Many hieroglyphs - many neural networks: how to build an effective recognition system for a large number of classes?
In previous articles, we have already written about how we have text recognition technology:
Approximately the same way, until 2018, recognition of Japanese and Chinese characters was arranged: primarily using raster and attribute classifiers. But with the recognition of hieroglyphs there are difficulties:

It is as difficult to say exactly how many characters Chinese characters have in writing as it is to accurately count how many words are in Russian. But most often in Chinese writing ~ 10,000 characters are used. We have limited the number of classes used in recognition.
Both problems described above also lead to the fact that in order to achieve high quality one has to use a large number of signs and these signs themselves are calculated on the images of symbols longer.
So that these problems did not lead to the strongest slowdowns in the entire recognition system, we had to use a lot of heuristics, primarily aimed at quickly cutting off a significant number of hieroglyphs, which this picture does not exactly look like. It still did not help to the end, but we wanted to bring our technologies to a qualitatively new level.
We began to investigate the applicability of convolutional neural networks in order to raise both the quality and speed of recognition of hieroglyphs. I wanted to replace the entire unit recognition of a separate character for these languages using neural networks. In this article we will describe how we managed to do it in the end.
In general, the use of convolutional networks for character recognition is not a new idea. Historically, their first time was used precisely for this task back in 1998. True then it was not printed hieroglyphs, but handwritten English letters and numbers.
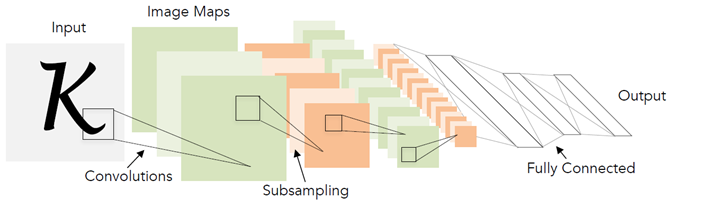
For 20 years, technology in the field of deep learning, of course, greatly leaped forward. Including more advanced architectures and new approaches to learning.
The architecture presented in the diagram above (LeNet), in fact, and today is very well suited for such simple tasks as the recognition of printed text. “Simple” I call it compared to other tasks of computer vision, such as, for example, search and recognition of faces.
It would seem - that the solution is nowhere easier. We take a neural network, a sample of marked hieroglyphs and teach it for the task of classification. Unfortunately, it turned out that everything is not so simple. All possible modifications of LeNet for the classification task of 10,000 hieroglyphs did not give sufficient quality (at least comparable with the recognition system we already have).
To achieve the required quality, we had to consider deeper and more complex architectures: WideResNet, SqueezeNet, etc. With their help, it was possible to achieve the required quality level, but they gave a strong drawdown on the speed of work - by 3-5 times compared with the basic algorithm on the CPU.
Someone may ask the question: “What is the point of measuring the speed of the network on the CPU, if it works much faster on the graphics processor (GPU)”? Here it is worth making a remark about the fact that for us the speed of the algorithm on the CPU is primarily important. We develop technologies for a large line of recognition products in ABBYY. In the largest number of scenarios, recognition is performed on the client side, and we cannot obviously assume that it has a GPU.
So, in the end, we came to the following problem: one neural network for recognizing all characters, depending on the choice of architecture, works either too badly or too slowly.
I had to look for another way. At the same time, there was no wish to abandon neural networks. It seemed that the biggest problem was the enormous number of classes that had to build networks of complex architecture. Therefore, we decided that we will not train the network for a large number of classes, that is, for the entire alphabet, but instead we will train many networks for a small number of classes (subsets of the alphabet).
In general, the ideal system was as follows: the alphabet is divided into groups of similar characters. The first level network classifies to which group of characters this image belongs. For each group, in turn, a second level network is trained, which makes the final classification within each group.
