About proteins and complex networks
In pursuit of the post on proteins, I’ll try to talk about a seemingly unrelated topic of biology such as complex networks.
A complex network is called graphs with non-trivial topological properties. By non-trivial topological properties, we usually mean that the connections between the nodes of the graph are distributed according to a cunning law, which in turn gives various cluster structures, hubs, vulnerabilities, and so on.
The concept of a complex network grew out of the idea to track citation of scientific works in the 50s of the last century, and slowly grew, capturing the Internet, social networks, road networks and even many areas of theoretical physics, up to quantum. The pioneer of complex networks was the Hungarian mathematician Paul Erdős, who has published dozens of articles on network theory and related problems. It is curious that in his honor in the scientific community, citations were jokingly measured with the Erdosh number. This is a comic metric that shows the length of the connection between Erdosh and another author in a collaborator’s network. That is, if Vasily Pupkin is a co-author of Alfred Renyi, who in turn is a co-author of Erdosh, then Vasily has an Erdosh number of two (Paul and Alfred have zero and one, respectively).
One of the key problems (and, as a consequence, properties) in the theory of complex networks is the problem of splitting a network into clusters. A cluster is an array of nodes that are more connected to each other than to the rest of the network. Now there are dozens, if not hundreds, of clustering algorithms, but all have limitations and disadvantages: either they are too slow, or the computational time astronomically increases with the number of nodes, or accuracy suffers depending on the conditions of the initial task. In this article, we will use the gradient cluster algorithm, the essence of which is as follows: for each node, we leave only the maximum connection with the other node (thus excluding self-connections), deleting all the others. Thus, the network will be divided into subnets, which will be clusters.
