Evaluate processes in a development team based on objective data.
Software development is considered to be a poorly measurable process, and it seems that in order to effectively manage it, you need a special flair. And if the intuition with emotional intelligence is not developed very well, then the time will inevitably shift, the quality of the product will sink and the speed of delivery will fall.

Sergey Semenov believes that this happens mainly for two reasons.
And offers an approach to assessing and controlling processes based on objective data.
Below is the video and text version of the report by Sergey, who, according to the audience voting, took second place on Saint TeamLead Conf .
About the speaker: Sergey Semenov ( sss0791 ) has worked in IT for 9 years, was a developer, team leader, product manager, now the CEO of GitLean. GitLean is an analytical product for managers, technical directors, and team leaders who are designed to make objective management decisions. Most of the examples in this story are based not only on personal experience, but also on the experience of client companies with a development staff of 6 to 200 people.
About the evaluation of the developers, we have already with my colleague Alexander Kiselyov told in February on the previous TeamLead Conf. I will not dwell on this in detail, but I will refer to the article on some metrics. Today we will talk about the processes and how to control and measure them.
Data sources
If we are talking about measurements, it would be good to understand where to get the data. First of all, we have:
In addition, there is such a cool mechanism, as the collection of various subjective assessments. I will make a reservation that it should be used systematically if we want to rely on this data.

Of course, there is dirt and pain waiting for you in the data - there's nothing you can do about it, but this is not so bad. The most annoying thing is that the data on the work of your processes in these sources can often not be there. This may be because the processes were built in such a way that they do not leave any artifacts in the data.
The first rule we recommend to follow when designing and building processes is to make them so that they leave artifacts in the data. We need to build not just Agile, but make it measurable ( Measurable Agile ).
I'll tell you a scary story that we met at one of the clients who came to us with a request to improve the quality of the product. So that you understand the scale - about 30-40 bugs from production came to a team of 15 developers a week. We started to understand the reasons, and found that 30% of the tasks do not fall into the status of "testing". At first, we thought it was just a data error, or testers did not update the status of the task. But it turned out that really 30% of tasks are simply not tested. Once there was a problem in the infrastructure, due to which 1-2 puzzles in the iteration did not get into testing. Then everyone forgot about this problem, testers stopped talking about it, and over time it turned into 30%. In the end, this led to more global problems.
Therefore, the first important metric for any process is that it leaves data. Be sure to follow this.

Sometimes, for the sake of measurability, you have to sacrifice some of the principles of Agile and, for example, somewhere prefer to write oral communication.
Due date practice proved to be very good, which we implemented in several teams in order to improve predictability. Its essence is as follows: when a developer takes a task and drags it into “in progress”, he must deliver due date when the task is either released or ready for release. This practice teaches the developer to be a conditional micro project manager of his own tasks, that is, to take into account external dependencies and understand that the task is ready only when the client can use its result.
In order for learning to occur, after the due date, the developer needs to go to Jira and put a new due date and leave comments in a specially defined form, why this happened. It would seem, why do we need such a bureaucracy. But in fact, after two weeks of this practice, we unload all such comments from Jira with a simple script and conduct a retrospective with this texture. It turns out a bunch of insights about why deadlines fail. Very cool work, I recommend to use.
Approach from problems
In the measurement of processes, we profess the following approach: we must proceed from the problems. We imagine some ideal practices and processes, and then we will be creative, in what ways they may not work.
It is necessary to monitor the violation of processes , and not how we follow some kind of practice. Processes often do not work, not because people maliciously violate them, but because the developer and manager do not have enough control and memory to follow them all. By tracking violations of the rules, we can automatically remind people about what to do and get automatic controls.
To understand what processes and practices need to be implemented, you need to understand why it should be done in the development team, what the business needs from development. Everyone understands that you need not so much:
That is, predictability, quality and speed are important . Therefore, we will look at all the problems and metrics with regard to how they affect predictability and quality. We’re almost not going to discuss speed, because of the nearly 50 teams we worked with in one way or another, only two could work with speed. In order to increase speed, you need to be able to measure it, and so that it is at least a little predictable, and this is predictability and quality.
In addition to predictability and quality, we introduce such a direction as a discipline . We will call discipline everything that ensures the basic functioning of processes and data collection, on the basis of which the analysis of problems with predictability and quality is carried out.
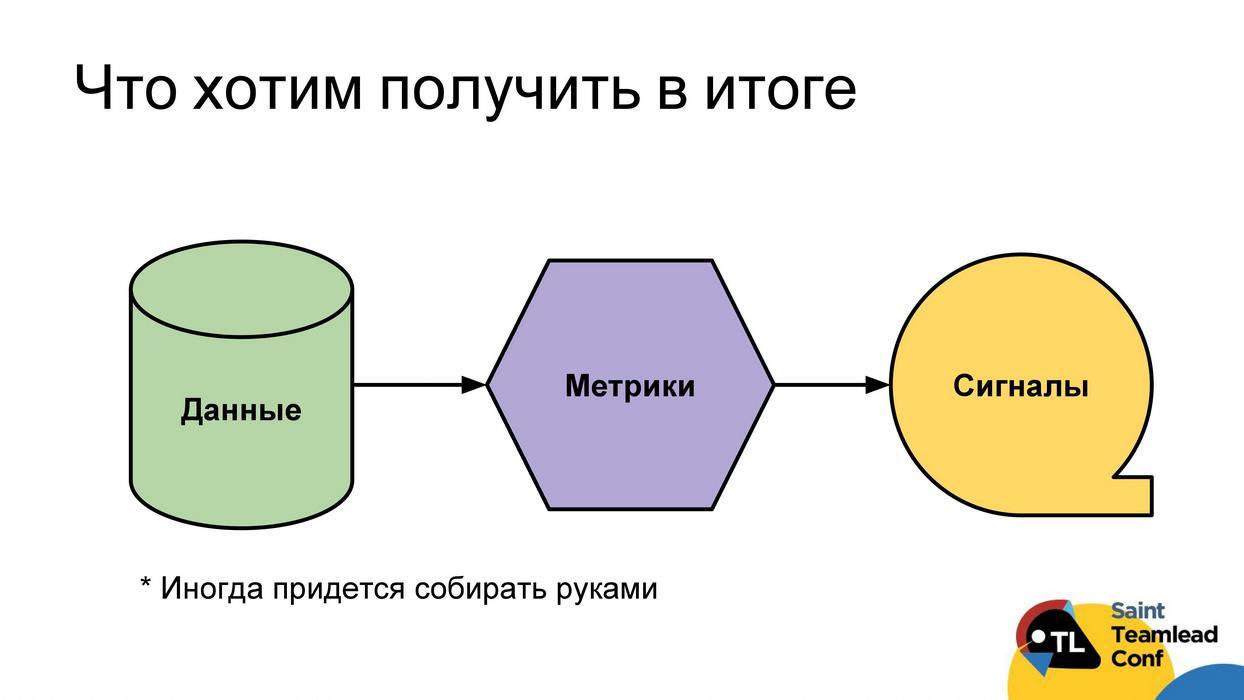
Ideally, we want to build the following workflow: so that we have automatic data collection; from this data we could build metrics; using metrics to find problems; signal problems directly to the developer, team leader or team. Then everyone will be able to respond to them in a timely manner and cope with the problems found. I’ll say right away that it’s not always possible to reach clear signals. Sometimes metrics will remain just metrics that will have to be analyzed, look at values, trends, and so on. Even with the data there will sometimes be a problem, sometimes they cannot be collected automatically and you have to do it with your hands (I will separately clarify such cases).
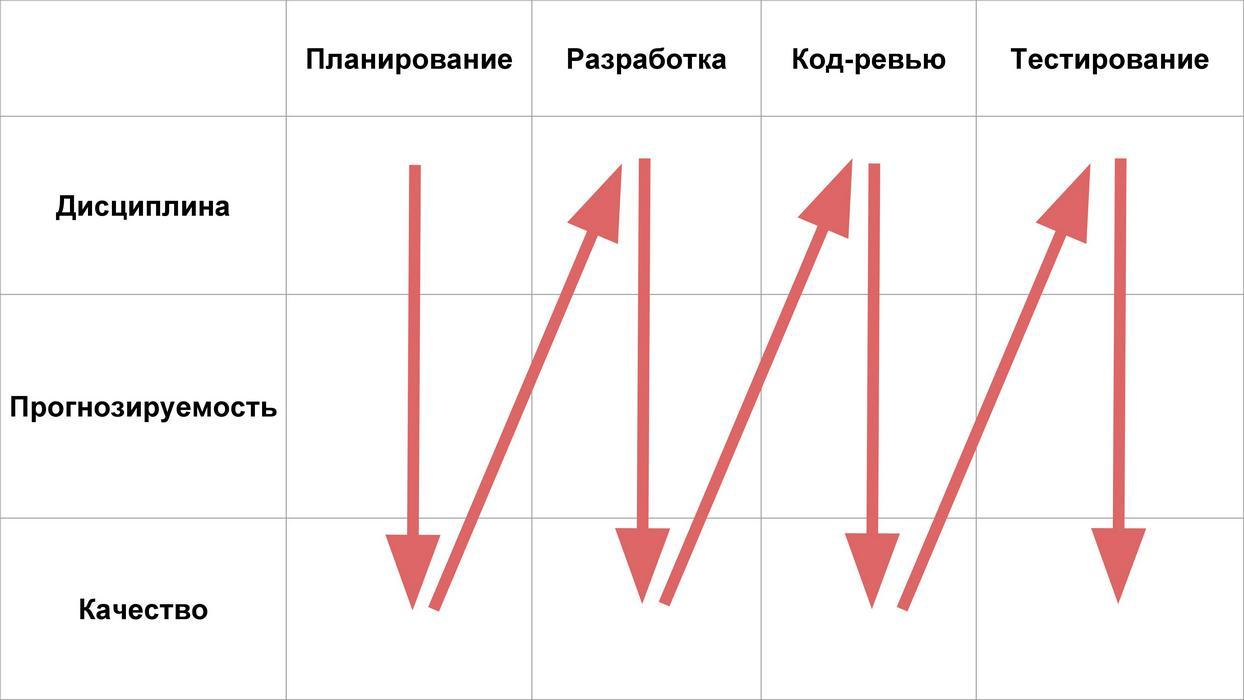
Next we look at 4 stages of feature life:
And let us analyze what problems with discipline, predictability and quality can be at each of these stages.
Problems with discipline at the planning stage
There is a lot of information, but I pay attention to the most important points. They may seem simple enough, but they are faced with a very large number of commands.

