Configuring a multi-region cluster for cloud storage with OpenStack Swift
Author: Oleg Gelbukh
Last fall, the SwiftStack team posted an interesting overview of their approach to creating multi-regional OpenStack Object Storage clusters (project code name is Swift). This approach goes well with the geographically distributed Swift cluster layout with a reduced number of replicas (3 + 1 instead of 3 + 3, for example), which we worked on with Webex around the same time. I would like to briefly describe our approach and focus on the implementation plan and proposed changes to the Swift code.
I would like to start with a brief overview of the current Swift algorithms, then explain what exactly needs to be done to create a cluster of several geographically separated regions.
The Swift cluster standard ring (ring or hash ring) is a data structure that allows you to separate storage devices into zones. The swift-ring-builder script included in the Essex release ensures that replicas of objects do not fall into the same zone.
The ring structure includes the following components:
- Device list : includes all storage devices (disks) known to the ring. Each element of this list is a dictionary that includes the device identifier, its symbolic name, zone identifier, IP address of the data storage node on which the storage device is installed, network port, weight and metadata.
- Partition allocation table: A two-dimensional array with the number of rows equal to the number of replicas. Each cell of the array contains the identifier of the device (from the list of devices) on which the replica of the section corresponding to the column index is located ...
- Section area number: number of bits from the MD5 checksum from the path to the object (/ account / container / objec), which determines the partition of everything spaces of possible MD5 hashes per partition.
In the Folsom version, changes were made to the ring file format. These changes significantly increase processing efficiency and redefine the ring balancing algorithm. The strict condition, which required the distribution of replicas across different zones, was replaced by a much more flexible algorithm that organizes zones, nodes and devices into layers.
The ring balancer tries to position the replicas as far apart as possible; preferably in different zones, but if only one zone is available, then in different nodes; and if only one node is available, then to various devices on the node. This algorithm, operating on the principle of “maximum distribution”, potentially supports a geographically distributed cluster. This can be achieved by adding a region-level diagram to the top. A region is essentially a group of zones with one location, be it a rack or an entire data center.
In our proposal, a region is defined in the same field (region) in the devs device dictionary.
The proxy server provides the public Swift API to clients and performs basic operations with objects, containers and accounts, including writing with a PUT request and reading with a GET request.
When servicing PUT requests, the proxy server follows the following algorithm:
1. Calculates the MD5 checksum of the path to the object in the format / account [/ container [/ object]].
2. Computes the partition number as the first N bits of the MD5 checksum.
3. Selects devices from the partition distribution table on which replicas of the calculated partition are stored.
4. Selects the IP address and port of the data storage node from the list of devices for all devices found in step # 3.
5. It will try to establish a connection to all nodes on the corresponding ports, if it is impossible to connect to at least half of the nodes, rejects the PUT request.
6. Tries to download the object (or create an account or container) on all nodes to which a connection has been established; if at least half of the downloads are canceled, rejects the PUT request.
7. If the data is uploaded to N / 2 + 1 nodes (where N is the number of nodes found in step # 4), it sends a confirmation of a successful PUT request to the client.
When serving GET requests, the proxy server in general performs the following algorithm:
1. Repeats steps 1-4 of the PUT request processing algorithm and determines the list of nodes that store replicas of objects.
2. Shuffles the list of nodes using the shuffle function and connects to the first of the received list.
3. If it is not possible to establish a connection, proceeds to the next node from the list.
4. If the connection is established, it begins to transmit data to the client in response to the request.
Replication in Swift works on partitions, not on individual objects. The replicator workflow starts periodically with a custom interval. The default interval is 30 seconds.
The replicator in general follows the following algorithm:
1. Create a replicator task. That is, scan all devices on the node, scan all found devices and find a list of all partitions, and then create a replication dictionary for each section.
{
'path':,
'nodes': [replica_node1, replica_node2, ...],
'delete':,
'partition':}
-- this is the path in the file system to the partition (/ srv / node // objects /)
- [replica_node1, replica_node2, ...] is the list of nodes that store replicas of partitions. The list is imported from the ring for objects.
