Performance Test: Amazing and Simple
It so happened that over the past six months I have been actively engaged in performance tests and it seems to me that in this area of IT there is an absolute misunderstanding of what is happening. Nowadays, when the growth of computing power has decreased (vertical scalability), and the volume of tasks is growing at the same speed, the performance problem becomes more acute. But before rushing into the struggle with productivity, it is necessary to obtain a quantitative characteristic.
Summary of the article:
Once, traveling in a train, I wanted to calculate what is the distance between the power poles. Armed with a regular watch and estimating the average train speed of 80-100km / h (25 m / s), I tracked the time between 2 posts. Oddly enough, this naive method gave a very depressing result, up to 1.5-2 times the difference. Naturally, the method was not difficult to fix, which I did, it was enough to detect 1 minute and calculate the number of posts. It doesn’t matter that the instantaneous speed can vary over the course of a minute, and it’s not even important whether we count the last column or the minute will expire in the middle, because the measurements are enough for the desired result.
The point of the test is to get compelling measurements for yourself and for others.
This story reminds me of what happens with performance testing in Software Engineering. A fairly frequent phenomenon is the launch of 1-2 tests, graphing and obtaining conclusions about the scalability system. Even if it is possible to use OLS or to find out a standard error, this is not done as “unnecessary.” A particularly interesting situation is when, after these 2 dimensions, people discuss how fast the system is, how it scales and compare it with other systems according to personal feelings.
Of course, it’s not difficult to evaluate how fast the team runs. On the other hand, faster does not mean better. Software systems have over 10 different parameters, from the hardware on which they work to input, which the user enters at different points in time. And often, 2 equivalent algorithms can give completely different scalability parameters in different conditions, which makes the choice not at all obvious.
On the other hand, measurement results always remain a source of speculation and mistrust.
- Yesterday we measured it was X, and today 1.1 * X. Did someone change something? - 10% - this is normal, we now have more records in the database.
- During the test, the antivirus, skype, animated screensaver was disabled?
- No, no, for normal tests we need to purchase a cluster of servers, set microsecond time synchronization between them ... remove the OS, run in protected mode ...
- How many users do we support? We have 5000 registered users, suddenly 20% of them logged in, you need to run tests with 1000 parallel agents.
Firstly, it is worth recognizing that we already have the iron that we have and we need to get the maximum results on it. Another question is how we can explain the behavior on other machines (production / quality testing). Those who advocate “clean room” experiments simply do not trust you, since you do not give enough explanations or data, a “clean room” is an illusion.
Secondly, the most important advantage in testing programs is the cheapness of the tests. If physicists could conduct 100 tests of a simplified situation instead of 5 full ones, they would definitely choose 100 (and 5 full ones to check the results :)). In no case, you can not lose the cheapness of the tests, run them at home, at a colleague, on the server, in the morning and at lunch. Resist the temptation of “real” hourly tests with thousands of users, it’s more important to understand how the system behaves than to know a couple of absolute numbers.
Third, keep the results. The value of the tests is represented by the measurements themselves, not the conclusions. Conclusions are far more likely to be wrong than the measurements themselves.
So, our task is to conduct a sufficient number of tests in order to predict system behavior in a given situation.
Immediately make a reservation that we consider the system as a "black box". Since systems can work under virtual machines, with and without using a database, it makes no sense to partition the system and take measurements in the middle (usually this leads to unaccounted for important points). But if it is possible to test the system, it must be done in different configurations.
For testing, even a simple test, it is better to have an independent system like JMeter, which can calculate the results, average. Of course, setting up the system takes time, but we want to get the result much faster and we are writing something like that.
Running once we get the number X. Run once again we get 1.5 * X, 2 * X, 0.7 * X. In fact, we can and should stop here if we take a temporary measurement and we do not need to insert this number in the report. If we want to share this number with someone, it is important for us that it converges with other dimensions and does not cause suspicion.
The first "logical" step seems to be putting the numbers X and averaging them, but, in fact, averaging the averages is nothing more than increasing the count for one test. Oddly enough, increasing the count can lead to even more unstable results, especially if you run the test and do something at the same time.
The problem is that the average is not a stable characteristic, one failed test, which was performed 10 times longer, will be enough so that your results do not coincide with others. It is not paradoxical for simple performance tests it is advisable to take the minimum execution time . Naturally, operation () should be measured in this context, usually 100 ms - 500 ms for the system is more than enough. Of course, the minimum time will not be 1 to 1 coincide with the observed effect or with the real one, but this number will be comparable with other measurements.
Quantiles 10%, 50% (median), 90% are more stable than the average, and much more informative. We can find out with what probability the request will execute the time 0.5 * X or 0.7 * X. There is another problem with them; counting quantiles on the knee is much more difficult than taking min, max.
JMeter provides a median and 90% measurement in the Aggregate Report out of the box, which should be used naturally.
As a result of measurements, we get a certain number (median, minimum, or another), but what can we say about our system (function) by one number? Imagine you are automating the process of obtaining this number and every day you will check it, when you need to sound the alarm and look for the guilty? For example, here is a typical schedule of the same test every day.
If we want to write a performance report, with one number it will look empty. Therefore, we will definitely test for different parameters. Tests for different parameters will give us a beautiful graph and an idea of the scalability of the system.
Consider a system with one numerical parameter. First of all, you need to select the parameter values. It makes no sense to choose numbers from different ranges, like [1, 100, 10000], you simply conduct 3 completely different disconnected tests and it will be impossible to find the dependence on such numbers. Imagine you want to plot, which numbers would you choose? Something similar to [X * 1, X * 2, X * 3, X * 4, X * 5,].
So, we select 5-10 (7 best) control points, for each point we conduct 3-7 measurements, take the minimum number for each point and build a graph.