The picture is clickable
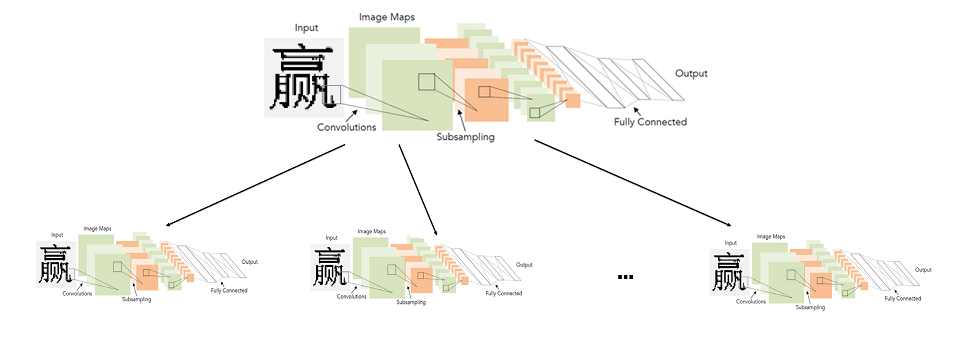
Thus, we produce the final classification by launching two networks: the first determines which network of the second level to run, and the second one already produces the final classification.
Actually, the fundamental point here is how to divide the characters into groups so that the first level network can be made accurate and fast.
To understand which network symbols are easier to distinguish, and which ones are more difficult, the easiest way is to look at which signs stand out for certain symbols. To do this, we took a classifier network trained to distinguish all the characters of the alphabet with good quality and looked at the activation statistics of the penultimate layer of this network — we began to look at the final indicative representations that the network receives for all characters.
At the same time, we knew that the picture there should be something like the following:
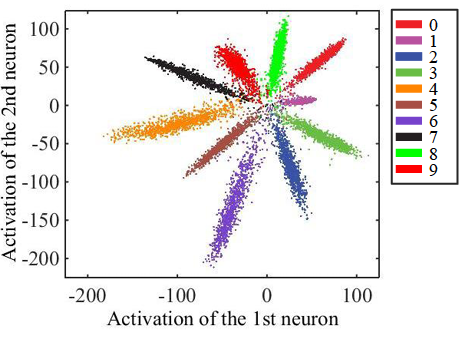
This is a simple example for the case of handwritten number sampling classification (MNIST) into 10 classes. There are only 2 neurons on the penultimate hidden layer that goes before the classification, thanks to which the statistics of their activations can be easily displayed on the plane. Each point on the graph corresponds to some example from the test set. The color of the point corresponds to a particular class.
In our case, the dimension of the attribute space was larger than in the example — 128. We drove a group of images from the test sample and obtained a feature vector for each image. After that, they were normalized (divided by length). From the picture above it is obvious why this is worth doing. We clustered normalized vectors with the KMeans method. Got a sample split into groups of similar (from a network point of view) images.
But we finally needed to get a partition of the alphabet into groups, and not a partition of the test sample. But the first of the second is easy to obtain: it is enough to attribute each class label to the cluster in which the most images of this class fall into. In most situations, of course, the whole class will end up inside a single cluster.
Well, that's it, we got the partition of the whole alphabet into groups of similar characters. It remains to choose a simple architecture and train the classifier to distinguish these groups.
Here is an example of random 6 groups, which are obtained as a result of splitting the entire source alphabet into 500 clusters:

Next you need to decide on what target character sets the second-level classifiers will learn. It seems that the answer is obvious - it should be the groups of symbols obtained in the previous step. This will work, but not always with good quality.
The fact is that the first level classifier in any case makes mistakes and can be partially leveled by constructing second level sets as follows:
For example, images of the symbol “A” were assigned by the classifier of the first level 980 times to the 5th group, 19 times to the 2nd group and 1 time to the 6th group. We have a total of 1000 images of this symbol.
Then we can add the symbol “A” to the 5th group and get a coverage of this symbol in 98%. We can attribute it to the 5th and 2nd group and get a coverage of 99.9%. And we can immediately relate to the groups (5, 2, 6) and get a coverage of 100%.
In fact, T_acc sets some balance between speed and quality. The higher it is, the higher the final quality of the classification will be, but the greater will be the target sets of the second level and the classification at the second level is potentially more complex.
Practice shows that even with T_acc = 1, the increase in the size of sets as a result of the replenishment procedure described above is not that significant - on average, about 2 times. Obviously, this will directly depend on the quality of the trained first level classifier.
Here is an example of how this recruitment works for one of the sets from the same partition into 500 groups, which was higher:
Trained two-tier models have finally worked faster and better used earlier classifiers. In fact, it was not so easy to “make friends” with the same linear division graph (GLD). For this, we had to separately teach the model to distinguish characters from a priori garbage and string segmentation errors (to return low confidence in these situations).
