A word to the linguist: what if computers talk better than we

Photo: Alexander Korolkov / WG
June 3, the final day of the Moscow Book Festival on Red Square, linguist Alexander Piperski spoke about computer linguistics. He spoke about machine translations, neural networks, vector mapping of words, and raised questions of the limits of artificial intelligence.
The lecture was listened to by different people. To my right, for example, a Chinese tourist was nodding her nose. Alexander, for sure, also understood - a couple of unnecessary numbers, formulas and words about algorithms, and people will flee to the next tent to listen to science fiction.
I asked Alexander to prepare a “director's version” lecture for Habr, where nothing was cut out that could put random tourists to sleep. After all, most of all, the performance lacked an audience with sensible questions and a generally good discussion. I think we can develop it here.
Where does AI start
Recently, we constantly communicate with computers in a voice, and all sorts of Alice, Alex and Siri answer us with a voice. If you look from the outside, it seems that the computer understands us, gives lists of relevant sites, reports the address of the nearest restaurant, indicates how to get to it.
Looks like we are dealing with a rather smart device. You can even say this device has what is called artificial intelligence (AI). Although no one really understands what it means and where the borders lie.
When they say “AI performs creative functions that are considered the prerogative of a person” - what does this mean? What are creative features? What is creative and what is not? Selection of the nearest Chinese restaurant - a creative feature? Now it seems rather not.
We are constantly inclined to refuse a computer in artificial intelligence. As soon as we are accustomed to the intellectual manifestations that a computer makes, we say, "this is not AI, this is complete nonsense, routine tasks, nothing interesting."
A simple example - from our point of view there is nothing more stupid than a pocket calculator. It is sold in any stall for 50 rubles. Take the usual eight-digit calculator, poke the buttons and get the result in seconds. Well, think about it, consider some things. This is not intelligence.
And imagine such a machine in the XVIII century. It would seem a miracle, because the calculation was the prerogative of man.
The same happens with computational linguistics. We tend to despise all its achievements. I enter the query “poems of Pushkin” into Google, it finds a page that says “A. Pushkin - Poems. It would seem that this? Perfectly normal behavior. But computer linguists had to spend dozens of years so that the word poem contained the word poem, so that the word Pushkin contained the word Pushkin and there was no Cannon.
Computer chess and machine translations
Computational linguistics originated at the same time as computer chess, but chess was once also the prerogative of man. Claude Shannon, one of the founders of computer science, in 1950 wrote an article on how to program a computer to play chess. According to him, we can develop two types of strategies.
A - with exhaustive continuation. It is necessary to test all possible moves at each stage.
B - iterate only those continuations that are evaluated as promising.
The person, obviously, uses strategy B. The grandmaster, most likely, sorts out only the options that are reasonable in his opinion, and gives a good move in a fairly quick time.
Strategy A is difficult to implement. By Shannon's calculation, in order to calculate the three moves, you must go through 109 options, and if the position is estimated at one microsecond (which was over-optimistic in the middle of the 20th century), then it will take 17 minutes per turn. And three moves ahead is an insignificant depth of prediction.
The whole further history of chess consists in the development of methods that will make it possible not to go through everything, but to understand what it is necessary to go through and what is not necessary. And the victory over the man has already been achieved, finally and irrevocably. The computer has bypassed the world chess champion about 20 years ago, and since then has only been improving.
The best program was considered Stockfish. Last year, AlphaZero played 100 games with it.
| Whites | Black | White win | Draw | Black victory |
|---|---|---|---|---|
| Alphazero | Stockfish | 25 | 25 | 0 |
| Stockfish | Alphazero | 0 | 47 | 3 |
AlphaZero is an artificial neural network that just played chess with itself for four hours. And I learned to play better than all the programs before her.
Similar is happening in computational linguistics now - a surge in neural network modeling. We began to work on machine chess simultaneously with machine translations - in the middle of the last century. Since then, there are three stages of development.
- Machine translation based on the rules.
It works very simply - just like in grammar lessons, a computer highlights the subject, predicate, addition. Understands how all this is translated into another language, learns how to express subject, predicates, additions, and everything.
Such a translation developed 30 years, not having great success.
- Statistical (phrasal) translation
The computer relies on a large database of texts translated by man. It selects words and phrases in it that correspond to the words and phrases of the original, collects them into sentences in the target language and outputs the result.
When on the Internet they write about the next “20 most stupid machine translations” - most likely, we are talking about phrasal translation. Although he achieved some success.
