Node.js and server rendering in Airbnb
- Transfer
The material, the translation of which we publish today, is dedicated to the story of how Airbnb optimizes server parts of web applications with an eye to the increasing use of server-side rendering technologies. Over the course of several years, the company gradually transferred its entire frontend to a uniformarchitecture, in accordance with which web pages are hierarchical structures of React-components, filled with data from their API. In particular, during this process there was a systematic rejection of Ruby on Rails. In fact, Airbnb is planning to switch to a new service based solely on Node.js, thanks to which fully prepared pages rendered on the server will be sent to users' browsers. This service will generate most of the HTML code for all Airbnb products. The rendering engine in question is different from most of the backend services used by the company due to the fact that it is not written in Ruby or Java. However, it differs from the traditional high-load Node.js-services, around which mental models and auxiliary tools used in Airbnb are built.

Reflecting on the Node.js platform, you can draw in your imagination how an application built using the asynchronous data processing capabilities of this platform quickly and efficiently serves hundreds or thousands of parallel connections. The service pulls out the data it needs from everywhere and processes it a little to match the needs of a huge number of customers. The owner of such an application has no reason to complain, he is confident in the lightweight model of simultaneous data processing used by him (in this material we use the word "simultaneous" to convey the term "concurrent", for the term "parallel" - "parallel"). She perfectly solves her task.
Server-side rendering (SSR, Server Side Rendering) changes the basic ideas leading to a similar vision of the issue. So, server rendering requires large computational resources. The code in the Node.js environment is executed in one thread, as a result, to solve computational problems (as opposed to input / output tasks), the code can be executed simultaneously, but not in parallel. The Node.js platform is capable of handling a large number of parallel I / O operations; however, when it comes to calculations, the situation changes.
Since, when using server rendering, the computational part of the request processing task is increased compared to the I / O part of the task, simultaneously incoming requests will affect the speed of the server response due to the fact that they are competing for processor resources. It should be noted that when using asynchronous rendering, the competition for resources is still present. Asynchronous rendering solves the problems of responsiveness of a process or browser, but does not improve the situation with delays or concurrency. In this article we will focus on a simple model that includes only computational loads. If we talk about a mixed load, which includes both input and output operations and calculations, simultaneously incoming requests will increase delays, but taking into account the advantages
Consider a view command

Parallel execution of operations by means of I / O subsystem
if

Performing computational tasks
One of the operations will have to wait for the completion of the second operation, since there is only one stream in Node.js.
In the case of server rendering, this problem occurs when the server process has to handle several simultaneous requests. The processing of such requests will be delayed until the requests received earlier are processed. Here's what it looks like.
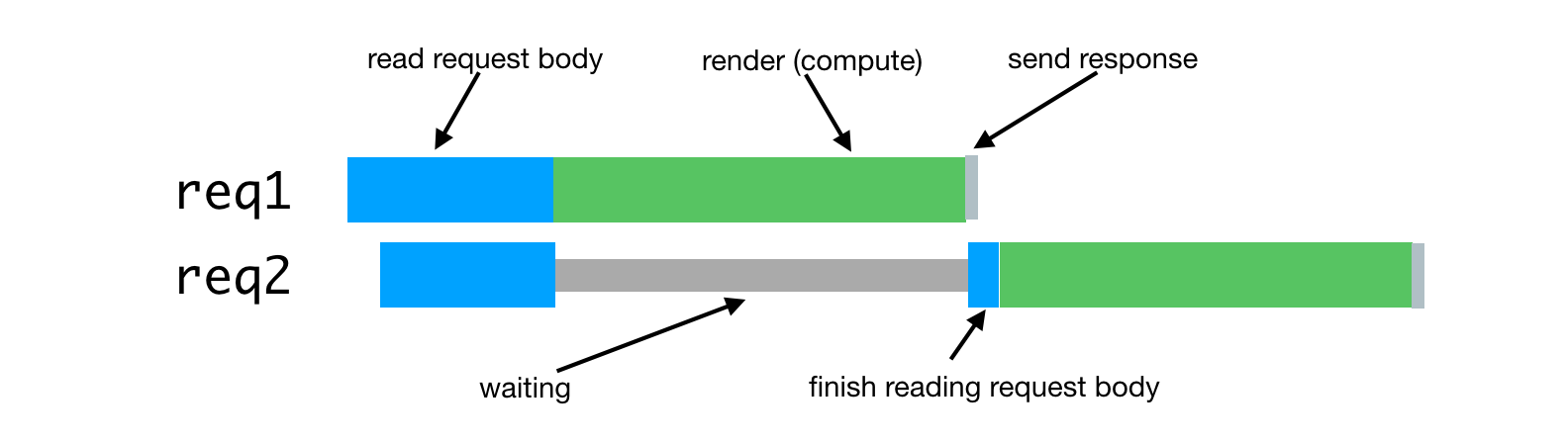
Processing simultaneously received requests
In practice, processing a request often consists of a set of asynchronous phases, even if they imply a serious computational load on the system. This can lead to an even more difficult situation with the alternation of tasks for processing such requests.
Assume our queries consist of a chain of tasks-like here such:

Processing requests that came with a small interval, the problem of struggling for processor resources
In this case, the processing of each request takes about two times longer than the processing of a separate request. As the number of requests processed simultaneously increases, the situation becomes even worse.
In addition, one of the typical goals of an SSR implementation is the ability to use the same or very similar code on both the client and the server. The major difference between these environments is that the client environment is essentially the environment in which one client works, and the server environment, by its nature, is a multi-client environment. What works well on the client, such as singletons or other approaches to storing the global state of the application, leads to errors, data leaks, and, in general, to confusion, while simultaneously processing multiple requests to the server.
These features become problems in situations where you need to simultaneously process multiple requests. Everything usually works quite normally under lower loads in a cozy environment of the development environment, which is used by one client in the person of a programmer.
This leads to a situation that is very different from the classic examples of Node.js applications. It should be noted that we use the JavaScript runtime for the rich set of libraries available in it, and because it is supported by browsers, and not for its simultaneous data processing model. In this application, the asynchronous model of simultaneous data processing demonstrates all its shortcomings, which are not compensated by advantages, which are either very few or not at all.
Our new rendering service, Hyperloop, will be the main service with which users of the Airbnb site will interact. As a result, its reliability and performance play a crucial role in ensuring the convenience of working with the resource. By implementing Hyperloop in production, we take into account the experience that we gained while working with our earlier server rendering system, Hypernova .
Hypernova does not work like our new service. This is a pure rendering system. It is called from our monolithic Rail service, called Monorail, and returns only HTML fragments for specific rendered components. In many cases, this “fragment” is the lion’s share of a page, and Rails provides only the page layout. With legacy technology, parts of the page can be linked together using ERB. In any case, however, Hypernova does not load any data needed to form a page. This is a Rails task.
Thus, Hyperloop and Hypernova have similar performance characteristics related to computing. At the same time, Hypernova, as a production service that processes significant amounts of traffic, provides a good field for testing, leading to an understanding of how the Hypernova replacement will behave in combat conditions.
