BMW Mnemonic for finding boundary values
Content
- Mnemonic BMW
- Common examples
- My examples from the Big Mouse practice
- Linux, Lucene, Mmap
- Redhat 6 ≠ Redhat 7
- Java and garbage collection
- Wildfly
- Logging
- Transliteration
- Oracle RAC
Little mouse - Total
Mnemonic - a word or phrase that helps us to remember something. The most famous mnemonic is “every hunter wants to know where a pheasant sits.” Whom do not ask, everyone is familiar with it.
But in the professional field everything is a little sadder. Ask comrades if they know what SPDFOT or RCRCRC is. Far from a fact ... But mnemonics help us get rid of tests, not forgetting to check the most important. Check list, collapsed into one phrase!
English-speaking testers actively use mnemonics. A friend who reads foreign blogs says that Americans make them up for almost every sneeze.
And I think this is great. Alien mnemonics may not be suitable for your system or your processes. And my own, native, will remind “do not continue to check this and this” and limit the number of bugs in production.
Today I want to share with you my BMW mnemonic to study the boundary values. You can:
- give a junior for general development in test design;
- to use at the interview - the task “find the border in the number” the candidate usually decides, but will he find the border in the string or to load the file?
Mnemonic BMW
B - big
M - small
B - just right

It is easy to remember. Just remember this cool car and immediately the decoding is ready! But what does it mean and how will it help at the interviews?
Just right

In principle, “just right” you are testing and without any mnemonics. We always start with positive testing to verify that the system works in principle.
If the field is numeric, enter the common value. Let's say we have a retail online store. In the quantity of goods we can check 1 or 2.
Positive test - this is “just right”. I showed the mnemonic in the form of a mouse. Here it is a standard size.
Big
Then we say that the little mouse needs to be blown up to unbelievable sizes, so that it does not fit straight into the picture. And see how the system will work with it.

In this case, we just go "far ahead." VERY FAR! The big mouse personifies the search for a technological frontier somewhere, outside arbitrary.
To enter the amount of goods it will be "99999999999999999999999999999999999999999999999999999999 ...". Not just some great value (9999), but VERY big. Remember the little mouse - it was so swollen that it didn’t even fit the picture.
The difference is important, great value will help to find an arbitrary border, and a huge one - a technological one. The “big” test is often performed, the “huge” test is not. Mnemonic reminds of him.
Little
We pierce a little mouse, and it is blown away to the microscopic size.

A little mouse is a search for values near zero. The most minimal positive value.
How about a test for "0.00000001"? They checked for zero, but do not forget to dig it side by side.
And so what?
It seems to be the obvious things I say. It seems that this is what everyone knows. You only give a puzzle to the numbers on the interview, the same triangle (the problem from Myers ), and you understand that this is not so ... Very few people will go looking for a technological boundary or try to enter a fractional value around zero. Maximum zero and offer to check.
And if you propose to test the number is not, then it is even more stupor. Since the number is okay, they checked the zero and the border according to the TZ, it's already quite good. And what about testing? And in the file?
This is what I want to tell in the article. How can mnemonics be applied in real life while catching bugs? Let's start with common examples - which are found on every project. And which can be given at the interview in the form of a small task.
And then I will tell examples from my work. Yes, they are specific. Yes, they are about specific technologies. So what? But they show how to apply mnemonics in more complex places.
The meaning is the same: there are borders almost everywhere. Just find the number and experiment with it. And do not forget about the BMW mnemonic, because it is on the B and M that we can often encounter bugs.
Common examples
Examples that are in any project: a numeric field, a string, a date ... We will consider in this order:
- Just right
- Big
- Little
Number
- ten
- 0,00000001
- 999999999999999999999999 ....
For example, a field with the number of books, dresses or juice packs. As a positive test, we choose some adequate amount: 3, 5, 10.
As a small value, we choose as close as possible to zero. Remember that the mouse should be quite small. This is not just a unit, but the Nth decimal place. Suddenly it will be rounded to zero and somewhere in the formulas will fail? At the same time, on the number “1” everything will work well.
Well, the maximum is achieved by entering 10 million nines. Generate such a string using Perlclip type tools, and go ahead, test for VERY MUCH!