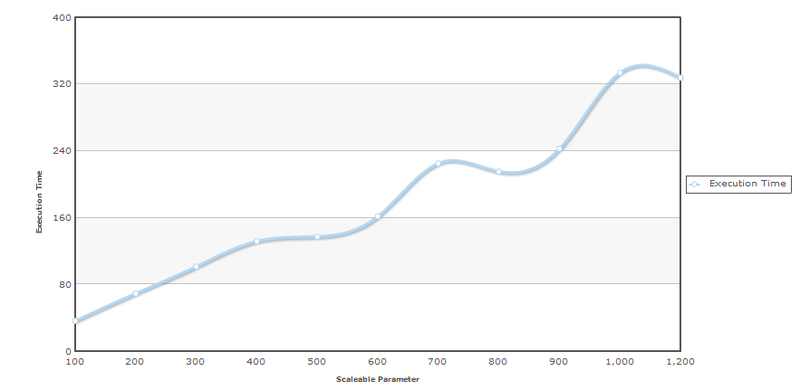
As you can see, the dots are located exactly around an imaginary straight line. Now we come to the most interesting part of the measurements, we can determine the complexity of the algorithm based on the measurements. Determining the complexity of an algorithm based on tests is much simpler for complex programs than analyzing the text of source programs. Using the test, you can even find special points when the complexity changes, for example, launching Full GC.
Determining the complexity of the program according to the test results is a direct task of the Regression analysis.. Obviously, there is no general way to find a function only by a point, so first we make an assumption about some dependence, and then it is checked. In our case and in most others, we assume that the function is a linear relationship.
To search for linear dependence coefficients, there is a simple and optimal OLS method . The advantage of this method is that the formulas can be programmed in 10 lines and they are absolutely understandable.
We present our calculations in the table.
In the highlighted line, we see the linear coefficient of our model, it is 95.54, the free coefficient is 2688. Now we can do a simple but not obvious focus, we can attach importance to these numbers. 95.54 is measured in milliseconds (like our measurements), 95.54 is the time we spend on each component, and 2688 ms the time we spend on the system itself does not depend on the number of components. This method allowed us to identify quite accurately the time of the external system, in this case, the database, although it is ten times longer than the time of the 1st component. If we used the formula Time_with_N_component / N, we would have to measure for N> 1000, so that the error would be less than 10%.
The linear coefficient of the model is the most important number of our measurements and, oddly enough, it is the most stable number of our measurements. Also, a linear coefficient allows you to adequately measure and interpret operations that occur in nanoseconds, and separating the overhead of the system itself.
The graph shows the results of independent test runs at different times, which confirms the greater stability of the linear coefficient than individual tests.

Using the graph, we can clearly see that our measurements really satisfy the linear model, but this method is far from accurate and we cannot automate it. In this case, the Pearson coefficient can help us . This method really shows deviations from a straight line, but for 5-10 measurements it is clearly not enough. The following is an example of a clearly non linear relationship, but the Pearson coefficient is quite high.
Returning to our table, knowing the ovehead system (free coefficient), we can calculate the linear coefficient for each measurement, which is done in the table. As we see the numbers (100, 101, 93, 96, 102, 81, 94, 100, 93, 98) - about 95 are randomly distributed, which gives us good reason to believe that the dependence is linear. Following the letter of mathematics, in fact, deviations from the average value must satisfy the normal distribution, and to check the normal distribution it is enough to check the Kolmogorov-Smirnov criterion, but we will leave this for sophisticated testers.
Oddly enough, not all dependencies are linear. The first thing that comes to mind is a quadratic dependence. In fact, quadratic dependence is very dangerous, it kills performance first slowly and then very quickly. Even if for you for 1000 elements everything is done in fractions of a second, then for 10000 it will already be tens of seconds (multiplied by 100). Another example is sorting, which cannot be solved in linear time. We calculate how applicable the linear analysis method is for algorithms with complexity O (n * log n)
That is, for n> = 1000, the deviation will be within 10%, which is significant, but in some cases it can be applied, especially if the coefficient for log is large enough.
Consider an example of a nonlinear relationship.
The first thing to note is a negative overhead, for obvious reasons the system cannot have a negative time spent on preparation. The second, looking at the column of coefficients, you can notice the pattern, the linear coefficient drops, and then grows. It resembles a parabola plot.
Naturally, most systems do not consist of a single parameter. For example, a table reader program already consists of 2 parameters, columns and rows. Using parameterized tests, we can calculate what are the costs of reading a row of 100 columns (let 100ms) and what are the costs of reading a column for 100 rows (let 150ms). 100 * 100ms! = 100 * 150ms and this is not a paradox, we just don’t take into account that overhead reading of 100 columns is already inherent in the speed of reading lines. That is, 100ms / 100 columns = 1ms - this is not the speed of reading a single cell! In fact, 2 measurements will not be enough to calculate the reading speed of one cell. The general formula is where A is the cost per cell, B is one line, C is a column: We compose a system of equations, taking into account the available values and another necessary measurement:
From here, we get A = 0.9 ms, B = 10 ms, C = 50 ms.
Of course, having a formula similar to LMNK for this case, all calculations would be simplified and automated. In the general case, the general LMNC does not apply to us, because a function that is linear in each of the arguments is by no means a multidimensional linear function (a hyperplane in N-1 space). It is possible to use the gradient method of finding the coefficients, but this will no longer be an analytical method.
One of the favorite things to do with performance tests is extrapolation. Especially people like to extrapolate to that area for which they cannot receive values. For example, having 2 cores or 1 core in the system, I want to extrapolate as if the system behaved with 10 cores. And of course, the first wrong assumption is that the relationship is linear. For the normal determination of the linear dependence, it is necessary from 5 points, which of course is impossible to obtain on 2 cores.
One of the closest approximations is Amdal's law .
It is based on the calculation of the percentage of the parallelized code α (outside the synchronization block) and the synchronized code (1 - α). If one process takes time T on one core, then with multiple running tasks N, the time will be T '= T * α + (1-α) * N * T. On average, of course, N / 2, but Amdahl admits N. Parallel acceleration, respectively, S = N * T / T '= N / (α + (1-α) * N) = 1 / (α / N + (1- α )).
Of course, the graph above is not so dramatic in reality (there is a logarithmic scale in X). However, a significant drawback of synchronization blocks is the asymptote. Relatively speaking, it is not possible to increase the power to overcome the acceleration limit lim S = 1 / (1 - α). And this limit is quite strict, that is, for 10% of the synchronized code, the limit is 10, for 5% (which is very good) the limit is 20.
