A brief history of one "smart tape"

Social networks are one of the most popular Internet products today and one of the main sources of data for analysis. Inside the social networks themselves, the most difficult and interesting task in the field of data science is considered to be the formation of the news line. After all, to meet the ever increasing demands of the user for the quality and relevance of the content, it is necessary to learn to collect information from many sources, calculate the forecast of the user's reaction and balance between dozens of competing metrics in the A / B test. And large amounts of data, high loads and stringent requirements for response speed make the task even more interesting.
It would seem that the ranking tasks for today have already been studied in and out, but if you look closely, it is not so simple. The content in the tape is very heterogeneous - this is a photo of friends, and memesiki, viral videos, longrides, and nauchpop. In order to put everything together, you need knowledge from different areas: computer vision, work with texts, recommendation systems, and, without fail, modern high-loaded storage and data processing facilities. Finding one person with all the skills is extremely difficult today, so sorting the tape is really a team task.
With different algorithms ranking ribbons in Odnoklassnikithey started experimenting back in 2012, and in 2014 machine learning was connected to this process. This was made possible primarily due to the progress in data flow technology. Only by starting to collect object displays and their signs in Kafka and aggregating logs with the help of Samza , we were able to build datasets for training models and calculate the most “pulling” features: Click Through Rate of the object and predictions of the reference system “based on” the work of colleagues from LinkedIn .

It quickly came to the realization that the workhorse of the logistic regression cannot take out the tape alone, because the user can have a very different reaction: class, comment, click, concealment, etc., while the content can be very different - photo a friend, a group post, or a vidosik faded by a friend. Each reaction for each type of content has its own specifics and its own business value. As a result, we came to the concept of “ logistic regressions matrix ”: for each type of content and each reaction a separate model is built, and then their forecasts are multiplied by a matrix of weights, formed by hands based on current business priorities.
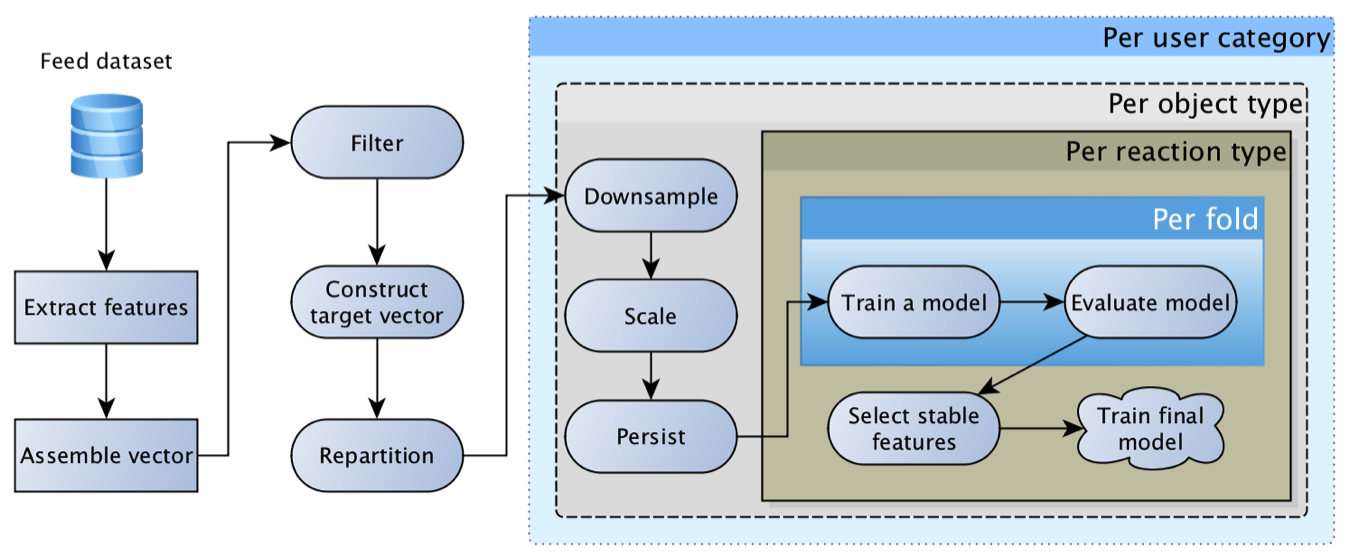
This model turned out to be extremely viable and for a long time was the main one. Over time, it has acquired more and more interesting signs: for objects, for users, for authors, for a user-author relationship, for those who interacted with an object, etc. As a result, the first attempts to replace the regression with a neural network ended in a sad “features we have are too finished, the boost grid does not give.”
At the same time, often the most noticeable boost from the point of view of user activity was given technical, rather than algorithmic improvements: scoop up more candidates for ranking, more accurately track the facts of the show, optimize the response rate of the algorithm, and deepen the viewing history. Such improvements often gave units, and sometimes even tens of percent of the increase in activity, while updating the model and adding a trait more often gave tenths of a percent increase.

Separate complexity in experiments with updating the model created a rebalance of content - the distribution of forecasts of the "new" model could often significantly differ from its predecessor, which led to the redistribution of traffic and feedback. As a result, it is difficult to assess the quality of the new model, as you first need to calibrate the balance of content (repeat the process of setting the matrix weights for business purposes). After studying the experience of colleagues from Facebook , we realized that the model needs to be calibrated , and an isotonic regression attached to the top of the logistic regression :).
Often, in the process of preparing new content attributes, we experienced frustration - a simple model using basic collaborative techniques can give 80%, or even 90% of the result, whereas a fashionable neural network that has been studying for a week on super-expensive GPUs will perfectly detect cats and cars, but it gives an increase metrics only in the third sign. A similar effect can often be seen when introducing thematic models, fastText, and other embeddings. It was possible to overcome the frustration by looking at validation from the right angle: the performance of collaborative algorithms improves significantly as information about the object is accumulated, while for “fresh” objects the content attributes give a noticeable boost.
But, of course, someday the results of the logistic regression should have been improved, and it was possible to make progress by applying the recently released XGBoost-Spark . Integration was not easy , but in the end, the model has finally become fashionable-youth, and the metrics have grown by interest.
Surely from the data you can extract much more knowledge and bring the ribbon ranking to a new height - and today everyone has the opportunity to try their hand at this nontrivial task at the SNA Hackathon 2019 competition. The competition takes place in two stages: from February 7 to March 15, download the solution to one of three problems. After March 15, interim results will be announced, and 15 people from the top leaderboard for each of the tasks will receive invitations to the second stage, which will be held from March 30 to April 1 in the Moscow office of Mail.ru Group. In addition, the invitation to the second stage will be received by three people who are at the top of the rating at the end of February 23.
Why are there three tasks? As part of the online phase, we offer three sets of data, each of which presents only one of the aspects: an image, a text, or information about various collaborative features. And only at the second stage, when experts in different areas come together, a common dataset will be revealed, allowing you to find points for synergy of different methods.
Interested in the task? Join SNA Hackathon :)