- Neural network translation
We will talk about it in more detail. He entered into mass use literally before our eyes: Google turned on the neural network translation at the end of 2016. For Russian, it appeared in March 2017. Yandex launched at the end of 2017 a hybrid system based on neural networks and statistics.
Neural networks
Neural network translation is based on this idea: if you mathematically simulate and reproduce the work of neurons in a person’s head, you can assume that the computer learns to work with the language in the same way as a person.
To do this, take a look at the cells in the human brain.
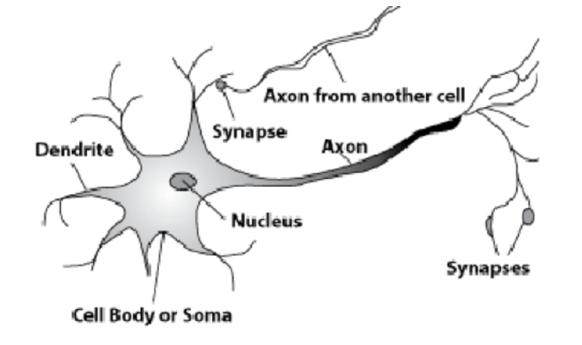
Here is a natural neuron. The long process, the axon, leaves the nucleus. It is attached to the processes from other cells - synapses. According to the axons in the synapse, cells transmit information about some electrochemical processes. Only one axon leaves each cell, and many synapses can enter. Signals spread, and so is the transfer of information.
Some cells are connected to the outside world. They receive signals that are further processed by the neural network.
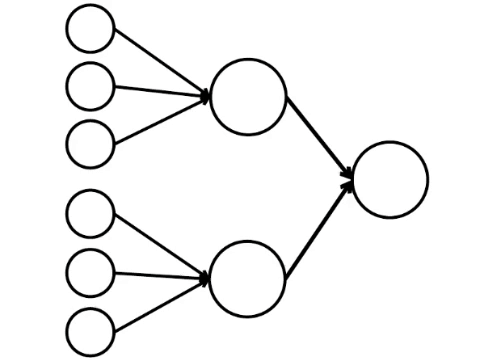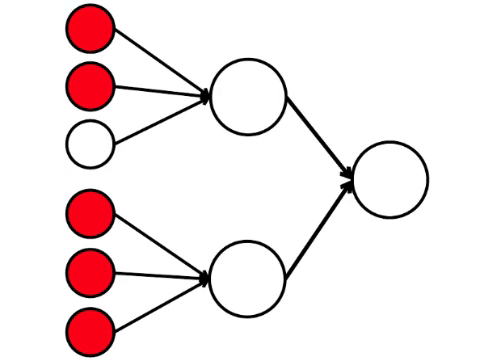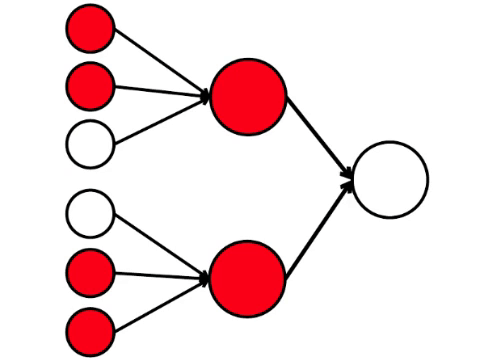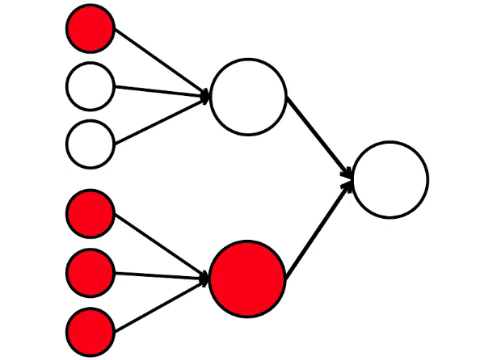
And here is the simplest mathematical model of what we can do here. I drew nine connected circles. These are neurons.

The six neurons on the left are the input layer, which receives a signal from the external environment. Neurons of the second and third layer do not come into contact with the environment, but only with other neurons. We introduce a rule - if at least two arrows from activated neurons enter the neuron, then this neuron is also activated.