The function has a limit, but it is constantly growing, from this arises a strange at first glance task: to evaluate which hardware is optimal for our algorithm. In reality, increasing the percentage of paralyzed can be quite difficult. Let us return to the formula T '= T * α + (1-α) * N * T, optimal from the point of view of efficiency: if the core is idle, it will work as long as it does. That is, T * α = (1-α) * N * T, whence we get N =
α / (1-α). For 10% - 9 cores, for 5% - 19 cores.
A computational acceleration model is theoretically possible, but not always real. Consider the client-server situation, when N clients constantly run some task on the server, one by one, and we do not experience any costs for synchronizing the results, since the clients are completely independent! Keeping statistics for example introduces a synchronization element. Having an M-nuclear machine, we expect that the average query time T when N <M is the same, and when N> M the query time grows in proportion to the number of cores and users. We calculate throughput as the number of requests processed per second and get the following “perfect” schedule.
Naturally perfect graphics are achievable if we have 0% synchronized blocks (critical sections). Below are real measurements of one algorithm with different parameter values.
We can calculate the linear coefficient and build a graph. Also, having a machine with 8 cores, you can conduct a series of experiments for 2, 4, 8 cores. From the test results, you can see that a system with 4 cores and 4 users behaves exactly the same as a system with 8 cores and 4 users. Of course, this was expected, and gives us the opportunity to conduct only one series of tests for a machine with the maximum number of cores.
The measurement graphs are close in value to the Amdal law, but still significantly different. Having measurements for 1, 2, 4, 8 cores, you can calculate the number of non-parallelizable code using the formula
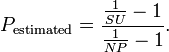
Where NP is the number of cores, SU = Throughpt NP core / Throughput 1 core. According to Amdahl’s law, this number must be constant, but in all dimensions this number drops, although not significantly (91% - 85%).
The throughput per core graph is not always a continuous line. For example, with a lack of memory or when running GC, deviations in throughput can be very significant.
When measuring the load of multi-user systems, we introduced the definition Throughput = NumberOfConcurrentUsers / AverageTimeResponse . To interpret the results, Throughput is the throughput of the system, how many users the system can serve at a time, and this definition is closely related to the queuing theory . The complexity of measuring throughput is that the value depends on the input stream. For example, in queuing systems, it is assumed that the response time does not depend on how many requests are in the queue. In a simple software implementation, without a queue of applications, the time between all flows will be divided and, accordingly, the system will degrade. It is important to note that you should not trust JMeterthroughput measurements, it was noticed that Jmeter averages throughput between all steps of the test, which is not correct.
Consider the following case: when loading with 1 user, the system gives Throughput = 10, with 2 - Throughput = 5. This situation is quite possible, since a typical Throughput / User graph is a function that has one local (and global maximum).
Therefore, with an input stream of 1 user every 125ms, the system will process 8 users per second (input throughput).
With an input stream of 2 users, every 125ms the system will begin to collapse, since 8 (input throughput)> 5 (possible throughput).
Consider an example of a collapsing system in more detail. After conducting the Throughput / Users test, we have the following results.
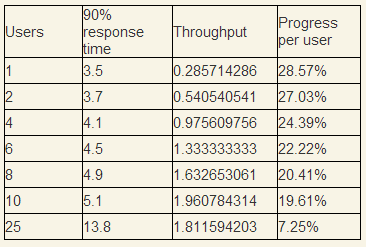
Users - the number of simultaneous users in the system, Progress per user - how much percentage of the work the user does in one second. Mentally simulate the situation that 10 users come every second and begin to perform the same operation, the question is whether the system can serve this stream.
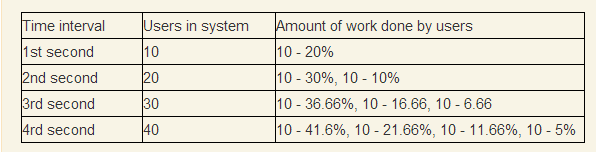
In 1 second, 10 users on average will perform only 20% of their work, based on the assumption that on average they will do all in 5. At the second second, there will already be 20 users in the system and they will share resources between 20 threads, which will reduce percentage of work performed. We continue the series until the moment when the first 10 users finish the work (theoretically they should finish it as the series 1/2 + 1/3 + 1/4 ... diverging).

It is quite obvious that the system will collapse, because after 80 seconds there will be 800 users in the system, and at that moment only the first 10 users will be able to finish.
This test shows that for any distribution of the incoming stream, if the incoming throughput (expectation) is greater than the maximum
measured throughput for the system, the system will begin to degrade and fall under constant load. But the opposite is not true, in the 1st example, the maximum measured throughput (= 10)> incoming (8), but the system will also not be able to cope.
An interesting case is a workable system. Based on our measurements, we will test that every 1 second 2 new users come. Since the minimum response time exceeds a second, at first the number of users will accumulate.
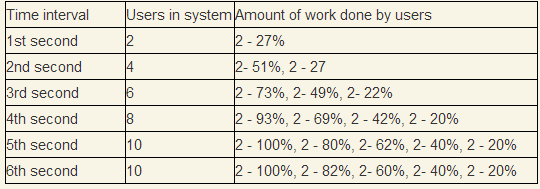
As we can see, the system will enter the stationary mode exactly at that point, the graph when the measured throughput coincides with the input throughput. The number of users in the system will average 10.
From this we can conclude that the Throughput / Users graph on the one hand represents the number of processed users per second (throughput) and the number of users in the system (users). The graph falling to the right of this point characterizes only the stability of the system in stressful situations and the dependence on the nature of the incoming distribution. In any case, conducting Throughput / Users tests, it will not be out of place to conduct a behavioral test with approximate characteristics.
When conducting performance tests, there are almost always measurements taking much longer than expected. If the testing time is large enough, then the following picture can be observed. How to choose one number from all these measurements?