The first problem that often arises during planning is a trite organizational problem - not everyone who should be there is present at the planning meeting.
Example: the team complains that the tester is testing something wrong. It turns out that testers in this team never go on planning at all. Or, instead of sitting and planning something, the team frantically searches for a place to sit, because it forgot to book a meeting.
You do not need to configure metrics and signals, just please make sure that you do not have these problems. The rally is marked in the calendar, everyone is invited to it, the venue is occupied. No matter how funny it may sound, they face it in different teams.
Now we will discuss situations in which signals and metrics are needed. At the planning stage, most of the signals that I will talk about should be sent to the team about an hour after the end of the planning meeting, so as not to distract the team in the process, but so that the focus remains.
The first disciplinary problem is that tasks have no description,or they are poorly described. It is controlled by elementary. There is a format to which the tasks should correspond - check if this is so. For example, we follow that acceptance criteria are set, or for frontend tasks there is a link to the layout. You also need to keep track of the components that are placed, because the description format is often tied to the component. For the backend task, one description is relevant, for a frontend one, another.

The next common problem is that priorities are spoken orally or not at all and are not reflected in the data . As a result, by the end of the iteration, it turns out that the most important tasks have not been accomplished. You need to ensure that the team uses priorities and uses them adequately. If a team has 90% of tasks in an iteration having a high priority, it is all the same that there are no priorities at all.
We try to come to such a distribution: 20% high priority tasks (it’s impossible to release); 60% - medium priority; 20% - low priority (not scary if not released). Hang on all this signals.

The last problem with the discipline, which happens at the planning stage - there is not enough data , including for subsequent metrics. The basic ones are: the tasks have no ratings (a signal should be made) or the types of tasks are inadequate. That is, bugs start up as tasks, and the tasks of technical duty are not tracked at all. Unfortunately, it is impossible to automatically check the second type of problems. We recommend just once a couple of months, especially if you are a CTO and you have several teams, to look through the backlog and make sure that people get bugs like bugs, save as stori, technical debt tasks like technical debts.
Predictability problems at the planning stage
We turn to problems with predictability.

The basic problem is that we do not fall within the time limits and estimates , we estimate it incorrectly. Unfortunately, there is no way to find a magic signal or metric that will solve this problem. The only way is to encourage the team to learn better, to sort through examples of the causes of errors with one or another assessment. And this learning process can be facilitated by automatic means.
The first thing you can do is to deal with obviously problematic tasks with a high estimate of execution time. We hang the SLA and control that all tasks are fairly well decomposed. We recommend a limit of two days for execution to begin with, and then you can go to one-day.
The next item can facilitate the collection of artifacts on which it will be possible to conduct training and disassemble with the team why there was an error with the assessment. We recommend using the practice Due date for this. She has proven herself very cool here.
Another way is a metric called Churn code within the task. Its essence is that we look at what percentage of the code in the framework of the task was written, but did not live to see the release (for more details, see the last report ). This metric shows how well the tasks are thought out. Accordingly, it would be nice to pay attention to the tasks with Churn jumps and to understand what we did not take into account and why we made a mistake in the assessment.

The next story is standard: the team was planning something, sprint filled, but in the enddid not what was planned . It is possible to tune signals for stuffing, changing priorities, but for the majority of the teams with which we did this, they were irrelevant. Often these are legal operations by the product manager to throw something into the sprint, change the priority, so there will be a lot of false positives.
What can be done here? Calculate fairly standard basic metrics: the closability of the initial sprint skopa, the number of stuffing in the sprint, the closability of the stuffing itself, the change of priorities, to see the structure of stuffing. After that, estimate how many tasks and bugs you usually throw into the iteration. Further, using a signal to control what you are laying out this quota at the planning stage .
Quality problems at the planning stage
The first problem: the team does not think out the functionality of the released features . I will talk about quality in a general sense - the problem with quality is if the client says that it is. This may be some product nedodumki, and may be technical things.
Regarding the product lack of thought, a metric such as 3-week churn works well , revealing that 3 weeks after the release of the churn task is above the norm. The essence is simple: the task was released, and then within three weeks a rather high percentage of its code was deleted. Apparently, the task was not well implemented. We catch such cases and sort them out with the team.

The second metric is needed for teams that have problems with bugs, crashes and quality. We offer to buildchart of the balance of bugs and crashes: how many bugs are there right now, how many flew in yesterday, how many did yesterday. You can hang such a Real Time Monitor right in front of the team so that it can see it every day. This is a great emphasis on the quality problems of the team. We did this with two teams, and they really began to think through the tasks better.

