Serverless and React 2: sleight of hand and no fraud
Is it possible to simply tell front-end developers about the work of the “cloudless” Serverless architecture within AWS (Amazon Web Services)? Why not. Let's render a React / Redux application in the AWS architecture, and then talk about the pros and cons of AWS-lambda.
The material is based on the decoding of the report of Marina Mironovich from our spring conference HolyJS 2018 in St. Petersburg.
Officially Marina is the lead developer of EPAM. Now she works in a solution architect group for a customer and because of this she participates in a large number of projects. Therefore, it will be easier for us to outline the circle of its current interests than to list all the technologies with which it works.
 First of all, I am interested in all cloud technologies, in particular, AWS, because I work a lot in production with this. But I try to keep up with everything else.
First of all, I am interested in all cloud technologies, in particular, AWS, because I work a lot in production with this. But I try to keep up with everything else.
The frontend is my first love and it seems forever. In particular, I am currently working with React and React Native, so I know a little more about this. I also try to follow everything else. I am interested in everything related to documenting a project, for example, UML diagrams. Since I am in the solution architect group, I have to do this a lot.
I had an idea to talk about Serverless about a year ago. I wanted to talk about Serverless for front-end developers easily and naturally. So that you do not need any additional knowledge to use it, especially technologies now allow you to do it.
To some extent, the idea was implemented - I told about Serverlesson FrontTalks 2017. But it turned out that 45 minutes is not enough for a simple and understandable story. Therefore, the report was divided into two parts, and now the second “series” is before you. Who has not seen the first - do not worry, it does not hurt to understand what is written below. As in the decent series, I will start with a brief summary of the previous part. Then go to the juice itself - we will render a React / Redux application. And finally, I will talk about the pros and cons of cloud functions in principle (in particular, AWS-lambda) and what else can be done with them. I hope that this part will be useful to all those who are already familiar with AWS-lambda. Most importantly, the world does not end on Amazon, so let's talk about what else is in the area of cloud functions.
To render an application, I will use many Amazon services:
In fact, Serverless is a big deception, because of course there is a server: somewhere it all starts. But what happens there?
We write a function, and this function runs on the servers. Of course, it starts not just like that, but in some kind of container. And, actually, this function in the container on the server is called lambda.

In the case of lambda we can forget about the servers. I would even say this: when you write a lambda function, it’s bad to think about them. We work with a lambda not how we work with the server.
A logical question arises: if we do not have a server, how do we deploy it? There is SSH on the server, we uploaded the code, launched it - everything is fine. What to do with lambda?
Option 1. We can not deploy it
AWS in the console made for us a sweet and gentle IDE, where we can come and write a function right there.

It's cute, but not very expandable.
Option 2. We can make a zip and download it from the command line.
How do we make a zip file? If you use node_modules, all of this is stored in one archive. Further, depending on whether you are creating a new function or you already have such a function, you are doing either
What is the problem? First, the AWS CLI wants to know whether a function is being created or whether you already have one. These are two different teams. If you want to update not only the code, but also some attributes of this function, problems begin. The number of these commands is growing, and you need to sit with the directory and think about which command to use.
We can do it better and easier. We have frameworks for this.
There are a lot of such frameworks. This is primarily AWS CloudFormation, which works in conjunction with the AWS CLI. CloudFormation is a Json file describing your services. You describe them in a Json file, then the AWS CLI then says “execute” and it will automatically create everything for you in the AWS service.
But it is still difficult for such a simple task as rendering something. There is too much entry threshold - you need to read what structure CloudFormation has, etc.
Let's try to simplify. And here different frameworks appear: APEX, Zappa (only for Python), Claudia.js. I have listed only a few, randomly.
The problem and strength of these frameworks is that they are highly specialized. It means that they do some simple task very well. For example, Claudia.js is very good for creating a REST API. It will make the AWS call API Gateway, it will create a lambda for you, it will all beautifully work. But if you need to add a little more, problems begin - you have to add something, help, search, etc.
Zappa was written only for Python. And you want something more ambitious. And here comes Terraform and my love Serverless.
Serverless is somewhere in the middle between a very large CloudFormation, which can do almost everything, and these highly specialized frameworks. Almost everything can be deployed in it, but it is still quite easy to do. In addition, it has a very easy syntax.
Terraform - to some extent similar to CloudFormation. Terraform is open source, everything can be deployed in it - or almost everything. And when AWS creates services, you can add something new there. But he is big and complex.
To be honest, in production we use Terraform, because with Terraform everything that we have comes up easier - Serverless will not describe all this. But Terraform is very complicated. And when I write something for work, I first write it on Serverless, test it for performance and only after my configuration has been tested and worked out, I rewrite it to Terraform (this is “fun” for a couple of days).
Why I love Serverless?
Now I will show how it all really works. Over the next one and a half to two minutes we will be able to create a service that will render our HTML page.
First, I will launch the SLS Create template in the new folder: Serverless developers took care of us - they made it possible to create services from templates. In this case, I use a template that will create some files for me, such as the webpack configuration, package.json, some functions, and serverless.yml: I don't need all the functions. I will delete the first, rename the second one in holyjs: I’ll correct serveless.yml a bit, where I have a description of all the necessary services: Well, then I’ll fix the response that the function returns: I’ll make HTML “Hello HolyJS” and add the handle for rendering.