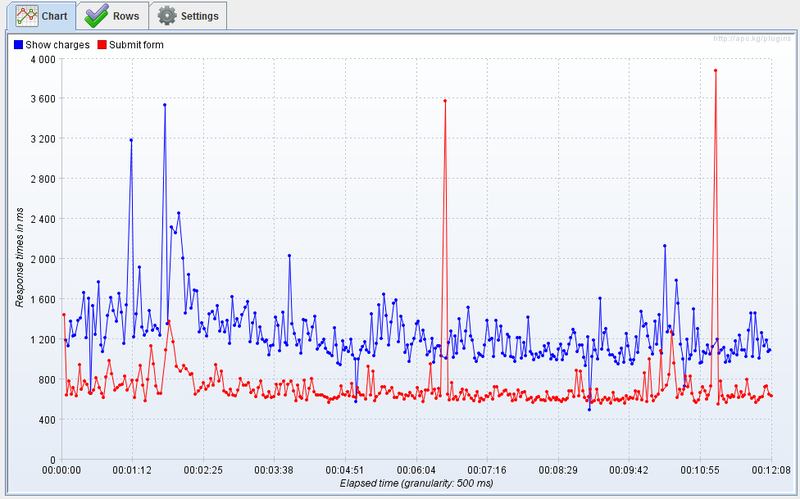
The simplest statistics are average, but for the above reasons, it is not completely stable, especially for a small number of measurements. To determine the quantiles, it is convenient to use the distribution function graph. Thanks to the wonderful JMeter plugin , we have such an opportunity. After the first 10-15 measurements, the picture is usually not clear enough, therefore, a detailed study of the function will require 100 measurements.
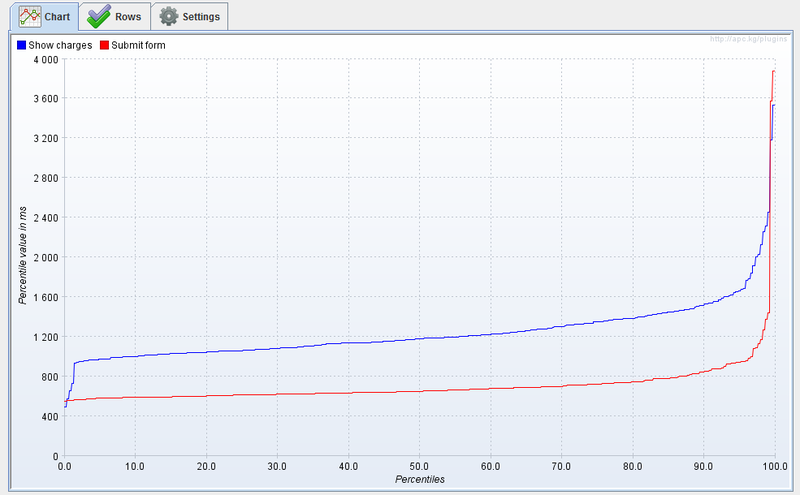
Obtaining the N-quantile from this graph is very simple; just take the value of the function at a given point. The function shows a rather strange behavior around the minimum, but then it grows quite stably and only around 95% of the quantile a sharp rise begins.
Is this distribution analytical or known? To do this, you can plot the distribution density and try to look at the known functions, fortunately there are not many of them .

Honestly, this method did not bring any results, at first glance similar distribution functions: Beta distribution, Maxwell distribution, turned out to be quite far from statistics.
It is important to note that the range of values of our random variable is by no means [0, + ∞ [, but some [Min, + ∞ [. We cannot expect a program to execute faster than a theoretical minimum. If we assume that the measured minimum converges to the theoretical one and subtract this number from all statistics, then we can observe a rather interesting regularity.
It turns out Minimum + StdDev = Mean (Average), and this is typical for all measurements. There is one known distribution in which, the mathematical expectation coincides with variance, this is an exponential distribution. Although the graph of the distribution density differs at the beginning of the definition domain, the main quantiles are quite the same. It is quite possible that the random variable is the sum of the exponential distribution and the normal one, which completely explains the fluctuations around the point of theoretical minimum.
Unfortunately, I could not find a theoretical justification why the test results satisfy the exponential distribution. Most often, the exponential distribution appears in the problems of device failure time and even human lifetime. It is also unclear whether this is the specifics of the platform (Windows) or Java GC or some physical processes occurring in the computer.
However, taking into account that each exponential distribution is defined by 2 parameters (dispersion and mathematical expectation) and the performance test distribution function is exponential, we can assume that for the peformance test, we need and only 2 indicators are enough. The average is the test execution time, the variance is the deviation from this time. Naturally, the smaller the variance, the better, but it is impossible to say unequivocally that it is better to reduce the average or variance.
If someone has a theory of where dispersion comes from and how this or that algorithm affects its value, please share. I want to note on my own that I did not find the relationship between the test execution time and the variance. 2 tests performed on average the same time (without sleep) can have different dispersion orders.
Summary of the article:
- The simplest test : methods for measuring the test, the choice of statistics (quantiles, median, average).
- Parametrized test : assessment of the complexity of the algorithm, the application of OLSs to assess the linearity of the test.
- Tests on multicore machines : the difficulty of extrapolating the results of tests on multicore machines, Amdal's law and the appropriateness of measurements.
- Behavioral test : what, for a given model of user behavior, will be the time waiting for a request and what can lead to a collapse of the system. Throughput and how to count it.
- Amazing static distribution of performance test results.
Background
Once, traveling in a train, I wanted to calculate what is the distance between the power poles. Armed with a regular watch and estimating the average train speed of 80-100km / h (25 m / s), I tracked the time between 2 posts. Oddly enough, this naive method gave a very depressing result, up to 1.5-2 times the difference. Naturally, the method was not difficult to fix, which I did, it was enough to detect 1 minute and calculate the number of posts. It doesn’t matter that the instantaneous speed can vary over the course of a minute, and it’s not even important whether we count the last column or the minute will expire in the middle, because the measurements are enough for the desired result.
The point of the test is to get compelling measurements for yourself and for others.
Tests "on the knee"
This story reminds me of what happens with performance testing in Software Engineering. A fairly frequent phenomenon is the launch of 1-2 tests, graphing and obtaining conclusions about the scalability system. Even if it is possible to use OLS or to find out a standard error, this is not done as “unnecessary.” A particularly interesting situation is when, after these 2 dimensions, people discuss how fast the system is, how it scales and compare it with other systems according to personal feelings.
Of course, it’s not difficult to evaluate how fast the team runs. On the other hand, faster does not mean better. Software systems have over 10 different parameters, from the hardware on which they work to input, which the user enters at different points in time. And often, 2 equivalent algorithms can give completely different scalability parameters in different conditions, which makes the choice not at all obvious.