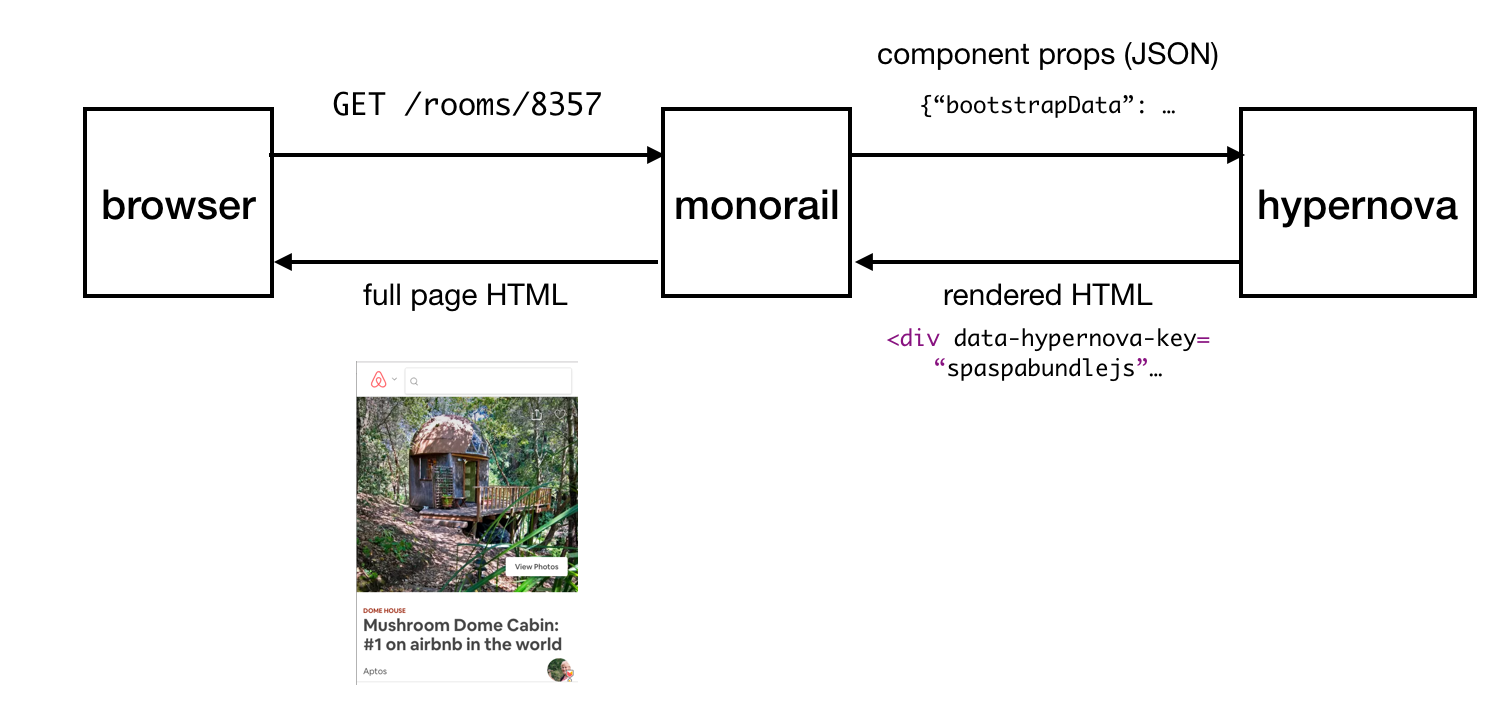
Hypernova work scheme
This is how Hypernova works. User requests come to our main Rails application, Monorail, which collects the properties of React components that need to be displayed on a page and makes a request to Hypernova, passing these properties and component names. Hypernova renders the components with properties in order to generate the HTML code that needs to be returned to the Monorail application, which then inserts this code into the page template and sends it all back to the client.
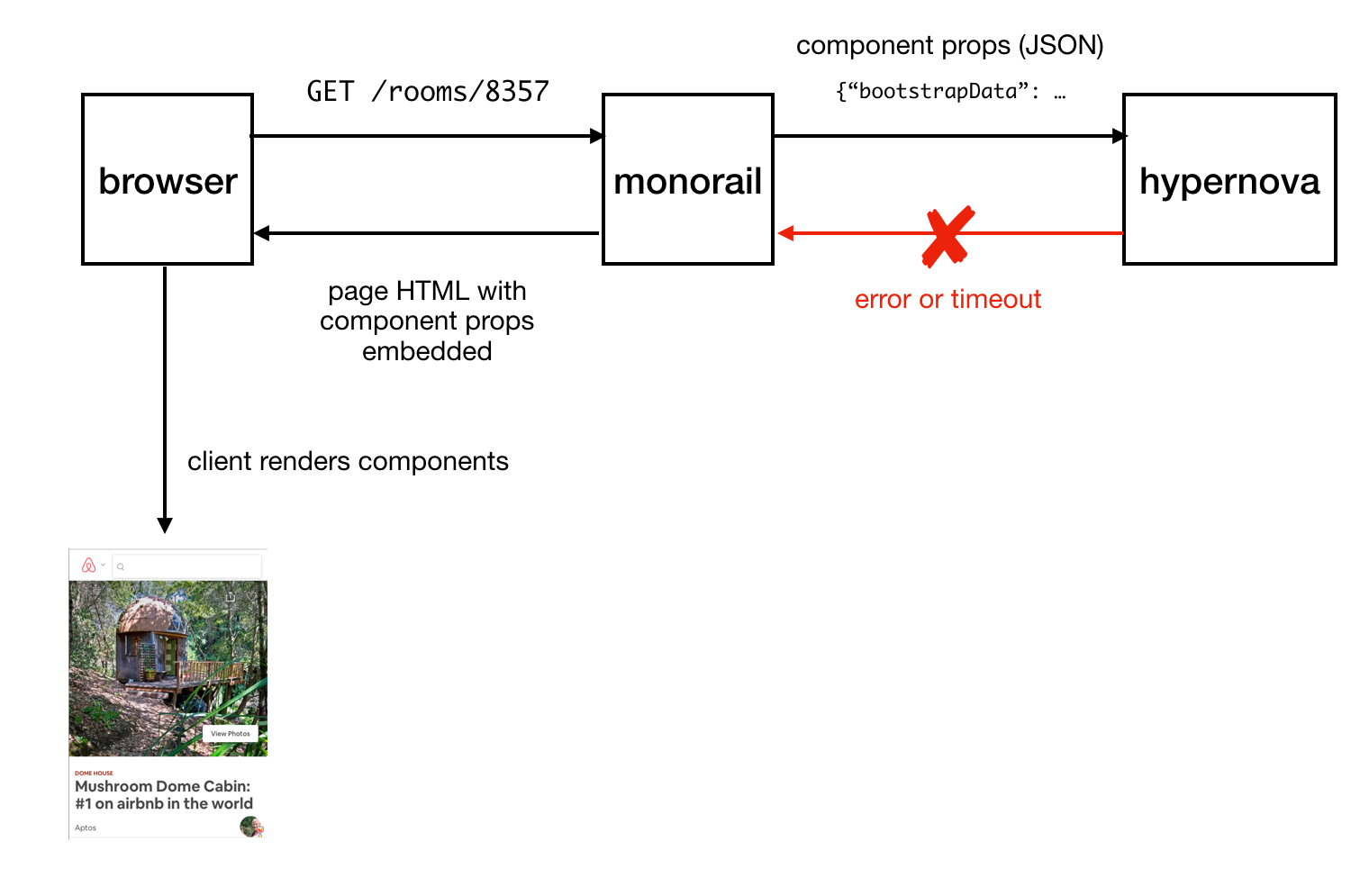
Sending the finished page to the client
In the event of an emergency situation (it may be an error or timeout waiting for a response) in Hypernova, there is a fallback option, using which components and their properties are embedded in the page without HTML generated on the server, after which all of this is sent to the client and it is already rendered there, we hope, successfully. This led us to not considering Hypernova as a critical part of the system. As a result, we could allow the occurrence of a certain number of failures and situations in which timeout is triggered. Adjusting the request timeouts, we, based on observations, set them at about the level of P95. As a result, it is not surprising that the system worked with a basic timeout rate of less than 5%.
