How We Scaled Nginx and Save the World 54 Years of Waiting Every Day
- Transfer
“The @Cloudflare team has just made changes that have significantly improved our network performance, especially for the slowest requests. How much faster? We estimate that we are saving the Internet about 54 years of time per day that would otherwise have been spent waiting for sites to load . ” - Matthew Prince tweet , June 28, 2018
10 million sites, applications and APIs use Cloudflare to speed up content downloads for users. At the peak, we process more than 10 million requests per second in 151 data centers. Over the years, we have made many changes to our version of Nginx to cope with growth. This article is about one of these changes.
Nginx is one of the programs that uses event processing loops to solve the C10K problem . Each time a network event arrives (a new connection, request or notification to send a larger amount of data, etc.), Nginx wakes up, processes the event, and then returns to another job (this may be processing other events). When an event arrives, the data for it is ready, which allows you to efficiently process many simultaneous requests without downtime.
For example, here's what a piece of code might look like to read data from a file descriptor:
If fd is a network socket, then bytes already received will be returned. The last call will return
If fd is a regular file on Linux, then
In other words, the code above is essentially reduced to this:
If the handler needs to read from the disk, then it blocks the event loop until the read is completed, and subsequent event handlers wait.
This is normal for most tasks, since reading from a disk is usually quite fast and much more predictable than waiting for a packet from the network. Especially now that everyone has an SSD, and all our caches are on SSDs. In modern SSDs, a very small delay, usually in tens of microseconds. In addition, you can run Nginx with multiple workflows so that a slow event handler does not block requests in other processes. Most of the time you can rely on Nginx to quickly and efficiently process requests.
As you might have guessed, these rosy assumptions are not always true. If each reading always takes 50 μs, then reading 0.19 MB in blocks of 4 KB (and we read in even larger blocks) will take only 2 ms. But tests showed that the time to the first byte is sometimes much worse, especially in the 99th and 999th percentile. In other words, the slowest reading out of every 100 (or 1000) readings often takes much longer.
Solid state drives are very fast, but known for their complexity. They have computers inside that queue and reorder I / O, and also perform various background tasks, such as garbage collection and defragmentation. From time to time, requests slow down noticeably. My colleague Ivan Bobrovlaunched several I / O benchmarks and recorded read delays of up to 1 second. Moreover, some of our SSDs have more such performance spikes than others. In the future we are going to take this indicator into account when purchasing an SSD, but now we need to develop a solution for existing equipment.
Uniform load distribution with
It is difficult to avoid one slow response per 1000 requests, but what we really do not want is to block the remaining 1000 requests for a whole second. Conceptually, Nginx is able to process many requests in parallel, but it only starts 1 event handler at a time. So I added a special metric:
The 99th percentile (p99)
Each of our machines runs Nginx with 15 workflows, that is, one slow I / O will block no more than 6% of requests. But the events are not evenly distributed: the main worker receives 11% of the requests.
The solution is to make read () non-blocking. Actually this function is implemented in normal Nginx ! Using the following configuration, read () and write () are executed in the thread pool and do not block the event loop:
But we tested this configuration and instead of improving the response time by 33 times, we noticed only a small change in p99, the difference is within the margin of error. The result was very discouraging, so we temporarily postponed this option.
There are several reasons why we did not have significant improvements, like the Nginx developers. In the test they used 200 simultaneous connections for requesting files of 4 MB to the HDD. Winchesters have much more I / O latency, so optimization has a greater effect.
In addition, we are mainly concerned about the performance of p99 (and p999). Optimizing the average delay does not necessarily solve the peak emission problem.
Finally, in our environment, typical file sizes are much smaller. 90% of our cache hits are less than 60KB. The smaller the files, the less cases of blocking (usually we read the entire file in two reads).
Let's look at disk I / O when hit in the cache:
32K are not always read. If the headers are small, then you need to read only 4 KB (we do not use I / O directly, so the kernel rounds to 4 KB).