The next very standard problem is that the team has no time for technical debt.. This story is easily monitored if you observe the work with the types, that is, the technical debt tasks are evaluated and set up as technical debt tasks in Jira. We can calculate what time distribution quota was given to the team for technical debt during the quarter. If we agreed with the business that it is 20%, and spent only 10%, this can be taken into account and take more time to the technical debt in the next quarter.
Problems with discipline at the development stage
We now turn to the development stage. What problems can there be with discipline?
Unfortunately, it happens that developers do nothing or we cannot understand whether they do anything. Track it easily for two banal signs:
If not, then it’s not a fact that you need to beat the developer’s hands, but you need to know about it.
The second problem, which can knock even the most powerful people and the brain, even a very tough developer, is constant processing . It would be nice if you, as a tmilid, know that a person is recycling: writing code or doing a review code during off-hours.
It may also violate various rules of working with Git . The first thing we urge to follow all the commands is to specify the task prefixes from the tracker in the commit messages, because only in this case can we link the task and the code to it. It’s better not even to build signals, but to directly configure git hook. For any additional git-rules that you have, for example, you cannot commit to master, we also configure git hooks.
The same applies to the agreed practitioners. At the design stage, there are many practices that a developer must follow. For example, in the case of Due date there will be three signals:
Signals are tuned to everything. For any other practice, you can also set up such things.
Predictability problems during development
Many things can go wrong in the predictions during the development phase.
The task may just hang in development for a long time. We have already tried to solve this problem at the planning stage - to decompose the tasks rather small. Unfortunately, this does not always help, and there are tasks that hang . We recommend to start by simply setting the SLA to “in progress” status, so that there is a signal that this SLA is violated. This will not allow us to start releasing tasks faster right now, but this will again allow us to collect the invoice, react to it and discuss with the team what happened, why the task hangs for a long time.
Predictability may suffer if there are too many tasks on one developer.. The number of parallel tasks that the developer does is preferably checked by code, not by Jira, because Jira does not always reflect the relevant information. We are all human, and if we do many parallel tasks, then the risk that something goes wrong somewhere increases.

The developer may have some problems about which he does not speak, but which are easily identified on the basis of the data. For example, yesterday the developer had little code activity. This does not necessarily mean that there is a problem, but you, as a team leader, can come up and find out. Perhaps he was stuck and he needed help, but he hesitates to ask her.
Another example, the developer, on the contrary, has a big task, which is growing and growing in code. This can also be identified and possibly decomposed, so that in the end there are no problems with the code review or the testing stage.
It makes sense to adjust the signal and to the fact that during the work on the task the code is repeatedly rewritten. Perhaps it is constantly changing requirements, or the developer does not know which architectural solution to choose. On the data it is easy to detect and discuss with the developer.
Quality problems at the design stage
Development directly affects quality. The question is how to understand which of the developers most influences the decline in quality.
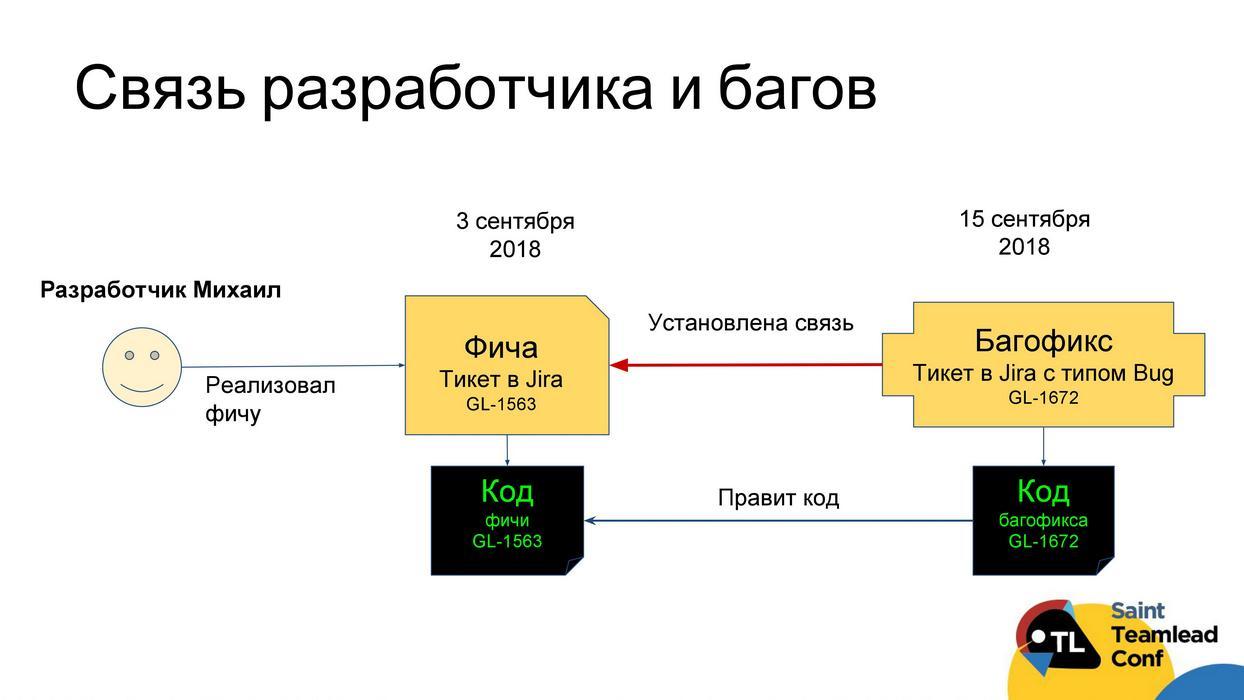
We suggest doing this as follows. It is possible to calculate the criterion of the “importance” of the developer : we take all the tasks that were in the tracker for three months; among all the tasks we find “bug” tasks; We look at the code of these tasks of the type "bug"; We look, the code of what tasks fixed this bug fix. Accordingly, we can understand the correlation of tasks, in which later defects were discovered, to all tasks that the developer did - this will be the “criterion of importance”.
If we supplement this history with statistics on returns from testing, that is, the proportion of developer tasks that were returned to testing for improvements, it will be possible to assess which of the developers has the most quality problems. As a result, we will understand by whom it is worthwhile to tweak the code review and testing processes, whose code should be carefully reviewed and whose tasks should be given to more corrosive testers.
The next problem that may be with the quality at the development stage is that we write hard-to-maintain code , such a “layered” architecture. I will not dwell here in detail, I described it in detail last time. There is a metric called Legacy Refactoring, which just shows how much time is spent on embedding a new code into an existing one, how much old code is deleted and changed when writing a new one.
Probably one of the most important criteria when assessing quality at the development stage is the SLA control for high-priority bugs . I hope you are already watching this. If not, I recommend starting it, because it is often one of the most important indicators for a business: the high-priority and critical bugs development team undertakes to close at a certain time.
The last thing you often come across with is no autotest. First, they need to be written. Secondly, it is necessary to monitor that the coating is kept at a certain level and does not fall below the threshold. Many people write autotests, but forget to follow the coverage.
Problems with discipline at the code review stage
We proceed to the Code review stage. What problems can there be with discipline? Let's start with probably the most stupid reason - forgotten pull requests. First, the author may simply not assign a reviewer for the pull request, which will be forgotten as a result. Or, for example, they forgot to move the ticket to the “in review” status, and the developers check which tasks need to be reviewed in Jira. We must not forget to follow this, for which we set up simple signals. If you have practice, which should be more than 2-3 reviewers per task, then this is also easily controlled with a simple signal.

