Field-level OCR. What is it for?
: under the cut, it’s not about the clouds, but about OCR") We already announced a cool thing called ABBYY Cloud OCR SDK. It is gradually gaining popularity - the other day, the service recognized a millionth page. This seems to be a good reason to improve OCR literacy for current and future users. So, let's begin.
We already announced a cool thing called ABBYY Cloud OCR SDK. It is gradually gaining popularity - the other day, the service recognized a millionth page. This seems to be a good reason to improve OCR literacy for current and future users. So, let's begin. Today we will talk about the existence of two types of recognition - Full Page OCR and Field-level OCR. These approaches differ not only in price, there are fundamental differences between them in why they are needed. Unfortunately, not all novice OCR developers understand these differences and are forced to learn from mistakes. Moreover, many large and well-known players in the Data Capture market continue to use the single-pass algorithm where a multi-pass is good (i.e. Full Page OCR instead of Field-level). The reasons for their behavior are commonplace: the application was written many years ago, and it is too expensive for them to redo the architecture, UI, and re-train their partners. And they are forced to pay for it with restrictions in the field of recognition quality.
The need for Field-level OCR arises at the moment when we want to extract some useful data from the document. This processing scenario is commonly called Data Capture in the industry. For example, we want to extract from Invoice the name of the counterparty company, the amount to be paid and the date by which payment is due. Moreover, on such documents there are many amounts and dates, and here it is important not to miss and choose the right one. Just imagine the consequences of, for example, that when you pay, instead of the invoice amount, your phone number will be used.
Usually the process of processing such documents looks like this:

Depending on the type of documents being processed, various field search methods can be applied. In the simplest case - machine-readable forms that "coincide in the gap", the coordinates of the fields are known in advance, it remains only to combine the sheet with the template, for which various "frames" are used, such as these black squares.

In the case of invoices, this method no longer works. Here more sophisticated methods are applied, which are based on the search for keywords like “Invoice #”, “Due date:”, and already starting from them, zones on the document are defined in which the required fields are located. In this case, preliminary knowledge is used on how the invoice of a given company is usually arranged.
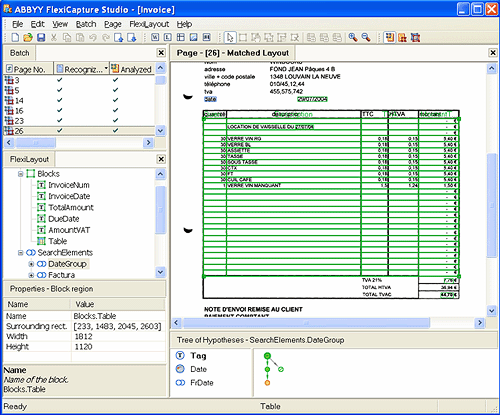
Right at this moment, when we have already determined the location of the fields or, (as in the most advanced systems like FlexiCapture) several possible hypotheses of the location of the fields - it's time to decide how we will extract the text of these fields.
Suppose we determined the location of the fields correctly, and in the Total Amount field we still have the amount, not the phone number. But we still have a great chance to put the “$ 1.000.00” dot in the wrong place, or just not notice the comma, and pay a hundred thousand instead of a thousand dollars. That is why the extraction of such data is usually taken very seriously, and the question “how many percent of recognition errors” is already replaced by the question “how much time is required for manual verification”. The quality of technology here is no longer measured in the number of incorrect characters, but in the amount of manual labor required to correct system recognition errors. Moreover, this is connected not only with the accuracy of recognition, but also with her ability to correctly say “something I'm not sure about this symbol,” but this is a topic for a separate article.
As I said, there is a class of applications that use only one pass. Already at the stage of determining the type of document, the page is fully recognized. Its text serves as the basis for deciding on the type of document (for example, by searching for typical keywords for a given type), and then searching for supporting elements and determining the location of the fields. And the same text is ultimately used to extract data from the fields.
In our opinion, at this very moment it makes sense to once again recognize specific fields, but already setting the recognition parameters more precisely. The fact is that by significantly narrowing the possible set of recognized values, we can significantly increase the accuracy of both recognition and determination of uncertainly recognized characters. As a result, it positively affects the main parameter of the system - the amount of manual labor for entering and processing documents.
In particular, knowing which field we will now recognize, we can determine the following parameters:
· Set a regular expression or a special language for dates, amounts, bank details, and so on.
· Define a dictionary of possible values if this field has a limited set of text values (company name, nomenclature, etc.)
· Specify text segmentation parameters (one line or several, monospaced text or not, etc.).
· Specify the type of text if the field is printed in a special font like OCR-A , etc.
· Apply special image processing settings (for example, if the text itself is printed in a different color, or it often gets the organization’s seal or signature)
In principle, all this setting consists in disabling various automation, which is in any high-quality OCR, and almost always works correctly. But as I said, in the DataCapture script there is not enough quality level "almost always works correctly." The presence of this “practically” leads to the fact that the recognition results are first checked by automatic rules, and then manually by operators, and sometimes in several stages, since people, too, unfortunately, “almost never make mistakes”.
Let's look at such an example. Here, for example, a scanned cash receipt.

