How JS works: WebRTC and P2P communication mechanisms
- Transfer
[We advise you to read] Other 19 parts of the cycle
Часть 1: Обзор движка, механизмов времени выполнения, стека вызовов
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Today we publish a translation of the 18th part of a series of materials dedicated to everything related to JavaScript. Here we talk about the technology WebRTC, which aims to organize the direct exchange of data between browser applications in real time.
Overview
What is WebRTC? For a start it is worth saying that the abbreviation RTC stands for Real Time Communication (real-time communication). This alone gives a lot of information about this technology.
WebRTC occupies a very important niche among the mechanisms of the web platform. Previously, P2P technologies (peer-to-peer, point-to-point connections, peer-to-peer, peer-to-peer networks) used by applications such as desktop chats gave them opportunities that web projects did not have. WebRTC is changing the situation for the better for web technology.
WebRTC, if we consider this technology in general terms, allows web applications to create P2P connections, which we will discuss below. In addition, we will touch on the following topics in order to show a complete picture of the internal structure of WebRTC:
- P2P communication.
- Firewalls and NAT Traversal technology.
- Signaling, sessions and protocols.
- WebRTC API.
P2P communications
Suppose two users have launched, each in their own browser, an application that allows you to organize video chat using WebRTC. They want to establish a P2P connection. After the decision is made, we need a mechanism that allows browsers to detect each other and to establish a connection taking into account the information protection mechanisms available in the systems. After the connection is established, users will be able to exchange multimedia information in real time.
One of the main difficulties associated with browser-based P2P connections is that browsers first need to detect each other, and then establish a socket-based network connection to provide bidirectional data transfer. We propose to discuss the difficulties associated with the installation of such compounds.
When a web application needs some data or resources, it downloads it from the server and that’s it. The server address is known to the application. If we are talking about, for example, creating a P2P chat, whose work is based on a direct connection of browsers, the addresses of these browsers are unknown in advance. As a result, in order to establish a P2P connection, you will have to cope with some problems.
Firewalls and NAT Traversal
Normal computers usually do not have static external IP addresses assigned to them. The reason for this is that these computers are usually located behind firewalls and NAT devices.
NAT is a mechanism that translates the internal local IP addresses located behind the firewall into external global IP addresses. NAT is used, firstly for security reasons, and secondly, because of the limitations imposed by IPv4 on the number of global IP addresses available. That is why Web applications that use WebRTC should not rely on the current device having a global static IP address.
Let's see how NAT works. If you are in a corporate network and connected to WiFi, your computer will be assigned an IP address that exists only behind your NAT device. Suppose this is the IP address 172.0.23.4. To the outside world, however, your IP address may look like 164.53.27.98. The outside world, as a result, sees your requests as coming from the address 164.53.27.98, but thanks to NAT, the answers to the requests made by your computer to external services will be sent to your internal address 172.0.23.4. This is done using the translation tables. Please note that in addition to the IP-address for the organization of network interaction, you also need the port number.
Considering that NAT is involved in the process of interaction of your system with the outside world, your browser needs to find out the IP address of the computer on which the browser you want to contact is installed to establish a WebRTC connection.
This is where STUN (Session Traversal Utilities for NAT) and TURN (Traversal Using Relays around NAT) servers come on the scene. To ensure the operation of the WebRTC technology, a request is first made to the STUN server, aimed at finding out your external IP address. In fact, we are talking about a request that is executed to a remote server in order to find out from which IP address the server receives this request. The remote server, having received a similar request, will send a response containing the IP address visible to it.
Based on the assumption that this scheme is working and that you received information about your external IP address and port, then you can tell other system participants (we will call them “peers”) about how to contact you directly. These peers can also do the same using STUN or TURN servers and can tell you which addresses are assigned to them.
Signaling, sessions and protocols
The process of finding out the network information described above is one of the parts of a large signaling system that, in the case of WebRTC, is based on the JSEP (JavaScript Session Establishment Protocol) standard. Signaling includes the discovery of network resources, the creation and management of sessions, the security of communications, the coordination of media data parameters, error handling.
In order for the connection to work, peers must agree on the data formats that they will exchange, and gather information about the network addresses of the computer on which the application is running. A signaling mechanism for sharing this critical information is not part of the WebRTC API.
Signaling is not defined by the WebRTC standard, and it is not implemented in its API in order to provide flexibility in the technologies and protocols used. Signaling and the servers that support it are the responsibility of the developer of the WebRTC application.