The next story that the reviewer uncovers a task cannot quickly understand to which task the pull request relates, he is too lazy to ask and he postpones it. Here we also make a signal - we make sure that in the pull request there is always a link to the ticket in Jira and the reviewer can easily read it.

The next problem, which, unfortunately, cannot be excluded. There are always huge pull requests in which a lot of things have been done. Accordingly, the reviewer opens them, looks at them and thinks: “No, I'd rather check it later, something is too much here.” In this case, the author can help the reviewer with onboarding, and we can control this process. Large pull requests must have a good clear description that matches a specific format, and this format is different from the ticket in Jira.
The second kind of practice for greater pull request, which can also be monitored, is when the author himself in advance in the code puts comments in places where something needs to be discussed, where there is some non-obvious solution, thus, as if inviting the reviewer to discussion. Signals are also easily tuned to this.
Further, a problem that we also often encounter, - the author says that he simply does not know when he can begin to correct everything, because he does not know whether the review is complete. To do this, elementary disciplinary practice is being introduced: the reviewer must at the end of the review be sure to unsubscribe with a special comment that "I have finished, you can fix." Accordingly, you can configure automatic notifications about this to the author.

Please configure linter. In half of the teams we work with, for some reason linter is not configured, and they themselves are engaged in such a syntax code review and for some reason do the work with which the machine will cope much better.
Problems with predictability at the code-review stage
If the tasks continue to hang , we recommend that you configure the SLA that the task either waits for fixes for a long time, or it waits for a long time to review. Accordingly, be sure to ping both the author and the reviewer.
If SLA does not help, I recommend to introduce into practice the morning " code-review hour " or the evening one - how convenient. This is the time when the whole team sits down and is engaged in a purely code review. The implementation of this metric is very easy to monitor by shifting the activity time in a pull request to the desired hour.

It happens that there are people overloaded with code reviewand this is also not very good. For example, in one of the teams, the CTO stood at the very beginnings of the system, wrote all of it, and it just so happened that he was always the main reviewer. All developers are constantly hung on him the task of code review. At some point, everything came to the fact that in a team of 6 people more than 50% of the code-review hung on it and continued to accumulate and accumulate. As a result, as it is easy to guess, their iterations were closed by the same 50%, because the CTO did not have time to check everything. When they introduced elementary disciplinary practice that it was impossible to hang more than two or three tasks on the CTO in the iteration, the next iteration showed the team to close the sprint by almost 100%.
The next story that is easily monitored using metrics is that the holivar began in the code review. Triggers can be:
All this is a reason to check if there is a holivar in this code review.
Quality problems at the code review stage
First of all, the problem may be just a very superficial code review. In order to monitor this, there are two good metrics. You can measure the activity of the reviewer as the number of comments for every 100 lines of code. Someone reviews every 10 lines of code, while others scroll through entire screens and leave 1-2 comments. Of course, not all comments are equally useful. Therefore, it is possible to refine this metric by measuring the influence of the reviewer — the percentage of comments that indicated a line of code that was later changed as part of the review. Thus, we understand who is the most corrosive, and most effective in the sense that his comments most often lead to code changes.

With those who approach the review very formally, it is possible to talk and monitor them further, to see if they begin to review more carefully.
The next problem is that the author makes a very crude code on the review and the review turns into the correction of the most obvious bugs, instead of paying attention to something more complicated, or is simply delayed. The metric here is a high churn code after the revision code, i.e. The percentage change in the code in pull request after the review begins.
The case when nothing is clear due to refactoring, unfortunately, it is worth controlling with your hands; this is automatically quite problematic. We check that the stylistic refactoring is allocated either in a separate commit, or ideally in general in a separate branch, so as not to interfere with a quality code review.

The quality of the review code can still be controlled using practices such as anonymous polling after the code review (when the pull request is successfully closed), in which the reviewer and the author would rate the code quality and quality of the code review, respectively. And one of the criteria can be just whether the stylistic refactoring is highlighted in a separate commit, including. Such subjective assessments make it possible to find hidden conflicts and problems in the team.
Problems with discipline at the testing stage
We proceed to the testing phase and problems with discipline at this stage. The most frequent we face is that there is no information about testers in Jira. That people save on licenses and do not add testers in Jira. That tasks that simply do not fall into the status of "testing". That we can not determine the return of the task for revision on the task-tracker. We recommend setting up signals for all of this and watching for data to be accumulated, otherwise it will be extremely difficult to say something about the tester.

Predictability issues at the testing stage
In terms of predictability at the testing stage, I again recommend hanging the SLA for the testing period and for the testing waiting time . And all cases of SLA failure to speak with the team, including hanging the signal at the time of fixation after the return of the task from testing to development.
As with the code review, there may be an overload problem for testers in testing, especially in teams where testers are a team resource. We recommend just to see the distribution of tasks by testers. Even if your tester performs tasks from several teams, then you need to look at the distribution of tasks for testers for several teams in order to understand who is the bottle neck right now .

A difficult test-environment pipeline is a superfunctional problem, but, unfortunately, not everyone builds on this metrics. The build time is very long, the system rollout time, the autotest run time - if you can adjust the metrics for this, we recommend doing it. If not, then at least once every 1-2 months we recommend sitting down next to your tester for the whole day, in order to understand that sometimes he lives very uneasy. If you have never done this, then you will get a lot of insights.
Quality problems at the testing stage
The objective function of testing is not to skip production bugs. It would be good to understand which testers are coping well with this function. There is exactly the same scheme as it was with the developers, now we simply evaluate the criterion of the tester's “importance” as the number of tasks that the tester tested, and then they fixed bugs in relation to all the tasks that the tester tested.
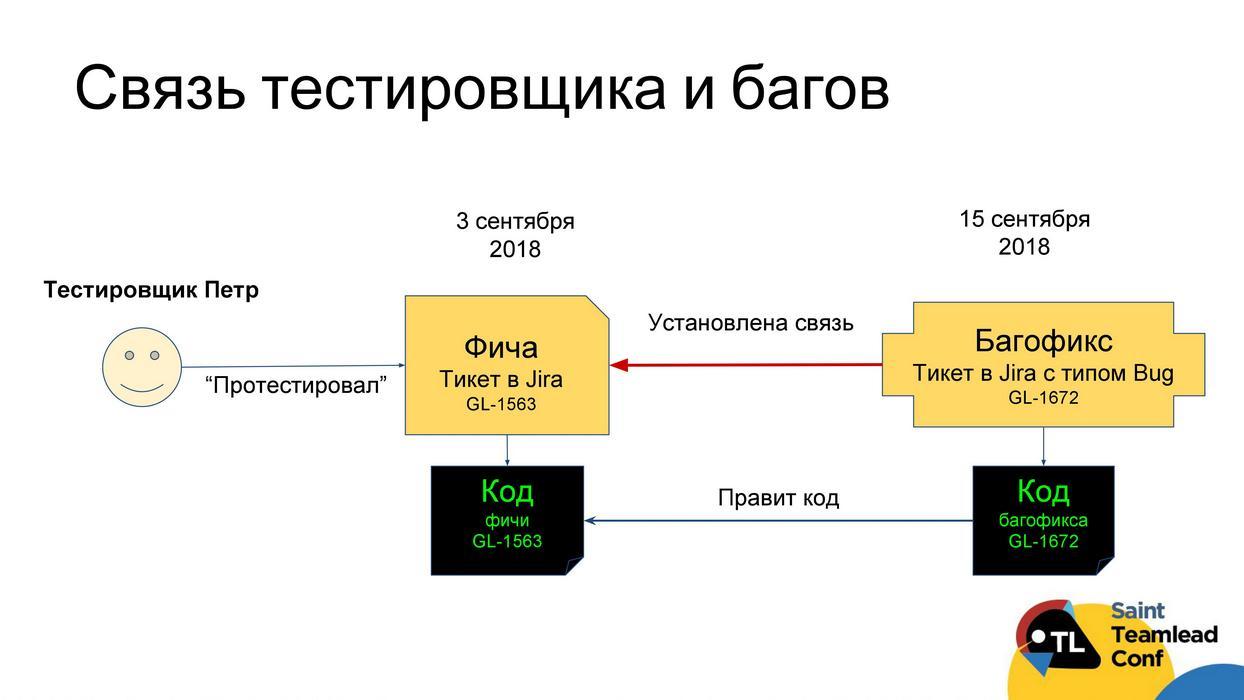
Then we can still see how much this tester tests all tasks, how often it returns tasks, and thereby build a certain rating of testers. Very often, amazing discoveries awaited us at this stage. It turned out that testers, whom everyone loves, because they pack tests very quickly, test tasks, and do it at the least quality. And the tester, who was directly disliked, turned out to be the most corrosive, just not very fast. The point here is very simple: the most corrosive testers who test the best quality of all need to be given the most important, complex or potentially most risky tasks.