These are 6 separate readings that produce
Therefore, we made a change to Nginx so that
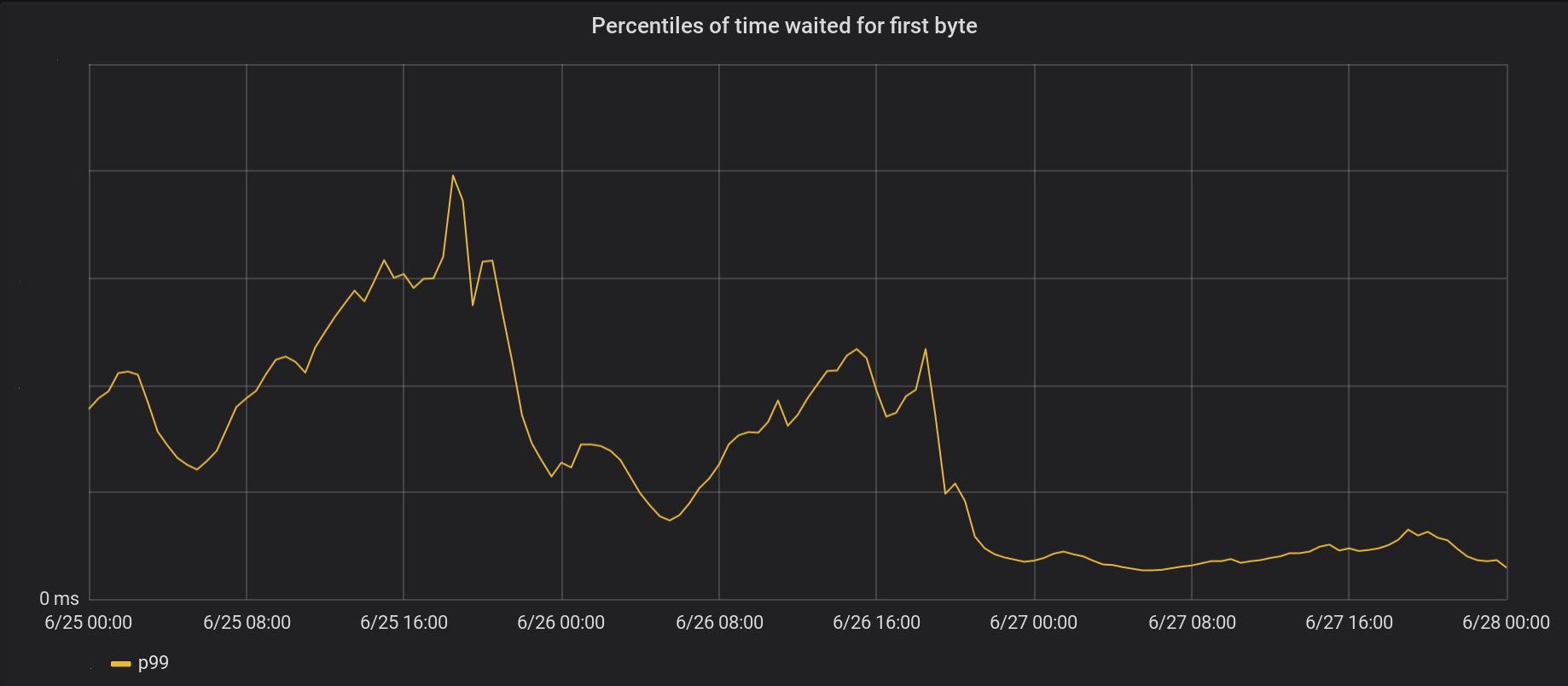
on June 26 we rolled the changes to the 5 busiest data centers, and the next day - to all the other 146 data centers around the world. The total peak p99 TTFB decreased by 6 times. In fact, if we summarize all the time from processing 8 million requests per second, we save the Internet 54 years of waiting every day.
Our series of events has not yet completely got rid of the locks. In particular, blocking still occurs the first time the file is cached (and
Nginx is a powerful platform, but scaling extremely high Linux I / O loads can be a daunting task. Standard Nginx offloads reading in separate threads, but on our scale we often need to go one step further.
10 million sites, applications and APIs use Cloudflare to speed up content downloads for users. At the peak, we process more than 10 million requests per second in 151 data centers. Over the years, we have made many changes to our version of Nginx to cope with growth. This article is about one of these changes.
How Nginx Works
Nginx is one of the programs that uses event processing loops to solve the C10K problem . Each time a network event arrives (a new connection, request or notification to send a larger amount of data, etc.), Nginx wakes up, processes the event, and then returns to another job (this may be processing other events). When an event arrives, the data for it is ready, which allows you to efficiently process many simultaneous requests without downtime.
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/For example, here's what a piece of code might look like to read data from a file descriptor:
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}If fd is a network socket, then bytes already received will be returned. The last call will return
EWOULDBLOCK. This means that the local read buffer has ended and you should no longer read from this socket until data appears.Disk I / O is different from network
If fd is a regular file on Linux, then
EWOULDBLOCKthey EAGAINnever appear, and the read operation always expects the entire buffer to be read, even if the file is opened with O_NONBLOCK. As written in the open (2) manual :Please note that this flag is not valid for regular files and block devices.
In other words, the code above is essentially reduced to this:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}If the handler needs to read from the disk, then it blocks the event loop until the read is completed, and subsequent event handlers wait.
This is normal for most tasks, since reading from a disk is usually quite fast and much more predictable than waiting for a packet from the network. Especially now that everyone has an SSD, and all our caches are on SSDs. In modern SSDs, a very small delay, usually in tens of microseconds. In addition, you can run Nginx with multiple workflows so that a slow event handler does not block requests in other processes. Most of the time you can rely on Nginx to quickly and efficiently process requests.