Distrust of tests
On the other hand, measurement results always remain a source of speculation and mistrust.
- Yesterday we measured it was X, and today 1.1 * X. Did someone change something? - 10% - this is normal, we now have more records in the database.
- During the test, the antivirus, skype, animated screensaver was disabled?
- No, no, for normal tests we need to purchase a cluster of servers, set microsecond time synchronization between them ... remove the OS, run in protected mode ...
- How many users do we support? We have 5000 registered users, suddenly 20% of them logged in, you need to run tests with 1000 parallel agents.
What do we do?
Firstly, it is worth recognizing that we already have the iron that we have and we need to get the maximum results on it. Another question is how we can explain the behavior on other machines (production / quality testing). Those who advocate “clean room” experiments simply do not trust you, since you do not give enough explanations or data, a “clean room” is an illusion.
Secondly, the most important advantage in testing programs is the cheapness of the tests. If physicists could conduct 100 tests of a simplified situation instead of 5 full ones, they would definitely choose 100 (and 5 full ones to check the results :)). In no case, you can not lose the cheapness of the tests, run them at home, at a colleague, on the server, in the morning and at lunch. Resist the temptation of “real” hourly tests with thousands of users, it’s more important to understand how the system behaves than to know a couple of absolute numbers.
Third, keep the results. The value of the tests is represented by the measurements themselves, not the conclusions. Conclusions are far more likely to be wrong than the measurements themselves.
So, our task is to conduct a sufficient number of tests in order to predict system behavior in a given situation.
Simple test
Immediately make a reservation that we consider the system as a "black box". Since systems can work under virtual machines, with and without using a database, it makes no sense to partition the system and take measurements in the middle (usually this leads to unaccounted for important points). But if it is possible to test the system, it must be done in different configurations.
For testing, even a simple test, it is better to have an independent system like JMeter, which can calculate the results, average. Of course, setting up the system takes time, but we want to get the result much faster and we are writing something like that.
long t = - System.currentTimeMillis();
int count = 100;
while (count -- > 0) operation();
long time = (t + System.currentTimeMillis()) / 100;
Recording a measurement result
Running once we get the number X. Run once again we get 1.5 * X, 2 * X, 0.7 * X. In fact, we can and should stop here if we take a temporary measurement and we do not need to insert this number in the report. If we want to share this number with someone, it is important for us that it converges with other dimensions and does not cause suspicion.
The first "logical" step seems to be putting the numbers X and averaging them, but, in fact, averaging the averages is nothing more than increasing the count for one test. Oddly enough, increasing the count can lead to even more unstable results, especially if you run the test and do something at the same time.
Minimum runtime as the best statistics
The problem is that the average is not a stable characteristic, one failed test, which was performed 10 times longer, will be enough so that your results do not coincide with others. It is not paradoxical for simple performance tests it is advisable to take the minimum execution time . Naturally, operation () should be measured in this context, usually 100 ms - 500 ms for the system is more than enough. Of course, the minimum time will not be 1 to 1 coincide with the observed effect or with the real one, but this number will be comparable with other measurements.
Quantiles
Quantiles 10%, 50% (median), 90% are more stable than the average, and much more informative. We can find out with what probability the request will execute the time 0.5 * X or 0.7 * X. There is another problem with them; counting quantiles on the knee is much more difficult than taking min, max.
JMeter provides a median and 90% measurement in the Aggregate Report out of the box, which should be used naturally.
Parameterized test
As a result of measurements, we get a certain number (median, minimum, or another), but what can we say about our system (function) by one number? Imagine you are automating the process of obtaining this number and every day you will check it, when you need to sound the alarm and look for the guilty? For example, here is a typical schedule of the same test every day.
Hidden text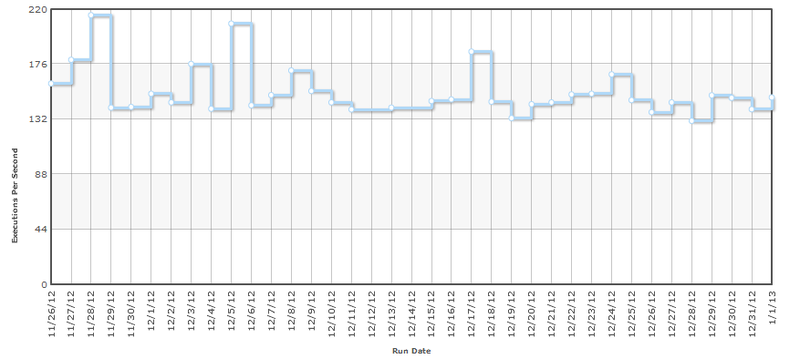
If we want to write a performance report, with one number it will look empty. Therefore, we will definitely test for different parameters. Tests for different parameters will give us a beautiful graph and an idea of the scalability of the system.
Single parameter test
Consider a system with one numerical parameter. First of all, you need to select the parameter values. It makes no sense to choose numbers from different ranges, like [1, 100, 10000], you simply conduct 3 completely different disconnected tests and it will be impossible to find the dependence on such numbers. Imagine you want to plot, which numbers would you choose? Something similar to [X * 1, X * 2, X * 3, X * 4, X * 5,].
So, we select 5-10 (7 best) control points, for each point we conduct 3-7 measurements, take the minimum number for each point and build a graph.
Algorithm complexity
As you can see, the dots are located exactly around an imaginary straight line. Now we come to the most interesting part of the measurements, we can determine the complexity of the algorithm based on the measurements. Determining the complexity of an algorithm based on tests is much simpler for complex programs than analyzing the text of source programs. Using the test, you can even find special points when the complexity changes, for example, launching Full GC.
Determining the complexity of the program according to the test results is a direct task of the Regression analysis.. Obviously, there is no general way to find a function only by a point, so first we make an assumption about some dependence, and then it is checked. In our case and in most others, we assume that the function is a linear relationship.