- 'delete' is set to true if the number of replicas in this section exceeds the configured number of replicas in the cluster.
- represents the section identifier number.
2. Process each section in accordance with the task for replication. That is:
- If the section is marked for deletion, the replicator maps each subdirectory of the job ['path'] directory to all nodes from the job ['nodes'] list, sends a REPLICATE request to each node on which the replica is located, and removes the job [' path '].
- If the section is not marked for deletion, the replicator calculates the checksums of the contents of all subfolders of the job ['path'] directory (that is, the account / container databases and object files in the section). The replicator issues a REPLICATE request to all replicas of the job ['partition'] section and receives in response from the remote subfolders of the checksum correspondence section. It then compares the checksum mappings and uses rsync to send the modified subfolders to the remote nodes. Replication success is verified by resubmitting the REPLICATE request.
3. If there is no access to the so-called “main” replica, the replicator uses the get_more_node method of the ring class. This method uses a specific deterministic algorithm to determine the set of “spare” nodes where you can save a temporary copy of this section ... The algorithm determines the zone to which the “main” device that failed, and selects the “spare” device from another zone to save the temporary section replicas. If another device is also not available, a node is selected from the third zone, and the cycle continues until all zones and all nodes are enumerated.
We suggest adding a region field to the list of devices. This parameter should use the RingBuilder class when balancing the ring as described below. The region parameter is an additional level in the system that allows you to group zones. Thus, all devices that belong to zones that make up one region must belong to that region.
In addition, regions can be added to the ring as an additional structure — a dictionary with regions as keys and a list of zones as values, for example:
It is important to note that a zone can belong to only one region.
In this case, the regions are used similarly to the previous use, but the ring class must include additional code for processing the dictionary of regional zone assignments and determine to which region a particular device belongs.
Assigning a default region to a zone should assign all zones to a single default region to play standard Swift behavior.
In the latest release of the Swift project, regional level support has already been added to the ring, which means an important step towards the full implementation of geographically distributed object storage based on Swift.
The RingBuilder balancing algorithm should recognize the region setting in the device list. The algorithm can be configured to distribute replicas in various ways. Below we offer one of the possible implementations of the distribution algorithm that we selected for the development of the prototype.
Partition replicas should be placed on devices with the following conditions:
- Replicas must be located on devices belonging to different groups at the highest possible level (standard behavior of the ring balancing algorithm).
- For N replicas and M regions (zone groups), the number of replicas falling into each region is equal to the integer number of quotients from the N / M division. The rest of the replicas is added to one region (which is the main one for this section).
- A region cannot contain more replicas than the number of zones in a region.
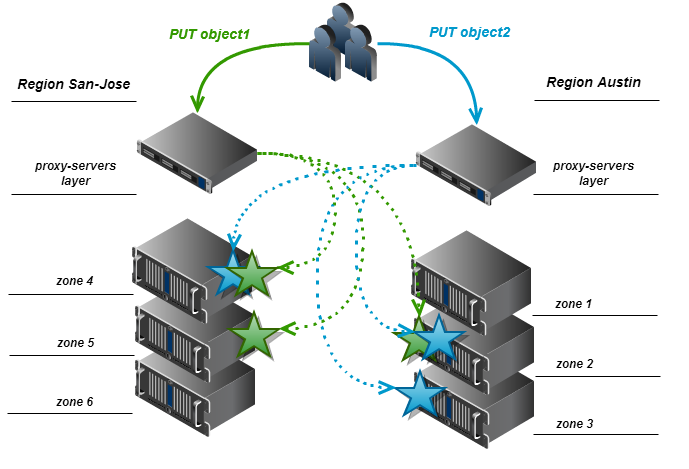
For example, if N = 3 and M = 2, with this algorithm we will have a ring in which one replica is included in each region (the integer part of the fraction 3/2 is 1), and the remaining one replica is included in one of the two regions, randomly selected. The diagram below reflects the distribution of replicas by region in the example above.
