Search Mail.Ru, part two: a review of the data preparation architectures of large search engines
Overview of Big Search Engine Data Preparation Architectures
Last time we remembered how Go.Mail.Ru started in 2010, and how Search was before. In this post we will try to draw a big picture - we will dwell on how others work, but first we will talk about search distribution.
How search engines are distributed
As you requested, we decided to dwell on the basics of the distribution strategies of the most popular search engines.
There is an opinion that Internet search is one of those services that most users choose on their own, and the strongest should win this battle. This position is extremely attractive to us - it is for this reason that we are constantly improving our search technologies. But the situation on the market is making its adjustments, and the so-called “browser wars” intervene in the first place.
There was a time when the search was not related to the browser. Then the search engine was just another site that the user went to at his discretion. Imagine —Internet Explorer before the 7th version, which appeared in 2006, did not have a search bar; Firefox had a search bar from the first version, but he himself only appeared in 2004.
Where did the search string come from? It wasn’t invented by the authors of browsers - for the first time it appeared in the Google Toolbar, released in 2001. The Google Toolbar added “quick access to Google search” functionality to the browser - namely, the search line in its panel:
Why did Google release its toolbar? This is how Douglas Edwards, Google’s brand manager at that time, describes his mission in his book “I'm Feeling Lucky: The Confessions of Google Employee Number 59”:
“The Toolbar was a secret weapon in our war against Microsoft. By embedding the Toolbar in the browser, Google opened another front in the battle for unfiltered access to users. Bill Gates wanted complete control over the PC experience, and rumors abounded that the next version of Windows would incorporate a search box right on the desktop. We needed to make sure Google's search box didn't become an obsolete relic. "
“The Toolbar was the secret weapon in the war against Microsoft. By integrating Toolbar into the browser, Google opened another front in the battle for direct access to users. Bill Gates wanted to have complete control over how users interact with a PC: rumors were circulating that in the next version of Windows the search bar would be installed directly on the desktop. It was necessary to take measures to prevent the Google search bar from becoming a relic of the past. ”
How was the toolbar distributed? Yes, all the same, along with popular software: RealPlayer , Adobe Macromedia Shockwave Player , etc.
It is clear that other search engines began to distribute their toolbars (Yahoo Toolbar, for example), and browser manufacturers did not hesitate to take this opportunity to get an additional source of income from search engines and built a search line to themselves by introducing the concept of "default search engine."
The business departments of browser manufacturers have chosen the obvious strategy: the browser is the user's entry point to the Internet, the default search settings are likely to be used by the browser audience - so why not sell these settings? And they were right in their own way, because Internet search is a product with almost zero “stickiness”.
At this point, it is worthwhile to dwell in more detail. Many are outraged: “no, a person gets used to searching and uses only the system that he trusts,” but practice proves the opposite. If, say, your inbox or social account. for some reason, the network is unavailable, you don’t immediately go to another email service or other social network, because you are “stuck” to your accounts: your friends, colleagues, family know them. Changing an account is a long and painful process. With search engines, everything is completely different: the user is not tied to a particular system. If the search engine is unavailable for some reason, users don’t sit and wait for it to finally work - they just go to other systems (for example, we clearly saw it on the LiveInternet counters a year ago, during a failure of one of our competitors ) At the same time, users do not suffer much from the accident, because all search engines are arranged in approximately the same way (search line, query, results page) and even an inexperienced user will not get lost when working with any of them. Moreover, in approximately 90% of cases, the user will receive an answer to his question, no matter what system he searches for.
So, the search, on the one hand, has practically zero “stickiness” (in English there is a special term “stickiness”). On the other hand, some kind of search is already pre-installed in the browser by default, and a fairly large number of people will use it only for the reason that it is convenient to use from there. And if the search behind the search line satisfies the user's tasks, then he can continue to use it.
What are we coming to? The leading search engines had no choice but to fight for the search strings of browsers, distributing their desktop search products - toolbars, which during the installation process change the default search in the user's browser. The instigator of this struggle was Google, the rest had to defend themselves. You can, for example, read such words by Arkady Volozh, the creator and owner of Yandex, in his interview :
“When in 2006-2007. Google’s share in the Russian search market began to grow, at first we couldn’t understand why. Then it became obvious that Google is promoting itself by embedding it in browsers (Opera, Firefox). And with the release of its own browser and mobile operating system, Google began to destroy the relevant markets altogether. ”
Since Mail.Ru is also a search, it cannot stand aloof from the “browser wars”. We just entered the market a little later than others. Now the quality of our Search has grown markedly, and our distribution is a reaction to the very struggle of toolbars that is being waged on the market. Moreover, it is really important for us that an increasing number of people who are trying to use our Search are satisfied with the results.