In situations where traffic reaches peak values, we could see that up to 40% of requests to Hypernova are closed by timeouts in Monorail. On the Hypernova side, we saw peaks of
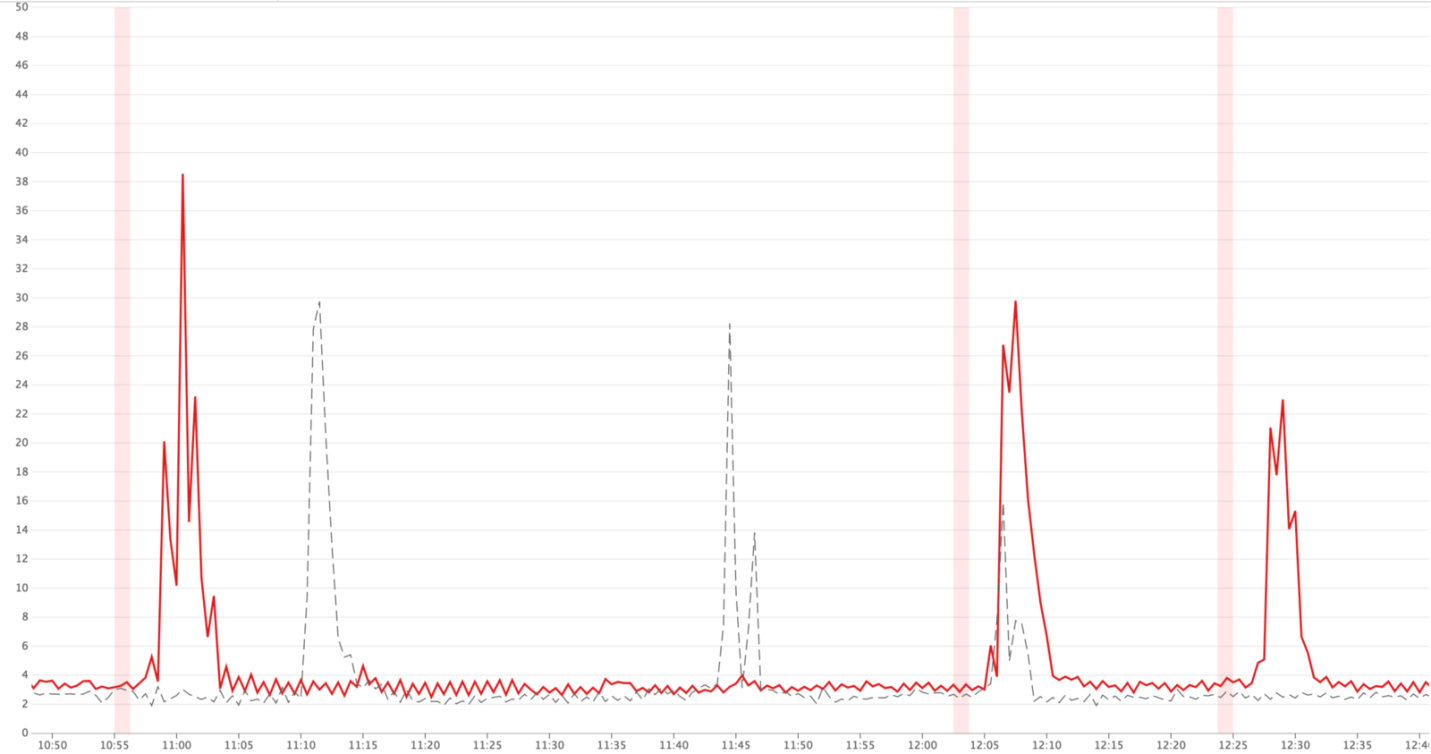
Peak timeout response values (red lines)
Since our system could work without Hypernova, we didn’t pay much attention to these features, they were perceived as annoying little things, and not as serious problems. We explained these problems by the features of the platform, by the fact that the launch of the application is slow due to the rather heavy initial garbage collection operation, due to the peculiarities of compiling code and caching data, and for other reasons. We hoped that the new React or Node releases would include performance improvements that would mitigate the disadvantages of slow service startup.
I suspected that what was happening was very likely the result of poor load balancing or a consequence of problems in the deployment of a solution when increasing delays were manifested due to excessive computational load on the processes. I added an auxiliary layer to the system to log information about the number of requests processed simultaneously by separate processes, as well as to record cases in which the process received more than one request.

Results of the study
We considered the delay in the service to be the culprit for the delays, and in fact the problem was caused by parallel requests competing for CPU time. According to the measurement results, it turned out that the time spent by the request while waiting for the completion of processing other requests corresponds to the time spent processing the request. In addition, this meant that the increase in delays due to simultaneous processing of requests looks the same as an increase in delays due to an increase in the computational complexity of the code, which leads to an increase in the load on the system when processing each request.
This, moreover, made it more obvious that the error

Error caused by disconnection of the client who did not wait for an answer.
We decided to deal with this problem, using a couple of standard tools, in which we had considerable experience. This is a reverse proxy server ( nginx ) and a load balancer ( HAProxy ).
In order to take advantage of the multi-core processor architecture, we run several Hypernova processes using the built-in Node.js cluster module . Since these processes are independent, we can simultaneously handle simultaneously incoming requests.

Parallel processing of requests that arrive at the same time.
The problem here is that each Node process turns out to be fully occupied during the entire processing time for a single request, including reading the request body sent from the client (Monorail plays a role in this case). Although we can read many queries in parallel in a single process, this, when it comes to rendering, leads to alternation of computational operations.
Node process resource utilization is tied to client and network speed.
As a solution to this problem, consider a buffering reverse proxy server that will allow you to maintain communication sessions with clients. The inspiration for this idea was the unicorn web server that we use for our Rails applications.The principles declared by unicorn perfectly explain why this is so. For this purpose we used nginx. Nginx reads the request coming from the client into the buffer, and sends the request to the Node server only after it has been completely read. This data transfer session runs on a local machine, through a loopback interface, or using Unix domain sockets, and this is much faster and more reliable than data transfer between individual computers.
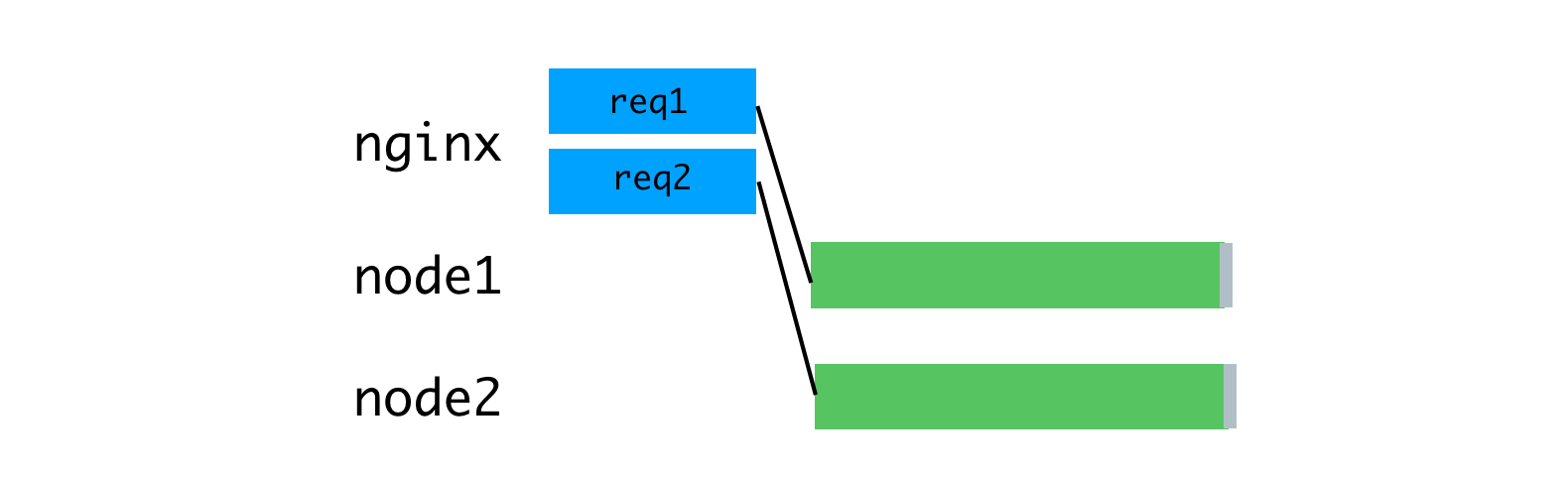
Nginx buffers requests, after which it sends them to the Node server.
Due to the fact that nginx is now engaged in reading requests, we were able to achieve a more even load on Node processes.