Least Squares Method (Linear Model)
To search for linear dependence coefficients, there is a simple and optimal OLS method . The advantage of this method is that the formulas can be programmed in 10 lines and they are absolutely understandable.
y = a + bx
a = ([xy] - b[x])/[x^2]
b = ([y] - a[x])/ n
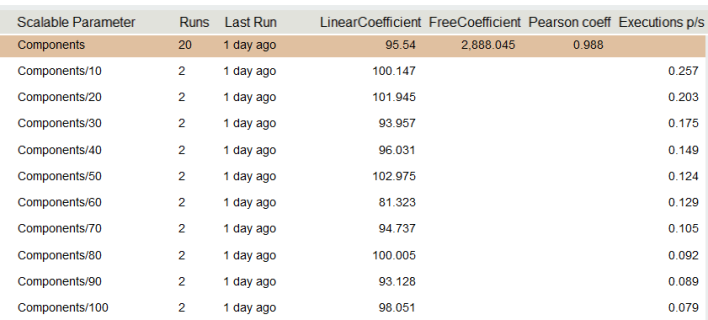
We present our calculations in the table.
In the highlighted line, we see the linear coefficient of our model, it is 95.54, the free coefficient is 2688. Now we can do a simple but not obvious focus, we can attach importance to these numbers. 95.54 is measured in milliseconds (like our measurements), 95.54 is the time we spend on each component, and 2688 ms the time we spend on the system itself does not depend on the number of components. This method allowed us to identify quite accurately the time of the external system, in this case, the database, although it is ten times longer than the time of the 1st component. If we used the formula Time_with_N_component / N, we would have to measure for N> 1000, so that the error would be less than 10%.
The linear coefficient of the model is the most important number of our measurements and, oddly enough, it is the most stable number of our measurements. Also, a linear coefficient allows you to adequately measure and interpret operations that occur in nanoseconds, and separating the overhead of the system itself.
The graph shows the results of independent test runs at different times, which confirms the greater stability of the linear coefficient than individual tests.
Model linearity estimation and Pearson coefficient
Using the graph, we can clearly see that our measurements really satisfy the linear model, but this method is far from accurate and we cannot automate it. In this case, the Pearson coefficient can help us . This method really shows deviations from a straight line, but for 5-10 measurements it is clearly not enough. The following is an example of a clearly non linear relationship, but the Pearson coefficient is quite high.
Returning to our table, knowing the ovehead system (free coefficient), we can calculate the linear coefficient for each measurement, which is done in the table. As we see the numbers (100, 101, 93, 96, 102, 81, 94, 100, 93, 98) - about 95 are randomly distributed, which gives us good reason to believe that the dependence is linear. Following the letter of mathematics, in fact, deviations from the average value must satisfy the normal distribution, and to check the normal distribution it is enough to check the Kolmogorov-Smirnov criterion, but we will leave this for sophisticated testers.
Oddly enough, not all dependencies are linear. The first thing that comes to mind is a quadratic dependence. In fact, quadratic dependence is very dangerous, it kills performance first slowly and then very quickly. Even if for you for 1000 elements everything is done in fractions of a second, then for 10000 it will already be tens of seconds (multiplied by 100). Another example is sorting, which cannot be solved in linear time. We calculate how applicable the linear analysis method is for algorithms with complexity O (n * log n)
(10n log 10n )/ (n log n)= 10 + (10*log 10)/(log n)
That is, for n> = 1000, the deviation will be within 10%, which is significant, but in some cases it can be applied, especially if the coefficient for log is large enough.
Consider an example of a nonlinear relationship.
Nonlinear Algorithm Complexity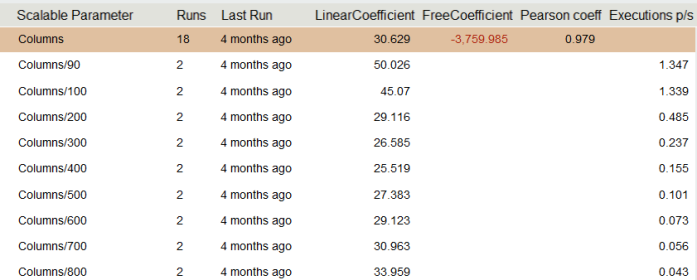
The first thing to note is a negative overhead, for obvious reasons the system cannot have a negative time spent on preparation. The second, looking at the column of coefficients, you can notice the pattern, the linear coefficient drops, and then grows. It resembles a parabola plot.
Test with two or more parameters
Naturally, most systems do not consist of a single parameter. For example, a table reader program already consists of 2 parameters, columns and rows. Using parameterized tests, we can calculate what are the costs of reading a row of 100 columns (let 100ms) and what are the costs of reading a column for 100 rows (let 150ms). 100 * 100ms! = 100 * 150ms and this is not a paradox, we just don’t take into account that overhead reading of 100 columns is already inherent in the speed of reading lines. That is, 100ms / 100 columns = 1ms - this is not the speed of reading a single cell! In fact, 2 measurements will not be enough to calculate the reading speed of one cell. The general formula is where A is the cost per cell, B is one line, C is a column: We compose a system of equations, taking into account the available values and another necessary measurement:
Time(row, column) = A * row * column + B * row + C * column + Overhead
Time(row, 100) = 100 * A * row + B * row + o = 100 * row + o.
Time(row, 50) = 50 * A * row + B * row + o = 60 * row + o.
Time(100, column) = 100 * B * column + C * column + o = 150 * column + o.
100 * A + B = 100.
50 * A + B = 55.
100 * B + C = 150.
From here, we get A = 0.9 ms, B = 10 ms, C = 50 ms.
Of course, having a formula similar to LMNK for this case, all calculations would be simplified and automated. In the general case, the general LMNC does not apply to us, because a function that is linear in each of the arguments is by no means a multidimensional linear function (a hyperplane in N-1 space). It is possible to use the gradient method of finding the coefficients, but this will no longer be an analytical method.
Multiuser tests and tests of multicore systems
The myth "throughput per core"
One of the favorite things to do with performance tests is extrapolation. Especially people like to extrapolate to that area for which they cannot receive values. For example, having 2 cores or 1 core in the system, I want to extrapolate as if the system behaved with 10 cores. And of course, the first wrong assumption is that the relationship is linear. For the normal determination of the linear dependence, it is necessary from 5 points, which of course is impossible to obtain on 2 cores.