By the way, our distribution policy is several times less active than that of the nearest competitor. We see this on the counter top.mail.ru, which is installed on most of the websites of Runet. If the user navigates to the site on demand through one of the distribution products (toolbar, own browser, browser box of the partner browser), the clid = parameter is present in the URL. Thus, we can estimate the capacity of distribution requests: the competitor has almost 4 times more, than ours.
But let's move on from distribution to how other search engines work. After all, we naturally began our internal discussions of architecture with a study of the architectural solutions of other search engines. I will not describe their architectures in detail - instead, I will give links to open materials and highlight those features of their solutions that seem important to me.
Data preparation in large search engines
Rambler
The Rambler search engine, now closed, had a number of interesting architectural ideas. For example, it was known about their own data storage system (NoSQL, as it is now fashionable to call such systems) and distributed computing HICS ( or HCS ), which was used, in particular, for calculations on the link graph. HICS also allowed standardizing the presentation of data within a search in a single, universal format.
The architecture of Rambler was quite different from ours in the organization of the spider. Our spider was executed as a separate server, with its own, self-written, base of addresses of downloaded pages. To download each site, a separate process was launched, which simultaneously downloaded pages, parsed them, highlighted new links and could immediately follow them. Rambler's spider was made much simpler.
On one server, a large text file was located with all the addresses of documents known to Rambler, one per line, sorted in lexicographical order. Once a day, this file was bypassed and other text files-tasks for pumping were generated, which were performed by special programs that could only download documents from a list of addresses. Then the documents were parsed, links were extracted and placed next to this large file-list of all known documents, sorted, after which the lists were merged into a new large file, and the cycle repeated again.
The advantages of this approach were simplicity, the presence of a single registry of all known documents. The disadvantages were the inability to go to the freshly extracted document addresses immediately, since downloading new documents could happen only at the next iteration of the spider. In addition, the size of the database and its processing speed was limited to one server.
Our spider, on the contrary, could quickly follow all the new links from the site, but it was very poorly managed from the outside. It was difficult to “pour” additional data to the addresses (necessary for ranking documents within the site, which determine the priority of pumping), it was difficult to dump the database.
Yandex
Not much was known about Yandex's internal search engine until Den Raskovalov talked about it in his lecture course .
From there, you can find out that Yandex search consists of two different clusters:
- batch processing
- real-time data processing (this is not really “real time” in the sense in which this term is used in control systems where delay in the execution of tasks can be critical. Rather, it is the possibility of a document getting into the index as quickly as possible and independently of others documents or tasks; a kind of “soft” version of real time)
The first is used for regular Internet downloads, the second - for delivery to the index of the best and most interesting documents that have just appeared. We will consider so far only batch processing, because before the index was updated in real time, then we were quite far away, we wanted to go out to update the index once every two days.
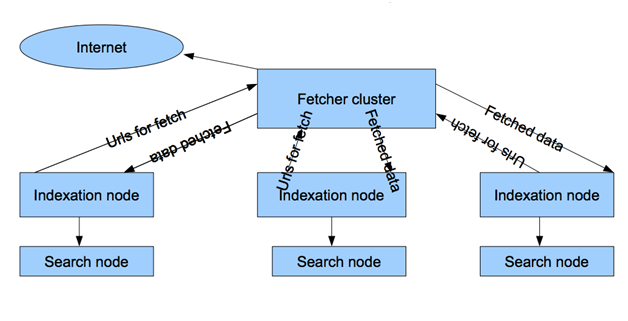
At the same time, despite the fact that the appearance of the Yandex batch processing cluster was somewhat similar to our pair of swing and index clusters, there were several serious differences in it:
- The base of page addresses is one, stored on indexing nodes. As a result, there are no problems with the synchronization of the two databases.
- Pumping logic control is transferred to indexing nodes, i.e. spider nodes are very simple, download what indexers indicate to them. Our spider himself determined what he and when to download.
- And, a very important difference - inside, all the data is presented in the form of relational tables of documents, sites, links. With us, all the data was distributed to different hosts, stored in different formats. The tabular presentation of the data greatly simplifies access to them, allows you to make various samples and get the most diverse analytics of the index. We were deprived of all this, and at that time only the synchronization of our two document bases (spider and indexer) took a week, and we had to stop both clusters for this time.
Google, without a doubt, is the world’s technological leader, so they always pay attention to it, analyze what it did, when and why. And the Google search architecture, of course, was the most interesting for us. Unfortunately, Google rarely opens its architectural features, each article is a big event and almost instantly generates a parallel OpenSource project (sometimes not one) that implements the technologies described.