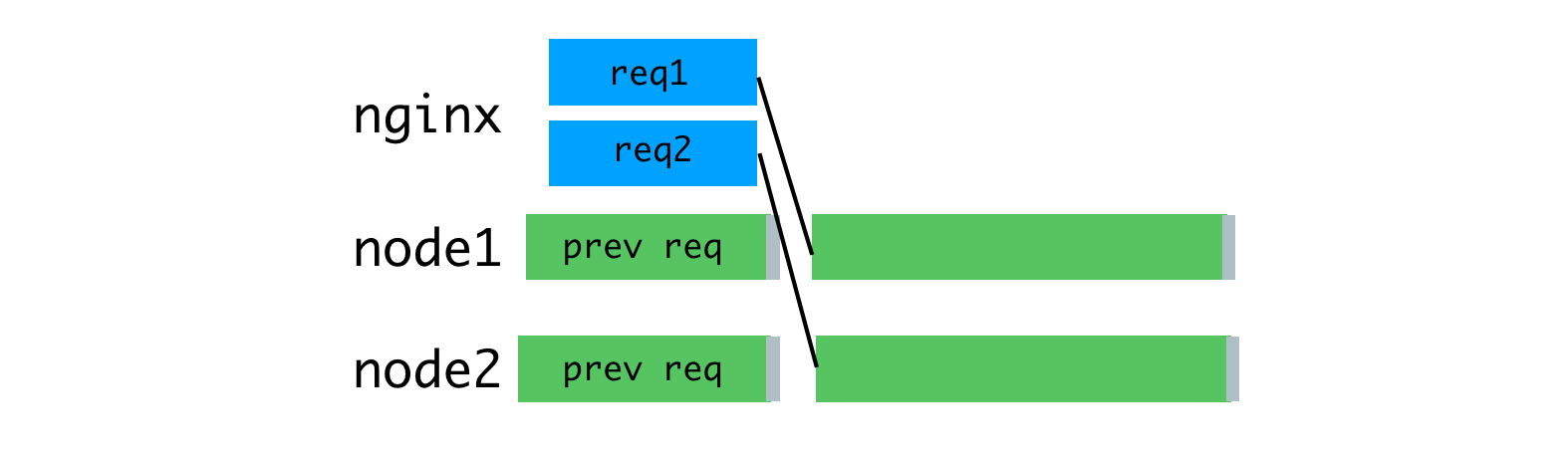
Uniform loading of processes through the use of nginx
In addition, we used nginx to process some requests that do not require access to Node processes. The discovery and routing layer of our service uses requests that do not create a large load on the system to
The next improvement concerns load balancing. We need to make thoughtful decisions about the distribution of requests between Node-processes. Module
The module
The round-robin algorithm is good when there is a low variability in query latency. For example, in the situation illustrated below.
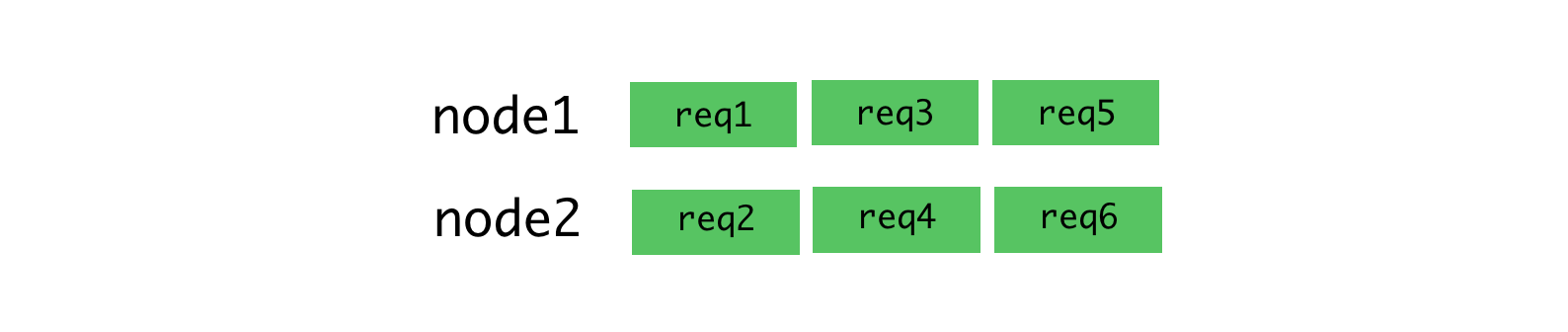
The round-robin algorithm and connections for which requests are stably received.
This algorithm is no longer so good when it comes to processing requests of different types, which can take quite different amounts of time to process. The most recent request sent to a certain process is forced to wait for the completion of processing all requests sent earlier, even if there is another process that has the ability to process such a request.
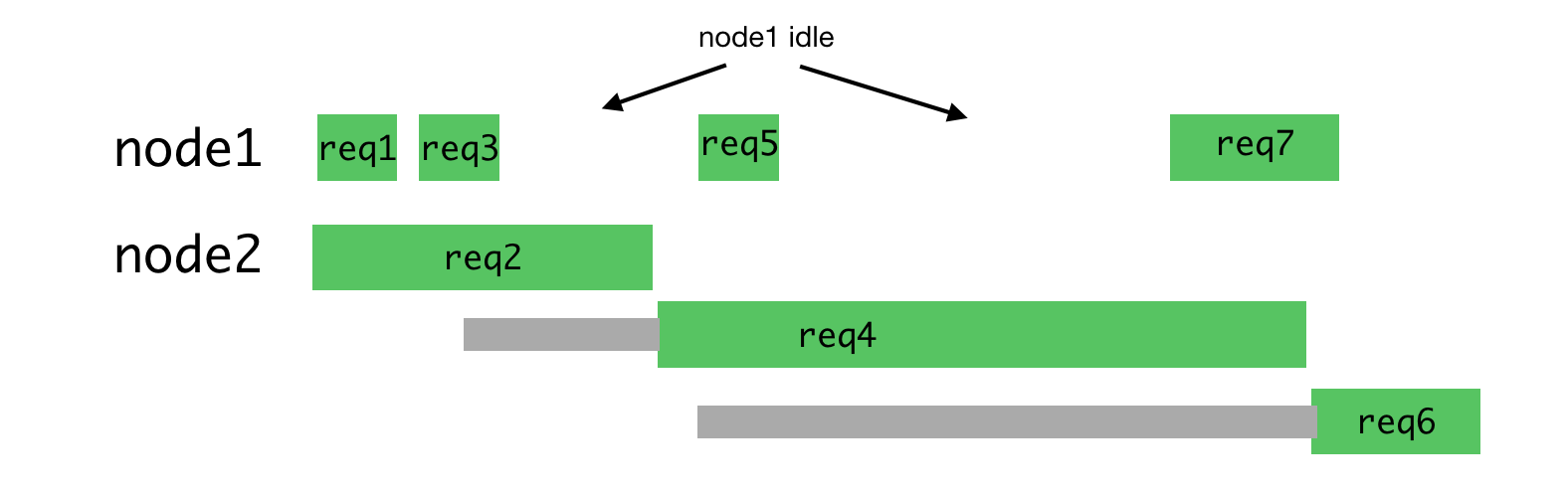
Uneven load on the processes
If you distribute the requests shown above more rationally, you get something like the one shown in the figure below.