Amdahl's Law
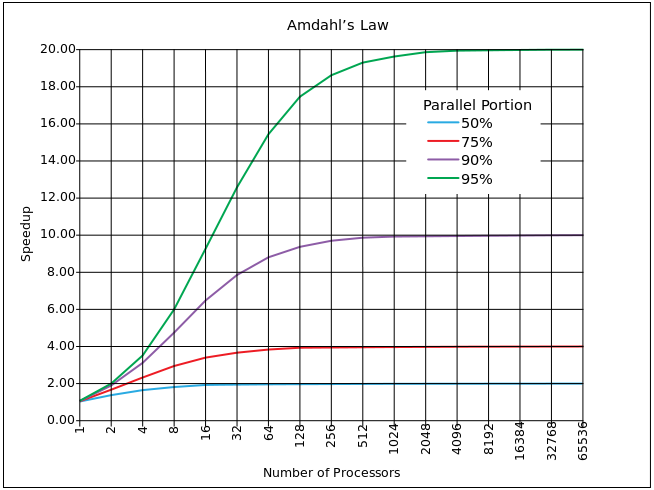
One of the closest approximations is Amdal's law .
It is based on the calculation of the percentage of the parallelized code α (outside the synchronization block) and the synchronized code (1 - α). If one process takes time T on one core, then with multiple running tasks N, the time will be T '= T * α + (1-α) * N * T. On average, of course, N / 2, but Amdahl admits N. Parallel acceleration, respectively, S = N * T / T '= N / (α + (1-α) * N) = 1 / (α / N + (1- α )).
Of course, the graph above is not so dramatic in reality (there is a logarithmic scale in X). However, a significant drawback of synchronization blocks is the asymptote. Relatively speaking, it is not possible to increase the power to overcome the acceleration limit lim S = 1 / (1 - α). And this limit is quite strict, that is, for 10% of the synchronized code, the limit is 10, for 5% (which is very good) the limit is 20.
The function has a limit, but it is constantly growing, from this arises a strange at first glance task: to evaluate which hardware is optimal for our algorithm. In reality, increasing the percentage of paralyzed can be quite difficult. Let us return to the formula T '= T * α + (1-α) * N * T, optimal from the point of view of efficiency: if the core is idle, it will work as long as it does. That is, T * α = (1-α) * N * T, whence we get N =
α / (1-α). For 10% - 9 cores, for 5% - 19 cores.
The relationship between the number of users and the number of cores. Perfect schedule.
A computational acceleration model is theoretically possible, but not always real. Consider the client-server situation, when N clients constantly run some task on the server, one by one, and we do not experience any costs for synchronizing the results, since the clients are completely independent! Keeping statistics for example introduces a synchronization element. Having an M-nuclear machine, we expect that the average query time T when N <M is the same, and when N> M the query time grows in proportion to the number of cores and users. We calculate throughput as the number of requests processed per second and get the following “perfect” schedule.
Perfect graphics

Experimental measurements
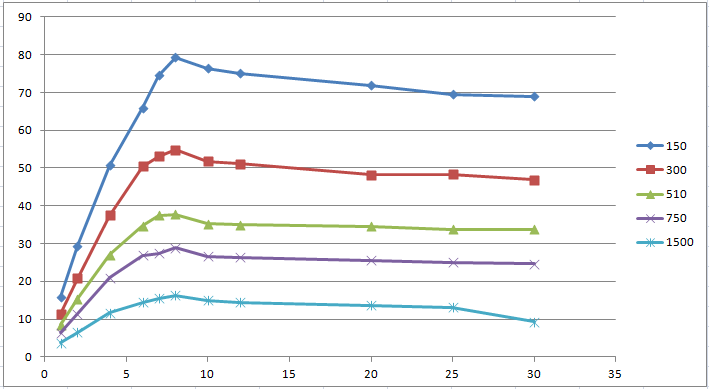
Naturally perfect graphics are achievable if we have 0% synchronized blocks (critical sections). Below are real measurements of one algorithm with different parameter values.
We can calculate the linear coefficient and build a graph. Also, having a machine with 8 cores, you can conduct a series of experiments for 2, 4, 8 cores. From the test results, you can see that a system with 4 cores and 4 users behaves exactly the same as a system with 8 cores and 4 users. Of course, this was expected, and gives us the opportunity to conduct only one series of tests for a machine with the maximum number of cores.
Experimental measurements using a linear coefficient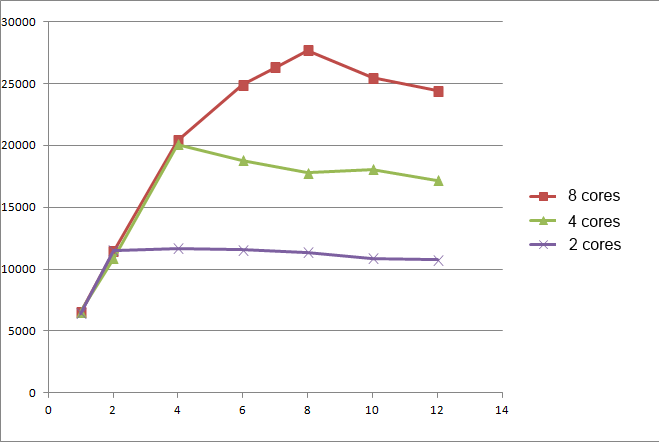
The measurement graphs are close in value to the Amdal law, but still significantly different. Having measurements for 1, 2, 4, 8 cores, you can calculate the number of non-parallelizable code using the formula
Where NP is the number of cores, SU = Throughpt NP core / Throughput 1 core. According to Amdahl’s law, this number must be constant, but in all dimensions this number drops, although not significantly (91% - 85%).
The throughput per core graph is not always a continuous line. For example, with a lack of memory or when running GC, deviations in throughput can be very significant.
Significant throughput swings with Full GC
Behavioral Test
Throughput
When measuring the load of multi-user systems, we introduced the definition Throughput = NumberOfConcurrentUsers / AverageTimeResponse . To interpret the results, Throughput is the throughput of the system, how many users the system can serve at a time, and this definition is closely related to the queuing theory . The complexity of measuring throughput is that the value depends on the input stream. For example, in queuing systems, it is assumed that the response time does not depend on how many requests are in the queue. In a simple software implementation, without a queue of applications, the time between all flows will be divided and, accordingly, the system will degrade. It is important to note that you should not trust JMeterthroughput measurements, it was noticed that Jmeter averages throughput between all steps of the test, which is not correct.