Based on the assumption that your WebRTC application running in the browser is able to determine the external IP address of the browser using STUN, as described above, the next step is to discuss session parameters and establish a connection with another browser.
The initial discussion of session parameters and the establishment of a connection takes place using a signaling / communication protocol that specializes in multimedia communications. This protocol is also responsible for enforcing the rules according to which the session is managed and terminated.
One of these protocols is called SIP (Session Initiation Protocol). Note that due to the flexibility of the WebRTC signaling subsystem, SIP is not the only signaling protocol that can be used. The selected signaling protocol must also work with an application level protocol called SDP (Session Description Protocol), which is used when using WebRTC. All metadata related to multimedia data is transmitted using SDP.
Any peer (that is, an application that uses WebRTC) that tries to communicate with another peer generates a set of candidate routes for the ICE (Interactive Connectivity Establishment) protocol. Candidates represent some combination of IP address, port, and transport protocol that can be used. Please note that a single computer can have multiple network interfaces (wired, wireless, and so on), so it can be assigned several IP addresses, one for each interface.
Here is a MDN diagram illustrating the above data exchange process.
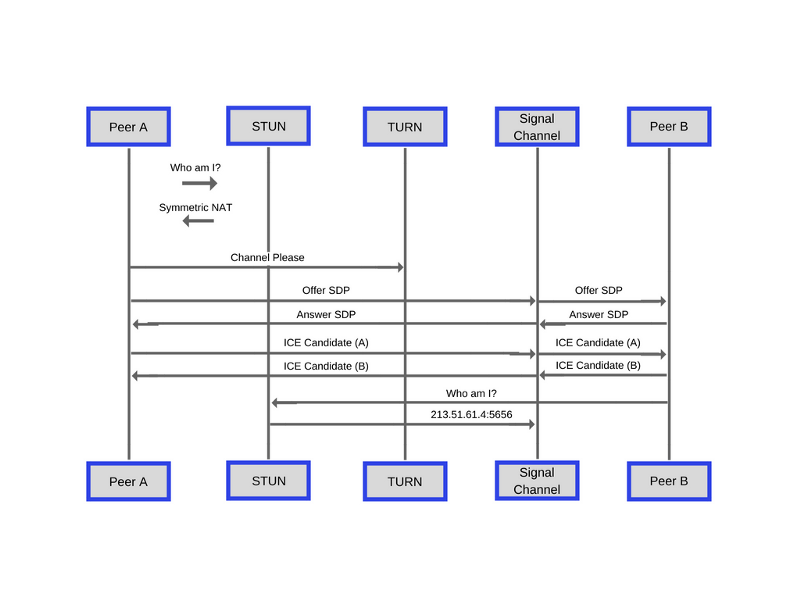
The process of exchanging the data necessary to establish a P2P connection
Establishing connection
Each party first finds its external IP address as described above. Then, dynamically created “channels” of signaling data are used to detect peers and support data exchange between them, to discuss the parameters of sessions and their installation.
These “channels” are unknown and inaccessible to the outside world, a unique identifier is required to access them.
Note that due to the flexibility of WebRTC, and the fact that the signaling process is not defined by the standard, the concept of “channels” and the way they are used may differ slightly depending on the technology used. In fact, some protocols do not require a “channel” mechanism for data exchange. We, for the purposes of this material, assume that “channels” in the implementation of the system are used.
If two or more peers are connected to the same "channel", peers are able to exchange data and discuss information about the session. This process is similar to the publisher-subscriber template . In general, the initiating connection pir sends a “bid” using a signaling protocol such as SIP or SDP. The initiator expects to receive a “response” from the recipient of the proposal, which is connected to the “channel” in question.
After the answer is received, the process of identifying and discussing the best ICE candidates collected by each peer takes place. After the optimal ICE candidates are selected, the parameters of the data that peers and the network routing mechanism (IP address and port) will exchange are agreed upon.
Then an active network socket session is established between peers. Next, each peer creates local data streams and end points of the data channels, and the two-way transfer of multimedia data begins using the technology used.
