odessa, accidentally meet the author there, ask her for chords, hardcode.
The Viterbi algorithm allows, according to indirect data (well, that is, in our case, according to chromograms) for a certain period of the life of the Markov chain, to obtain the most probable sequence of states (chords), passed by the process for this period. The algorithm is very simple, and I tried to implement it, but, apparently, I do not know how to cook it. Depending on the likelihood of a "non-transition", it either sticks to one chord or gives out a bunch of garbage (though usually in the correct key). Maybe this is due to the requirement "the results of the observations must 1-to-1 correspond to the passed" steps "of the random process." But, on the other hand, who prevents us from believing that our “step” has a fixed physical lifetime, and then the next step comes, even if the condition has not changed? I do not know. Or maybe
That's it. Thanks for attention!
Sources can be taken here: https://github.com/t0mm/ChordDetector
So, the statement of the problem:
There is a file with digitized music (not MIDI!), For definiteness mp3. It is necessary to determine the sequence of the change of chords, forming the harmony of the work. By “music” we mean typical European music - 12 semitones in an octave, harmony mainly based on major / minor triads, reduced and increased triads and * sus2 / * sus4 (chords with the 2nd / 4th stage instead of 3 are also acceptable) th).
Bit of theory
Notes in European music are sounds with frequencies from a fixed set (more on that below), while sounds differing in frequency by 2, 4, 8 ... times are indicated by one note. Musical intervals are fixed ratios of frequencies of two notes. This interval system is arranged as follows:
- the interval f1 / f2 == 2 is called an octave
- an octave is divided into 12 equal (in the "logarithmic" sense) minimum intervals, called small seconds or semitones. If the notes n1 and n2 make up a small second, then their frequencies f1 and f2 are related as
f2 / f1 = 2 1/12 . Two small seconds make up a big second, three make up a small third, four make a big third, seven make a fifth. The remaining intervals we do not need.
The letter notation in the notation accepted in Russia is as follows:
A - A, B - B flat, H - B, C - C, D - re, E - mi, F - fa, G - salt.
# (sharp) indicates an increase in frequency by 1/2 tone, b (flat) indicates a decrease by 1/2 tone. On an octave of 12 halftones, the notes are displayed like this:
ABHCC # / Db DD # / Eb EFF # / Gb GG # / Ab
Octaves have tricky names and numbers, but we are not interested, it’s enough to know that the frequency of the “a” note of the first octave is 440 Hz The frequencies of the remaining notes are easy to calculate based on the above.
The chord consists of several simultaneously sounding notes. At the same time, they can be extracted sequentially (arpeggio, it’s also “busting” in the jargon of yard guitarists), but since the sound does not calm down immediately, the notes manage to sound together for some time. In the European tradition, the most common chords of three sounds (actually triads). Major and minor triads are commonly used. In major chords, the 1st (beginning with the lowest) and 2nd notes form a large third, and the 2nd and 3rd - a minor, in minor, on the contrary, the 1st and 2nd - a small, 2nd and 3rd is big. The 1st and 3rd notes in both cases form a fifth. There are also reduced (two small thirds) and increased (two large thirds) triads, and sustained chords (I don’t know how they are in Russian) are quite common in rock music - sus2 with a 2nd note in 1/2 tones below, than minor and sus4 with the 2nd note, 1/2 tone higher than the major. The 3rd note in both versions of the sustained chord forms with the 1st regular fifth.
In one piece of music, it is rare that all 12 notes are used to the same extent. As a rule, there is a “basic” subset of 7 notes, and the notes are mainly taken from it. Such a subset can be determined using a mask of 0 and 1 superimposed on a vector of 12 notes. If you exaggerate, such a subset is called tonality, and the set of all possible cyclic shifts of the tonality mask is called the fret. In European music, two frets are mainly used:
- major with mask 1 0 1 0 1 1 0 1 0 1 0 1
- minor with mask 1 0 1 1 0 1 0 1 1 0 1 0
The chords used in a particular key are built, if possible, from the notes of that key.
You may notice that the masks of major and minor differ with accuracy to a shift. Accordingly, the chords, for example, in C major and the corresponding A-minor are used the same (this is what we so unobtrusively returned to our task).
The note “beginning with which” the mask was applied is called a tonic. The number of the note entering the key, starting with the tonic, is called the step. When talking about the structure of a particular chord, the steps are counted from its 1st note (the so-called main tone).