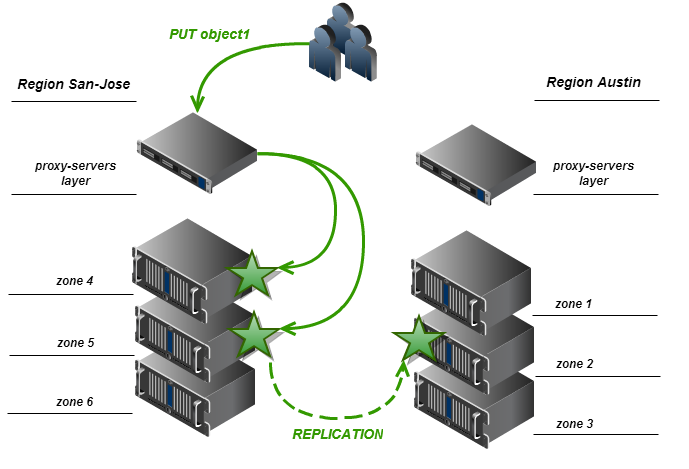
Performing a direct PUT request from a proxy server to a storage node in a remote region is not so simple: in most cases, we may not have access to the cluster’s internal network from outside. Thus, for the initial implementation, we assume that only local replicas are written when the PUT request is executed, and remote regional replicas are created by the replication process.
By default, the number of replicas is three, and the regions are one. This case reproduces the standard Swift configuration and ring balancing algorithm.
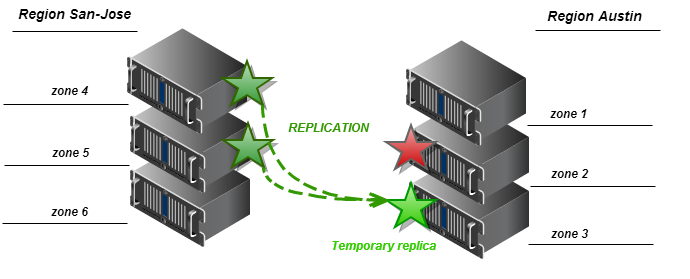
We suggest changes to the get_more_nodes method of the Ring class to recognize regions when selecting “spare” zones for temporary replicas. The algorithm should sort candidates for “spare” so that zones from the region that contains the lost replica are selected first. If the local region does not have access to the zones (for example, the network connection between the regions is closed), the algorithm returns the node that belongs to the zone from one of the external regions. The following two schemes describe the algorithm for two extreme cases.
For the Swift proxy server to work correctly in an environment with several geographically distributed regions, it needs to have the information to which region it belongs. A proxy server can obtain this information based on an analysis of network latency when connecting to data storage servers, or directly from a configuration file. The first approach is implemented in the current version of Swift (1.8.0). The proxy server sorts the data storage nodes based on the response time after connecting to each of them, and selects the fastest one to read. This approach works well for read requests, but when writing, you need to work with all the “main” storage servers, as well as possibly with a few “spare” ones. In this case, the configuration method for determining the local region is better suited.
This is quite simple by adding a region parameter to the [DEFAULT] section of the proxy server configuration file (proxy-server.conf), for example:
[DEFAULT]
...
region = san-jose
This parameter is used by the proxy server for ring reading operations, and also possibly when choosing nodes to serve GET requests. Our goal is for the proxy server to prefer to connect to storage nodes from local zones (that is, zones that belong to the same region as the proxy server).
In a SwiftStack article, this functionality is called proxy affinity.
A proxy server should not read data from a host that belongs to an external region if a local replica is available. This allows you to reduce the load on network connections between regions, and also work when there is no network connection between regions (as a result of a temporary failure or cluster topology features).