In the upper picture, the clusters are easy to find by eye, and in the bottom?


Why is all this necessary? The fact is that proteins under the influence of external factors (temperature, pressure, ions, water etc) can be in different states (conformations), which correspond to different biological functions, which are not always useful. Usually, states are described by a certain parameter or several parameters (order parameter), such as the radius of inertia, the number of hydrogen bonds, the distance between certain atoms, etc.
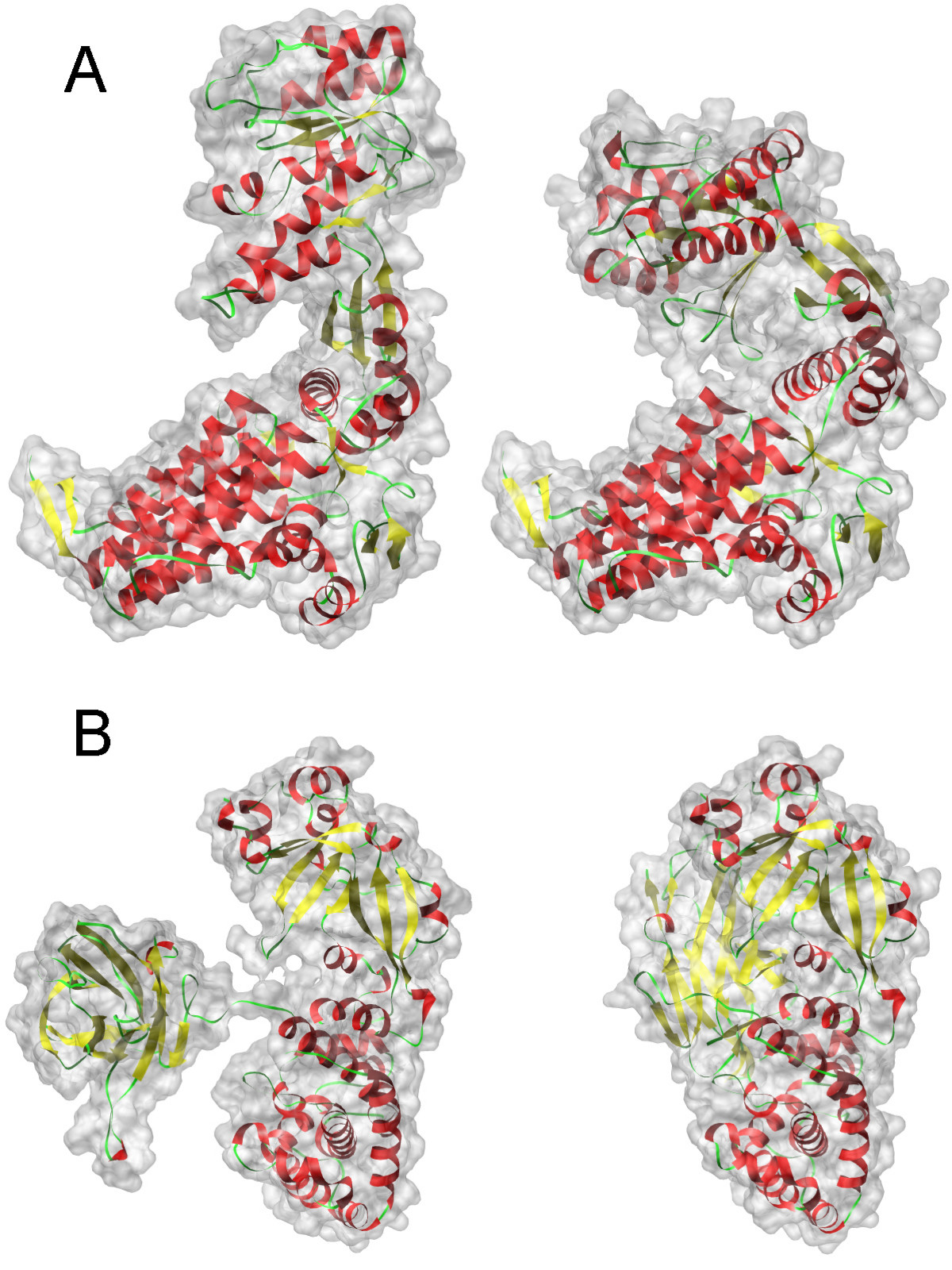
The picture shows two states of two different proteins. Functions in different states, respectively, are different
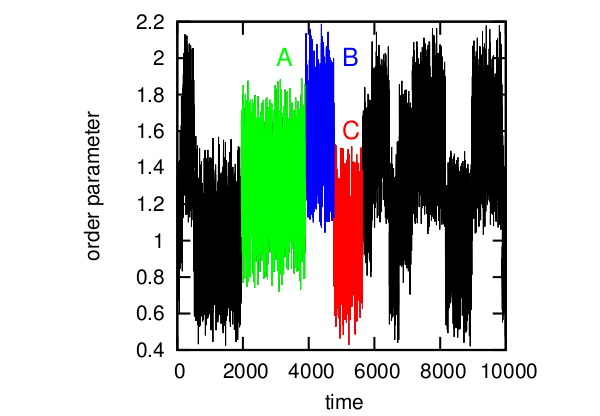
Consider the simplest example. The time series of the conditional order parameter for the protein. Here we can distinguish three states (A, B, C), which correspond to three states of the protein. Usually, in such cases, the formula F = -kT log (P) is used, where kT are constants, P is the probability of the state, and F is free energy, and a free energy profile is constructed whose minima correspond to different protein structures. And further, it would seem to be said that the system jumps between several energy wells, depending on external factors. Everything seems to be fine.
An example of a time series.
The profile of free energy.
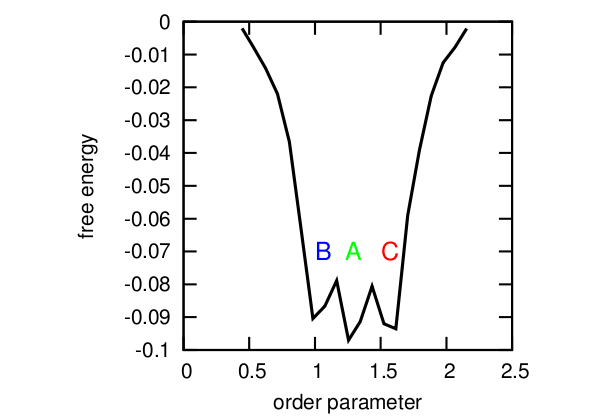
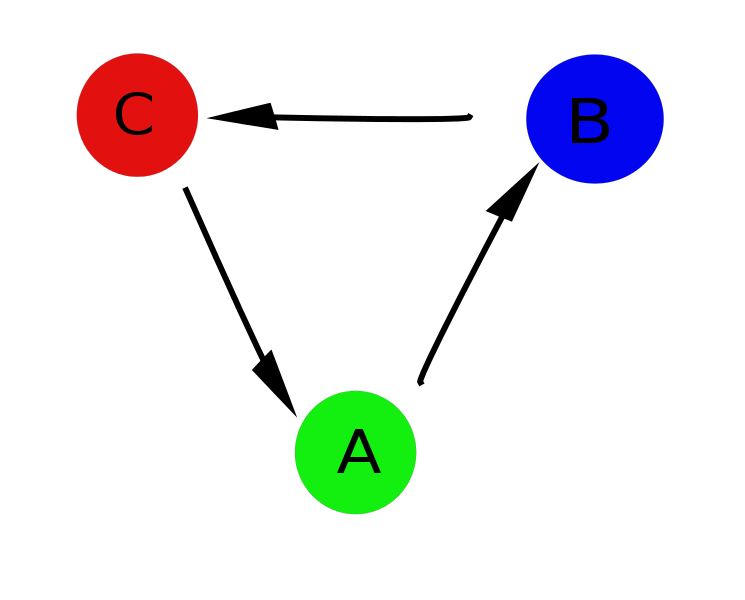
But there are several problems: the first, and the most obvious - it is not always possible to say what parameter value corresponds to which state (for example, with OP = 1.4, all three states are possible), and the profile we obtained slightly distorts the real picture. And secondly, the fact is that in fact there is a strictly defined cycle A-> B-> C, and the transition from state A to state C is directly impossible and projecting everything on one axis as a result, we got a picture that is quite far from reality.