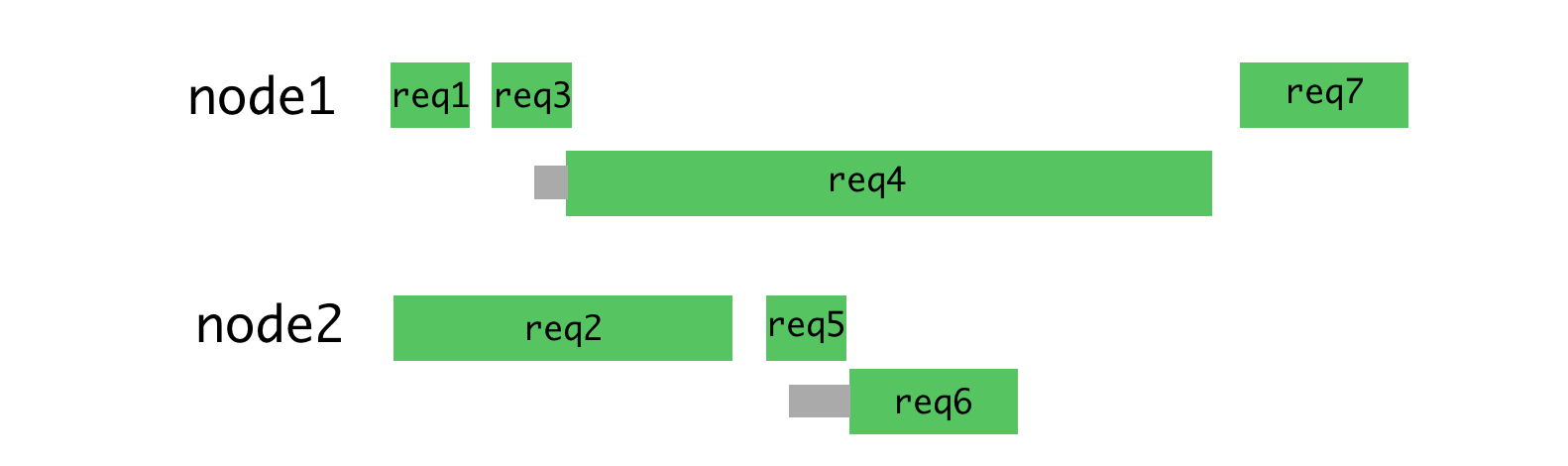
Rational distribution of requests by threads
With this approach, waiting is minimized and it becomes possible to quickly send responses to requests.
You can achieve this by placing requests in a queue, and assigning them to a process only when it is not busy processing another request. For this purpose we use HAProxy.
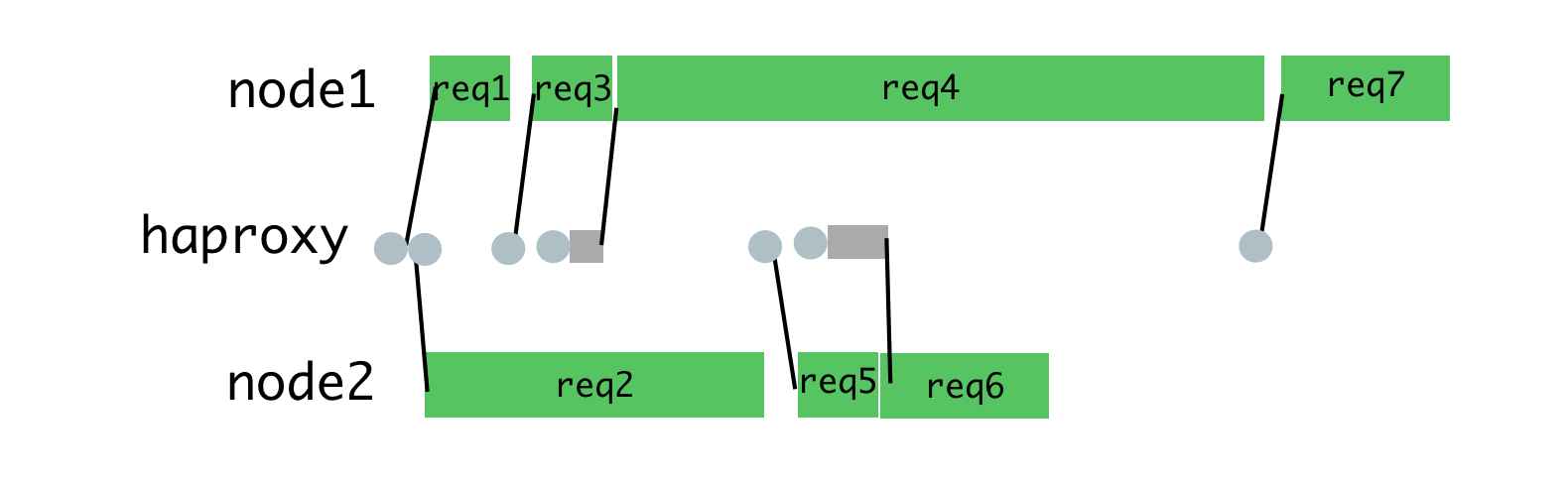
HAProxy and process load balancing
When we used HAProxy to balance the load on Hypernova, we completely eliminated timeout peaks, as well as errors
Simultaneous requests were also the main cause of delays during normal operation; this approach reduced such delays. One of the consequences of this is that now only 2% of requests were closed by timeout, not 5%, with the same timeout settings. The fact that we managed to move from a situation with 40% of errors to a situation with timeout in 2% of cases showed that we are moving in the right direction. As a result, today our users see the loading screen of the website much less often. It should be noted that the stability of the system will be of particular importance for us with the expected transition to a new system that does not have the same backup mechanism as Hypernova has.
In order for all this to work, you need to configure nginx, HAProxy and Node-application. Here is an example of a similar application using nginx and HAProxy, by analyzing which, you can understand the device of the system in question. This example is based on the system that we use in production, but it is simplified and modified so that it can be performed in the foreground on behalf of an unprivileged user. In production, everything should be configured using some kind of supervisor (we use runit, or, increasingly, kubernetes).
The nginx configuration is fairly standard, using the server listening on port 9000, configured to proxying requests to the HAProxy server, which listens on port 9001 (in our configuration, we use Unix domain sockets).
In addition, this server intercepts requests to the endpoint
Node.js module
In the HAProxy settingsIt is indicated that the proxy listens to port 9001 and redirects traffic to four workflows that listen to ports 9002 to 9005. The most important parameter here is
HAProxy start page HAProxy
keeps track of the current number of open connections between it and each of the worker processes. It has a limit set by property
Probably, the configuration considered here is very close to what you would like to receive from such a system. There are other interesting options (as well as the standard settings). In the process of preparing this configuration, we conducted many tests, both in normal and in anomalous conditions, and used the values obtained on the basis of these tests. I must say that this may lead us into the jungle of server configuration and is not absolutely necessary for understanding the system described here, but we will talk about this in the next section.
Much of our system depends on the proper operation of HAProxy. The system would not be of particular benefit to us if it did not process incoming requests at the same time as we would expect if it were not correctly distributed among work processes or it would not be so queued. In addition, it was important for us to understand how different types of failures are handled (or not handled). We needed confidence in the fact that the new system is a suitable replacement for the existing one based on the module
During the tests, we used the utility
In our configuration, 15 workflows were used instead of 4 from the example application, and we ran
The first set of tests was an imitation of the usual operation of the system, in general, nothing particularly interesting happened here. The next set of tests was carried out after an accurate restart of all the processes, as would happen when the system was deployed. When executing the last set of these tests, I randomly stopped some processes, imitating the situation of uncaught exceptions that would stop these processes. In addition, we had some problems associated with infinite loops in the application code, we investigated these problems.
Tests helped shape the configuration, as well as better understand the features of our system.
In normal operation, the parameter
We did not use HTTP or TCP performance monitoring on backends, since we found that this was more of a problem than a good. There was a feeling that the monitoring does not take into account the parameter
We found that the health checks are not sufficiently manageable to use them, in our case, and decided to avoid unpredictable situations involving the use of overlapping health check modes.
Here are the connection errors - this is what we could work with. We applied the parameter
This only applies to connections rejected because the corresponding service did not listen on its port. Connection timeout in this situation is not particularly useful, since we work in a local network. We initially expected to be able to set a short connection timeout to protect against processes that fell into an infinite loop. We set the timeout to 100 ms and were surprised when our requests were completed by timeout after 10 seconds, which was determined by other parameters set at that time. At the same time, control was not returned to the event loop, which did not allow accepting new connections. This is due to the fact that the kernel considers the connection established from the client’s point of view before the
An interesting side effect of this is that even setting the queue limit for incoming connections (backlog ) does not lead to the fact that connections are no longer established. The queue length is determined after the response of the SYN-ACK server ( this is actually implemented in such a way that the server does not pay attention to the ACK response from the client). The consequence of this system behavior is that a request with an already established connection cannot be re-dispatched, since we have no way of knowing whether the request has processed the backend or not.