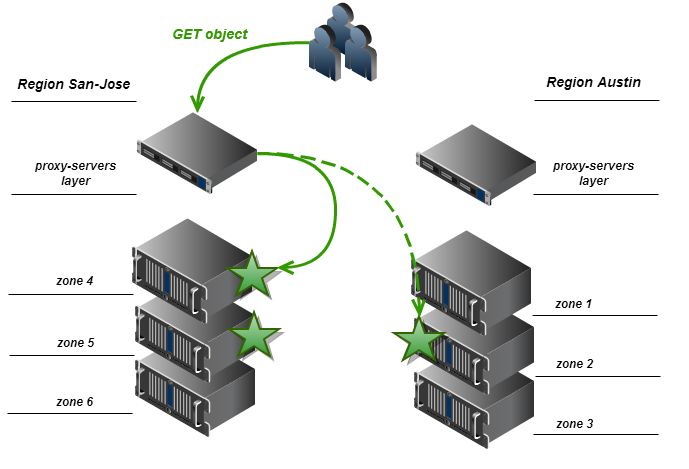
We then replace the node list shuffle operation in step # 2 of the GET request processing algorithm (see above) with a procedure that arranges the nodes in such a way that the drives belonging to the local proxy region are the first in the list. After this sorting, the lists of local regional and external regional nodes are mixed independently, and then the list of external regional nodes is added to the list of local regional nodes. As an alternative, at this stage, the method described above for selecting the data storage node for the minimum response time can be used.
Replication between geographically distributed data centers in our prototype works for the regions as a whole as for a cluster with one region. However, since a huge number of REPLICATE requests between clusters over a low-speed WAN connection can be sent as part of the replication process. This can lead to a serious drop in overall cluster performance.
As a simple workaround for this problem, add a counter to the replicator in such a way that partitions are transferred to devices in the remote region for every Nth replication. More complex solutions may include dedicated replicator gateways in neighboring regions, and will be developed as part of our research project.
Original article in English
Last fall, the SwiftStack team posted an interesting overview of their approach to creating multi-regional OpenStack Object Storage clusters (project code name is Swift). This approach goes well with the geographically distributed Swift cluster layout with a reduced number of replicas (3 + 1 instead of 3 + 3, for example), which we worked on with Webex around the same time. I would like to briefly describe our approach and focus on the implementation plan and proposed changes to the Swift code.
Current Status of OpenStack Swift
I would like to start with a brief overview of the current Swift algorithms, then explain what exactly needs to be done to create a cluster of several geographically separated regions.
Ring
The Swift cluster standard ring (ring or hash ring) is a data structure that allows you to separate storage devices into zones. The swift-ring-builder script included in the Essex release ensures that replicas of objects do not fall into the same zone.
The ring structure includes the following components:
- Device list : includes all storage devices (disks) known to the ring. Each element of this list is a dictionary that includes the device identifier, its symbolic name, zone identifier, IP address of the data storage node on which the storage device is installed, network port, weight and metadata.
- Partition allocation table: A two-dimensional array with the number of rows equal to the number of replicas. Each cell of the array contains the identifier of the device (from the list of devices) on which the replica of the section corresponding to the column index is located ...
- Section area number: number of bits from the MD5 checksum from the path to the object (/ account / container / objec), which determines the partition of everything spaces of possible MD5 hashes per partition.
In the Folsom version, changes were made to the ring file format. These changes significantly increase processing efficiency and redefine the ring balancing algorithm. The strict condition, which required the distribution of replicas across different zones, was replaced by a much more flexible algorithm that organizes zones, nodes and devices into layers.
The ring balancer tries to position the replicas as far apart as possible; preferably in different zones, but if only one zone is available, then in different nodes; and if only one node is available, then to various devices on the node. This algorithm, operating on the principle of “maximum distribution”, potentially supports a geographically distributed cluster. This can be achieved by adding a region-level diagram to the top. A region is essentially a group of zones with one location, be it a rack or an entire data center.
In our proposal, a region is defined in the same field (region) in the devs device dictionary.
