Databases in online games. From Allods Online to Skyforge
When talking about game development, usually it’s about shaders, graphics, AI, etc. Extremely rarely affects the server side of game projects, and even less so - databases. We will correct this annoying misunderstanding: today I will talk about our experience with databases that we acquired during the development of Allods Online and our new Skyforge project . Both of these games are client MMORPGs. In the first, several million players are registered. The second is developed by the studio in the strictest secrecy in the bowels of the Allods Team.
My name is Andrey Frolov. I am the lead programmer for Allods Team and work as a server team. My development experience is almost 10 years, but I only got into games in October 2009. I have been in the team for more than three years, since March 2010. I started working on Allods Online, and now on Skyforge. I’m doing everything that is somehow connected with the Skyforge server and databases. In this article I will talk about databases in online games using the example of Allods and Skyforge.

If you don’t really like to read, I suggest scrolling through the article to the end and watch a video of my report from the Game Developers Conference. Those who remain in the post have a bonus - an important addition to the report in the form of a story about NoSQL-JSON hybrid and a relational data model.
The game base is a typical OLTP system (many small and short transactions). But the use of databases in games is somewhat different from their use on the web, banks and other enterprises. Firstly, this is due to the fact that the data model in games is much more complicated than in banks. Secondly, most programmers in game dev came out of the harsh world of C ++, taking with them a beard and a love of binary packaging. Absolutely all of them, if they need to save the character to disk, the first thing they want to serialize it to a file. That is how it all began in Allods Online. Programmers made a file storage, but quickly thought better of it and rewrote everything under MySQL. The project was successfully launched, people played, experience accumulated.
What we had in Allods:
A few years later Skyforge started. Skyforge had completely different requirements, and therefore had to rethink our approach to working with databases.
These are the requirements:
Well, let's look behind the scenes and see what we came to during the evolutionary development of our technological thought.
Firstly, our server is distributed. The base is also distributed. Secondly, the architecture of our server is service-oriented. This means that everything is presented in the form of services that exchange messages. There are dozens of services in the game, but only transaction execution services have direct access to the database. In general terms and to the best of my artistic abilities, it looks something like this:

You just need to consider that all the elements shown in the picture exist in several copies.
This simple scheme has one important point. Our avatar is needed for the performance of game mechanics, but as a side effect, it is actually a cache over the database. All requests of the form “Show me the items of this player” or “Where is Vasily's avatar?” served by this avatar. When a player enters the game, we upload his avatar, and he lives as long as the player is online. Such a simple trick allows you to remove from the database most of the read requests, and even part of the write requests.
We divide all player data into two categories:
So, how do we synchronize the state of our important data in the database and the avatar that is on another server? Everything is actually quite simple. Consider the scheme of taking the subject.
At Skyforge, we abandoned MySQL for a combination of the reasons listed below.
PostgreSQL solved all these problems, in return giving only a problem with auto-vacuum. We decided not to take the NoSQL database, because we have very high requirements for data consistency, and not a single NoSQL database in the world can consistently and transactionally transfer an item from one avatar to another. Eventual consistency in this case did not suit us very much, because it spoils the game experience a lot.
The fact that we use PostgreSQL does not mean that we should store data in a relational form. The relational database can be used as key-value storage. The
completely relational model does not suit us, because contains several performance bottlenecks. For example, we have a player, and he has quests. A player can complete hundreds of quests, and upon entering the game we will need to show them all. If you use the relational model, you have to make a request to return hundreds of rows from the database, and this is slow. On the other hand, the non-relational model has many disadvantages: the absence of constants, the inability to partially update the data, etc.
After various experiments, we agreed that we are satisfied with a bundle of the relational model, in which some of the fields contain non-relational data. In Allods and until recently in Skyforge we serialized part of the data binary and stored as fields in tables. But just three weeks ago, we finally understood everything and now we store the data in a relational schema with JSON inserts.
It looks something like this:
Such a scheme allows us to use all the bonuses of the relational model and compensate for its bottlenecks with non-relational inserts on JSON. In addition, PostgreSQL 9.3 allows you to make JSON queries. Thus, we get a kind of two-in-one cocktail - PostgreSQL and MongoDB at the price of PostgreSQL.
To cope with the load on the record, we shard our database of accounts. To do this, in the entity ID, we encode the number of the shard on which the avatar lives, and the account.