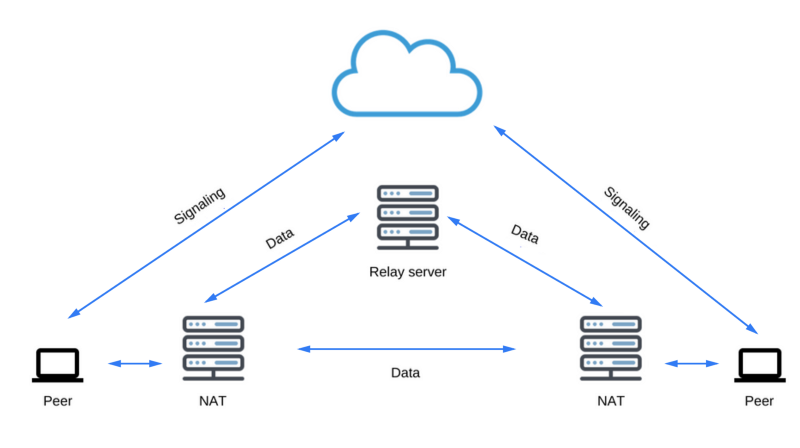
If the process of negotiating the choice of the best ICE candidate did not succeed, which sometimes occurs due to the fault of firewalls and NAT systems, a fallback option is used, consisting in using the TURN server as a repeater. This process involves a server that acts as an intermediary that relays the data that peers exchange. Note that this scheme is not a true P2P connection, in which peers transmit data directly to each other.
When using a fallback using TURN to exchange data, each feast no longer needs to know how to communicate with others and how to transfer data to it. Instead, peers need to know which external TURN server needs to send multimedia data in real time and from which server they need to be received during a communication session.
It is important to understand that now we were talking about a backup method of organizing communications. TURN servers must be very reliable, have a large bandwidth and serious computing power, and support work with potentially large amounts of data. Using the TURN server thus obviously results in additional costs and increases in system complexity.
WebRTC API
There are three main categories of APIs that exist in WebRTC:
- The Media Capture and Streams API is responsible for capturing multimedia data and working with streams. This API allows you to connect to input devices, such as microphones and webcams, and receive media streams from them.
- API RTCPeerConnection. Using the API of this category, it is possible, from one WebRTC endpoint, to send, in real time, the captured stream of audio or video data via the Internet to another WebRTC endpoint. Using this API, you can create connections between the local machine and the remote peer. It provides methods for connecting to a remote peer, for managing a connection, and for monitoring its state. Its mechanisms are used to close unwanted connections.
- API RTCDataChannel. The mechanisms represented by this API allow the transfer of arbitrary data. Each data channel is connected to the RTCPeerConnection interface.
Let's talk about these APIs.
API Media Capture and Streams
Media Capture and Streams API, which is often called the Media Stream API or Stream API, is an API that supports work with audio and video data, methods for working with them. The means of this API set the limitations associated with data types, there are callbacks of successful and unsuccessful completion of operations, used when using asynchronous mechanisms for working with data, and events that are triggered during work.
The MediaDevices
getUserMedia() API method prompts the user for permission to work with input devices that produce MediaStream streams .with audio or video tracks containing the requested types of media data. Such a stream may include, for example, a video track (its source is either a hardware or virtual video source, such as a camera, video recorder, screen sharing service, and so on), an audio track (similarly, physical or virtual audio sources can form it like a microphone, an analog-to-digital converter, and so on), and possibly other types of tracks. This method returns a promise that resolves to a MediaStream object . If the user rejected a request for permission, or the relevant media data is not available, then the promise will be resolved, respectively, with an error
PermissionDeniedErroror NotFoundError.Access to the singleton
MediaDevicecan be obtained through the object navigator:navigator.mediaDevices.getUserMedia(constraints)
.then(function(stream){
/* использовать поток */
})
.catch(function(err){
/* обработать ошибку */
});Note that when calling a method,
getUserMedia()it needs to pass an object constraintsthat tells the API what type of stream it should return. You can configure a lot of things here, including which camera you want to use (front or rear), frame rate, resolution, and so on. Starting from version 25, Chromium-based browsers allow you to transfer audio data from
getUserMedia()audio or video elements (however, note that media elements will be disabled by default). The method
getUserMedia()can also be used as an input node for the Web Audio API :functiongotStream(stream) {
window.AudioContext = window.AudioContext || window.webkitAudioContext;
var audioContext = new AudioContext();
// Создать AudioNode из потока
var mediaStreamSource = audioContext.createMediaStreamSource(stream);
// Подключить его к целевому объекту для того, чтобы слышать самого себя,
// или к любому другому узлу для обработки!