Chords are traditionally indicated by the symbol of its fundamental tone, to which a chord type suffix is assigned to the right without a space. For example, notes A (a):
- A - major triad
- Am - minor triad
- A5 + - increased triad (it has a different, official designation, but I often come across this)
- Am5- - reduced triad (again, there are other notations)
- Asus2 - sustained with the second stage
- Asus4 - sustained with the fourth step
[Offtopic for those who studied at the music school] I heard about the differences between melodic and harmonic minors and about the problems of temperament (returning to the roots of the 12th degree), too. But, as it seems to me, within the framework of this article, the above simplified description of the subject area is enough.
Let's move on to practice
So we need:
- unzip mp3 into an array of numbers, which is a graph of the amplitude of sound versus time
- determine what notes sound at any given moment in time
- determine which chords form these notes
I did not bother with the first task - I took a ready-made sox sound converter that supports both mp3 and “raw” formats, where the sound is stored just like a graph of the amplitude versus time. In * nix-systems it is installed trivially with the help of the package manager - on Ubuntu it looks like this:
$ sudo apt-get install sox
$ sudo apt-get install lame
The second line puts LAME mp3 encoder.
Under Windows, sox can be downloaded from the official site, but then you will have to suffer a bit with searching the Internet for suitable LAME DLLs.
With the second task, in principle, everything is simple. In order to understand what notes sound at a particular moment in time, it is necessary to perform a spectral analysis of a piece of our array with amplitudes in the index range corresponding to a small neighborhood of this moment. As a result of spectral analysis, we obtain the amplitudes for the set of frequencies that "make up" the analyzed piece of sound. It is necessary to filter the frequencies, selecting those that are close to the frequencies of the notes, and select the largest of them - they correspond to the loudest notes. I say “close”, not “equal”, because in nature there are no perfectly tuned musical instruments; this is especially true for guitars.
For spectral analysis of a discrete representation of a time-varying signal, you can use the window fast Fourier transform. I tore off the simplest non-optimized FFT implementation from the Internet, transferred it from C ++ to Scala, and took the Hann function as a window function. You can read more about this in the relevant Wikipedia articles.
After receiving an array of amplitudes in frequencies, we select the frequencies in the neighborhood (by default, its size is 1/4 semitone) around the frequency of each note in a certain range of octaves (experience shows that it is best to analyze octaves with a large second or third octave). In each such neighborhood, we calculate the maximum amplitude and consider it as the loudness of the corresponding note. After that, we summarize the "volume" of each note in all octaves and, finally, divide all the elements of the resulting array of 12 "volumes" by the value of its maximum element. The resulting vector of 12 elements in different sources is called a chromogram.
Here it is impossible not to mention a couple of subtleties. Firstly, for different works, the convenient range of octaves for analysis is different - for example, the introduction to My Friend Of Misery Metallica is played, apparently, on the bass and sounds pretty low; in the upper octaves there are mostly overtone and left frequencies from distortion, which only interfere.
Secondly, there are no perfectly tuned guitars in nature. This is probably due to the fact that the strings, depending on the fret, differently lengthen when clamped (well, in general, the fingers press on them unevenly). In addition, this instrument is quickly upset during the game on it. For example, in Letov’s acoustic recordings with tuning, the finish is complete - well, this can be understood. And here is why in the same My Friend Of Misery one I don’t remember which note stably sounds exactly a quarter tone, either higher or lower - a mystery. And even with well-tuned guitars on the recordings of various tenants, the structure usually does not coincide with the canonical in overall height - i.e. The “la” of the first octave may not be exactly 440 hertz.
To neutralize such jambs, it was necessary to provide in the program the possibility of compensating for the general shift of the system. But there is nothing to be done with the frustration of individual strings and the overall inherent “inability” of guitars. So an ambush with the main rock instrument.
[Another offtopic] The set of compositions that will be mentioned in this, so to speak, "essay" may seem somewhat wild. However, the selection criteria were very simple:
- the work should begin with the introduction of "on the same chords" (without a complex melody)
- it is desirable that the main instrument in the arrangement is a piano or, even better, electronic keys. If the arrangement is guitar, the recording should be studio (see above about the features of this wonderful instrument)
That is, I tried to simplify my life, at least at the beginning of torment with the selection of each song.