See also:
Equivalence classes for a string that indicates a number - even more ideas for tests of a numeric string
How to generate a large string, tools - assistants in generating great value
date
- 05/26/2017
- 01/01/1900
- 21.12.3003
A positive date is either “today” if we load the report on some date. Or your date of birth, if we are talking about DR, or some other that fits your business process.
As a small date, we take the magic date "01/01/1900", on which applications often fall apart. From this date begins the countdown in Excel. She also crawls into the application. You set this magic number - and the report falls apart, even if there is a fool proof to zeros. So I highly recommend her to check.
If we talk about a very small mouse, then you can also check out “00.00.0000”. This will be a zero check, which is also important. But developers are protected from such a fool more often than from 01/01/1900.
"Far ahead" can also be different. You can go into the negative and check a date or month, which does not really exist: 05.05.2018. Or search for a technology border using the date 99.99.9999. And you can take a little more real value, which simply does not come soon: 2400 or 3000.
See also:
Equivalence classes for a string that indicates a date - even more ideas for date testing

Line
- Vasya
- (one space)
- (There was a lot of text here)
For example, during registration there is a field with the name. The positive test is the usual name: Olga, Vasya, Peter ...
When searching for a little mouse, we take an empty string or a life hack: one or two spaces. At the same time, the line remains empty (there are no characters there), but at the same time it seems to be filled.
What is the emphasis when searching for a big mouse? When we test a large string, we need to test a BIG string! Recall that the mouse should be BIG. Because I usually explain to students how it all works, how to search for a technological frontier, and so on. And then they give me a DZ and write, "I checked 1000 characters - there is no technological limit."
21 century in the yard, well, what 1000 characters? We take any tool that allows us to generate 10 million, and insert 10 million. This will already be a search for a technological border. And there are already some bugs on it, the system can break off on it. But 1000 characters? Not.
See also:
How to generate a large string, tools are helpers in generating great value.
But ok, everything is also clear here. What happens if we test the file?
File
Where can I find the number in the file?
First, the file has its size:
- 5 mb
- 1 kb
- 10 GB
When testing a large file, they usually try something like 30MB, and they calm down on it. And then you load 1GB - and that's all, the server is frozen.
Of course, if you are a beginner and are testing for the experience of a real site, you should not load it without the knowledge of the owner. But when you test at work, be sure to check out the big mouse.
Secondly, the file has a name → and this is the length of the string we just discussed.
But the file still has its content! There are a number of columns (columns) and lines. Tests in the lines:
- 5 lines
- 1 line
- 10000000000 lines
And here the interesting begins. Because even in the same Excel in different versions there are different restrictions on the number of lines that it supports:
- Excel below 97 - 16 384
- Excel 97-2003 - 65,536
- Excel 2007 - 1 048 576
But still the numbers are quite large, it is not interesting. But on the columns the old Excel did not open more than 256, and now this is a serious limitation:
- Excel 2003 - 256
- Excel 2007 - 16 385
His free colleague, LibreOffice, cannot open more than 1024 columns.

Life story
We write some autotests in CSV format. At the entrance to the table at the exit table. Open and edit in LibreOffice to see where the column is. Everything is great, everything works. While the number of columns does not get out for 1024.
Here begins # life-pain. The LibreOffice test will no longer open, in the CSV format is inconvenient, because it is difficult to understand where the 555 column is. You open the test in Excel, edit, save, run the test ... It falls in 10 new places: the INN has become corrupted. After all, it is long, for example 7710152113. Excel, it happily translates it into the format 1,2Е + 5.
Other long numbers are also lost.
If the value was in quotes, it turns into additional quotes that the test does not expect.
And you correct these little things already in CSV format, mentally berating Excel to yourself ... So there is a limitation, you should remember about it! Although it is not displayed on the work of the system itself, it may simply complicate the life of the tester.
Oracle table (database)
And since we started talking about 1024 columns, we’ll recall about Oracle (a popular database). There is the same restriction: in one table there can be a maximum of 1024 columns.
This is better to remember in advance! We had a table in which there were about 1000 columns, but half was reserved for the future: “someday it will come in handy, this will be enough for us for a long time”. Enough, but not for long ...