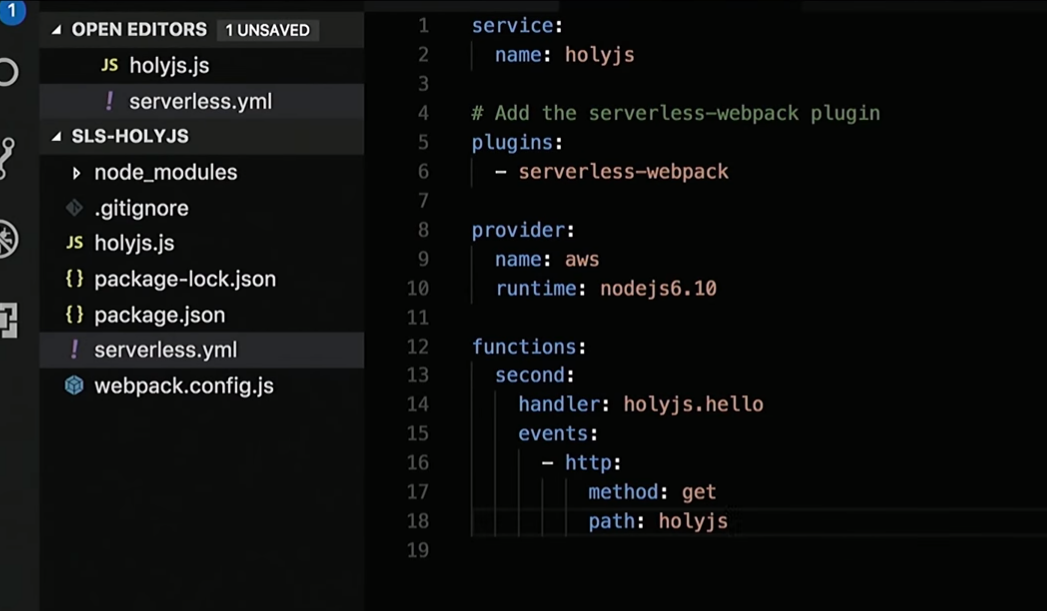

Next: And voila! There is a URL by which I can see in public access what is being rendered: Trust, but verify. I will go to the AWS Console and check that the holyjs function has been created for me: As you can see, Serverless will collect it using a webpack before it is closed. In addition, the rest of the infrastructure, which is described there - API Gateway, etc., will be created. When I want to delete it: All infrastructure, which is described in serverless.yml, will be removed. If someone lags behind the process described here, I invite you to simply review my previous report .

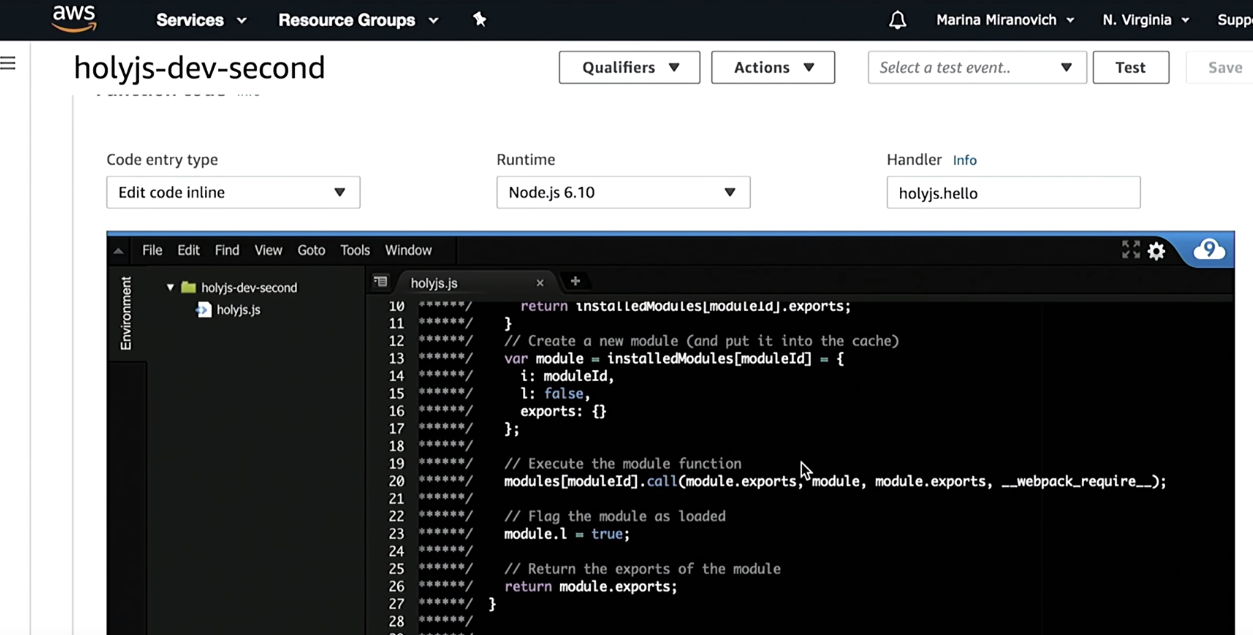

I mentioned that lambda can be run locally. There are two options to start.
Option 1. We simply run everything in the terminal.
We get what our function returns. Option 2. Run the lambda locally serverless-offline Do not forget, we make an isomorphic application, it will be HTML and CSS, so in the terminal it is somehow not very interesting to look at long HTML lines. There you can check that the function works. But I would like to launch and render it in a browser. Accordingly, I need a bunch of API gateway with lambda. To do this, there is a separate serverless-offline plugin, which will launch your lambda on any port (this is written), then output a URL in the terminal where you can access it.
The best part is that there is a hot reloading. That is, you write the function code, update your browser and update what the function returns. You do not need to restart everything.
This was a summary of the first part of the report. Now we come to the main part.
The project described below is already on GitHub. If you're interested, you can download the code there.
Let's start with how it all works.

Suppose there is a user - me.
Let's do a little code review of what I wrote.
If you go to GitHub, you will see the following file structure: All this is generated automatically in the React / Redux tool kit. In fact, here we will be interested in literally a couple of files and they will have to be corrected a little:
In order for us to gather everything on the server, we need to add another webpack.config:

This webpack.config will already be generated for you if you use the template. And there will automatically be a variable

We will need to render everything for the node (
We just add a couple of scripts - start and build have already been generated with React / Redux - nothing changes. Add a script to run the lambda, and a script to deploy the lambda.

A very small file - only 17 lines, all of them below:

What is interesting to us in it? First handler. The full path to the file (
If you really want, in one file you can register several handlers. There is also a path to the webpack, which should collect all this. In principle, everything: the rest is already generated automatically.
Here is a huge React / Redux application (in my case it is not huge - per page). In the additional lambda folder there is everything we need to render lambda:
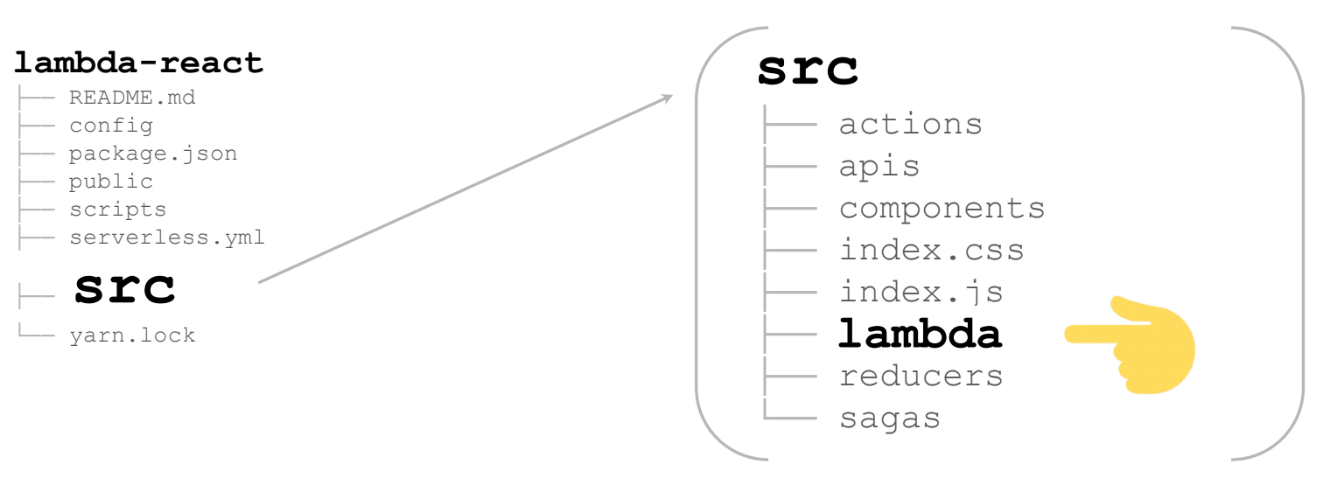
These are 2 files:
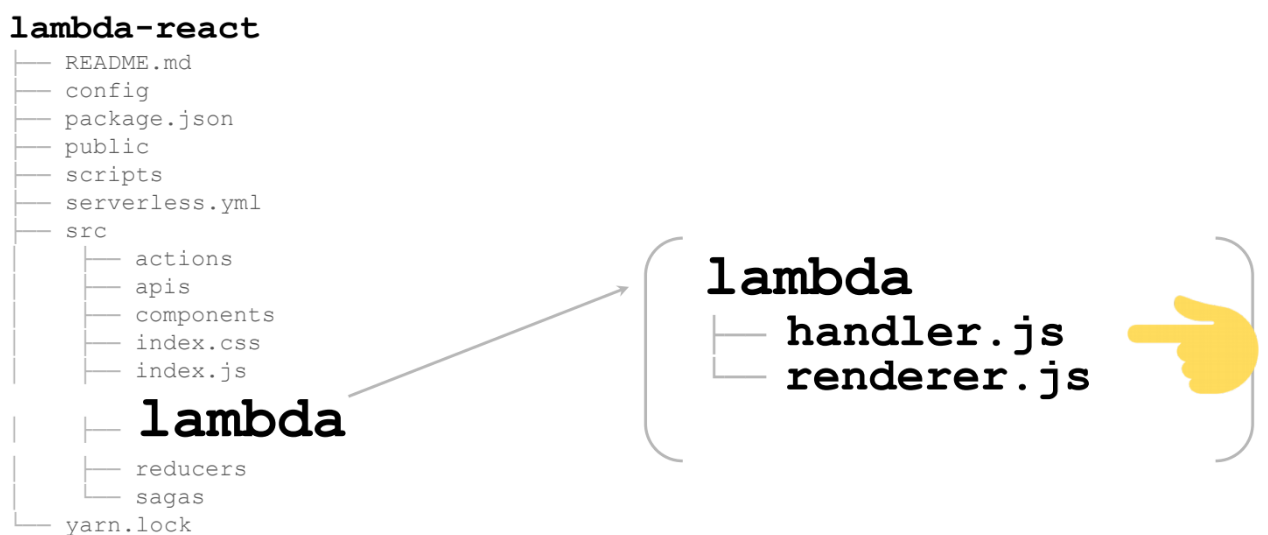
Let's start with the handler. The most important is the 13th line. This is the renderer, which is the very lambda that will be called in the clouds:

As you can see, the function
If we have no errors and exceptions, we call a function

Here the most interesting is the function

This function comes to us from renderer.js. Let's see what is there.
An isomorphic application is being rendered there. Moreover, it is rendered on any server - it does not matter here whether it is lambda or not.
I will not tell you in detail about what an isomorphic application is, how to render it, because this is a completely different topic, and there are people who told it better than me. Here are some tutorials that I found, just a few minutes googling:

If you know any other reports, you can advise, I will give them links on Twitter.
In order not to lose anyone, I will simply go over the tops, tell you what is happening there.
First of all, we need to render this into an HTML string with React / Redux.
This is done through the standard React method -

Next we need to render the styles so that we don’t blink content. This is not a very trivial task. There are several npm packages that solve it. For example, I used

If there are better packages - this is up to you.
Next we need to pass the Redux state. Once you render it on the server, you probably want to get some data, and you don’t want Redux to re-request it and re-render it. This is a fairly standard task. On the main Redux site, there are examples of how to do this: we create an object and then pass it through a global variable:

Now a little closer to the lambda.
It is necessary to do error handling. We want to catch everything and do something with them, at least stop the development of the lambda. For example, I did it through

Next, we need to substitute our URLs for static files. And for this we need to find out where the lambda is running - locally or somewhere in the clouds. How to find out?
We will do this through environment variables:
An interesting question: how are the environment variables configured in lambda. Really easy enough. In yml, you can

Well, and the bonus - after we have secured the lambda, we want to close all the static assets. To do this, we have already written a plugin where you can designate that S3-basket where you want to add something: In

total, we made an isomorphic application in about five minutes to show that all this is easy.
Now let's talk a little about the theory - about the pros and cons of lambda.
Let's start with the bad.
The downside may be (or maybe not) the time of a cold start. For example, for the lambda on Node.js, which we are writing now, the time for a cold start does not mean much.
The graph below shows the cold start time. And it can be a big deal especially for Java and C # (notice the orange dots) - you don't want five or six seconds for you to take just the beginning of the code.
For Node.js, the start time is almost zero - 30 - 50 ms. Of course, for someone this can also be a problem. But the functions can be reheated (although this is not the topic of this report). If someone is interested in how these tests were conducted, welcome to acloud.guru, they will tell you everything ( in the article ).