Proxy server
The proxy server provides the public Swift API to clients and performs basic operations with objects, containers and accounts, including writing with a PUT request and reading with a GET request.
When servicing PUT requests, the proxy server follows the following algorithm:
1. Calculates the MD5 checksum of the path to the object in the format / account [/ container [/ object]].
2. Computes the partition number as the first N bits of the MD5 checksum.
3. Selects devices from the partition distribution table on which replicas of the calculated partition are stored.
4. Selects the IP address and port of the data storage node from the list of devices for all devices found in step # 3.
5. It will try to establish a connection to all nodes on the corresponding ports, if it is impossible to connect to at least half of the nodes, rejects the PUT request.
6. Tries to download the object (or create an account or container) on all nodes to which a connection has been established; if at least half of the downloads are canceled, rejects the PUT request.
7. If the data is uploaded to N / 2 + 1 nodes (where N is the number of nodes found in step # 4), it sends a confirmation of a successful PUT request to the client.
When serving GET requests, the proxy server in general performs the following algorithm:
1. Repeats steps 1-4 of the PUT request processing algorithm and determines the list of nodes that store replicas of objects.
2. Shuffles the list of nodes using the shuffle function and connects to the first of the received list.
3. If it is not possible to establish a connection, proceeds to the next node from the list.
4. If the connection is established, it begins to transmit data to the client in response to the request.
Replication
Replication in Swift works on partitions, not on individual objects. The replicator workflow starts periodically with a custom interval. The default interval is 30 seconds.
The replicator in general follows the following algorithm:
1. Create a replicator task. That is, scan all devices on the node, scan all found devices and find a list of all partitions, and then create a replication dictionary for each section.
{
'path':
'nodes': [replica_node1, replica_node2, ...],
'delete':
'partition':}
-
- [replica_node1, replica_node2, ...] is the list of nodes that store replicas of partitions. The list is imported from the ring for objects.
- 'delete' is set to true if the number of replicas in this section exceeds the configured number of replicas in the cluster.
- represents the section identifier number.
2. Process each section in accordance with the task for replication. That is:
- If the section is marked for deletion, the replicator maps each subdirectory of the job ['path'] directory to all nodes from the job ['nodes'] list, sends a REPLICATE request to each node on which the replica is located, and removes the job [' path '].
- If the section is not marked for deletion, the replicator calculates the checksums of the contents of all subfolders of the job ['path'] directory (that is, the account / container databases and object files in the section). The replicator issues a REPLICATE request to all replicas of the job ['partition'] section and receives in response from the remote subfolders of the checksum correspondence section. It then compares the checksum mappings and uses rsync to send the modified subfolders to the remote nodes. Replication success is verified by resubmitting the REPLICATE request.
3. If there is no access to the so-called “main” replica, the replicator uses the get_more_node method of the ring class. This method uses a specific deterministic algorithm to determine the set of “spare” nodes where you can save a temporary copy of this section ... The algorithm determines the zone to which the “main” device that failed, and selects the “spare” device from another zone to save the temporary section replicas. If another device is also not available, a node is selected from the third zone, and the cycle continues until all zones and all nodes are enumerated.
Proposed Changes to OpenStack Swift
Adding a “Region” Level to a Ring
We suggest adding a region field to the list of devices. This parameter should use the RingBuilder class when balancing the ring as described below. The region parameter is an additional level in the system that allows you to group zones. Thus, all devices that belong to zones that make up one region must belong to that region.
In addition, regions can be added to the ring as an additional structure — a dictionary with regions as keys and a list of zones as values, for example:
| Key (region) | Value (list of zones) |
| Austin | 1,2,3 |
| San jose | 4,5,6 |
It is important to note that a zone can belong to only one region.
In this case, the regions are used similarly to the previous use, but the ring class must include additional code for processing the dictionary of regional zone assignments and determine to which region a particular device belongs.
Assigning a default region to a zone should assign all zones to a single default region to play standard Swift behavior.
In the latest release of the Swift project, regional level support has already been added to the ring, which means an important step towards the full implementation of geographically distributed object storage based on Swift.
