T2F: project to convert text to face drawing with in-depth training
- Transfer

The project code is available in the repository.
Introduction
When I read descriptions of the appearance of the characters in the books, I was always wondering what they would look like in life. It is quite possible to imagine a person as a whole, but the description of the most conspicuous details is a difficult task, and the results vary from person to person. Many times I couldn’t imagine anything but a very blurred face for a character until the very end of the piece. Only when a book is turned into a film does the blurry face fill with details. For example, I could never imagine exactly how Rachel's face from the book “The Girl on the Train ” looks . But when the movie came out, I was able to match Emily Blunt’s face with Rachel’s character. Surely it takes a lot of time for people involved in the selection of actors to correctly depict the characters of the script.
This problem inspired and motivated me to find a solution. After that, I began to study the literature on depth learning in search of something similar. Fortunately, there were quite a lot of research on the synthesis of images from text. Here are some of those that I based on:
- arxiv.org/abs/1605.05396 “Generative Adversarial Text to Image Synthesis”
- arxiv.org/abs/1612.03242 “StackGAN: Text to Photo-realistic Image with Stacked Generated Adversarial Networks”
- arxiv.org/abs/1710.10916 “StackGAN ++: Realistic Image Synthesis with Stacked Generative Adversarial Networks”
[ Generating adversarial network (GAN) / approx. trans. ]
Having studied the literature, I chose an architecture that was simplified compared to StackGAN ++, and is doing quite well with my problem. In the following sections, I will explain how I solved this problem, and I will share preliminary results. I will also describe some details of programming and training, for which I spent a lot of time.
Data analysis
Undoubtedly, the most important aspect of the work is the data used to train the model. As Professor Andrew Un spoke in his deeplearning.ai courses: “It’s not the one who has the best algorithm but the one who has the best data in the machine learning business.” So began my search for a dataset for people with good, rich, and varied text descriptions. I ran across different data sets - either they were just faces, or faces with names, or faces with descriptions of eye color and face shape. But there were none that I needed. My last option was to use an early project - the generation of a description of structural data in natural language. But such an option would add an extra noise to an already fairly noisy data set.
Time passed, and at some point a new project Face2Text appeared . It was a collection of a database of detailed text descriptions of persons. I thank the authors of the project for the provided data set.
The data set contained textual descriptions of 400 randomly selected images from the LFW database (marked-up faces). Descriptions have been cleared to eliminate ambiguous and minor characteristics. Some descriptions contained not only information about individuals, but also some conclusions drawn from images - for example, “the person in the photo is probably a criminal”. All these factors, as well as the small size of the data set, led to the fact that my project so far only demonstrates the proof of the efficiency of the architecture. Subsequently, this model can be scaled to a larger and more diverse data set.
Architecture
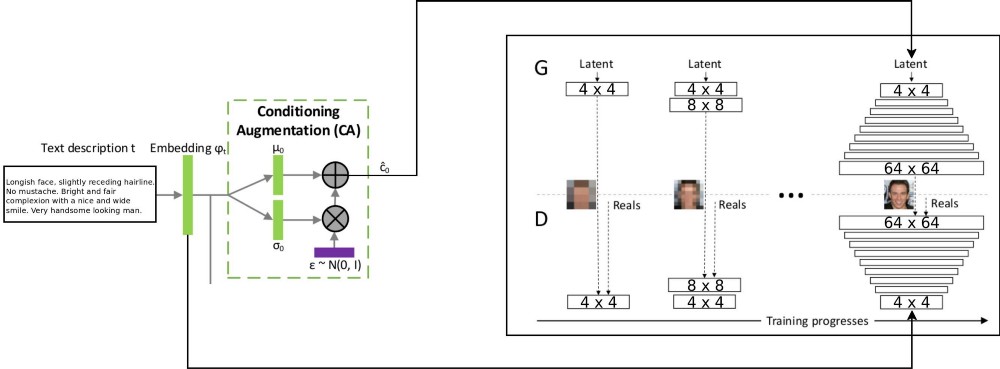
The T2F project architecture combines two stackGAN architectures for text encoding with a conditional increment, and ProGAN ( progressive GSS growth ) for synthesizing face images. The original architecture of stackgan ++ used several GSS with different spatial resolutions, and I decided that this was too serious an approach for any task to match the distribution. But ProGAN uses only one GSS, which is progressively trained at more and more detailed resolutions. I decided to combine these two approaches.
Explanation of the flow of data through is: text descriptions are encoded into the final vector using LSTM (Embedding) (psy_t) network embedding (see diagram). Then the embedding is transmitted through the conditional addition block (Conditioning Augmentation) (one linear layer) to get the text part of the eigenvector (using the VAE repair technique) for the GSS as an input. The second part of the eigenvector is random Gaussian noise. The resulting eigenvector is fed to the GSS generator, and the embedding is fed to the last layer of the discriminator for conditional distribution of compliance. Training processes GSS goes exactly the same way as in the article on ProGAN - in layers, with an increase in spatial resolution. A new layer is introduced using the fade-in technique to avoid the destruction of previous learning outcomes.
Implementation and other details
The application was written in python using the PyTorch framework. I used to work with tensorflow and keras packages, but now I wanted to try PyTorch. I liked using the python debugger for working with the Network architecture - all thanks to the early execution strategy. In tensorflow recently also included the eager execution mode. However, I do not want to judge which framework is better, I just want to emphasize that the code for this project was written using PyTorch.
Quite a few parts of the project seem reusable to me, especially ProGAN. Therefore, I wrote for them a separate code in the form of an extensionPyTorch module, and it can be used on other data sets. It is only necessary to indicate the depth and size of the GSS features. GSS can be trained progressively for any data set.
Workout details
I have trained quite a few versions of the network using different hyperparameters. Work details are as follows:
- The discriminator does not have batch-norm or layer-norm operations, so the loss of a WGAN-GP can grow explosively. I used a drift penalty with lambda of 0.001.
- To control one's own variety obtained from the coded text, it is necessary to use the Kullback – Leibler distance in the generator losses.
- To make the resulting images better match the incoming textual distribution, it is better to use the WGAN variant of the corresponding (Matching-Aware) discriminator.
- The fade-in time for the upper level must exceed the fade-in time for the lower ones. I used 85% as a fade-in value when training.
- I found that higher resolution examples (32 x 32 and 64 x 64) produce more background noise than lower resolution examples. I think this is due to lack of data.
- During a progressive workout, it is better to spend more time on smaller resolutions, and to reduce the time you work with higher resolutions.
The video shows the Timelapse Generator. The video is collected from images with different spatial resolution, obtained during the GSS training session.
Conclusion
According to preliminary results, it is possible to judge that the T2F project is efficient, and has interesting applications. Suppose it can be used to compile identikits. Or for cases when it is necessary to spur the imagination. I will continue to work on scaling this project on data sets such as Flicker8K, Coco captions, and so on.
Progressive GSS growth is a phenomenal technology for faster and more stable GSS training. It can be combined with various modern technologies mentioned in other articles. GSS can be used in different areas of MO.