There is nowhere to expand the table - they came up against the constraint. So either divide the table into two, or pack the contents into a BLOB: this is something zip-archive with data is obtained, takes one column, and inside contains as many as you want.
But in any case, this is data migration. And data migration is always a life pain. On a large base, it takes a long time, brings new problems that can fire only after six months ... Brrr! If you can do without migration, then it is better to do.
If you have a table in which a lot of data, think about the future. Will you always fit into 1024 columns? Do not have to migrate later? After all, the longer the system lives, the more difficult the transfer will be. And “enough for 5 years” means a five-year volume will need to be migrated.
How to test it? Yes, by code, evaluate your data tables, take a closer look at what lies there. Pay attention to the big mouse: those tables that already have a lot of columns. Will there be problems with them in the future?
Report in the system
And why do we load files into the system or download data from oracle? Most likely in order to build some kind of report. And here you can also apply this mnemonic.
Data can be both at the input (many, little, just right), and at the output! And this is also important, since these are different equivalence classes.
As a result, we are testing the quantity:
- report columns;
- lines;
- input data;
- data output (in the report itself).
Structure (columns and rows)
Can we influence the number of rows or columns? Sometimes yes, we can. In the second paper, I tested the report designer: on the left you have cubes with the names of the parameters that you can throw in the report itself horizontally or vertically. That is, you yourself decide how many rows there will be, and how many columns.
Apply mnemonic. After the sample report (positive test, “just right” mouse) we try to do a little:
- 1 column, 0 rows;
- 0 columns, 1 row;
- 1 column, 1 row.
Then a lot:
- maximum of columns, 1 row (all cubes were thrown into columns);
- row maximum, 1 column;
- if the cubes can be duplicated, then there and there to the maximum, but this is doubtful;
- maximum nested levels (this is when there are two others inside one aggregator column).
Next, we test the input and output data. Here we can influence them in any report, even if there is no designer and the number of rows and columns is always the same.
Input
data Find out how the report is generated. For example, every day some data is filled in, say, the number of dresses sold, sundresses, T-shirts. And in the report we see the grouping of data by categories, colors, sizes. How many sold per day / month / hour.
We build the report, and we affect the data at the input:
- The usual number (5 dresses per day, although on huge venues this number may be 2,000 or more, you need to clarify what will be more positive for your system).
- Empty, nothing sold / sold 1 item for a month.
- The volume is unrealistically large, to the maximum of each product, each color, each size. We put the maximum “lies in stock” and sell everything: within a month or even one day. What will the reporting say to this?
Data at the output
In theory, the data at the output correlate with the data at the input. At the input a little → at the output will be small. At the entrance a lot - at the exit a lot.
But this does not always work. Sometimes the input data can be eliminated, or, conversely, multiplied. And then we can somehow play with it.
For example, the Dadat system . You load the file with one column full name, you get several at once on the output:
- Original name that was in the file;
- Dismantled name (if you could make out);
- Rod case;
- Dat case;
- Creative. case;
- Surname;
- Name;
- Middle name;
- Status parsing - confident recognition of the mechanism or to verify a person;

We received 9 from one cell. And this is only in full name, and the system also knows how to parse addresses. There, almost 50 are obtained from one cell: in addition to the granular components, there are all sorts of codes KLADR, FIAS, OKATO ...
And here it is already interesting. It turns out that we may have little data at the input, but a lot at the output. And if we examine the maximum in columns, then we have two options:
- 500 columns at the output (which is about 10 addresses at the entrance);
- 500 columns at the entrance (and a whole bunch at the exit).
The principle works in the opposite direction. What if the input is a whole bunch of data, and the output is zilch? If instead of the name there is some kind of nonsense like “or34e8n8pe”? Then it turns out that all the additional columns are empty, only the status of parsing "you sent me garbage." So we get a minimum output (small mouse), which is also worth checking out.
And if the speakers can be excluded! It is also possible to check the equivalence class “zero” when the output is zero, the source file is non-empty. You can at least check when left 1 column out of a hundred.
The main thing is to remember that in addition to the input data, we have data on the output. And sometimes they can check the boundaries, which will not depend on the input data. And then it must be done.