The final result of embedding in the full document recognition algorithm is below (obtained on the collection of Chinese and Japanese documents), the speed is indicated for the full algorithm:
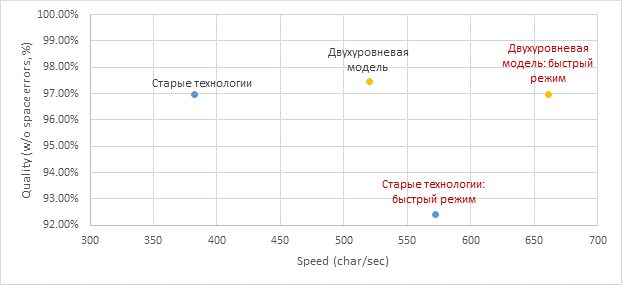
We raised the quality and accelerated both in the usual and in the fast mode, transferring all the character recognition to the neural networks.
Today, most of the publicly known OCR systems (the same Tesseract from Google) use the end-to-end architecture of neural networks to recognize strings or their entire fragments. We used neural networks here as a replacement for the module of recognition of a separate symbol. This is no accident.
The fact is that segmentation of a string into characters in printed Chinese and Japanese is not a big problem due to monospaced printing. In this regard, the use of End-to-End recognition for these languages does not greatly improve the quality, but at the same time is much slower (at least on the CPU). Anyway, how to use the proposed two-tier approach in the End-to-End context is not clear.
There are, on the contrary, languages for which linear division into symbols is a key problem. The obvious examples are Arabic, Hindi. For Arabic, for example, End-to-End solutions are already being actively investigated here. But that's another story.
Alexey Zhuravlev, Head of OCR New Technologies Group
Post series navigator
Approximately the same way, until 2018, recognition of Japanese and Chinese characters was arranged: primarily using raster and attribute classifiers. But with the recognition of hieroglyphs there are difficulties:
- A huge number of classes that need to be distinguished.
- More complex device character in general.
It is as difficult to say exactly how many characters Chinese characters have in writing as it is to accurately count how many words are in Russian. But most often in Chinese writing ~ 10,000 characters are used. We have limited the number of classes used in recognition.
Both problems described above also lead to the fact that in order to achieve high quality one has to use a large number of signs and these signs themselves are calculated on the images of symbols longer.
So that these problems did not lead to the strongest slowdowns in the entire recognition system, we had to use a lot of heuristics, primarily aimed at quickly cutting off a significant number of hieroglyphs, which this picture does not exactly look like. It still did not help to the end, but we wanted to bring our technologies to a qualitatively new level.
We began to investigate the applicability of convolutional neural networks in order to raise both the quality and speed of recognition of hieroglyphs. I wanted to replace the entire unit recognition of a separate character for these languages using neural networks. In this article we will describe how we managed to do it in the end.
Simple approach: one convolution network for recognizing all hieroglyphs
In general, the use of convolutional networks for character recognition is not a new idea. Historically, their first time was used precisely for this task back in 1998. True then it was not printed hieroglyphs, but handwritten English letters and numbers.
For 20 years, technology in the field of deep learning, of course, greatly leaped forward. Including more advanced architectures and new approaches to learning.
The architecture presented in the diagram above (LeNet), in fact, and today is very well suited for such simple tasks as the recognition of printed text. “Simple” I call it compared to other tasks of computer vision, such as, for example, search and recognition of faces.
It would seem - that the solution is nowhere easier. We take a neural network, a sample of marked hieroglyphs and teach it for the task of classification. Unfortunately, it turned out that everything is not so simple. All possible modifications of LeNet for the classification task of 10,000 hieroglyphs did not give sufficient quality (at least comparable with the recognition system we already have).
To achieve the required quality, we had to consider deeper and more complex architectures: WideResNet, SqueezeNet, etc. With their help, it was possible to achieve the required quality level, but they gave a strong drawdown on the speed of work - by 3-5 times compared with the basic algorithm on the CPU.
Someone may ask the question: “What is the point of measuring the speed of the network on the CPU, if it works much faster on the graphics processor (GPU)”? Here it is worth making a remark about the fact that for us the speed of the algorithm on the CPU is primarily important. We develop technologies for a large line of recognition products in ABBYY. In the largest number of scenarios, recognition is performed on the client side, and we cannot obviously assume that it has a GPU.