Another interesting result of our tests, concerning the study of processes that fell into an infinite loop, was that timeouts lead to unexpected system behavior. When a request is sent to a process leading to its falling into an infinite loop, the backend connection count is set to 1. Thanks to the parameter
In addition, we found a rather unsightly situation arising from a high load. If the workflow fails (this should happen extremely rarely) at a time when the server constantly has a queue of requests, attempts will be made to send requests to the stopped backend, but the connection cannot be established because there is no connection waiting on this backend . Then HAProxy will redirect the request to the next backend with an open connection slot, which will be the same backend that you just could not access (since all other backends are processing requests). During such calls to an idle server, the limit of the repeated requests will be reached very quickly, which will lead to a request rejection, because the connection error messages are issued much faster, What is HTML rendering? The process will continue to try to give the non-working backend other requests that are in the queue, and this will happen before the queue is empty. This is bad, but it is mitigated by the rarity of the emergency termination of processes, the rarity of the presence of a constantly filled queue of requests (if requests are constantly queued, this means that there are not enough servers in the system). In our particular case, a malfunctioning service will attract the attention of the health monitoring system, which will quickly find out that it is unsuitable for processing new requests and will notice this accordingly. There is little good, but it at least minimizes the risk. In the future, this can be fought through deeper HAProxy integration,
Another change worth noting is that
In addition, we found that setting a parameter
And finally, setting the Node parameter can be useful here.
This can be achieved by implementing a separate queue for each process, as it is done, for example, here .
Using server rendering on Node.js means an increased computational load on the system. Such a load differs from the traditional one, mainly related to the processing of I / O operations. It is in such situations that the Node.js platform performs best. In our case, we, trying to achieve high performance of the server part of the application, faced a number of problems that we managed to solve by working on the system architecture and using auxiliary mechanisms such as nginx and HAProxy.
We hope that the experience of Airbnb will be useful to anyone who uses Node.js for solving server rendering tasks.
Dear readers! Do you use server rendering in your projects?

Node.js platform
Reflecting on the Node.js platform, you can draw in your imagination how an application built using the asynchronous data processing capabilities of this platform quickly and efficiently serves hundreds or thousands of parallel connections. The service pulls out the data it needs from everywhere and processes it a little to match the needs of a huge number of customers. The owner of such an application has no reason to complain, he is confident in the lightweight model of simultaneous data processing used by him (in this material we use the word "simultaneous" to convey the term "concurrent", for the term "parallel" - "parallel"). She perfectly solves her task.
Server-side rendering (SSR, Server Side Rendering) changes the basic ideas leading to a similar vision of the issue. So, server rendering requires large computational resources. The code in the Node.js environment is executed in one thread, as a result, to solve computational problems (as opposed to input / output tasks), the code can be executed simultaneously, but not in parallel. The Node.js platform is capable of handling a large number of parallel I / O operations; however, when it comes to calculations, the situation changes.
Since, when using server rendering, the computational part of the request processing task is increased compared to the I / O part of the task, simultaneously incoming requests will affect the speed of the server response due to the fact that they are competing for processor resources. It should be noted that when using asynchronous rendering, the competition for resources is still present. Asynchronous rendering solves the problems of responsiveness of a process or browser, but does not improve the situation with delays or concurrency. In this article we will focus on a simple model that includes only computational loads. If we talk about a mixed load, which includes both input and output operations and calculations, simultaneously incoming requests will increase delays, but taking into account the advantages
Consider a view command
Promise.all([fn1, fn2]). If fn1or fn2are the promises resolved by the I / O subsystem, then during the execution of this command, parallel execution of operations can be achieved. It looks like this:Parallel execution of operations by means of I / O subsystem
if
fn1andfn2are they computing tasks performed thus:Performing computational tasks
One of the operations will have to wait for the completion of the second operation, since there is only one stream in Node.js.
In the case of server rendering, this problem occurs when the server process has to handle several simultaneous requests. The processing of such requests will be delayed until the requests received earlier are processed. Here's what it looks like.
Processing simultaneously received requests
In practice, processing a request often consists of a set of asynchronous phases, even if they imply a serious computational load on the system. This can lead to an even more difficult situation with the alternation of tasks for processing such requests.
Assume our queries consist of a chain of tasks-like here such:
renderPromise().then(out => formatResponsePromise(out)).then(body => res.send(body)). When a couple of such requests arrive in the system, with a small interval between them, we can observe the following picture.Processing requests that came with a small interval, the problem of struggling for processor resources
In this case, the processing of each request takes about two times longer than the processing of a separate request. As the number of requests processed simultaneously increases, the situation becomes even worse.
In addition, one of the typical goals of an SSR implementation is the ability to use the same or very similar code on both the client and the server. The major difference between these environments is that the client environment is essentially the environment in which one client works, and the server environment, by its nature, is a multi-client environment. What works well on the client, such as singletons or other approaches to storing the global state of the application, leads to errors, data leaks, and, in general, to confusion, while simultaneously processing multiple requests to the server.
These features become problems in situations where you need to simultaneously process multiple requests. Everything usually works quite normally under lower loads in a cozy environment of the development environment, which is used by one client in the person of a programmer.
This leads to a situation that is very different from the classic examples of Node.js applications. It should be noted that we use the JavaScript runtime for the rich set of libraries available in it, and because it is supported by browsers, and not for its simultaneous data processing model. In this application, the asynchronous model of simultaneous data processing demonstrates all its shortcomings, which are not compensated by advantages, which are either very few or not at all.
Lessons from the Hypernova project
Our new rendering service, Hyperloop, will be the main service with which users of the Airbnb site will interact. As a result, its reliability and performance play a crucial role in ensuring the convenience of working with the resource. By implementing Hyperloop in production, we take into account the experience that we gained while working with our earlier server rendering system, Hypernova .
Hypernova does not work like our new service. This is a pure rendering system. It is called from our monolithic Rail service, called Monorail, and returns only HTML fragments for specific rendered components. In many cases, this “fragment” is the lion’s share of a page, and Rails provides only the page layout. With legacy technology, parts of the page can be linked together using ERB. In any case, however, Hypernova does not load any data needed to form a page. This is a Rails task.
Thus, Hyperloop and Hypernova have similar performance characteristics related to computing. At the same time, Hypernova, as a production service that processes significant amounts of traffic, provides a good field for testing, leading to an understanding of how the Hypernova replacement will behave in combat conditions.
Hypernova work scheme
This is how Hypernova works. User requests come to our main Rails application, Monorail, which collects the properties of React components that need to be displayed on a page and makes a request to Hypernova, passing these properties and component names. Hypernova renders the components with properties in order to generate the HTML code that needs to be returned to the Monorail application, which then inserts this code into the page template and sends it all back to the client.
Sending the finished page to the client
In the event of an emergency situation (it may be an error or timeout waiting for a response) in Hypernova, there is a fallback option, using which components and their properties are embedded in the page without HTML generated on the server, after which all of this is sent to the client and it is already rendered there, we hope, successfully. This led us to not considering Hypernova as a critical part of the system. As a result, we could allow the occurrence of a certain number of failures and situations in which timeout is triggered. Adjusting the request timeouts, we, based on observations, set them at about the level of P95. As a result, it is not surprising that the system worked with a basic timeout rate of less than 5%.
In situations where traffic reaches peak values, we could see that up to 40% of requests to Hypernova are closed by timeouts in Monorail. On the Hypernova side, we saw peaks of
BadRequestError: Request abortedsmaller errors . These errors, in addition, existed in normal conditions, while in normal operation, due to the architecture of the solution, the other errors were not particularly noticeable.Peak timeout response values (red lines)
Since our system could work without Hypernova, we didn’t pay much attention to these features, they were perceived as annoying little things, and not as serious problems. We explained these problems by the features of the platform, by the fact that the launch of the application is slow due to the rather heavy initial garbage collection operation, due to the peculiarities of compiling code and caching data, and for other reasons. We hoped that the new React or Node releases would include performance improvements that would mitigate the disadvantages of slow service startup.