Regarding potentially the most risky tasks, you can build the same story with the “value” for files, that is, look at the files in which they find the most bugs. Accordingly, the tasks that these files affect, trust the most responsible tester.

Another story that affects the quality of the testing phase is such a constant ping-pong between testing and development . The tester simply returns the task to the developer, and the latter, in turn, without changing anything, returns it back to the tester. You can look at this either as a metric, or set up a signal for such tasks and look closely at what is happening there and if there are any problems.
Metrics Methodology
We talked about metrics, and now the question is how to work with all this? I told only the most basic things, but even they are quite a lot. What to do with all this and how to use it?
We recommend that you automate this process to the maximum and deliver all signals to the team using a bot in messengers. We tried different communication channels: both e-mail and dashboard does not work very well. Bot has proven itself best. You can write the bot yourself, you can get OpenSource from someone, you can buy from us.
The point here is very simple: the team responds to signals from the bot much more calmly than to the manager, who points to problems. If possible, deliver most signals directly to the developer first, then to the team if the developer does not respond, for example, within one or two days.

No need to try to build all the signals at once. Most of them simply will not work, because you will not have data, because of the banal problems with discipline. Therefore, we first establish discipline and set up signals for disciplinary practices. According to the experience of the teams with whom we communicated, it took a year and a half to simply build up the discipline in the development team without automation. With automation, with the help of constant signals, the team begins to work in a disciplined manner in about a couple of months, that is, much faster.
Any signals that you make public, or send directly to the developer, in no case can not just take and turn on. First of all, it is necessary to coordinate this with the developer, to speak with him and with the team. It is advisable to put in writing all the thresholds in the Team Agreement, the reasons why you are doing this, what the next steps will be, and so on.

It should be borne in mind that all processes have exceptions, and take this into account at the design stage. We do not build a concentration camp for developerswhere it is impossible to take a step to the right, a step to the left. All processes have an exception, we just want to know about them. If the bot constantly swears for some task that cannot really be decomposed, and work on which will take 5 days, you need to put a “no-tracking” tag, so that the bot takes this into account and that's it. As a manager, you can separately monitor the number of such “no-tracking” tasks, and thereby understand how good those processes and the signals that you are building are. If the number of tasks labeled “no-tracking” is steadily growing, then, unfortunately, this means that the signals and processes that you have invented are difficult for the team, it cannot follow them, and it is easier for them to bypass them.

