DIY PACS server
Not so long ago, our company completed work on the implementation of a PACS server ( Picture Archiving and Communication System ) in one of the medical diagnostic centers in our city. Before that, there was an open source PACS server - dcm4chee, which did not shine with high speed, since it is written in Java. In addition, one of the requirements of the customer was to have access to the internal structure of the server. Therefore, it was decided to write your own. In addition, the company had experience in similar developments of both client and server parts of PACS systems, so the compromise was to create our own PACS archive that meets customer requirements. I had to deal with most of the server core implementation, and during this time I gained specific experience in this area, which I want to share with the Habra community. But first things first.
For a general understanding, consider the role of the PACS system in the diagnostic center. Any diagnostic center has diagnostic equipment: MRI, CT scanners, ultrasound stations or ECG devices (any of these devices in terms of the DICOM protocol is called Modality) and diagnostic software ( OsiriX was used by our doctors ). Having received the images on the tomograph, you must send them to the diagnostic station. Obviously, this requires some kind of integrating link, which collects images from tomographs, ultrasound stations, ECG devices, is able to search for them and transmit images over the network. Such a link are PACS servers:
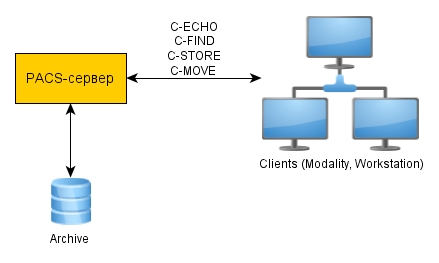
Obviously, a single protocol is needed for the interaction of diverse medical equipment. And just such a protocol is DICOM ( Digital Imaging and Communications in Medicine ), which over the past 20 years has been seriously improved, which made it easy to integrate medical equipment into a common information system. Almost all medical device manufacturers follow this protocol. Therefore, DICOM protocol support was a natural requirement for a PACS server. It was decided to implement a multi-threaded highly loaded PACS, capable of working in a cluster. The server was developed in C ++ and the most adequate library for working with the DICOM protocol, written in C ++ - DCMTK was used today. Thanks to this library, it became possible to quickly implement highly loaded PACS-systems.
The database in the PACS-system allows you to store information about stored images and search them. Images also need to be able to be transmitted over the network, and with it meta-information about the image (who is in the picture, in which clinic they were produced, who conducted the research, etc.). For these purposes, the DICOM protocol provides a special 4-level data model, which you can briefly learn about here.. A complete list of all possible file attributes can be found on the official protocol website [1]. In the images obtained from different devices, the list of these attributes will be different, which is completely normal. However, some attributes remain mandatory to support universal image search. There are a few of them - there are ten in total, among them Patient Name, Patient ID, Patient Birthday, Modality Type (CT, MRI, ultrasound, etc.), Study Date (date of study), etc. In addition to the required parameters, there are optional ones, there are quite a lot of them to support them in the database, as practice shows, is superfluous.
The presence of a large number of optional parameters in the meta-information of images is one of the drawbacks of the DICOM protocol. Some devices set some parameters, some others. Therefore, supporting them in the database for searching is pointless. As a result, having worked on several options, we settled on this DB option:
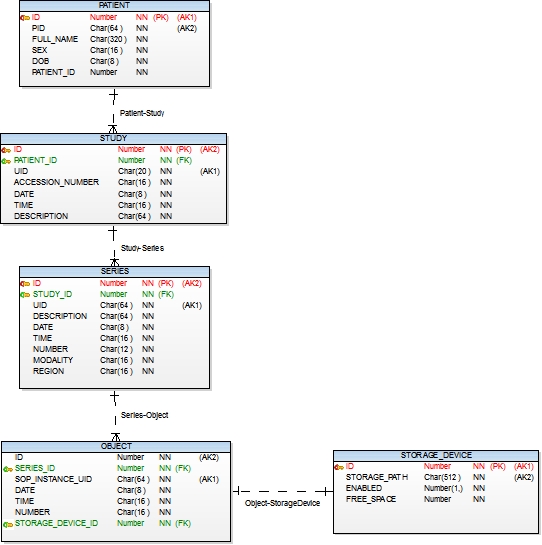
As you can see, the database schema corresponds to the multilevel structure of DICOM files. One patient can have many stages (read research). A study is a series of episodes defined by a research protocol. The series stores many images.