The neural network processes the signal that arrives at the input, and ultimately, the right one - the output - the neuron lights up or does not light up. With such an architecture, at least four activated neurons in the left row are needed to activate the right neuron. If 6 or 5 are lit, it will definitely light up, if from 0 to 3 it will not light up exactly. But if four burn, then it will light up only if they are evenly distributed: 2 in the upper half and 2 in the lower.
It turns out that the simplest scheme of nine circles leads to a rather branched reasoning.
Artificial neural networks work in much the same way, but usually not with such simple things as “lit / ignited” (that is, 1 or 0), but with real numbers.
Take, for example, a network of 5 neurons — two in the input layer, two on average (hidden) and one in the output. Between all the neurons of the adjacent layers there are connections to which numbers are assigned - weights. To find out what happens in a still unfilled neuron, let's do a very simple thing: let's see which links lead to it, multiply the weight of each link by the number that is written in the neuron of the previous layer from which this link comes, and sum it all up. In the upper green neuron, the scheme is 50 × 1 + 3 × 10 = 80, and in the lower one - 50 × 0.5 - 3 × 10 = −5.
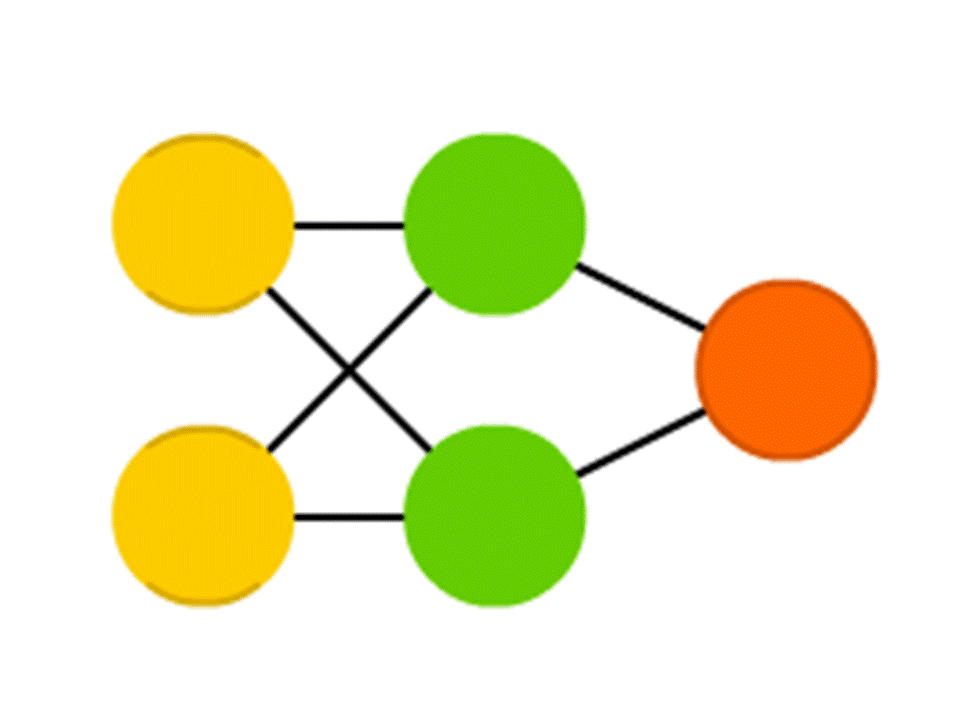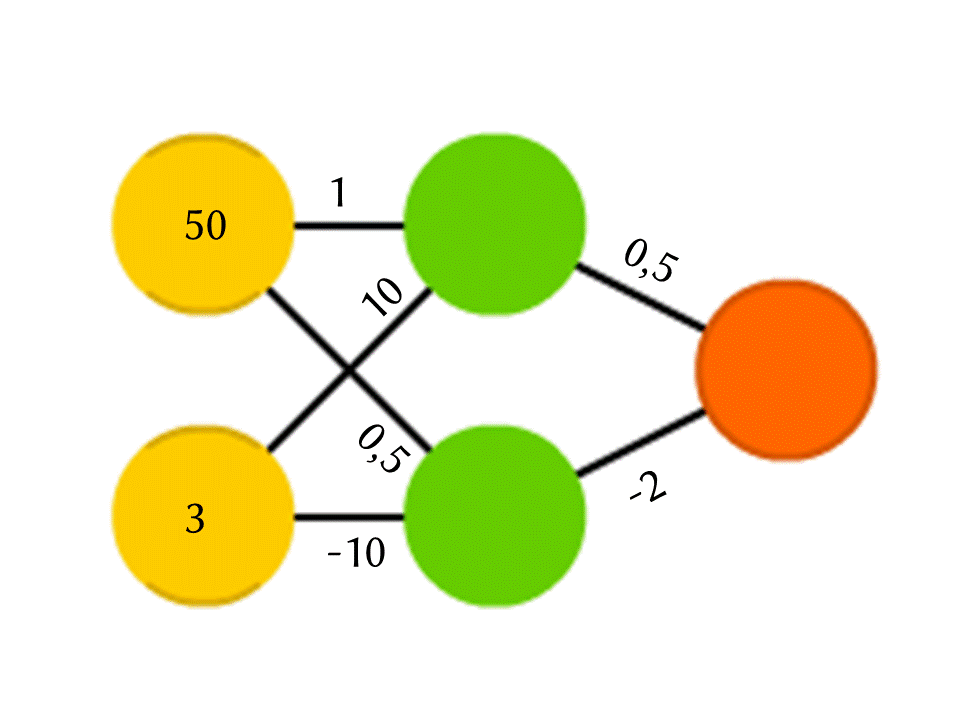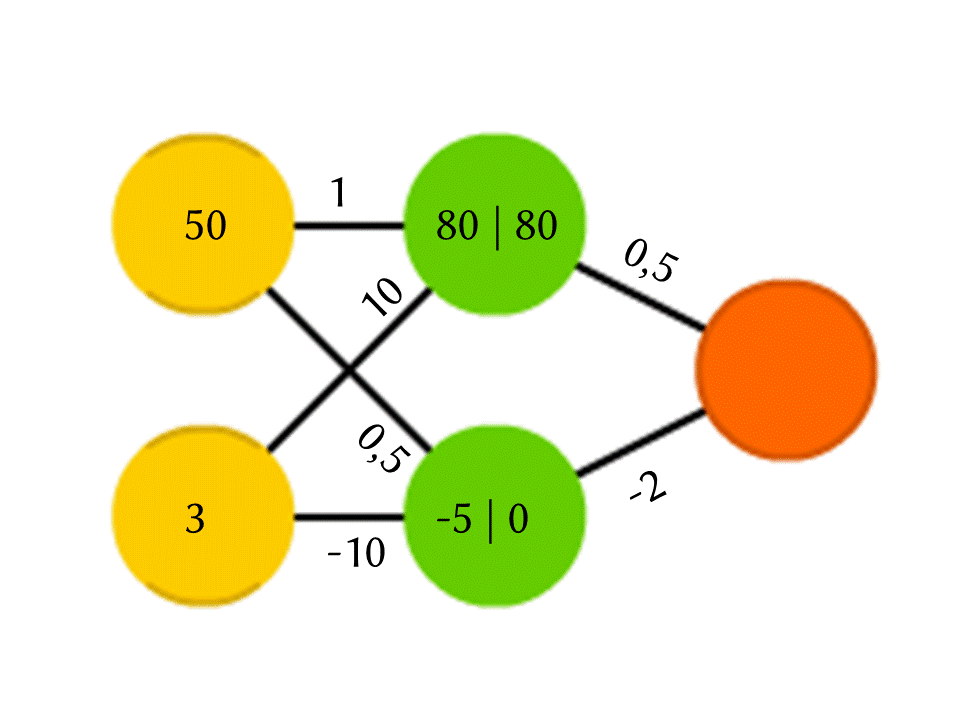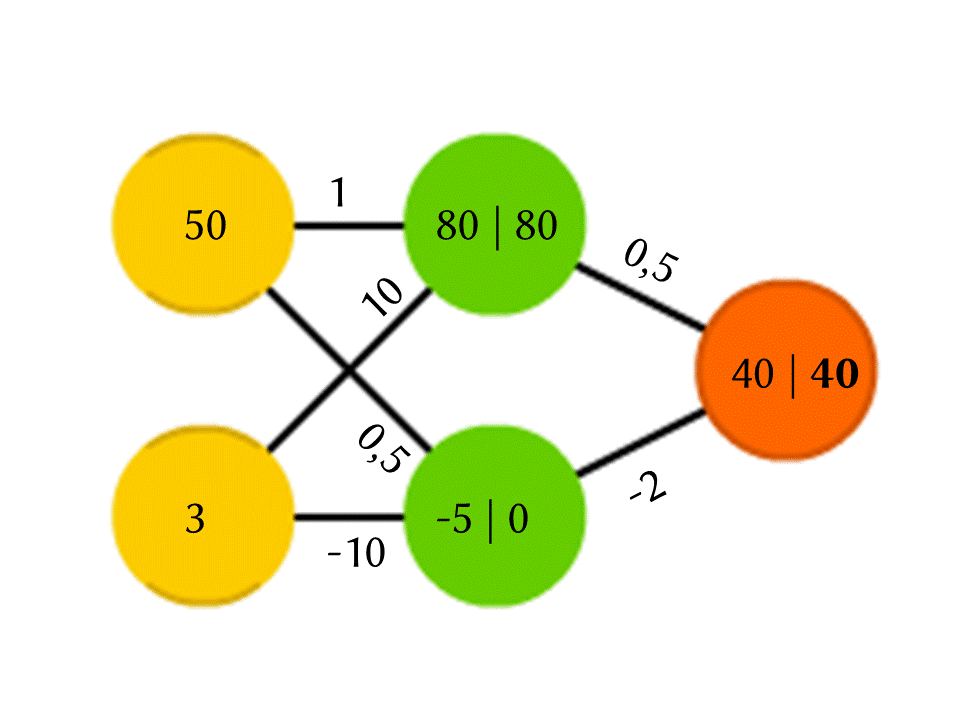