So what are the cons?
The code must be less than 50 MB. Is it possible to write such a large function? Please do not forget about node_modules. If you connect something, especially if there are binary files, you can really easily go over 50 MB, even for zip files. I had such cases. But this is an additional reason to see what you connect to the node_modules.
By default, the function is executed a second. If it does not end in a second, you will have a timeout. But this time can be increased in the settings. When creating a function, you can set the value to five minutes. Five minutes is a hard deadline. For the site is not a problem. But if you want to do something more interesting on lambdas, for example, image processing, translating text into sound or sound into text, etc., such calculations can easily take more than five minutes. And it will be a problem. What to do with it? Optimize or not use lambda.
Another interesting thing that arises in connection with the limitation on the execution time of the lambda. Recall the scheme of our site. Everything worked fine, until the product came and did not want to on the site real time feed - show news in real time. We know that this is implemented with WebSockets. But WebSockets don't work for five minutes, they have to be kept longer. And here the limit of five minutes becomes a problem.

A small note. For AWS, this is no longer a problem. They found how to get around this. But generally speaking, as soon as web sockets appear, lambda is not a solution for you. You need to go back to the good old server.
Above is a limit from 500 to 3000, depending on the region where you are. In my opinion, in Europe, almost everywhere 500. 3000 is supported in the United States.
If you have a busy site and you expect more than three thousand requests per minute (which is easy to imagine) this becomes a problem. But before we talk about this minus, let's talk a little bit about how the lambda scales.
We receive a request, and we have a lambda. While this lambda is being fulfilled, two more requests come to us - two more lambdas are being launched. People are starting to come to our website, requests appear and more and more lambdas are launched.

At the same time you pay for the time when lambda is performed. Suppose you pay one cent for one second of lambda execution. If you have 10 lambdas for a second, respectively, you will pay 10 cents for that second. If you have a million lambdas in a second, it will be about 10 thousand dollars. Unpleasant figure.
Therefore, AWS decided that they do not want to empty your wallet in a second if you did your tests incorrectly and start DDOS yourself, causing lambdas, or DDOS came you someone else. Therefore, a limit of three thousand was established - so that you have the opportunity to react to the situation.
If the load of 3000 requests is regular for you, you can write to AWS and they will raise the limit.
This is the last, again, controversial minus.
What is stateless? Here is a joke about goldfish - they just do not hold the context:

Lambda, called a second time, does not know anything about the first call.
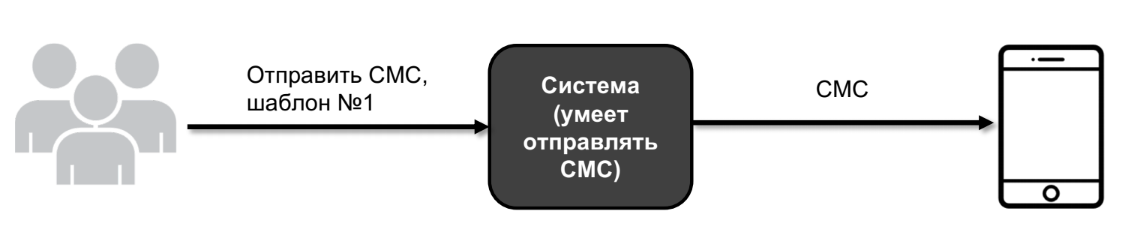
Let me show it with an example. Suppose I have a system - a big black box. And this system, among other things, is able to send SMS.
The user comes and says: send SMS template number 1. And the system sends it to a real device.
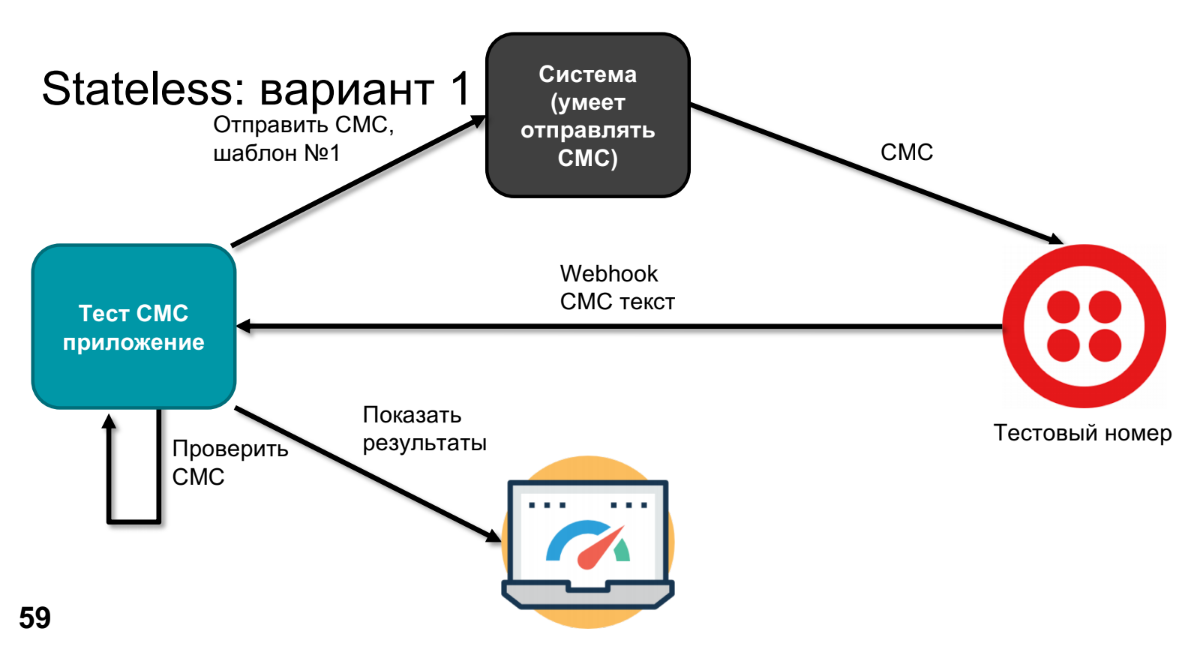
At some point, the product expresses a wish to find out what goes there and check that nothing has broken anywhere in this system. To do this, we will replace the real device with a test number - for example, Twilio can do it. He will call Webhook, send SMS text, we will process this SMS text in the application (we need to check that our template has become the correct SMS text).
To check, we need to know what was sent - we will do this through a test application. It remains to compare and display the results.
Let's try to do the same on lambda.
Lambda will send SMS, SMS will come to Twilio.
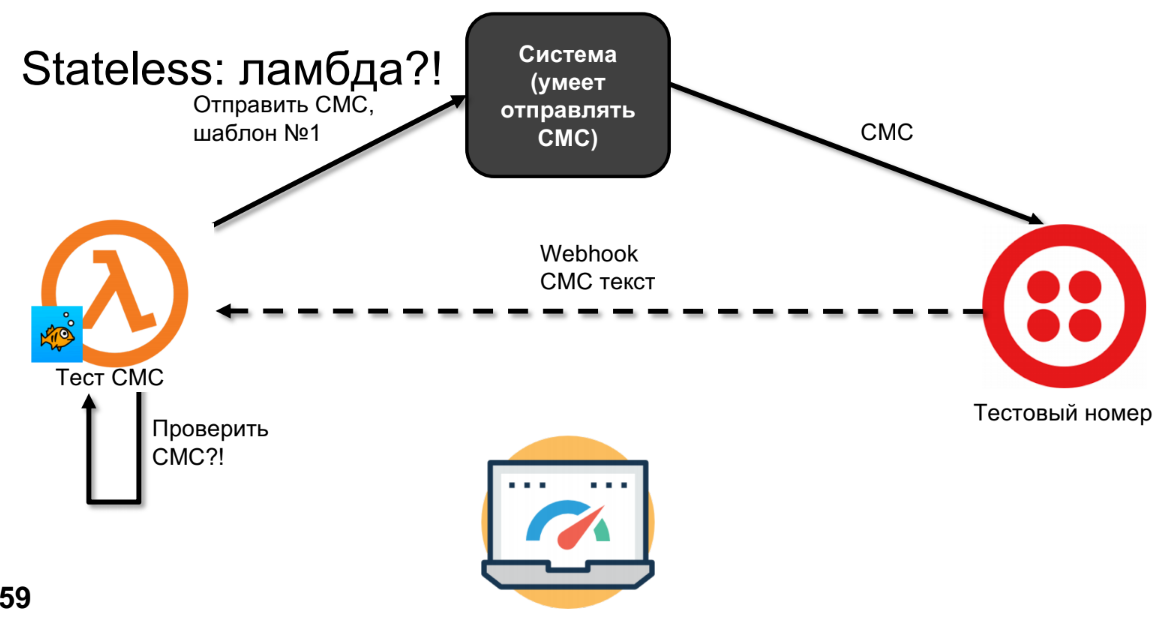
I drew a dotted line not by chance, because SMS can come back in minutes, hours or days - it depends on your operator, that is, it is not a synchronous call. By this time, lambda will forget everything, and we will not be able to check the SMS.
I would say that this is not a minus, but a feature. The scheme can be altered. There are several options to do this, I will offer my own. If we have stateless, and we want to save something, then we should definitely use the storage, for example, the database, S3, and anything that will store our context.
In the scheme with SMS storage will be sent to the test number. And when Webhook calls it - I suggest calling, for example, the second lambda, because this is a slightly different function. And the second lambda will already be able to go and retrieve from the database the SMS that went, check it and display the results.