Let us briefly consider the main functions (services) of a standard PACS-system, almost all of which I have already mentioned. Since any interaction between workstations and the PACS-system is client-server, all operations are also implemented in two versions - client and server. There are implementations of both options in DCMTK. PACS implements the server side.
The prefix 'C-' for operations means Composite, which implies that the operation is integral and self-sufficient and is performed without reference to other operations. There are also operations with the prefix 'N -' (N-CREATE, N-SET, N-GET, etc.), which are performed as part of some more general operation (set statuses, inform about the start of the study, etc.). These operations are not relevant to this article.
C-ECHO- a team that allows you to find out the availability of a client on the network. Similar to the ping command in Windows. The implementation of the command is very simple - you just need to send a response with the status STATUS_Success:
where assoc is the connection established by the client, request is an incoming request.
C-STORE - a command that allows you to save images on a PACS server in DCM format.
Here is a piece of code that does this:
Callback storeSCPCallback is triggered for each package, and not for each file. The condition indicates the completion of the file download
I also want to say that the OBJECT table is populated very intensively. One study on an MRI tomograph lasts an average of 20 minutes, during which time a tomograph produces 100-300 images, a CT scanner 500-700 images. Total images per day can reach 1440/20 * 500 = 36000 images per day. In our diagnostic center, there are practically no breaks in the work of tomographs day or night. Therefore, the OBJECT table should store as little data as possible.
C-MOVE - a command that allows you to transfer images from PACS to a workstation or diagnostic station. The command is transmitted by the calling station (source) to the PACS and it indicates which station (destination) the images are to be uploaded to. In the particular case, if source = destination, then the files are simply downloaded.
The C-MOVE command is more versatile than the C-GET command, which only allows you to download images. C-MOVE can download images not only to its own, but also to any other. The command indicates the AETitle of the station to which images are to be uploaded. AETitle is the name of the client, usually in capital letters (for example, CLIENT_SCU). It is installed when the dicom-listener (server) starts.
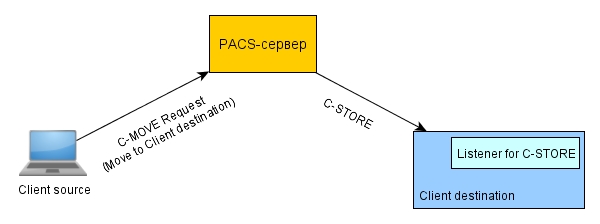
That is, the client initializing the C-MOVE command to the PACS server must launch mini-PACS, which only accepts the C-STORE command. And the PACS server, in turn, must, with the C-MOVE command, establish a new connection with the client, pick up the images from the repository and execute for each of the bottom the client version of the C-STORE command back to the client. By the way, only the C-MOVE command allows you to transfer both compressed images (JPEG) and uncompressed due to the establishment of a new connection.
The C-GET team, however, is able to download images without establishing a new connection and, therefore, without having to raise the server on the client side. In this case, PACS also executes the client version of the C-STORE command, only through the connection established by the C-GET command.
C-FIND- a team that allows you to search images at different levels. That is, there are actually four types of C-FIND commands: C-FIND at the PATIENT level, at the STUDY level, at the SERIES level, and at the IMAGE level.
That is, in the callback you need to fill out the response objects - response parameters and responseDataSet - information about the patient / stage / series / image that needed to be found. The DIMSE_findProvider () function from DCMTK will take care of sending them back to the client.