Fine tune RingBuilder balancing algorithm
The RingBuilder balancing algorithm should recognize the region setting in the device list. The algorithm can be configured to distribute replicas in various ways. Below we offer one of the possible implementations of the distribution algorithm that we selected for the development of the prototype.
Alternate Distribution Algorithm
Partition replicas should be placed on devices with the following conditions:
- Replicas must be located on devices belonging to different groups at the highest possible level (standard behavior of the ring balancing algorithm).
- For N replicas and M regions (zone groups), the number of replicas falling into each region is equal to the integer number of quotients from the N / M division. The rest of the replicas is added to one region (which is the main one for this section).
- A region cannot contain more replicas than the number of zones in a region.
For example, if N = 3 and M = 2, with this algorithm we will have a ring in which one replica is included in each region (the integer part of the fraction 3/2 is 1), and the remaining one replica is included in one of the two regions, randomly selected. The diagram below reflects the distribution of replicas by region in the example above.
Performing a direct PUT request from a proxy server to a storage node in a remote region is not so simple: in most cases, we may not have access to the cluster’s internal network from outside. Thus, for the initial implementation, we assume that only local replicas are written when the PUT request is executed, and remote regional replicas are created by the replication process.
By default, the number of replicas is three, and the regions are one. This case reproduces the standard Swift configuration and ring balancing algorithm.
Once again about Get_more_nodes
We suggest changes to the get_more_nodes method of the Ring class to recognize regions when selecting “spare” zones for temporary replicas. The algorithm should sort candidates for “spare” so that zones from the region that contains the lost replica are selected first. If the local region does not have access to the zones (for example, the network connection between the regions is closed), the algorithm returns the node that belongs to the zone from one of the external regions. The following two schemes describe the algorithm for two extreme cases.
Regional proxy server
For the Swift proxy server to work correctly in an environment with several geographically distributed regions, it needs to have the information to which region it belongs. A proxy server can obtain this information based on an analysis of network latency when connecting to data storage servers, or directly from a configuration file. The first approach is implemented in the current version of Swift (1.8.0). The proxy server sorts the data storage nodes based on the response time after connecting to each of them, and selects the fastest one to read. This approach works well for read requests, but when writing, you need to work with all the “main” storage servers, as well as possibly with a few “spare” ones. In this case, the configuration method for determining the local region is better suited.
This is quite simple by adding a region parameter to the [DEFAULT] section of the proxy server configuration file (proxy-server.conf), for example:
[DEFAULT]
...
region = san-jose
This parameter is used by the proxy server for ring reading operations, and also possibly when choosing nodes to serve GET requests. Our goal is for the proxy server to prefer to connect to storage nodes from local zones (that is, zones that belong to the same region as the proxy server).
In a SwiftStack article, this functionality is called proxy affinity.
A proxy server should not read data from a host that belongs to an external region if a local replica is available. This allows you to reduce the load on network connections between regions, and also work when there is no network connection between regions (as a result of a temporary failure or cluster topology features).
We then replace the node list shuffle operation in step # 2 of the GET request processing algorithm (see above) with a procedure that arranges the nodes in such a way that the drives belonging to the local proxy region are the first in the list. After this sorting, the lists of local regional and external regional nodes are mixed independently, and then the list of external regional nodes is added to the list of local regional nodes. As an alternative, at this stage, the method described above for selecting the data storage node for the minimum response time can be used.
Replication in Swift
Replication between geographically distributed data centers in our prototype works for the regions as a whole as for a cluster with one region. However, since a huge number of REPLICATE requests between clusters over a low-speed WAN connection can be sent as part of the replication process. This can lead to a serious drop in overall cluster performance.
As a simple workaround for this problem, add a counter to the replicator in such a way that partitions are transferred to devices in the remote region for every Nth replication. More complex solutions may include dedicated replicator gateways in neighboring regions, and will be developed as part of our research project.
Original article in English