Bingo!
At the very beginning, I said that you need to forget about the servers if you write lambda. I met people who write on node.js and are used to express servers. They like to rely on cash, and cash stays lambda. And sometimes, when they test, it will work, and sometimes not. How is this possible?
Suppose we have a server, and a container is started in it. Launching a container is quite an expensive operation. It is necessary, first, to make this container. Only after it is created will the function code be deployed there and can it be executed. After your function has completed, the container is not killed, because AWS thinks you can call this function again. AWS never wrote how long the container lives after the function has stopped. We did the experiments. In my opinion, for a node it is three minutes, for Java they can hold a container for 12-15 minutes. But this means that when the call to the next function comes, it will be called in the same container and in the same environment. If you use node cache somewhere, you create variables there, etc. - if you have not cleaned them, they will remain there. So if you write on lambda, you have to forget about the cache in general, otherwise you can get into unpleasant situations. It is difficult to otdebezhit.
They are smaller, but they seem to me more pleasant.
I gave a fairly standard example - I talked about rendering an isomorphic application, because mostly lambdas are thought of as a REST API. But I want to give a few more examples of what can be done with them, just to give you food for thought and fantasy.
In principle, you can do anything on lambdas ... with an asterisk.
Now besides Amazon, Google, Azure, IBM, Twillio - almost all large services want to implement cloud functions. If Roskomnadzor blocks everything, we start a small favorite server in our garage and deploy our cloud computing there. To do this, we need open source (especially since you have to pay for services, and open source is free). And open source does not stand still. They have already made an unreal number of implementations of all this. I will now say scary words for frontends - Dockers farm, Kubernetes - it all works that way.
The best part is that, firstly, the cloud functions are just as simple. If you had AWS or Lambda functions, it’s still as easy to convert them to open source.
Below are not all the development. I just chose a bigger and more interesting. The complete list is huge: a lot of startups are starting to work on this topic now:
I tried Fnproject and spent only a couple of hours to transfer this isomorphic application to Fnproject and run it locally with the Kubernetes container.
Still scaling fast. You will have a bunch of API Gateway (of course, without the rest of the services), but you still have the URL that causes the lambda. And in fact, almost everyone can forget about the servers, as promised, except for one person who will deploy this framework and set up this Kubernetes orchestra to be used so that happy developers can use it.
The material is based on the decoding of the report of Marina Mironovich from our spring conference HolyJS 2018 in St. Petersburg.
Officially Marina is the lead developer of EPAM. Now she works in a solution architect group for a customer and because of this she participates in a large number of projects. Therefore, it will be easier for us to outline the circle of its current interests than to list all the technologies with which it works.
First of all, I am interested in all cloud technologies, in particular, AWS, because I work a lot in production with this. But I try to keep up with everything else. The frontend is my first love and it seems forever. In particular, I am currently working with React and React Native, so I know a little more about this. I also try to follow everything else. I am interested in everything related to documenting a project, for example, UML diagrams. Since I am in the solution architect group, I have to do this a lot.
Part 1. Background
I had an idea to talk about Serverless about a year ago. I wanted to talk about Serverless for front-end developers easily and naturally. So that you do not need any additional knowledge to use it, especially technologies now allow you to do it.
To some extent, the idea was implemented - I told about Serverlesson FrontTalks 2017. But it turned out that 45 minutes is not enough for a simple and understandable story. Therefore, the report was divided into two parts, and now the second “series” is before you. Who has not seen the first - do not worry, it does not hurt to understand what is written below. As in the decent series, I will start with a brief summary of the previous part. Then go to the juice itself - we will render a React / Redux application. And finally, I will talk about the pros and cons of cloud functions in principle (in particular, AWS-lambda) and what else can be done with them. I hope that this part will be useful to all those who are already familiar with AWS-lambda. Most importantly, the world does not end on Amazon, so let's talk about what else is in the area of cloud functions.
What will i use
To render an application, I will use many Amazon services:
- S3 - this is, consider the file system in the clouds. There we will store static assets.
- IAM (access rights for users and services) - implicitly, but it will be used in the background so that the services communicate with each other.
- API Gateway (URL to access the site) - you will see the URL by which we can call our lambda.
- CloudFormation (for deployment) - will be used implicitly in the background.
- AWS Lambda - we came here for this.
What is serverless and what is AWS Lambda?
In fact, Serverless is a big deception, because of course there is a server: somewhere it all starts. But what happens there?
We write a function, and this function runs on the servers. Of course, it starts not just like that, but in some kind of container. And, actually, this function in the container on the server is called lambda.
In the case of lambda we can forget about the servers. I would even say this: when you write a lambda function, it’s bad to think about them. We work with a lambda not how we work with the server.
How to lambda
A logical question arises: if we do not have a server, how do we deploy it? There is SSH on the server, we uploaded the code, launched it - everything is fine. What to do with lambda?
Option 1. We can not deploy it
AWS in the console made for us a sweet and gentle IDE, where we can come and write a function right there.
It's cute, but not very expandable.
Option 2. We can make a zip and download it from the command line.
How do we make a zip file? If you use node_modules, all of this is stored in one archive. Further, depending on whether you are creating a new function or you already have such a function, you are doing either
zip -r build/lambda.zip index.js [node_modules/] [package.json]
aws lambda create-function...
aws lambda update-function-code...
What is the problem? First, the AWS CLI wants to know whether a function is being created or whether you already have one. These are two different teams. If you want to update not only the code, but also some attributes of this function, problems begin. The number of these commands is growing, and you need to sit with the directory and think about which command to use.