Manual control still remains.. It will not be possible to turn on the bot and go somewhere in Bali - you still have to deal with each situation. You received some kind of signal, the person didn’t react to him - you’ll have to find out in a day or two what the reason is, to speak the problem and work out a solution.
In order to optimize this process, we recommend introducing such practices as process attendant . This is a moving post of a person (once a week) who deals with the problems that the bot signals. And you, as a team leader, help the duty officer to deal with these problems, that is, you supervise him. Thus, the developer increases the motivation to work with this product. He understands his benefit, because he sees how these problems can be solved and how to react to them. Thereby you reduce your uniqueness to the team and bring closer the moment when the team becomes autonomous , and you can still go to Bali.
Conclusions
Collect data. Build processes so that you have data collected. Even if you do not want to build metrics and signals now, you can do a cool, retrospective analysis in the future if you now start collecting them.
Automatically monitor processes. When designing processes, always think about how you can hack them, and how you can recognize such hacks by data.
When the signals are not enough for several weeks - you are well done!We were faced with the fact that when the team sees that the signals are getting small, and the situation seems to be getting better, it starts frantically inventing some more practices, starts to introduce something in order to see these packets of signals again. This is not always necessary, perhaps, if the signals were not enough - you are fine, the team began to work as you wanted from the very beginning, and you are well done :)
Sergey Semenov believes that this happens mainly for two reasons.
- There are no tools and standards for evaluating the work of programmers. Managers have to resort to a subjective assessment, which in turn leads to errors.
- No automatic control of processes in a team is used. Without proper control, the processes in the development teams cease to perform their functions, as they start to be executed partially or simply ignored.
And offers an approach to assessing and controlling processes based on objective data.
Below is the video and text version of the report by Sergey, who, according to the audience voting, took second place on Saint TeamLead Conf .
About the speaker: Sergey Semenov ( sss0791 ) has worked in IT for 9 years, was a developer, team leader, product manager, now the CEO of GitLean. GitLean is an analytical product for managers, technical directors, and team leaders who are designed to make objective management decisions. Most of the examples in this story are based not only on personal experience, but also on the experience of client companies with a development staff of 6 to 200 people.
About the evaluation of the developers, we have already with my colleague Alexander Kiselyov told in February on the previous TeamLead Conf. I will not dwell on this in detail, but I will refer to the article on some metrics. Today we will talk about the processes and how to control and measure them.
Data sources
If we are talking about measurements, it would be good to understand where to get the data. First of all, we have:
- Git with code info;
- Jira or any other task tracker with task information;
- GitHub , Bitbucket, Gitlab with code review information.
In addition, there is such a cool mechanism, as the collection of various subjective assessments. I will make a reservation that it should be used systematically if we want to rely on this data.
Of course, there is dirt and pain waiting for you in the data - there's nothing you can do about it, but this is not so bad. The most annoying thing is that the data on the work of your processes in these sources can often not be there. This may be because the processes were built in such a way that they do not leave any artifacts in the data.
The first rule we recommend to follow when designing and building processes is to make them so that they leave artifacts in the data. We need to build not just Agile, but make it measurable ( Measurable Agile ).
I'll tell you a scary story that we met at one of the clients who came to us with a request to improve the quality of the product. So that you understand the scale - about 30-40 bugs from production came to a team of 15 developers a week. We started to understand the reasons, and found that 30% of the tasks do not fall into the status of "testing". At first, we thought it was just a data error, or testers did not update the status of the task. But it turned out that really 30% of tasks are simply not tested. Once there was a problem in the infrastructure, due to which 1-2 puzzles in the iteration did not get into testing. Then everyone forgot about this problem, testers stopped talking about it, and over time it turned into 30%. In the end, this led to more global problems.
Therefore, the first important metric for any process is that it leaves data. Be sure to follow this.
Sometimes, for the sake of measurability, you have to sacrifice some of the principles of Agile and, for example, somewhere prefer to write oral communication.
Due date practice proved to be very good, which we implemented in several teams in order to improve predictability. Its essence is as follows: when a developer takes a task and drags it into “in progress”, he must deliver due date when the task is either released or ready for release. This practice teaches the developer to be a conditional micro project manager of his own tasks, that is, to take into account external dependencies and understand that the task is ready only when the client can use its result.
In order for learning to occur, after the due date, the developer needs to go to Jira and put a new due date and leave comments in a specially defined form, why this happened. It would seem, why do we need such a bureaucracy. But in fact, after two weeks of this practice, we unload all such comments from Jira with a simple script and conduct a retrospective with this texture. It turns out a bunch of insights about why deadlines fail. Very cool work, I recommend to use.
Approach from problems
In the measurement of processes, we profess the following approach: we must proceed from the problems. We imagine some ideal practices and processes, and then we will be creative, in what ways they may not work.
It is necessary to monitor the violation of processes , and not how we follow some kind of practice. Processes often do not work, not because people maliciously violate them, but because the developer and manager do not have enough control and memory to follow them all. By tracking violations of the rules, we can automatically remind people about what to do and get automatic controls.
To understand what processes and practices need to be implemented, you need to understand why it should be done in the development team, what the business needs from development. Everyone understands that you need not so much:
- that the product is delivered for an adequate predictable time;
- that the product was of proper quality, not necessarily perfect;
- for it all to be fast enough.
That is, predictability, quality and speed are important . Therefore, we will look at all the problems and metrics with regard to how they affect predictability and quality. We’re almost not going to discuss speed, because of the nearly 50 teams we worked with in one way or another, only two could work with speed. In order to increase speed, you need to be able to measure it, and so that it is at least a little predictable, and this is predictability and quality.
In addition to predictability and quality, we introduce such a direction as a discipline . We will call discipline everything that ensures the basic functioning of processes and data collection, on the basis of which the analysis of problems with predictability and quality is carried out.
Ideally, we want to build the following workflow: so that we have automatic data collection; from this data we could build metrics; using metrics to find problems; signal problems directly to the developer, team leader or team. Then everyone will be able to respond to them in a timely manner and cope with the problems found. I’ll say right away that it’s not always possible to reach clear signals. Sometimes metrics will remain just metrics that will have to be analyzed, look at values, trends, and so on. Even with the data there will sometimes be a problem, sometimes they cannot be collected automatically and you have to do it with your hands (I will separately clarify such cases).
Next we look at 4 stages of feature life:
And let us analyze what problems with discipline, predictability and quality can be at each of these stages.
Problems with discipline at the planning stage
There is a lot of information, but I pay attention to the most important points. They may seem simple enough, but they are faced with a very large number of commands.
The first problem that often arises during planning is a trite organizational problem - not everyone who should be there is present at the planning meeting.
Example: the team complains that the tester is testing something wrong. It turns out that testers in this team never go on planning at all. Or, instead of sitting and planning something, the team frantically searches for a place to sit, because it forgot to book a meeting.
You do not need to configure metrics and signals, just please make sure that you do not have these problems. The rally is marked in the calendar, everyone is invited to it, the venue is occupied. No matter how funny it may sound, they face it in different teams.
Now we will discuss situations in which signals and metrics are needed. At the planning stage, most of the signals that I will talk about should be sent to the team about an hour after the end of the planning meeting, so as not to distract the team in the process, but so that the focus remains.
The first disciplinary problem is that tasks have no description,or they are poorly described. It is controlled by elementary. There is a format to which the tasks should correspond - check if this is so. For example, we follow that acceptance criteria are set, or for frontend tasks there is a link to the layout. You also need to keep track of the components that are placed, because the description format is often tied to the component. For the backend task, one description is relevant, for a frontend one, another.
The next common problem is that priorities are spoken orally or not at all and are not reflected in the data . As a result, by the end of the iteration, it turns out that the most important tasks have not been accomplished. You need to ensure that the team uses priorities and uses them adequately. If a team has 90% of tasks in an iteration having a high priority, it is all the same that there are no priorities at all.
We try to come to such a distribution: 20% high priority tasks (it’s impossible to release); 60% - medium priority; 20% - low priority (not scary if not released). Hang on all this signals.
The last problem with the discipline, which happens at the planning stage - there is not enough data , including for subsequent metrics. The basic ones are: the tasks have no ratings (a signal should be made) or the types of tasks are inadequate. That is, bugs start up as tasks, and the tasks of technical duty are not tracked at all. Unfortunately, it is impossible to automatically check the second type of problems. We recommend just once a couple of months, especially if you are a CTO and you have several teams, to look through the backlog and make sure that people get bugs like bugs, save as stori, technical debt tasks like technical debts.
Predictability problems at the planning stage
We turn to problems with predictability.