The ID consists of two parts: the first byte is the number of the shard, the rest is the entity ID inside the shard.
long id =
The game has several dozen database services. Each of them is single-thread and works with its own small base. We put several such small bases on one physical service. This approach is used by many Internet giants, it is called virtual shards and solves the problem of rebalancing. Suppose we have two physical servers, and on them lies 15 small shards. If we suddenly got a lot of users and everything began to slow down, we just buy another server and transfer 5 shards from the old servers to it. And instead of a 2x10 scheme, we very simply get a 3x10 scheme. In this way, rebalancing can be very simple without having to saw data inside the database.
The real silver bullet in the fight for performance for us was the SSD. Solid state drives allowed us to write thousands of transactions per second to disk without costly RAID arrays. And, which is very important for us, we write data to the disk synchronously, without delayed commits and disabling fsync.
A small digression. Our game database is actually not very large, about 200 GB, and therefore can fit on one SSD. But if you approach the problem of database performance wisely, using SSD you can accelerate larger databases. It is enough to put PostgreSQL WAL files on the SSD, into which the main load is written, and the rest of the data can be placed on slower disks. As a result, almost any project can benefit from using SSD!
There are four facts, a combination of which led us to an interesting solution.
From here a great idea was born, how to use the processor power of a replica machine and increase the reliability of data storage.
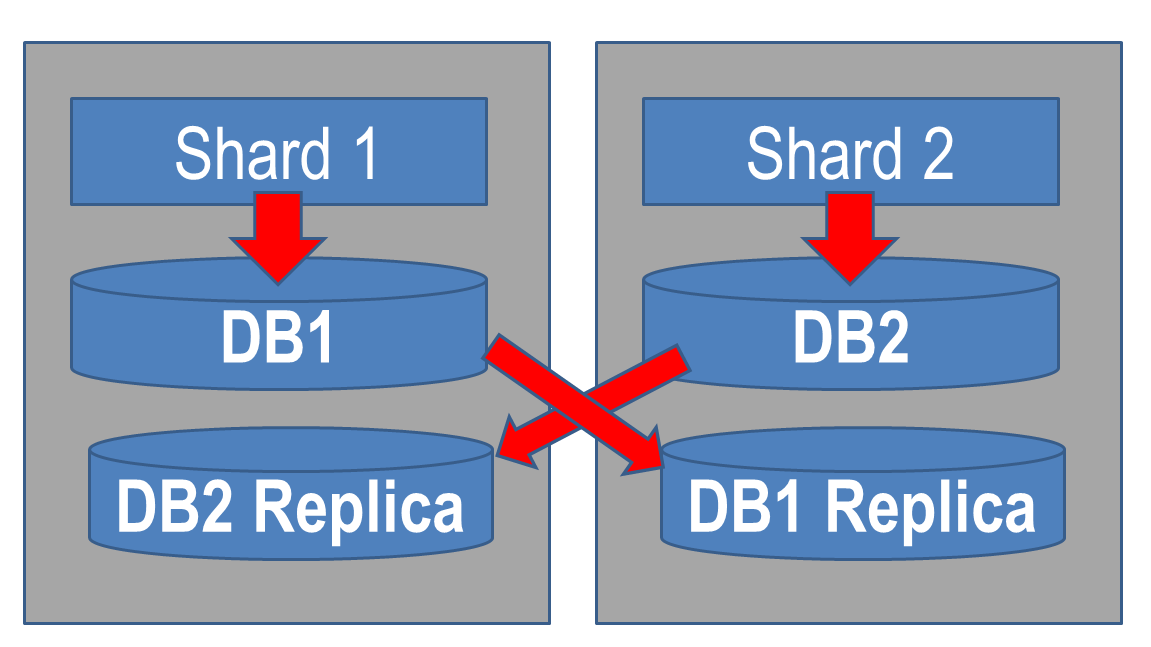
Databases located on the first server are synchronously replicated to the second. The second server synchronously replicates to the first. Thus, instead of a master-slave pair, we get two full-fledged servers, double redundancy and the presence of a replica, which can be transferred to asynchronous mode and saved without harm to the main server.
You can learn more about this and some other topics from the video recording of the report from the Game Developers Conference.
Slides are available here.
I will be happy to answer questions about the database in online games in the comments.
The rest of our articles on various aspects of the work of games can be read on our website and in our Vkontakte community
My name is Andrey Frolov. I am the lead programmer for Allods Team and work as a server team. My development experience is almost 10 years, but I only got into games in October 2009. I have been in the team for more than three years, since March 2010. I started working on Allods Online, and now on Skyforge. I’m doing everything that is somehow connected with the Skyforge server and databases. In this article I will talk about databases in online games using the example of Allods and Skyforge.