But back to our three tasks.
The remaining, third, task seems trivial - we select the three loudest notes and add a chord from them. But in reality, nothing will turn out that way (well, not at all - see below, but there is very little sense from this approach). And in general, this task turned out to be the most difficult of all.
Now, first things first.
Naive chord definition method
At first, I did exactly as described above - after analyzing each “window” of the sound file, I selected the three loudest notes and tried to create a chord from them.
The first composition on which I tried to experience the magical effect of my miracle program was Letov’s in Paradise by Letov in the version from the Tyumen bootleg aka “Russian Field of Experiments (acoustics)”. The introduction to this song is a slot in a minor minor triad for about a dozen seconds.
However, having run my program at the beginning of this song, I did not find a single (!) Em chord in the output. Basically nothing was determined, occasionally all completely “left” nonsense climbed. What was the matter, it was not clear. I had to implement the frequency dump of each window in the form of a histogram of the symbols '*'. From the histogram, it was first found out that the guitar structure differs by about a quarter tone from the face value. OK, enter the correction. Hurrah! The notes E and H began to be determined - the 1st and 3rd notes in the chord. But where is G?
Further investigation of the dump revealed the following:
- the bass “mi” spectrum is spread from D to F # with several local maxima, as a result, the second highest volume note is sometimes D #
- From somewhere aggressively climbs "la" (maybe this is the fifth quinton from "mi"?). And when D # disappears somewhere, it takes its place. In this case, there is a chance to get in the output of Asus2, which is the same as Esus4, up to the choice of a bass note (in music this is called “appeal”). Already something, but I need something Em!
- The “salt” in the Em chord in its standard fingering (in the first position) sounds on only one string - on the third (for comparison, “mi” - on three). And in this clandestine record, apparently, due to the poor quality of the equipment, most of the frequencies were cut very much.
Apparently, that's why G rarely happens to even be in 4th place.
In general, I scored on Letov’s selection. In general, it became clear that you need to look for another way to analyze the chromogram. But, in fairness, it must be said that at least one fragment exists in nature that is normally selected in this way. This is an introduction to Olga Pulatova’s song “Pink Elephant”, which is an arpeggio on electronic keys. The program on it produced the following result (after manually clearing artifacts formed “at the junctions” of chords and removing successive repeats): Fm Cm (c db f) Ab Abm Eb Ebm B. ((c db f) - a non-standard consonance that without special damage can be replaced by Db). Independent verification shows that the chords are correct.
Here it is, the power of a dull piece of iron! With Olin’s hands, a sophistication with three tonalities of 8 chords can be selected for a long time and unsuccessfully ... But, alas, I repeat, this is the only composition I know that can be successfully analyzed in this way. The reasons for the failure are understandable - on the one hand, the overtone and the “left” frequencies of the guitar “lotions” interfere, on the other hand, chords rarely sound on their own, on top of them with a larger, moreover, usually there is a melody in volume - vocals, guitar / keyboard solo, etc. .P. A melody rarely ever completely fits in with harmony in notes - it is too sad, as a result, “temporary” harmonies are constantly formed in the stream of sound, which do not correspond to any canonical chords, and everything breaks.
A little less naive way
I had to google and dig. The topic turned out to be quite popular in the scientific and semi-scientific environment, and in nature there is something to read about it, if you are not afraid of terms such as hidden Markov model, naive bayesian classifier, gaussian mix, expectation maximization etc. At first I was afraid to climb into all this jungle. Then he sorted it out slowly.
Here lies the article that turned out to be the most useful for me:
http://academia.edu/1026470/Enhancing_chord_classification_through_neighborhood_histograms
To begin with, the authors propose not to search for exact matches with chords, but to evaluate the degree of “proximity” of the chromogram to the chord. They offer three ways to evaluate such proximity:
- maximum scalar chromogram product per chord pattern
- naive bayesian classifier
- estimation of the parameters of a Gaussian mixture using the expectation maximization method and using the Mahalanobis distance as a measure of the proximity of chromograms
The third method, after a somewhat more detailed study of other sources, I threw back - judging by the conclusions from the above article, it gives results slightly better than the trivial first method, and hemorrhoids with matrix arithmetic, calculation of determinants, etc. many.
But the first two I implemented.