The basic problem is that we do not fall within the time limits and estimates , we estimate it incorrectly. Unfortunately, there is no way to find a magic signal or metric that will solve this problem. The only way is to encourage the team to learn better, to sort through examples of the causes of errors with one or another assessment. And this learning process can be facilitated by automatic means.
The first thing you can do is to deal with obviously problematic tasks with a high estimate of execution time. We hang the SLA and control that all tasks are fairly well decomposed. We recommend a limit of two days for execution to begin with, and then you can go to one-day.
The next item can facilitate the collection of artifacts on which it will be possible to conduct training and disassemble with the team why there was an error with the assessment. We recommend using the practice Due date for this. She has proven herself very cool here.
Another way is a metric called Churn code within the task. Its essence is that we look at what percentage of the code in the framework of the task was written, but did not live to see the release (for more details, see the last report ). This metric shows how well the tasks are thought out. Accordingly, it would be nice to pay attention to the tasks with Churn jumps and to understand what we did not take into account and why we made a mistake in the assessment.
The next story is standard: the team was planning something, sprint filled, but in the enddid not what was planned . It is possible to tune signals for stuffing, changing priorities, but for the majority of the teams with which we did this, they were irrelevant. Often these are legal operations by the product manager to throw something into the sprint, change the priority, so there will be a lot of false positives.
What can be done here? Calculate fairly standard basic metrics: the closability of the initial sprint skopa, the number of stuffing in the sprint, the closability of the stuffing itself, the change of priorities, to see the structure of stuffing. After that, estimate how many tasks and bugs you usually throw into the iteration. Further, using a signal to control what you are laying out this quota at the planning stage .
Quality problems at the planning stage
The first problem: the team does not think out the functionality of the released features . I will talk about quality in a general sense - the problem with quality is if the client says that it is. This may be some product nedodumki, and may be technical things.
Regarding the product lack of thought, a metric such as 3-week churn works well , revealing that 3 weeks after the release of the churn task is above the norm. The essence is simple: the task was released, and then within three weeks a rather high percentage of its code was deleted. Apparently, the task was not well implemented. We catch such cases and sort them out with the team.
The second metric is needed for teams that have problems with bugs, crashes and quality. We offer to buildchart of the balance of bugs and crashes: how many bugs are there right now, how many flew in yesterday, how many did yesterday. You can hang such a Real Time Monitor right in front of the team so that it can see it every day. This is a great emphasis on the quality problems of the team. We did this with two teams, and they really began to think through the tasks better.
The next very standard problem is that the team has no time for technical debt.. This story is easily monitored if you observe the work with the types, that is, the technical debt tasks are evaluated and set up as technical debt tasks in Jira. We can calculate what time distribution quota was given to the team for technical debt during the quarter. If we agreed with the business that it is 20%, and spent only 10%, this can be taken into account and take more time to the technical debt in the next quarter.
Problems with discipline at the development stage
We now turn to the development stage. What problems can there be with discipline?
Unfortunately, it happens that developers do nothing or we cannot understand whether they do anything. Track it easily for two banal signs:
- commit frequency - at least once a day;
- at least one active task in Jira.
If not, then it’s not a fact that you need to beat the developer’s hands, but you need to know about it.
The second problem, which can knock even the most powerful people and the brain, even a very tough developer, is constant processing . It would be nice if you, as a tmilid, know that a person is recycling: writing code or doing a review code during off-hours.
It may also violate various rules of working with Git . The first thing we urge to follow all the commands is to specify the task prefixes from the tracker in the commit messages, because only in this case can we link the task and the code to it. It’s better not even to build signals, but to directly configure git hook. For any additional git-rules that you have, for example, you cannot commit to master, we also configure git hooks.
The same applies to the agreed practitioners. At the design stage, there are many practices that a developer must follow. For example, in the case of Due date there will be three signals:
- tasks for which due date is not set;
- tasks that have overdue due date;
- tasks for which due date has been changed, but there is no comment.
Signals are tuned to everything. For any other practice, you can also set up such things.
Predictability problems during development
Many things can go wrong in the predictions during the development phase.
The task may just hang in development for a long time. We have already tried to solve this problem at the planning stage - to decompose the tasks rather small. Unfortunately, this does not always help, and there are tasks that hang . We recommend to start by simply setting the SLA to “in progress” status, so that there is a signal that this SLA is violated. This will not allow us to start releasing tasks faster right now, but this will again allow us to collect the invoice, react to it and discuss with the team what happened, why the task hangs for a long time.
Predictability may suffer if there are too many tasks on one developer.. The number of parallel tasks that the developer does is preferably checked by code, not by Jira, because Jira does not always reflect the relevant information. We are all human, and if we do many parallel tasks, then the risk that something goes wrong somewhere increases.
The developer may have some problems about which he does not speak, but which are easily identified on the basis of the data. For example, yesterday the developer had little code activity. This does not necessarily mean that there is a problem, but you, as a team leader, can come up and find out. Perhaps he was stuck and he needed help, but he hesitates to ask her.
Another example, the developer, on the contrary, has a big task, which is growing and growing in code. This can also be identified and possibly decomposed, so that in the end there are no problems with the code review or the testing stage.
It makes sense to adjust the signal and to the fact that during the work on the task the code is repeatedly rewritten. Perhaps it is constantly changing requirements, or the developer does not know which architectural solution to choose. On the data it is easy to detect and discuss with the developer.
Quality problems at the design stage
Development directly affects quality. The question is how to understand which of the developers most influences the decline in quality.
We suggest doing this as follows. It is possible to calculate the criterion of the “importance” of the developer : we take all the tasks that were in the tracker for three months; among all the tasks we find “bug” tasks; We look at the code of these tasks of the type "bug"; We look, the code of what tasks fixed this bug fix. Accordingly, we can understand the correlation of tasks, in which later defects were discovered, to all tasks that the developer did - this will be the “criterion of importance”.
If we supplement this history with statistics on returns from testing, that is, the proportion of developer tasks that were returned to testing for improvements, it will be possible to assess which of the developers has the most quality problems. As a result, we will understand by whom it is worthwhile to tweak the code review and testing processes, whose code should be carefully reviewed and whose tasks should be given to more corrosive testers.
The next problem that may be with the quality at the development stage is that we write hard-to-maintain code , such a “layered” architecture. I will not dwell here in detail, I described it in detail last time. There is a metric called Legacy Refactoring, which just shows how much time is spent on embedding a new code into an existing one, how much old code is deleted and changed when writing a new one.
Probably one of the most important criteria when assessing quality at the development stage is the SLA control for high-priority bugs . I hope you are already watching this. If not, I recommend starting it, because it is often one of the most important indicators for a business: the high-priority and critical bugs development team undertakes to close at a certain time.
The last thing you often come across with is no autotest. First, they need to be written. Secondly, it is necessary to monitor that the coating is kept at a certain level and does not fall below the threshold. Many people write autotests, but forget to follow the coverage.
Problems with discipline at the code review stage
We proceed to the Code review stage. What problems can there be with discipline? Let's start with probably the most stupid reason - forgotten pull requests. First, the author may simply not assign a reviewer for the pull request, which will be forgotten as a result. Or, for example, they forgot to move the ticket to the “in review” status, and the developers check which tasks need to be reviewed in Jira. We must not forget to follow this, for which we set up simple signals. If you have practice, which should be more than 2-3 reviewers per task, then this is also easily controlled with a simple signal.
The next story that the reviewer uncovers a task cannot quickly understand to which task the pull request relates, he is too lazy to ask and he postpones it. Here we also make a signal - we make sure that in the pull request there is always a link to the ticket in Jira and the reviewer can easily read it.
The next problem, which, unfortunately, cannot be excluded. There are always huge pull requests in which a lot of things have been done. Accordingly, the reviewer opens them, looks at them and thinks: “No, I'd rather check it later, something is too much here.” In this case, the author can help the reviewer with onboarding, and we can control this process. Large pull requests must have a good clear description that matches a specific format, and this format is different from the ticket in Jira.
The second kind of practice for greater pull request, which can also be monitored, is when the author himself in advance in the code puts comments in places where something needs to be discussed, where there is some non-obvious solution, thus, as if inviting the reviewer to discussion. Signals are also easily tuned to this.
Further, a problem that we also often encounter, - the author says that he simply does not know when he can begin to correct everything, because he does not know whether the review is complete. To do this, elementary disciplinary practice is being introduced: the reviewer must at the end of the review be sure to unsubscribe with a special comment that "I have finished, you can fix." Accordingly, you can configure automatic notifications about this to the author.
Please configure linter. In half of the teams we work with, for some reason linter is not configured, and they themselves are engaged in such a syntax code review and for some reason do the work with which the machine will cope much better.
Problems with predictability at the code-review stage