mediaStreamSource.connect(audioContext.destination);
}
navigator.getUserMedia({audio:true}, gotStream);Restrictions related to the protection of personal information
Unauthorized capture of data from a microphone or camera is a serious interference with the user's personal life. Therefore, the use
getUserMedia()provides for the implementation of very specific requirements for notifying the user about what is happening and for managing permissions. The method getUserMedia()should always receive the user's permission before opening any input device that collects media data, such as a webcam or microphone. Browsers may offer a one-time permission setting for a domain, but they must request permission at least when they first try to access media devices, and the user must explicitly give such permission.In addition, the rules related to notifying the user about what is happening are important. Browsers are required to display an indicator that indicates the use of a microphone or camera. The display of such an indicator does not depend on the presence of hardware indicators in the system that indicate the operation of such devices. In addition, browsers should show an indicator that permission is given to use the input device, even if the device is not used at a certain time to record the relevant data.
Interface RTCPeerConnection
The RTCPeerConnection interface is a WebRTC connection between a local computer and a remote peer. It provides methods for connecting to a remote system, for maintaining a connection and monitoring its state, and for closing a connection after it is no longer needed.
Here is a WebRTC architecture diagram showing the role of the RTCPeerConnection.
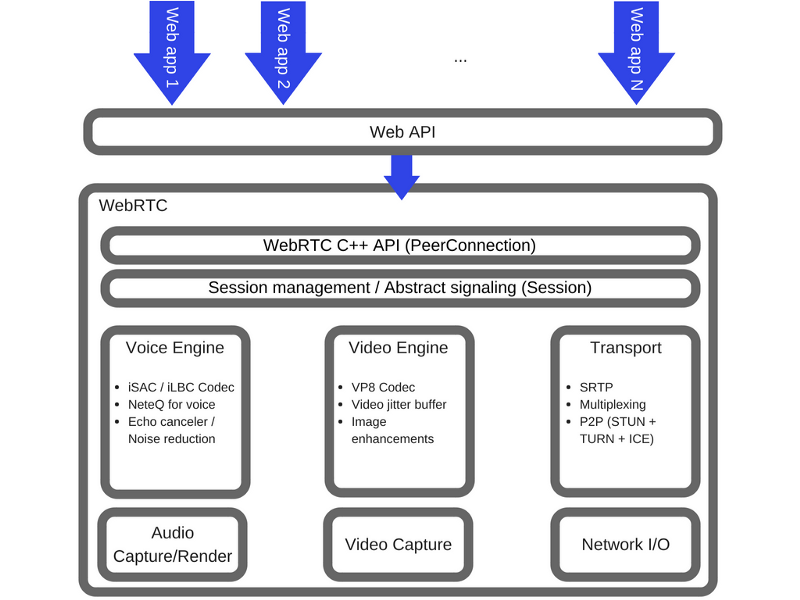
The Role of RTCPeerConnection
From a JavaScript perspective, the main knowledge that can be extracted from the analysis of this diagram is that RTCPeerConnection abstracts the web developer from complex mechanisms located at deeper levels of the system. The codecs and protocols used by WebRTC do a lot of work to make real-time data exchange possible, even when using unreliable networks. Here are some of the tasks solved by these mechanisms:
- Masking packet loss.
- Echo cancellation
- Bandwidth adaptation.
- Dynamic buffering to eliminate jitter.
- Automatic volume control.
- Noise reduction and suppression.
- "Cleaning" the image.
API RTCDataChannel
Just as in the case of audio and video data, WebRTC supports the transfer of other types of data in real time. API RTCDataChannel allows you to organize P2P-exchange of arbitrary data.
There are many scenarios for using this API. Here are some of them:
- Games.
- Real time text chat.
- File transfer
- Organization of decentralized networks.
This API is focused on using the RTCPeerConnection API as efficiently as possible and allows you to organize a powerful and flexible data exchange system in a P2P environment. Among its features are the following:
- Effective work with sessions using RTCPeerConnection.
- Support for multiple simultaneously used communication channels with prioritization.
- Support for reliable and unreliable message delivery methods.
- Integrated security controls (DTLS) and congestion.