The C-FIND team is dangerous in that the client may specify too general search criteria and the client will have to give a large amount of information. For example, you can request all stages for the last year. If you try to download all the data to the server first, the server will most likely hang. Therefore, you cannot make large requests; you need to load data as callbacks are triggered. To do this, you need to implement a database query in the form of an iterator and, as callbacks are triggered, call next () and thus take the next object. In addition, the search can be canceled only upon the arrival of the callback, therefore, if the search on PACS hangs for a while on the sample from the database, and the client causes the request to be canceled, then no reaction will occur on the client. This is relevant for patient and stage searches. For series-level searches, this is irrelevant, since the stages containing more than 15 series, we have not seen in practice. Similarly, for searches at the image level - series with more than 1000 images, we have not seen in practice.
So, we examined the main functions of the PACS-system and its role in the overall structure of the diagnostic center. Practical aspects and various aspects of the implementation of medical industrial PACS systems are also highlighted. However, PACS systems are usually not limited to this functionality. There is also a WADO service (Web Access to DICOM Objects) and a service for managing work tasks (Modality worklist), also included in the functions of PACS systems. I hope for someone this article will be useful and save a lot of time.
1. List of all DICOM tags (http://medical.nema.org/Dicom/2011/11_06pu.pdf, page 8).
2. The official page of the DICOM protocol - medical.nema.org/standard.html
3. About PACS systems in Russian - ru.wikipedia.org/wiki/PACS
4. About DICOM in Russian - ru.wikipedia.org/wiki/DICOM
Preamble
For a general understanding, consider the role of the PACS system in the diagnostic center. Any diagnostic center has diagnostic equipment: MRI, CT scanners, ultrasound stations or ECG devices (any of these devices in terms of the DICOM protocol is called Modality) and diagnostic software ( OsiriX was used by our doctors ). Having received the images on the tomograph, you must send them to the diagnostic station. Obviously, this requires some kind of integrating link, which collects images from tomographs, ultrasound stations, ECG devices, is able to search for them and transmit images over the network. Such a link are PACS servers:
Obviously, a single protocol is needed for the interaction of diverse medical equipment. And just such a protocol is DICOM ( Digital Imaging and Communications in Medicine ), which over the past 20 years has been seriously improved, which made it easy to integrate medical equipment into a common information system. Almost all medical device manufacturers follow this protocol. Therefore, DICOM protocol support was a natural requirement for a PACS server. It was decided to implement a multi-threaded highly loaded PACS, capable of working in a cluster. The server was developed in C ++ and the most adequate library for working with the DICOM protocol, written in C ++ - DCMTK was used today. Thanks to this library, it became possible to quickly implement highly loaded PACS-systems.
We design a database
The database in the PACS-system allows you to store information about stored images and search them. Images also need to be able to be transmitted over the network, and with it meta-information about the image (who is in the picture, in which clinic they were produced, who conducted the research, etc.). For these purposes, the DICOM protocol provides a special 4-level data model, which you can briefly learn about here.. A complete list of all possible file attributes can be found on the official protocol website [1]. In the images obtained from different devices, the list of these attributes will be different, which is completely normal. However, some attributes remain mandatory to support universal image search. There are a few of them - there are ten in total, among them Patient Name, Patient ID, Patient Birthday, Modality Type (CT, MRI, ultrasound, etc.), Study Date (date of study), etc. In addition to the required parameters, there are optional ones, there are quite a lot of them to support them in the database, as practice shows, is superfluous.
The presence of a large number of optional parameters in the meta-information of images is one of the drawbacks of the DICOM protocol. Some devices set some parameters, some others. Therefore, supporting them in the database for searching is pointless. As a result, having worked on several options, we settled on this DB option:
As you can see, the database schema corresponds to the multilevel structure of DICOM files. One patient can have many stages (read research). A study is a series of episodes defined by a research protocol. The series stores many images.
The main functions of the PACS system
Let us briefly consider the main functions (services) of a standard PACS-system, almost all of which I have already mentioned. Since any interaction between workstations and the PACS-system is client-server, all operations are also implemented in two versions - client and server. There are implementations of both options in DCMTK. PACS implements the server side.
The prefix 'C-' for operations means Composite, which implies that the operation is integral and self-sufficient and is performed without reference to other operations. There are also operations with the prefix 'N -' (N-CREATE, N-SET, N-GET, etc.), which are performed as part of some more general operation (set statuses, inform about the start of the study, etc.). These operations are not relevant to this article.