Those who are interested in the features of the Google search can be confidently advised to study almost all the presentations and speeches of one of the most important specialists in the company for internal infrastructure - Jeffrey Dean , for example:
- “Challenges in Building Large-Scale Information Retrieval Systems” (slides) that help you learn how Google developed, starting with the very first version, which was still made by students and graduate students at Stanford University until 2008, before the introduction of Universal Search. There is a video of this performance and a similar presentation in Stanford, “Building Software Systems At Google and Lessons Learned”
- "MapReduce: Simplified Data Processing on Large Clusters . " The article describes a computational model that makes it easy to parallelize computations on a large number of servers. Immediately after this publication, the open source Hadoop platform appeared.
- “BigTable: A Distributed Structured Storage System”, a story about the BigTable NoSQL database, based on which HBase and Cassandra were made ( video can be found here , slides here )
- “MapReduce, BigTable, and Other Distributed System Abstractions for Handling Large Datasets” describes Google’s most famous technology.
Based on these presentations, we can highlight the following features of the Google search architecture:
- Tabular structure for data preparation. The entire search database is stored in a huge table, where the key is the document address, and the meta-information is stored in separate columns, united in families. Moreover, the table was originally made in such a way as to work effectively with sparse data (i.e. when far from all documents have values in columns).
- Unified distributed computing system MapReduce. Data preparation (including creating a search index) is a sequence of mapreduce tasks performed on BigTable tables or files in a distributed GFS file system.
All this looks pretty reasonable: all known document addresses are stored in one large table, they are prioritized, calculated on the link graph, etc., the search spider brings the contents of the pumped out pages to it, and as a result, an index is built on it.
There is another interesting presentation by another Google specialist, Daniel Peng (Daniel Peng) about innovations in BigTable, which allowed to implement a quick, in a few minutes, adding new documents to the index. This technology “outside” Google was advertised under the name Caffeine , and in publications was called Percolator. A video of the performance at OSDI'2010 can be seen here .
Speaking very rudely, this is the same BigTable, but in which the so-called triggers, - the ability to load your pieces of code that work on changes inside the table. If so far I have described batch processing of data, i.e. when the data are combined and processed together if possible, the implementation of the same on the triggers is completely different. Suppose a spider has downloaded something, placed new content in a table; the trigger worked, signaling "new content has appeared, it needs to be indexed." The indexing process started immediately. It turns out that all the tasks of the search engine as a result can be divided into subtasks, each of which is launched by its own click. Having a large amount of equipment, resources and debugged code, you can solve the problem of adding new documents quickly,
The difference between Google architecture and Yandex architecture, where the real-time index updating system was also indicated, is that Google, as claimed, the entire procedure for constructing the index is performed on triggers, while Yandex has it only for a small subset of the best, most valuable documents.
Lucene
It is worth mentioning another search engine - Lucene. This is a freeware search engine written in Java. In a sense, Lucene is a platform for creating search engines, for example, a web search engine called Nutch has budged from it. In fact, Lucene is the search engine for creating the index and the search engine, and Nutch is the same plus spider that crawls pages, because the search engine does not necessarily search for documents that are on the web.
In fact, Lucene itself does not have many interesting solutions that could be borrowed by a large search engine on the web, designed for billions of documents. On the other hand, do not forget that it was the Lucene developers who launched the Hadoop and HBase projects (every time a new interesting article from Google appeared, the Lucene authors tried to apply the voiced solutions at home. For example, HBase, which is a BigTable clone, appeared) . However, these projects have long existed on their own.
For me at Lucene / Nutch, it was interesting how they used Hadoop. For example, in Nutch, a special spider was written for pumping the web, which was performed entirely in the form of tasks for Hadoop. Those. the entire spider is just the processes that run in Hadoop in the MapReduce paradigm. This is a rather unusual solution that goes beyond how Hadoop is used. After all, this is a platform for processing large amounts of data, and this assumes that the data is already available. But here this task does not calculate or process anything, but, on the contrary, downloads it.
On the one hand, this solution captivates with its simplicity. After all, the spider needs to get all the addresses of one site for pumping, go around them one after another, the spider itself must also be distributed and run on several servers. So we make a mapper in the form of a separator of addresses for sites, and we implement each individual pumping process in the form of a reducer.
On the other hand, this is a rather bold decision, because it’s hard to pump out sites - not every site is responsible for the guaranteed time, and the cluster’s computing resources are spent just waiting for a response from someone else’s web server. Moreover, the problem of "slow" sites is always there when there is a sufficiently large number of pumping addresses. For 20% of the time, the spider pumps 80% of documents from fast sites, then spends 80% of the time trying to download slow sites - and almost never can completely pump them, you always have to drop something and leave it “next time”.
We analyzed such a solution for some time, and as a result, abandoned it. Perhaps, for us, the architecture of this spider was interesting as a kind of “negative example”.
In more detail about the structure of our search engine, about how we built the search engine, I will tell in the next post.