Mobile applications
Connection
There are different communication options:
- Normal;
- Quite fig (small mouse);
- Super fast (large).
And a bad connection can be partially: if you are in a zone with a normal wifi and a bad cellular network. Internet works well, but bad sms.
Amount of memory
It is also important how much memory the application has:
- Normal amount;
- Very little;
- Lots of.
And if in this case the first and third tests can be combined in this case, then the small mouse is very interesting. And here there are different options:
- we run the application on the phone, which already has little memory;
- we start when memory is normal, we collapse, we expand something large, we try to return to the first application.
Now, if the application does not know how to properly reserve memory, then in the second case it will simply fall, the memory is already depressed.
Device diagonal
- Standard (we study the market, see what is more popular with our users).
- Minimum (telephone).
- Maximum (large tablet).
Screen resolution
- Standard;
- The smallest;
- The biggest;
Do not confuse resolution and diagonal, these are different things. You may have an old device with a large display, and I have a new trendy smartphone, where the resolution is 5 times better. And so what will happen in 20 years, scary to imagine.
GPX paths
GPX paths are XML files with consecutive coordinates. They can be loaded into mobile emulators so that the phone thinks that it moves in space with some speed.
Useful if the application reads GPS coordinates for some of its own purposes. So it determines whether you are going, running or going. And you can not run, just feed the application coordinates, set the coefficient of their passage and test, sitting in the office.
What factors should be checked? All according to mnemonic:
- 1 - the usual coefficient, simple walking replaces;
- 0.01 - as if you are lagging behind me;
- 200 - do not even run, and fly!
Why is all this necessary to check? What bugs can be found?
For example, the application may crash on the plane - launched, but it immediately collapsed. As it reads the coordinates and tries to determine your speed. But who knew that the speed will be above 130?
At a slow speed, the application may crash. Set yourself a million intermediate points and not mastered to keep them in memory. And that's all, bye bye ...
See also:
What are GPX paths and why are they to the tester? - more about gpx paths and an example of such a file
Summary of Common Examples
I want to show here that it would seem that “big, small” is a numerical field and that’s all!
And in fact, mnemonics can be used everywhere, whether files, toys, reports ... And it really helps us to find bugs. Here are some examples from my practice:
Little mouse (lower bound)
- Date 01/01/1900
When I worked on freelancing, this date I was breaking up all the reports. Because even if the developer set protection against a fool, he set protection against 0000. And he did not set protection against 1900.
- Lonely line end character
This test was suggested to me by a more experienced colleague when we were discussing examples of the use of mnemonics. If the system checks the file for emptiness, you need to check is not entirely empty.
I recommend the following test: add the line end character to the file. Not even a space, but a special character. And see how the system responds. And it does not always respond well =)
Big mouse (upper border)
If we talk about a big mouse, then there is generally an infinite number of bugs:
- War and peace;
- A lot of data;
- 2 GB.
You can load war and peace into the text field, upload a huge file to the system, get a lot of data at the entrance or at the exit. These are all typical mistakes that I have encountered in my practice. And not only me, the upper limit in general is often checked just because they know that there may be bugs. It is rather about a small mouse forgotten.
Another example of a big mouse is load testing. ABOUT! I have such examples, so we are switching to hardcore.
If you know the context, if you know how your application works inside, in what programming language it is written, what database it uses, you can also apply this mnemonic. And I want to show it with concrete examples.
My examples from practice
Big mouse
Linux, Lucene, Mmap
In the Linux operating system there is a setting for the maximum number of open file descriptors:
- redhat-6 - /etc/security/limits.conf
- redhat-7 - / etc / systemd / system / [name of service] .service.d / limits.conf (for each service its own)
The file descriptor opens for any action with the files:
- create a database connection;
- read file;
- write to file.
- ...
If your system is actively working with files and conducting many operations - the setting should be increased. Otherwise, the slightest load will put you.
Our system uses the search index Lucene. This is when we take some data from the database and upload it to the disk, so that we can search for them faster. And if we build an index with the help of mmap technology, then during the construction of the index it opens a lot of files for writing.