SSD performance: not always as promised
As you might have guessed, these rosy assumptions are not always true. If each reading always takes 50 μs, then reading 0.19 MB in blocks of 4 KB (and we read in even larger blocks) will take only 2 ms. But tests showed that the time to the first byte is sometimes much worse, especially in the 99th and 999th percentile. In other words, the slowest reading out of every 100 (or 1000) readings often takes much longer.
Solid state drives are very fast, but known for their complexity. They have computers inside that queue and reorder I / O, and also perform various background tasks, such as garbage collection and defragmentation. From time to time, requests slow down noticeably. My colleague Ivan Bobrovlaunched several I / O benchmarks and recorded read delays of up to 1 second. Moreover, some of our SSDs have more such performance spikes than others. In the future we are going to take this indicator into account when purchasing an SSD, but now we need to develop a solution for existing equipment.
Uniform load distribution with SO_REUSEPORT
It is difficult to avoid one slow response per 1000 requests, but what we really do not want is to block the remaining 1000 requests for a whole second. Conceptually, Nginx is able to process many requests in parallel, but it only starts 1 event handler at a time. So I added a special metric:
gettimeofday(&start, NULL);
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
gettimeofday(&event_start_handle, NULL);
// handle event[1]: send out response to GET http://cloudflare.com/
timersub(&event_start_handle, &start, &event_loop_blocked);The 99th percentile (p99)
event_loop_blockedexceeded 50% of our TTFB. In other words, half the time when servicing a request is the result of blocking the event processing cycle by other requests. event_loop_blockedmeasures only half the block (because pending calls are epoll_wait()not measured), so the actual ratio of the blocked time is much higher. Each of our machines runs Nginx with 15 workflows, that is, one slow I / O will block no more than 6% of requests. But the events are not evenly distributed: the main worker receives 11% of the requests.
SO_REUSEPORTcan solve the problem of uneven distribution. Marek Maykovsky previously wrote about the lackthis approach is in the context of other Nginx instances, but here you can basically ignore it: upstream connections in the cache are durable, so you can neglect a slight increase in the delay when opening the connection. This one configuration change with activation SO_REUSEPORTimproved peak p99 by 33%.Moving read () to a thread pool: not a silver bullet
The solution is to make read () non-blocking. Actually this function is implemented in normal Nginx ! Using the following configuration, read () and write () are executed in the thread pool and do not block the event loop:
aio threads;
aio_write on;But we tested this configuration and instead of improving the response time by 33 times, we noticed only a small change in p99, the difference is within the margin of error. The result was very discouraging, so we temporarily postponed this option.
There are several reasons why we did not have significant improvements, like the Nginx developers. In the test they used 200 simultaneous connections for requesting files of 4 MB to the HDD. Winchesters have much more I / O latency, so optimization has a greater effect.
In addition, we are mainly concerned about the performance of p99 (and p999). Optimizing the average delay does not necessarily solve the peak emission problem.
Finally, in our environment, typical file sizes are much smaller. 90% of our cache hits are less than 60KB. The smaller the files, the less cases of blocking (usually we read the entire file in two reads).
Let's look at disk I / O when hit in the cache:
// мы получили запрос на https://example.com с ключом кэша 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// чтение метаданных до 32 КБ и заголовков
// производится в пуле потоков, если "aio threads" включен
read(fd, buf, 32*1024);32K are not always read. If the headers are small, then you need to read only 4 KB (we do not use I / O directly, so the kernel rounds to 4 KB).
open()seems harmless, but actually takes resources. At a minimum, the kernel should check whether the file exists and whether the calling process has permission to open it. He needs to find an inode for /cache/prefix/dir/EF/BE/CAFEBEEF, and for this he will have to look CAFEBEEFin /cache/prefix/dir/EF/BE/. In short, in the worst case, the kernel performs this search:/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEFThese are 6 separate readings that produce
open(), compared to 1 reading read()! Fortunately, in most cases the search falls into the dentry cache and does not reach the SSD. But it is clear that processing read()in a thread pool is only half the picture.Final chord: non-blocking open () in thread pools
Therefore, we made a change to Nginx so that
open()for the most part it runs inside the thread pool and does not block the event loop. And here is the result from the non-blocking open () and read () at the same time: on June 26 we rolled the changes to the 5 busiest data centers, and the next day - to all the other 146 data centers around the world. The total peak p99 TTFB decreased by 6 times. In fact, if we summarize all the time from processing 8 million requests per second, we save the Internet 54 years of waiting every day.
Our series of events has not yet completely got rid of the locks. In particular, blocking still occurs the first time the file is cached (and
open(O_CREAT), andrename()) or when updating revalidation. But such cases are rare compared to cache accesses. In the future, we will consider the possibility of moving these elements outside the event processing loop to further improve the delay factor p99.Conclusion
Nginx is a powerful platform, but scaling extremely high Linux I / O loads can be a daunting task. Standard Nginx offloads reading in separate threads, but on our scale we often need to go one step further.