If you don’t really like to read, I suggest scrolling through the article to the end and watch a video of my report from the Game Developers Conference. Those who remain in the post have a bonus - an important addition to the report in the form of a story about NoSQL-JSON hybrid and a relational data model.
Evolution
The game base is a typical OLTP system (many small and short transactions). But the use of databases in games is somewhat different from their use on the web, banks and other enterprises. Firstly, this is due to the fact that the data model in games is much more complicated than in banks. Secondly, most programmers in game dev came out of the harsh world of C ++, taking with them a beard and a love of binary packaging. Absolutely all of them, if they need to save the character to disk, the first thing they want to serialize it to a file. That is how it all began in Allods Online. Programmers made a file storage, but quickly thought better of it and rewrote everything under MySQL. The project was successfully launched, people played, experience accumulated.
What we had in Allods:
- Java, MySQL
- Shards. And each of them was designed for a certain limited number of players who are online
- This number of players generated approximately 200 transactions per second
- The service that works with the database was monotraded, because that was enough for so many transactions
A few years later Skyforge started. Skyforge had completely different requirements, and therefore had to rethink our approach to working with databases.
These are the requirements:
- We no longer have shards. We have one big united world
- We count our server on 100,000 players who are online, and possibly more
- According to our estimates, these players should issue more than 7000 transactions per second
- We still write in Java, but with MySQL we switched to PostgreSQL
Well, let's look behind the scenes and see what we came to during the evolutionary development of our technological thought.
Architecture
Firstly, our server is distributed. The base is also distributed. Secondly, the architecture of our server is service-oriented. This means that everything is presented in the form of services that exchange messages. There are dozens of services in the game, but only transaction execution services have direct access to the database. In general terms and to the best of my artistic abilities, it looks something like this:
You just need to consider that all the elements shown in the picture exist in several copies.
- There are avatars on the game mechanics servers. An avatar is a Java object representing our player. There are several times more game mechanics servers than database servers.
- All servers communicate with the database through a special interface. This interface contains hundreds of methods, hides the distributed essence of the base from programmers of game mechanics and provides an understandable contract: one method - one transaction. You need to understand that this is not one class with hundreds of methods, but one class with ten methods, which give small "subinterfaces" with ten methods each. A kind of "pack" of operations.
- The database service (database) performs the operations that have arrived and writes their results to the database. The database service and the database itself are located on the same physical server so as not to waste extra time on the network.
Avatar as a cache
This simple scheme has one important point. Our avatar is needed for the performance of game mechanics, but as a side effect, it is actually a cache over the database. All requests of the form “Show me the items of this player” or “Where is Vasily's avatar?” served by this avatar. When a player enters the game, we upload his avatar, and he lives as long as the player is online. Such a simple trick allows you to remove from the database most of the read requests, and even part of the write requests.
We divide all player data into two categories:
- Unimportant data, the loss of which the player can survive. These include position on the map, level of health, etc. We "accumulate" such data from the avatar and periodically, as well as once upon leaving the game, we drop it into the database.
- Important data, the loss of which will be painful for the player. These include items, money, quests and similar things. With this data, everything is much more complicated. We try to make sure that the player never lost this data, because he spent a lot of time and effort on them. Therefore, they must be saved to the database synchronously. It is the preservation of important data that creates the main burden on our database.
So, how do we synchronize the state of our important data in the database and the avatar that is on another server? Everything is actually quite simple. Consider the scheme of taking the subject.
- The game mechanics server sends a request to the database service “take item XXX”.
- The database server performs the necessary checks (is there enough space in the bag, does this item need to be “glazed”, and so on). After that, he saves the updated state of the avatar bag to the base.
- Only if the save was successful, will the avatar be updated with the status of his bag. The avatar, in turn, sends updates to the game client. As a result, the player will see that he has an item, only when the item is safely stored in the base.
PostgreSQL
At Skyforge, we abandoned MySQL for a combination of the reasons listed below.
- In MySQL, all features are spread over various storage engines. Something was in InnoDB, something in MyISAM, something in the MEMORY engine. This greatly complicated life.
- In MySQL, a distributed transaction mechanism is broken, which we really wanted to use. MySQL developers promised to fix it only to the sixth version, which is not yet even in the plans.