However, if we only do this, we will get at the output simply the result of calculating the linear function of the input values (in our example 25 Y - 0.5 X will be released, where X is the number in the upper yellow neuron, and Y is in the lower), therefore, we agree that something else is going on inside the neuron. The simplest and at the same time yielding good results is the ReLU (Rectified Linear Unit) function: if a neuron has a negative number, we give it to output 0, and if it is non-negative, we give it in unchanged form.
So, in our −5 scheme, at the output of the lower green neuron, it turns into 0, and it is this number that is used in further calculations. Of course, the architecture of real neural networks used in practice is much more complicated than our toy examples, and weights are taken not from the ceiling, but are selected by training, but the principle itself is important.
What does this have to do with the language?
The most direct, provided that we represent the language as numbers. Encode each word and launch into such a neural network.
Here a very important achievement of computational linguistics comes to the rescue, which appeared in terms of ideas 50 years ago, and in terms of implementation, the last 10 years have been actively developing: the vector representation of words.

This and the two following pictures are from the presentation of Stefan Evert.
This is a representation of words as an array of numbers based on a very simple consideration. In order to learn the meaning of a word, we look not into a dictionary, but into huge arrays of text and we consider next to which our word occurs more often.
For example, do you know the word muffler? If not, try to guess by looking at the texts where the word muffler is.
- Black coat and white cap. Well, and some other indispensable muffler ...
Next to him are garments, a coat and a cap, probably, and a muffler from their row. This is hardly a food, hardly an element of architecture.
“For some reason, on the neck of his stuffy night, an old striped muffler was crouched.
On the neck - it means that it is not socks. It can be screwed up - apparently, it is flexible, made of cloth, and not, say, of wood or stone.
“Nerzhin’s wet towel was hung on his neck like a muffler.”
We replenish and replenish the bank of examples and, looking at them, we will gradually understand what a muffler is - something like a scarf. Exactly the same thing makes the computer, which looks at the text and does a simple thing - fixes the words that stand nearby.
Here are the Egyptian hieroglyphs.
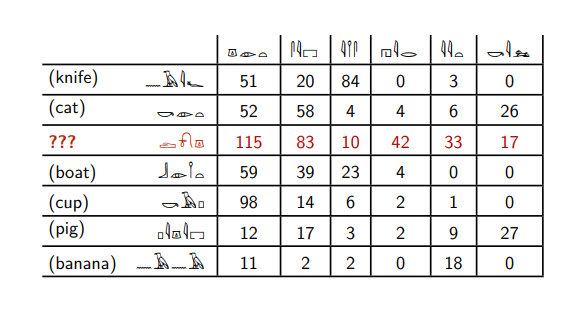
Suppose you know the meanings of six of them, and you want to understand what word is highlighted in red. This table says how many times these words are found next to other Egyptian hieroglyphs.
The red word meets the sixth word - the same as the words cat and pig . And other words do not meet him at all.
The red word meets with the second word much more often than with the third, unlike the words knife and banana. The words cat, boat, pig and cup behave in the same way .