The first way is super simple. Suppose we have a chord (for definiteness Am) and a chromogram. How to determine how much the chromogram is “similar” to a chord?
We take a mask of notes that sound in a chord - like the one we painted for tonality. For Am, it will be 1 0 0 1 0 0 0 1 0 0 0 0. Multiply this mask scalarly by the chromogram, as if it were 12-dimensional vectors (well, that is, we stupidly summarize the elements of the chromogram with those indices for which one is in the mask) . Voila - here it is, a measure of "similarity." We sort through all the chords that we know, we find the one with the greatest “similarity” - we believe that it sounds.
The second method in implementation is a little more complicated, but requires training data. It is based on Bayes theorem. On the fingers, it looks like this.
There is the concept of conditional probability: the conditional probability P (A | B) is the probability of event A , provided that event B has occurred. This value is determined by this identity:P (AB) == P (A | Bed and) * P (Bed and) , where P (AB) - probability of simultaneous occurrence of the events A and Bed and .
Hence:
P (AB) == P (A | B) * P (B)
P (AB) == P (B | A) * P (A)
That is, provided that P (A)
P (B | A) == P (A | B) * P (B) / P (A)
This is Bayes' theorem.
How do we use this? We rewrite the statement of the theorem in the notation convenient for our problem:
P (Chord | Chroma) = P (Chroma | Chord) * P (Chord) / P (Chroma) ,
where Chord is a chord, Chroma is a chromogram
If we find out somewhere the distribution of chromograms depending on the chord, then we can find the most plausible chord for a given chromogram by maximizing the product P (Chroma | Chord) * P (Chord) - since we have a chromogram, and P (Chroma) , therefore, a constant.
It remains to understand where to get the distributions of P (Chroma | Chord) . You can, for example, let the program “listen” to the recordings of specific knownly known chords so that it evaluates these distributions on their basis. But there is a nuance. The probability of getting a specific value of the chromogram on the “training” examples is negligible - simply because there are very, very many possible values. As a result, when using learning outcomes for real work in the vast majority of casesP (Chroma | Chord) for all values of Chord will be equal to zero, and there will be nothing to maximize.
It is possible (and necessary) to simplify the chromograms before classification, for example, by dividing the relative amplitude range [0, 1], on which the components of the chromogram are defined, say, into 3 parts (with the meaning “almost as loud as the loudest note”, “somewhat quieter than the loudest note "," quite quiet compared to the loudest note "). But still there will be too many options.
The next thing that can be done is to assume that the probability distribution of each component of the chromogram is independent of the other components. In this case, P (Chroma | Chord) = P (c 1 | Chord) * ... * P (c 12 | Chord) , where c1 ..c 12 - components.
chromograms, and for this particular case we get the following formulation of Bayes's theorem:
But P (c i | Chord) can already be extracted even from the meager amount of training data - provided, of course, “simplify” the chromogram by limiting the domain of definition of ci to three values, as we agreed above.
It remains to take P (Chord) from somewherefor all the considered chords. It doesn’t matter - for this, any collection of songs with chords is suitable, the main thing is that there are a lot of songs, and they were different authors.
Classifier based on maximizing the expression P (c 1 | Chord) * ... * P (c 12 | Chord) * P (Chord)according to the Chord parameter , and is called the naive Bayesian classifier. And in this particular case, its “naivety” is significant, since in reality the components of the chromogram are dependent random variables - for example, because of the same overtones. However, as we will see later, this approach works.
All this is easily implemented - the code of the classifier itself and the “subsystem” of its training are much less than the description given here. I taught him on a set of major and minor grand piano chords from some free sample site and a collection of the author's song of the 90s with chords (the first that was found on the Internet as a single text file).
Now about the results of field trials. In the tests participated, in addition to the already mentioned My Friend Of Misery and "Pink Elephant", the following compositions:
- Chizh & Co "Assol". Acoustic guitar, “cunning” chords, the first half of the song in D minor with not too strong absences in some places
- E. Letov “Soldiers are not born” in the version from the concert collection “Music of Spring”. Acoustic guitar, seemingly tuned ... Chords are the usual triads, marching “battle”, all in one key. Recording, albeit a concert, of good quality
- O. Pulatova “In a Dream” from “Home Records”. Acoustic piano, terrible recording quality; begins with the usual triads, possibly with a modified bass, then the melodic decorations begin. There are some ways out of the pitch by ear, but not very radical ... Although the “Elephant” by ear is not very radical ...