If you look closely, we will see that this is a real nightmare for OCR. The letters are stuck together and not completely imprinted.

Nevertheless, modern OCR technologies can cope with this. If we simply open it in ABBYY FineReader 11 and recognize it with the default settings, we will see that even something can be pulled out of this horror. In general, he coped well, although he made a lot of mistakes. In particular, in the part that is of particular interest to us — the table with goods and price, one of the values was recognized as “$ o.ce” instead of “$ 0.00”.

But why, you say? After all, it is obvious that this is exactly "$ 0.00"! But why is this obvious to you? Because you, looking at the image, understand that this is a cash receipt, and in the center there is a table, and in the third column of the table are numbers, not abracadabra. But how could the OCR program know this? After all, in the left column, there can be full gibberish like “5UAMM575”, why don't they meet in the third too? The program does not go shopping, and does not make purchases, and with default settings it is equally likely to expect to enter both checks, newspapers, and magazine articles with a glamorous layout. In the case of a two-pass algorithm, we determine that, generally speaking, it is a check, in addition we can determine its structure and also remember that for AJ Auto Detailing Inc. checks the third column always contains $ XXX format amounts. XX and no letters can be there. Thus, re-recognizing only these fields, setting the appropriate restrictions (for example, through a regular expression), we are guaranteed to get rid of such errors.
In the case of a one-pass algorithm, we are forced to rely completely on automation and set the widest possible image processing settings, since it is necessary to recognize not only these fields, but also the rest of the text, as well as for all possible types of documents, and all for one time. This is a serious limiting factor, which developers are trying to compensate for with more intelligent rules for subsequent processing and verification of results, a more efficient process of manual verification, etc. All this, of course, is also important, but if there is an opportunity to significantly reduce the number of errors immediately, why not take advantage?
If besides the prices of goods we are also interested in their nomenclatures, then by connecting the dictionary of available nomenclatures for this supplier, you can also go through these fields too, significantly improving the quality of the data. But why not connect the dictionary right away? But at first, after all, we don’t even know the supplier, which means that we will have to connect all the dictionaries of all suppliers at once, and from this the result may well only get worse.
By the way, the argument of processing time is usually given in this dispute, as an explanation of why they do not use the second pass. But the fact is that just this argument is in favor of two-pass recognition, and that's why. With repeated recognition, a negligible part of the area of the original document is processed, and even a good proportion of the automation is turned off and turned into manual mode. If recognition occurs on the local server, the time for an additional recognition pass is vanishingly small compared to the time of the first pass. However, in a two-pass scenario, the first pass is used only for extracting reference text and classifications that are tolerant to recognition errors through the use of fuzzy comparison algorithms. The text itself does not go directly to the results, which means
In the case of recognition in the cloud, indeed, we will have to make two calls to the server instead of one. But even in this case, the argument about the ability to achieve higher quality remains valid.
Original article in English on the SDK team blog .
Andrey Isaev,
Director of the Department of Products for Developers.