I suspected that what was happening was very likely the result of poor load balancing or a consequence of problems in the deployment of a solution when increasing delays were manifested due to excessive computational load on the processes. I added an auxiliary layer to the system to log information about the number of requests processed simultaneously by separate processes, as well as to record cases in which the process received more than one request.
Results of the study
We considered the delay in the service to be the culprit for the delays, and in fact the problem was caused by parallel requests competing for CPU time. According to the measurement results, it turned out that the time spent by the request while waiting for the completion of processing other requests corresponds to the time spent processing the request. In addition, this meant that the increase in delays due to simultaneous processing of requests looks the same as an increase in delays due to an increase in the computational complexity of the code, which leads to an increase in the load on the system when processing each request.
This, moreover, made it more obvious that the error
BadRequestError: Request abortedit was impossible to confidently explain the slow launch of the system. The error was based on the request body parsing code, and occurred when the client canceled the request before the server was able to read the request body completely. The client stopped working, closed the connection, depriving us of the data that is needed in order to continue processing the request. It’s much more likely that this was due to the fact that we started processing the request, after this the event loop turned out to be blocked by rendering for another request, and then we returned to the interrupted task in order to complete it, but the result was that the client , who sent us this request, has already disconnected, interrupting the request. In addition, the data transmitted in requests to Hypernova were quite voluminous, on average, in the region of several hundred kilobytes, and this, of course,Error caused by disconnection of the client who did not wait for an answer.
We decided to deal with this problem, using a couple of standard tools, in which we had considerable experience. This is a reverse proxy server ( nginx ) and a load balancer ( HAProxy ).
Reverse proxying and load balancing
In order to take advantage of the multi-core processor architecture, we run several Hypernova processes using the built-in Node.js cluster module . Since these processes are independent, we can simultaneously handle simultaneously incoming requests.
Parallel processing of requests that arrive at the same time.
The problem here is that each Node process turns out to be fully occupied during the entire processing time for a single request, including reading the request body sent from the client (Monorail plays a role in this case). Although we can read many queries in parallel in a single process, this, when it comes to rendering, leads to alternation of computational operations.
Node process resource utilization is tied to client and network speed.
As a solution to this problem, consider a buffering reverse proxy server that will allow you to maintain communication sessions with clients. The inspiration for this idea was the unicorn web server that we use for our Rails applications.The principles declared by unicorn perfectly explain why this is so. For this purpose we used nginx. Nginx reads the request coming from the client into the buffer, and sends the request to the Node server only after it has been completely read. This data transfer session runs on a local machine, through a loopback interface, or using Unix domain sockets, and this is much faster and more reliable than data transfer between individual computers.
Nginx buffers requests, after which it sends them to the Node server.
Due to the fact that nginx is now engaged in reading requests, we were able to achieve a more even load on Node processes.
Uniform loading of processes through the use of nginx
In addition, we used nginx to process some requests that do not require access to Node processes. The discovery and routing layer of our service uses requests that do not create a large load on the system to
/pingverify communication between the hosts. Processing all of this in nginx eliminates a significant source of additional (albeit small) load on Node.js processes. The next improvement concerns load balancing. We need to make thoughtful decisions about the distribution of requests between Node-processes. Module
clusterdistributes requests in accordance with the round-robin algorithm, in most cases with attempts to bypass processes that do not respond to requests. With this approach, each process receives a request in turn. The module
clusterdistributes connections, not requests, so all this does not work as we need. The situation gets worse when using permanent connections. Any permanent connection from a client is tied to a single specific workflow, which complicates the efficient distribution of tasks. The round-robin algorithm is good when there is a low variability in query latency. For example, in the situation illustrated below.
The round-robin algorithm and connections for which requests are stably received.
This algorithm is no longer so good when it comes to processing requests of different types, which can take quite different amounts of time to process. The most recent request sent to a certain process is forced to wait for the completion of processing all requests sent earlier, even if there is another process that has the ability to process such a request.
Uneven load on the processes
If you distribute the requests shown above more rationally, you get something like the one shown in the figure below.
Rational distribution of requests by threads
With this approach, waiting is minimized and it becomes possible to quickly send responses to requests.
You can achieve this by placing requests in a queue, and assigning them to a process only when it is not busy processing another request. For this purpose we use HAProxy.
HAProxy and process load balancing
When we used HAProxy to balance the load on Hypernova, we completely eliminated timeout peaks, as well as errors
BadRequestErrors.Simultaneous requests were also the main cause of delays during normal operation; this approach reduced such delays. One of the consequences of this is that now only 2% of requests were closed by timeout, not 5%, with the same timeout settings. The fact that we managed to move from a situation with 40% of errors to a situation with timeout in 2% of cases showed that we are moving in the right direction. As a result, today our users see the loading screen of the website much less often. It should be noted that the stability of the system will be of particular importance for us with the expected transition to a new system that does not have the same backup mechanism as Hypernova has.
Details about the system and its settings
In order for all this to work, you need to configure nginx, HAProxy and Node-application. Here is an example of a similar application using nginx and HAProxy, by analyzing which, you can understand the device of the system in question. This example is based on the system that we use in production, but it is simplified and modified so that it can be performed in the foreground on behalf of an unprivileged user. In production, everything should be configured using some kind of supervisor (we use runit, or, increasingly, kubernetes).
The nginx configuration is fairly standard, using the server listening on port 9000, configured to proxying requests to the HAProxy server, which listens on port 9001 (in our configuration, we use Unix domain sockets).
In addition, this server intercepts requests to the endpoint
/pingfor direct servicing of requests aimed at checking network connectivity. This configuration differs from our internal standard nginx configuration in that we have reduced the exponent worker_processesto 1, since one nginx process is more than enough to meet the needs of our only HAProxy process and Node application. In addition, we use large request and response buffers, since the properties of the components transmitted by Hypernova can be quite large (hundreds of kilobytes). You should choose the size of the buffers according to the size of your requests and responses. Node.js module
clusterdealt with load balancing and creating new processes. In order to switch load balancing on HAProxy, we needed to create a replacement for the part clusterthat deals with process management. The task of managing processes in our case is solved by the pool-hall . This is a system that uses its own approach to managing workflows, different from the one that it uses cluster, but it does not participate at all in load balancing. The example shows how pool-hallto start four workflows, each of which listens to its own port. In the HAProxy settingsIt is indicated that the proxy listens to port 9001 and redirects traffic to four workflows that listen to ports 9002 to 9005. The most important parameter here is
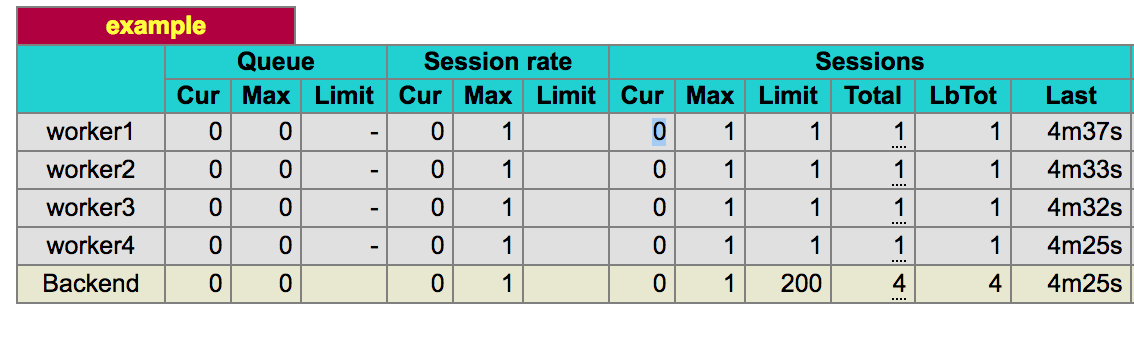
maxconn 1that defined for each workflow. It limits each of them to processing one request at a time. This can be seen on the HAProxy start page (it is available on port 8999).HAProxy start page HAProxy
keeps track of the current number of open connections between it and each of the worker processes. It has a limit set by property
maxconn. Routing is set tostatic-rr(static round-robin), as a result, as a rule, each worker process receives a request in turn. Due to the established limit, routing is performed on the basis of the round-robin algorithm, but if the number of requests to the workflow has reached the limit, the system, until it is released, does not assign it new requests. If all workflows are busy, the request is put in a queue and will be sent to the process that will be released first. We need exactly this behavior of the system.Probably, the configuration considered here is very close to what you would like to receive from such a system. There are other interesting options (as well as the standard settings). In the process of preparing this configuration, we conducted many tests, both in normal and in anomalous conditions, and used the values obtained on the basis of these tests. I must say that this may lead us into the jungle of server configuration and is not absolutely necessary for understanding the system described here, but we will talk about this in the next section.