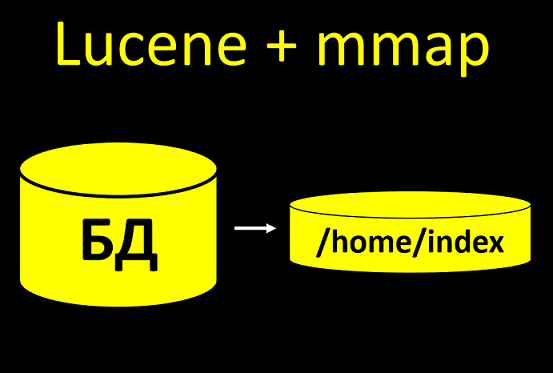
There are usually 100 clients in the test base, well, 1000. Not so much. Rebuilding passes without problems, even if you do not configure descriptors.
And in a real system there will be 10+ million customers. And if the number of file descriptors is not configured there, then everything will simply collapse when you start building indexes.
You need to know about this and immediately write an instruction: configure the operating system on the server, otherwise there will be such and such consequences. And on its side it is important to carry out not only functional tests, but also load, on the actual amount of data.
Redhat 6 ≠ Redhat 7
When testing a big mouse (load), do not forget that in different configurations the application will work differently. If you take the instruction from the previous paragraph, then you should not only write it, but also check it. And check in the environment of the customer.
Because different operating systems work differently. And we had such a situation that everything seems to be set up, but the system crashes and says “I don’t have enough open file descriptors”. We say:
- Check the parameter.
- It is configured, all according to your instructions!
How so? It turns out that we have instructions for Redhat 6, and they have Redhat 7, where the setting is completely different! As a result, they did it according to non-working instructions and seemed not to do at all.
So if you work with different versions of linux-distributions, they need to check everything. And not just deploy the services on the machine, but also perform load testing at least once: make sure that everything works. After all, it is better to catch a bug in the test environment than to understand production.
Java and garbage collection
We use the java language, which has a built-in garbage collector ... Sometimes it seems that if an application uses a lot of memory and is on the verge of OOM (Out of Memory) for some complex operation, then you can solve this problem easily by simply increasing the amount of available memory. ! Why test?
Not really. Give a lot of Xmx - the application will hang on the garbage collector ...

And it manifests itself very suddenly for the user. At night, they submitted a large load, loaded a lot of data, especially during off-hours, so as not to disturb anyone. In the morning the user comes, he is the only one working with the system, almost no load, and everything hangs on him. And he doesn't even understand why.
But in fact, the load has passed, the load is gone, and the garbijklelektor went out to clean everything up, because of this, friezes. And although there is no load now and the lonely user works, he is sad.
Therefore, simply allocating a lot of memory to the application "and you can not test" - this does not work. Better check.
Wildfly
WildFly java application server will not allow downloading large files if it is not configured accordingly.

We use the Jboss application server, aka Wildfly. And it turns out that by default you cannot upload large files. And we remember that the mouse should be BIG. If we test 5mb or 50, everything works, everything is fine.
But if you try to download 2GB, the system issues a 404 error, and you cannot understand anything by logs: the application logs are empty. Because this is not an application can not download the file, Wildfly itself cuts it.
If you do not conduct testing on your side - the customer may face this. And it will be very unpleasant, he will come up with the question “Why isn’t he loading?”, But you cannot say anything without a developer. Therefore, it is better not to forget to test the boundaries, including large files in the system to push. At a minimum, you will know the result of such actions.
And here we either fix it by increasing the max-post-size parameter, or give information about the restriction and write it in the statement of work.