Based on such reasoning, we can say that the red word is most similar to the words cat and pig - only they are found with the sixth word, they have a similar ratio of the second and third.
And we will not be mistaken, because the red word is the word dog .

In fact, these are not Egyptian hieroglyphs, but English nouns and verbs, for which it is indicated how many times they appear together in a large collection of English texts. That sixth word is the verb kill .
The words cat, dog and pigoften found to the right of the word kill . Knives, boats and bananas are rarely killed. Although in Russian, if you wish, you can say, “I killed my boat,” but this is a rare thing.
This is exactly what a computer does when it processes text. He simply thinks that he is found next to something, and no more masterpieces of understanding occur.
Next, the computer represents words in the form of a certain set of numbers: in the example above, the word dog corresponds to numbers (115; 83; 10; 42; 33; 17). In fact, we must calculate how many times it occurs not with six words, but with all the words in our texts: if we have 100,000 different words, then the word dogwe will associate an array of 100,000 numbers. This is not very convenient in practice, so methods of decreasing the dimensions are usually used to convert the results obtained for each word into an array of several hundred elements in length (for more details, read here ).
There are ready-made libraries for programming languages that allow you to do this: for example, gensim for Python. After giving her an input of about 1 million words in the Brownian corpus of English , in a few seconds I can build a model in which the word cat will look like this:

We represent an animal, with fur, tail, it meows. My computer, which I taught English, represents the wordcat in the form of a hundred numbers, which came from the adjacent words.
Here is an example on Russian material from the RusVectōres site . I took the word raven and asked the computer to tell me which words most resemble it - or, in other words, sets of numbers for which words most resemble a set of numbers for the word raven .

8 words out of 10 were the names of the birds. Without knowing anything, the computer produced an excellent result - I realized that birds look like a crow. But where did the words come from and the rulenka?
You can guess
With all three, the word white is often used: to white heat, under the white ruchenki, white crow.
By receiving arrays of numbers and passing them through themselves, neural networks produce an amazingly good result. Here is a rather complex, philosophical text from the speech of Academician Andrei Zaliznyak, devoted to the status of science in the modern world. He translated into English by Google translator a month ago, and requires minimal editor intervention.

Here a global philosophical question arises.
This is the problem of the so-called Chinese room - a thought experiment about the limits of artificial intelligence. He was formulated by the philosopher John Searle in 1980.
In the room sits a man who does not know Chinese. He was given instructions, he has books, dictionaries and two windows. In one window he is given little notes in Chinese, and in another window he gives answers - also in Chinese, acting solely on instructions.
For example, in the instructions it can be written, “here you have received a note, find the hieroglyph in the dictionary. If this is the hieroglyph number 518, give out the hieroglyph number 409 in the right window, if the hieroglyph number 711 has entered, give out the character number 35 in the right window, and so on. ” If the person in the room performs the instructions well and if these instructions are well written, then the person on the street who gives and receives little notes may assume that the room or the person who is in it knows the Chinese language. After all, outside it is not visible what is happening inside.
We know that this is a man who just gave stupid instructions. He performs some operations on them, but does not know Chinese at all. Although from the point of view of the observer - this is knowledge of the language.
The philosophical question is how do we relate to this? Does the room know Chinese? Maybe the Chinese language knows the author of these instructions? Or maybe not, because you can issue instructions based on an array of ready-made questions and answers.
On the other hand, what does it mean to know Chinese? Here you know Russian. What can you do? What is going on in your head? Any biochemical reactions. Ears or eyes get some signal, it causes some reactions, you understand something. But what does "understand" mean? What do you do when you understand?
And an even more difficult question - do you do it in the best way? Is it true that you work with the language better than any apparatus could work with the language? Can you imagine that you will speak Russian worse than any computer? We always compare Siri, Alice with how we speak, and laugh, if they speak wrong from our point of view. On the other hand, we gave the computer a lot of what was previously considered the prerogative of man. Nowadays, machines count and play chess much better, but earlier they could not. It is possible that something similar will happen with talking computers: after 100, 10, or even 5 years we recognize that the machine has mastered the language much better, understands much more and is generally a much better native-language speaker than we are.
What then to do with the fact that a person is used to define himself through language? After all, they say, only a person speaks the language. What happens if we recognize the victory at the computer and in this area?
Leave your questions in the comments. Perhaps a little later we will be able to do an interview with Alexander. Or maybe he himself will come to the comments on our invite and talk to everyone who is interested.