What happened. Both classifiers work very twitchy, all the time jumping from chord to chord. Naive Bayes is a little more stable than the maximum of the scalar product, but it seems that only because it “knows” fewer chords (only major and minor). Since he, in contrast to the “scalar” brother, “knows” the probabilities that various chords meet in the author’s, damn, song of the 90s, he behaves somewhat redneckly, trying, roughly speaking, to stick “three thieves” everywhere . Glimpses of the mind are found in both classifiers, but for some reason, as a rule, on different fragments of the same work. Best of all, they dealt with Misery. Bayes periodically rather steadily gave out steam locomotives Dm and Am, which is correct (there is harmony like Dsus2 / E Am / E many, many times; / E is with bass “I” in the sense).
Something managed to be pulled out of the “In a dream”. Despite the poor sound quality, almost correct chords of the entry Cm Eb Bm (in fact, the last B chord, as it should be in the minor minor) and the couplet - Cm Gm Cm Gm Ab F Ab F. The second, “decorated”, part of the entry drowned in garbage (looking ahead - I still did not pick it up, more advanced classification methods also give nonsense).
From “Soldiers are not born” it was not possible to get anything at all ... Why - I do not understand. In dumps of a spectrum garbage. But it sounds normal by ear and you can pick it up manually - Am CGH is there in the introduction, however, I'm not sure about the tonality - the well-known beast has stepped in my ear).
With "Assoll" naive Bayes coped better. He clearly liked KSP-shnaya harmony in D minor, and glimpses of his mind happened quite often - he picked up 20-25 chords correctly, which against the general sad background and taking into account the “cunning” chords of comrade. Chigrakov is not bad. But why did he replace almost all A with F # and F # m? Nonconformist, however.
In general, it was clear that we had to dig further.
We are in flight, and we have nothing to lose but chains. But not his own, but Markov
Why do the above methods work so poorly? If you know how to play something, imagine that you are offered to pick up a song, playing individually fragments of half a second in length, and not in order, but at random, so that you cannot take into account the already selected part when working with the next “quantum." Will you get something? I would venture to suggest that even if you have absolute hearing, the result will be disastrous.
Therefore, the authors of the work mentioned above (as well as other similar studies) suggest, after evaluating the "similarity" of the chromogram to different chords, to use, as they say, musical knowledge. For them, this secret knowledge boils down to the fact that the probability of meeting one of the chords that has already been encountered earlier in the composition (or rather, in a certain time window of it) is higher than such a probability for previously not encountered chords. At the same time, they take into account the “fuzziness” of chord recognition, the frequency of their occurrence in the analyzed window, etc.
In general, this is equivalent to such empirical knowledge "Songs are usually written in one, at most two keys, and therefore the set of chords used in them is limited."
I decided to go a little different way. I proceeded from the following:
- firstly, it should be taken into account that with a small size of the window analyzed using the Fourier transform, it is likely that the chord between two consecutive windows does not change (several windows in a row fall into the period of one chord)
- secondly, the probabilities of transitions from one chord to another for each pair of specific chords are different. In fact, of course, the probability of meeting a particular chord in the next place in the sequence depends on a longer “history” (for example, if we hesitate between G and Gm, then after Am Dm, there will most likely be G, and after B Dm, it’s more likely Gm). But such a model seemed to me too complicated to implement, and I decided to limit myself to taking into account only one previous chord.
With this assumption, you can use Markov chains to simulate the process of changing chords.
Imagine a system with a finite (or infinite but countable, i.e. "numbered") the set of states S . Let her “live” in discrete time, which has an initial “0th” moment and then each moment of time can be designated by its number - t 1 , t 2 , etc. Let the probability distribution for the initial state of the system P 0 (S i ) and the transition probabilities P (S (t n ) = S i | S (t n-1 ) = S j ). Such a random process, when the probability of a system transitioning to a specific state depends only on its current state, is called a Markov chain (in our case, with discrete time). If the probability distribution of the transitions does not depend on the time t n , the Markov chain is called homogeneous.