The syntax here is similar to the one used when working with WebSocket technology. Here the method
send()and the event are applied message:var peerConnection = new webkitRTCPeerConnection(servers,
{optional: [{RtpDataChannels: true}]}
);
peerConnection.ondatachannel = function(event) {
receiveChannel = event.channel;
receiveChannel.onmessage = function(event){
document.querySelector("#receiver").innerHTML = event.data;
};
};
sendChannel = peerConnection.createDataChannel("sendDataChannel", {reliable: false});
document.querySelector("button#send").onclick = function (){
var data = document.querySelector("textarea#send").value;
sendChannel.send(data);
}WebRTC in the real world
In the real world, to organize WebRTC communications, servers are needed. The systems are not too complicated, thanks to them the following sequence of actions is implemented:
- Users discover each other and exchange information about each other, for example, names.
- Client WebRTC applications (peers) exchange network information.
- Peers exchange information about media data, such as video format and resolution.
- WebRTC client applications establish a connection, bypassing NAT gateways and firewalls.
In other words, WebRTC needs four types of server functions:
- Means to detect users and organize their interaction.
- Signaling
- NAT traversal and firewalls.
- Relay servers used when it is not possible to establish a P2P connection.
The STUN protocol and its TURN extension are used by ICE to enable RTCPeerConnection to work with NAT traversal mechanisms and to cope with other difficulties encountered when transmitting data over a network.
As already mentioned, ICE is a protocol for connecting peers, such as two video chat clients. At the very beginning of a communication session, ICE tries to connect peers directly, with the lowest possible delay, via UDP. During this process, the STUN servers have only one task: to allow the peer located behind NAT to find out its public address and port. Take a look at this list of available STUN servers (Google also has such servers).
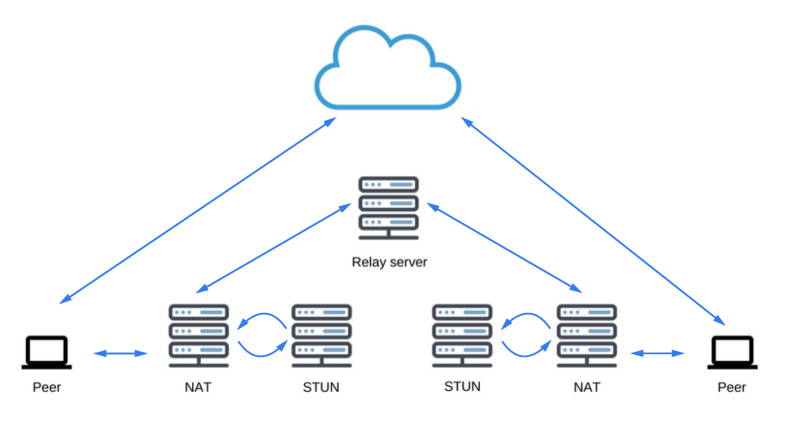
STUN servers
ICE Candidate Detection
If a UDP connection fails, ICE tries to establish a TCP connection: first via HTTP, then via HTTPS. If a direct connection fails - in particular, due to the impossibility of circumventing corporate NATs and firewalls, ICE uses an intermediary (repeater) as a TURN server. In other words, ICE will first try to use STUN with UDP for direct connection of peers, and, if this does not work out, will use a fallback option with the renter in the form of a TURN server. The expression "search for candidates" refers to the process of finding network interfaces and ports.
Search for suitable network interfaces and ports
Security
Real-time communications applications or related plug-ins can lead to security issues. In particular, we are talking about the following:
- Unencrypted media or other data can be intercepted along a path between browsers, or between a browser and a server.
- The application can, without the knowledge of the user, record and transmit video and audio data to the attacker.
- Along with a harmless-looking plug-in or application, a virus or other malware can enter the user's computer.
WebRTC has several mechanisms designed to combat these threats:
- WebRTC implementations use secure protocols like DTLS and SRTP .
- For all components of WebRTC systems, encryption is required. This also applies to signaling mechanisms.
- WebRTC is not a plugin. WebRTC components are executed in the browser sandbox, and not in a separate process. Components are updated when the browser is updated.
- Access to the camera and microphone must be given explicitly. And, when a camera or microphone is used, this fact is clearly displayed in the user interface of the browser.
Results
WebRTC is a very interesting and powerful technology for projects that use the transfer of any data between browsers in real time. The author of the material says that his company, SessionStack , uses traditional data exchange mechanisms with users, involving the use of servers. However, if they used WebRTC to solve the corresponding tasks, it would allow organizing data exchange directly between browsers, which would reduce the delay in data transfer and reduce the load on the company's infrastructure.
Dear readers! Do you use WebRTC technology in your projects?