Logging
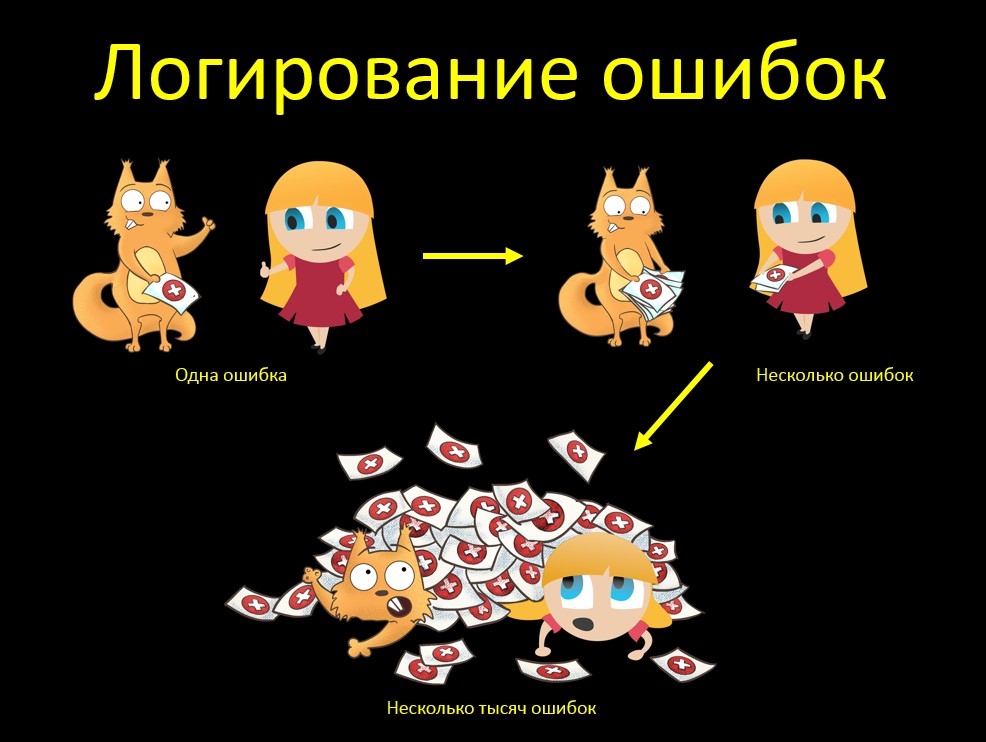
Another example of testing a "big" mouse. Yes, I somehow remember more examples on it ... More often, bugs catch!
Suppose we check the error logging. That the error is written to the frame in the log. Here we checked, we are great: yes, everything is cool, everything is recorded! And I understood everything from the stack in the text of the error. If the customer falls, I immediately understand why.

And what will happen if we have more than one mistake? Everything is good too, everything is logged, everything is fine! But we remember that the mouse should be GREAT:

What will happen if we have a lot of mistakes? We just had this situation. The source system uploads data to the buffer table in the database. Our system takes this data from there and somehow works with it later.
The source system crashed and it unloaded an incorrect increment, where all the data was erroneous. Our system took the increment, and there are 13600 errors. And when Java tried to generate a stack trace for 13k errors, she devoured all the memory that she had been allocated, and then said, “Oh, java heap space”.
How to fix? Added the maxStoredErrors (default 100) parameter to the load task — the maximum number of errors stored in the memory for a single thread. Upon reaching this amount, errors are displayed in the log and the list is cleared.
We also removed duplication of error messages on the execution of the task by our Task and the Quarz RunShell, increasing the logging level of the latter to warn (the message is displayed by it in info). Due to duplication, the stack doubled again ...
And what is the conclusion from this story? It is not enough to check "just right". This is an important and useful test, yes, no one argues. We look, whether the error is logged in principle, in what test, etc. But then it is very important to check the BIG mouse. What happens if there are a lot of mistakes?
And you need to understand that "a lot" - it means a lot. If you load an increment of 10 errors and say “10 errors are also normal, the system displays all the stack traces,” then the tests seem to have been performed, but the problem was not revealed. If we see that the system displays all the messages, we need to think in advance: what will happen if there are MANY of them? And check.
Transliteration
If you have some kind of transliteration principle, you can go and try to find out, but how does it even work inside? If he transliterates two letters as one, then what will happen if we enter three letters or four identical letters?
OO = At
OOO =?

And what will happen if we introduce a lot of them? It is possible that the system will start sorting through the options and go into an endless recursion, and then just hang. So we check the long string:
Oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
She hangs up the application tightly if the developers did not consider the infinite loop of options "oo"

Oracle RAC
Oracle is a popular database. Oracle RAC is when you have several database instances. It is necessary to ensure the smooth operation of business-critical systems: even if one instance is broken, the rest continue to work, the user will not even know about it.
If you are using Oracle RAC, you MUST conduct load testing on it. If you do not have it, then you need to ask the customer, from whom he stands, to carry out the load on his side.