Features of using HAProxy
Much of our system depends on the proper operation of HAProxy. The system would not be of particular benefit to us if it did not process incoming requests at the same time as we would expect if it were not correctly distributed among work processes or it would not be so queued. In addition, it was important for us to understand how different types of failures are handled (or not handled). We needed confidence in the fact that the new system is a suitable replacement for the existing one based on the module
cluster. In order to find out, we conducted a series of tests. During the tests, we used the utility
ab(Apache Benchmark) to execute 10,000 server requests. In different tests, these requests were distributed differently in time. To run the tests, the following command was used:ab -l -c <CONCURRENCY> -n 10000 http://<HOSTNAME>:9000/renderIn our configuration, 15 workflows were used instead of 4 from the example application, and we ran
abon a separate computer in order to avoid undesirable effects of the test on the system under test. We ran tests at low load ( concurrency=5), at high load ( concurrency=13), and at very high load, under which the system begins to use the request queue ( concurrency=20). In the latter case, the load is so high that it ensures the constant use of the request queue.The first set of tests was an imitation of the usual operation of the system, in general, nothing particularly interesting happened here. The next set of tests was carried out after an accurate restart of all the processes, as would happen when the system was deployed. When executing the last set of these tests, I randomly stopped some processes, imitating the situation of uncaught exceptions that would stop these processes. In addition, we had some problems associated with infinite loops in the application code, we investigated these problems.
Tests helped shape the configuration, as well as better understand the features of our system.
In normal operation, the parameter
maxconn 1manifests itself exactly as expected, limiting each process to processing one request at a time. We did not use HTTP or TCP performance monitoring on backends, since we found that this was more of a problem than a good. There was a feeling that the monitoring does not take into account the parameter
maxconn, although I did not check this in the code. We expected the system to behave in such a way that the process is either in good condition and able to handle requests, or does not listen on the port and instantly gives a connection error (here, however, there is one important exception).We found that the health checks are not sufficiently manageable to use them, in our case, and decided to avoid unpredictable situations involving the use of overlapping health check modes.
Here are the connection errors - this is what we could work with. We applied the parameter
option redispatchand used the installation retries 3, which allowed us to translate requests, when we tried to process which we received a connection error message, to another backend, which we could hope to process the request. Due to the speed of receiving messages about the rejection of the connection, we were able to maintain system performance.This only applies to connections rejected because the corresponding service did not listen on its port. Connection timeout in this situation is not particularly useful, since we work in a local network. We initially expected to be able to set a short connection timeout to protect against processes that fell into an infinite loop. We set the timeout to 100 ms and were surprised when our requests were completed by timeout after 10 seconds, which was determined by other parameters set at that time. At the same time, control was not returned to the event loop, which did not allow accepting new connections. This is due to the fact that the kernel considers the connection established from the client’s point of view before the
acceptserver calls it . An interesting side effect of this is that even setting the queue limit for incoming connections (backlog ) does not lead to the fact that connections are no longer established. The queue length is determined after the response of the SYN-ACK server ( this is actually implemented in such a way that the server does not pay attention to the ACK response from the client). The consequence of this system behavior is that a request with an already established connection cannot be re-dispatched, since we have no way of knowing whether the request has processed the backend or not.
Another interesting result of our tests, concerning the study of processes that fell into an infinite loop, was that timeouts lead to unexpected system behavior. When a request is sent to a process leading to its falling into an infinite loop, the backend connection count is set to 1. Thanks to the parameter
maxconnthis leads to the expected behavior of the system and does not allow other requests to fall into the same trap. The connection counter is reset to 0 after the timeout expires, which allows us to violate our rule that one process does not start processing a new request until it processes the previous request. This leads to incorrect processing of the next request coming in to the same process. When the client closes the connection by timeout or for some other reason, this does not affect the connection counter, we still have the same routing system running. The installation abortonclosereduces the connection count immediately after the client closes the connection. Given this, it is best to increase the timeouts and not includeabortonclose. More stringent timeouts can be installed on the client or on the nginx side.In addition, we found a rather unsightly situation arising from a high load. If the workflow fails (this should happen extremely rarely) at a time when the server constantly has a queue of requests, attempts will be made to send requests to the stopped backend, but the connection cannot be established because there is no connection waiting on this backend . Then HAProxy will redirect the request to the next backend with an open connection slot, which will be the same backend that you just could not access (since all other backends are processing requests). During such calls to an idle server, the limit of the repeated requests will be reached very quickly, which will lead to a request rejection, because the connection error messages are issued much faster, What is HTML rendering? The process will continue to try to give the non-working backend other requests that are in the queue, and this will happen before the queue is empty. This is bad, but it is mitigated by the rarity of the emergency termination of processes, the rarity of the presence of a constantly filled queue of requests (if requests are constantly queued, this means that there are not enough servers in the system). In our particular case, a malfunctioning service will attract the attention of the health monitoring system, which will quickly find out that it is unsuitable for processing new requests and will notice this accordingly. There is little good, but it at least minimizes the risk. In the future, this can be fought through deeper HAProxy integration,
Another change worth noting is that
server.closein Node.js it waits for the completion of existing requests, but everything in HAProxy's queue will not work properly, because the server does not know that it needs to wait for the completion of requests that it not yet received. In most cases, in order to cope with this problem, you need to set an adequate time between the moment when the instance stops receiving requests and the moment when the server restart process begins. In addition, we found that setting a parameter
balance firstby which most of the traffic is sent to the first available workflow (usually loadingworker1) reduces the delays in our application by about 15% and under synthetic, and under real load, if we compare the figures obtained using the parameter balance static-rr. This effect manifests itself in sufficiently long time intervals; it can hardly be simply explained by the “warming up” of the process. It lasts hours after the system starts. When more time passes (12 hours), performance deteriorates, probably due to memory leaks in intensively running processes. With this approach, in addition, the system reacts less flexibly to traffic peaks, since “cold” processes do not have enough time to “warm up”. We do not yet have a decent explanation for this phenomenon. And finally, setting the Node parameter can be useful here.
server.maxconnections, (it seemed to me that this is so), but we found that it, in fact, does not bear any particular benefit and sometimes leads to mistakes. This setting does not allow the server to accept more connections than specified inmaxconnection, closing any new handlers after it is detected that the specified limit is exceeded. This check is performed in JavaScript, so it does not protect against the case of an infinite loop (the request will complete correctly only after returning to the event loop). In addition, we saw connection errors caused by this setting during the normal operation of the system, even though there was no other evidence of processing multiple requests. We suspect that this is either a small problem with the timings, or the result of a difference of opinion between HAProxy and Node on the question of when the connection begins and when it ends. We support the desire to ensure that on the side of the application there would be reliable mechanisms for using singletones or other global repositories of the application state.This can be achieved by implementing a separate queue for each process, as it is done, for example, here .
Results
Using server rendering on Node.js means an increased computational load on the system. Such a load differs from the traditional one, mainly related to the processing of I / O operations. It is in such situations that the Node.js platform performs best. In our case, we, trying to achieve high performance of the server part of the application, faced a number of problems that we managed to solve by working on the system architecture and using auxiliary mechanisms such as nginx and HAProxy.
We hope that the experience of Airbnb will be useful to anyone who uses Node.js for solving server rendering tasks.
Dear readers! Do you use server rendering in your projects?