We can do it better and easier. We have frameworks for this.
AWS Lambda Framework
There are a lot of such frameworks. This is primarily AWS CloudFormation, which works in conjunction with the AWS CLI. CloudFormation is a Json file describing your services. You describe them in a Json file, then the AWS CLI then says “execute” and it will automatically create everything for you in the AWS service.
But it is still difficult for such a simple task as rendering something. There is too much entry threshold - you need to read what structure CloudFormation has, etc.
Let's try to simplify. And here different frameworks appear: APEX, Zappa (only for Python), Claudia.js. I have listed only a few, randomly.
The problem and strength of these frameworks is that they are highly specialized. It means that they do some simple task very well. For example, Claudia.js is very good for creating a REST API. It will make the AWS call API Gateway, it will create a lambda for you, it will all beautifully work. But if you need to add a little more, problems begin - you have to add something, help, search, etc.
Zappa was written only for Python. And you want something more ambitious. And here comes Terraform and my love Serverless.
Serverless is somewhere in the middle between a very large CloudFormation, which can do almost everything, and these highly specialized frameworks. Almost everything can be deployed in it, but it is still quite easy to do. In addition, it has a very easy syntax.
Terraform - to some extent similar to CloudFormation. Terraform is open source, everything can be deployed in it - or almost everything. And when AWS creates services, you can add something new there. But he is big and complex.
To be honest, in production we use Terraform, because with Terraform everything that we have comes up easier - Serverless will not describe all this. But Terraform is very complicated. And when I write something for work, I first write it on Serverless, test it for performance and only after my configuration has been tested and worked out, I rewrite it to Terraform (this is “fun” for a couple of days).
Serverless
Why I love Serverless?
- Serverless has a system that allows you to create plugins. In my opinion, this is salvation from everything. Serverless - open source. But adding something to open source is not always easy. You need to understand what is happening in the existing code, observe the guidelines, at least the codestyle, give PR to the PR, forget about this PR, and it will dust for three years. As a result, you forecause, and this will lie somewhere separately for you. All this is not very cool. But when there are plugins, everything is simplified. It is necessary to add something - you are creating a little plugin on your knee. To do this, you no longer need to understand what is happening inside Serverless (if this is not a super-custom question). You simply use an accessible API, save a plugin somewhere or deploy it for everyone. And everything works for you. In addition, there is already a large zoo of plugins and people who write these plugins. I.e,
- Serverless helps run lambda locally. A big minus of lambda is that AWS did not think about how we will debug it and test it. But Serverless allows you to run everything locally, see what happens (it even does it in conjunction with API Gateway).
Demonstration
Now I will show how it all really works. Over the next one and a half to two minutes we will be able to create a service that will render our HTML page.
First, I will launch the SLS Create template in the new folder: Serverless developers took care of us - they made it possible to create services from templates. In this case, I use a template that will create some files for me, such as the webpack configuration, package.json, some functions, and serverless.yml: I don't need all the functions. I will delete the first, rename the second one in holyjs: I’ll correct serveless.yml a bit, where I have a description of all the necessary services: Well, then I’ll fix the response that the function returns: I’ll make HTML “Hello HolyJS” and add the handle for rendering.
mkdir sls-holyjs
cd sls-holyjs
sls create --template aws-nodejs-ecma-script
npm install
nodejs-ecma-scriptls
Next: And voila! There is a URL by which I can see in public access what is being rendered: Trust, but verify. I will go to the AWS Console and check that the holyjs function has been created for me: As you can see, Serverless will collect it using a webpack before it is closed. In addition, the rest of the infrastructure, which is described there - API Gateway, etc., will be created. When I want to delete it: All infrastructure, which is described in serverless.yml, will be removed. If someone lags behind the process described here, I invite you to simply review my previous report .
sls deploy
sls remove
Launch lambda locally
I mentioned that lambda can be run locally. There are two options to start.
Option 1. We simply run everything in the terminal.
We get what our function returns. Option 2. Run the lambda locally serverless-offline Do not forget, we make an isomorphic application, it will be HTML and CSS, so in the terminal it is somehow not very interesting to look at long HTML lines. There you can check that the function works. But I would like to launch and render it in a browser. Accordingly, I need a bunch of API gateway with lambda. To do this, there is a separate serverless-offline plugin, which will launch your lambda on any port (this is written), then output a URL in the terminal where you can access it.
sls invoke local -f [fn_name]
sls offline --port 8000 start
The best part is that there is a hot reloading. That is, you write the function code, update your browser and update what the function returns. You do not need to restart everything.
This was a summary of the first part of the report. Now we come to the main part.
Part 2. Rendering with AWS
The project described below is already on GitHub. If you're interested, you can download the code there.
Let's start with how it all works.
Suppose there is a user - me.
- I open the site.
- At no URL, we are accessing the API gateway. I want to note that API Gateway is already an AWS service, we are already in the clouds.
- API Gateway will cause lambda.
- Lambda will render the site, and all this will return to the browser.
- The browser will start to render and realize that there are not enough static files. Then he will turn to the S3 bucket (our file system, where we will keep all the statics; in the S3 bucket you can put everything - fonts, images, CSS, JS).
- The data from the S3 bucket will return to the browser.
- The browser will render the page.
- Everyone is happy.
Let's do a little code review of what I wrote.
If you go to GitHub, you will see the following file structure: All this is generated automatically in the React / Redux tool kit. In fact, here we will be interested in literally a couple of files and they will have to be corrected a little:
lambda-react
README.md
config
package.json
public
scripts
serverless.yml
src
yarn.lock
- config
- package.json
- serverless.yml - because we will deploy,
- src - nowhere without it.
Let's start with the configuration
In order for us to gather everything on the server, we need to add another webpack.config:
This webpack.config will already be generated for you if you use the template. And there will automatically be a variable