If the tasks continue to hang , we recommend that you configure the SLA that the task either waits for fixes for a long time, or it waits for a long time to review. Accordingly, be sure to ping both the author and the reviewer.
If SLA does not help, I recommend to introduce into practice the morning " code-review hour " or the evening one - how convenient. This is the time when the whole team sits down and is engaged in a purely code review. The implementation of this metric is very easy to monitor by shifting the activity time in a pull request to the desired hour.
It happens that there are people overloaded with code reviewand this is also not very good. For example, in one of the teams, the CTO stood at the very beginnings of the system, wrote all of it, and it just so happened that he was always the main reviewer. All developers are constantly hung on him the task of code review. At some point, everything came to the fact that in a team of 6 people more than 50% of the code-review hung on it and continued to accumulate and accumulate. As a result, as it is easy to guess, their iterations were closed by the same 50%, because the CTO did not have time to check everything. When they introduced elementary disciplinary practice that it was impossible to hang more than two or three tasks on the CTO in the iteration, the next iteration showed the team to close the sprint by almost 100%.
The next story that is easily monitored using metrics is that the holivar began in the code review. Triggers can be:
- there is a thread in which there are more than two answers from each of the participants;
- a large number of participants in the code review;
- There is no activity on commits, but there is activity by comments.
All this is a reason to check if there is a holivar in this code review.
Quality problems at the code review stage
First of all, the problem may be just a very superficial code review. In order to monitor this, there are two good metrics. You can measure the activity of the reviewer as the number of comments for every 100 lines of code. Someone reviews every 10 lines of code, while others scroll through entire screens and leave 1-2 comments. Of course, not all comments are equally useful. Therefore, it is possible to refine this metric by measuring the influence of the reviewer — the percentage of comments that indicated a line of code that was later changed as part of the review. Thus, we understand who is the most corrosive, and most effective in the sense that his comments most often lead to code changes.
With those who approach the review very formally, it is possible to talk and monitor them further, to see if they begin to review more carefully.
The next problem is that the author makes a very crude code on the review and the review turns into the correction of the most obvious bugs, instead of paying attention to something more complicated, or is simply delayed. The metric here is a high churn code after the revision code, i.e. The percentage change in the code in pull request after the review begins.
The case when nothing is clear due to refactoring, unfortunately, it is worth controlling with your hands; this is automatically quite problematic. We check that the stylistic refactoring is allocated either in a separate commit, or ideally in general in a separate branch, so as not to interfere with a quality code review.
The quality of the review code can still be controlled using practices such as anonymous polling after the code review (when the pull request is successfully closed), in which the reviewer and the author would rate the code quality and quality of the code review, respectively. And one of the criteria can be just whether the stylistic refactoring is highlighted in a separate commit, including. Such subjective assessments make it possible to find hidden conflicts and problems in the team.
Problems with discipline at the testing stage
We proceed to the testing phase and problems with discipline at this stage. The most frequent we face is that there is no information about testers in Jira. That people save on licenses and do not add testers in Jira. That tasks that simply do not fall into the status of "testing". That we can not determine the return of the task for revision on the task-tracker. We recommend setting up signals for all of this and watching for data to be accumulated, otherwise it will be extremely difficult to say something about the tester.
Predictability issues at the testing stage
In terms of predictability at the testing stage, I again recommend hanging the SLA for the testing period and for the testing waiting time . And all cases of SLA failure to speak with the team, including hanging the signal at the time of fixation after the return of the task from testing to development.
As with the code review, there may be an overload problem for testers in testing, especially in teams where testers are a team resource. We recommend just to see the distribution of tasks by testers. Even if your tester performs tasks from several teams, then you need to look at the distribution of tasks for testers for several teams in order to understand who is the bottle neck right now .
A difficult test-environment pipeline is a superfunctional problem, but, unfortunately, not everyone builds on this metrics. The build time is very long, the system rollout time, the autotest run time - if you can adjust the metrics for this, we recommend doing it. If not, then at least once every 1-2 months we recommend sitting down next to your tester for the whole day, in order to understand that sometimes he lives very uneasy. If you have never done this, then you will get a lot of insights.
Quality problems at the testing stage
The objective function of testing is not to skip production bugs. It would be good to understand which testers are coping well with this function. There is exactly the same scheme as it was with the developers, now we simply evaluate the criterion of the tester's “importance” as the number of tasks that the tester tested, and then they fixed bugs in relation to all the tasks that the tester tested.
Then we can still see how much this tester tests all tasks, how often it returns tasks, and thereby build a certain rating of testers. Very often, amazing discoveries awaited us at this stage. It turned out that testers, whom everyone loves, because they pack tests very quickly, test tasks, and do it at the least quality. And the tester, who was directly disliked, turned out to be the most corrosive, just not very fast. The point here is very simple: the most corrosive testers who test the best quality of all need to be given the most important, complex or potentially most risky tasks.
Regarding potentially the most risky tasks, you can build the same story with the “value” for files, that is, look at the files in which they find the most bugs. Accordingly, the tasks that these files affect, trust the most responsible tester.
Another story that affects the quality of the testing phase is such a constant ping-pong between testing and development . The tester simply returns the task to the developer, and the latter, in turn, without changing anything, returns it back to the tester. You can look at this either as a metric, or set up a signal for such tasks and look closely at what is happening there and if there are any problems.
Metrics Methodology
We talked about metrics, and now the question is how to work with all this? I told only the most basic things, but even they are quite a lot. What to do with all this and how to use it?
We recommend that you automate this process to the maximum and deliver all signals to the team using a bot in messengers. We tried different communication channels: both e-mail and dashboard does not work very well. Bot has proven itself best. You can write the bot yourself, you can get OpenSource from someone, you can buy from us.
The point here is very simple: the team responds to signals from the bot much more calmly than to the manager, who points to problems. If possible, deliver most signals directly to the developer first, then to the team if the developer does not respond, for example, within one or two days.
No need to try to build all the signals at once. Most of them simply will not work, because you will not have data, because of the banal problems with discipline. Therefore, we first establish discipline and set up signals for disciplinary practices. According to the experience of the teams with whom we communicated, it took a year and a half to simply build up the discipline in the development team without automation. With automation, with the help of constant signals, the team begins to work in a disciplined manner in about a couple of months, that is, much faster.
Any signals that you make public, or send directly to the developer, in no case can not just take and turn on. First of all, it is necessary to coordinate this with the developer, to speak with him and with the team. It is advisable to put in writing all the thresholds in the Team Agreement, the reasons why you are doing this, what the next steps will be, and so on.
It should be borne in mind that all processes have exceptions, and take this into account at the design stage. We do not build a concentration camp for developerswhere it is impossible to take a step to the right, a step to the left. All processes have an exception, we just want to know about them. If the bot constantly swears for some task that cannot really be decomposed, and work on which will take 5 days, you need to put a “no-tracking” tag, so that the bot takes this into account and that's it. As a manager, you can separately monitor the number of such “no-tracking” tasks, and thereby understand how good those processes and the signals that you are building are. If the number of tasks labeled “no-tracking” is steadily growing, then, unfortunately, this means that the signals and processes that you have invented are difficult for the team, it cannot follow them, and it is easier for them to bypass them.
Manual control still remains.. It will not be possible to turn on the bot and go somewhere in Bali - you still have to deal with each situation. You received some kind of signal, the person didn’t react to him - you’ll have to find out in a day or two what the reason is, to speak the problem and work out a solution.
In order to optimize this process, we recommend introducing such practices as process attendant . This is a moving post of a person (once a week) who deals with the problems that the bot signals. And you, as a team leader, help the duty officer to deal with these problems, that is, you supervise him. Thus, the developer increases the motivation to work with this product. He understands his benefit, because he sees how these problems can be solved and how to react to them. Thereby you reduce your uniqueness to the team and bring closer the moment when the team becomes autonomous , and you can still go to Bali.
Conclusions
Collect data. Build processes so that you have data collected. Even if you do not want to build metrics and signals now, you can do a cool, retrospective analysis in the future if you now start collecting them.
Automatically monitor processes. When designing processes, always think about how you can hack them, and how you can recognize such hacks by data.
When the signals are not enough for several weeks - you are well done!We were faced with the fact that when the team sees that the signals are getting small, and the situation seems to be getting better, it starts frantically inventing some more practices, starts to introduce something in order to see these packets of signals again. This is not always necessary, perhaps, if the signals were not enough - you are fine, the team began to work as you wanted from the very beginning, and you are well done :)
Come share your Timlid finds on TeamLead Conf . The February conference will be held in Moscow and Call for Papers is already open . Want to get someone else's experience? Sign up for our newsletter on management to receive news of the program and not to miss the time of profitable purchase of tickets to the conference.