C-ECHO- a team that allows you to find out the availability of a client on the network. Similar to the ping command in Windows. The implementation of the command is very simple - you just need to send a response with the status STATUS_Success:
DIMSE_sendEchoResponse(assoc, presID, request, STATUS_Success, NULL)
where assoc is the connection established by the client, request is an incoming request.
C-STORE - a command that allows you to save images on a PACS server in DCM format.
Here is a piece of code that does this:
OFCondition storeSCP()
{
T_DIMSE_C_StoreRQ* req = &m_msg->msg.CStoreRQ;
DcmDataset* dset = 0x0;
OFCondition cond = DIMSE_storeProvider(m_assoc, m_presID, req, NULL, OFTrue, &dset,storeSCPCallback, 0x0, DIMSE_BLOCKING, 0);
if (cond.bad())
Log::error("C-STORE provider failed. Text: %s", cond.text());
return cond;
}
void storeSCPCallback( void* /*callbackData*/,
T_DIMSE_StoreProgress *progress,
T_DIMSE_C_StoreRQ* /*request*/,
char * /*imageFileName*/,
DcmDataset **imageDataSet,
T_DIMSE_C_StoreRSP* response,
DcmDataset **statusDetail)
{
if (progress->state == DIMSE_StoreEnd)
{
if ((imageDataSet != NULL) && (*imageDataSet != NULL))
{
DcmFileFormat dcmff(*imageDataSet);
// some error
if (!commandStore(&dcmff))
response->DimseStatus = STATUS_STORE_Refused_OutOfResources;
delete *imageDataSet;
*imageDataSet = 0x0;
}
}
delete *statusDetail;
*statusDetail = 0x0;
}
bool ServerCoreImpl::commandStore(DcmFileFormat* file)
{
// здесь
// 1. парсим файл, составляем объекты(бины) для таблиц PATIENT, STUDY, SERIES, OBJECT.
// 2. Если такого файла нет в базе, то сохраняем его на диск
// 3. Если пришлось сохранять файл, то оставляем на него ссылку в БД (делаем
// вставку бинов)
// Функция возвращает true, если всё прошло удачно, иначе false
}
Callback storeSCPCallback is triggered for each package, and not for each file. The condition indicates the completion of the file download
progress->state == DIMSE_StoreEnd, then we can save the file. The only difficulty in implementing this command is the choice of the directory structure when saving the file. In order not to store the file path in the OBJECTS table, we calculate it from the rest of the data. We settled on this directory structure: PATH_K_STORAGE / STUDY.DATE (YEAR) /STUDY.DATE (MONTH) /STUDY.DATE (DAY) /STUDY.TIME (HOUR) /PATIENT.PID (first letter) / PATIENT.PID/STUDY .UID / {images}. This hierarchical structure allows you to minimize the number of subfolders, which allows you to work with this directory structure without time lags.I also want to say that the OBJECT table is populated very intensively. One study on an MRI tomograph lasts an average of 20 minutes, during which time a tomograph produces 100-300 images, a CT scanner 500-700 images. Total images per day can reach 1440/20 * 500 = 36000 images per day. In our diagnostic center, there are practically no breaks in the work of tomographs day or night. Therefore, the OBJECT table should store as little data as possible.
C-MOVE - a command that allows you to transfer images from PACS to a workstation or diagnostic station. The command is transmitted by the calling station (source) to the PACS and it indicates which station (destination) the images are to be uploaded to. In the particular case, if source = destination, then the files are simply downloaded.
The C-MOVE command is more versatile than the C-GET command, which only allows you to download images. C-MOVE can download images not only to its own, but also to any other. The command indicates the AETitle of the station to which images are to be uploaded. AETitle is the name of the client, usually in capital letters (for example, CLIENT_SCU). It is installed when the dicom-listener (server) starts.
That is, the client initializing the C-MOVE command to the PACS server must launch mini-PACS, which only accepts the C-STORE command. And the PACS server, in turn, must, with the C-MOVE command, establish a new connection with the client, pick up the images from the repository and execute for each of the bottom the client version of the C-STORE command back to the client. By the way, only the C-MOVE command allows you to transfer both compressed images (JPEG) and uncompressed due to the establishment of a new connection.