slsw.lib.entriesthat will point to your lambda handlers. If you want, you can change it yourself by specifying something else. We will need to render everything for the node (
target: ‘node’). In principle, all other loaders remain the same as for the normal React application.Next in package.json
We just add a couple of scripts - start and build have already been generated with React / Redux - nothing changes. Add a script to run the lambda, and a script to deploy the lambda.
serverless.yml
A very small file - only 17 lines, all of them below:
What is interesting to us in it? First handler. The full path to the file (
src/lambda/handler) is written there and the handler function is specified through the dot. If you really want, in one file you can register several handlers. There is also a path to the webpack, which should collect all this. In principle, everything: the rest is already generated automatically.
The most interesting is src
Here is a huge React / Redux application (in my case it is not huge - per page). In the additional lambda folder there is everything we need to render lambda:
These are 2 files:
Let's start with the handler. The most important is the 13th line. This is the renderer, which is the very lambda that will be called in the clouds:
As you can see, the function
render ()returns a promise, from which you must catch all exceptions. This is a feature of the lambda, otherwise the lambda will not end immediately, but will work until the timeout. You will have to pay extra money for a code that has already fallen. To avoid this, it is necessary to finish the work of the lambda as early as possible - first of all, catch and handle all exceptions. Later we will come back to this.If we have no errors and exceptions, we call a function
createResponsethat takes literally five lines. We will simply add all headers so that it is rendered correctly in the browser: Here the most interesting is the function
renderthat will render our page: This function comes to us from renderer.js. Let's see what is there.
An isomorphic application is being rendered there. Moreover, it is rendered on any server - it does not matter here whether it is lambda or not.
I will not tell you in detail about what an isomorphic application is, how to render it, because this is a completely different topic, and there are people who told it better than me. Here are some tutorials that I found, just a few minutes googling:
If you know any other reports, you can advise, I will give them links on Twitter.
In order not to lose anyone, I will simply go over the tops, tell you what is happening there.
First of all, we need to render this into an HTML string with React / Redux.
This is done through the standard React method -
renderToString: Next we need to render the styles so that we don’t blink content. This is not a very trivial task. There are several npm packages that solve it. For example, I used
node-style-loaderthat will put everything in styleTag, and then you can paste it into HTML. If there are better packages - this is up to you.
Next we need to pass the Redux state. Once you render it on the server, you probably want to get some data, and you don’t want Redux to re-request it and re-render it. This is a fairly standard task. On the main Redux site, there are examples of how to do this: we create an object and then pass it through a global variable:
Now a little closer to the lambda.
It is necessary to do error handling. We want to catch everything and do something with them, at least stop the development of the lambda. For example, I did it through
promise: Next, we need to substitute our URLs for static files. And for this we need to find out where the lambda is running - locally or somewhere in the clouds. How to find out?
We will do this through environment variables:
…
const bundleUrl = process.env.NODE_ENV === 'AWS' ?
AWS_URL : LOCAL_URL;
An interesting question: how are the environment variables configured in lambda. Really easy enough. In yml, you can
environmentpass in any variables. When it comes, they will be available: Well, and the bonus - after we have secured the lambda, we want to close all the static assets. To do this, we have already written a plugin where you can designate that S3-basket where you want to add something: In
total, we made an isomorphic application in about five minutes to show that all this is easy.
Now let's talk a little about the theory - about the pros and cons of lambda.
Let's start with the bad.
Cons lambda functions
The downside may be (or maybe not) the time of a cold start. For example, for the lambda on Node.js, which we are writing now, the time for a cold start does not mean much.
The graph below shows the cold start time. And it can be a big deal especially for Java and C # (notice the orange dots) - you don't want five or six seconds for you to take just the beginning of the code.
For Node.js, the start time is almost zero - 30 - 50 ms. Of course, for someone this can also be a problem. But the functions can be reheated (although this is not the topic of this report). If someone is interested in how these tests were conducted, welcome to acloud.guru, they will tell you everything ( in the article ).
So what are the cons?
Function Code Size Limitations
The code must be less than 50 MB. Is it possible to write such a large function? Please do not forget about node_modules. If you connect something, especially if there are binary files, you can really easily go over 50 MB, even for zip files. I had such cases. But this is an additional reason to see what you connect to the node_modules.
Time limits
By default, the function is executed a second. If it does not end in a second, you will have a timeout. But this time can be increased in the settings. When creating a function, you can set the value to five minutes. Five minutes is a hard deadline. For the site is not a problem. But if you want to do something more interesting on lambdas, for example, image processing, translating text into sound or sound into text, etc., such calculations can easily take more than five minutes. And it will be a problem. What to do with it? Optimize or not use lambda.
Another interesting thing that arises in connection with the limitation on the execution time of the lambda. Recall the scheme of our site. Everything worked fine, until the product came and did not want to on the site real time feed - show news in real time. We know that this is implemented with WebSockets. But WebSockets don't work for five minutes, they have to be kept longer. And here the limit of five minutes becomes a problem.
A small note. For AWS, this is no longer a problem. They found how to get around this. But generally speaking, as soon as web sockets appear, lambda is not a solution for you. You need to go back to the good old server.
Number of parallel functions per minute
Above is a limit from 500 to 3000, depending on the region where you are. In my opinion, in Europe, almost everywhere 500. 3000 is supported in the United States.
If you have a busy site and you expect more than three thousand requests per minute (which is easy to imagine) this becomes a problem. But before we talk about this minus, let's talk a little bit about how the lambda scales.
We receive a request, and we have a lambda. While this lambda is being fulfilled, two more requests come to us - two more lambdas are being launched. People are starting to come to our website, requests appear and more and more lambdas are launched.