So, in the end, we came to the following problem: one neural network for recognizing all characters, depending on the choice of architecture, works either too badly or too slowly.
Two-level neural network model of recognition of hieroglyphs
I had to look for another way. At the same time, there was no wish to abandon neural networks. It seemed that the biggest problem was the enormous number of classes that had to build networks of complex architecture. Therefore, we decided that we will not train the network for a large number of classes, that is, for the entire alphabet, but instead we will train many networks for a small number of classes (subsets of the alphabet).
In general, the ideal system was as follows: the alphabet is divided into groups of similar characters. The first level network classifies to which group of characters this image belongs. For each group, in turn, a second level network is trained, which makes the final classification within each group.
The picture is clickable
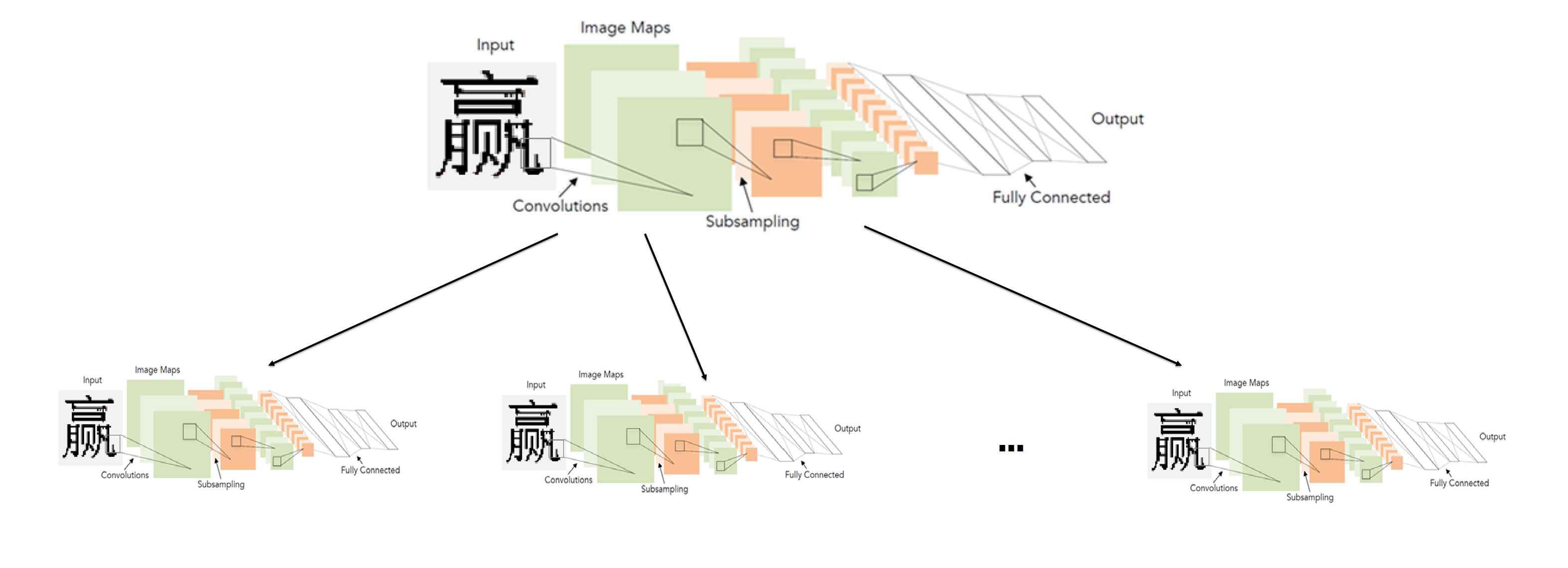
Thus, we produce the final classification by launching two networks: the first determines which network of the second level to run, and the second one already produces the final classification.
Actually, the fundamental point here is how to divide the characters into groups so that the first level network can be made accurate and fast.
Construction of the first level classifier
To understand which network symbols are easier to distinguish, and which ones are more difficult, the easiest way is to look at which signs stand out for certain symbols. To do this, we took a classifier network trained to distinguish all the characters of the alphabet with good quality and looked at the activation statistics of the penultimate layer of this network — we began to look at the final indicative representations that the network receives for all characters.