- In MySQL, the mechanism of group commit was broken. It was repaired in version 5.5, and this item is no longer relevant.
- In MySQL, there are actually quite a few bugs, strange features and a very limited query optimizer.
PostgreSQL solved all these problems, in return giving only a problem with auto-vacuum. We decided not to take the NoSQL database, because we have very high requirements for data consistency, and not a single NoSQL database in the world can consistently and transactionally transfer an item from one avatar to another. Eventual consistency in this case did not suit us very much, because it spoils the game experience a lot.
Hybrid data schema
The fact that we use PostgreSQL does not mean that we should store data in a relational form. The relational database can be used as key-value storage. The
completely relational model does not suit us, because contains several performance bottlenecks. For example, we have a player, and he has quests. A player can complete hundreds of quests, and upon entering the game we will need to show them all. If you use the relational model, you have to make a request to return hundreds of rows from the database, and this is slow. On the other hand, the non-relational model has many disadvantages: the absence of constants, the inability to partially update the data, etc.
After various experiments, we agreed that we are satisfied with a bundle of the relational model, in which some of the fields contain non-relational data. In Allods and until recently in Skyforge we serialized part of the data binary and stored as fields in tables. But just three weeks ago, we finally understood everything and now we store the data in a relational schema with JSON inserts.
It looks something like this:
# select * from avatar limit 1;
id | 144115188075857124
position |
{"point":{"x":7402.2793,"y":6080.2197,"z":51.42402},"yaw":0.0,"map":"id:132646944","isLocal":false,"isValid":true}
death_descriptor | {"deathTime":-1,"respawnTime":-1,"sparkReturnDelay":-1,"recentDeathTimesArray":[]}
health | 1250
mana_descriptor | {"mana":{"8":300}}
avatar_client_info | \x
character_race_class_res_id | 26209282
character_sex_res_id | 550995
last_online_time | 1371814800726
Such a scheme allows us to use all the bonuses of the relational model and compensate for its bottlenecks with non-relational inserts on JSON. In addition, PostgreSQL 9.3 allows you to make JSON queries. Thus, we get a kind of two-in-one cocktail - PostgreSQL and MongoDB at the price of PostgreSQL.
Virtual shards
To cope with the load on the record, we shard our database of accounts. To do this, in the entity ID, we encode the number of the shard on which the avatar lives, and the account.
The ID consists of two parts: the first byte is the number of the shard, the rest is the entity ID inside the shard.
long id =
The game has several dozen database services. Each of them is single-thread and works with its own small base. We put several such small bases on one physical service. This approach is used by many Internet giants, it is called virtual shards and solves the problem of rebalancing. Suppose we have two physical servers, and on them lies 15 small shards. If we suddenly got a lot of users and everything began to slow down, we just buy another server and transfer 5 shards from the old servers to it. And instead of a 2x10 scheme, we very simply get a 3x10 scheme. In this way, rebalancing can be very simple without having to saw data inside the database.
SSD
The real silver bullet in the fight for performance for us was the SSD. Solid state drives allowed us to write thousands of transactions per second to disk without costly RAID arrays. And, which is very important for us, we write data to the disk synchronously, without delayed commits and disabling fsync.
A small digression. Our game database is actually not very large, about 200 GB, and therefore can fit on one SSD. But if you approach the problem of database performance wisely, using SSD you can accelerate larger databases. It is enough to put PostgreSQL WAL files on the SSD, into which the main load is written, and the rest of the data can be placed on slower disks. As a result, almost any project can benefit from using SSD!
Cross replica
There are four facts, a combination of which led us to an interesting solution.
- PostgreSQL provides a very interesting feature - synchronous replication.
- A large performance boost from the SSD allows you to relax a bit and not sacrifice reliability for speed.
- For backup and other service purposes, each database server requires a replica server.
- Rolling a replica spends significantly less resources than performing the same operations on the master. Replica server resources are almost always idle.
From here a great idea was born, how to use the processor power of a replica machine and increase the reliability of data storage.
Databases located on the first server are synchronously replicated to the second. The second server synchronously replicates to the first. Thus, instead of a master-slave pair, we get two full-fledged servers, double redundancy and the presence of a replica, which can be transferred to asynchronous mode and saved without harm to the main server.
Videos, slides
You can learn more about this and some other topics from the video recording of the report from the Game Developers Conference.
Slides are available here.
I will be happy to answer questions about the database in online games in the comments.
The rest of our articles on various aspects of the work of games can be read on our website and in our Vkontakte community