The C-GET team, however, is able to download images without establishing a new connection and, therefore, without having to raise the server on the client side. In this case, PACS also executes the client version of the C-STORE command, only through the connection established by the C-GET command.
C-FIND- a team that allows you to search images at different levels. That is, there are actually four types of C-FIND commands: C-FIND at the PATIENT level, at the STUDY level, at the SERIES level, and at the IMAGE level.
void HandlerFind::findSCPCallback ( /* in */
void* callbackData,
OFBool cancelled,
T_DIMSE_C_FindRQ* request,
DcmDataset* requestIdentifiers,
int responseCount,
/* out */
T_DIMSE_C_FindRSP *response,
DcmDataset** responseDataSet,
DcmDataset** statusDetail)
{
// запрос отменён
if (cancelled)
{
strcpy(response->AffectedSOPClassUID, request->AffectedSOPClassUID);
response->MessageIDBeingRespondedTo = request->MessageID;
response->DimseStatus = STATUS_FIND_Cancel_MatchingTerminatedDueToCancelRequest;
response->DataSetType = DIMSE_DATASET_NULL;
return;
}
if (responseCount == 1)
{
//
// при первом запросе инициализируем запрос к БД.
// О критериях поиска и о уровне можно узнать в requestIdentifiers
//
}
/*
здесь запрашиваем очередной объект из базы и заполняем responseDataSet в соответствии с уровнем
*/
if (/*все данные отправили*/)
{
strcpy(response->AffectedSOPClassUID, request->AffectedSOPClassUID);
response->MessageIDBeingRespondedTo = request->MessageID;
response->DimseStatus = STATUS_Success;
response->DataSetType = DIMSE_DATASET_NULL;
return;
}
}
OFCondition HandlerFind::find()
{
OFCondition cond = EC_Normal;
T_DIMSE_C_FindRQ *req = &m_msg->msg.CFindRQ;
FindCallbackData cdata;
cond = DIMSE_findProvider(m_assoc, m_presID, req, findSCPCallback, &cdata, DIMSE_BLOCKING, 0);
if (cond.bad())
Log::loggerDicom.error("C-FIND provider failed. Text: %s", cond.text());
return cond;
}
That is, in the callback you need to fill out the response objects - response parameters and responseDataSet - information about the patient / stage / series / image that needed to be found. The DIMSE_findProvider () function from DCMTK will take care of sending them back to the client.
The C-FIND team is dangerous in that the client may specify too general search criteria and the client will have to give a large amount of information. For example, you can request all stages for the last year. If you try to download all the data to the server first, the server will most likely hang. Therefore, you cannot make large requests; you need to load data as callbacks are triggered. To do this, you need to implement a database query in the form of an iterator and, as callbacks are triggered, call next () and thus take the next object. In addition, the search can be canceled only upon the arrival of the callback, therefore, if the search on PACS hangs for a while on the sample from the database, and the client causes the request to be canceled, then no reaction will occur on the client. This is relevant for patient and stage searches. For series-level searches, this is irrelevant, since the stages containing more than 15 series, we have not seen in practice. Similarly, for searches at the image level - series with more than 1000 images, we have not seen in practice.
Summarize
So, we examined the main functions of the PACS-system and its role in the overall structure of the diagnostic center. Practical aspects and various aspects of the implementation of medical industrial PACS systems are also highlighted. However, PACS systems are usually not limited to this functionality. There is also a WADO service (Web Access to DICOM Objects) and a service for managing work tasks (Modality worklist), also included in the functions of PACS systems. I hope for someone this article will be useful and save a lot of time.
References
1. List of all DICOM tags (http://medical.nema.org/Dicom/2011/11_06pu.pdf, page 8).
2. The official page of the DICOM protocol - medical.nema.org/standard.html
3. About PACS systems in Russian - ru.wikipedia.org/wiki/PACS
4. About DICOM in Russian - ru.wikipedia.org/wiki/DICOM