At the same time, we knew that the picture there should be something like the following:
This is a simple example for the case of handwritten number sampling classification (MNIST) into 10 classes. There are only 2 neurons on the penultimate hidden layer that goes before the classification, thanks to which the statistics of their activations can be easily displayed on the plane. Each point on the graph corresponds to some example from the test set. The color of the point corresponds to a particular class.
In our case, the dimension of the attribute space was larger than in the example — 128. We drove a group of images from the test sample and obtained a feature vector for each image. After that, they were normalized (divided by length). From the picture above it is obvious why this is worth doing. We clustered normalized vectors with the KMeans method. Got a sample split into groups of similar (from a network point of view) images.
But we finally needed to get a partition of the alphabet into groups, and not a partition of the test sample. But the first of the second is easy to obtain: it is enough to attribute each class label to the cluster in which the most images of this class fall into. In most situations, of course, the whole class will end up inside a single cluster.
Well, that's it, we got the partition of the whole alphabet into groups of similar characters. It remains to choose a simple architecture and train the classifier to distinguish these groups.
Here is an example of random 6 groups, which are obtained as a result of splitting the entire source alphabet into 500 clusters:
Construction of second level classifiers
Next you need to decide on what target character sets the second-level classifiers will learn. It seems that the answer is obvious - it should be the groups of symbols obtained in the previous step. This will work, but not always with good quality.
The fact is that the first level classifier in any case makes mistakes and can be partially leveled by constructing second level sets as follows:
- We fix some separate sample of symbol images (not involved in either training or testing);
- We run this sample through the first level trained classifier, marking each image with the label of this classifier (group label);
- For each character, we consider all possible groups to which the images of this character refer the first level classifier;
- Добавляем этот символ во все группы до тех пор, пока не будет достигнута требуемая степень покрытия T_acc;
- Итоговые группы символов считаем целевыми множествами второго уровня, на которые будут обучаться классификаторы.
For example, images of the symbol “A” were assigned by the classifier of the first level 980 times to the 5th group, 19 times to the 2nd group and 1 time to the 6th group. We have a total of 1000 images of this symbol.
Then we can add the symbol “A” to the 5th group and get a coverage of this symbol in 98%. We can attribute it to the 5th and 2nd group and get a coverage of 99.9%. And we can immediately relate to the groups (5, 2, 6) and get a coverage of 100%.
In fact, T_acc sets some balance between speed and quality. The higher it is, the higher the final quality of the classification will be, but the greater will be the target sets of the second level and the classification at the second level is potentially more complex.
Practice shows that even with T_acc = 1, the increase in the size of sets as a result of the replenishment procedure described above is not that significant - on average, about 2 times. Obviously, this will directly depend on the quality of the trained first level classifier.
Here is an example of how this recruitment works for one of the sets from the same partition into 500 groups, which was higher:
Model Embedding Results
Trained two-tier models have finally worked faster and better used earlier classifiers. In fact, it was not so easy to “make friends” with the same linear division graph (GLD). For this, we had to separately teach the model to distinguish characters from a priori garbage and string segmentation errors (to return low confidence in these situations).
The final result of embedding in the full document recognition algorithm is below (obtained on the collection of Chinese and Japanese documents), the speed is indicated for the full algorithm:
We raised the quality and accelerated both in the usual and in the fast mode, transferring all the character recognition to the neural networks.
A little bit about End-to-End recognition
Today, most of the publicly known OCR systems (the same Tesseract from Google) use the end-to-end architecture of neural networks to recognize strings or their entire fragments. We used neural networks here as a replacement for the module of recognition of a separate symbol. This is no accident.
The fact is that segmentation of a string into characters in printed Chinese and Japanese is not a big problem due to monospaced printing. In this regard, the use of End-to-End recognition for these languages does not greatly improve the quality, but at the same time is much slower (at least on the CPU). Anyway, how to use the proposed two-tier approach in the End-to-End context is not clear.
There are, on the contrary, languages for which linear division into symbols is a key problem. The obvious examples are Arabic, Hindi. For Arabic, for example, End-to-End solutions are already being actively investigated here. But that's another story.
Alexey Zhuravlev, Head of OCR New Technologies Group