At the same time you pay for the time when lambda is performed. Suppose you pay one cent for one second of lambda execution. If you have 10 lambdas for a second, respectively, you will pay 10 cents for that second. If you have a million lambdas in a second, it will be about 10 thousand dollars. Unpleasant figure.
Therefore, AWS decided that they do not want to empty your wallet in a second if you did your tests incorrectly and start DDOS yourself, causing lambdas, or DDOS came you someone else. Therefore, a limit of three thousand was established - so that you have the opportunity to react to the situation.
If the load of 3000 requests is regular for you, you can write to AWS and they will raise the limit.
Stateless
This is the last, again, controversial minus.
What is stateless? Here is a joke about goldfish - they just do not hold the context:
Lambda, called a second time, does not know anything about the first call.
Let me show it with an example. Suppose I have a system - a big black box. And this system, among other things, is able to send SMS.
The user comes and says: send SMS template number 1. And the system sends it to a real device.
At some point, the product expresses a wish to find out what goes there and check that nothing has broken anywhere in this system. To do this, we will replace the real device with a test number - for example, Twilio can do it. He will call Webhook, send SMS text, we will process this SMS text in the application (we need to check that our template has become the correct SMS text).
To check, we need to know what was sent - we will do this through a test application. It remains to compare and display the results.
Let's try to do the same on lambda.
Lambda will send SMS, SMS will come to Twilio.
I drew a dotted line not by chance, because SMS can come back in minutes, hours or days - it depends on your operator, that is, it is not a synchronous call. By this time, lambda will forget everything, and we will not be able to check the SMS.
I would say that this is not a minus, but a feature. The scheme can be altered. There are several options to do this, I will offer my own. If we have stateless, and we want to save something, then we should definitely use the storage, for example, the database, S3, and anything that will store our context.
In the scheme with SMS storage will be sent to the test number. And when Webhook calls it - I suggest calling, for example, the second lambda, because this is a slightly different function. And the second lambda will already be able to go and retrieve from the database the SMS that went, check it and display the results.
Bingo!
At the very beginning, I said that you need to forget about the servers if you write lambda. I met people who write on node.js and are used to express servers. They like to rely on cash, and cash stays lambda. And sometimes, when they test, it will work, and sometimes not. How is this possible?
Suppose we have a server, and a container is started in it. Launching a container is quite an expensive operation. It is necessary, first, to make this container. Only after it is created will the function code be deployed there and can it be executed. After your function has completed, the container is not killed, because AWS thinks you can call this function again. AWS never wrote how long the container lives after the function has stopped. We did the experiments. In my opinion, for a node it is three minutes, for Java they can hold a container for 12-15 minutes. But this means that when the call to the next function comes, it will be called in the same container and in the same environment. If you use node cache somewhere, you create variables there, etc. - if you have not cleaned them, they will remain there. So if you write on lambda, you have to forget about the cache in general, otherwise you can get into unpleasant situations. It is difficult to otdebezhit.
Pluses lambda functions
They are smaller, but they seem to me more pleasant.
- First of all, we really forget that there is a server. As a developer, I write a function in javascript, and that's it. I am sure that many of you have written functions on javascript, you don’t need to know anything else about it.
- No need to think about the cache, nor about scaling, vertical or horizontal. What you wrote will work. It doesn’t matter whether one person comes to your site per month or there will be a million visits.
- In the case of AWS lambda, they already have their own integration with almost all of their servers (DynamoDB, Alexa, API Gateway, etc.).
What else can be done on lambdas?
I gave a fairly standard example - I talked about rendering an isomorphic application, because mostly lambdas are thought of as a REST API. But I want to give a few more examples of what can be done with them, just to give you food for thought and fantasy.
In principle, you can do anything on lambdas ... with an asterisk.
- HTTP Services is what I said. REST API, each endpoint API is one lambda. The match is just perfect. Especially considering how often enterprise uses node.js when creating middleware. We have java, which does the entire cost estimate, then we write a layer on js that handles requests very easily. It can be rewritten in lambda and will be even steeper.
- IoT - for example, at us Alexa runs a request to the server with some kind of file decryption, and your server is actually not a server, but a lambda.
- Chat Bots is almost the same as IoT.
- Image / Video conversions.
- Machine learning.
- Batch Jobs - due to the scaling of the lambdas, any Batch Job is just perfect for this.
Now besides Amazon, Google, Azure, IBM, Twillio - almost all large services want to implement cloud functions. If Roskomnadzor blocks everything, we start a small favorite server in our garage and deploy our cloud computing there. To do this, we need open source (especially since you have to pay for services, and open source is free). And open source does not stand still. They have already made an unreal number of implementations of all this. I will now say scary words for frontends - Dockers farm, Kubernetes - it all works that way.
The best part is that, firstly, the cloud functions are just as simple. If you had AWS or Lambda functions, it’s still as easy to convert them to open source.
Below are not all the development. I just chose a bigger and more interesting. The complete list is huge: a lot of startups are starting to work on this topic now:
- Iron functions
- Fnproject
- Openfaas
- Apache OpenWhisk
- Kubeless
- Fission
- Funktion
I tried Fnproject and spent only a couple of hours to transfer this isomorphic application to Fnproject and run it locally with the Kubernetes container.
Still scaling fast. You will have a bunch of API Gateway (of course, without the rest of the services), but you still have the URL that causes the lambda. And in fact, almost everyone can forget about the servers, as promised, except for one person who will deploy this framework and set up this Kubernetes orchestra to be used so that happy developers can use it.
Minute advertising. We recently announced the conference HolyJS 2018 Moscow, which will be held November 24-25 in Moscow. The site already has the first speakers and reports, as well as tickets for Early Bird-price.