We increase the reliability of the data center! (photo from the thermal imager inside)
Almost all accidents in correctly planned data centers are predictable and can be detected at the pre-accident stage. But how to understand in advance where to “lay straws”? Under cat, our experience of improving the reliability of the data center on the street. Prishvina (e-Style Telecom).
The data center infrastructure must be maintained and checked, and shutdowns, of course, are not allowed. How to achieve this?
How to fix a potential problem before it can affect the system’s performance?
The real reliability of the data center in our country is determined by only three factors:
1. the degree of indifference and stupidity of data center designers and builders;
2. external risks in the company, premises and connections;
3. the degree of carelessness and sloppiness of the data center employees.
Thanks to the painful and expensive experience, based on our own and others' mistakes, we were able to detect a significant number of shortcomings and stupidity at the stages of planning, designing and equipping a data center. And, most importantly, eliminate them in time.
Regarding the risks of the company, the premises and connections, everything worked out - the building and the transformer were built "for themselves", everything was owned, and our company in one of the largest IT holdings is R-Style / e-Style.
It remains only to provide competent service and operation ... easy to say! How? Our steps along this path:
First step, basic: two parallel monitoring systems, common SNMP interface, isolated management network. Absolutely all the equipment of the e-Style Telecom data center was equipped / understaffed with means of self-diagnosis and monitoring. There was already enough information to understand the current state of the systems.
Second - hundreds of temperature sensors have been added (at different points in the equipment room, in different zones). It has become much more informative, the distribution of capacities and temperatures, changes when switching air conditioning units. At this stage, we were no longer able to place new equipment blindly “according to the project”, but to see and compare the real thermal picture and plan the hardware load.
Third- regularly conduct a survey of infrastructure and server equipment with a thermal imager. When they found this method, they were very happy. The thermal imager allows you to quickly get a lot of information for analysis.
Batteries, terminals, connections, drives in storage, wires, filters, fans, air flows, air flow between the corridors - are now visible in advance. After each round, as a rule, something suspicious is detected and eliminated. Today, for example, they found a cable temperature increased by 7 degrees in one cabinet - the client fed 5kW of load through one cable, ignoring the other sockets in the PDU.
A picture of a cold corridor in which cabinets without equipment are immediately visible in the lower part, through which air flows from hot corridors.

Engineer in the cold corridor:

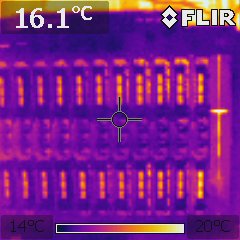
Snapshot of IBM blade with evenly loaded blades:
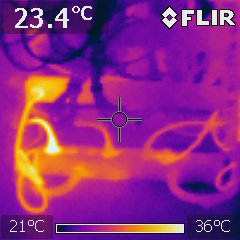
Snapshot of the battery cabinet during battery testing:



Power cables in the cabinets:
Excessive heat generation is often a good prediction of possible problems, the main thing to see in time. We did what we could to know in advance where to “lay straws”.
The data center infrastructure must be maintained and checked, and shutdowns, of course, are not allowed. How to achieve this?
How to fix a potential problem before it can affect the system’s performance?
The real reliability of the data center in our country is determined by only three factors:
1. the degree of indifference and stupidity of data center designers and builders;
2. external risks in the company, premises and connections;
3. the degree of carelessness and sloppiness of the data center employees.
Thanks to the painful and expensive experience, based on our own and others' mistakes, we were able to detect a significant number of shortcomings and stupidity at the stages of planning, designing and equipping a data center. And, most importantly, eliminate them in time.
Regarding the risks of the company, the premises and connections, everything worked out - the building and the transformer were built "for themselves", everything was owned, and our company in one of the largest IT holdings is R-Style / e-Style.
It remains only to provide competent service and operation ... easy to say! How? Our steps along this path:
First step, basic: two parallel monitoring systems, common SNMP interface, isolated management network. Absolutely all the equipment of the e-Style Telecom data center was equipped / understaffed with means of self-diagnosis and monitoring. There was already enough information to understand the current state of the systems.
Second - hundreds of temperature sensors have been added (at different points in the equipment room, in different zones). It has become much more informative, the distribution of capacities and temperatures, changes when switching air conditioning units. At this stage, we were no longer able to place new equipment blindly “according to the project”, but to see and compare the real thermal picture and plan the hardware load.
Third- regularly conduct a survey of infrastructure and server equipment with a thermal imager. When they found this method, they were very happy. The thermal imager allows you to quickly get a lot of information for analysis.
Batteries, terminals, connections, drives in storage, wires, filters, fans, air flows, air flow between the corridors - are now visible in advance. After each round, as a rule, something suspicious is detected and eliminated. Today, for example, they found a cable temperature increased by 7 degrees in one cabinet - the client fed 5kW of load through one cable, ignoring the other sockets in the PDU.
A picture of a cold corridor in which cabinets without equipment are immediately visible in the lower part, through which air flows from hot corridors.
Engineer in the cold corridor:
Snapshot of IBM blade with evenly loaded blades:
Snapshot of the battery cabinet during battery testing:
Power cables in the cabinets:
Excessive heat generation is often a good prediction of possible problems, the main thing to see in time. We did what we could to know in advance where to “lay straws”.