Then the question may arise - why then do you not have it? It's simple, the iron for testing usually always give worse. And if the system is focused on Oracle and one customer out of twenty uses the RAC, then buying it for testing will be unprofitable, since RAC is very expensive. Easier to negotiate with the client and help him conduct tests.
What happens if load testing is not performed? Here is an example from life.
There is an opportunity to create a column in the database and say that it is an auto-incremental field. This means that you do not fill in the field at all, it is generated by the database. Is there a new line? Recorded the value "1". Still new line? She will have the value "2". And each new value will be more and more.
For example, it is very convenient to generate identifiers. You always know that your id is unique. And for each new line it is more than for the previous one. In theory ...
We have two entity identifiers in the system:
- id - identifier of a specific version, auto-increment field;
- hid is a historical identifier, it is always constant for one entity and does not change.
As a result, you can make a selection for a specific version, or you can make a selection by a hid-entity and see its entire history.
When an entity is created, id = hid. And then the id increases, it is always greater for new versions than hid. Therefore, the version definition formula is:
version = (id - hid) + 1
It cannot be negative, since the base itself creates the id.
But they come to us with a question on the essence and show the records from the database. I do not remember what the question was about, and it does not matter. I look at the records and do not believe my eyes: the version has negative values. How so ?? This is impossible. It turned out possible.
In the RAC, each node has its own cache. And it may happen that the nodes do not have time to notify each other, and you see the same number twice in the table:
- An entity is created. Noda looks into the cache, what is the last value of the auto-incrementally field? Yeah, 10. So, I'll give the identifier 11.
- A new entity immediately arrives at the second node (requests came simultaneously and the balancer one threw at node 1, and the second at node 2).
- The second node looks into its cache, what is the last value of the field? Yeah, 10 (the first node has not yet managed to tell the second that it took this number). So, I will give the identifier 11.
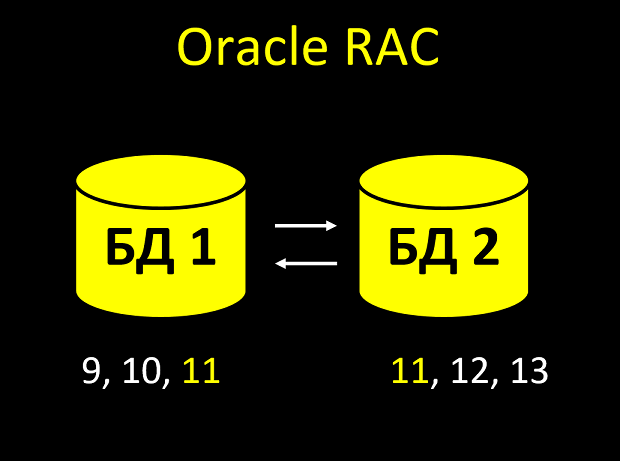
Total we receive not unique value of a unique field. And in fact, with a large load of such intersections of identifiers there will be not one or even two ... If you have all the business logic tied to the fact that id is always unique and always increases, there will be OY.
In our case, nothing catastrophic happened, and carrying out load testing on the test bench of the customer helped. Found the problem early, as it turned out, negative versions of the system do not interfere with life. But we have added to the scripts for creating the database the ordering of sequences, just for such cases.
The moral of this story is that it is VERY important to carry out load testing on the same hardware that will be in PROD. Everything can affect the result: the settings of the OS itself, the settings of the database, whatever. What you did not even suspect.
Conduct tests in advance. And remember that not all problems can be found functional tests. In this example, a simple test would not find bugs. After all, if you create entities manually, that is, slowly, all the nodes of the database will have time to notify neighboring ones, so we will not get inconsistency.
Little mouse
Blank json
If you are using the open-source Axis library, try sending empty JSON to the application. He may well hang everything completely.
And most importantly - you can not do anything with it on your side! This is a bug in a third-party library. So here either wait for the official correction, or change the library, which can be very difficult.
In fact, this bug has already been fixed in the new version of Axis. It would seem, just be updated, and that's it! But ... The system rarely uses one third-party library. Usually there are several, they are tied to one another. To update them, you need to update everything at once. It is necessary to refactor, because they now work differently. It is necessary to allocate developer resources.