Consider the following case: when loading with 1 user, the system gives Throughput = 10, with 2 - Throughput = 5. This situation is quite possible, since a typical Throughput / User graph is a function that has one local (and global maximum).
Therefore, with an input stream of 1 user every 125ms, the system will process 8 users per second (input throughput).
With an input stream of 2 users, every 125ms the system will begin to collapse, since 8 (input throughput)> 5 (possible throughput).
Collapsing system
Consider an example of a collapsing system in more detail. After conducting the Throughput / Users test, we have the following results.
Users - the number of simultaneous users in the system, Progress per user - how much percentage of the work the user does in one second. Mentally simulate the situation that 10 users come every second and begin to perform the same operation, the question is whether the system can serve this stream.
In 1 second, 10 users on average will perform only 20% of their work, based on the assumption that on average they will do all in 5. At the second second, there will already be 20 users in the system and they will share resources between 20 threads, which will reduce percentage of work performed. We continue the series until the moment when the first 10 users finish the work (theoretically they should finish it as the series 1/2 + 1/3 + 1/4 ... diverging).
It is quite obvious that the system will collapse, because after 80 seconds there will be 800 users in the system, and at that moment only the first 10 users will be able to finish.
This test shows that for any distribution of the incoming stream, if the incoming throughput (expectation) is greater than the maximum
measured throughput for the system, the system will begin to degrade and fall under constant load. But the opposite is not true, in the 1st example, the maximum measured throughput (= 10)> incoming (8), but the system will also not be able to cope.
Stationary system
An interesting case is a workable system. Based on our measurements, we will test that every 1 second 2 new users come. Since the minimum response time exceeds a second, at first the number of users will accumulate.
As we can see, the system will enter the stationary mode exactly at that point, the graph when the measured throughput coincides with the input throughput. The number of users in the system will average 10.
From this we can conclude that the Throughput / Users graph on the one hand represents the number of processed users per second (throughput) and the number of users in the system (users). The graph falling to the right of this point characterizes only the stability of the system in stressful situations and the dependence on the nature of the incoming distribution. In any case, conducting Throughput / Users tests, it will not be out of place to conduct a behavioral test with approximate characteristics.
Amazing distribution
When conducting performance tests, there are almost always measurements taking much longer than expected. If the testing time is large enough, then the following picture can be observed. How to choose one number from all these measurements?
Statistics Selection
The simplest statistics are average, but for the above reasons, it is not completely stable, especially for a small number of measurements. To determine the quantiles, it is convenient to use the distribution function graph. Thanks to the wonderful JMeter plugin , we have such an opportunity. After the first 10-15 measurements, the picture is usually not clear enough, therefore, a detailed study of the function will require 100 measurements.
First measurements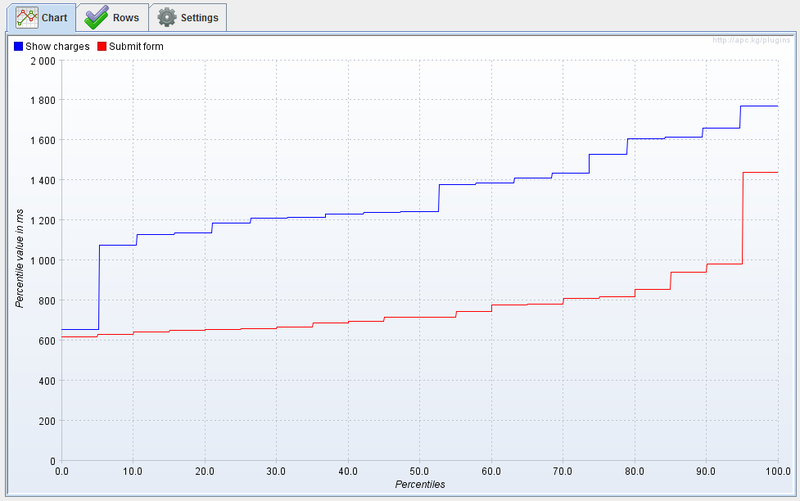
Obtaining the N-quantile from this graph is very simple; just take the value of the function at a given point. The function shows a rather strange behavior around the minimum, but then it grows quite stably and only around 95% of the quantile a sharp rise begins.
Distribution?
Is this distribution analytical or known? To do this, you can plot the distribution density and try to look at the known functions, fortunately there are not many of them .
Honestly, this method did not bring any results, at first glance similar distribution functions: Beta distribution, Maxwell distribution, turned out to be quite far from statistics.
Minimum and exponential distribution
It is important to note that the range of values of our random variable is by no means [0, + ∞ [, but some [Min, + ∞ [. We cannot expect a program to execute faster than a theoretical minimum. If we assume that the measured minimum converges to the theoretical one and subtract this number from all statistics, then we can observe a rather interesting regularity.
It turns out Minimum + StdDev = Mean (Average), and this is typical for all measurements. There is one known distribution in which, the mathematical expectation coincides with variance, this is an exponential distribution. Although the graph of the distribution density differs at the beginning of the definition domain, the main quantiles are quite the same. It is quite possible that the random variable is the sum of the exponential distribution and the normal one, which completely explains the fluctuations around the point of theoretical minimum.
Variance and average
Unfortunately, I could not find a theoretical justification why the test results satisfy the exponential distribution. Most often, the exponential distribution appears in the problems of device failure time and even human lifetime. It is also unclear whether this is the specifics of the platform (Windows) or Java GC or some physical processes occurring in the computer.
However, taking into account that each exponential distribution is defined by 2 parameters (dispersion and mathematical expectation) and the performance test distribution function is exponential, we can assume that for the peformance test, we need and only 2 indicators are enough. The average is the test execution time, the variance is the deviation from this time. Naturally, the smaller the variance, the better, but it is impossible to say unequivocally that it is better to reduce the average or variance.
If someone has a theory of where dispersion comes from and how this or that algorithm affects its value, please share. I want to note on my own that I did not find the relationship between the test execution time and the variance. 2 tests performed on average the same time (without sleep) can have different dispersion orders.