And here networks come to the rescue. You can set the correspondence between the value of the order parameter at each moment of time and the network node, and create a connection with the weight equal to a conditional unit between two neighboring in time, and if during the analysis this moment is repeated, increase it accordingly. Further, as you already guessed, we apply the clustering algorithm described above, and we get a picture that really describes the system.
Bit of theory
A complex network is called graphs with non-trivial topological properties. By non-trivial topological properties, we usually mean that the connections between the nodes of the graph are distributed according to a cunning law, which in turn gives various cluster structures, hubs, vulnerabilities, and so on.
The concept of a complex network grew out of the idea to track citation of scientific works in the 50s of the last century, and slowly grew, capturing the Internet, social networks, road networks and even many areas of theoretical physics, up to quantum. The pioneer of complex networks was the Hungarian mathematician Paul Erdős, who has published dozens of articles on network theory and related problems. It is curious that in his honor in the scientific community, citations were jokingly measured with the Erdosh number. This is a comic metric that shows the length of the connection between Erdosh and another author in a collaborator’s network. That is, if Vasily Pupkin is a co-author of Alfred Renyi, who in turn is a co-author of Erdosh, then Vasily has an Erdosh number of two (Paul and Alfred have zero and one, respectively).
One of the key problems (and, as a consequence, properties) in the theory of complex networks is the problem of splitting a network into clusters. A cluster is an array of nodes that are more connected to each other than to the rest of the network. Now there are dozens, if not hundreds, of clustering algorithms, but all have limitations and disadvantages: either they are too slow, or the computational time astronomically increases with the number of nodes, or accuracy suffers depending on the conditions of the initial task. In this article, we will use the gradient cluster algorithm, the essence of which is as follows: for each node, we leave only the maximum connection with the other node (thus excluding self-connections), deleting all the others. Thus, the network will be divided into subnets, which will be clusters.
In the upper picture, the clusters are easy to find by eye, and in the bottom?
Application
Why is all this necessary? The fact is that proteins under the influence of external factors (temperature, pressure, ions, water etc) can be in different states (conformations), which correspond to different biological functions, which are not always useful. Usually, states are described by a certain parameter or several parameters (order parameter), such as the radius of inertia, the number of hydrogen bonds, the distance between certain atoms, etc.
The picture shows two states of two different proteins. Functions in different states, respectively, are different
Consider the simplest example. The time series of the conditional order parameter for the protein. Here we can distinguish three states (A, B, C), which correspond to three states of the protein. Usually, in such cases, the formula F = -kT log (P) is used, where kT are constants, P is the probability of the state, and F is free energy, and a free energy profile is constructed whose minima correspond to different protein structures. And further, it would seem to be said that the system jumps between several energy wells, depending on external factors. Everything seems to be fine.
An example of a time series.
The profile of free energy.
But there are several problems: the first, and the most obvious - it is not always possible to say what parameter value corresponds to which state (for example, with OP = 1.4, all three states are possible), and the profile we obtained slightly distorts the real picture. And secondly, the fact is that in fact there is a strictly defined cycle A-> B-> C, and the transition from state A to state C is directly impossible and projecting everything on one axis as a result, we got a picture that is quite far from reality.
And here networks come to the rescue. You can set the correspondence between the value of the order parameter at each moment of time and the network node, and create a connection with the weight equal to a conditional unit between two neighboring in time, and if during the analysis this moment is repeated, increase it accordingly. Further, as you already guessed, we apply the clustering algorithm described above, and we get a picture that really describes the system.