In general, just updating the library version sometimes takes a whole release of a cool developer. So, for example, when we moved to a new version of Lucene, we spent 56 hours on a task, this is 7 person-days, a full-time developer’s week, plus testing. The task itself looks something like this, put by its architect:
Lucene. Go to using PointValues instead of Long / IntegerField.And this is just a library update! And to abandon one library because of a bug in it is generally scary to imagine how long it will take ...
In the Lucene Migration 5 -> 6 dock, there is a clause about abandoning Long (Integer / Double) Field in favor of PointValues.
When switching to Lucene 6.3.1, I left the old fields (all classes were renamed with the addition of the Legacy prefix), because the translation pulls into a separate task.
It is necessary to abandon the old fields and use the Long (Integer / Double) Point classes, which, according to tests, weigh faster and less in the index. We'll have to rewrite a lot of code.
Sure to! The transition must be backward compatible so that the search (at least the key functions) does not break off with the upgrade version. It should work on the old index (before rebuilding), and after rebuilding (at a convenient time for the customer) new fields should be picked up.
So it’s quite possible that you’ll just live with a bug for a while. Know about him, but do not change anything. In the end, "there is nothing stupid requests to send."
But in any case, you should at least know about the presence of a bug. Because if a user comes to you and says, “Everything is hanging on you,” you should understand why. With that in the logs is empty. Because this is not your application freezes, everything hangs at the stage of JSON conversion.
It would seem - an empty request! But what can it lead to ... That is, even if you do not know that Axis has such a bug, you can simply check the empty JSON, the empty SOAP request. In the end, this is a great example of a zero test in the context of a JSON request.
Do not forget to test zero. And the smallest value is a little mouse, because it also brings bugs, and sometimes so scary.
See also:
Equivalence class “Zero-non-zero” - more about testing zero
"Moscow" in the address field
Service Dadata is able to standardize addresses - lay out the address in one line on the granular components + determine the area of the apartment, if it is in the directory.
During testing, there was a funny bug - if you type the word "Moscow", the system determines the area of the apartment. Although it would seem, where in this "address" apartment?

I think this is a great example of a “little mouse.” Because what is usually checked? The usual address, the address to the street, to the house ... Empty field. Any single character is considered a unit test.
But if you enter one letter - the system determines the input as a complete trash and clears the address. It behaves correctly, but it is a negative case for a unit. This is a check of the field length only
And here it is worth thinking about whether there is a positive unit? There is. One word, such a system will determine. And here there are also different equivalence classes: it can be a word from the beginning of the address (city), and maybe from the middle (street). Try it is worth both. But if you limit yourself to only “one in the text field = one character”, then you will never find this bug.
Total
Mnemonic there is a great many. And using them can help you. Because you are already looking at your app the 10th, the 100th time ... You already have a glimpse of your eyes, you can skip the obvious error. And if you take any existing mnemonic, then look at the application in a new way. What will help discover new bugs.
And even such a simple mnemonic like a BMW helps a lot. But it would seem ... Big, small, think! Simple boundary values. But they must always be remembered and always checked! This brings fruit and a variety of bugs.
In my examples, I wanted to show that you can search for borders not only in a text or numeric field. Mnemonics works everywhere: in Oracle RAC, Java, Wildfly, anywhere! Learn to look at the boundaries wider than usual understanding of "entered" War and Peace "in the text field."
Of course, we focus on the “big mouse”, it is she who brings most of the bugs. It is such cases that come to mind when you think that you met on your project.
But about the "little mouse" should not be forgotten. Yes, I could only recall a couple of examples specific to my work. But this does not mean that I do not find bugs on a small mouse. I find! Those that are in the section of general examples: date 01/01/1900, 1 kb file, empty report with filled data ...
Borders are very important. Do not forget to test them. I hope my examples will inspire you, and the BMW mnemonic will always pop up in your head when allocating equivalence classes.
Or maybe you will invent your own mnemonic. Which will be for you, for your team, for your features, for your processes. And this is also great, it is also a success. The main thing is that it helps!
PS is an excerpt from my book for beginner testers. I also talked about mnemonics in a report on SQA Days, a video here .