I fiddled with the distribution of the first chord and transitions from the heap of songs, unpacking a 40-megabyte chm nickname with a name like "all Russian rock with chords." However, the authors “drive” - there are no chords there even for some Kino and Crematorium albums, not to mention such exotic as Pulatova (there are texts, interestingly). But nevertheless, the array of selections is quite large, so the sample can be considered representative enough to estimate the parameters of our Markov chain. The analysis of the songs went from 10 pm to at least 5 am the next day, however, on the "atomic" netbook.
Move on. Remember Bayes' theorem - P (Chord | Chroma) = P (Chroma | Chord) * P (Chord) / P (Chroma) ? Using our Markov chain, we will evaluate P (Chord) , and P (Chroma | Chord)let it still be evaluated by naive Bayesian and "scalar" classifiers. Regarding the latter, we don’t really need a “real” probability here, therefore, we can consider our scalar product of chromograms and the mask of the chord as the “probability” that this chromogram corresponds to this chord. Well, you can still normalize these scalar products so that their sum for all chords is 1, although this is not necessary to find the maximum, and I scored it.
So, we can evaluate P (Chord (t 0 ) = C i ) based on a statistical estimate of the distribution of the first chords in the Russian rock collection (in this way we take into account actually different frequencies of using different keys). For the following windows, we can evaluate P (Chord (tn ) = C n ) as
where P (Chord (t n-1 ) = C j ) were evaluated in the previous step. We find the maximum value of this expression for all i and get the most likely chord. Please note - this takes into account the fact that we do not know reliably which chord sounded in the previous window, we only have an estimate of the probability distribution of various chords.
As for the likelihood of a “non-transition” from chord to chord, I added the appropriate command line parameter and select the optimal value manually. In fact, this probability depends on the ratio between the durations of the analyzed stream window and the musical tempo of the work.
The above algorithm with the correct selection of parameters has proved to be very stable. Straying from the right path when trying to "cattle" of some complex harmony, he honestly tries to return from the split, and most often he succeeds.
A couple of small optimizations
Optimization number 1. It was noticed that the classifiers "blows the roof", as a rule, in different fragments. It is also noted that if the classifier has determined the same chord several times in a row, then this chord is usually correct. These observations led to the appearance of the following optimization: we start a ring buffer for several chords and shove the chords there from the output of both classifiers. If once again the classifiers issued different chords for the same window, we take the one that is more often found in the buffer (well, if the same frequency occurs or does not occur at all, then the first of two).
Optimization number 2.Different keys are used in music (especially in the guitar, where fingering depends on them) with different frequencies. Basically, people, of course, love those with fewer alteration icons in the key - i.e. in A minor / C major, E minor / G major, D minor / F major, or, as a last resort, B minor / D major.
Because of this, the statistics on transitions between chords for the most common keys are “better” than for less common ones. Hence the possibility of “virtual transposition” - the command line switches, which tells the program “pick up the chords in the key you see, but take the transition probabilities as if everything sounds n semitones lower / higher”.
This approach is often used for manual selection - for example, we know that the song is in D minor, but we select chords in A-minor, mooing the melody one and a half tones lower, because what kind of chords are there in this D-minor - you still need to figure it out and still fingers keep the barre tired all the time.
The results of this stage are as follows: when applying the approach described above with both optimizations, it was possible to select chords for the songs of O. Pulatova “In a Dream” (except for the second part of the introduction) and “River of Times” (introduction and couplet; tonality is a kind of cross between minor) with a reliability of selection of about 70% or even a little more. Hurrah!
As for the second half of the introduction to "In a Dream" - the optimal implementation, apparently, would be to go to Odessa, accidentally meet the author there, ask her for chords, hardcode.
Viterbi Algorithm
The Viterbi algorithm allows, according to indirect data (well, that is, in our case, according to chromograms) for a certain period of the life of the Markov chain, to obtain the most probable sequence of states (chords), passed by the process for this period. The algorithm is very simple, and I tried to implement it, but, apparently, I do not know how to cook it. Depending on the likelihood of a "non-transition", it either sticks to one chord or gives out a bunch of garbage (though usually in the correct key). Maybe this is due to the requirement "the results of the observations must 1-to-1 correspond to the passed" steps "of the random process." But, on the other hand, who prevents us from believing that our “step” has a fixed physical lifetime, and then the next step comes, even if the condition has not changed? I do not know. Or maybe
That's it. Thanks for attention!
Sources can be taken here: https://github.com/t0mm/ChordDetector